Les organisations ont choisi de construire des lacs de données au-dessus de Service de stockage simple Amazon (Amazon S3) depuis de nombreuses années. Un lac de données est le choix le plus populaire pour les organisations pour stocker toutes leurs données organisationnelles générées par différentes équipes, dans tous les domaines d'activité, à partir de tous les formats différents, et même au cours de l'historique. Selon selon une étude, l'entreprise moyenne voit le volume de ses données augmenter à un rythme supérieur à 50 % par an, gérant généralement en moyenne 33 sources de données uniques à des fins d'analyse.
Les équipes tentent souvent de répliquer des milliers de tâches à partir de bases de données relationnelles avec le même modèle d'extraction, de transformation et de chargement (ETL). Il y a beaucoup d'efforts pour maintenir les états des travaux et planifier ces travaux individuels. Cette approche aide les équipes à ajouter des tables avec peu de modifications et à maintenir le statut du travail avec un minimum d'effort. Cela peut conduire à une amélioration considérable du calendrier de développement et au suivi des travaux avec facilité.
Dans cet article, nous vous montrons comment répliquer facilement tous vos magasins de données relationnelles dans un lac de données transactionnel de manière automatisée avec un seul travail ETL utilisant Apache Iceberg et Colle AWS.
Architecture de la solution
Les lacs de données sont habituellement organisé en utilisant des compartiments S3 distincts pour trois couches de données : la couche brute contenant les données dans leur forme d'origine, la couche intermédiaire contenant les données traitées intermédiaires optimisées pour la consommation et la couche d'analyse contenant des données agrégées pour des cas d'utilisation spécifiques. Dans la couche brute, les tables sont généralement organisées en fonction de leurs sources de données, tandis que les tables de la couche intermédiaire sont organisées en fonction des domaines métier auxquels elles appartiennent.
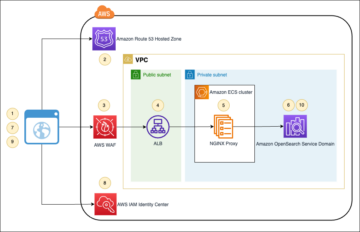
Ce poste propose une AWS CloudFormation modèle qui déploie une tâche AWS Glue qui lit un chemin Amazon S3 pour une source de données de la couche brute du lac de données et ingère les données dans les tables Apache Iceberg sur la couche d'étape à l'aide Prise en charge d'AWS Glue pour les infrastructures de lac de données. Le travail s'attend à ce que les tables de la couche brute soient structurées de la manière Service de migration de base de données AWS (AWS DMS) les ingère : schéma, puis table, puis fichiers de données.
Cette solution utilise Magasin de paramètres AWS Systems Manager pour la configuration des tableaux. Vous devez modifier ce paramètre en spécifiant les tables que vous souhaitez traiter et comment, y compris des informations telles que la clé primaire, les partitions et le domaine métier associé. Le travail utilise ces informations pour créer automatiquement une base de données (si elle n'existe pas déjà) pour chaque domaine métier, créer les tables Iceberg et effectuer le chargement des données.
Enfin, nous pouvons utiliser Amazone Athéna pour interroger les données dans les tables Iceberg.
Le diagramme suivant illustre cette architecture.

Cette implémentation a les considérations suivantes :
- Toutes les tables de la source de données doivent avoir une clé primaire pour être répliquées à l'aide de cette solution. La clé primaire peut être une seule colonne ou une clé composite avec plusieurs colonnes.
- Si le lac de données contient des tables qui n'ont pas besoin d'upserts ou qui n'ont pas de clé primaire, vous pouvez les exclure de la configuration des paramètres et implémenter des processus ETL traditionnels pour les ingérer dans le lac de données. C'est en dehors de la portée de ce post.
- Si des sources de données supplémentaires doivent être ingérées, vous pouvez déployer plusieurs piles CloudFormation, une pour gérer chaque source de données.
- La tâche AWS Glue est conçue pour traiter les données en deux phases : le chargement initial qui s'exécute une fois qu'AWS DMS a terminé la tâche de chargement complet et le chargement incrémentiel qui s'exécute selon une planification qui applique les fichiers de capture de données modifiées (CDC) capturés par AWS DMS. Le traitement incrémental est effectué à l'aide d'un Signet de tâche AWS Glue.
Il y a neuf étapes pour terminer ce didacticiel :
- Configurez un point de terminaison source pour AWS DMS.
