Aujourd'hui, des centaines de milliers de clients utilisent des lacs de données pour l'analyse et l'apprentissage automatique. Cependant, les ingénieurs de données doivent nettoyer et préparer ces données avant de pouvoir les utiliser. Les données sous-jacentes doivent être exactes et récentes pour que le client puisse prendre des décisions commerciales en toute confiance. Sinon, les consommateurs de données perdent confiance dans les données et prennent des décisions sous-optimales ou incorrectes. C'est une tâche courante pour les ingénieurs de données d'évaluer si les données sont exactes et récentes ou non. Il existe aujourd'hui différents outils de qualité des données. Cependant, les outils courants de qualité des données nécessitent généralement des processus manuels pour surveiller la qualité des données.
AWS Glue Data Quality est une fonctionnalité en avant-première de Colle AWS qui mesure et surveille la qualité des données de Service de stockage simple Amazon (Amazon S3) des lacs de données et dans les tâches d'extraction, de transformation et de chargement (ETL) AWS Glue. Il s'agit d'une fonctionnalité d'aperçu ouvert, elle est donc déjà activée dans votre compte dans le Régions disponibles. Vous pouvez facilement définir et mesurer les contrôles de qualité des données dans la console AWS Glue Studio sans écrire de codes. Il simplifie votre expérience de gestion de la qualité des données.
Cet article est la partie 2 d'une série de quatre articles expliquant le fonctionnement d'AWS Glue Data Quality. Consultez le post précédent de cette série :
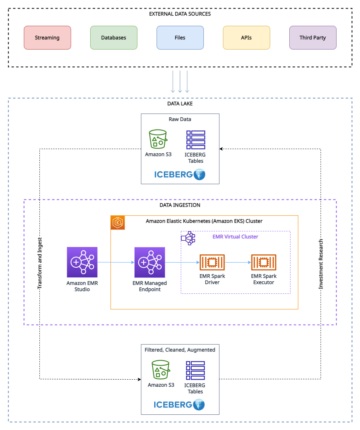
Dans cet article, nous montrons comment créer une tâche AWS Glue qui mesure et surveille la qualité des données d'un pipeline de données. Nous montrons également comment agir en fonction des résultats de la qualité des données.
Vue d'ensemble de la solution
Prenons un exemple de cas d'utilisation dans lequel un ingénieur de données doit créer un pipeline de données pour ingérer les données d'une zone brute vers une zone organisée dans un lac de données. En tant qu'ingénieur de données, l'une de vos principales responsabilités, avec l'extraction, la transformation et le chargement des données, est de valider la qualité des données. L'identification en amont des problèmes de qualité des données vous permet d'éviter de placer de mauvaises données dans la zone organisée et d'éviter les incidents de corruption de données ardus.
Dans cet article, vous apprendrez à configurer facilement intégré ainsi que Customiser vérifications de validation des données dans votre travail AWS Glue pour empêcher les mauvaises données de corrompre les données de haute qualité en aval.
L'ensemble de données utilisé pour cet article est généré synthétiquement ; la capture d'écran suivante montre un exemple des données.

Configurer des ressources avec AWS CloudFormation
Ce poste comprend un AWS CloudFormation modèle pour une configuration rapide. Vous pouvez le consulter et le personnaliser en fonction de vos besoins.
Le modèle CloudFormation génère les ressources suivantes :
- Un compartiment Amazon Simple Storage Service (Amazon S3) (
gluedataqualitystudio-*). - Les préfixes et objets suivants dans le compartiment S3 :
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- Gestion des identités et des accès AWS (IAM) utilisateurs, rôles et stratégies. Le rôle IAM (
GlueDataQualityStudio-*) est autorisé à lire et à écrire à partir du compartiment S3. - AWS Lambda fonctions et stratégies IAM requises par ces fonctions pour créer et supprimer cette pile.
Pour créer vos ressources, procédez comme suit :
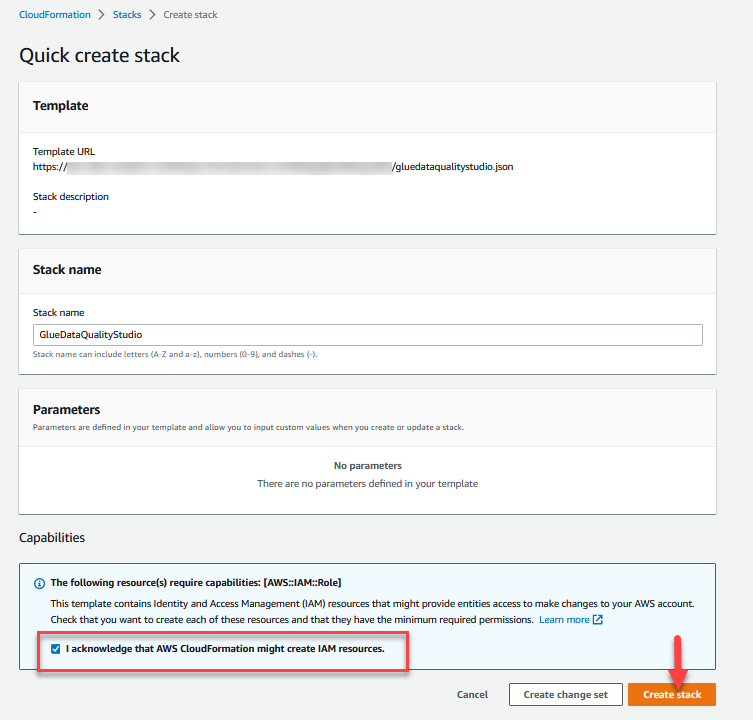
- Connectez-vous à la Console AWS CloudFormation dans l'
us-east-1Région. - Selectionnez Lancer la pile:

- Sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM.
