Les réseaux de neurones apprennent à travers les nombres, de sorte que chaque mot sera mappé sur des vecteurs pour représenter un mot particulier. La couche d'incorporation peut être considérée comme une table de recherche qui stocke les incorporations de mots et les récupère à l'aide d'indices.
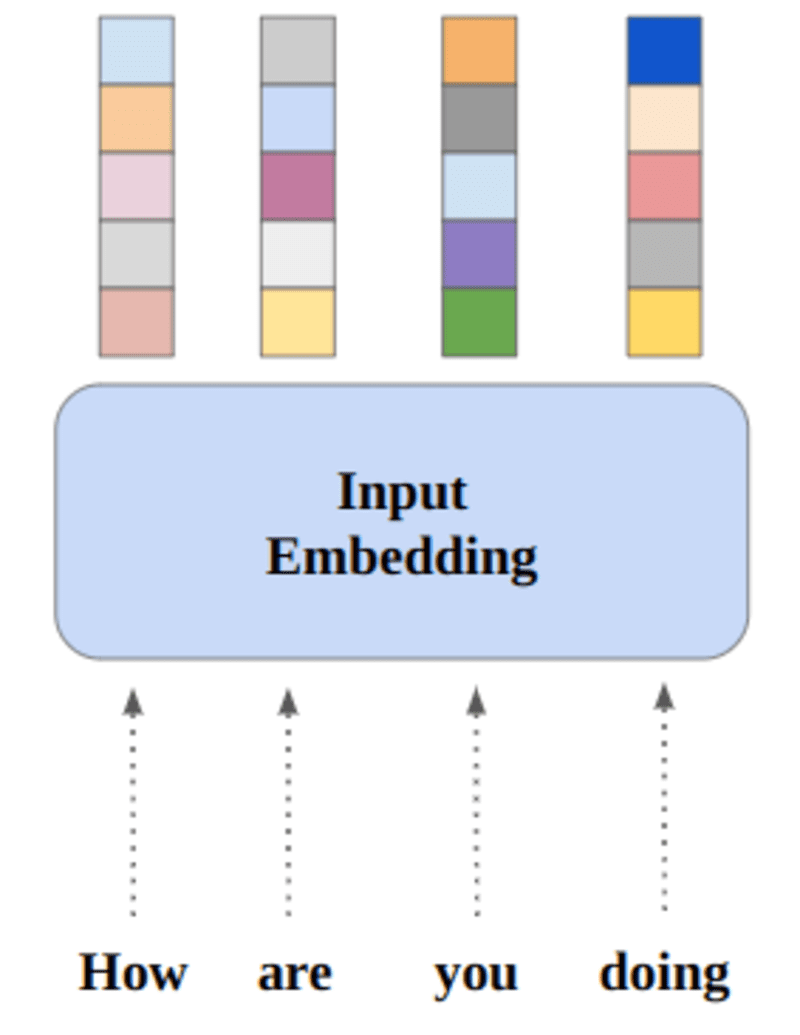
Les mots qui ont le même sens seront proches en termes de similarité distance euclidienne/cosinus. par exemple, dans la représentation des mots ci-dessous, "samedi", "dimanche" et "lundi" sont associés au même concept, nous pouvons donc voir que les mots sont similaires.

La détermination de la position du mot, Pourquoi avons-nous besoin de déterminer la position du mot ? Parce que l'encodeur du transformateur n'a pas de récurrence comme les réseaux de neurones récurrents, nous devons ajouter des informations sur les positions dans les plongements d'entrée. Cela se fait à l'aide d'un codage positionnel. Les auteurs de l'article ont utilisé les fonctions suivantes pour modéliser la position d'un mot.
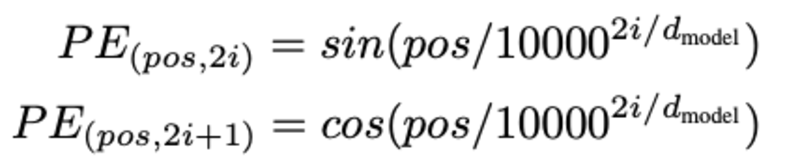
Nous allons essayer d'expliquer le codage positionnel.
