Ce billet est co-écrit avec Hernan Figueroa, Sr. Manager Data Science chez Marubeni Power International.
Marubeni Power International Inc. (MPII) possède et investit dans des plateformes commerciales d'énergie dans les Amériques. Un secteur vertical important pour MPII est la gestion des actifs pour les énergies renouvelables et les actifs de stockage d'énergie, qui sont essentiels pour réduire l'intensité carbone de notre infrastructure électrique. Travailler avec des actifs d'énergie renouvelable nécessite des solutions numériques prédictives et réactives, car la production d'énergie renouvelable et les conditions du marché de l'électricité évoluent en permanence. MPII utilise un moteur d'optimisation des offres d'apprentissage automatique (ML) pour éclairer les processus de prise de décision en amont dans la gestion et la négociation des actifs énergétiques. Cette solution aide les analystes de marché à concevoir et à exécuter des stratégies d'enchères basées sur les données optimisées pour la rentabilité des actifs énergétiques.
Dans cet article, vous apprendrez comment Marubeni optimise les décisions du marché en utilisant le large éventail de services d'analyse et de ML d'AWS, pour créer une solution d'optimisation des enchères puissante et rentable.
Vue d'ensemble de la solution
Les marchés de l'électricité permettent d'échanger de l'électricité et de l'énergie afin d'équilibrer l'offre et la demande d'électricité dans le réseau électrique et de couvrir les différents besoins de fiabilité du réseau électrique. Les acteurs du marché, tels que les opérateurs d'actifs MPII, proposent constamment des quantités d'électricité et d'énergie sur ces marchés de l'électricité pour tirer des bénéfices de leurs actifs énergétiques. Un acteur du marché peut soumettre des offres à différents marchés simultanément pour augmenter la rentabilité d'un actif, mais il doit tenir compte des limites de puissance des actifs et des vitesses de réponse ainsi que d'autres contraintes opérationnelles des actifs et de l'interopérabilité de ces marchés.
La solution de moteur d'optimisation des enchères de MPII utilise des modèles ML pour générer des enchères optimales pour la participation à différents marchés. Les offres les plus courantes sont les offres d'énergie journalières, qui doivent être soumises 1 jour avant le jour de négociation réel, et les offres d'énergie en temps réel, qui doivent être soumises 75 minutes avant l'heure de négociation. La solution orchestre les enchères dynamiques et le fonctionnement d'un actif énergétique et nécessite l'utilisation des capacités d'optimisation et de prédiction disponibles dans ses modèles ML.
La solution Power Bid Optimization comprend plusieurs composants qui jouent des rôles spécifiques. Passons en revue les composants impliqués et leur fonction commerciale respective.
Collecte et ingestion de données
La couche de collecte et d'ingestion de données se connecte à toutes les sources de données en amont et charge les données dans le lac de données. Les appels d'offres sur le marché de l'électricité nécessitent au moins quatre types d'entrées :
- Prévisions de la demande d'électricité
- Prévisions météorologiques
- Historique des prix du marché
- Prévisions des prix de l'électricité
Ces sources de données sont accessibles exclusivement via des API. Par conséquent, les composants d'ingestion doivent pouvoir gérer l'authentification, l'approvisionnement des données en mode pull, le prétraitement des données et le stockage des données. Étant donné que les données sont récupérées toutes les heures, un mécanisme est également nécessaire pour orchestrer et planifier les tâches d'ingestion.
Préparation des données
Comme dans la plupart des cas d'utilisation de ML, la préparation des données joue un rôle essentiel. Les données proviennent de sources disparates dans un certain nombre de formats. Avant qu'il ne soit prêt à être consommé pour l'entraînement du modèle ML, il doit passer par certaines des étapes suivantes :
- Consolidez les ensembles de données horaires en fonction de l'heure d'arrivée. Un jeu de données complet doit inclure toutes les sources.
- Améliorez la qualité des données en utilisant des techniques telles que la standardisation, la normalisation ou l'interpolation.
À la fin de ce processus, les données conservées sont mises en scène et mises à disposition pour une consommation ultérieure.
Formation et déploiement de modèles
La prochaine étape consiste à former et à déployer un modèle capable de prédire les offres de marché optimales pour l'achat et la vente d'énergie. Pour minimiser le risque de sous-performance, Marubeni a utilisé la technique de modélisation d'ensemble. La modélisation d'ensemble consiste à combiner plusieurs modèles ML pour améliorer les performances de prédiction. Marubeni regroupe les sorties des modèles de prédiction externes et internes avec une moyenne pondérée pour tirer parti de la force de tous les modèles. Les modèles internes de Marubeni sont basés sur des architectures de mémoire longue à court terme (LSTM), qui sont bien documentées et faciles à mettre en œuvre et à personnaliser dans TensorFlow. Amazon Sage Maker prend en charge les déploiements TensorFlow et de nombreux autres environnements ML. Le modèle externe est propriétaire et sa description ne peut pas être incluse dans cet article.
