Le déploiement de modèles d'apprentissage automatique (ML) formés et de haute qualité pour effectuer des inférences par lots ou en temps réel est un élément essentiel pour apporter de la valeur aux clients. Cependant, le processus d'expérimentation ML peut être fastidieux - il existe de nombreuses approches nécessitant beaucoup de temps à mettre en œuvre. C'est pourquoi des modèles de ML pré-entraînés comme ceux fournis dans le Zoo modèle PyTorch sont si utiles. Amazon Sage Maker fournit une interface unifiée pour expérimenter différents modèles ML, et le zoo de modèles PyTorch nous permet d'échanger facilement nos modèles de manière standardisée.
Cet article de blog montre comment effectuer une inférence ML à l'aide d'un modèle de détection d'objet du zoo de modèles PyTorch dans SageMaker. Les modèles ML pré-formés du zoo de modèles PyTorch sont prêts à l'emploi et peuvent facilement être utilisés dans le cadre d'applications ML. Configurer ces modèles ML en tant que point de terminaison SageMaker ou Transformation par lots SageMaker travail pour l'inférence en ligne ou hors ligne est facile avec les étapes décrites dans ce billet de blog. Nous utiliserons un R-CNN plus rapide modèle de détection d'objets pour prédire les boîtes englobantes pour les classes d'objets prédéfinies.
Nous passons en revue un exemple de bout en bout, du chargement des poids du modèle de détection d'objets Faster R-CNN à leur enregistrement dans un Service de stockage simple Amazon (Amazon S3) bucket, et d'écrire un fichier de point d'entrée et de comprendre les paramètres clés de l'API PyTorchModel. Enfin, nous déploierons le modèle ML, effectuerons une inférence à l'aide de SageMaker Batch Transform, inspecterons la sortie du modèle ML et apprendrons à interpréter les résultats. Cette solution peut être appliquée à tout autre modèle pré-formé sur le PyTorch Model Zoo. Pour une liste des modèles disponibles, consultez le Documentation du zoo modèle PyTorch.
Vue d'ensemble de la solution
Ce billet de blog passera par les étapes suivantes. Pour une version de travail complète de toutes les étapes, voir create_pytorch_model_sagemaker.ipynb
- Étape 1 : configuration
- Étape 2 : Charger un modèle ML à partir de PyTorch Model Zoo
- Étape 3 Enregistrez et chargez les artefacts du modèle ML sur Amazon S3
- Étape 4 : Créer des scripts d'inférence de modèle de ML
- Étape 5 : Lancement d'une tâche de transformation par lots SageMaker
- Étape 6 : Visualiser les résultats
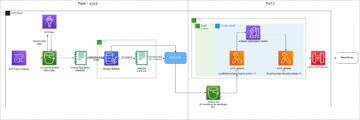
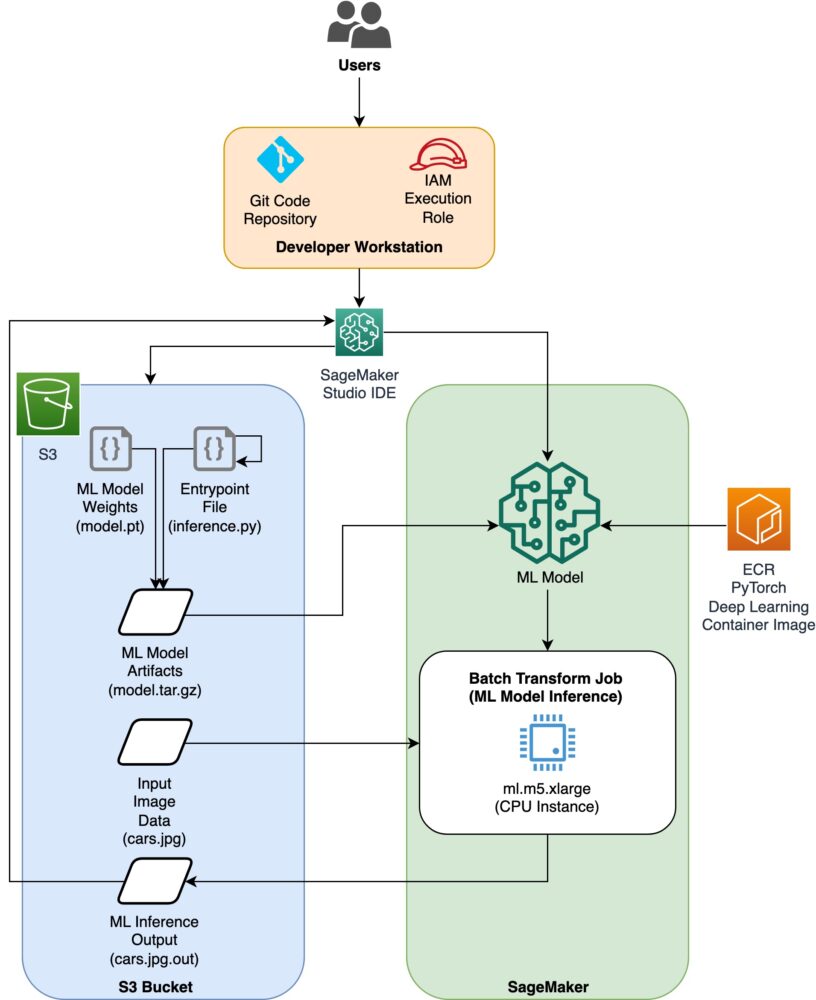
Diagramme d'architecture

Structure du répertoire
