Ce billet de blog est co-écrit par Guillermo Ribeiro, Sr. Data Scientist chez Cepsa.
L'apprentissage automatique (ML) a rapidement évolué, passant d'une tendance à la mode émergeant des environnements universitaires et des départements d'innovation à devenir un moyen clé de créer de la valeur dans toutes les entreprises de tous les secteurs. Cette transition des expériences en laboratoire à la résolution de problèmes réels dans des environnements de production va de pair avec MLOps, ou l'adaptation de DevOps au monde du ML.
MLOps aide à rationaliser et à automatiser le cycle de vie complet d'un modèle ML, en mettant l'accent sur les ensembles de données source, la reproductibilité des expériences, le code d'algorithme ML et la qualité du modèle.
At Cepsa, une société énergétique mondiale, nous utilisons le ML pour résoudre des problèmes complexes dans tous nos secteurs d'activité, de la maintenance prédictive des équipements industriels à la surveillance et à l'amélioration des processus pétrochimiques dans nos raffineries.
Dans cet article, nous expliquons comment nous avons construit notre architecture de référence pour MLOps à l'aide des services AWS clés suivants :
- Amazon Sage Maker, un service permettant de créer, d'entraîner et de déployer des modèles de ML
- Fonctions d'étape AWS, un service de flux de travail visuel low-code sans serveur utilisé pour orchestrer et automatiser les processus
- Amazon Event Bridge, un bus d'événements sans serveur
- AWS Lambda, un service de calcul sans serveur qui vous permet d'exécuter du code sans provisionner ni gérer de serveurs
Nous expliquons également comment nous avons appliqué cette architecture de référence pour démarrer de nouveaux projets ML dans notre entreprise.
Le défi
Au cours des 4 dernières années, plusieurs secteurs d'activité de Cepsa ont lancé des projets ML, mais bientôt certains problèmes et limitations ont commencé à survenir.
Nous n'avions pas d'architecture de référence pour ML, donc chaque projet a suivi un chemin de mise en œuvre différent, effectuant une formation et un déploiement de modèle ad hoc. Sans une méthode commune pour gérer le code et les paramètres du projet et sans un registre de modèles ML ou un système de gestion des versions, nous avons perdu la traçabilité entre les ensembles de données, le code et les modèles.
Nous avons également détecté une marge d'amélioration dans la façon dont nous exploitions les modèles en production, car nous ne surveillions pas les modèles déployés et n'avions donc pas les moyens de suivre les performances des modèles. En conséquence, nous avons généralement recyclé les modèles en fonction de calendriers, car nous n'avions pas les bonnes mesures pour prendre des décisions de recyclage éclairées.
La solution
Partant des défis que nous avons dû surmonter, nous avons conçu une solution générale qui visait à dissocier la préparation des données, la formation des modèles, l'inférence et la surveillance des modèles, et comportait un registre de modèles centralisé. De cette façon, nous avons simplifié la gestion des environnements sur plusieurs comptes AWS, tout en introduisant une traçabilité centralisée des modèles.
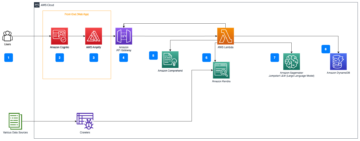
Nos data scientists et développeurs utilisent AWSCloud9 (un IDE cloud pour l'écriture, l'exécution et le débogage du code) pour la gestion des données et l'expérimentation ML et GitHub comme référentiel de code Git.
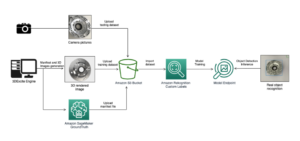
Un flux de travail de formation automatique utilise le code créé par l'équipe de science des données pour former des modèles sur SageMaker et pour enregistrer les modèles de sortie dans le registre des modèles.
Un workflow différent gère le déploiement du modèle : il obtient la référence du registre de modèles et crée un point de terminaison d'inférence à l'aide de Fonctionnalités d'hébergement de modèles SageMaker.
Nous avons implémenté à la fois des flux de travail de formation et de déploiement de modèles à l'aide de Step Functions, car il fournissait un cadre flexible qui permet la création de flux de travail spécifiques pour chaque projet et orchestre différents services et composants AWS de manière simple.