- Déployez la solution à l'aide d'AWS CloudFormation.
- Passez en revue la tâche de réplication AWS DMS.
- Ajoutez éventuellement des autorisations pour le chiffrement et le déchiffrement ou Formation AWS Lake.
- Vérifiez la configuration de la table sur Parameter Store.
- Effectuez le chargement initial des données.
- Effectuer un chargement de données incrémentiel.
- Surveiller l'ingestion de table.
- Planifiez le chargement de données par lots incrémentiel.
Pré-requis
Avant de commencer ce didacticiel, vous devez déjà être familiarisé avec Iceberg. Si ce n'est pas le cas, vous pouvez commencer par répliquer une seule table en suivant les instructions de Implémenter un UPSERT basé sur CDC dans un lac de données à l'aide d'Apache Iceberg et d'AWS Glue. En outre, configurez les éléments suivants :
Configurer un point de terminaison source pour AWS DMS
Avant de créer notre tâche AWS DMS, nous devons configurer un point de terminaison source pour se connecter à la base de données source :
- Sur la console AWS DMS, choisissez Endpoints dans le volet de navigation.
- Selectionnez Créer un point de terminaison.
- Si votre base de données s'exécute sur Amazon RDS, choisissez Sélectionnez l'instance de base de données RDS, puis choisissez l'instance dans la liste. Sinon, choisissez le moteur source et fournissez les informations de connexion via AWS Secrets Manager ou manuellement.
- Pour Identifiant du point de terminaison, entrez un nom pour le point de terminaison ; par exemple, source-postgresql.
- Selectionnez Créer un point de terminaison.
Déployez la solution à l'aide d'AWS CloudFormation
Créez une pile CloudFormation à l'aide du modèle fourni. Effectuez les étapes suivantes :
- Selectionnez Pile de lancement :

- Selectionnez Suivant.
- Indiquez un nom de pile, tel que
transactionaldl-postgresql. - Saisissez les paramètres requis :
- DMSS3EndpointIAMRoleARN – L'ARN du rôle IAM pour AWS DMS pour écrire des données dans Amazon S3.
- ReplicationInstanceArnReplicationInstanceArn – L'ARN de l'instance de réplication AWS DMS.
- S3BucketStage – Le nom du compartiment existant utilisé pour la couche intermédiaire du lac de données.
- S3BucketColle – Le nom du compartiment S3 existant pour stocker les scripts AWS Glue.
- S3BucketBrut – Le nom du compartiment existant utilisé pour la couche brute du lac de données.
- SourceEndpointArn – L'ARN du point de terminaison AWS DMS que vous avez créé précédemment.
- Nom de la source – L'identifiant arbitraire de la source de données à répliquer (par exemple,
postgres). Ceci est utilisé pour définir le chemin S3 du lac de données (couche brute) où les données seront stockées.
- Ne modifiez pas les paramètres suivants :
- SourceS3BucketBlog – Le nom du compartiment dans lequel le script AWS Glue fourni est stocké.
- Préfixe SourceS3Bucket – Le nom du préfixe de compartiment dans lequel le script AWS Glue fourni est stocké.
- Selectionnez Suivant deux fois.
- Sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM avec des noms personnalisés.
- Selectionnez Créer une pile.
Après environ 5 minutes, la pile CloudFormation est déployée.
Examiner la tâche de réplication AWS DMS
Le déploiement AWS CloudFormation a créé un point de terminaison cible AWS DMS pour vous. En raison de deux paramètres de point de terminaison spécifiques, les données seront ingérées selon nos besoins sur Amazon S3.
- Sur la console AWS DMS, choisissez Endpoints dans le volet de navigation.
- Recherchez et choisissez le point de terminaison qui commence par
dmsIcebergs3endpoint. - Vérifiez les paramètres du point de terminaison :
DataFormatest spécifié commeparquet.TimestampColumnNameajoutera la colonnelast_update_timeavec la date de création des enregistrements sur Amazon S3.

Le déploiement crée également une tâche de réplication AWS DMS qui commence par dmsicebergtask.
- Selectionnez Tâches de réplication dans le volet de navigation et recherchez la tâche.
Vous verrez que le Type de tâche est marqué comme Chargement complet, réplication continue. AWS DMS effectuera un chargement initial complet des données existantes, puis créera des fichiers incrémentiels avec les modifications apportées à la base de données source.