- Selectionnez Créer une pile et attendez que l'étape de création de la pile soit terminée.
Mettre en œuvre la solution
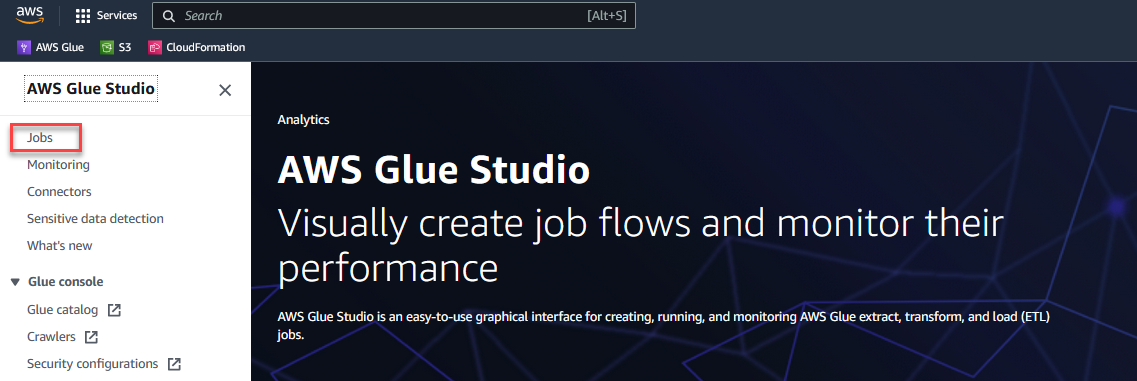
Pour commencer à configurer votre solution, procédez comme suit :
- Sur le Console AWS Glue Studio, choisissez Emplois dans le volet de navigation.
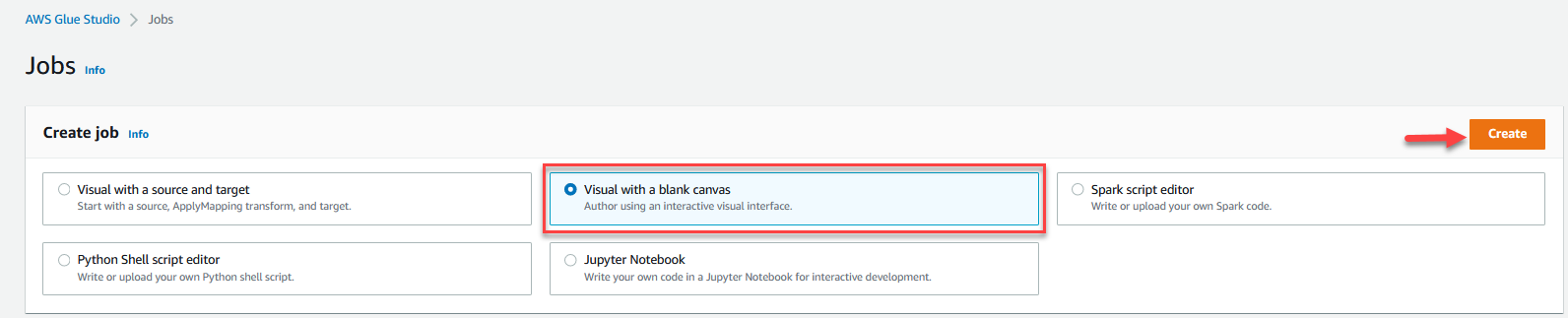
- Sélectionnez Visuel avec une toile vierge et choisissez Création.
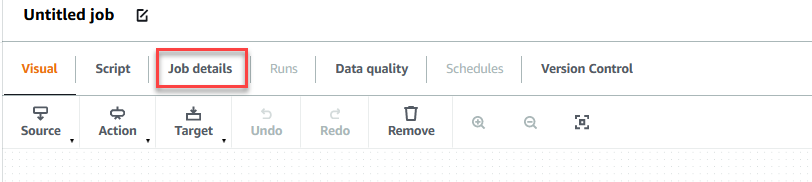
- Choisissez le Détails de l'emploi onglet pour configurer la tâche.