Le code de ce blog se trouve dans ce GitHub référentiel. La base de code contient tout ce dont nous avons besoin pour créer des artefacts de modèle ML, lancer la tâche de transformation et visualiser les résultats.
C'est le flux de travail que nous utilisons. Toutes les étapes suivantes feront référence aux modules de cette structure.
Les sagemaker_torch_model_zoo dossier doit contenir inference.py en tant que fichier de point d'entrée, et create_pytorch_model_sagemaker.ipynb pour charger et enregistrer les pondérations du modèle, créer un objet de modèle SageMaker et enfin le transmettre à une tâche de transformation par lots SageMaker. Afin d'apporter vos propres modèles ML, modifiez les chemins dans la section Étape 1 : configuration du notebook et chargez un nouveau modèle dans la section Étape 2 : Chargement d'un modèle ML à partir de la section Zoo de modèles PyTorch. Le reste des étapes suivantes ci-dessous resterait le même.
Étape 1 : configuration
Rôles IAM
SageMaker effectue des opérations sur une infrastructure gérée par SageMaker. SageMaker ne peut effectuer que les actions autorisées telles que définies dans le rôle d'exécution IAM associé au bloc-notes pour SageMaker. Pour une documentation plus détaillée sur la création de rôles IAM et la gestion des autorisations IAM, consultez le Documentation des rôles AWS SageMaker. Nous pouvons créer un nouveau rôle, ou nous pourrions obtenir le Bloc-notes SageMaker (Studio)le rôle d'exécution par défaut de en exécutant les lignes de code suivantes :
Le code ci-dessus obtient le rôle d'exécution SageMaker pour l'instance de bloc-notes. Il s'agit du rôle IAM que nous avons créé pour notre instance de bloc-notes SageMaker ou SageMaker Studio.
Paramètres configurables par l'utilisateur
Voici tous les paramètres configurables nécessaires à la création et au lancement de notre tâche de transformation par lots SageMaker :
Étape 2 : Charger un modèle ML à partir du zoo de modèles PyTorch
Ensuite, nous spécifions un modèle de détection d'objet à partir du zoo de modèles PyTorch et enregistrons ses poids de modèle ML. En règle générale, nous enregistrons un modèle PyTorch en utilisant les extensions de fichier .pt ou .pth. L'extrait de code ci-dessous télécharge un modèle Faster R-CNN ResNet50 ML pré-formé à partir du zoo de modèles PyTorch :
modèle = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
La transformation par lots SageMaker nécessite en entrée certaines pondérations de modèle, nous allons donc enregistrer le modèle ML pré-formé sous model.pt. Si nous voulons charger un modèle personnalisé, nous pourrions enregistrer les poids du modèle à partir d'un autre modèle PyTorch en tant que model.pt à la place.