Dans le cas d'utilisation de Marubeni, les modèles d'enchères effectuent une optimisation numérique pour maximiser les revenus en utilisant une version modifiée des fonctions objectives utilisées dans la publication. Opportunités de stockage d'énergie dans CAISO.
SageMaker permet à Marubeni d'exécuter des algorithmes de ML et d'optimisation numérique dans un environnement unique. Ceci est essentiel, car lors de la formation du modèle interne, la sortie de l'optimisation numérique est utilisée dans le cadre de la fonction de perte de prédiction. Pour plus d'informations sur la manière d'aborder les cas d'utilisation d'optimisation numérique, reportez-vous à Résolution des problèmes d'optimisation numérique tels que la planification, le routage et l'allocation avec Amazon SageMaker Processing.
Nous déployons ensuite ces modèles via des points de terminaison d'inférence. Comme de nouvelles données sont ingérées périodiquement, les modèles doivent être recyclés car ils deviennent obsolètes avec le temps. La section architecture plus loin dans cet article fournit plus de détails sur le cycle de vie des modèles.
Génération de données d'enchères puissantes
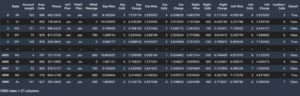
Sur une base horaire, la solution prédit les quantités et les prix optimaux auxquels l'électricité devrait être offerte sur le marché, également appelée offres. Les quantités sont mesurées en MW et les prix sont mesurés en $/MW. Des offres sont générées pour de multiples combinaisons de conditions de marché prévues et perçues. Le tableau suivant montre un exemple de la finale courbe d'enchères sortie pour l'heure de fonctionnement 17 à un nœud commercial illustratif près du bureau de Marubeni à Los Angeles.
| Date | heure | Marché | Localisation | MW | Prix |
| 11/7/2022 | 17 | RT Énergie | LCIENEGA_6_N001 | 0 | $0 |
| 11/7/2022 | 17 | RT Énergie | LCIENEGA_6_N001 | 1.65 | $80.79 |
| 11/7/2022 | 17 | RT Énergie | LCIENEGA_6_N001 | 5.15 | $105.34 |
| 11/7/2022 | 17 | RT Énergie | LCIENEGA_6_N001 | 8 | $230.15 |
Cet exemple représente notre volonté d'offrir 1.65 MW d'électricité si le prix de l'électricité est d'au moins 80.79 $, 5.15 MW si le prix de l'électricité est d'au moins 105.34 $ et 8 MW si le prix de l'électricité est d'au moins 230.15 $.
Les opérateurs de système indépendants (ISO) surveillent les marchés de l'électricité aux États-Unis et sont chargés d'attribuer et de rejeter les offres afin de maintenir la fiabilité du réseau électrique de la manière la plus économique. California Independent System Operator (CAISO) gère les marchés de l'électricité en Californie et publie les résultats du marché toutes les heures avant la prochaine fenêtre d'appel d'offres. En recoupant les conditions actuelles du marché avec leur équivalent sur la courbe, les analystes sont en mesure d'en déduire un revenu optimal. La solution Power Bid Optimization met à jour les futures offres à l'aide de nouvelles informations de marché entrantes et de nouvelles sorties prédictives de modèles
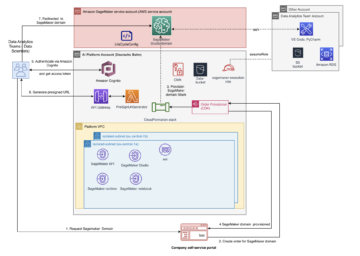
Présentation de l'architecture AWS
L'architecture de la solution illustrée dans la figure suivante implémente toutes les couches présentées précédemment. Il utilise les services AWS suivants dans le cadre de la solution :
- Service de stockage simple Amazon (Amazon S3) pour stocker les données suivantes :
- Données sur les prix, la météo et les prévisions de charge provenant de diverses sources.
- Données consolidées et augmentées prêtes à être utilisées pour la formation de modèles.
- Courbes d'enchères de sortie actualisées toutes les heures.
