Dans cet article, vous découvrirez différentes méthodes pour convertir un PDF en Google Sheets.
Vous apprendrez également comment les nanonets peuvent automatiser l'ensemble du flux de travail de conversion de PDF en Google Sheets en ligne.
Avant de voir comment convertir un PDF en Google Sheets, voyons pourquoi il est important de le faire.
Pourquoi convertir des PDF en Google Sheets ?
Selon ce Blogue de Google post de la page officielle du blog Google, plus de 5 millions d'entreprises utilisent leur solution G Suite. Dans le même temps, un grand nombre d'entreprises ont également commencé à utiliser les intégrations de Google Sheets pour automatiser les tâches.
Considérons un cas d'utilisation typique. Votre équipe Comptabilité fournisseurs reçoit une facture, au format PDF standard. Quelqu'un parcourt manuellement la facture et saisit les informations requises dans un document Google Sheets avant de le transmettre à la section Finance. La section Finance paie votre fournisseur et effectue une écriture dans le grand livre de l'entreprise.
En plus d'être un processus de longue haleine, cela est sujet aux erreurs et il serait beaucoup plus logique de simplement l'automatiser.
Maintenant que la nécessité de convertir des PDF en un formulaire de feuille Google est claire, examinons comment les documents PDF sont structurés et quels sont les défis liés à leur analyse.
Envie de convertir PDF fichiers à Google Sheets ? Check-out Nanonets ' faim Convertisseur PDF en CSV. Ou découvrez comment automatisez l'intégralité de votre flux de travail PDF vers Google Sheets avec Nanonets.
Défis liés à l'analyse d'un document PDF
Le format de document portable était un format de fichier initialement développé par Adobe et a ensuite été publié en tant que norme ouverte. Il a depuis été largement adopté car il est indépendant du système d'exploitation sous-jacent.
Alors, pourquoi est-il si difficile d'analyser un PDF et de convertir son contenu dans un autre format ? Les images suivantes parlent mille mots et enfonceront le clou.
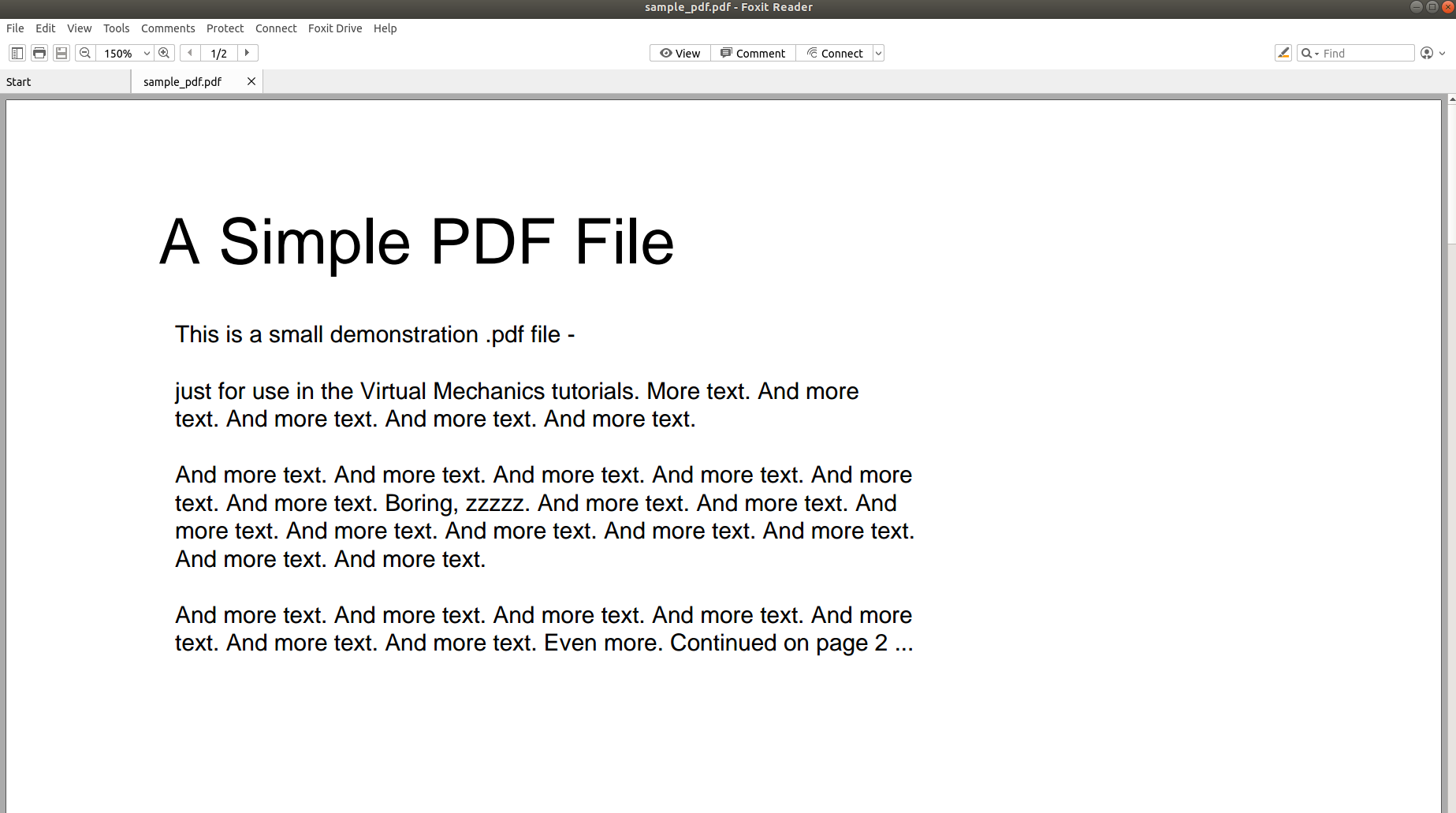
L'image ci-dessus montre la capture d'écran d'un document PDF ouvert à l'aide d'un lecteur PDF. Essayons d'ouvrir le même document PDF à l'aide d'un éditeur de texte.
