Si vous opérez dans un pays avec plusieurs langues officielles ou dans plusieurs régions, vos fichiers audio peuvent contenir différentes langues. Les participants peuvent parler des langues complètement différentes ou peuvent basculer entre les langues. Envisagez un appel au service client pour signaler un problème dans une zone avec une importante population multilingue. Bien que la conversation puisse commencer dans une langue, il est possible que le client change de langue pour décrire le problème, en fonction de son niveau de confort ou de ses préférences d'utilisation avec d'autres langues. Dans le même ordre d'idées, le représentant du service client peut passer d'une langue à l'autre tout en transmettant des instructions d'utilisation ou de dépannage.
Avec un minimum de 3 secondes d'audio, Amazon Transcribe peut identifier automatiquement et générer efficacement des transcriptions dans les langues parlées dans l'audio sans avoir besoin d'humains pour spécifier les langues. Cela s'applique à divers cas d'utilisation tels que la transcription des appels des clients, la conversion des messages vocaux en texte, la capture des interactions de réunion, le suivi des communications des forums d'utilisateurs ou la surveillance des workflows de production et de localisation de contenu multimédia.
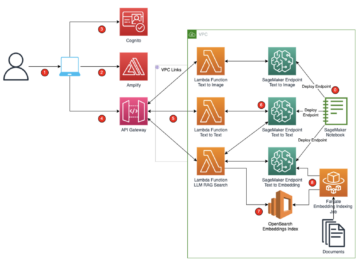
Cet article décrit les étapes de transcription d'un fichier audio multilingue à l'aide d'Amazon Transcribe. Nous expliquons comment rendre les fichiers audio disponibles pour Amazon Transcribe et activer la transcription de fichiers audio multilingues lors de l'appel des API Amazon Transcribe.
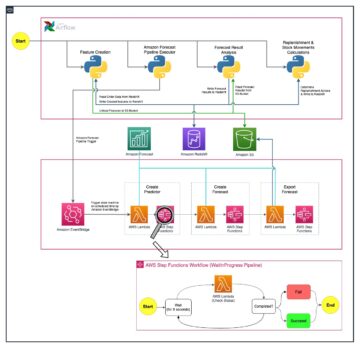
Vue d'ensemble de la solution
Amazon Transcribe est un service AWS qui vous permet de convertir facilement la parole en texte. L'ajout de la fonctionnalité parole au texte à n'importe quelle application est simple avec l'aide d'Amazon Transcribe, un service de reconnaissance vocale automatisée (ASR). Vous pouvez ingérer une entrée audio à l'aide d'Amazon Transcribe, créer des transcriptions claires faciles à lire et à réviser, augmenter la précision grâce à la personnalisation et filtrer les informations pour protéger la confidentialité des clients.
La solution utilise également Service de stockage simple Amazon (Amazon S3), un service de stockage d'objets conçu pour stocker et récupérer n'importe quelle quantité de données de n'importe où. Il s'agit d'un service de stockage simple qui offre une durabilité, une disponibilité, des performances, une sécurité et une évolutivité pratiquement illimitées à un coût très bas. Lorsque vous stockez des données dans Amazon S3, vous travaillez avec des ressources appelées seaux ainsi que objets. Un seau est un conteneur d'objets. Un objet est un fichier et toutes les métadonnées qui décrivent le fichier.
Dans cet article, nous vous expliquons les étapes suivantes pour mettre en œuvre une solution de transcription audio multilingue :
- Créez un compartiment S3.
- Téléchargez votre fichier audio dans le compartiment.
- Créez la tâche de transcription.
- Examinez la sortie du travail.
Pré-requis
Pour cette procédure pas à pas, vous devez disposer des prérequis suivants:
Amazon Transcribe offre la possibilité de stocker la sortie transcrite dans un compartiment S3 géré par le service ou par le client. Pour cet article, Amazon Transcribe écrit les résultats dans un compartiment S3 géré par le service.
Notez qu'Amazon Transcribe est un service régional et que les points de terminaison de l'API Amazon Transcribe appelés doivent se trouver dans la même région que les compartiments S3.
Créez un compartiment S3 pour stocker vos fichiers d'entrée audio
Pour créer votre bucket S3, procédez comme suit :
- Sur la console Amazon S3, choisissez Créer un seau.

- Pour Nom du compartiment, saisissez un nom global unique pour le compartiment.
- Pour Région AWS, choisissez la même région que vos points de terminaison d'API Amazon Transcribe.
