Ce billet a été coécrit avec Babu Srinivasan et Robert Walters de MongoDB.
Amazon Managed Streaming pour Apache Kafka (Amazon MSK) est un service Apache Kafka entièrement géré et hautement disponible. Amazon MSK facilite l'ingestion et le traitement des données de streaming en temps réel et l'utilisation aisée de ces données au sein de l'écosystème AWS. Avec Amazon MSK sans serveur, vous pouvez provisionner et gérer automatiquement les ressources requises pour fournir une capacité de streaming et de stockage à la demande pour vos applications.
Amazon MSK prend également en charge l'intégration de sources de données telles que MongoDB Atlas via Connexion Amazon MSK. MSK Connect permet l'intégration sans serveur des données MongoDB avec Amazon MSK à l'aide du Connecteur MongoDB pour Apache Kafka.
MongoDB Atlas sans serveur fournit des services de base de données qui augmentent et diminuent dynamiquement avec la taille et le débit des données, et les coûts évoluent en conséquence. Il convient mieux aux applications avec des demandes variables à gérer avec une configuration minimale. Il offre des performances et une fiabilité élevées avec des fonctionnalités de mise à niveau, de chiffrement, de sécurité, de métriques et de sauvegarde automatisées intégrées à l'infrastructure MongoDB Atlas.
MSK Serverless est un type de cluster pour Amazon MSK. Tout comme MongoDB Atlas Serverless, MSK Serverless provisionne et dimensionne automatiquement les ressources de calcul et de stockage. Vous pouvez désormais créer des workflows sans serveur de bout en bout. Vous pouvez créer un pipeline de streaming sans serveur avec une ingestion sans serveur à l'aide de MSK Serverless et du stockage sans serveur à l'aide de MongoDB Atlas. De plus, MSK Connect prend désormais en charge noms d'hôtes DNS privés. Cela permet aux instances MSK sans serveur de se connecter aux clusters MongoDB sans serveur via Lien privé AWS, vous offrant une connectivité sécurisée entre les plates-formes.
Si vous souhaitez utiliser un cluster non sans serveur, reportez-vous à Intégration de MongoDB avec Amazon Managed Streaming pour Apache Kafka (MSK).
Cet article montre comment implémenter un pipeline de streaming sans serveur avec MSK Serverless, MSK Connect et MongoDB Atlas.
Vue d'ensemble de la solution
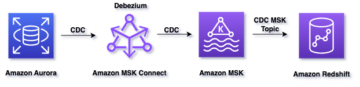
Le diagramme suivant illustre notre architecture de solution.
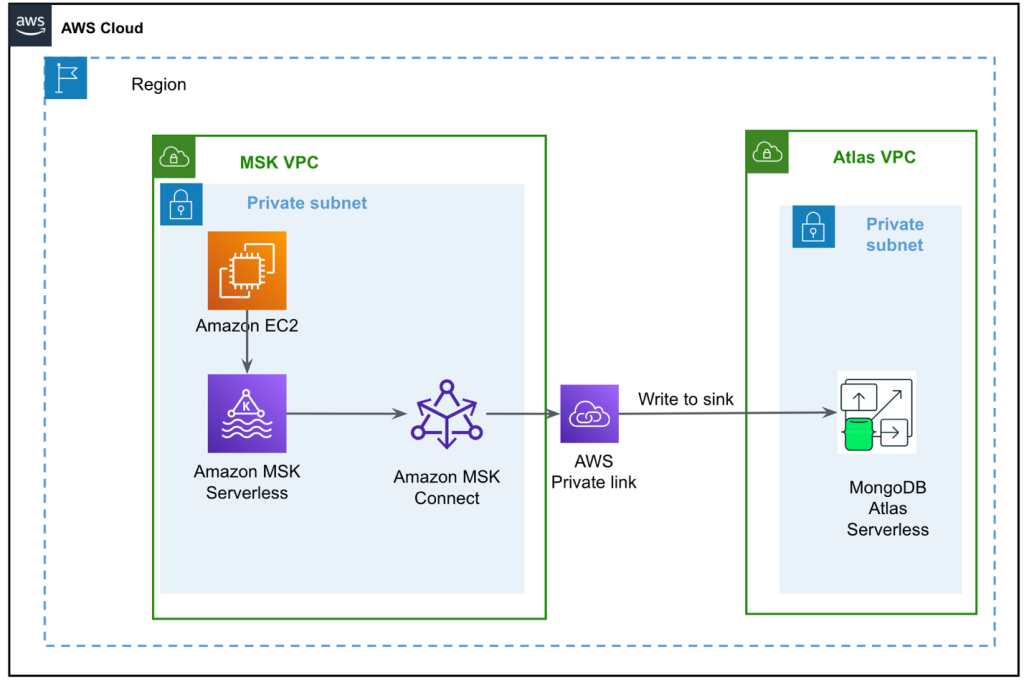
Le flux de données commence par un Cloud de calcul élastique Amazon (Amazon EC2) instance client qui écrit des enregistrements dans une rubrique MSK. Au fur et à mesure que les données arrivent, une instance du connecteur MongoDB pour Apache Kafka écrit les données dans une collection du cluster MongoDB Atlas Serverless. Pour une connectivité sécurisée entre les deux plates-formes, une connexion AWS PrivateLink est créée entre le cluster MongoDB Atlas et le VPC contenant l'instance MSK.
Cet article vous guide à travers les étapes suivantes:
- Créez le cluster MSK sans serveur.
- Créez le cluster MongoDB Atlas Serverless.
- Configurez le plug-in MSK.
- Créez le client EC2.
- Configurez une rubrique MSK.
- Configurez le connecteur MongoDB pour Apache Kafka en tant que récepteur.
Configurer le cluster MSK sans serveur
Pour créer un cluster MSK sans serveur, procédez comme suit :
- Sur la console Amazon MSK, choisissez Clusters dans le volet de navigation.