Modèle de consommation de données
Chez Cepsa, nous utilisons une série de lacs de données pour couvrir divers besoins commerciaux, et tous ces lacs de données partagent un modèle de consommation de données commun qui permet aux ingénieurs et aux scientifiques des données de trouver et de consommer plus facilement les données dont ils ont besoin.
Pour gérer facilement les coûts et les responsabilités, les environnements de lac de données sont complètement séparés des applications de production et de consommation de données, et déployés dans différents comptes AWS appartenant à une organisation AWS commune.
Les données utilisées pour former les modèles ML et les données utilisées comme entrée d'inférence pour les modèles formés sont mises à disposition à partir des différents lacs de données via un ensemble d'API bien définies utilisant Passerelle d'API Amazon, un service pour créer, publier, gérer, surveiller et sécuriser des API à grande échelle. Le backend de l'API utilise Amazone Athéna (un service de requête interactif pour analyser les données à l'aide de SQL standard) pour accéder aux données déjà stockées dans Service de stockage simple Amazon (Amazon S3) et catalogué dans le Colle AWS Catalogue de données.
Le diagramme suivant donne un aperçu général de l'architecture MLOps de Cepsa.

Formation de modèle
Le processus de formation est indépendant pour chaque modèle et géré par un Flux de travail standard des fonctions d'étape, ce qui nous donne la flexibilité de modéliser les processus en fonction des différentes exigences du projet. Nous avons défini un modèle de base que nous réutilisons sur la plupart des projets, en effectuant des ajustements mineurs si nécessaire. Par exemple, certains propriétaires de projets ont décidé d'ajouter des portes manuelles pour approuver les déploiements de nouveaux modèles de production, tandis que d'autres propriétaires de projets ont mis en place leurs propres mécanismes de détection d'erreurs et de nouvelles tentatives.
Nous effectuons également des transformations sur les jeux de données d'entrée utilisés pour la formation du modèle. Pour cela, nous utilisons des fonctions Lambda qui sont intégrées dans les workflows de formation. Dans certains scénarios où des transformations de données plus complexes sont nécessaires, nous exécutons notre code dans Service de conteneur élastique Amazon (Amazon ECS) sur AWSFargate, un moteur de calcul sans serveur pour exécuter des conteneurs.
Notre équipe de science des données utilise fréquemment des algorithmes personnalisés, nous profitons donc de la possibilité de utiliser des conteneurs personnalisés dans la formation du modèle SageMaker, reposant sur Registre des conteneurs élastiques Amazon (Amazon ECR), un registre de conteneurs entièrement géré qui facilite le stockage, la gestion, le partage et le déploiement d'images de conteneurs.
La plupart de nos projets ML sont basés sur la bibliothèque Scikit-learn, nous avons donc étendu la norme Conteneur SageMaker Scikit-learn pour inclure les variables d'environnement requises pour le projet, telles que les informations sur le référentiel Git et les options de déploiement.
Avec cette approche, nos scientifiques des données n'ont plus qu'à se concentrer sur le développement de l'algorithme d'entraînement et à spécifier les bibliothèques requises par le projet. Lorsqu'ils envoient des modifications de code au référentiel Git, notre système CI/CD (Jenkins hébergé sur AWS) construit le conteneur avec le code de formation et les bibliothèques. Ce conteneur est transmis à Amazon ECR et finalement transmis en tant que paramètre à l'appel de formation SageMaker.
Lorsque le processus de formation est terminé, le modèle résultant est stocké dans Amazon S3, une référence est ajoutée dans le registre des modèles et toutes les informations et métriques collectées sont enregistrées dans le catalogue d'expériences. Cela garantit une reproductibilité totale car le code de l'algorithme et les bibliothèques sont liés au modèle formé avec les données associées à l'expérience.
Le diagramme suivant illustre le processus de formation et de recyclage du modèle.

Déploiement de modèle
L'architecture est flexible et permet des déploiements automatiques et manuels des modèles formés. Le flux de travail du déployeur de modèles est automatiquement appelé au moyen d'un événement que la formation SageMaker publie dans EventBridge une fois la formation terminée, mais il peut également être appelé manuellement si nécessaire, en transmettant la bonne version de modèle à partir du registre de modèles. Pour plus d'informations sur l'appel automatique, voir Automatisation d'Amazon SageMaker avec Amazon EventBridge.