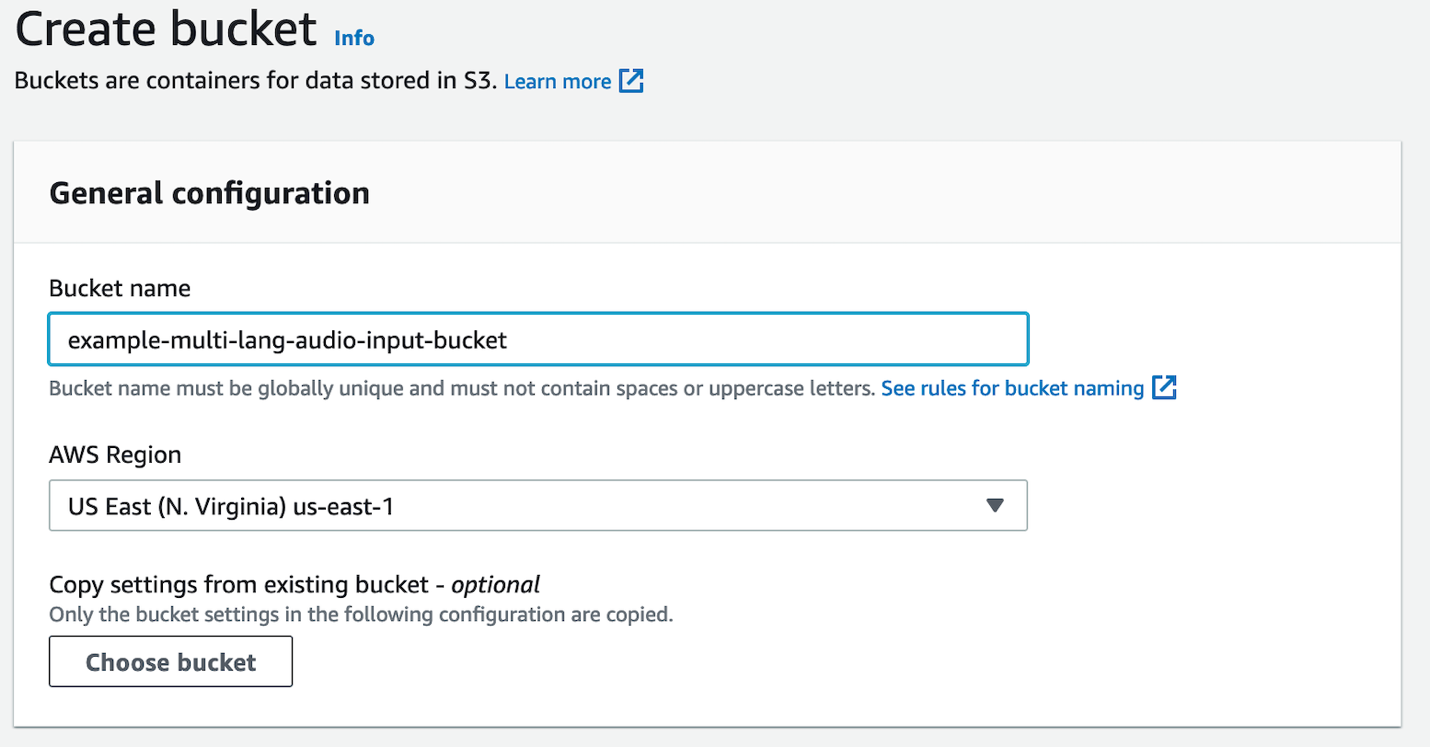
- Laissez toutes les valeurs par défaut telles quelles.
- Selectionnez Créer un seau.
Chargez votre fichier audio dans le compartiment S3
Chargez votre fichier audio multilingue dans le compartiment S3 de votre compte AWS. Pour les besoins de cet exercice, nous utilisons l'exemple suivant fichier audio multilingue. Il capture un appel d'assistance client impliquant les langues anglaise et espagnole.
- Sur la console Amazon S3, choisissez Chapeaux cloche dans le volet de navigation.
- Choisissez le compartiment que vous avez créé précédemment pour stocker les fichiers audio d'entrée.
- Selectionnez Téléchargement.
- Selectionnez Ajouter des fichiers.