- Pour Nom, Entrer
GlueDataQualityStudio. - Pour Rôle IAM, choisissez le rôle commençant par
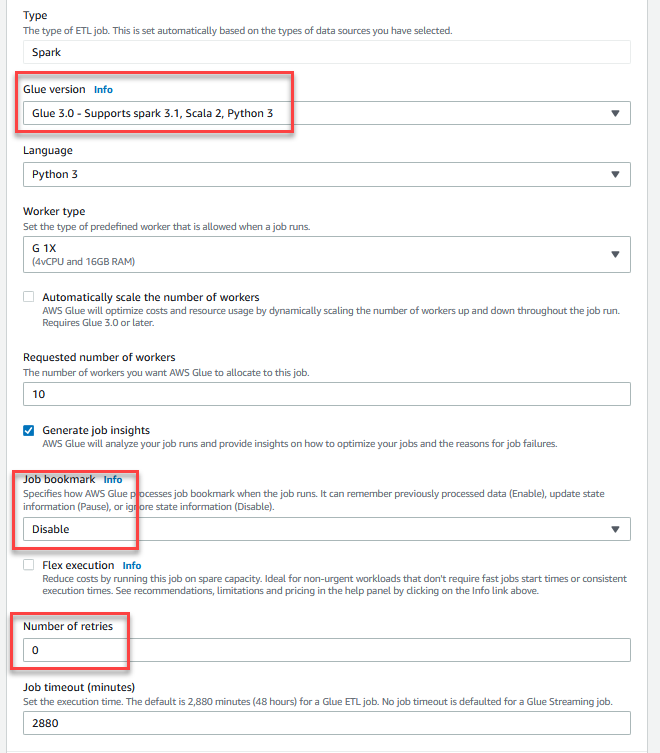
GlueDataQualityStudio-*. - Pour Version colle, choisissez Colle 3.0.
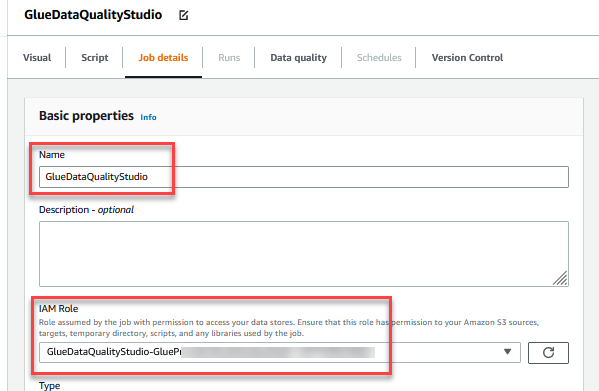
- Pour Signet d'emploi, choisissez Désactiver. Cela vous permet d'exécuter cette tâche plusieurs fois avec le même jeu de données d'entrée.
- Pour Nombre de tentatives, Entrer
0.
- Dans le Propriétés avancées , fournissez le compartiment S3 créé par le modèle CloudFormation (commençant par
gluedataqualitystudio-*).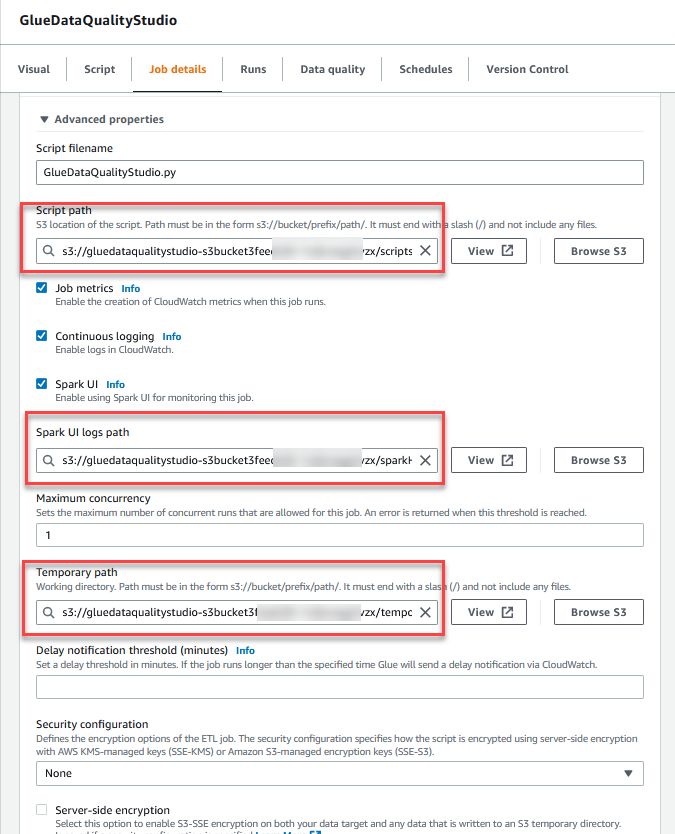
- Selectionnez Épargnez.
- Une fois le travail enregistré, choisissez le Visuel onglet et sur l'onglet Identifier menu, choisissez Amazon S3.