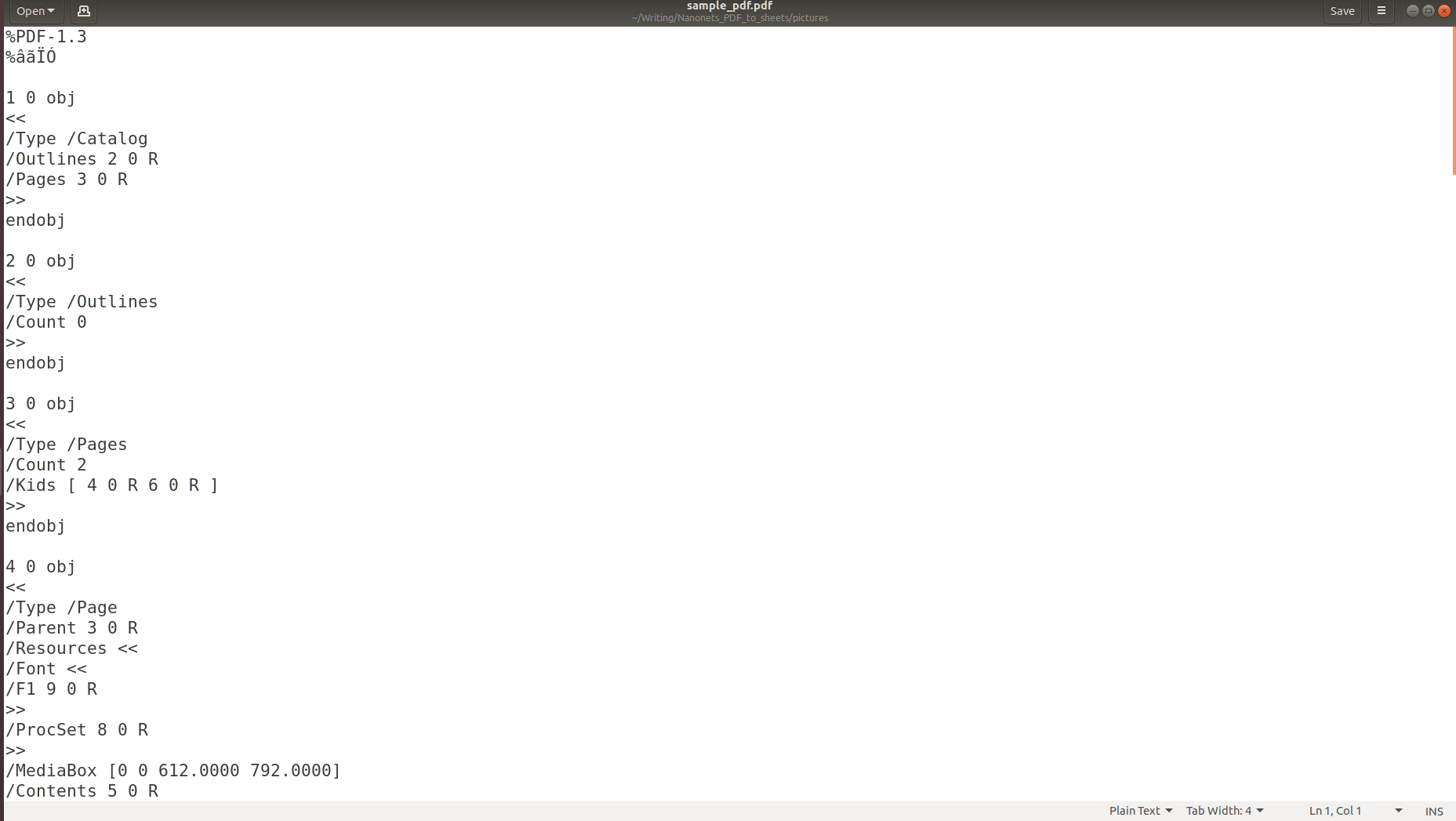
Les images ci-dessus montrent clairement que lorsque des informations sont stockées dans un PDF, sa structure d'origine est complètement perdue. En effet, le format PDF consiste simplement en des instructions sur la façon d'imprimer/dessiner une séquence de caractères sur une page.
Si vous pensez que l'extraction de texte est difficile, extraire les données présentes dans les tableaux est encore plus difficile en raison des formats tabulaires très variés qui sont utilisés.
J'espère que vous êtes convaincu que la conversion d'un document PDF en un formulaire Google Sheets n'est pas une promenade de santé. La section suivante traite de l'approche adoptée par la plupart des analyseurs PDF modernes pour reconnaître/analyser les informations d'un document PDF.
L'approche moderne de l'analyse des documents PDF
La plupart des analyseurs PDF modernes utilisent le flux décrit ci-dessous pour analyser des données non structurées à partir de documents PDF.
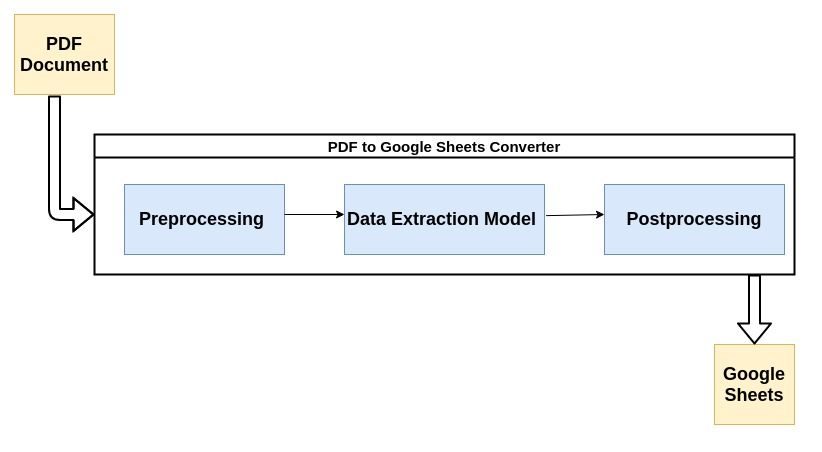
Examinons brièvement chaque étape du processus :
1. Prétraitement ou nettoyage des données :
Plus votre PDF est beau, plus il sera facile pour votre modèle d'apprentissage automatique d'extraire ou capturer des données à partir de cela. Par exemple, si le document PDF a été numérisé, il contiendra forcément des artefacts de numérisation qui pourraient affecter les performances du convertisseur.