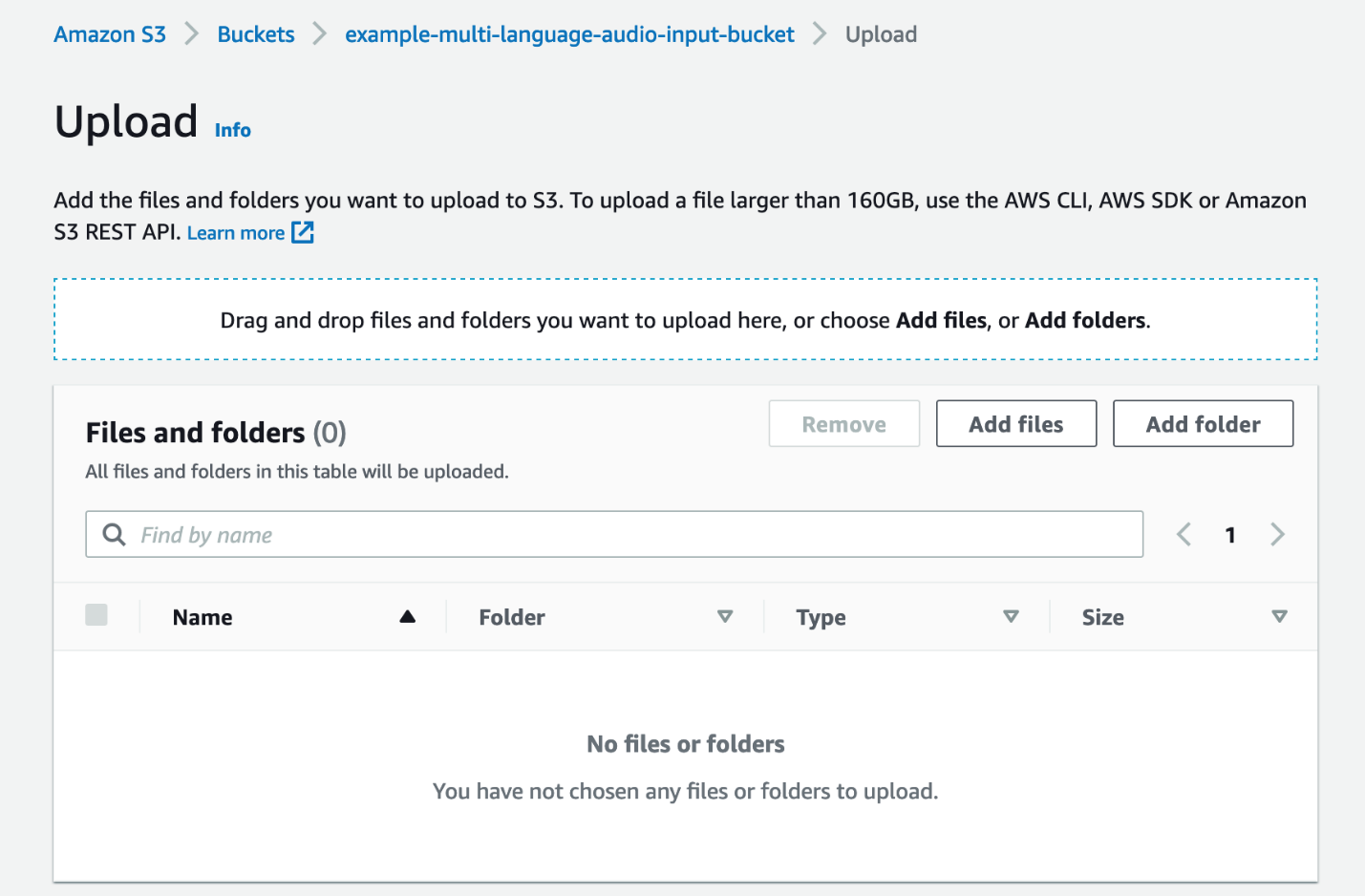
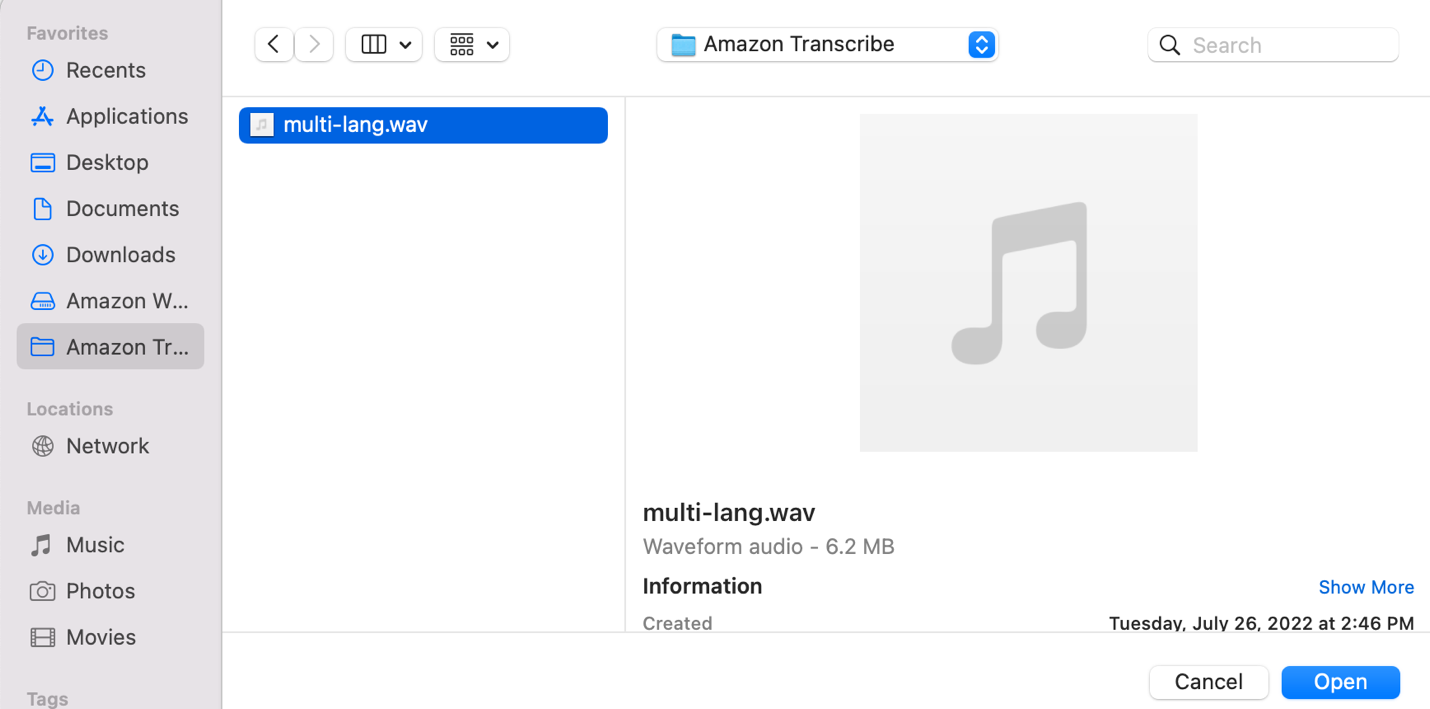
- Choisissez le fichier audio que vous souhaitez transcrire depuis votre ordinateur local.