Sur le Règles de mappage , il existe deux types de règles :
- Une règle de sélection avec le nom du schéma source et des tables qui seront ingérées à partir de la base de données source. Par défaut, il utilise la base de données exemple fournie dans les prérequis,
dms_sample, et toutes les tables avec le mot-clé %. - Deux règles de transformation qui incluent dans les fichiers cibles sur Amazon S3 le nom du schéma et le nom de la table sous forme de colonnes. Ceci est utilisé par notre tâche AWS Glue pour savoir à quelles tables correspondent les fichiers du lac de données.
Pour en savoir plus sur la façon de personnaliser cela pour vos propres sources de données, reportez-vous à Règles de sélection et actions.

Modifions quelques configurations pour terminer la préparation de notre tâche.
- Sur le Actions menu, choisissez modifier.
- Dans le Paramètres de la tâche section, sous Arrêter la tâche une fois le chargement complet terminé, choisissez Arrêter après avoir appliqué les modifications mises en cache.
De cette façon, nous pouvons contrôler le chargement initial et la génération de fichiers incrémentiels en deux étapes différentes. Nous utilisons cette approche en deux étapes pour exécuter la tâche AWS Glue une fois par étape.
- Sous Journaux des tâches, choisissez Activer les journaux CloudWatch.
- Selectionnez Épargnez.
- Attendez environ 1 minute pour que l'état de la tâche de migration de la base de données s'affiche comme Prêt à fonctionner.
Ajouter des autorisations pour le chiffrement et le déchiffrement ou Lake Formation
En option, vous pouvez ajouter des autorisations pour le chiffrement et le déchiffrement ou Lake Formation.
Ajouter des autorisations de chiffrement et de déchiffrement
Si vos compartiments S3 utilisés pour les couches brutes et intermédiaires sont chiffrés à l'aide Service de gestion des clés AWS (AWS KMS) clés gérées par le client, vous devez ajouter des autorisations pour permettre à la tâche AWS Glue d'accéder aux données :
Ajouter des autorisations de formation de lac
Si vous gérez les autorisations à l'aide de Lake Formation, vous devez autoriser votre travail AWS Glue à créer les bases de données et les tables de votre domaine via le rôle IAM GlueJobRole.
- Accorder des autorisations pour créer des bases de données (pour obtenir des instructions, reportez-vous à Création d'une base de données).
- Accordez des autorisations SUPER au
defaultbase de données. - Accorder des autorisations d'emplacement des données.
- Si vous créez des bases de données manuellement, accordez des autorisations sur toutes les bases de données pour créer des tables. Faire référence à Accorder des autorisations de table à l'aide de la console Lake Formation et de la méthode de ressource nommée or Accorder des autorisations Data Catalog à l'aide de la méthode LF-TBAC selon votre cas d'utilisation.
Une fois que vous avez terminé l'étape ultérieure d'exécution du chargement initial des données, assurez-vous d'ajouter également des autorisations permettant aux consommateurs d'interroger les tables. Le rôle de travail deviendra le propriétaire de toutes les tables créées, et l'administrateur du lac de données pourra alors accorder des droits à des utilisateurs supplémentaires.
Examiner la configuration de la table dans Parameter Store
La tâche AWS Glue qui effectue l'ingestion de données dans les tables Iceberg utilise la spécification de table fournie dans Parameter Store. Effectuez les étapes suivantes pour examiner le magasin de paramètres qui a été configuré automatiquement pour vous. Si nécessaire, modifiez selon vos propres besoins.
- Sur la console Parameter Store, choisissez Mes paramètres dans le volet de navigation.
La pile CloudFormation a créé deux paramètres :
iceberg-configpour les configurations de travailiceberg-tablespour la configuration des tables
- Choisissez le paramètre tables iceberg.
La structure JSON contient des informations qu'AWS Glue utilise pour lire les données et écrire les tables Iceberg sur le domaine cible :
- Un objet par table – Le nom de l'objet est créé à l'aide du nom du schéma, d'un point et du nom de la table ; Par exemple,
schema.table. - clé primaire – Cela doit être spécifié pour chaque table source. Vous pouvez fournir une seule colonne ou une liste de colonnes séparées par des virgules (sans espaces).
- partitionCols – Cela partitionne éventuellement les colonnes pour les tables cibles. Si vous ne souhaitez pas créer de tables partitionnées, fournissez une chaîne vide. Sinon, fournissez une seule colonne ou une liste de colonnes séparées par des virgules à utiliser (sans espaces).