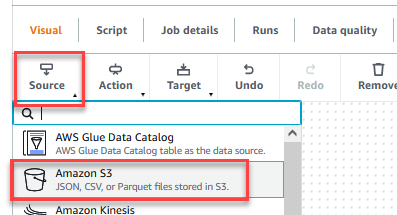
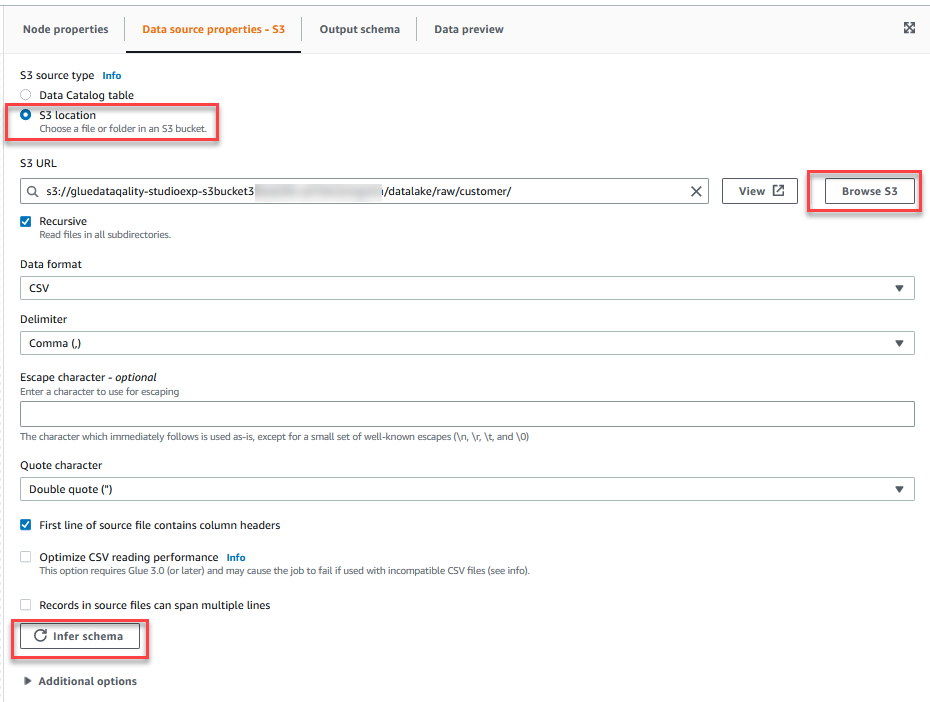
- Sur le Propriétés de la source de données - S3 onglet, pour Type de source S3, sélectionnez Emplacement S3.
- Selectionnez Parcourir S3 et accédez au préfixe
/datalake/raw/customer/dans le compartiment S3 commençant pargluedataqualitystudio-*. - Selectionnez Déduire le schéma.
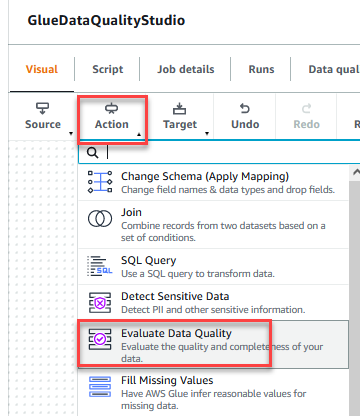
- Sur le Action menu, choisissez Évaluer la qualité des données.
- Choisissez le Évaluer la qualité des données nœud.
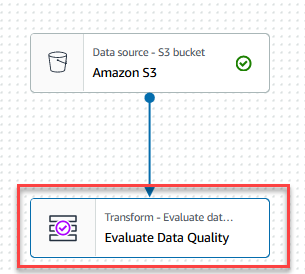
Sur le Transformer , vous pouvez maintenant commencer à créer des règles de qualité des données. La première règle que vous créez consiste à vérifier siCustomer_IDest unique et non nul en utilisant leisPrimaryKeyrègle. - Sur le Types de règles onglet du Générateur de règles DQDL, rechercher
isprimarykeyet choisissez le signe plus.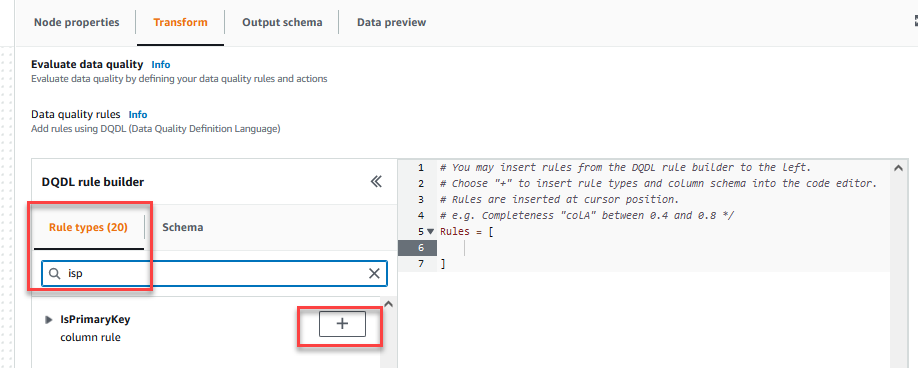
- Sur le Programme onglet du Générateur de règles DQDL, choisissez le signe plus à côté de
Customer_ID. - Dans l'éditeur de règles, supprimez
id.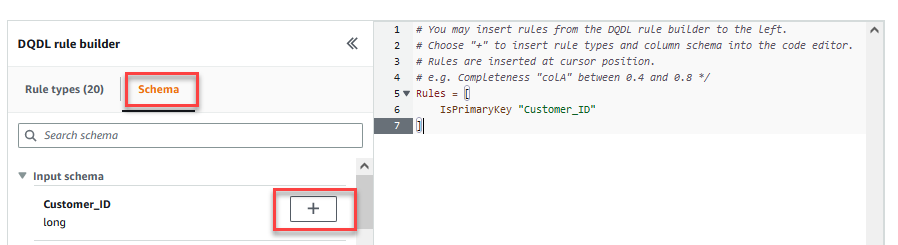
La règle suivante que nous ajoutons vérifie que leFirst_Namela valeur de la colonne est présente pour toutes les lignes. - Vous pouvez également saisir les règles de qualité des données directement dans l'éditeur de règles. Ajoutez une virgule (,) et entrez
IsComplete "First_Name",après la première règle.