- Selectionnez Téléchargement.
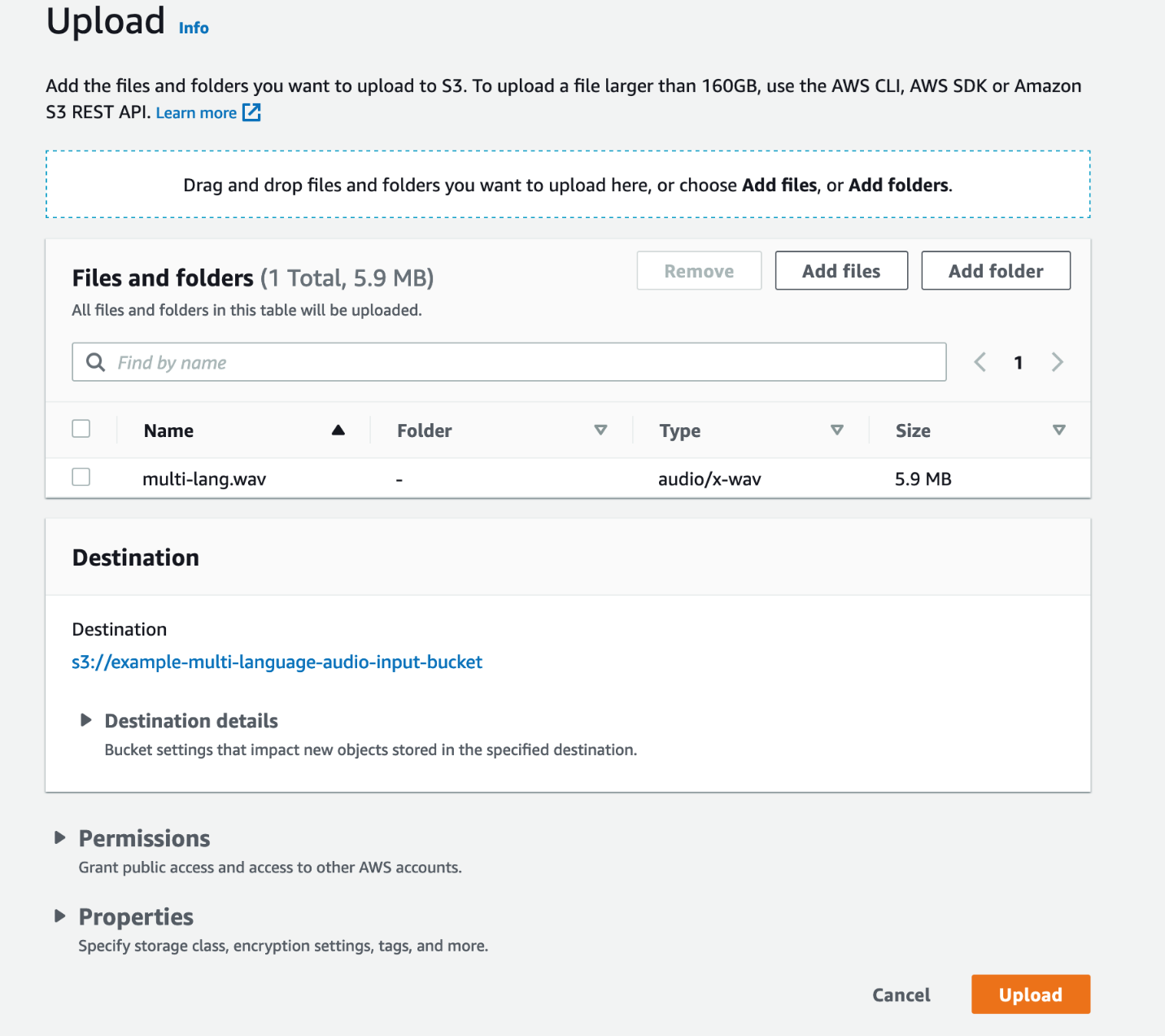
Votre fichier audio sera bientôt disponible dans le compartiment S3.