La suppression du bruit à l'aide de filtres appropriés, la binarisation, la correction de l'asymétrie, etc. sont quelques-unes des étapes de prétraitement les plus courantes. Le post suivant sur les Nanonets Poste de Tesseract Nanonets contient quelques excellents exemples de la façon dont les documents peuvent être prétraités avant Reconnaissance optique de caractères(OCR) est exécuté sur eux.
C'est là que la plus grande partie de la magie se produit. L'extraction de données est généralement effectuée par un modèle d'apprentissage automatique (ML). La plupart des modèles de ML utilisés pour l'extraction de données à partir de fichiers PDF contiennent une combinaison d'outils de reconnaissance optique de caractères, d'outils de reconnaissance de texte et de formes, etc.
Pour les besoins de cet article, nous pouvons traiter le modèle comme une boîte noire qui prend votre document PDF en entrée et recrache les informations analysées. De plus, étant donné qu'il utilise le ML en son cœur, il peut être recyclé avec des données personnalisées pour s'adapter au cas d'utilisation de votre entreprise.
3. Post-traitement :
Dans cette étape, les données extraites sont converties au format requis tel que CSV, XML, JSON, etc. En outre, des règles supplémentaires définies par l'utilisateur sont ajoutées aux prédictions faites par l'IA. Cela pourrait inclure des règles de formatage de la sortie, des contraintes supplémentaires sur les informations extraites, etc.
La section suivante examine certaines métriques que nous pourrions utiliser pour mesurer les performances d'un analyseur PDF.
Envie de convertir PDF fichiers à Google Sheets ? Check-out Nanonets ' faim Convertisseur PDF en CSV. Découvrez comment automatiser l'intégralité de votre flux de travail PDF vers Google Sheets avec Nanonets.