Ensuite, vous ajoutez une règle personnalisée pour valider qu'aucune ligne n'existe sansTelephoneorEmail. - Saisissez la règle personnalisée suivante dans l'éditeur de règles :

La fonction Évaluer la qualité des données fournit des actions pour gérer le résultat d'un travail en fonction des résultats de qualité du travail. - Pour cet article, sélectionnez Échec du travail lorsque la qualité des données échoue et choisissez Échec de la tâche sans chargement de la cible données Actions. Dans le Paramètre de sortie de la qualité des données section, choisissez Parcourir S3 et accédez au préfixe
dqresultsdans le compartiment S3 commençant pargluedataqualitystudio-*.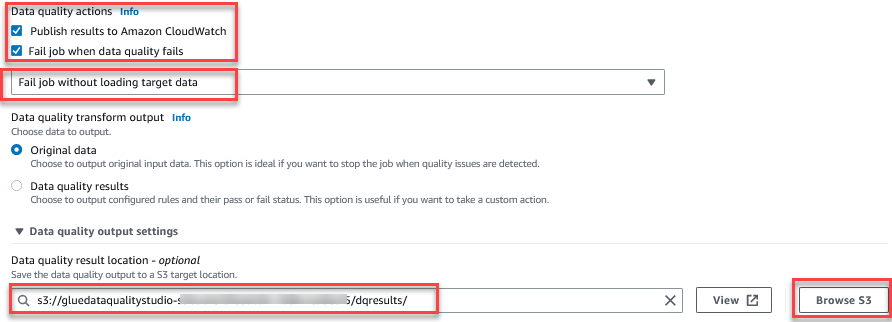
- Sur le Target menu, choisissez Amazon S3.
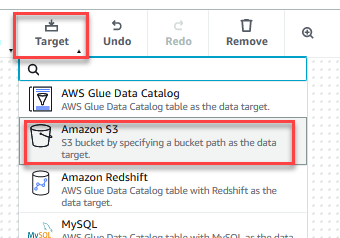
- Choisissez le Cible de données – compartiment S3 nœud.
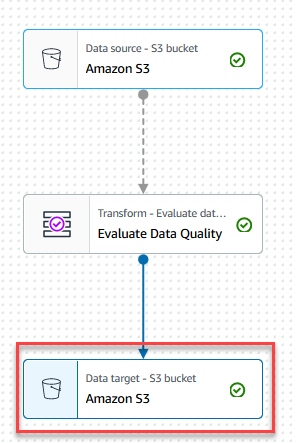
- Sur le Propriétés de la cible de données - S3 onglet, pour Format, choisissez Parquet, Et pour Type de compression, choisissez brusque.
- Pour Emplacement cible S3, choisissez Parcourir S3 et accédez au préfixe
/datalake/curated/customer/dans le compartiment S3 commençant pargluedataqualitystudio-*.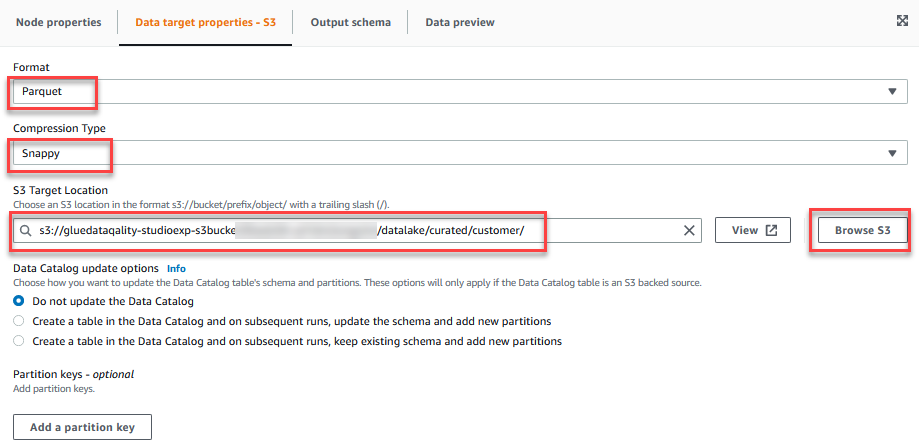
- Selectionnez Épargnez, Puis choisissez Courir.