- Selectionnez Créer un cluster.
- Pour Méthode de création, sélectionnez Création personnalisée.
- Pour Nom du cluster, Entrer
MongoDBMSKCluster. - Pour Type de grappesélectionner Sans serveur.
- Selectionnez Suivant.
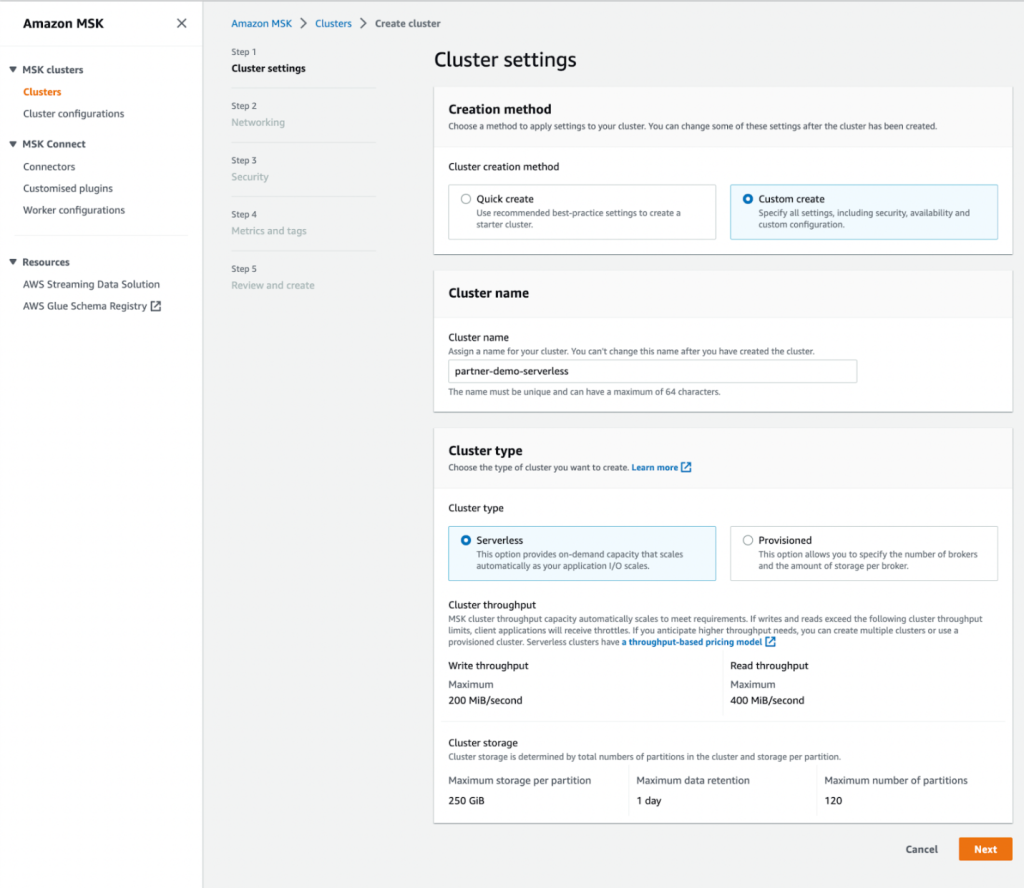
- Sur le Réseautage , spécifiez votre VPC, les zones de disponibilité et les sous-réseaux correspondants.
- Notez les zones de disponibilité et les sous-réseaux à utiliser ultérieurement.
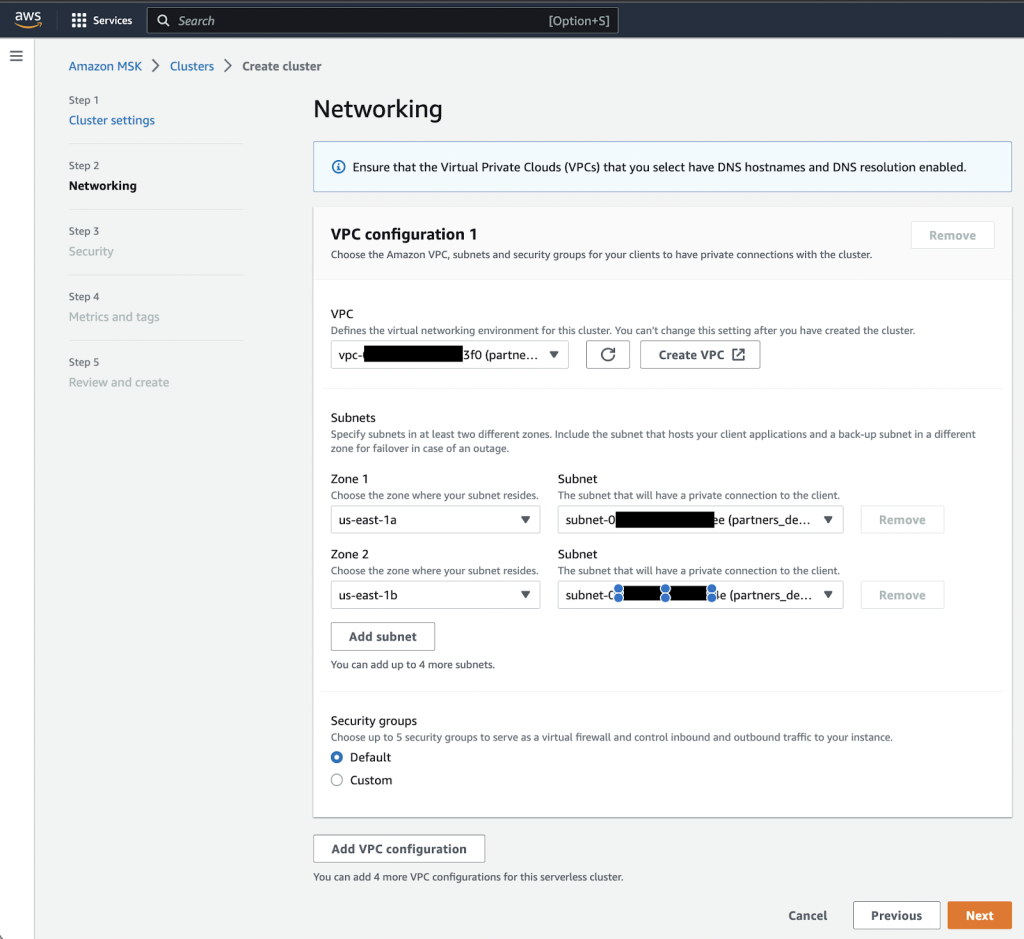
- Selectionnez Suivant.