Métriques pour mesurer les performances d'un convertisseur PDF
Étant donné que la plupart des convertisseurs PDF seront utilisés pour le traitement des factures ou des tâches connexes, la précision et la vitesse d'extraction des tableaux d'un document PDF sont un facteur critique pour juger des performances du convertisseur PDF.
2. Capacité multilingue :
La plupart des grandes entreprises sont tenues de recevoir des factures dans un certain nombre de langues différentes. L'analyseur PDF doit soit prendre en charge l'analyse multilingue prête à l'emploi, soit fournir une option permettant aux utilisateurs d'entraîner le modèle à l'aide de données personnalisées.
3. Intégration avec le logiciel de comptabilité :
Le convertisseur PDF idéal devrait être un module plug and play qui peut facilement être ajouté à votre flux de travail de document. Il devrait prendre en charge l'intégration avec les logiciels de comptabilité populaires tels que QuickBooks, Xero, Wave, etc.
4. Facile et intuitif :
L'outil sera très probablement utilisé par des utilisateurs non techniques. Il serait avantageux qu'il puisse être utilisé avec un minimum de connaissances techniques.
Diverses méthodes de conversion de PDF en Google Sheets
1.Utilisation de Google Docs pour convertir un PDF en Google Sheets
Google Drive a une capacité intégrée pour reconnaître les tableaux et le texte dans des documents PDF simples. Vous devez simplement :
-
Téléchargez votre fichier PDF sur Google Drive
-
Cliquez sur "Ouvrir avec Google Docs"
-
Copiez les données souhaitées et collez-les dans Google Sheets
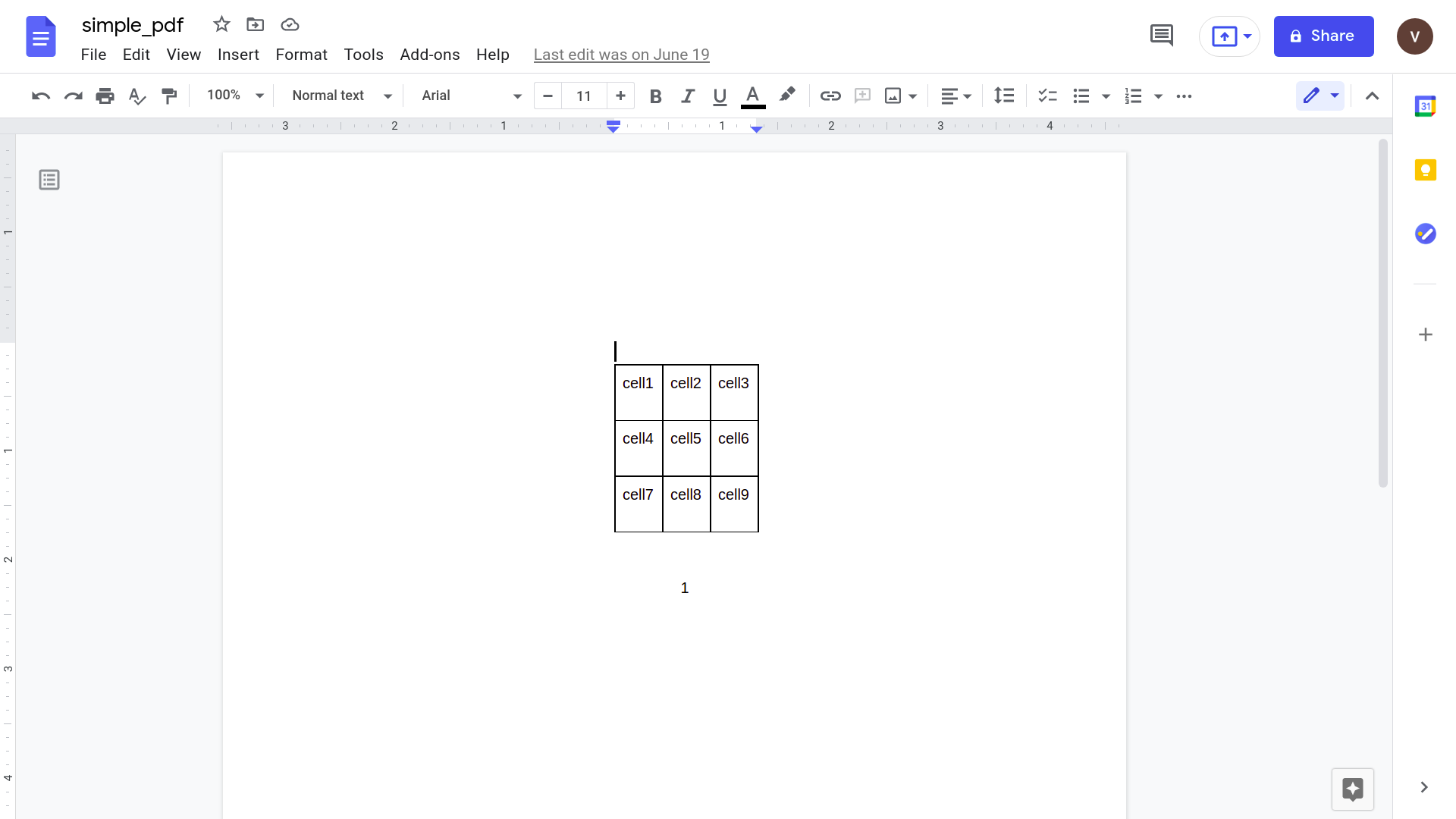
Bien que cela semble bien fonctionner, essayons quelque chose d'un peu plus pratique. Considérez cette simple facture.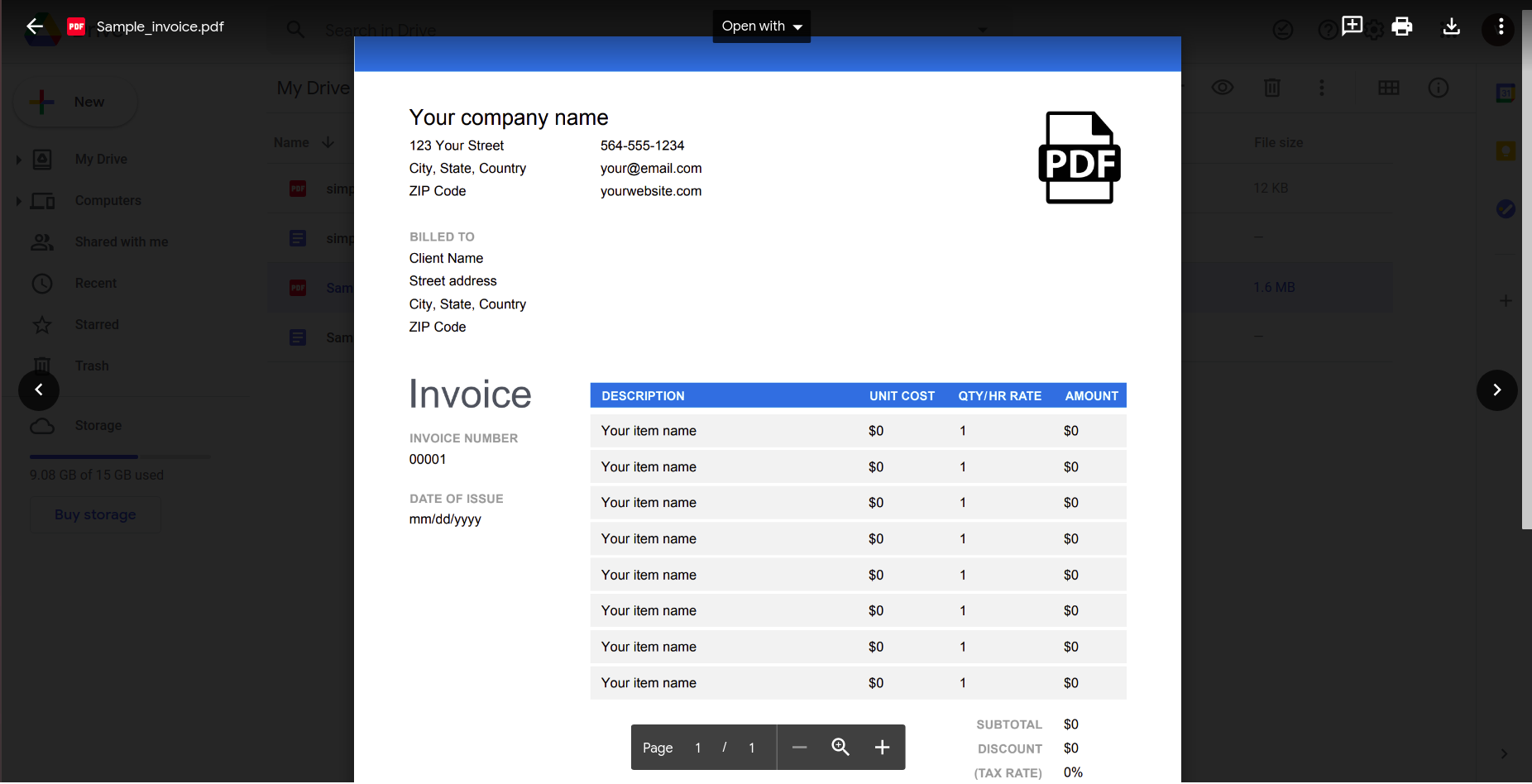
L'ouvrir à l'aide de l'application Google docs donne le résultat suivant.