Créer la tâche de transcription
Une fois le fichier audio téléchargé, nous créons maintenant une tâche de transcription.
- Sur la console Amazon Transcribe, choisissez Emplois de transcription dans le volet de navigation.
- Selectionnez Créer un emploi.

- Pour Nom, saisissez un nom unique pour la tâche.
Ce sera également le nom du fichier de transcription de sortie. - Pour Paramètres de langue, sélectionnez Identification automatique de plusieurs langues.
Cette fonctionnalité permet à Amazon Transcribe d'identifier et de transcrire automatiquement toutes les langues parlées dans le fichier audio.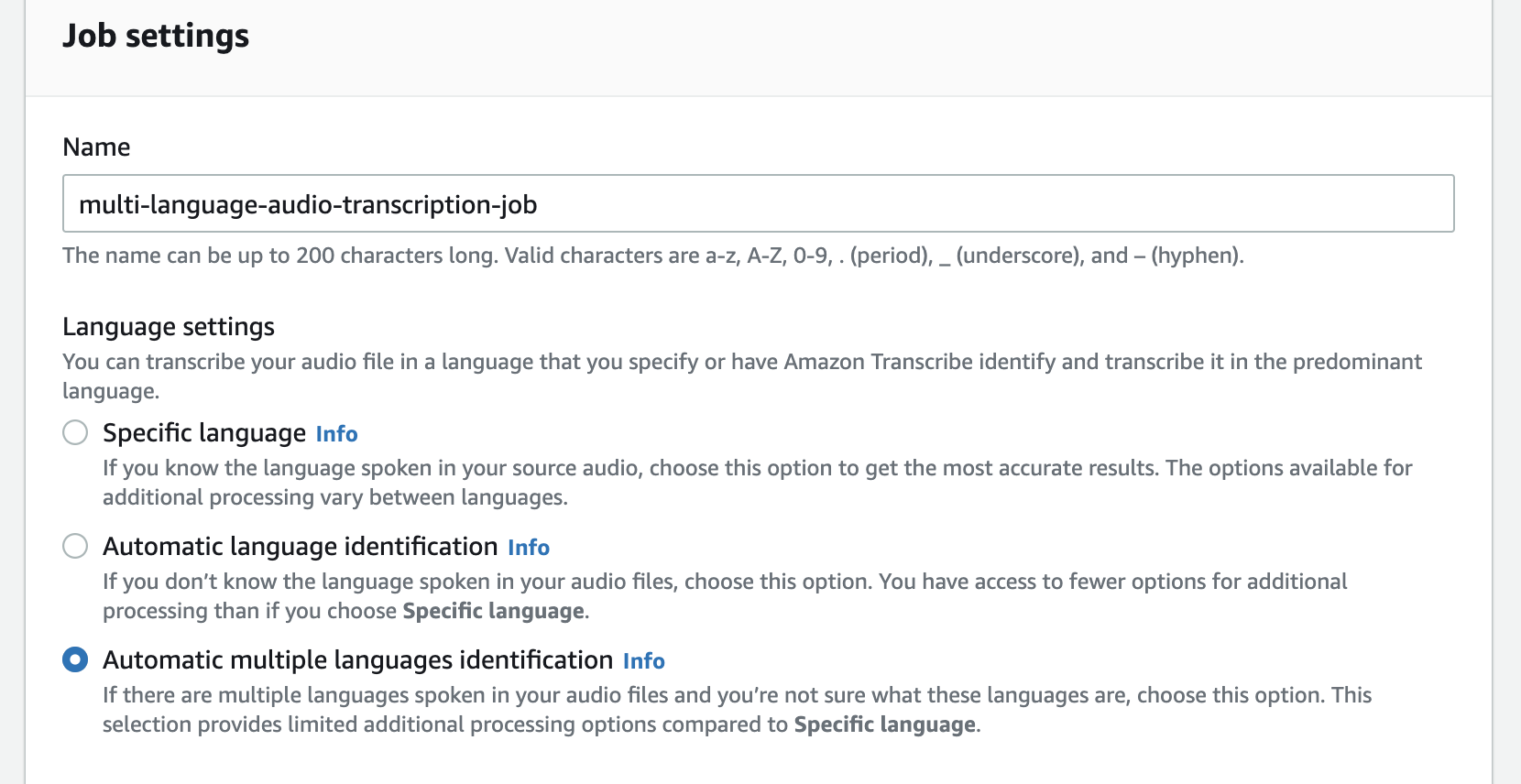
- Pour Options de langue pour l'identification automatique de la langue, laissez-le décoché.