- Si vous souhaitez utiliser votre propre source de données, utilisez le code JSON suivant et remplacez le texte en CAPS à partir du modèle fourni. Si vous utilisez l'exemple de source de données fourni, conservez les paramètres par défaut :
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Selectionnez Enregistrer les modifications.
Effectuer le chargement initial des données
Maintenant que la configuration requise est terminée, nous ingérons les données initiales. Cette étape comprend trois parties : ingestion des données de la base de données relationnelle source dans la couche brute du lac de données, création des tables Iceberg sur la couche intermédiaire du lac de données et vérification des résultats à l'aide d'Athena.
Ingérer des données dans la couche brute du lac de données
Pour ingérer les données de la source de données relationnelle (PostgreSQL si vous utilisez l'exemple fourni) dans notre lac de données transactionnel à l'aide d'Iceberg, procédez comme suit :
- Sur la console AWS DMS, choisissez Tâches de migration de base de données dans le volet de navigation.
- Sélectionnez la tâche de réplication que vous avez créée et sur le Actions menu, choisissez Redémarrer/Reprendre.
- Attendez environ 5 minutes que la tâche de réplication se termine. Vous pouvez surveiller les tables ingérées sur le Statistique de la tâche de réplication.

Après quelques minutes, la tâche se termine avec le message Chargement complet terminé.
- Sur la console Amazon S3, choisissez le compartiment que vous avez défini comme couche brute.
Sous le préfixe S3 défini sur AWS DMS (par exemple, postgres), vous devriez voir une hiérarchie de dossiers avec la structure suivante :
- Programme
- Nom de la table
LOAD00000001.parquetLOAD0000000N.parquet
- Nom de la table

Si votre compartiment S3 est vide, passez en revue Dépannage des tâches de migration dans AWS Database Migration Service avant d'exécuter la tâche AWS Glue.
Créer et ingérer des données dans des tables Iceberg
Avant d'exécuter la tâche, parcourons le script de la tâche AWS Glue fourni dans le cadre de la pile CloudFormation pour comprendre son comportement.
- Sur la console AWS Glue Studio, choisissez Emplois dans le volet de navigation.
- Rechercher l'emploi qui commence par
IcebergJob-et un suffixe du nom de votre pile CloudFormation (par exemple,IcebergJob-transactionaldl-postgresql). - Choisissez le travail.

Le script de travail obtient la configuration dont il a besoin à partir de Parameter Store. La fonction getConfigFromSSM() renvoie les configurations liées à la tâche, telles que les compartiments source et cible à partir desquels les données doivent être lues et écrites. La variable ssmparam_table_values contiennent des informations relatives aux tables telles que le domaine de données, le nom de la table, les colonnes de partition et la clé primaire des tables qui doivent être ingérées. Voir le code Python suivant :
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']Le script utilise un nom de catalogue arbitraire pour Iceberg défini comme my_catalog. Ceci est implémenté sur le catalogue de données AWS Glue à l'aide de configurations Spark, de sorte qu'une opération SQL pointant vers my_catalog sera appliquée sur le catalogue de données. Voir le code suivant :
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
Le script itère sur les tables définies dans Parameter Store et exécute la logique pour détecter si la table existe et si les données entrantes sont un chargement initial ou un upsert :
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')La initialLoadRecordsSparkSQL() La fonction charge les données initiales lorsqu'aucune colonne d'opération n'est présente dans les fichiers S3. AWS DMS ajoute cette colonne uniquement aux fichiers de données Parquet produits par la réplication continue (CDC). Le chargement des données est effectué à l'aide de la commande INSERT INTO avec SparkSQL. Voir le code suivant :
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Maintenant, nous exécutons la tâche AWS Glue pour ingérer les données initiales dans les tables Iceberg. La pile CloudFormation ajoute le --datalake-formats paramètre, en ajoutant les bibliothèques Iceberg requises au travail.
- Selectionnez Exécuter le travail.
- Selectionnez Exécutions de tâches pour surveiller l'état. Attendez que l'état soit Exécution réussie.
Vérifier les données chargées
Pour confirmer que la tâche a traité les données comme prévu, procédez comme suit :
- Sur la console Athena, choisissez Éditeur de requête dans le volet de navigation.
- Vérifier
AwsDataCatalogest sélectionné comme source de données. - Sous Base de données, choisissez le domaine de données que vous souhaitez explorer, en fonction de la configuration que vous avez définie dans le magasin de paramètres. Si vous utilisez l'exemple de base de données fourni, utilisez
sports.