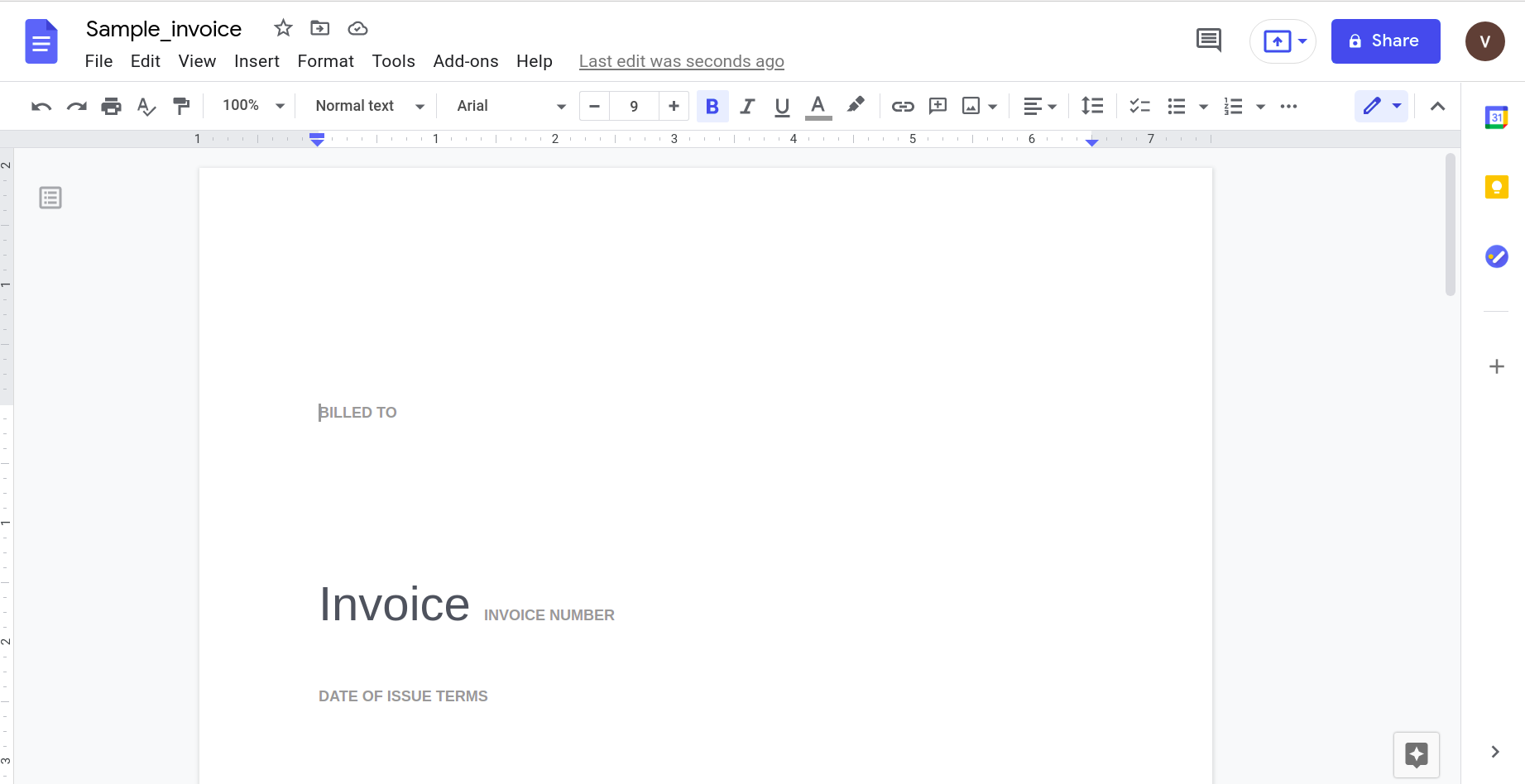
De toute évidence, à mesure que la complexité du document augmente, nous devons nous appuyer sur des outils plus sophistiqués pour reconnaître les données.
2. Utilisation des outils en ligne :
Plusieurs outils en ligne tels que l'extracteur de tableaux PDF, Online2PDF, etc. s'intègrent directement à Google Drive et offrent une capacité prête à l'emploi pour convertir des documents PDF en Google Sheets.
Cependant, lorsque ces outils ont été testés à l'aide de l'exemple de facture PDF illustré ci-dessus, les tableaux n'ont pas été détectés dans la majorité des cas.
Envie de convertir PDF fichiers à Google Sheets ? Check-out Nanonets ' faim Convertisseur PDF en CSV. Découvrez comment automatiser l'intégralité de votre flux de travail PDF vers Google Sheets avec Nanonets, comme illustré ci-dessous.
Automatisation du processus de conversion PDF vers Google Sheets
Nous pouvons automatiser complètement le processus d'analyse du PDF et d'extraction des données dans un formulaire Google Sheets en utilisant les outils suivants.
1. Utilisation des Webhooks :
Les Webhooks sont des requêtes HTTP personnalisées. Ils sont généralement déclenchés sur un événement, c'est-à-dire lorsqu'un événement se produit, l'application envoie des informations à une URL prédéfinie.
Comment pouvez-vous l'utiliser pour automatiser votre flux de travail ? Considérons le cas d'utilisation typique du traitement des factures. Vous recevez un certain nombre de factures de vos fournisseurs et les alimentez dans votre convertisseur PDF vers Google Sheets qui réside sur le cloud. Comment savoir quand le modèle a fini de traiter les documents ?
Au lieu de vérifier manuellement si la conversion est terminée, vous pouvez simplement utiliser un webhook qui vous avertit lorsque les données du PDF ont été extraites dans un document Google Sheets.
2. Utilisation des API
API signifie Application Programming Interface. À l'aide des appels d'API appropriés, la conversion de documents PDF en feuilles de calcul Google peut s'avérer aussi simple que d'écrire les lignes de code suivantes :
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Si votre entreprise a déjà configuré l'intégration avec les Webhooks, vous recevrez une notification lorsque vos documents PDF auront été convertis avec succès. Vous pouvez ensuite télécharger le formulaire Google Sheets à l'aide de l'API ci-dessous.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF vers Google Sheets avec Nanonets
L'analyseur PDF Nanonets rend l'analyse et la conversion faciles et précises. L'analyseur PDF a été utilisé pour analyser un exemple de facture. Cette section démontre la facilité d'utilisation et la précision de l'outil. Plutôt que de dire à quel point c'est génial, les images suivantes illustrent bien ce point.
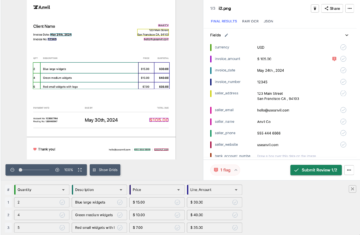
L'image ci-dessous est une capture d'écran de l'exemple de facture qui a été transmis à l'analyseur PDF Nanonets.