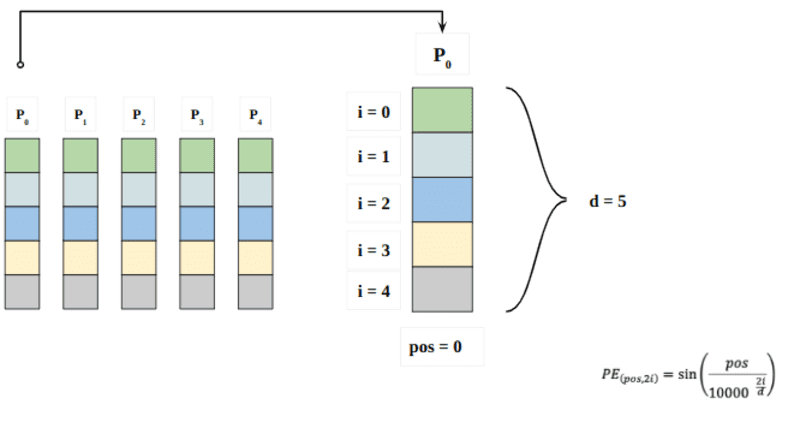
Ici, "pos" fait référence à la position du "mot" dans la séquence. P0 fait référence à l'encastrement de position du premier mot ; "d" signifie la taille de l'intégration du mot/jeton. Dans cet exemple d=5. Enfin, "i" fait référence à chacune des 5 dimensions individuelles de l'intégration (c'est-à-dire 0, 1,2,3,4)
si "i" varie dans l'équation ci-dessus, vous obtiendrez un tas de courbes avec des fréquences variables. Lecture des valeurs d'encastrement de position par rapport à différentes fréquences, donnant différentes valeurs à différentes dimensions d'encastrement pour P0 et P4.
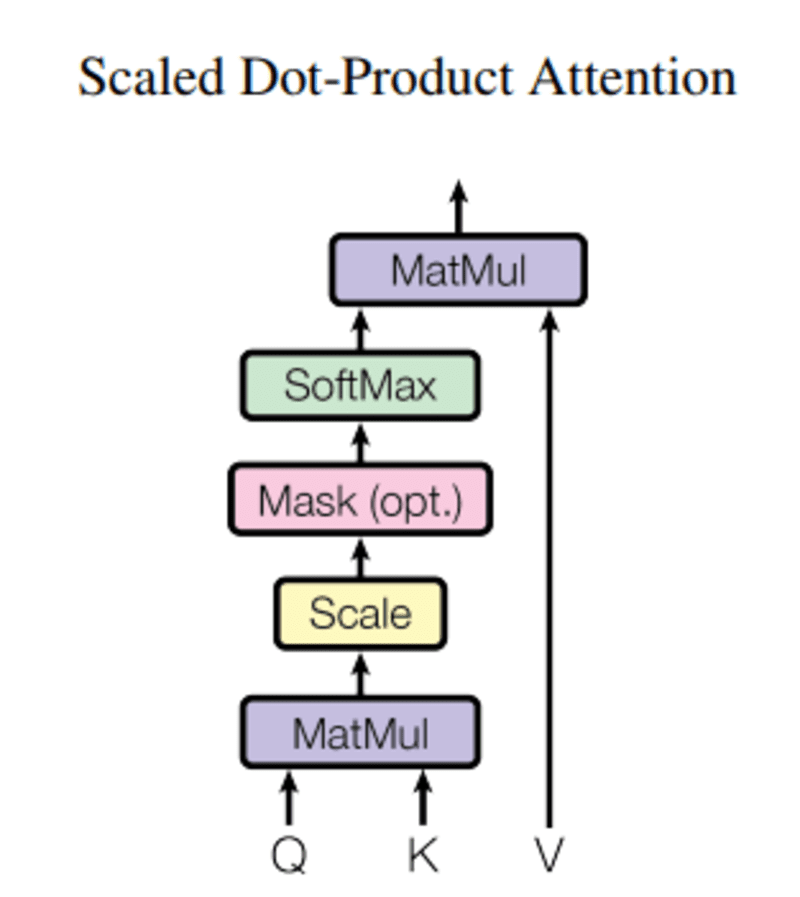
Dans ce nouvel article concernant notre nouveau projet question, Q représente un mot vectoriel, le touches K sont tous les autres mots de la phrase, et valeur V représente le vecteur du mot.
Le but de l'attention est de calculer l'importance du terme clé par rapport au terme de requête lié à la même personne/chose ou concept.