Sous Tableaux et vues, nous pouvons voir la liste des tables qui ont été créées par la tâche AWS Glue.
- Choisissez le menu des options (trois points) à côté du premier nom de table, puis choisissez Données de prévisualisation.
Vous pouvez voir les données chargées dans les tables Iceberg. 
Effectuer un chargement de données incrémentiel
Nous commençons maintenant à capturer les modifications de notre base de données relationnelle et à les appliquer au lac de données transactionnel. Cette étape est également divisée en trois parties : capturer les modifications, les appliquer aux tables Iceberg et vérifier les résultats.
Capturer les modifications de la base de données relationnelle
En raison de la configuration que nous avons spécifiée, la tâche de réplication s'est arrêtée après l'exécution de la phase de chargement complet. Maintenant, nous redémarrons la tâche pour ajouter des fichiers incrémentiels avec des modifications dans la couche brute du lac de données.
- Sur la console AWS DMS, sélectionnez la tâche que nous avons créée et exécutée auparavant.
- Sur le Actions menu, choisissez Reprendre.
- Selectionnez Démarrer la tâche pour commencer à capturer les modifications.
- Pour déclencher la création de nouveaux fichiers sur le lac de données, effectuez des insertions, des mises à jour ou des suppressions sur les tables de votre base de données source à l'aide de votre outil d'administration de base de données préféré. Si vous utilisez l'exemple de base de données fourni, vous pouvez exécuter les commandes SQL suivantes :
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- Sur la page des détails de la tâche AWS DMS, choisissez le Statistiques du tableau onglet pour voir les changements capturés.

- Ouvrez la couche brute du lac de données pour trouver un nouveau fichier contenant les modifications incrémentielles à l'intérieur du préfixe de chaque table, par exemple sous le
sporting_eventpréfixe.
Le dossier avec des changements pour le sporting_event le tableau ressemble à la capture d'écran suivante.

Notez le Op colonne au début identifiée par une mise à jour (U). De plus, la deuxième valeur de date/heure est la colonne de contrôle ajoutée par AWS DMS avec l'heure à laquelle la modification a été capturée.

Appliquer les modifications sur les tables Iceberg à l'aide d'AWS Glue
Maintenant, nous exécutons à nouveau la tâche AWS Glue, et elle ne traitera automatiquement que les nouveaux fichiers incrémentiels puisque le signet de la tâche est activé. Voyons comment cela fonctionne.
La dedupCDCRecords() La fonction effectue la déduplication des données, car plusieurs modifications apportées à un seul ID d'enregistrement peuvent être capturées dans le même fichier de données sur Amazon S3. La déduplication est effectuée en fonction de la last_update_time colonne ajoutée par AWS DMS qui indique l'horodatage du moment où la modification a été capturée. Voir le code Python suivant :
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFA la ligne 99, le upsertRecordsSparkSQL() La fonction effectue l'upsert de la même manière que le chargement initial, mais cette fois avec une commande SQL MERGE.
Examinez les modifications appliquées
Ouvrez la console Athena et exécutez une requête qui sélectionne les enregistrements modifiés dans la base de données source. Si vous utilisez l'exemple de base de données fourni, utilisez l'une des requêtes SQL suivantes :
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Surveiller l'ingestion de table
Le script de travail AWS Glue est codé avec de simples Gestion des exceptions Python pour intercepter les erreurs lors du traitement d'une table spécifique. Le signet de la tâche est enregistré une fois que chaque table a été traitée avec succès, pour éviter de retraiter les tables si l'exécution de la tâche est retentée pour les tables contenant des erreurs.
La Interface de ligne de commande AWS (AWS CLI) fournit une get-job-bookmark commande pour AWS Glue qui fournit un aperçu de l'état du signet pour chaque table traitée.
- Sur la console AWS Glue Studio, choisissez la tâche ETL.
- Choisissez le Exécutions de tâches et copiez l'ID d'exécution de la tâche.