- Amazon Sage Maker pour former, tester et déployer des modèles afin de proposer des offres optimisées via des points de terminaison d'inférence.
- Fonctions d'étape AWS pour orchestrer à la fois les pipelines de données et de ML. Nous utilisons deux machines d'état :
- Une machine d'état pour orchestrer la collecte de données et s'assurer que toutes les sources ont été ingérées.
- Une machine d'état pour orchestrer le pipeline ML ainsi que le workflow de génération d'enchères optimisé.
- AWS Lambda pour implémenter les fonctionnalités d'ingestion, de prétraitement et de post-traitement :
- Trois fonctions pour ingérer les flux de données d'entrée, avec une fonction par source.
- Une fonction pour consolider et préparer les données pour la formation.
- Une fonction qui génère la prévision de prix en appelant le point de terminaison du modèle déployé dans SageMaker.
- Amazone Athéna pour fournir aux développeurs et aux analystes commerciaux un accès SQL aux données générées à des fins d'analyse et de dépannage.
- Amazon Event Bridge pour déclencher l'ingestion de données et le pipeline ML selon un calendrier et en réponse à des événements.
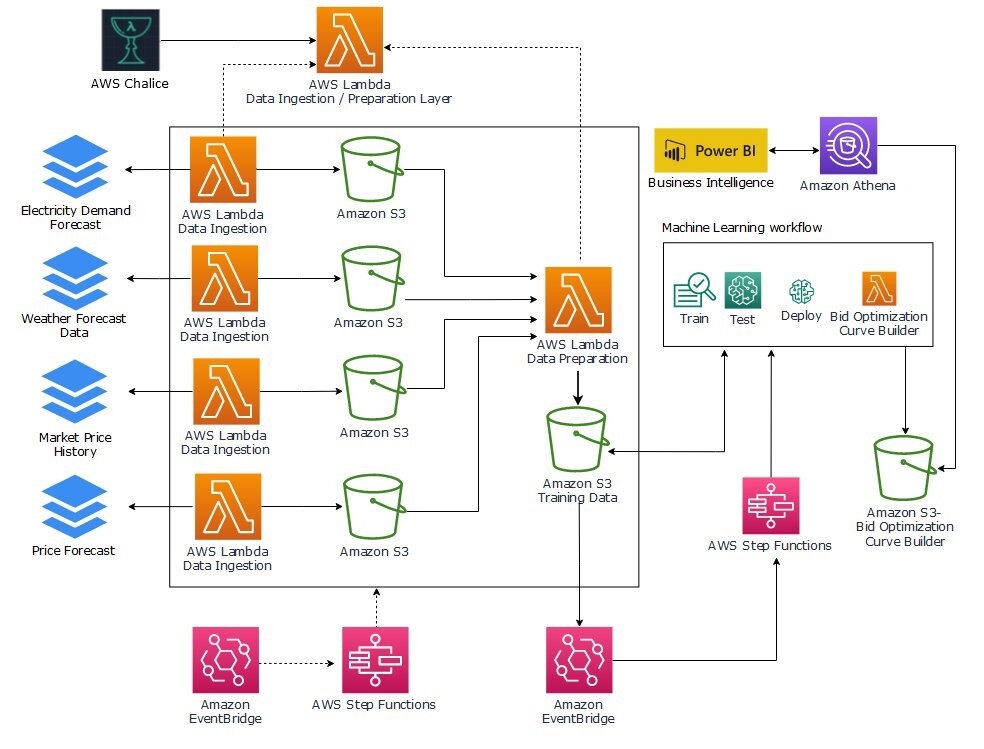
Dans les sections suivantes, nous abordons le flux de travail plus en détail.
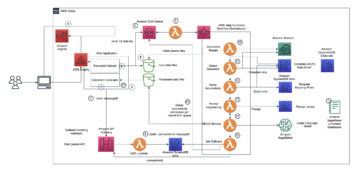
Collecte et préparation des données
Toutes les heures, la machine d'état Step Functions de préparation des données est invoquée. Il appelle chacune des fonctions Lambda d'ingestion de données en parallèle et attend que les quatre se terminent. Les fonctions de collecte de données appellent leur API source respective et récupèrent les données de l'heure écoulée. Chaque fonction stocke ensuite les données reçues dans leur compartiment S3 respectif.
Ces fonctions partagent une ligne de base d'implémentation commune qui fournit des blocs de construction pour la manipulation de données standard telle que la normalisation ou l'indexation. Pour ce faire, nous utilisons des couches Lambda et Calice AWS, comme décrit dans Utilisation des couches AWS Lambda avec AWS Chalice. Cela garantit que tous les développeurs utilisent les mêmes bibliothèques de base pour créer de nouvelles logiques de préparation des données et accélère la mise en œuvre.