 Vous pouvez afficher les détails de l'exécution du travail dans l'onglet Exécutions. Dans notre exemple, la tâche échoue avec le message d'erreur "AssertionError : la tâche a échoué en raison de l'échec des règles DQ pour le nœud : .”
Vous pouvez afficher les détails de l'exécution du travail dans l'onglet Exécutions. Dans notre exemple, la tâche échoue avec le message d'erreur "AssertionError : la tâche a échoué en raison de l'échec des règles DQ pour le nœud : .”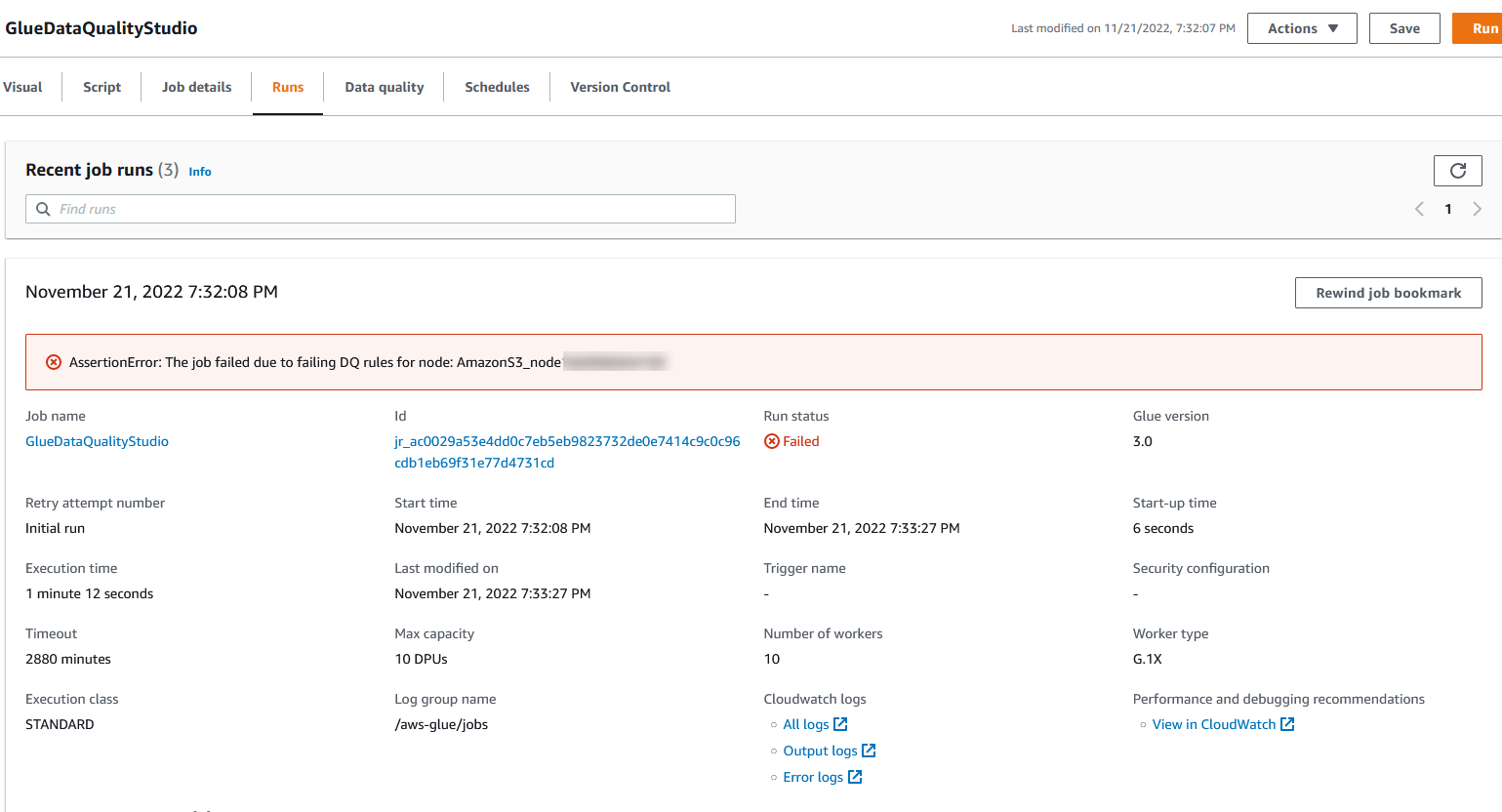 Vous pouvez consulter le résultat de la qualité des données dans l'onglet Qualité des données. Dans notre exemple, la validation personnalisée de la qualité des données a échoué car l'une des lignes de l'ensemble de données n'avait pas
Vous pouvez consulter le résultat de la qualité des données dans l'onglet Qualité des données. Dans notre exemple, la validation personnalisée de la qualité des données a échoué car l'une des lignes de l'ensemble de données n'avait pas TelephoneorEmailvaleur. Les résultats d'évaluation de la qualité des données sont également écrits dans le compartiment S3 au format JSON en fonction du paramètre d'emplacement des résultats de la qualité des données du nœud.