- Exécutez la commande suivante sur un terminal authentifié pour l'AWS CLI, en remplaçant
<GLUE_JOB_RUN_ID>sur la ligne 1 avec la valeur que vous avez copiée. Si votre pile CloudFormation n'est pas nomméetransactionaldl-postgresql, indiquez le nom de votre travail à la ligne 2 du script :
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunDans cette solution, lorsqu'un traitement de table provoque une exception, la tâche AWS Glue n'échouera pas selon cette logique. Au lieu de cela, la table sera ajoutée dans un tableau qui est imprimé une fois le travail terminé. Dans un tel scénario, la tâche sera marquée comme ayant échoué après avoir tenté de traiter le reste des tables détectées sur la source de données brutes. De cette façon, les tables sans erreurs n'ont pas à attendre que l'utilisateur identifie et résolve le problème sur les tables en conflit. L'utilisateur peut rapidement détecter les exécutions de tâche qui ont rencontré des problèmes à l'aide de l'état d'exécution de la tâche AWS Glue et identifier les tables spécifiques à l'origine du problème à l'aide des journaux CloudWatch pour l'exécution de la tâche.
- Le script de travail implémente cette fonctionnalité avec le code Python suivant :
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')La capture d'écran suivante montre comment les journaux CloudWatch recherchent les tables qui provoquent des erreurs de traitement.

Aligné avec le Lentille d'analyse de données AWS Well-Architected Framework pratiques, vous pouvez adapter des mécanismes de contrôle plus sophistiqués pour identifier et notifier les parties prenantes lorsque des erreurs apparaissent sur les pipelines de données. Par exemple, vous pouvez utiliser un Amazon DynamoDB table de contrôle pour stocker toutes les tables et les exécutions de travaux avec des erreurs, ou en utilisant Service de notification simple d'Amazon (Amazon SNS) à envoyer des alertes aux opérateurs lorsque certains critères sont remplis.
Planifier le chargement de données par lots incrémentiel
La pile CloudFormation déploie un Amazon Event Bridge règle (désactivée par défaut) qui peut déclencher l'exécution de la tâche AWS Glue selon une planification. Pour fournir votre propre planification et activer la règle, procédez comme suit :
- Sur la console EventBridge, choisissez Règles dans le volet de navigation.
- Recherchez la règle précédée du nom de votre pile CloudFormation suivi de
JobTrigger(par exemple,transactionaldl-postgresql-JobTrigger-randomvalue). - Choisissez la règle.
- Sous Calendrier officiel des événements, choisissez Modifier.
La planification par défaut est configurée pour se déclencher toutes les heures.
- Fournissez la planification que vous souhaitez exécuter le travail.
- De plus, vous pouvez utiliser un Expression cron EventBridge en sélectionnant Un calendrier détaillé.

- Lorsque vous avez terminé de configurer l'expression cron, choisissez Suivant trois fois, et enfin choisir Mettre à jour la règle enregistrer les modifications
La règle est créée désactivée par défaut pour vous permettre d'exécuter le chargement de données initial en premier.
- Activez la règle en choisissant Activer.
Vous pouvez utiliser le Le Monitoring pour afficher les invocations de règles, ou directement sur AWS Glue Exécution du travail détails.
Conclusion
Après avoir déployé cette solution, vous avez automatisé l'ingestion de vos tables sur une seule source de données relationnelle. Les organisations qui utilisent un lac de données comme plate-forme de données centrale doivent généralement gérer plusieurs, parfois même des dizaines de sources de données. De plus, de plus en plus de cas d'utilisation obligent les organisations à mettre en œuvre des capacités transactionnelles dans le lac de données. Vous pouvez utiliser cette solution pour accélérer l'adoption de ces fonctionnalités dans toutes vos sources de données relationnelles afin de permettre de nouveaux cas d'utilisation métier, en automatisant le processus de mise en œuvre pour tirer davantage de valeur de vos données.
À propos des auteurs
 Luis Gérardo Baeza est architecte Big Data au sein du laboratoire de données Amazon Web Services (AWS). Il a 12 ans d'expérience dans l'aide aux organisations des secteurs de la santé, de la finance et de l'éducation pour adopter des programmes d'architecture d'entreprise, le cloud computing et des capacités d'analyse de données. Luis aide actuellement des organisations à travers l'Amérique latine à accélérer les initiatives de données stratégiques.
Luis Gérardo Baeza est architecte Big Data au sein du laboratoire de données Amazon Web Services (AWS). Il a 12 ans d'expérience dans l'aide aux organisations des secteurs de la santé, de la finance et de l'éducation pour adopter des programmes d'architecture d'entreprise, le cloud computing et des capacités d'analyse de données. Luis aide actuellement des organisations à travers l'Amérique latine à accélérer les initiatives de données stratégiques.