Étape 3 : Enregistrer et charger des artefacts de modèle ML sur Amazon S3
Étant donné que nous utiliserons SageMaker pour l'inférence ML, nous devons télécharger les pondérations du modèle dans un compartiment S3. Nous pouvons le faire en utilisant les commandes suivantes ou en téléchargeant et en faisant simplement glisser et déposer le fichier directement dans S3. Les commandes suivantes vont d'abord compresser le groupe de fichiers dans model.pt dans une archive tar et copiez les poids du modèle de notre machine locale vers le compartiment S3.
Notes: Pour exécuter les commandes suivantes, vous devez disposer du Interface de ligne de commande AWS (AWS CLI) installé.
Ensuite, nous copions notre image d'entrée sur S3. Vous trouverez ci-dessous le chemin S3 complet de l'image.
Nous pouvons copier cette image sur S3 avec une autre commande aws s3 cp.
Étape 4 : Créer des scripts d'inférence de modèle de ML
Nous allons maintenant passer en revue notre fichier entrypoint, inference.py module. Nous pouvons déployer un modèle PyTorch formé en dehors de SageMaker à l'aide de la classe PyTorchModel. Tout d'abord, nous instancions l'objet PyTorchModelZoo. Ensuite, nous allons construire un fichier de point d'entrée inference.py pour effectuer une inférence ML à l'aide de la transformation par lots SageMaker sur des exemples de données hébergées dans Amazon S3.
Comprendre l'objet PyTorchModel
Les PyTorchModèle La classe dans l'API Python SageMaker nous permet d'effectuer une inférence ML à l'aide de notre artefact de modèle téléchargé.
Pour lancer la classe PyTorchModel, nous devons comprendre les paramètres d'entrée suivants :
name: Nom du modèle; nous vous recommandons d'utiliser soit le nom du modèle + la date et l'heure, soit une chaîne aléatoire + la date et l'heure pour l'unicité.model_data: L'URI S3 de l'artefact de modèle de ML empaqueté.entry_point: fichier Python défini par l'utilisateur à utiliser par l'image Docker d'inférence pour définir des gestionnaires pour les demandes entrantes. Le code définit le chargement du modèle, le prétraitement des entrées, la logique de prédiction et le post-traitement des sorties.framework_version: Doit être défini sur la version 1.2 ou supérieure pour activer le reconditionnement automatique du modèle PyTorch.source_dir: Le répertoire du fichier entry_point.role: Un rôle IAM pour faire des demandes de service AWS.image_uri: utilisez cette image de conteneur Amazon ECR Docker comme base pour l'environnement de calcul du modèle ML.sagemaker_session: La session SageMaker.py_version: La version de Python à utiliser
L'extrait de code suivant instancie la classe PyTorchModel pour effectuer une inférence à l'aide du modèle PyTorch pré-entraîné :
Comprendre le fichier de point d'entrée (inference.py)
Le paramètre entry_point pointe vers un fichier Python nommé inference.py. Ce point d'entrée définit le chargement du modèle, le prétraitement des entrées, la logique de prédiction et le post-traitement des sorties. Il complète le code de service de modèle ML dans le PyTorch prédéfini Conteneur d'apprentissage en profondeur SageMaker l'image.
Inference.py contiendra les fonctions suivantes. Dans notre exemple, nous implémentons la model_fn, input_fn, predict_fn ainsi que output_fn fonctions pour remplacer les gestionnaire d'inférence PyTorch par défaut.
model_fn: prend dans un répertoire contenant des points de contrôle de modèle statique dans l'image d'inférence. Ouvre et charge le modèle à partir d'un chemin spécifié et renvoie un modèle PyTorch.input_fn: prend en entrée la charge utile de la requête entrante (request_body) et le type de contenu d'une requête entrante (request_content_type). Gère le décodage des données. Cette fonction doit être ajustée en fonction de l'entrée attendue par le modèle.predict_fn: Appelle un modèle sur des données désérialisées dans input_fn. Effectue une prédiction sur l'objet désérialisé avec le modèle ML chargé.output_fn: sérialise le résultat de la prédiction dans le type de contenu de réponse souhaité. Convertit les prédictions obtenues à partir de la fonction predict_fn aux formats JSON, CSV ou NPY.