- Selectionnez Créer un cluster.
Lorsque le cluster est disponible, son statut devient Active.

Créer le cluster MongoDB Atlas Serverless
Pour créer un cluster MongoDB Atlas, suivez les Premiers pas avec Atlas Didacticiel. Notez que pour les besoins de cet article, vous devez créer une instance sans serveur.
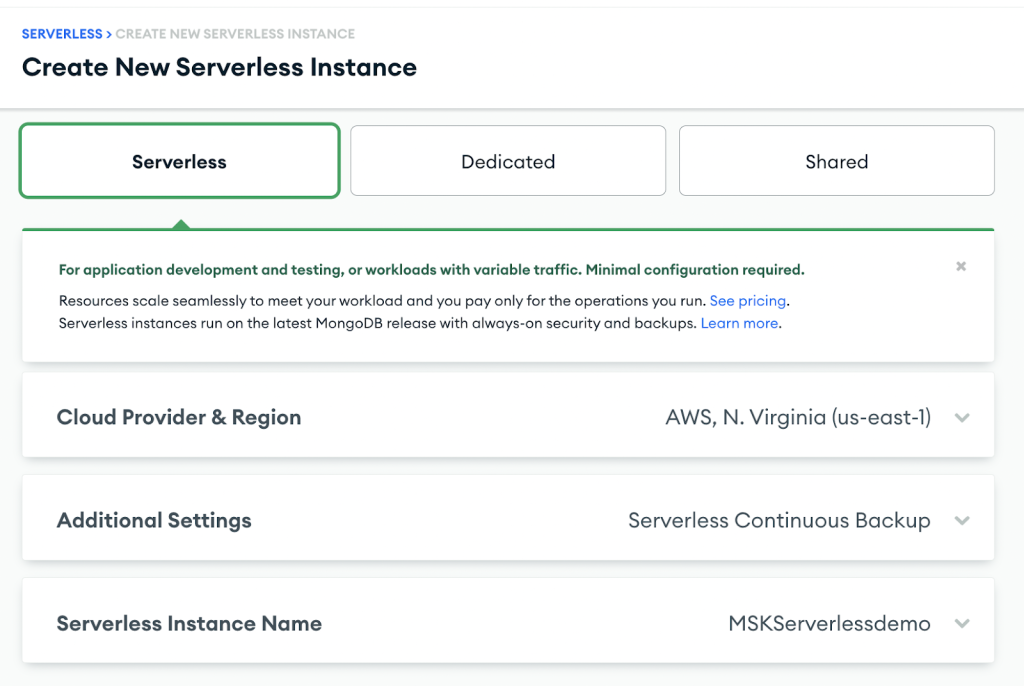
Une fois le cluster créé, configurez un point de terminaison privé AWS en procédant comme suit :
- Sur le Sécurité menu, choisissez L'accès au réseau.

- Sur le Point de terminaison privé onglet, choisissez Instance sans serveur.

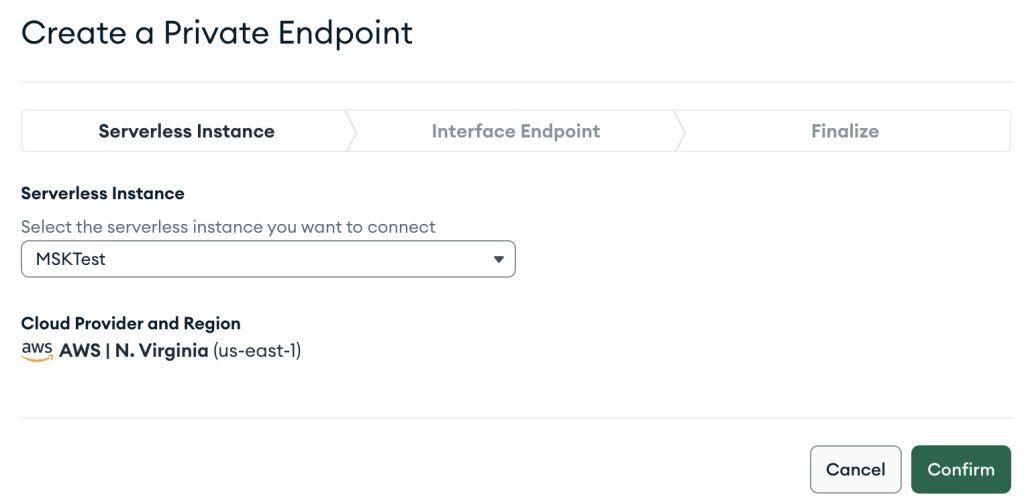
- Selectionnez Créer un nouveau point de terminaison.
- Pour Instance sans serveur, choisissez l'instance que vous venez de créer.
- Selectionnez Confirmer.
- Fournissez la configuration de votre point de terminaison VPC et choisissez Suivant.
