Cet article a été publié dans le cadre du Blogathon sur la science des données
Introduction
L'apprentissage en profondeur a beaucoup évolué ces dernières années et nous sommes tous ravis de construire des réseaux d'architecture plus profonds pour gagner en précision pour nos modèles. Ces techniques sont largement utilisées pour les travaux liés à l'image comme la classification, le clustering ou la synthèse. Aller en profondeur peut sembler cool, mais cela n'aidera pas car les réseaux de neurones sont confrontés à un problème appelé dégradation.
La précision est affectée dans une large mesure ici. Cela conduit également à un problème appelé Vanishing gradient descend. Cela ne nous permettra pas de mettre à jour correctement les poids lors de l'étape de rétropropagation. Au cours de l'étape de rétropropagation, nous utilisons la règle de la chaîne, les dérivées de chaque couche au fur et à mesure que nous descendons le réseau sont multipliées.
Si nous utilisons des couches plus profondes et avons des couches cachées comme le sigmoïde, les dérivées sont réduites en dessous de 0.25 dans chaque couche. Ainsi, lorsque de nombreuses dérivées de couches sont multipliées, le gradient diminue de manière exponentielle et nous obtenons une très petite valeur qui est inutile pour le calcul du gradient. Cela a conduit à la création de Resnet par Microsoft Research qui a utilisé des connexions ignorées pour éviter la dégradation. Dans cet article, nous discuterons d'une implémentation d'une architecture ResNet à 34 couches utilisant le framework Pytorch en Python.

Comme discuté ci-dessus, ce diagramme nous montre le problème du gradient de fuite. Les dérivées des fonctions sigmoïdes sont réduites en dessous de 0.25 et cela fait perdre beaucoup d'informations lors de la mise à jour des gradients.
Le problème des réseaux d'avions

Comme le montre la figure, nous voyons les réseaux plans, qui ont des couches plus profondes. Sur la gauche, nous avons l'erreur de train et l'erreur de test sur la droite. Nous penserions que cela pourrait être une cause de surapprentissage, mais ici, le% d'erreur du réseau à 56 couches est bien pire à la fois pour la formation et les données de test, ce qui ne se produit pas lorsque le modèle est en surapprentissage. C'est ce qu'on appelle la dégradation.
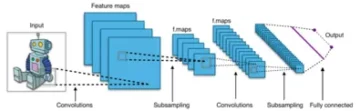
Architecture de Resnet-34

Initialement, nous avons une couche convolutive qui a 64 filtres avec une taille de noyau de 7×7 c'est le première circonvolution, puis suivi d'une couche max-pooling. Nous avons la foulée spécifiée comme 2 dans les deux cas. Ensuite, dans conv2_x nous avons la couche de mise en commun et les couches de convolution suivantes. Ces couches sont normalement regroupées par paires en raison de la manière dont les résidus sont connectés (les flèches montrent qu'elles sautent toutes les deux couches).
Ici, nous avons les 2 couches dont la kernel_size de 3×3, num_filters de 64, et toutes celles-ci sont répétées x3, ce qui correspond aux couches entre la piscine,/2 et le filtre 128, 6 couches au total (une paire fois 3). Ces 2 couches sont kernel_size de 3×3, num_filters est de 128, et celles-ci sont également répétées mais sur cette fois 4. Cela continue jusqu'à avg_pooling et la fonction softmax. Chaque fois que le nombre de filtres double, nous pouvons voir que la première couche spécifie nombre_filtres/2.
Code pour définir Resnet-34 dans Pytorch :
class ResNet34(nn.Module): def __init__(self): super(ResNet34,self).__init__() self.block1 = nn.Sequential( nn.Conv2d(1,64,kernel_size=2,stride=2,padding= 3,bias=False), nn.BatchNorm2d(64), nn.ReLU(True) ) self.block2 = nn.Sequential( nn.MaxPool2d(1,1), ResidualBlock(64,64), ResidualBlock(64,64,2 ,3) ) self.block64,128 = nn.Sequential( ResidualBlock(128,128,2), ResidualBlock(4) ) self.block128,256 = nn.Sequential( ResidualBlock(256,256,2), ResidualBlock(5) ) self.block256,512 = nn. Sequential( ResidualBlock(512,512,2), ResidualBlock(2) ) self.avgpool = nn.AvgPool2d(1) # voyelle_diacritique self.fc512,11 = nn.Linear(2) # grapheme_root self.fc512,168 = nn.Linear(3) # consonant_diacritic self.fc512,7 = nn.Linear(1) def forward(self,x): x = self.block2(x) x = self.block3(x) x = self.block4(x) x = self. block5(x) x = self.block0(x) x = self.avgpool(x) x = x.view(x.size(1),-1) x1 = self.fc2(x) x2 = self.fc3( x) x3 = self.fc1(x) renvoie x2,x3,xXNUMX
Ce code nous donne une implémentation complète d'un module pour Resnet-34. Approfondissons maintenant la compréhension du fonctionnement de chaque ligne. Pour cela raccourcissons l'architecture que nous avons vue plus haut. Reportez-vous aux 34 diagrammes en couches ci-dessous.