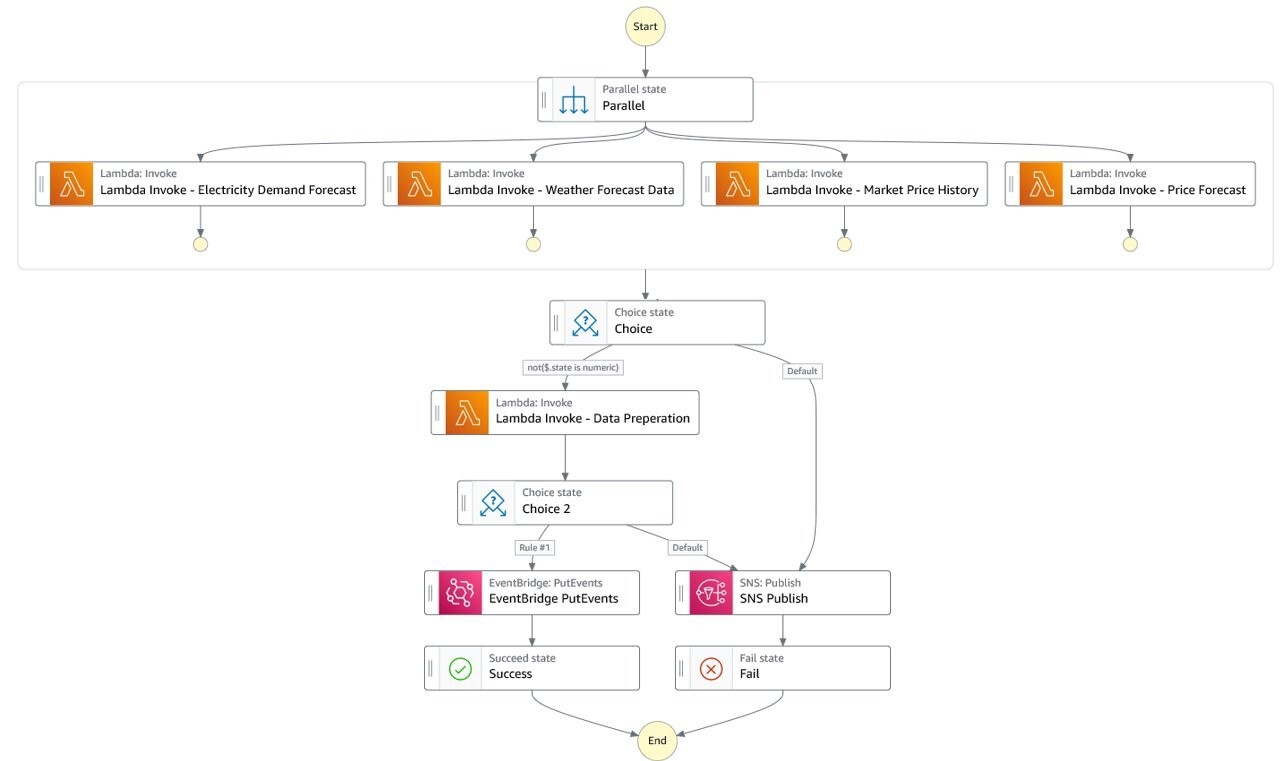
Une fois que les quatre sources ont été ingérées et stockées, la machine d'état déclenche la fonction Lambda de préparation des données. Les données sur le prix de l'électricité, la météo et les prévisions de charge sont reçues dans des fichiers JSON et délimités par des caractères. Chaque partie d'enregistrement de chaque fichier porte un horodatage qui est utilisé pour consolider les flux de données en un seul ensemble de données couvrant une période d'une heure.
Cette construction fournit un flux de travail entièrement piloté par les événements. La préparation des données d'entraînement est lancée dès que toutes les données attendues sont ingérées.