Le flux de travail du déployeur de modèles récupère les informations de modèle à partir du registre de modèles et utilise AWS CloudFormation, une infrastructure gérée en tant que service de code, pour déployer le modèle sur un point de terminaison d'inférence en temps réel ou effectuer une inférence par lots avec un jeu de données d'entrée stocké, selon les exigences du projet.
Chaque fois qu'un modèle est déployé avec succès dans n'importe quel environnement, le registre de modèles est mis à jour avec une nouvelle balise indiquant sur quels environnements le modèle est actuellement en cours d'exécution. Chaque fois qu'un point de terminaison est supprimé, sa balise est également supprimée du registre de modèles.
Le diagramme suivant montre le flux de travail pour le déploiement et l'inférence du modèle.

Expériences et registre de modèles
Le stockage de chaque version d'expérience et de modèle dans un emplacement unique et le fait de disposer d'un référentiel de code centralisé nous permettent de dissocier la formation et le déploiement de modèles et d'utiliser différents comptes AWS pour chaque projet et environnement.
Toutes les entrées d'expérience stockent l'ID de validation du code d'entraînement et d'inférence, nous avons donc une traçabilité complète de l'ensemble du processus d'expérimentation et sommes en mesure de comparer facilement différentes expériences. Cela nous évite d'effectuer un travail en double sur la phase d'exploration scientifique des algorithmes et des modèles, et nous permet de déployer nos modèles n'importe où, indépendamment du compte et de l'environnement où le modèle a été entraîné. Cela vaut également pour les modèles formés dans notre environnement d'expérimentation AWS Cloud9.
Dans l'ensemble, nous avons des pipelines de formation et de déploiement de modèles entièrement automatisés et avons la flexibilité d'effectuer des déploiements de modèles manuels rapides lorsque quelque chose ne fonctionne pas correctement ou lorsqu'une équipe a besoin d'un modèle déployé dans un environnement différent à des fins d'expérimentation.
Un cas d'utilisation détaillé : le projet YET Dragon
Le projet YET Dragon vise à améliorer les performances de production de l'usine pétrochimique de Cepsa à Shanghai. Pour atteindre cet objectif, nous avons étudié en profondeur le processus de production, en recherchant les étapes les moins efficaces. Notre objectif était d'augmenter l'efficacité de rendement des processus en maintenant la concentration des composants exactement en dessous d'un seuil.
Pour simuler ce processus, nous avons construit quatre modèles additifs généralisés ou GAM, des modèles linéaires dont la réponse dépend de fonctions lisses de variables prédictives, pour prédire les résultats de deux processus d'oxydation, un processus de concentration et le rendement susmentionné. Nous avons également construit un optimiseur pour traiter les résultats des quatre modèles GAM et trouver les meilleures optimisations pouvant être appliquées dans l'usine.
Bien que nos modèles soient formés avec des données historiques, l'usine peut parfois fonctionner dans des circonstances qui n'ont pas été enregistrées dans l'ensemble de données de formation ; nous nous attendons à ce que nos modèles de simulation ne fonctionnent pas bien dans ces scénarios, nous avons donc également construit deux modèles de détection d'anomalies à l'aide d'algorithmes Isolation Forests, qui déterminent à quelle distance se trouvent les points de données par rapport au reste des données pour détecter les anomalies. Ces modèles nous aident à détecter de telles situations pour désactiver les processus d'optimisation automatisés chaque fois que cela se produit.
Les processus chimiques industriels sont très variables et les modèles ML doivent être bien alignés avec le fonctionnement de l'usine, de sorte qu'un recyclage fréquent est nécessaire ainsi qu'une traçabilité des modèles déployés dans chaque situation. YET Dragon a été notre premier projet d'optimisation ML à proposer un registre de modèles, une reproductibilité complète des expériences et un processus de formation automatisé entièrement géré.
Désormais, le pipeline complet qui met un modèle en production (transformation des données, formation du modèle, suivi des expériences, registre des modèles et déploiement du modèle) est indépendant pour chaque modèle ML. Cela nous permet d'améliorer les modèles de manière itérative (par exemple en ajoutant de nouvelles variables ou en testant de nouveaux algorithmes) et de connecter les étapes de formation et de déploiement à différents déclencheurs.
Les résultats et améliorations futures
Nous sommes actuellement en mesure de former, déployer et suivre automatiquement les six modèles ML utilisés dans le projet YET Dragon, et nous avons déjà déployé plus de 30 versions pour chacun des modèles de production. Cette architecture MLOps a été étendue à des centaines de modèles ML dans d'autres projets de l'entreprise.