Amazon Transcribe identifie et transcrit automatiquement toutes les langues parlées dans l'audio. Pour améliorer la précision de la transcription, vous pouvez éventuellement sélectionner deux langues ou plus dont vous savez qu'elles ont été parlées dans l'audio.
- Pour Type de modèle, seulement le Modèle général option est disponible au moment de la rédaction de cet article.
- Pour Des données d'entrée, choisissez Parcourir S3.
- Choisissez le fichier source audio que nous avons téléchargé précédemment.
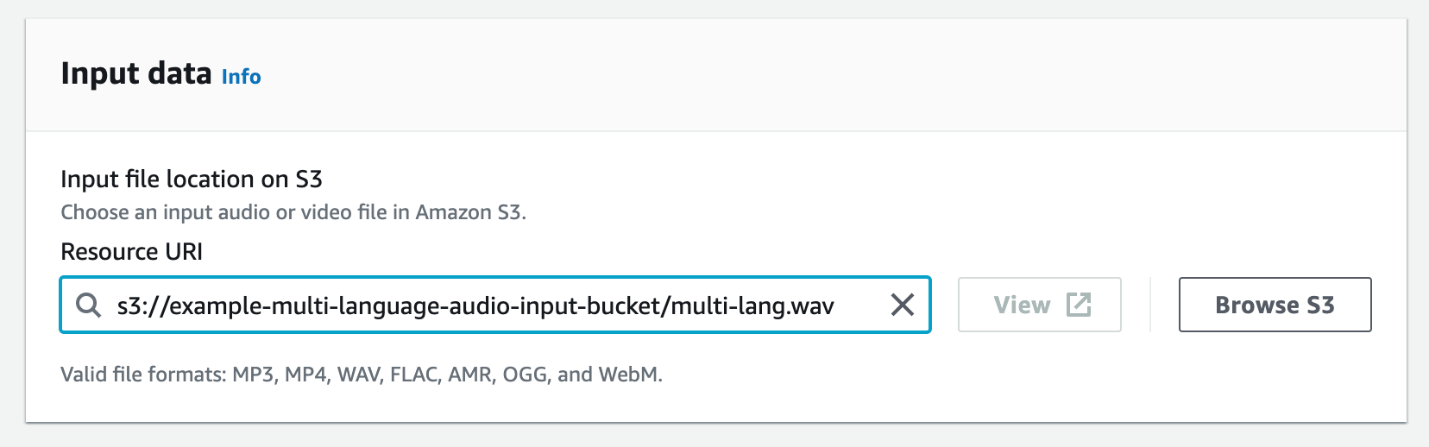
- Pour Des données de sortie, vous pouvez sélectionner soit Compartiment S3 géré par le service or Compartiment S3 spécifié par le client. Pour ce poste, sélectionnez Compartiment S3 géré par le service.