Dans notre cas, V est égal à Q.
Le mécanisme de l'attention nous donne l'importance du mot dans une phrase.
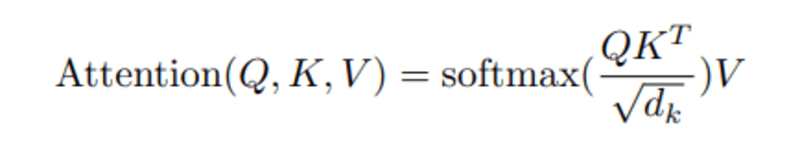
Lorsque nous calculons le produit scalaire normalisé entre la requête et les clés, nous obtenons un tenseur qui représente l'importance relative de chacun des autres mots pour la requête.
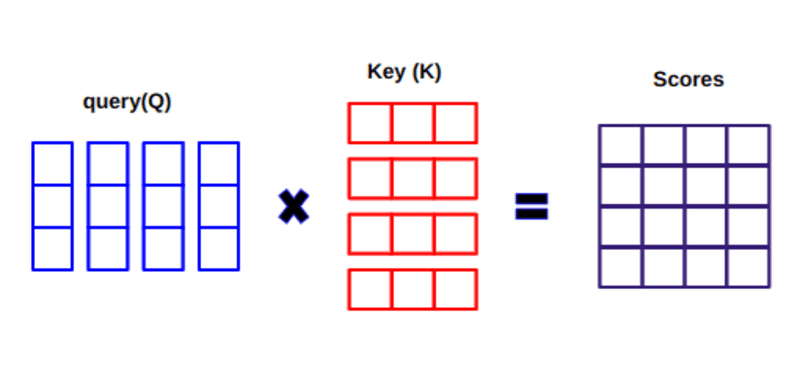
Lors du calcul du produit scalaire entre Q et KT, nous essayons d'estimer comment les vecteurs (c'est-à-dire les mots entre la requête et les clés) sont alignés et renvoyons un poids pour chaque mot de la phrase.
Ensuite, nous normalisons le résultat au carré de d_k et La fonction softmax régularise les termes et les redimensionne entre 0 et 1.
Enfin, nous multiplions le résultat (c'est-à-dire les poids) par la valeur (c'est-à-dire tous les mots) pour réduire l'importance des mots non pertinents et nous concentrer uniquement sur les mots les plus importants.
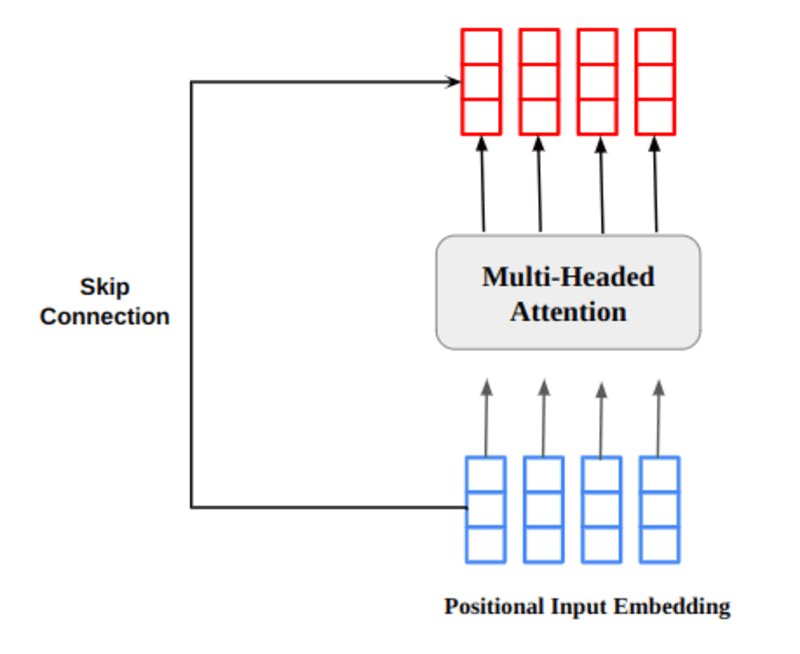
Le vecteur de sortie d'attention à plusieurs têtes est ajouté à l'incorporation d'entrée positionnelle d'origine. C'est ce qu'on appelle une connexion résiduelle/saut de connexion. La sortie de la connexion résiduelle passe par la normalisation de couche. La sortie résiduelle normalisée est transmise à travers un réseau d'anticipation ponctuelle pour un traitement ultérieur.