Nous prévoyons de continuer à lancer de nouveaux projets YET basés sur cette architecture, qui a réduit la durée moyenne des projets de 25 %, grâce à la réduction du temps de démarrage et à l'automatisation des pipelines ML. Nous avons également estimé des économies d'environ 300,000 XNUMX € par an grâce à l'augmentation du rendement et de la concentration qui découle directement du projet YET Dragon.
L'évolution à court terme de cette architecture MLOps est vers la surveillance des modèles et les tests automatisés. Nous prévoyons de tester automatiquement l'efficacité du modèle par rapport aux modèles précédemment déployés avant qu'un nouveau modèle ne soit déployé. Nous travaillons également à la mise en œuvre de la surveillance des modèles et de la surveillance de la dérive des données d'inférence avec Moniteur de modèle Amazon SageMaker, afin d'automatiser le réapprentissage du modèle.
Conclusion
Les entreprises sont confrontées au défi de mettre leurs projets ML en production de manière automatisée et efficace. L'automatisation du cycle de vie complet du modèle ML permet de réduire la durée des projets et garantit une meilleure qualité des modèles et des déploiements plus rapides et plus fréquents en production.
En développant une architecture MLOps standardisée qui a été adoptée par différentes entreprises de l'entreprise, nous, chez Cepsa, avons pu accélérer le démarrage des projets ML et améliorer la qualité du modèle ML, fournissant un cadre fiable et automatisé sur lequel nos équipes de science des données peuvent innover plus rapidement. .
Pour plus d'informations sur les MLOps sur SageMaker, visitez Amazon SageMaker pour MLOps et découvrez d'autres cas d'utilisation client dans le Blog sur l'apprentissage automatique AWS.
À propos des auteurs
 Guillermo Ribeiro Jimenez est un scientifique principal des données au Cepsa avec un doctorat. en physique nucléaire. Il a 6 ans d'expérience dans des projets de science des données, principalement dans l'industrie des télécommunications et de l'énergie. Il dirige actuellement des équipes de scientifiques des données au sein du département de transformation numérique de Cepsa, en se concentrant sur la mise à l'échelle et la productisation de projets d'apprentissage automatique.
Guillermo Ribeiro Jimenez est un scientifique principal des données au Cepsa avec un doctorat. en physique nucléaire. Il a 6 ans d'expérience dans des projets de science des données, principalement dans l'industrie des télécommunications et de l'énergie. Il dirige actuellement des équipes de scientifiques des données au sein du département de transformation numérique de Cepsa, en se concentrant sur la mise à l'échelle et la productisation de projets d'apprentissage automatique.
 Guillermo Menendez Corral est architecte de solutions chez AWS Energy and Utilities. Il a plus de 15 ans d'expérience dans la conception et la création d'applications logicielles et fournit actuellement des conseils architecturaux aux clients AWS du secteur de l'énergie, en mettant l'accent sur l'analyse et l'apprentissage automatique.
Guillermo Menendez Corral est architecte de solutions chez AWS Energy and Utilities. Il a plus de 15 ans d'expérience dans la conception et la création d'applications logicielles et fournit actuellement des conseils architecturaux aux clients AWS du secteur de l'énergie, en mettant l'accent sur l'analyse et l'apprentissage automatique.
- Coinsmart. Le meilleur échange Bitcoin et Crypto d'Europe.
- Platoblockchain. Intelligence métaverse Web3. Connaissance amplifiée. ACCÈS LIBRE.
- CryptoHawk. Radar Altcoins. Essai gratuit.