Étape 5 : Lancement d'une tâche de transformation par lots SageMaker
Pour cet exemple, nous obtiendrons des résultats d'inférence ML via une tâche de transformation par lots SageMaker. Les tâches de transformation par lots sont particulièrement utiles lorsque nous voulons obtenir des inférences à partir d'ensembles de données une seule fois, sans avoir besoin d'un point de terminaison persistant. Nous instancions un sagemaker.transformer.Transformateur objet pour créer et interagir avec les tâches de transformation par lots SageMaker.
Consultez la documentation relative à la création d'une tâche de transformation par lots à l'adresse Créer un travail de transformation.
Étape 6 : Visualiser les résultats
Une fois la tâche de transformation par lots SageMaker terminée, nous pouvons charger les sorties d'inférence ML à partir d'Amazon S3. Pour cela, accédez au Console de gestion AWS et recherchez Amazon SageMaker. Sur le panneau de gauche, sous Inférence, Voir Tâches de transformation par lots.

Après avoir sélectionné Transformation par lots, consultez la page Web répertoriant toutes les tâches de transformation par lots SageMaker. Nous pouvons voir la progression de l'exécution de notre tâche la plus récente.

Tout d'abord, le travail aura le statut "En cours". Une fois que c'est fait, voyez le statut passer à Terminé.

Une fois que le statut est marqué comme terminé, nous pouvons cliquer sur le travail pour afficher les résultats. Cette page Web contient le résumé du travail, y compris les configurations du travail que nous venons d'exécuter.

Sous Configuration des données de sortie, nous verrons un chemin de sortie S3. C'est là que nous trouverons notre sortie d'inférence ML.

Sélectionnez le chemin de sortie S3 et voyez un fichier [image_name].[file_type].out avec nos données de sortie. Notre fichier de sortie contiendra une liste de mappages. Exemple de sortie :
Ensuite, nous traitons ce fichier de sortie et visualisons nos prédictions. Ci-dessous, nous précisons notre seuil de confiance. Nous obtenons la liste des classes de la Mappage d'objets de l'ensemble de données COCO. Lors de l'inférence, le modèle ne nécessite que les tenseurs d'entrée et renvoie les prédictions post-traitées sous forme de List[Dict[Tensor]], une pour chaque image d'entrée. Les champs du Dict sont les suivants, où N est le nombre de détections :
- box (FloatTensor[N, 4]) : les boîtes prédites dans
[x1, y1, x2, y2]format, avec0 <= x1 < x2 <= W and 0 <= y1 < y2 <= H, OùWest la largeur de l'image etHest la hauteur de l'image - Étiquettes (
Int64Tensor[N]) : les étiquettes prédites pour chaque détection - partitions (
Tensor[N]) : les scores de prédiction pour chaque détection
Pour plus de détails sur la sortie, reportez-vous au Documentation PyTorch Faster R-CNN FPN.
La sortie du modèle contient des cadres de délimitation avec des scores de confiance respectifs. Nous pouvons optimiser l'affichage des faux positifs en supprimant les boîtes englobantes pour lesquelles le modèle n'est pas sûr. Les extraits de code suivants traitent les prédictions dans le fichier de sortie et dessinent des cadres de délimitation sur les prédictions où le score est supérieur à notre seuil de confiance. Nous fixons le seuil de probabilité, CONF_THRESH, à 75 pour cet exemple.
Enfin, nous visualisons ces mappages pour comprendre notre sortie.

Notes: si l'image ne s'affiche pas dans votre bloc-notes, veuillez la localiser dans l'arborescence des répertoires sur le côté gauche de JupyterLab et l'ouvrir à partir de là.
Exécution de l'exemple de code
Pour un exemple de travail complet, clonez le code dans le amazon-sagemaker-exemples GitHub et exécuter les cellules dans le create_pytorch_model_sagemaker.ipynb carnet.