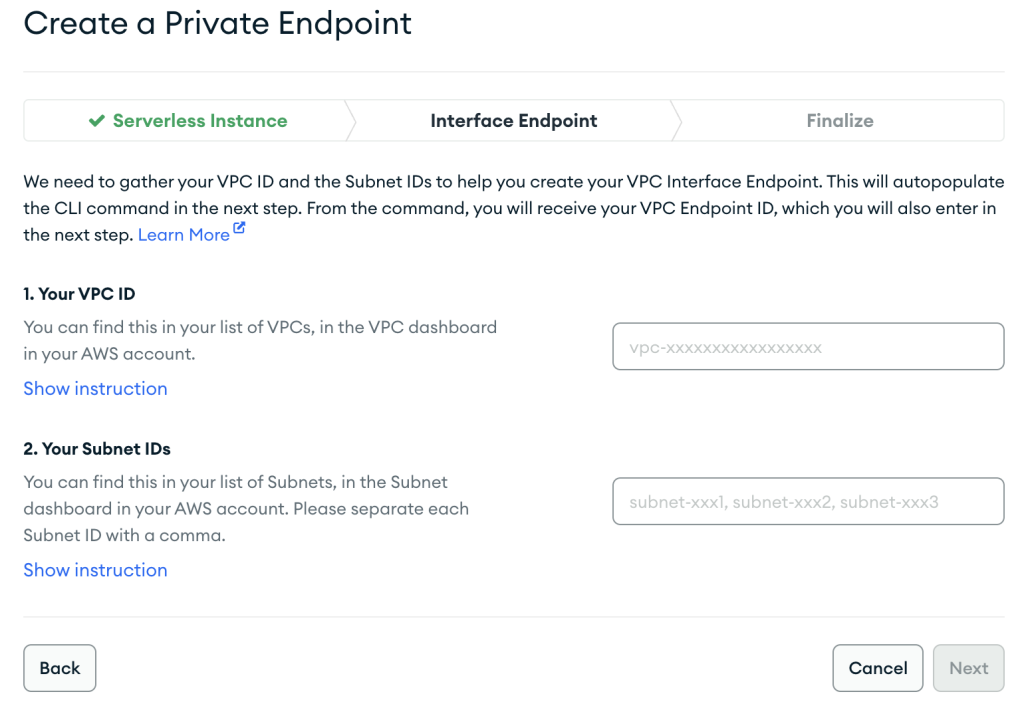
- Lors de la création de la ressource AWS PrivateLink, assurez-vous de spécifier exactement le même VPC et les mêmes sous-réseaux que vous avez utilisés précédemment lors de la création de la configuration de mise en réseau pour l'instance MSK sans serveur.
- Selectionnez Suivant.
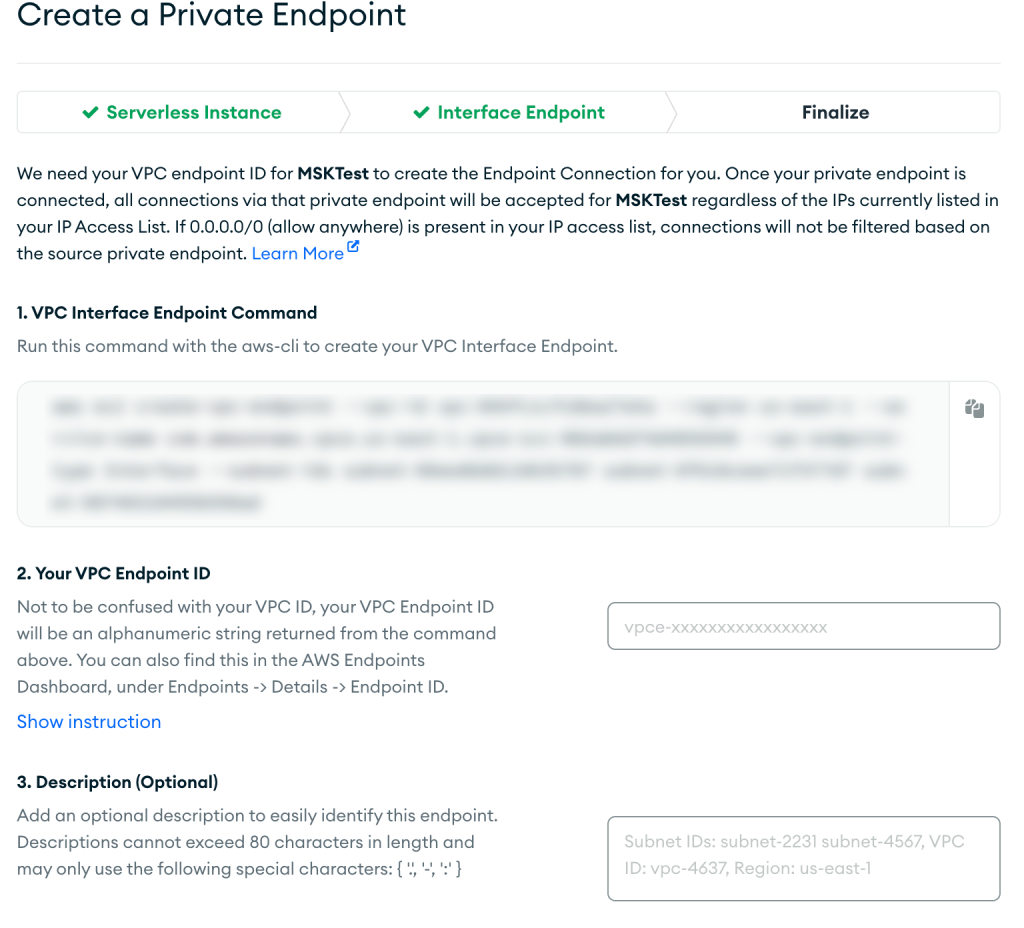
- Suivez les instructions sur le Finaliser page, puis choisissez Confirmer après la création de votre point de terminaison VPC.