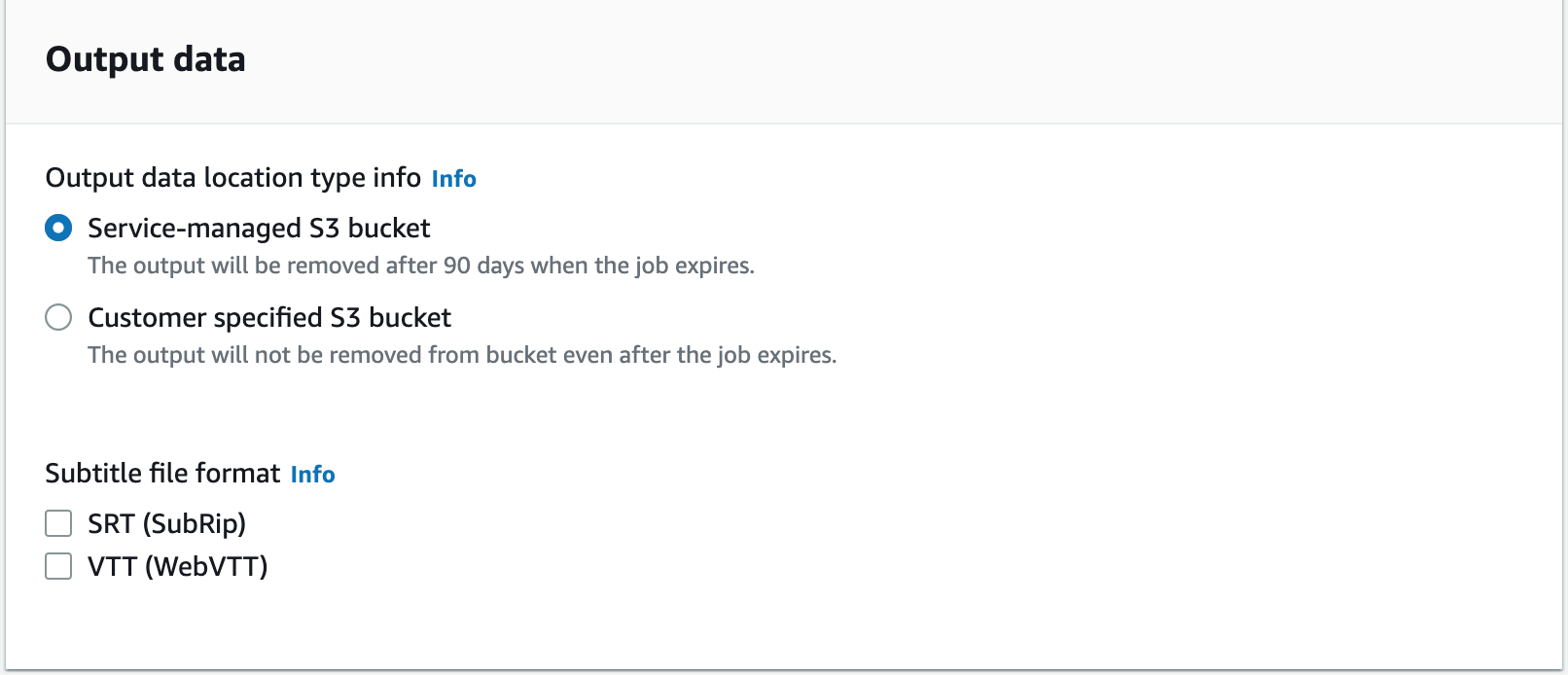
- Selectionnez Suivant.
- Selectionnez Créer un emploi.
Examiner la sortie du travail
Une fois la tâche de transcription terminée, ouvrez la tâche de transcription.![]()
Faites défiler jusqu'à la Aperçu de la transcription section. La transcription audio s'affiche sur le Texte languette. La transcription comprend les parties anglaise et espagnole de la conversation.![]()
Vous pouvez éventuellement télécharger une copie de la transcription sous forme de fichier JSON, que vous pourrez utiliser pour plus de détails. analyse post-appel.
Nettoyer
Pour éviter des frais futurs, videz et supprimez le compartiment S3 que vous avez créé pour stocker le fichier source audio d'entrée. Assurez-vous que les fichiers sont stockés ailleurs, car cela supprimera définitivement tous les objets contenus dans le compartiment. Sur la console Amazon Transcribe, sélectionnez et supprimez la tâche précédemment créée pour la transcription.
Conclusion
Dans cet article, nous avons créé un flux de travail de bout en bout pour automatiser l'identification et la transcription de fichiers audio multilingues, sans écrire de code. Nous avons utilisé la nouvelle fonctionnalité d'Amazon Transcribe pour identifier automatiquement différentes langues dans un fichier audio et transcrire correctement chaque langue.
Pour plus d'informations, reportez-vous à Identification de la langue avec des travaux de transcription par lots.
À propos des auteurs
![]() Murtuza Bootwala est architecte de solutions senior chez AWS avec un intérêt pour les technologies AI/ML. Il aime travailler avec les clients pour les aider à atteindre leurs résultats commerciaux. En dehors du travail, il aime les activités de plein air et passer du temps avec sa famille.
Murtuza Bootwala est architecte de solutions senior chez AWS avec un intérêt pour les technologies AI/ML. Il aime travailler avec les clients pour les aider à atteindre leurs résultats commerciaux. En dehors du travail, il aime les activités de plein air et passer du temps avec sa famille.
![]() Victor Rouge est passionné par l'IA/ML et le développement de logiciels. Il a aidé à faire fonctionner Amazon Alexa aux États-Unis et au Mexique. Il a également apporté Amazon Textract aux partenaires AWS et a lancé AWS Contact Center Intelligence (CCI). Il est actuellement le Global Tech Leader pour Conversational AI Partners.
Victor Rouge est passionné par l'IA/ML et le développement de logiciels. Il a aidé à faire fonctionner Amazon Alexa aux États-Unis et au Mexique. Il a également apporté Amazon Textract aux partenaires AWS et a lancé AWS Contact Center Intelligence (CCI). Il est actuellement le Global Tech Leader pour Conversational AI Partners.