Pipeline ML
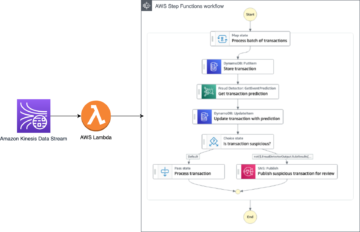
Après la préparation des données, les nouveaux ensembles de données sont stockés dans Amazon S3. Une règle EventBridge déclenche le pipeline ML via une machine d'état Step Functions. La machine d'état pilote deux processus :
- Vérifier si le modèle de génération de courbe d'enchères est actuel
- Déclenchez automatiquement le réentraînement du modèle lorsque les performances se dégradent ou que les modèles sont plus anciens qu'un certain nombre de jours
Si l'âge du modèle actuellement déployé est plus ancien que le dernier ensemble de données d'un certain seuil, disons 7 jours, la machine d'état Step Functions lance le pipeline SageMaker qui entraîne, teste et déploie un nouveau point de terminaison d'inférence. Si les modèles sont toujours à jour, le workflow ignore le pipeline ML et passe à l'étape de génération d'enchères. Quel que soit l'état du modèle, une nouvelle courbe d'offre est générée lors de la livraison d'un nouveau jeu de données horaire. Le diagramme suivant illustre ce flux de travail. Par défaut, le StartPipelineExecution l'action est asynchrone. Nous pouvons faire en sorte que la machine d'état attende la fin du pipeline avant d'invoquer l'étape de génération des offres en utilisant le 'Attente de rappel'option.
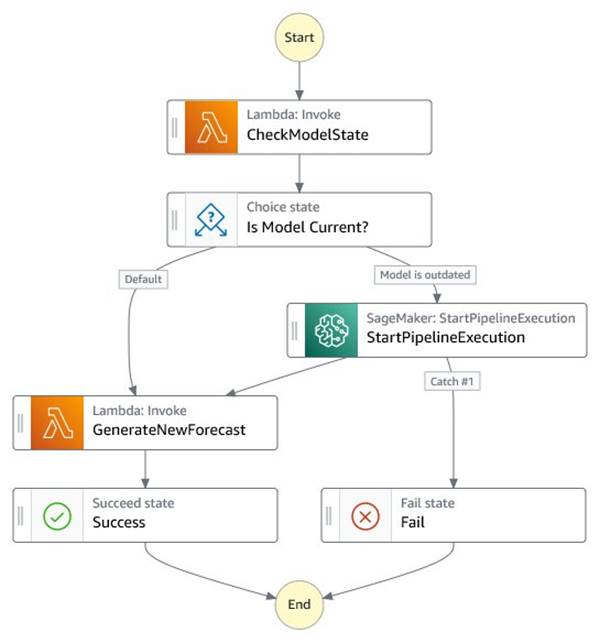

Pour réduire les coûts et les délais de mise sur le marché lors de la création d'une solution pilote, Marubeni a utilisé Inférence sans serveur Amazon SageMaker. Cela garantit que l'infrastructure sous-jacente utilisée pour la formation et le déploiement n'entraîne des frais qu'en cas de besoin. Cela facilite également le processus de construction du pipeline, car les développeurs n'ont plus besoin de gérer l'infrastructure. Il s'agit d'une excellente option pour les charges de travail qui ont des périodes d'inactivité entre les pics de trafic. Au fur et à mesure que la solution mûrit et passe en production, Marubeni révisera sa conception et adoptera une configuration plus adaptée à une utilisation prévisible et régulière.
Génération d'offres et requête de données
La fonction Lambda de génération d'offres appelle périodiquement le point de terminaison d'inférence pour générer des prédictions horaires et stocke la sortie dans Amazon S3.
Les développeurs et les analystes commerciaux peuvent ensuite explorer les données à l'aide d'Athena et de Microsoft Power BI pour la visualisation. Les données peuvent également être mises à disposition via une API pour les applications métier en aval. Dans la phase pilote, les opérateurs consultent visuellement la courbe d'offre pour soutenir leurs activités de transaction d'électricité sur les marchés. Cependant, Marubeni envisage d'automatiser ce processus à l'avenir, et cette solution fournit les bases nécessaires pour le faire.
Conclusion
Cette solution a permis à Marubeni d'automatiser entièrement ses pipelines de traitement et d'ingestion de données, ainsi que de réduire le temps de déploiement de ses modèles prédictifs et d'optimisation de quelques heures à quelques minutes. Les courbes d'enchères sont désormais générées automatiquement et mises à jour à mesure que les conditions du marché changent. Ils ont également réalisé une réduction des coûts de 80 % lors du passage d'un point de terminaison d'inférence provisionné à un point de terminaison sans serveur.
La solution de prévision de MPII est l'une des récentes initiatives de transformation numérique lancées par Marubeni Corporation dans le secteur de l'énergie. MPII prévoit de créer des solutions numériques supplémentaires pour prendre en charge les nouvelles plates-formes commerciales énergétiques. MPII peut compter sur les services AWS pour soutenir sa stratégie de transformation numérique dans de nombreux cas d'utilisation.