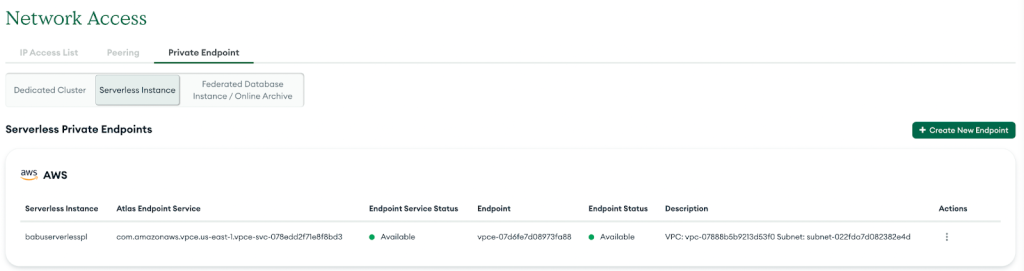
En cas de succès, le nouveau point de terminaison privé apparaîtra dans la liste, comme illustré dans la capture d'écran suivante.
Configurer le plugin MSK
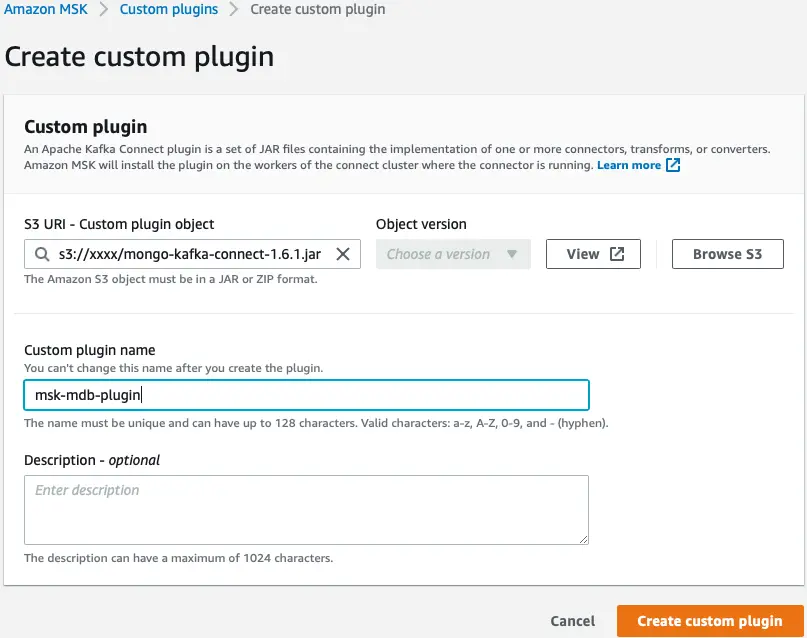
Ensuite, nous créons un plug-in personnalisé dans Amazon MSK à l'aide du connecteur MongoDB pour Apache Kafka. Le connecteur doit être téléchargé sur un Service de stockage simple Amazon (Amazon S3) avant de pouvoir créer le plug-in. Pour télécharger le connecteur MongoDB pour Apache Kafka, reportez-vous à Télécharger un fichier JAR de connecteur.
- Sur la console Amazon MSK, choisissez Plugins personnalisés dans le volet de navigation.
- Selectionnez Créer un plug-in personnalisé.
- Pour URI S3, entrez l'emplacement S3 du connecteur téléchargé.
- Selectionnez Créer un plug-in personnalisé.
Configurer un client EC2
Ensuite, configurons une instance EC2. Nous utilisons cette instance pour créer le sujet et insérer des données dans le sujet. Pour les instructions, reportez-vous à la section Configurer un client EC2 dans la poste Intégration de MongoDB avec Amazon Managed Streaming pour Apache Kafka (MSK).
Créer un sujet sur le cluster MSK
Pour créer un sujet Kafka, nous devons d'abord installer la CLI Kafka.
- Sur l'instance EC2 cliente, installez d'abord Java :
sudo yum install java-1.8.0
- Ensuite, exécutez la commande suivante pour télécharger Apache Kafka :
wget https://archive.apache.org/dist/kafka/2.6.2/kafka_2.12-2.6.2.tgz
- Décompressez le fichier tar à l'aide de la commande suivante :
tar -xzf kafka_2.12-2.6.2.tgz
La distribution de Kafka inclut un dossier bin avec des outils qui peuvent être utilisés pour gérer les sujets.
- Allez à
kafka_2.12-2.6.2répertoire et émettez la commande suivante pour créer une rubrique Kafka sur le cluster MSK sans serveur :
bin/kafka-topics.sh --create --topic sandbox_sync2 --bootstrap-server <BOOTSTRAP SERVER> --command-config=bin/client.properties --partitions 2
Vous pouvez copier le point de terminaison du serveur d'amorçage sur le Afficher les informations sur les clients page de votre cluster MSK sans serveur.
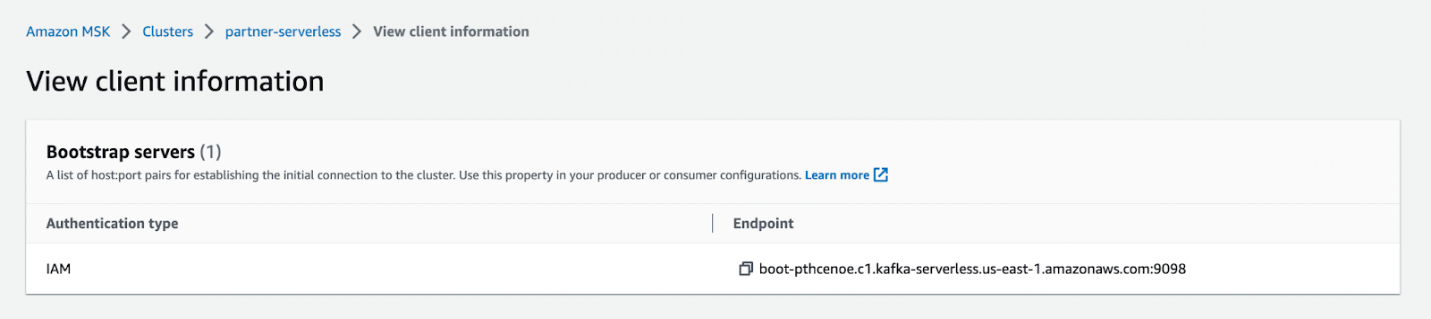
Vous pouvez configurer l'authentification IAM en suivant ces Des instructions.