 SaiKiran Reddy Aenugu est architecte de données au sein du laboratoire de données Amazon Web Services (AWS). Il a 10 ans d'expérience dans la mise en œuvre de processus de chargement, de transformation et de visualisation de données. SaiKiran aide actuellement les organisations en Amérique du Nord à adopter des architectures de données modernes telles que les lacs de données et le maillage de données. Il a de l'expérience dans les secteurs de la vente au détail, du transport aérien et de la finance.
SaiKiran Reddy Aenugu est architecte de données au sein du laboratoire de données Amazon Web Services (AWS). Il a 10 ans d'expérience dans la mise en œuvre de processus de chargement, de transformation et de visualisation de données. SaiKiran aide actuellement les organisations en Amérique du Nord à adopter des architectures de données modernes telles que les lacs de données et le maillage de données. Il a de l'expérience dans les secteurs de la vente au détail, du transport aérien et de la finance.
 Narendra Merla est architecte de données au sein du laboratoire de données Amazon Web Services (AWS). Il a 12 ans d'expérience dans la conception et la production de pipelines de données en temps réel et par lots et dans la création de lacs de données sur des environnements cloud et sur site. Narendra aide actuellement des organisations en Amérique du Nord à construire et à concevoir des architectures de données robustes et possède de l'expérience dans les secteurs des télécommunications et de la finance.
Narendra Merla est architecte de données au sein du laboratoire de données Amazon Web Services (AWS). Il a 12 ans d'expérience dans la conception et la production de pipelines de données en temps réel et par lots et dans la création de lacs de données sur des environnements cloud et sur site. Narendra aide actuellement des organisations en Amérique du Nord à construire et à concevoir des architectures de données robustes et possède de l'expérience dans les secteurs des télécommunications et de la finance.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Qui sommes-nous
- accélérer
- accès
- Selon
- reconnaître
- à travers
- adapter
- ajoutée
- Supplémentaire
- En outre
- Ajoute
- admin
- administration
- adopter
- Adoption
- Après
- compagnie aérienne
- Tous
- déjà
- Amazon
- Amazone Athéna
- Amazon RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- Amérique
- selon une analyse de l’Université de Princeton
- analytique
- ainsi que
- Angeles
- Apache
- apparaître
- Application
- appliqué
- Application
- une approche
- d'environ
- architecture
- tableau
- associé
- authentifié
- automatiser
- Automatisation
- automatiquement
- automatiser
- moyen
- éviter
- AWS
- AWS CloudFormation
- Colle AWS
- basé
- chauves-souris
- car
- devenez
- before
- Début
- Big
- Big Data
- construire
- constructeur
- Développement
- la performance des entreprises
- Peut obtenir
- capacités
- capes
- capturer
- Capturer
- maisons
- cas
- catalogue
- Attraper
- Causes
- les causes
- causer
- CDC
- central
- certaines
- Change
- Modifications
- le choix
- Selectionnez
- choose
- choisi
- le cloud
- le cloud computing
- code
- Colonne
- Colonnes
- Société
- complet
- informatique
- configuration
- les configurations
- Confirmer
- Contradictoire
- NOUS CONTACTER
- connexion
- considérations
- Console
- Les consommateurs
- consommation
- contient
- continuer
- continu
- des bactéries
- pourriez
- engendrent
- créée
- crée des
- La création
- création
- critères
- Lecture
- Customiser
- des clients
- personnaliser
- données
- Analyse de Donnée
- Lac de données
- Plateforme de données
- Base de données
- bases de données
- Date
- Réglage par défaut
- défini
- déployer
- déployé
- déployer
- déploiement
- déploie
- Conception
- un
- conception
- détails
- détecté
- Développement
- différent
- directement
- handicapé
- divisé
- Ne fait pas
- domaine
- domaines
- Ne pas
- pendant
- chacun
- Plus tôt
- même
- Éducation
- effort
- non plus
- permettre
- activé
- crypté
- chiffrement
- Endpoint
- Moteur
- Entrer
- Entreprise
- environnements
- Erreurs
- Ether (ETH)