![]() Babu Srinivasan est un AWS Sr. Specialist SA (Language AI Services) basé à Chicago. Il se concentre sur Amazon Transcribe (discours en texte), aidant nos clients à utiliser les services d'intelligence artificielle pour résoudre les problèmes commerciaux. En dehors du travail, il aime travailler le bois et faire des spectacles de magie.
Babu Srinivasan est un AWS Sr. Specialist SA (Language AI Services) basé à Chicago. Il se concentre sur Amazon Transcribe (discours en texte), aidant nos clients à utiliser les services d'intelligence artificielle pour résoudre les problèmes commerciaux. En dehors du travail, il aime travailler le bois et faire des spectacles de magie.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/automatically-identify-languages-in-multi-lingual-audio-using-amazon-transcribe/
- 100
- a
- Description
- Compte
- précision
- atteindre
- à travers
- activités
- AI
- Services d'IA
- AI / ML
- Alexa
- Tous
- Bien que
- Amazon
- Extrait d'Amazon
- Amazon Transcribe
- montant
- ainsi que
- Une autre
- de n'importe où
- api
- Apis
- Candidature
- Réservé
- acoustique
- automatiser
- Automatisation
- Automatique
- automatiquement
- disponibilité
- disponibles
- AWS
- basé
- car
- va
- jusqu'à XNUMX fois
- Apporté
- construit
- la performance des entreprises
- Appelez-nous
- appelé
- appel
- Appels
- captures
- Capturer
- les soins
- cas
- Canaux centraux
- Change
- des charges
- Chicago
- Selectionnez
- clair
- client
- code
- confort
- Les communications
- complet
- ordinateur
- Considérer
- Console
- contact
- centre de contact
- Contenant
- contenu
- Conversation
- de la conversation
- IA conversationnel
- convertir
- Prix
- pourriez
- Pays
- engendrent
- créée
- Lecture
- des clients
- Service à la clientèle
- Support à la clientèle
- Clients
- personnalisation
- données
- par défaut
- Selon
- décrire
- Développement
- différent
- discuter
- down
- download
- durabilité
- chacun
- efficacement
- non plus
- ailleurs
- permettre
- permet
- end-to-end
- Anglais
- Entrer
- entièrement
- Ether (ETH)
- Exercises
- famille
- réalisable
- Fonctionnalité
- Déposez votre dernière attestation
- Fichiers
- une fonction filtre
- se concentre
- Abonnement
- Forum
- de
- plus
- avenir
- générer
- obtenez
- Global
- À l'échelle mondiale
- Sol
- aider
- a aidé
- aider
- Comment
- How To
- HTML
- HTTPS
- Les êtres humains
- Identification
- identifie
- identifier
- Mettre en oeuvre
- améliorer
- in
- inclut
- Améliore
- leader de l'industrie
- d'information
- contribution
- Des instructions
- Intelligence
- interactions
- intérêt
- IT
- Emploi
- json
- Savoir
- connu
- langue
- Langues
- leader
- Laisser
- Niveau
- locales
- Localisation
- Faible
- la magie
- faire
- FAIT DU
- gérés
- Médias
- réunion
- Métadonnées
- Mexique
- pourrait
- minimum
- Stack monitoring
- PLUS
- plusieurs
- prénom
- Navigation
- Besoin
- besoin
- Nouveauté
- objet
- objets
- Offres Speciales
- officiel
- ONE
- ouvert
- fonctionner
- d'exploitation
- Option
- Options
- Autre
- au contrôle
- pain
- participants
- partenaires,
- passionné
- performant
- effectuer
- définitivement
- Platon
- Intelligence des données Platon
- PlatonDonnées
- population
- Post
- préférences
- conditions préalables
- précédemment
- la confidentialité
- Problème
- d'ouvrabilité
- Vidéo
- protéger
- fournir
- but
- Lire
- reconnaissance
- région
- régional
- régions
- supprimez
- rapport
- représentant
- Ressources
- Résultats
- Avis
- pour le running
- SA
- même
- Évolutivité
- secondes
- Section
- sécurité
- service
- Services
- Peu de temps
- devrait
- Spectacles
- similaires
- étapes
- Logiciels
- développement de logiciels
- sur mesure
- Solutions
- RÉSOUDRE
- Identifier
- Espagnol
- parlant
- spécialiste
- spécifié
- discours
- Reconnaissance vocale
- Dépenses
- Étapes
- storage
- Boutique
- stockée
- Ces
- tel
- Support
- Interrupteur
- technologie
- Les technologies
- La
- leur
- Avec
- fiable
- à
- Tracking
- Transcription
- transition
- unique
- illimité
- téléchargé
- us
- Utilisation
- utilisé
- Utilisateur
- divers
- pratiquement
- walkthrough
- qui
- tout en
- sera
- dans les
- sans
- Activités:
- workflows
- de travail
- écrire
- écriture
- Votre
- zéphyrnet