Configurer le connecteur du récepteur
Maintenant, configurons un connecteur de récepteur pour envoyer les données à l'instance MongoDB Atlas Serverless.
- Sur la console Amazon MSK, choisissez Connecteurs RF dans le volet de navigation.
- Selectionnez Créer un connecteur.
- Sélectionnez le plugin que vous avez créé précédemment.
- Selectionnez Suivant.
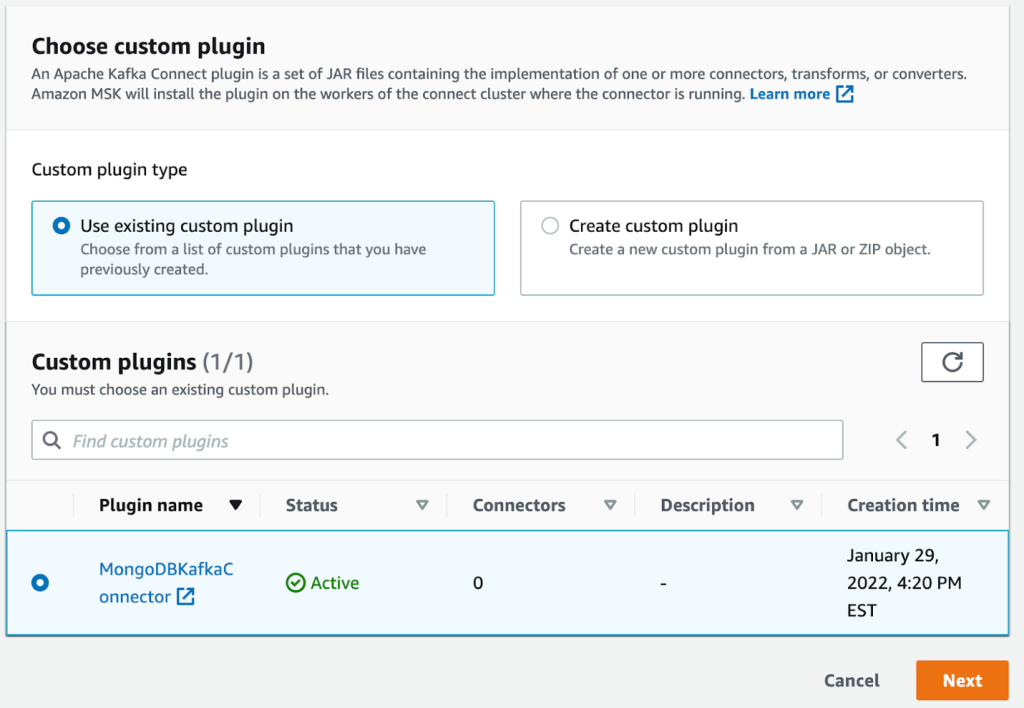
- Sélectionnez l'instance MSK sans serveur que vous avez créée précédemment.
- Saisissez votre configuration de connexion sous la forme du code suivant :
Assurez-vous que la connexion à l'instance MongoDB Atlas Serverless se fait via AWS PrivateLink. Pour plus d'informations, reportez-vous à Connexion sécurisée des applications à un plan de données MongoDB Atlas avec AWS PrivateLink.
- Dans le Autorisations d'accès section, créez une Gestion des identités et des accès AWS (IAM) rôle avec le stratégie de confiance requise.
- Selectionnez Suivant.
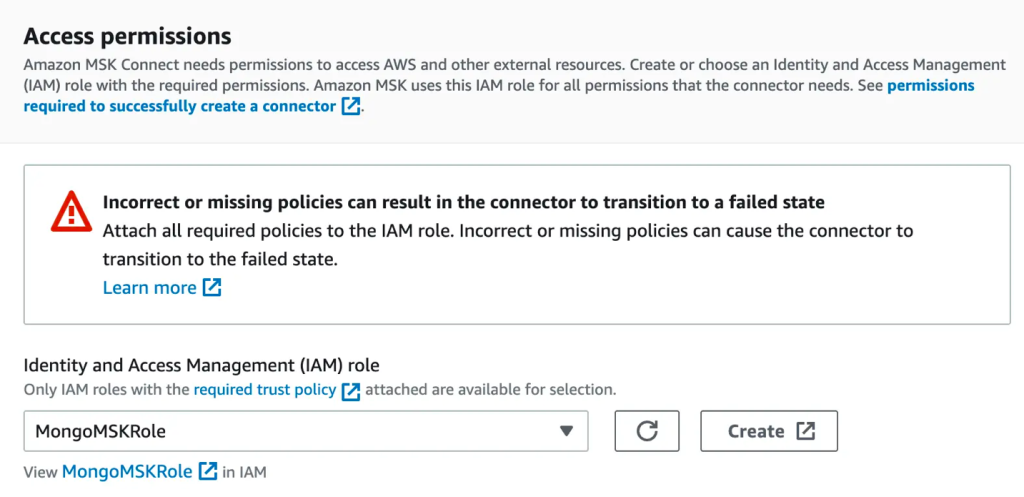
- Spécifier Journaux Amazon CloudWatch comme option de livraison de journaux.
- Complétez votre connecteur.
Lorsque l'état du connecteur passe à Actif, le pipeline est prêt.