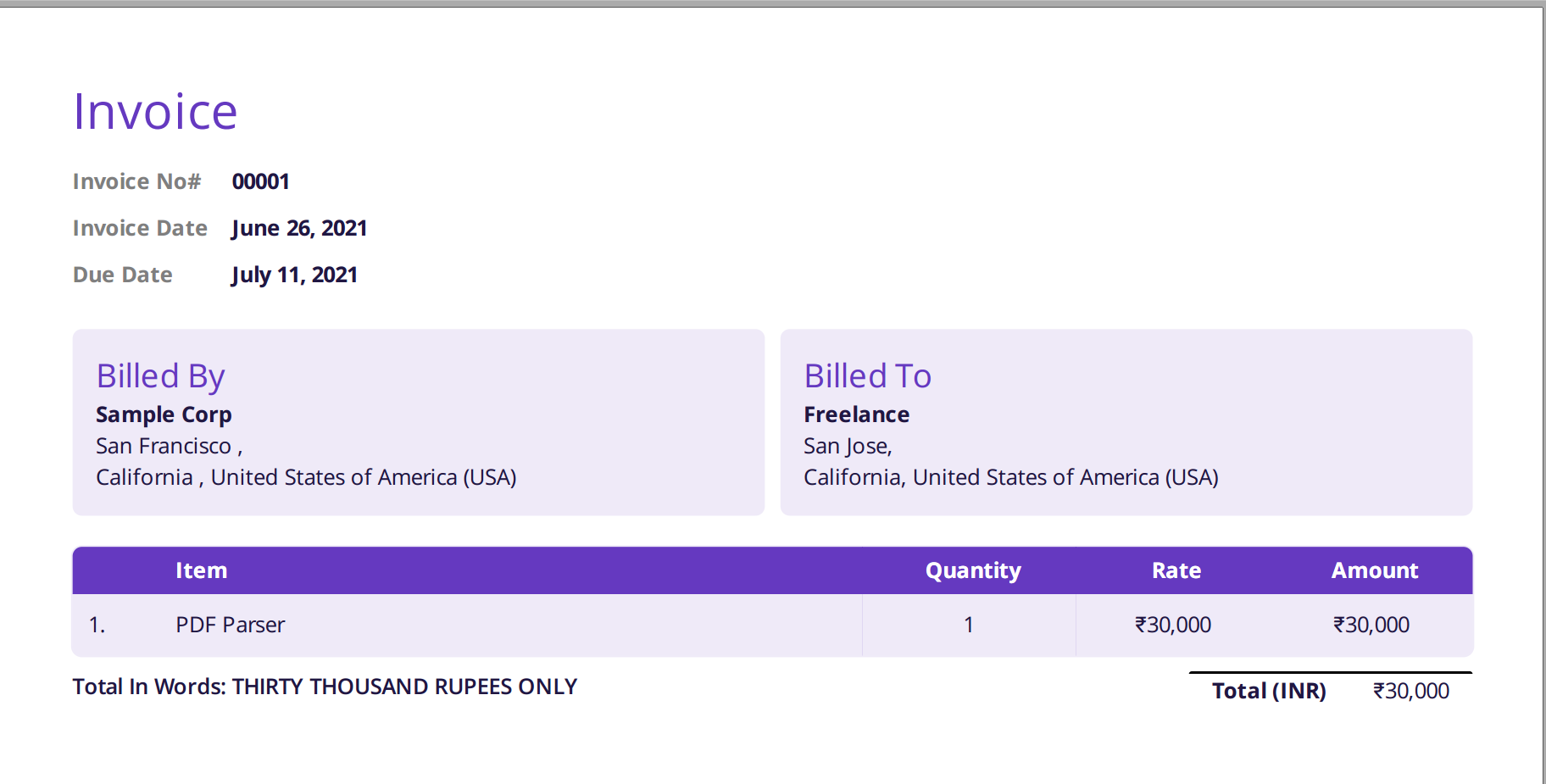
Accédez simplement au site Web de Nanonets et téléchargez la facture. La conversion ne prend que quelques secondes, après quoi les données analysées peuvent être téléchargées dans une variété de formats tels que CSV, XLSX etc. (consultez Nanonets' Convertisseur PDF en CSV)
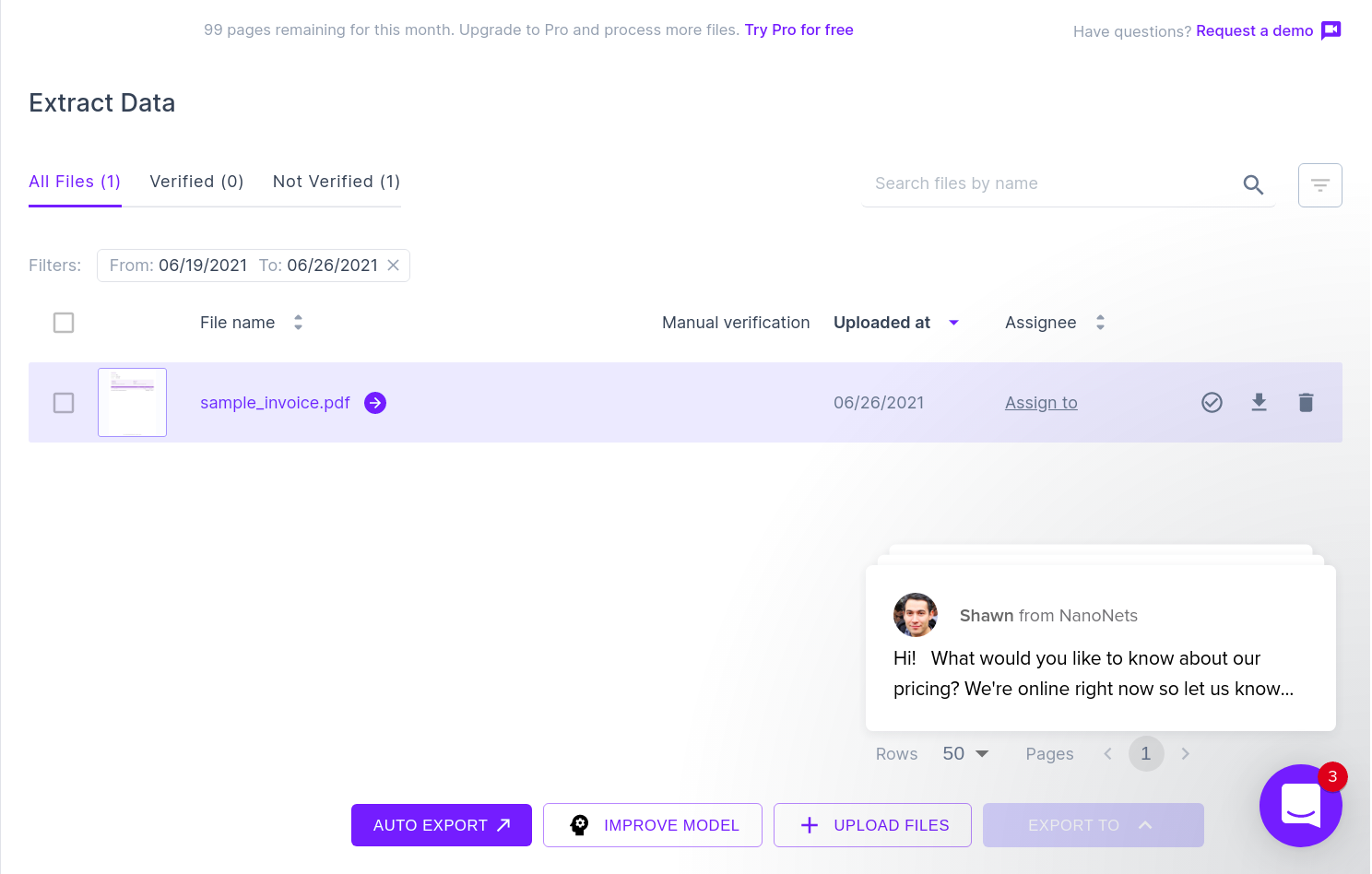
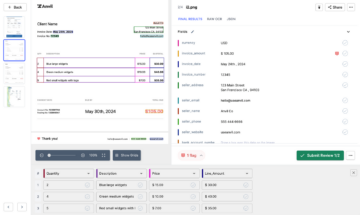
L'image suivante montre une capture d'écran du fichier CSV qui contient les données analysées du document PDF.