"Nous pouvons nous concentrer sur la gestion de la chaîne de valeur pour les nouvelles plateformes commerciales, sachant qu'AWS gère l'infrastructure numérique sous-jacente de nos solutions. »
– Hernan Figueroa, Sr. Manager Data Science chez Marubeni Power International.
Pour plus d'informations sur la manière dont AWS aide les organisations énergétiques dans leurs initiatives de transformation numérique et de développement durable, consultez AWS Énergie.
![]() Marubeni Power International est une filiale de Marubeni Corporation. Marubeni Corporation est un important conglomérat japonais de commerce et d'investissement. La mission de Marubeni Power International est de développer de nouvelles plateformes commerciales, d'évaluer les nouvelles tendances et technologies énergétiques et de gérer le portefeuille énergétique de Marubeni dans les Amériques. Si vous souhaitez en savoir plus sur Marubeni Power, consultez https://www.marubeni-power.com/.
Marubeni Power International est une filiale de Marubeni Corporation. Marubeni Corporation est un important conglomérat japonais de commerce et d'investissement. La mission de Marubeni Power International est de développer de nouvelles plateformes commerciales, d'évaluer les nouvelles tendances et technologies énergétiques et de gérer le portefeuille énergétique de Marubeni dans les Amériques. Si vous souhaitez en savoir plus sur Marubeni Power, consultez https://www.marubeni-power.com/.
À propos des auteurs
 Hernán Figueroa dirige les initiatives de transformation numérique chez Marubeni Power International. Son équipe applique la science des données et les technologies numériques pour soutenir les stratégies de croissance de Marubeni Power. Avant de rejoindre Marubeni, Hernan était Data Scientist à l'Université de Columbia. Il est titulaire d'un doctorat. en génie électrique et un BS en génie informatique.
Hernán Figueroa dirige les initiatives de transformation numérique chez Marubeni Power International. Son équipe applique la science des données et les technologies numériques pour soutenir les stratégies de croissance de Marubeni Power. Avant de rejoindre Marubeni, Hernan était Data Scientist à l'Université de Columbia. Il est titulaire d'un doctorat. en génie électrique et un BS en génie informatique.
 Lino Brescia est un responsable de compte principal basé à New York. Il a plus de 25 ans d'expérience dans la technologie et a rejoint AWS en 2018. Il gère des entreprises clientes mondiales alors qu'elles transforment leur entreprise avec les services cloud AWS et effectuent des migrations à grande échelle.
Lino Brescia est un responsable de compte principal basé à New York. Il a plus de 25 ans d'expérience dans la technologie et a rejoint AWS en 2018. Il gère des entreprises clientes mondiales alors qu'elles transforment leur entreprise avec les services cloud AWS et effectuent des migrations à grande échelle.
 Narcisse Zekpa est un architecte de solutions senior basé à Boston. Il aide les clients du nord-est des États-Unis à accélérer la transformation de leur entreprise grâce à des solutions innovantes et évolutives sur le cloud AWS. Lorsque Narcisse ne construit pas, il aime passer du temps avec sa famille, voyager, cuisiner, jouer au basket et courir.
Narcisse Zekpa est un architecte de solutions senior basé à Boston. Il aide les clients du nord-est des États-Unis à accélérer la transformation de leur entreprise grâce à des solutions innovantes et évolutives sur le cloud AWS. Lorsque Narcisse ne construit pas, il aime passer du temps avec sa famille, voyager, cuisiner, jouer au basket et courir.
 Pedram Jahangiri est un architecte de solutions d'entreprise avec AWS, avec un doctorat en génie électrique. Il a plus de 10 ans d'expérience dans l'industrie de l'énergie et de l'informatique. Pedram possède de nombreuses années d'expérience pratique dans tous les aspects de l'analyse avancée pour la création de solutions quantitatives et à grande échelle pour les entreprises en tirant parti des technologies cloud.
Pedram Jahangiri est un architecte de solutions d'entreprise avec AWS, avec un doctorat en génie électrique. Il a plus de 10 ans d'expérience dans l'industrie de l'énergie et de l'informatique. Pedram possède de nombreuses années d'expérience pratique dans tous les aspects de l'analyse avancée pour la création de solutions quantitatives et à grande échelle pour les entreprises en tirant parti des technologies cloud.
 Sarah Childer est un gestionnaire de compte basé à Washington DC. Elle est une ancienne enseignante en sciences devenue passionnée par le cloud et axée sur l'accompagnement des clients tout au long de leur parcours vers le cloud. Sarah aime travailler aux côtés d'une équipe motivée qui encourage les idées diversifiées pour équiper au mieux les clients avec les solutions les plus innovantes et les plus complètes.