Insérer des données dans le sujet MSK
Sur votre client EC2, insérez des données dans la rubrique MSK à l'aide de la kafka-console-producer comme suit:
Pour vérifier que les données circulent correctement du sujet Kafka vers le cluster MongoDB sans serveur, nous utilisons l'interface utilisateur MongoDB Atlas.

Si vous rencontrez des problèmes, assurez-vous de vérifier les fichiers journaux. Dans cet exemple, nous avons utilisé CloudWatch pour lire les événements générés à partir d'Amazon MSK et du connecteur MongoDB pour Apache Kafka.

Nettoyer
Pour éviter des frais futurs, nettoyez les ressources que vous avez créées. Commencez par supprimer le cluster MSK, le connecteur et l'instance EC2 :
- Sur la console Amazon MSK, choisissez Clusters dans le volet de navigation.
- Sélectionnez votre cluster et sur le Actions menu, choisissez Supprimer.
- Selectionnez Connecteurs RF dans le volet de navigation.
- Sélectionnez votre connecteur et choisissez Supprimer.
- Selectionnez Plugins personnalisés dans le volet de navigation.
- Sélectionnez votre plugin et choisissez Supprimer.
- Sur la console Amazon EC2, choisissez Cas dans le volet de navigation.
- Choisissez l'instance que vous avez créée.
- Selectionnez État de l'instance, Puis choisissez Mettre fin à l'instance.
- Sur le VPC Amazon console, choisissez Endpoints dans le volet de navigation.
- Sélectionnez le point de terminaison que vous avez créé et sur le Actions menu, choisissez Supprimer les points de terminaison d'un VPC.
Vous pouvez maintenant supprimer le cluster Atlas et AWS PrivateLink :
- Connectez-vous à la console du cluster Atlas.
- Accédez au cluster sans serveur à supprimer.
- Dans le menu déroulant des options, choisissez Mettre fin.
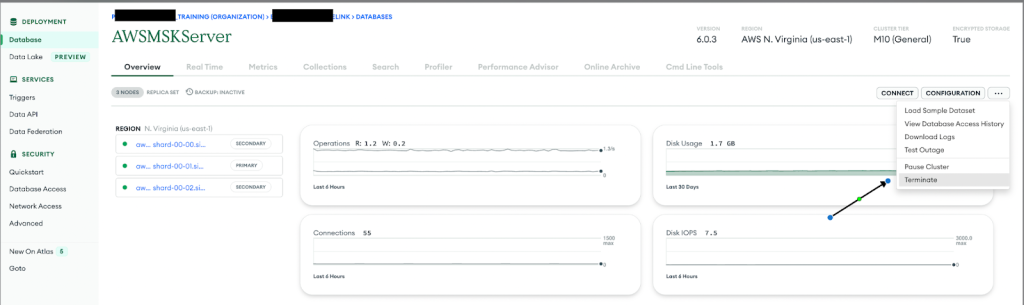
- Accédez à la L'accès au réseau .
- Choisissez le point de terminaison privé.
- Sélectionnez l'instance sans serveur.
- Dans le menu déroulant des options, choisissez Mettre fin.

Résumé
Dans cet article, nous vous avons montré comment créer un pipeline d'ingestion de streaming sans serveur à l'aide de MSK Serverless et de MongoDB Atlas Serverless. Avec MSK Serverless, vous pouvez provisionner et gérer automatiquement les ressources requises en fonction des besoins. Nous avons utilisé un connecteur MongoDB déployé sur MSK Connect pour intégrer de manière transparente les deux services, et utilisé un client EC2 pour envoyer des exemples de données au sujet MSK. MSK Connect prend désormais en charge Noms d'hôte DNS privés, vous permettant d'utiliser des noms de domaine privés entre les services. Dans cet article, le connecteur a utilisé les serveurs DNS par défaut du VPC pour résoudre le nom DNS privé spécifique à la zone de disponibilité. Cette configuration AWS PrivateLink a permis une connectivité sécurisée et privée entre l'instance MSK Serverless et l'instance MongoDB Atlas Serverless.
Pour continuer votre apprentissage, consultez les ressources suivantes :
À propos des auteurs

Igor Alekseev est Senior Partner Solution Architect chez AWS dans le domaine Data and Analytics. Dans son rôle, Igor travaille avec des partenaires stratégiques pour les aider à créer des architectures complexes optimisées pour AWS. Avant de rejoindre AWS, en tant qu'architecte de données/solutions, il a mis en œuvre de nombreux projets dans le domaine du Big Data, y compris plusieurs lacs de données dans l'écosystème Hadoop. En tant qu'ingénieur de données, il a été impliqué dans l'application de l'IA/ML à la détection des fraudes et à la bureautique.
 Kiran Matty est chef de produit principal chez Amazon Web Services (AWS) et travaille avec l'équipe Amazon Managed Streaming for Apache Kafka (Amazon MSK) basée à Palo Alto, en Californie. Il est passionné par la création de services de streaming et d'analyse performants qui aident les entreprises à réaliser leurs cas d'utilisation critiques.
Kiran Matty est chef de produit principal chez Amazon Web Services (AWS) et travaille avec l'équipe Amazon Managed Streaming for Apache Kafka (Amazon MSK) basée à Palo Alto, en Californie. Il est passionné par la création de services de streaming et d'analyse performants qui aident les entreprises à réaliser leurs cas d'utilisation critiques.
 Babu Srinivasan est un architecte de solutions partenaire principal chez MongoDB. Dans son rôle actuel, il travaille avec AWS pour construire les intégrations techniques et les architectures de référence pour les solutions AWS et MongoDB. Il a plus de deux décennies d'expérience dans les technologies de bases de données et de cloud. Il est passionné par la fourniture de solutions techniques aux clients travaillant avec plusieurs intégrateurs de systèmes mondiaux (GSI) dans plusieurs zones géographiques.