Conclusion
Dans cet article de blog, nous avons présenté un exemple de bout en bout d'inférence ML à l'aide d'un modèle de détection d'objets du zoo de modèles PyTorch à l'aide de la transformation par lots SageMaker. Nous avons couvert le chargement des pondérations du modèle de détection d'objets Faster R-CNN, leur enregistrement dans un compartiment S3, l'écriture d'un fichier de point d'entrée et la compréhension des paramètres clés de l'API PyTorchModel. Enfin, nous avons déployé le modèle et effectué l'inférence du modèle ML, visualisé la sortie du modèle et appris à interpréter les résultats.
À propos des auteurs
 Dipika Khullar est un ingénieur ML dans le Laboratoire de solutions Amazon ML. Elle aide les clients à intégrer des solutions ML pour résoudre leurs problèmes commerciaux. Plus récemment, elle a construit des pipelines de formation et d'inférence pour les clients des médias et des modèles prédictifs pour le marketing.
Dipika Khullar est un ingénieur ML dans le Laboratoire de solutions Amazon ML. Elle aide les clients à intégrer des solutions ML pour résoudre leurs problèmes commerciaux. Plus récemment, elle a construit des pipelines de formation et d'inférence pour les clients des médias et des modèles prédictifs pour le marketing.
 Marcelo Aberlé est ingénieur ML au sein de l'organisation AWS AI. Il dirige les efforts de MLOps au Laboratoire de solutions Amazon ML, aidant les clients à concevoir et à mettre en œuvre des systèmes de ML évolutifs. Sa mission est de guider les clients dans leur parcours ML d'entreprise et d'accélérer leur parcours ML vers la production.
Marcelo Aberlé est ingénieur ML au sein de l'organisation AWS AI. Il dirige les efforts de MLOps au Laboratoire de solutions Amazon ML, aidant les clients à concevoir et à mettre en œuvre des systèmes de ML évolutifs. Sa mission est de guider les clients dans leur parcours ML d'entreprise et d'accélérer leur parcours ML vers la production.
 Ninad Kulkarni est un scientifique appliqué dans le Laboratoire de solutions Amazon ML. Il aide les clients à adopter le ML et l'IA en créant des solutions pour résoudre leurs problèmes commerciaux. Plus récemment, il a construit des modèles prédictifs pour les clients du sport, de l'automobile et des médias.
Ninad Kulkarni est un scientifique appliqué dans le Laboratoire de solutions Amazon ML. Il aide les clients à adopter le ML et l'IA en créant des solutions pour résoudre leurs problèmes commerciaux. Plus récemment, il a construit des modèles prédictifs pour les clients du sport, de l'automobile et des médias.
 Yash Shah est directeur scientifique au Laboratoire de solutions Amazon ML. Lui et son équipe de scientifiques appliqués et d'ingénieurs ML travaillent sur une gamme de cas d'utilisation ML dans les domaines de la santé, du sport, de l'automobile et de la fabrication.