Sarah Childer est un gestionnaire de compte basé à Washington DC. Elle est une ancienne enseignante en sciences devenue passionnée par le cloud et axée sur l'accompagnement des clients tout au long de leur parcours vers le cloud. Sarah aime travailler aux côtés d'une équipe motivée qui encourage les idées diversifiées pour équiper au mieux les clients avec les solutions les plus innovantes et les plus complètes.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/how-marubeni-is-optimizing-market-decisions-using-aws-machine-learning-and-analytics/
- :est
- $UP
- 1
- 10
- 100
- 2018
- 7
- 8
- a
- Capable
- Description
- accélérer
- accès
- accédé
- Compte
- atteindre
- à travers
- Action
- activités
- Supplémentaire
- propos
- adopter
- avancer
- Avancée
- Avantage
- algorithmes
- Tous
- allocation
- aux côtés de
- Amazon
- Amazon Sage Maker
- Amériques
- montant
- selon une analyse de l’Université de Princeton
- Analystes
- analytique
- ainsi que
- Angeles
- api
- Apis
- applications
- architecture
- SONT
- arrivée
- AS
- aspects
- atout
- la gestion d'actifs
- Outils
- At
- augmentée
- Authentification
- automatiser
- automatiquement
- automatiser
- disponibles
- moyen
- AWS
- AWS Lambda
- Apprentissage automatique AWS
- Balance
- base
- basé
- Baseline
- base
- Basketball
- BE
- car
- devenez
- before
- va
- LES MEILLEURS
- jusqu'à XNUMX fois
- offre
- Blocs
- boston
- vaste
- construire
- Développement
- la performance des entreprises
- applications commerciales
- Transformation de l'entreprise
- Achat
- by
- Californie
- Appelez-nous
- appelé
- appel
- Appels
- CAN
- ne peut pas
- capacités
- capable
- carbone
- maisons
- cas
- certaines
- chaîne
- Change
- en changeant
- caractère
- des charges
- vérifier
- le cloud
- services de cloud computing
- collection
- Columbia
- комбинации
- combinant
- Commun
- complet
- composants électriques
- complet
- ordinateur
- Ingénierie informatique
- conditions
- configuration
- conglomérat
- connecte
- Considérer
- considérant
- consolider
- constamment
- contraintes
- construire
- consommées
- consommation
- continuellement
- cuisine
- SOCIÉTÉ
- Prix
- réduction des coûts
- rentable
- couverture
- couvrant
- critique
- références croisées
- organisée
- Courant
- Lecture
- courbe
- Clients
- personnaliser
- données
- Lac de données
- Préparation des données
- informatique
- science des données
- Data Scientist
- stockage de données
- data-driven
- ensembles de données
- Date
- journée
- dc
- La prise de décision
- décisions
- Réglage par défaut
- page de livraison.
- Demande
- déployer
- déployé
- déployer
- déploiement
- déploiements
- déploie
- décrit
- la description
- Conception
- détail
- détails
- développer
- mobiles
- différent
- numérique
- Transformation numérique
- discuter
- disparate
- diversifié
- pendant
- Dynamic
- chacun
- Plus tôt
- plus facilement
- Easy
- Électrique
- ingénierie électrique
- électricité
- permettre
- activé
- permet
- encourage
- Endpoint
- énergie
- Moteur
- ENGINEERING
- assurer
- Assure
- Entreprise
- clients entreprise
- entreprises
- passionné
- Environment
- environnements
- Équivalent
- Ether (ETH)
- événements
- Chaque
- exemple
- uniquement au
- exécutif
- attendu
- Découvrez
- explorez
- externe
- famille
- Récupéré
- Figure
- Déposez votre dernière attestation
- Fichiers
- finale
- Focus
- concentré
- Abonnement
- Pour
- Prévision
- Ancien
- Fondations
- CADRE
- à la main
- de
- d’étiquettes électroniques entièrement
- fonction
- fonctions
- plus
- avenir
- générer
- généré
- génère
- génération
- Global
- Go
- l'
- Grille
- Croissance
- hands-on
- Vous avez
- aider
- aide
- détient
- HEURES
- Comment
- How To
- Cependant
- HTML
- HTTPS
- et idées cadeaux
- Idle
- Mettre en oeuvre
- la mise en oeuvre
- met en oeuvre
- important
- in
- comprendre
- inclus