- Source : https://aws.amazon.com/blogs/machine-learning/how-cepsa-used-amazon-sagemaker-and-aws-step-functions-to-industrialize-their-ml-projects-and-operate- leurs-modèles-à-échelle/
- "
- 000
- 100
- 15 ans
- a
- capacité
- Qui sommes-nous
- accès
- Compte
- atteindre
- à travers
- Ad
- ajoutée
- Avantage
- à opposer à
- algorithme
- algorithmes
- Tous
- permet
- déjà
- Amazon
- parmi
- analytique
- il analyse
- de n'importe où
- api
- Apis
- applications
- appliqué
- une approche
- approuver
- architectural
- architecture
- autour
- associé
- automatiser
- Automatisation
- Automatique
- automatiquement
- automatiser
- Automation
- disponibles
- AWS
- car
- devenir
- before
- va
- ci-dessous
- LES MEILLEURS
- Blog
- construire
- Développement
- construit
- la performance des entreprises
- entreprises
- maisons
- cas
- centralisée
- certaines
- challenge
- globaux
- la chimie
- le cloud
- code
- commettre
- Commun
- Société
- complet
- complètement
- complexe
- composant
- composants électriques
- calcul
- concentration
- NOUS CONTACTER
- consommer
- consommateur
- consommation
- Contenant
- Conteneurs
- Costs
- pourriez
- couverture
- engendrent
- crée des
- création
- Lecture
- Customiser
- des clients
- Clients
- données
- science des données
- Data Scientist
- décidé
- décisions
- Selon
- dépend
- déployer
- déployé
- déploiement
- déploiements
- un
- conception
- détaillé
- détecté
- Détection
- Déterminer
- mobiles
- développement
- différent
- numérique
- Transformation numérique
- discuter
- Dragon
- chacun
- même
- efficace
- efficace
- économies émergentes.
- permet
- Endpoint
- énergie
- Moteur
- Les ingénieurs
- Environment
- l'équipements
- estimé
- événement
- évolution
- exactement
- exemple
- attendre
- Découvrez
- expérience
- exploration
- RAPIDE
- plus rapide
- Fonctionnalité
- en vedette
- finalement
- Prénom
- Flexibilité
- flexible
- Focus
- Abonnement
- Framework
- de
- plein
- fonctions
- avenir
- Portes
- Général
- Git
- GitHub
- Global
- objectif
- manipuler
- ayant
- vous aider
- aide
- très
- historique
- détient
- organisé
- hébergement
- Comment
- HTTPS
- Des centaines
- satellite
- la mise en oeuvre
- mis en œuvre
- améliorer
- amélioration
- l'amélioration de
- Dans d'autres
- comprendre
- Améliore
- indépendant
- indépendamment
- industriel
- industrie
- d'information
- Actualités
- Infrastructure
- Innovation
- contribution
- des services
- Interactif
- Découvrez le tout nouveau
- seul
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- XNUMX éléments à
- en gardant
- ACTIVITES
- lancement
- conduisant
- apprentissage
- Bibliothèque
- lignes
- emplacement
- recherchez-
- click
- machine learning
- LES PLANTES
- maintenir
- facile
- a prendre une
- FAIT DU
- gérer
- gérés
- les gérer
- manière
- Manuel
- manuellement
- veux dire
- Métrique
- ML
- modèle
- numériques jumeaux (digital twin models)
- Surveiller
- Stack monitoring
- PLUS
- (en fait, presque toutes)
- plusieurs
- Besoins
- fonctionner
- opération
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Options
- de commander
- organisation
- Autre
- propre
- propriétaires
- En passant
- performant
- effectuer
- phase
- Physique
- des notes bonus
- prévoir
- d'ouvrabilité
- processus
- les process
- producteur
- Vidéo
- Projet
- projets
- à condition de
- fournit
- aportando
- publier
- but
- des fins
- Poussé
- qualité
- en temps réel
- réduire
- vous inscrire
- inscrit
- fiable
- dépôt
- conditions
- Exigences
- réponse
- responsabilités
- REST
- résultant
- Résultats
- Courir
- pour le running
- Escaliers intérieurs
- mise à l'échelle
- Sciences
- Scientifique
- scientifiques
- sécurisé
- Série
- Sans serveur
- service
- Services
- set
- shanghai
- Partager
- assistance technique à court terme
- étapes
- simulation
- unique
- situation
- SIX
- So
- sur mesure
- Solutions
- quelques
- quelque chose
- groupe de neurones
- vitesse
- étapes
- Standard
- j'ai commencé
- storage
- Boutique
- rationaliser
- Avec succès
- combustion propre
- Target
- équipe
- équipes
- Telco
- tester
- Essais
- Les
- La Source
- donc
- complètement
- порог
- Avec
- fiable
- fois
- vers
- Traçabilité
- suivre
- Tracking
- Formation
- De La Carrosserie
- transformations
- transition
- sous
- us
- utilisé
- d'habitude
- les services publics
- Plus-value
- version
- bien défini
- tout en
- sans
- Activités principales
- workflows
- de travail
- world
- écriture
- an
- années
- Rendement