Yash Shah est directeur scientifique au Laboratoire de solutions Amazon ML. Lui et son équipe de scientifiques appliqués et d'ingénieurs ML travaillent sur une gamme de cas d'utilisation ML dans les domaines de la santé, du sport, de l'automobile et de la fabrication.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/create-amazon-sagemaker-models-using-the-pytorch-model-zoo/
- 1
- 100
- 214
- 28
- 7
- 9
- a
- au dessus de
- accélérer
- actes
- propos
- Ajusté
- adopter
- AI
- Tous
- permet
- Amazon
- Amazon Sage Maker
- montant
- ainsi que
- Une autre
- api
- applications
- appliqué
- approches
- Automatique
- l'automobile
- disponibles
- AWS
- base
- ci-dessous
- blog
- corps
- Box
- boîtes
- apporter
- Apporter
- construire
- Développement
- construit
- la performance des entreprises
- Appels
- fournisseur
- voitures
- cas
- Cellules
- Change
- classe
- les classes
- code
- Base de code
- Couleur
- Complété
- calcul
- ordinateur
- confiance
- confiance
- construire
- Contenant
- contient
- contenu
- pourriez
- couvert
- engendrent
- créée
- La création
- critique
- Customiser
- Clients
- données
- ensembles de données
- Date
- Le décryptage
- profond
- l'apprentissage en profondeur
- Réglage par défaut
- Définit
- déployer
- déployé
- Conception
- détaillé
- détails
- Détection
- DICT
- différent
- directement
- Commande
- Docker
- Documentation
- Ne fait pas
- téléchargements
- Goutte
- chacun
- même
- efforts
- non plus
- permettre
- end-to-end
- Endpoint
- ingénieur
- Les ingénieurs
- Entreprise
- entrée
- Environment
- Ether (ETH)
- peut
- exemple
- exécution
- expérience
- extensions
- plus rapide
- Des champs
- Déposez votre dernière attestation
- Fichiers
- remplir
- finalement
- Trouvez
- Prénom
- Abonnement
- suit
- le format
- trouvé
- de
- plein
- fonction
- fonctions
- obtenez
- Go
- Réservation de groupe
- guide
- Poignées
- la médecine
- la taille
- utile
- aider
- aide
- de haute qualité
- augmentation
- organisé
- Comment
- How To
- Cependant
- HTML
- HTTPS
- image
- satellite
- Mettre en oeuvre
- in
- Y compris
- Nouveau
- indice
- Infrastructure
- initier
- contribution
- instance
- plutôt ;
- intégrer
- interagissant
- Interfaces
- IT
- JIT
- Emploi
- Emplois
- chemin
- json
- ACTIVITES
- laboratoire
- Libellé
- Etiquettes
- lancer
- lancement
- conduisant
- APPRENTISSAGE
- savant
- apprentissage
- Gamme
- lignes
- Liste
- inscription
- charge
- chargement
- charges
- locales
- Lot
- click
- machine learning
- faire
- gérés
- gestion
- manager
- les gérer
- manière
- fabrication
- cartographie
- Stratégie
- Médias
- Mission
- ML
- MLOps
- modèle
- numériques jumeaux (digital twin models)
- Modules
- PLUS
- (en fait, presque toutes)
- prénom
- Nommé
- NAVIGUER
- Besoin
- Besoins
- Nouveauté
- cahier
- nombre
- objet
- Détection d'objet
- obtenu
- direct
- ONE
- en ligne
- ouvert
- ouvre
- Opérations
- Optimiser
- de commander
- organisation
- OS
- Autre
- décrit
- au contrôle
- propre
- panneau
- paramètre
- paramètres
- partie
- chemin
- effectuer
- effectuer
- effectue
- pièce
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- Point
- des notes bonus
- Post
- prévoir
- prédit
- prédiction
- Prédictions
- d'ouvrabilité
- processus
- Vidéo
- Progrès
- à condition de
- fournit
- Python
- pytorch
- gamme
- Lire
- en temps réel
- récent
- récemment
- recommander
- région
- rester
- enlever
- nécessaire
- demandes
- a besoin
- ceux
- réponse
- REST
- résultat
- Résultats
- retourner
- Retours
- Rôle
- rôle
- racine
- Courir
- pour le running
- sagemaker
- même
- Épargnez
- économie
- évolutive
- Sciences
- Scientifique
- scientifiques
- Rechercher
- Section
- la sélection
- service
- service
- Session
- set
- mise
- devrait
- significative
- étapes
- simplement
- So
- sur mesure
- Solutions
- RÉSOUDRE
- quelques
- spécifié
- Sportive
- Sports
- Statut
- étapes
- Étapes
- storage
- structure
- studio
- RÉSUMÉ
- Système
- prend
- équipe
- Les
- leur
- порог
- Avec
- fiable
- à
- torche
- Vision de la torche
- qualifié
- Formation
- Transformer
- typiquement
- sous
- comprendre
- compréhension
- us
- utilisé
- Plus-value
- version
- Voir
- W
- Quoi
- qui
- sera
- dans les
- sans
- Activités principales
- de travail
- pourra
- écriture
- Votre
- zéphyrnet
- ZOO