- inclut
- Nouveau
- Améliore
- indépendant
- industrie
- d'information
- Infrastructure
- les initiatives
- technologie innovante
- contribution
- interne
- International
- Interopérabilité
- un investissement
- Investit
- invoque
- impliqué
- IT
- Industrie informatique
- SES
- Japonais
- Emplois
- rejoint
- joindre
- chemin
- jpg
- json
- Kicks
- Savoir
- connaissance
- lac
- grande échelle
- Nouveautés
- lancement
- couche
- poules pondeuses
- Conduit
- APPRENTISSAGE
- apprentissage
- en tirant parti
- bibliothèques
- vos produits
- comme
- limites
- charge
- charges
- Location
- plus long
- les
- Los Angeles
- perte
- click
- machine learning
- Les machines
- LES PLANTES
- maintenir
- majeur
- FAIT DU
- gérer
- gestion
- manager
- gère
- les gérer
- Manipulation
- de nombreuses
- Marché
- les conditions du marché
- Marchés
- mûrit
- Maximisez
- mécanisme
- Mémoire
- Microsoft
- minimiser
- minutes
- Mission
- ML
- Mode
- modèle
- modélisation statistique
- numériques jumeaux (digital twin models)
- modifié
- PLUS
- (en fait, presque toutes)
- motivés
- se déplace
- plusieurs
- Près
- nécessaire
- Besoin
- nécessaire
- Besoins
- Nouveauté
- next
- nœud
- nombre
- NYC
- objectif
- obtenir
- of
- présenté
- Bureaux
- on
- ONE
- exploite
- d'exploitation
- opération
- opérationnel
- opérateur
- opérateurs
- optimaux
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- optimisé
- l'optimisation
- Option
- organisations
- Autre
- sortie
- Possède
- Parallèle
- partie
- participants
- participation
- passé
- perçu
- effectuer
- performant
- périodes
- phase
- pilote
- pipeline
- plans
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- jouer
- portefeuille
- Post
- power
- Power BI
- Alimentation
- Prévisible
- prédit
- prévoir
- prédiction
- Prédictions
- Prévoit
- Préparer
- présenté
- prix
- prévision de prix
- Tarifs
- Directeur
- Avant
- d'ouvrabilité
- processus
- les process
- traitement
- Vidéo
- de la rentabilité
- bénéfices
- propriétaire
- fournir
- fournit
- Publication
- Publie
- qualité
- quantitatif
- solutions
- en temps réel
- réalisé
- reçu
- récent
- record
- réduire
- Indépendamment
- fiabilité
- compter
- Renouvelable
- des énergies renouvelables
- représente
- conditions
- a besoin
- ceux
- réponse
- responsables
- sensible
- Résultats
- recyclage
- de revenus
- Avis
- Analyse
- robuste
- Rôle
- rôle
- Règle
- Courir
- pour le running
- s
- sagemaker
- même
- évolutive
- calendrier
- Sciences
- Scientifique
- Section
- les sections
- secteur
- Disponible
- besoin
- Sans serveur
- Services
- set
- Partager
- assistance technique à court terme
- devrait
- Spectacles
- étapes
- simultanément
- unique
- So
- sur mesure
- Solutions
- quelques
- disponible
- Identifier
- Sources
- Approvisionnement
- groupe de neurones
- vitesses
- Dépenses
- SQL
- Standard
- Région
- stable
- étapes
- Étapes
- Encore
- storage
- Boutique
- stockée
- STORES
- les stratégies
- de Marketing
- force
- soumettre
- soumis
- filiale
- tel
- la quantité
- Offre et la demande
- Support
- Appuyer
- Les soutiens
- Durabilité
- combustion propre
- table
- Prenez
- équipe
- techniques
- Les technologies
- Technologie
- tensorflow
- tester
- tests
- qui
- La
- El futuro
- L'État
- leur
- donc
- Ces
- Avec
- fiable
- horodatage
- à
- Commerce
- circulation
- Train
- Formation
- les trains
- transaction
- Transformer
- De La Carrosserie
- Stratégie de transformation
- transitions
- Voyages
- Trends
- déclencher
- Tourné
- types
- nous
- sous-jacent
- université
- Actualités
- Données en amont
- us
- Utilisation
- utilisé
- cas d'utilisation
- Plus-value
- divers
- version
- via
- visualisation
- attendez
- Washington
- Washington DC
- Façon..
- Météo
- WELL
- qui
- sera
- Bonne volonté
- avec
- dans les
- workflow
- de travail
- pourra
- années
- zéphyrnet