- Pourtant, la
- Chaque
- exemple
- dépasse
- Sauf
- exception
- existant
- existe
- attendu
- attend
- Découvrez
- explorez
- extensions
- extrait
- Échoué
- familier
- Mode
- Fonctionnalité
- few
- Déposez votre dernière attestation
- Fichiers
- finalement
- finance
- la traduction de documents financiers
- Trouvez
- finition
- Prénom
- suivi
- Abonnement
- Pour les consommateurs
- formulaire
- formation
- Framework
- de
- plein
- fonction
- généré
- génération
- obtenez
- subvention
- subventions
- Croissance
- manipuler
- la médecine
- aider
- aide
- hiérarchie
- Histoire
- tenue
- Comment
- How To
- HTML
- HTTPS
- majeur
- IAM
- identifié
- identifiant
- identifie
- identifier
- Mettre en oeuvre
- la mise en oeuvre
- mis en œuvre
- la mise en œuvre
- met en oeuvre
- amélioration
- in
- comprendre
- inclut
- Y compris
- Nouveau
- indique
- individuel
- d'information
- initiale
- les initiatives
- Inserts
- perspicacité
- instance
- plutôt ;
- Des instructions
- Intermédiaire
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- itération
- Emploi
- Emplois
- json
- XNUMX éléments à
- ACTIVITES
- clés
- Savoir
- laboratoire
- lac
- Danses latines
- Amérique latine
- couche
- poules pondeuses
- conduire
- APPRENTISSAGE
- bibliothèques
- LIMIT
- Gamme
- Liste
- charge
- chargement
- charges
- emplacement
- Style
- LOOKS
- les
- Los Angeles
- Lot
- Entrée
- maintient
- faire
- gérés
- gestion
- manager
- les gérer
- manuellement
- de nombreuses
- cartographie
- marqué
- Menu
- aller
- message
- pourrait
- migration
- minimum
- minute
- minutes
- Villas Modernes
- modifier
- Surveiller
- Stack monitoring
- PLUS
- (en fait, presque toutes)
- Le Plus Populaire
- plusieurs
- prénom
- Nommé
- noms
- NAVIGUER
- Navigation
- Besoin
- nécessaire
- Besoins
- Nouveauté
- next
- Nord
- Amérique du Nord
- déclaration
- nombre
- objet
- objets
- ONE
- en cours
- OP
- opération
- optimisé
- Options
- organisationnel
- organisations
- Organisé
- original
- autrement
- au contrôle
- propre
- propriétaire
- pain
- paramètre
- paramètres
- partie
- les pièces
- chemin
- Patron de Couture
- effectuer
- effectuer
- effectue
- période
- autorisations
- phase
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Populaire
- Post
- Postgresql
- pratiques
- préféré
- conditions préalables
- représentent
- primaire
- Problème
- processus
- les process
- traitement
- Produit
- Programmes
- fournir
- à condition de
- fournit
- Python
- vite.
- augmenter
- Tarif
- raw
- les données brutes
- Lire
- en temps réel
- record
- Articles
- remplacer
- répliquées
- réplication
- exigent
- conditions
- ressource
- Ressources
- REST
- Résultats
- détail
- retourner
- Retours
- Avis
- robuste
- Rôle
- Règle
- Courir
- pour le running
- même
- Épargnez
- scénario
- calendrier
- portée
- scripts
- Rechercher
- Deuxièmement
- Secteurs
- voir
- choisi
- la sélection
- sélection
- séparé
- Services
- set
- mise
- Paramétres
- devrait
- montrer
- Spectacles
- similaires
- étapes
- depuis
- unique
- So
- sur mesure
- Résout
- quelques
- sophistiqué
- Identifier
- Sources
- espaces
- Spark
- groupe de neurones
- spécification
- spécifié
- Sports
- SQL
- empiler
- Combos
- Étape
- parties prenantes
- Commencer
- j'ai commencé
- Commencez
- départs
- États
- statistiques
- Statut
- étapes
- Étapes
- arrêté
- storage
- Boutique
- stockée
- STORES
- Stratégique
- structure
- structuré
- studio
- Avec succès
- tel
- Super
- Support
- Système
- table
- Target
- Tâche
- tâches
- équipe
- équipes
- télécommunications
- modèle
- terminal
- La
- La Source
- leur
- milliers
- trois
- Avec
- fiable
- calendrier
- fois
- horodatage
- à
- outil
- top
- Total
- Tracking
- traditionnel
- transactionnel
- Transformer
- De La Carrosserie
- déclencher
- tutoriel
- types
- sous
- comprendre
- unique
- Mises à jour
- Actualités
- utilisé
- cas d'utilisation
- Utilisateur
- utilisateurs
- d'habitude
- Plus-value
- vérifier
- Voir
- visualisation
- le volume
- attendez
- Entrepots
- web
- services Web
- qui
- sera
- dans les
- sans
- vos contrats
- écrire
- code écrit
- yaml
- an
- années
- Votre
- zéphyrnet