Les résultats d'évaluation de la qualité des données sont également écrits dans le compartiment S3 au format JSON en fonction du paramètre d'emplacement des résultats de la qualité des données du nœud. - Accédez à
dqresultspréfixe sous le compartiment S3 commençantgluedataqualitystudio-*. Vous verrez que le résultat de la qualité des données est partitionné par date.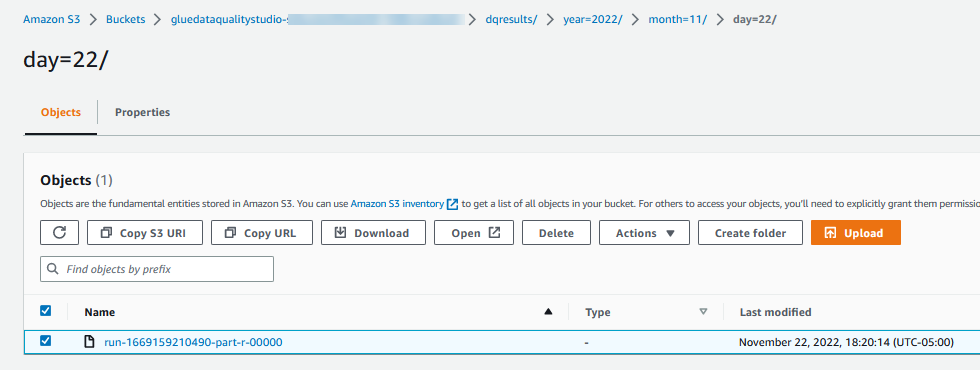
Voici la sortie du fichier JSON. Vous pouvez utiliser cette sortie de fichier pour créer des tableaux de bord de visualisation de la qualité des données personnalisés.

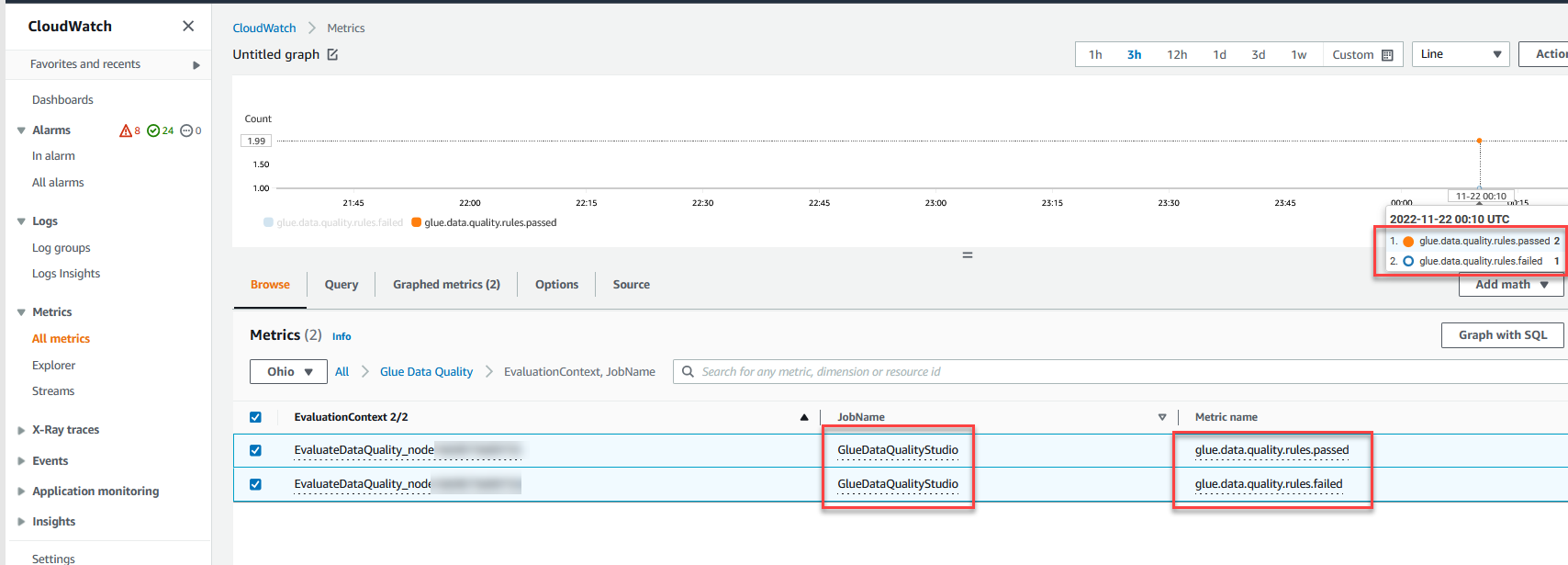
Vous pouvez également surveiller la Évaluer la qualité des données nœud à travers Amazon Cloud Watch métriques et définir des alarmes pour envoyer des notifications sur les résultats de la qualité des données. Pour en savoir plus sur la configuration des alarmes CloudWatch, consultez Utilisation des alarmes Amazon CloudWatch.
Nettoyer
Pour éviter des frais futurs et pour nettoyer les rôles et règles inutilisés, supprimez les ressources que vous avez créées :
- Supprimer l'
GlueDataQualityStudiotravail que vous avez créé dans le cadre de cet article. - Sur la console AWS CloudFormation, supprimez le
GlueDataQualityStudioassociation.