Nous pouvons voir que nous devons implémenter n'importe quelle architecture Resnet en 5 blocs. Le premier bloc a 64 filtres avec un pas de 2. suivi d'un pool max avec un pas de 2. L'architecture utilise un remplissage de 3. Puisqu'il existe un risque de décalage de covariable interne, nous devons stabiliser le réseau par une normalisation par lots. Nous utilisons l'activation ReLU à la fin. Le premier bloc est le même pour n'importe quelle architecture et les autres blocs sont modifiés pour différentes couches et sont répétés selon un modèle spécifique. Le 1er bloc peut être implémenté comme :
nn.Conv2d(1,64,kernel_size=2,stride=2,padding=3,bias=False), nn.BatchNorm2d(64), nn.ReLU(True)
À ce stade, nous avons une connexion de saut. C'est l'idée principale des réseaux résiduels. Le diagramme d'architecture que nous avons vu précédemment avait ignoré les connexions avec des flèches en pointillés et sombres. La ligne pointillée est ce qui se passe ici alors que nous entrons dans un canal avec plus de taille que le précédent. Le deuxième bloc a la mise en œuvre d'un pool max initial de 1 * 1 avec une taille de noyau de 3 * 3 et deux blocs résiduels comme indiqué dans le code ci-dessous. Ces deux prennent 64 comme canaux d'entrée et de sortie et sont répétés 3 fois comme indiqué dans l'architecture. Au final, le dernier est connecté au bloc suivant avec une foulée de 2.
nn.MaxPool2d(1,1), ResidualBlock(64,64), ResidualBlock(64,64,2)
Le contenu du dernier bloc s'est répété 3 fois et nous avions indiqué qu'avec la flèche noire dans le schéma d'architecture et la taille des canaux d'entrée et de sortie reste la même. Le '/2' affiché dans le schéma d'architecture nous renseigne sur la foulée utilisée.
Le troisième bloc prend une taille de noyau de 3 * 3 avec un canal d'entrée provenant du dernier bloc de 64 et donnant un canal de sortie de 128. Ensuite, nous prenons le même 128 comme canal d'entrée et 128 comme canal de sortie. Nous répétons cela 4 fois comme indiqué dans le schéma d'architecture précédent.
ResidualBlock(64,128), ResidualBlock(128,128,2)
De la même manière, nous construisons nos 4ème et 5ème blocs qui ont 256 et 512 comme tailles de noyau.
ResidualBlock(128,256), ResidualBlock(256,256,2)
ResidualBlock(256,512), ResidualBlock(512,512,2)
Les fonctions linéaires aident à relier cela enfin à la mission finale qui peut inclure des étapes telles que la classification des ensembles de données cifar 10, etc. et l'idée est d'aplatir les couches et de donner une valeur probabiliste pour trouver le max. Et la fonction forward que nous avons définie pour connecter chacun des blocs. Pour l'implémentation complète de python, y compris la formation, vous pouvez vous référer à ceci site de NDN Collective. Nous pouvons également utiliser la technique d'apprentissage par transfert de Pytorch et pour ce code, vous pouvez vous référer à ce GitHub repo.
Conclusion:
Référence:
- https://www.kaggle.com/khoongweihao/resnet-34-pytorch-starter-kit
- https://datascience.stackexchange.com/questions/33022/how-to-interpert-resnet50-layer-types
À propos de moi: Je suis un étudiant chercheur intéressé par le domaine de l'apprentissage en profondeur et du traitement du langage naturel et je poursuis actuellement des études supérieures en intelligence artificielle.
Image Source
- Image 1,2 : https://towardsdatascience.com/the-vanishing-gradient-problem-69bf08b15484
- Image 3,4 : https://datascience.stackexchange.com/questions/33022/how-to-interpert-resnet50-layer-types
- Image d'aperçu : https://www.zdnet.com/pictures/10-cool-robots-at-this-years-robobusiness-conference/2/
N'hésitez pas à me contacter sur :
- Linkedin : https://www.linkedin.com/in/siddharth-m-426a9614a/
- Github : https://github.com/Siddharth1698
Les médias présentés dans cet article sur ResNet-34 n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
- 11
- 7
- Tous
- analytique
- architecture
- article
- intelligence artificielle
- construire
- Développement
- cas
- Voies
- classification
- code
- Venir
- Connexions
- contenu
- continue
- données
- l'apprentissage en profondeur
- Dérivés
- etc
- Visage
- Figure
- filtres
- finalement
- Prénom
- Avant
- Framework
- Test d'anglais
- fonction
- GitHub
- Don
- l'
- guide
- ici
- Comment
- HTTPS
- idée
- image
- Y compris
- d'information
- Intelligence
- langue
- conduire
- apprentissage
- Gamme
- Fabrication
- Médias
- Microsoft
- Microsoft Research
- Mission
- modèle
- Langage naturel
- Traitement du langage naturel
- réseau et
- réseaux
- Neural
- les réseaux de neurones
- Patron de Couture
- pool
- Python
- pytorch
- un article
- REST
- Sciences
- décalage
- Taille
- petit
- So
- foulée
- Étudiant
- raconte
- tester
- Essais
- En pensant
- fiable
- Formation
- Mises à jour
- us
- Plus-value
- dans les
- vos contrats
- X
- années
- ZDNET



![Comment gagner de l’argent en utilisant les outils d’IA ? [14 meilleures méthodes et meilleurs outils]](https://platoaistream.net/wp-content/uploads/2024/03/how-to-make-money-using-ai-tools-14-best-ways-top-tools-360x198.png)