Enfin, pour convertir le fichier CSV en un formulaire de feuilles google, il suffit de télécharger le fichier XLSX/CSV dans votre lecteur google. Cette étape peut être automatisée en utilisant les API Google Drive.
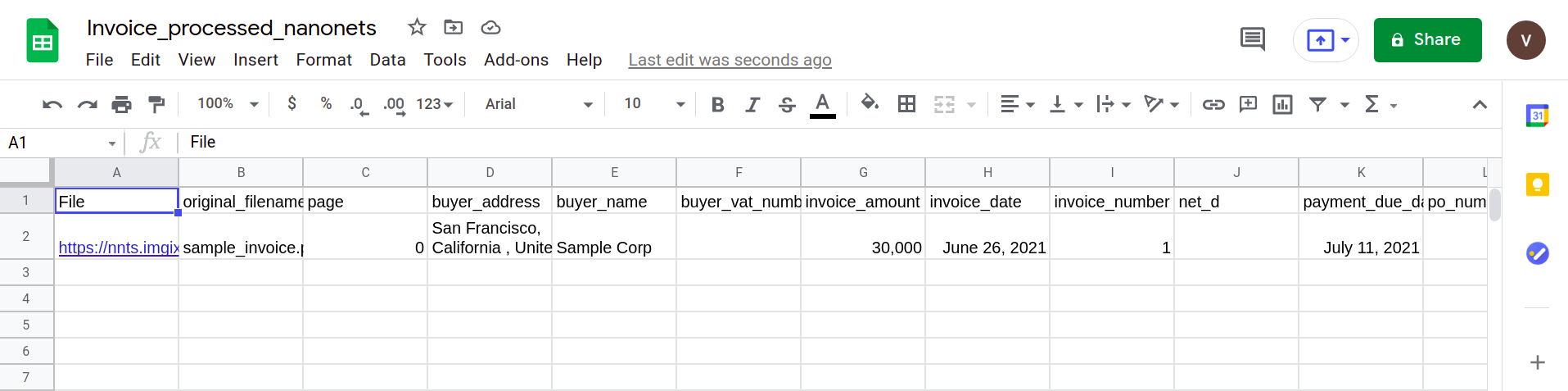
La section suivante montre comment créer un pipeline simple en utilisant l'analyseur PDF Nanonets.
Vous voulez extraire des informations de documents PDF et les convertir/ajouter dans un document Google Sheets ? Découvrez les nanonets™ pour automatiser l'exportation de n'importe quelle information de n'importe quel document PDF vers Google Sheets !
Création d'un pipeline simple
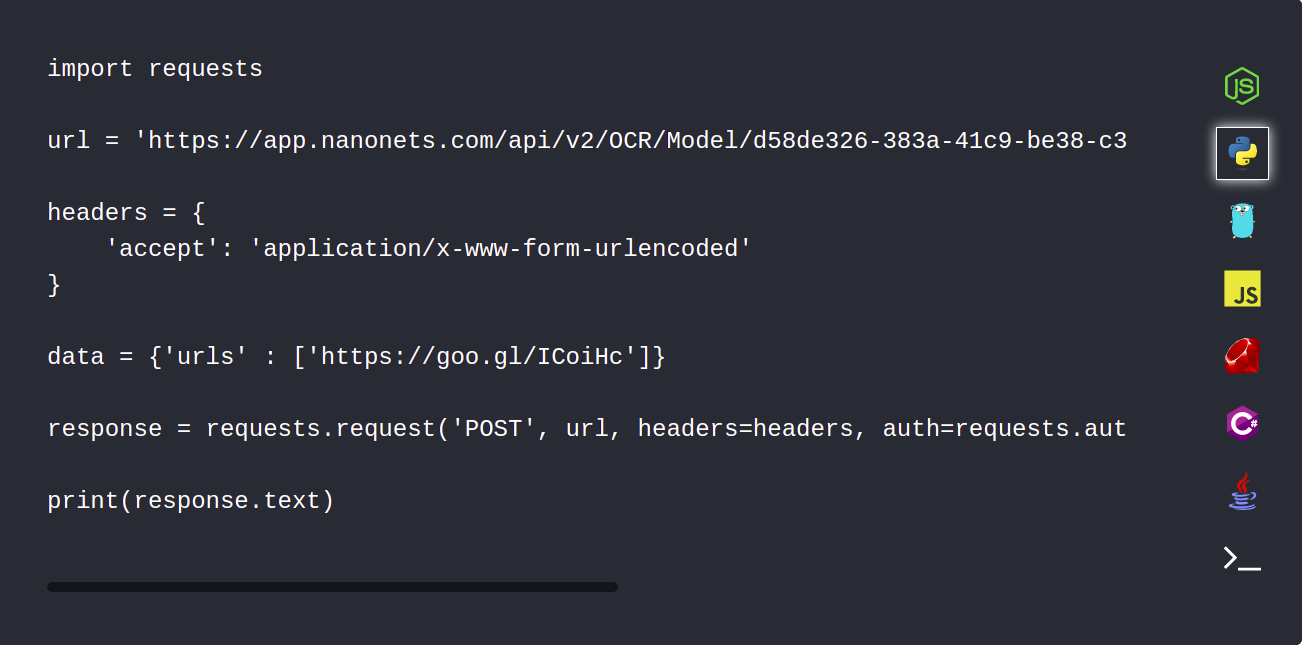
1. Téléchargez automatiquement vos documents PDF à l'aide de l'API Nanonets
L'API Nanonets vous permet de télécharger automatiquement vos documents qui doivent être analysés. L'extrait de code suivant montre comment cela peut être fait en utilisant python.