Conclusion
AWS Glue Data Quality offre un moyen simple de mesurer et de surveiller la qualité des données de votre pipeline ETL. Dans cet article, vous avez appris à prendre les mesures nécessaires en fonction des résultats de la qualité des données, ce qui vous aide à maintenir des normes de données élevées et à prendre des décisions commerciales en toute confiance.
Pour en savoir plus sur AWS Glue Data Quality, consultez la documentation :
À propos des auteurs
 Deenbandhu Prasad est un spécialiste senior de l'analyse chez AWS, spécialisé dans les services de Big Data. Il se passionne pour aider les clients à créer une architecture de données moderne sur le cloud AWS. Il a aidé des clients de toutes tailles à mettre en œuvre des solutions de gestion de données, d'entrepôt de données et de lac de données.
Deenbandhu Prasad est un spécialiste senior de l'analyse chez AWS, spécialisé dans les services de Big Data. Il se passionne pour aider les clients à créer une architecture de données moderne sur le cloud AWS. Il a aidé des clients de toutes tailles à mettre en œuvre des solutions de gestion de données, d'entrepôt de données et de lac de données.
 Yannis Mentékidis est ingénieur en développement logiciel senior au sein de l'équipe AWS Glue.
Yannis Mentékidis est ingénieur en développement logiciel senior au sein de l'équipe AWS Glue.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Description
- accès
- Compte
- Avec cette connaissance vient le pouvoir de prendre
- reconnaître
- Action
- actes
- Après
- Tous
- permet
- déjà
- Amazon
- analytique
- ainsi que
- architecture
- AWS
- AWS CloudFormation
- Colle AWS
- Mal
- mauvaises données
- basé
- car
- before
- Big
- Big Data
- construire
- Développement
- la performance des entreprises
- maisons
- des charges
- vérifier
- Contrôles
- Selectionnez
- le cloud
- Colonne
- Commun
- complet
- confiance
- Considérer
- Console
- Les consommateurs
- la corruption
- engendrent
- créée
- création
- organisée
- Customiser
- des clients
- Clients
- personnaliser
- données
- Lac de données
- gestion des données
- Date
- décisions
- détails
- Développement
- directement
- Documentation
- même
- éditeur
- ingénieur
- Les ingénieurs
- Entrer
- erreur
- Ether (ETH)
- évaluer
- exemple
- existe
- Découvrez
- Expliquer
- extrait
- Échoué
- échoue
- Fonctionnalité
- Déposez votre dernière attestation
- Prénom
- Abonnement
- le format
- de
- fonctions
- avenir
- généré
- génère
- obtention
- a aidé
- aider
- aide
- Haute
- de haute qualité
- Comment
- How To
- Cependant
- HTML
- HTTPS
- Des centaines
- identifier
- Active
- Mettre en oeuvre
- in
- inclut
- contribution
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- Emploi
- Emplois
- json
- clés / KEY :
- lac
- APPRENTISSAGE
- savant
- apprentissage
- charge
- chargement
- emplacement
- perdre
- click
- machine learning
- maintenir
- faire
- gérer
- gestion
- les gérer
- Manuel
- mesurer
- les mesures
- Menu
- message
- Métrique
- pourrait
- Villas Modernes
- Surveiller
- moniteurs
- PLUS
- plusieurs
- NAVIGUER
- Navigation
- nécessaire
- Besoins
- next
- nœud
- Notifications
- objets
- Offres Speciales
- ONE
- ouvert
- autrement
- pain
- paramètre
- partie
- passionné
- autorisation
- pipeline
- placement
- Platon
- Intelligence des données Platon
- PlatonDonnées
- plus
- politiques
- Post
- Préparer
- représentent
- empêcher
- Aperçu
- précédent
- primaire
- les process
- propriétés
- fournir
- fournit
- qualité
- Rapide
- raw
- Lire
- récent
- région
- exigent
- conditions
- Ressources
- résultat
- Résultats
- Avis
- Rôle
- rôle
- RANGÉE
- Règle
- Courir
- même
- Rechercher
- Section
- Série
- service
- Services
- set
- mise
- installation
- montrer
- Spectacles
- signer
- étapes
- tailles
- So
- Logiciels
- développement de logiciels
- sur mesure
- Solutions
- Identifier
- spécialiste
- spécialisation
- empiler
- Normes
- Commencer
- j'ai commencé
- Commencez
- étapes
- Étapes
- storage
- studio
- Combinaison
- synthétiquement
- Prenez
- Target
- Tâche
- équipe
- modèle
- La
- milliers
- Avec
- fois
- à
- aujourd'hui
- les outils
- Transformer
- transformer
- La confiance
- sous
- sous-jacent
- unique
- inutilisé
- utilisé
- cas d'utilisation
- utilisateurs
- d'habitude
- VALIDER
- validation
- Plus-value
- divers
- Voir
- visualisation
- attendez
- que
- qui
- sera
- sans
- vos contrats
- écrire
- écriture
- code écrit
- Votre
- zéphyrnet