Babu Srinivasan est un architecte de solutions partenaire principal chez MongoDB. Dans son rôle actuel, il travaille avec AWS pour construire les intégrations techniques et les architectures de référence pour les solutions AWS et MongoDB. Il a plus de deux décennies d'expérience dans les technologies de bases de données et de cloud. Il est passionné par la fourniture de solutions techniques aux clients travaillant avec plusieurs intégrateurs de systèmes mondiaux (GSI) dans plusieurs zones géographiques.
 Robert Walters est actuellement chef de produit senior chez MongoDB. Avant MongoDB, Rob a passé 17 ans chez Microsoft à occuper divers postes, notamment la gestion de programme au sein de l'équipe SQL Server, le conseil et l'avant-vente technique. Rob est co-auteur de trois brevets pour des technologies utilisées dans SQL Server et a été l'auteur principal de plusieurs livres techniques sur SQL Server. Rob est actuellement un blogueur actif sur les blogs MongoDB.
Robert Walters est actuellement chef de produit senior chez MongoDB. Avant MongoDB, Rob a passé 17 ans chez Microsoft à occuper divers postes, notamment la gestion de programme au sein de l'équipe SQL Server, le conseil et l'avant-vente technique. Rob est co-auteur de trois brevets pour des technologies utilisées dans SQL Server et a été l'auteur principal de plusieurs livres techniques sur SQL Server. Rob est actuellement un blogueur actif sur les blogs MongoDB.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/build-a-serverless-streaming-pipeline-with-amazon-msk-serverless-amazon-msk-connect-and-mongodb-atlas/
- 10
- 100
- 7
- a
- Qui sommes-nous
- accès
- en conséquence
- à travers
- infection
- ajout
- Après
- AI / ML
- permet
- Amazon
- Amazon EC2
- Amazon Web Services
- Amazon Web Services (AWS)
- Analytique
- analytique
- ainsi que
- Apache
- Apache Kafka
- applications
- Application
- architecture
- Arrive
- atlas
- Authentification
- auteur
- Automatisation
- automatiquement
- Automation
- disponibilité
- disponibles
- AWS
- sauvegarde
- basé
- base
- devient
- before
- LES MEILLEURS
- jusqu'à XNUMX fois
- Big
- Big Data
- blogue
- Livres
- Bootstrap
- construire
- Développement
- construit
- Californie
- Compétences
- cas
- Modifications
- des charges
- vérifier
- Selectionnez
- client
- le cloud
- Grappe
- code
- collection
- collections
- complet
- complexe
- calcul
- configuration
- NOUS CONTACTER
- connexion
- Connectivité
- Console
- consulting
- continuer
- Correspondant
- Prix
- engendrent
- créée
- La création
- création
- critique
- Courant
- Lecture
- Customiser
- Clients
- données
- ingénieur de données
- Base de données
- décennies
- Réglage par défaut
- page de livraison.
- demandes
- déployé
- détails
- Détection
- dialogue
- distribution
- dns
- domaine
- NOMS DE DOMAINE
- down
- download
- Plus tôt
- même
- risque numérique
- permettant
- chiffrement
- end-to-end
- Endpoint
- ingénieur
- Entrer
- entreprises
- Ether (ETH)
- événements
- exemple
- Découvrez
- Fonctionnalités:
- Déposez votre dernière attestation
- Fichiers
- Prénom
- flux
- Flux
- suivre
- Abonnement
- suit
- fraude
- détection de fraude
- de
- d’étiquettes électroniques entièrement
- avenir
- généré
- géographies
- Global
- Hadoop
- aider
- aider
- ici
- Haute
- très
- Comment
- How To
- HTML
- HTTPS
- IAM
- Active
- Mettre en oeuvre
- mis en œuvre
- in
- inclut
- Y compris
- d'information
- Infrastructure
- installer
- instance
- Des instructions
- intégrer
- l'intégration
- intégrations
- intéressé
- impliqué
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- Java
- joindre
- kafka
- ACTIVITES
- conduire
- apprentissage
- Liste
- emplacement
- faire
- FAIT DU
- gérer
- gérés
- gestion
- manager
- de nombreuses
- Menu
- Métrique
- Microsoft
- minimal
- MongoDB
- PLUS
- plusieurs
- prénom
- noms
- Navigation
- Besoin
- Besoins
- réseau et
- L'accès au réseau
- de mise en réseau
- Nouveauté
- Bureaux
- Option
- Options
- Palo Alto
- pain
- les partenaires
- partenaires,
- passionné
- Brevets
- performant
- pipeline
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- plug-in
- Post
- précédent
- Directeur
- Avant
- Privé
- processus
- Produit
- chef de produit
- Programme
- projets
- propriétés
- fournir
- fournit
- aportando
- disposition
- des fins
- Lire
- solutions
- réal
- en temps réel
- réaliser
- Articles
- fiabilité
- conditions
- ressource
- Ressources
- ROBERT
- Rôle
- rôle
- Courir
- même
- Escaliers intérieurs
- Balance
- de façon transparente
- Section
- sécurisé
- en toute sécurité
- sécurité
- supérieur
- Sans serveur
- service
- Services
- Paramétres
- plusieurs
- montrer
- montré
- étapes
- Taille
- sur mesure
- Solutions
- Identifier
- Sources
- dépensé
- SQL
- j'ai commencé
- départs
- Statut
- Étapes
- storage
- Stratégique
- Partenaires stratégiques
- streaming
- sous-réseau
- sous-réseaux
- succès
- Avec succès
- tel
- Les soutiens
- combustion propre
- tâches
- équipe
- Technique
- Les technologies
- Les
- leur
- trois
- Avec
- fiable
- à
- les outils
- sujet
- Les sujets
- La confiance
- tutoriel
- ui
- améliorer
- téléchargé
- utilisé
- Plus-value
- divers
- vérifier
- via
- web
- services Web
- sera
- dans les
- workflows
- de travail
- vos contrats
- années
- Votre
- zéphyrnet
- zones