2. Utilisez l'intégration des webhooks pour recevoir une notification à la fin de l'analyse
Les Webhooks peuvent être configurés pour vous avertir automatiquement une fois que les documents ont été analysés.
3. Vérifiez et importez dans Google Sheets
Téléchargez et examinez les fichiers CSV pour vous assurer que tout est en ordre et téléchargez les données dans Google Sheets à l'aide de l'API Google Drive.
Le bord des nanonets
Voici quelques fonctionnalités de l'analyseur PDF Nanonets qui en font l'outil idéal pour votre entreprise.
1. Intégrations externes :
Le modèle nanonets peut facilement être intégré à MySql, Quickbooks, Salesforce, etc. Cela signifie que votre flux de travail actuel reste inchangé et que le convertisseur nanonets peut simplement être branché en tant que module supplémentaire.
2. Haute précision et temps de traitement réduits :
L'outil d'analyse de PDF Nanonets a une précision de plus de 95%+, ce qui est beaucoup plus élevé que ses concurrents.
3. Fonctionnalités de post-traitement intéressantes :
Supposons que votre base de données a été intégrée au modèle nanonets. Le modèle remplit automatiquement certains champs (avec les données de votre base de données) en fonction des données extraites du document. Par exemple:
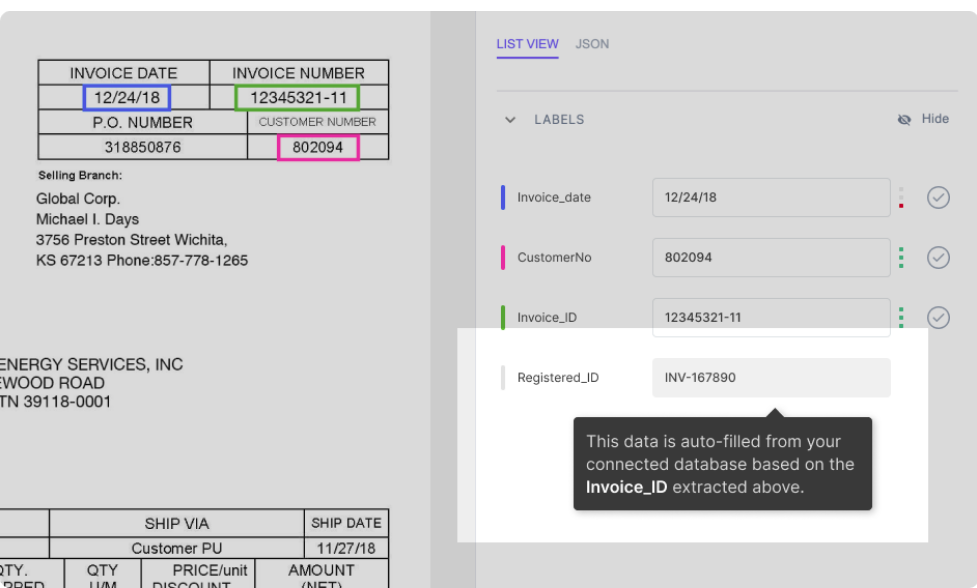
Comme le montre la figure, le champ Registered_ID est rempli automatiquement (par une recherche dans la base de données) en fonction de l'Invoice_ID extrait du PDF.
4. Interface simple et intuitive
Bien que cette fonctionnalité soit sous-estimée, j'ai trouvé que l'interface utilisateur et l'expérience utilisateur étaient parfaites. L'ensemble du processus d'inscription, de téléchargement du document et d'analyse des données a pris moins de 5 minutes. C'est presque égal au temps que prend mon ordinateur portable pour démarrer !
5. Énorme clientèle
Si vous avez encore des réserves sur l'utilisation de Nanonets pour automatiser votre flux de travail, jetez un œil à certaines des entreprises qui utilisent leurs services.
- Deloitte
- Sherwin Williams
- DoorDash
- P & G
Vous voulez extraire des informations de documents PDF et les convertir/ajouter dans un document Google Sheets ? Découvrez les nanonets™ pour automatiser l'exportation de n'importe quelle information de n'importe quel document PDF vers Google Sheets !
Conclusion
Dans cet article, nous avons examiné comment vous pouvez automatiser votre flux de travail en utilisant un convertisseur PDF vers Google Sheets. Au départ, nous avons appris la nécessité de convertir des documents PDF en feuilles de calcul Google, suivi des défis rencontrés au cours de ce processus. Nous nous sommes ensuite penchés sur les approches adoptées par les analyseurs modernes pour analyser les documents PDF et avons également mis en œuvre certaines des approches courantes. Nous avons également appris comment automatiser complètement la conversion à l'aide d'intégrations externes telles que des webhooks et des API. Enfin, nous avons utilisé l'outil Nanonets pour analyser un exemple de facture, extraire les données dans un formulaire Google Sheets et également exploré certaines de ses fonctionnalités de post-traitement intéressantes.
Avez-vous essayé le modèle Nanonets ? Si tel est le cas, veuillez laisser un commentaire ci-dessous concernant votre expérience avec l'outil. Sinon, allez-y et essayez-le. Cela pourrait bien faire votre journée!
- AI
- AI et apprentissage automatique
- art de l'IA
- générateur d'art ai
- robot IA
- intelligence artificielle
- certification en intelligence artificielle
- intelligence artificielle en banque
- robot d'intelligence artificielle
- robots d'intelligence artificielle
- logiciel d'intelligence artificielle
- blockchain
- conférence blockchain ai
- cognitif
- intelligence artificielle conversationnelle
- crypto conférence ai
- de dall
- l'apprentissage en profondeur
- google ai
- machine learning
- pdf vers feuilles google
- Platon
- platon ai
- Intelligence des données Platon
- Jeu de Platon
- PlatonDonnées
- jeu de platogamie
- échelle ai
- syntaxe
- zéphyrnet