Le masque est une matrice de la même taille que les scores d'attention remplie de valeurs de 0 et d'infinis négatifs.
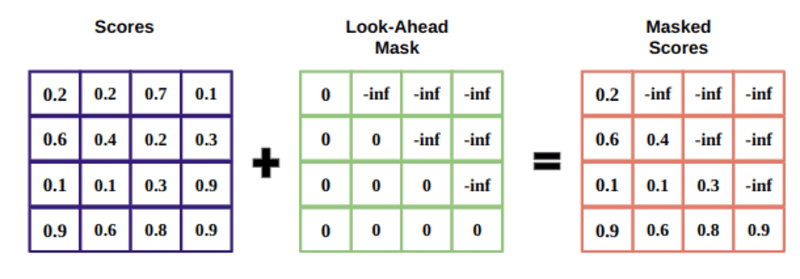
La raison du masque est qu'une fois que vous prenez le softmax des scores masqués, les infinis négatifs deviennent nuls, laissant zéro score d'attention pour les futurs jetons.
Cela indique au modèle de ne pas mettre l'accent sur ces mots.
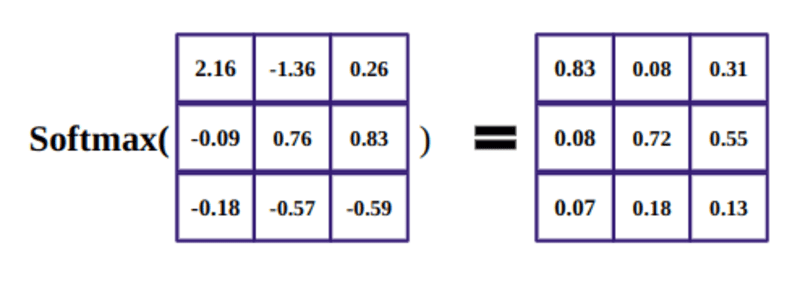
Le but de la fonction softmax est de saisir des nombres réels (positifs et négatifs) et de les transformer en nombres positifs dont la somme est égale à 1.
Ravikumar Naduvin est occupé à créer et à comprendre des tâches NLP à l'aide de PyTorch.
ORIGINALE. Republié avec permission.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- À propos
- au dessus de
- ajoutée
- à opposer à
- aligné
- Tous
- ainsi que
- associé
- précaution
- auteurs
- car
- before
- ci-dessous
- jusqu'à XNUMX fois
- Développement
- Bouquet
- appelé
- maisons
- Fermer
- par rapport
- calcul
- informatique
- concept
- concepts
- connexion
- Déterminer
- détermination
- différent
- dimensions
- DOT
- chacun
- estimation
- exemple
- Expliquer
- rempli
- finalement
- Prénom
- Focus
- Abonnement
- fonction
- fonctions
- plus
- avenir
- obtenez
- obtention
- GitHub
- donne
- Don
- Goes
- saisir
- Comment
- HTTPS
- importance
- important
- in
- Indices
- individuel
- d'information
- contribution
- KDnuggetsGenericName
- clés / KEY :
- clés
- Savoir
- couche
- APPRENTISSAGE
- départ
- rechercher
- masque
- Matrice
- sens
- veux dire
- mécanisme
- modèle
- (en fait, presque toutes)
- Besoin
- négatif
- réseau et
- réseaux
- Neural
- les réseaux de neurones
- nlp
- numéros
- original
- Autre
- Papier
- particulier
- passé
- autorisation
- Platon
- Intelligence des données Platon
- PlatonDonnées
- position
- positions
- positif
- traitement
- Produit
- but
- mettre
- pytorch
- en cours
- réal
- raison
- récurrence
- réduire
- se réfère
- en relation
- représentent
- représentation
- représente
- résultat
- résultant
- retourner
- même
- phrase
- Séquence
- devrait
- similaires
- Taille
- So
- quelques
- quadrillé
- STORES
- table
- Prenez
- tâches
- raconte
- conditions
- La
- pensée
- Avec
- à
- Tokens
- transformateurs
- TOUR
- compréhension
- us
- Plus-value
- Valeurs
- poids
- qui
- sera
- Word
- des mots
- zéphyrnet
- zéro