Redshift d'Amazon est un entrepôt de données rapide, évolutif, sécurisé et entièrement géré qui vous permet d'analyser facilement et à moindre coût toutes vos données à l'aide du langage SQL standard. Redshift d'Amazon Partage de données permet aux clients de partager en toute sécurité des données en direct et cohérentes sur le plan transactionnel dans un cluster Amazon Redshift avec un autre cluster Amazon Redshift sur plusieurs comptes et régions sans avoir besoin de copier ou de déplacer des données d'un cluster à un autre.
Amazon Redshift Data Sharing a été initialement lancé en Mars 2021, et la prise en charge du partage de données entre comptes a été ajoutée dans Août 2021. Le support interrégional est devenu généralement disponible dans Février 2022. Cela offre une flexibilité et une agilité totales pour partager des données entre les clusters Redshift dans le même compte AWS, différents comptes ou différentes régions.
Le partage de données Amazon Redshift est utilisé pour redéfinir fondamentalement les architectures de déploiement d'Amazon Redshift dans un modèle de maillage de données en étoile afin de mieux respecter les SLA de performance, fournir une isolation de la charge de travail, effectuer des analyses intergroupes, intégrer facilement de nouveaux cas d'utilisation et, surtout, faire tout ceci sans la complexité du déplacement des données et des copies de données. Certaines des questions les plus fréquemment posées lors du déploiement du partage de données sont : "Quelle taille doivent avoir mes clusters de consommateurs et mes clusters de producteurs ?" et "Comment puis-je obtenir les meilleures performances de prix pour l'isolation de la charge de travail ?". Étant donné que les caractéristiques de la charge de travail telles que la taille des données, le taux d'ingestion, le modèle de requête et les activités de maintenance peuvent avoir un impact sur les performances de partage des données, une stratégie continue de dimensionnement des clusters consommateurs et producteurs afin de maximiser les performances et de minimiser les coûts doit être mise en œuvre. Dans cet article, nous proposons une approche étape par étape pour vous aider à déterminer la taille de vos clusters de producteurs et de consommateurs pour obtenir les meilleures performances tarifaires en fonction de votre charge de travail spécifique.
Conseils génériques sur les tailles des consommateurs
Les étapes suivantes montrent la stratégie générique pour dimensionner vos clusters de producteurs et de consommateurs. Vous pouvez l'utiliser comme point de départ et le modifier en conséquence pour répondre à votre scénario de cas d'utilisation spécifique.
Dimensionnez votre cluster de producteurs
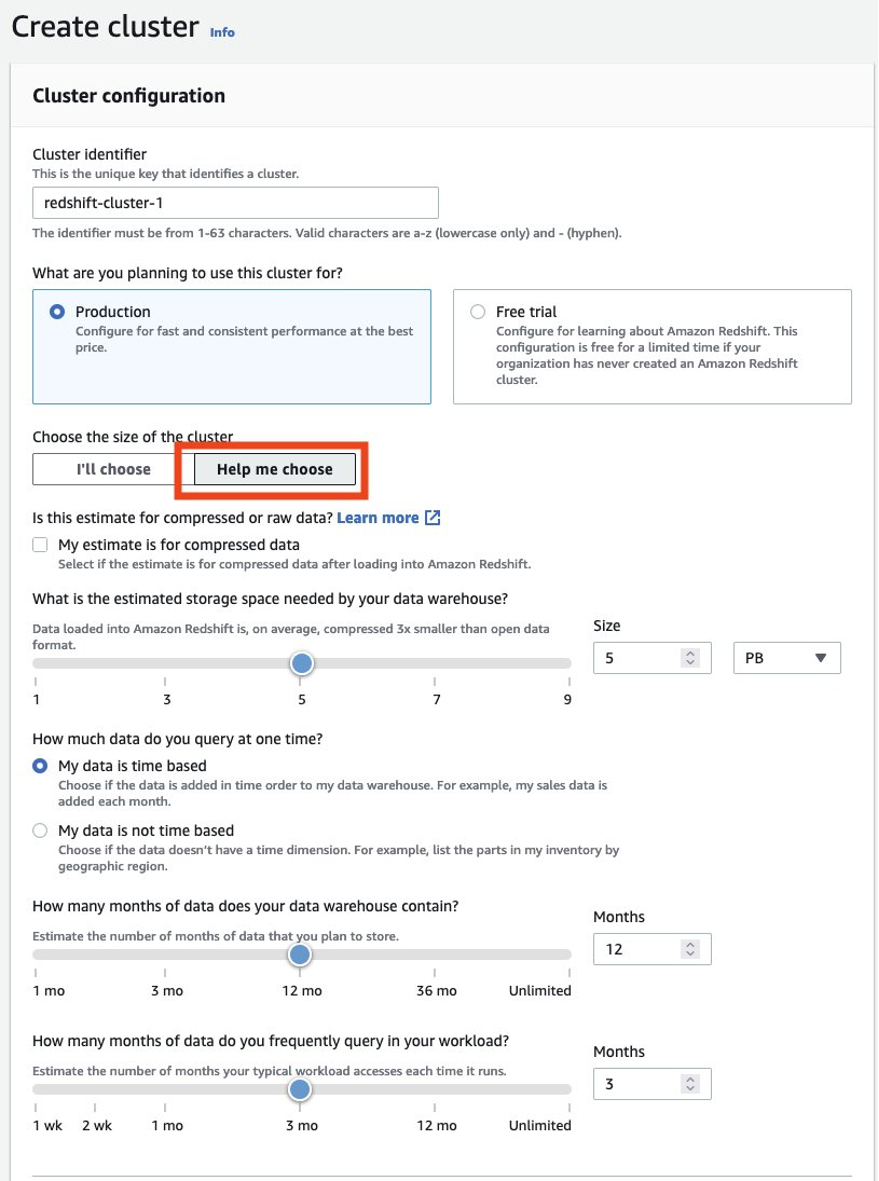
Vous devez toujours vous assurer que vous dimensionnez correctement votre cluster producteur pour obtenir les performances dont vous avez besoin pour respecter votre SLA. Vous pouvez tirer parti du calculateur de dimensionnement de la console Amazon Redshift pour obtenir une recommandation pour le cluster producteur en fonction de la taille de vos données et de la caractéristique de requête. Chercher Aide moi à choisir sur la console dans les régions AWS qui prennent en charge les types de nœuds RA3 pour utiliser ce calculateur de dimensionnement. Notez qu'il ne s'agit que d'une recommandation initiale pour commencer, et vous devez tester l'exécution de votre charge de travail complète sur le cluster de taille initiale et redimensionner élastiquement le cluster en conséquence pour obtenir les meilleures performances de prix.
Taille et configuration du cluster consommateur initial
Vous devez toujours dimensionner votre cluster consommateur en fonction de vos besoins de calcul. Une façon de commencer est de suivre le guide générique de dimensionnement des clusters similaire au cluster de producteurs ci-dessus.
Configurer le partage de données Amazon Redshift
Configurez le partage de données du producteur au consommateur une fois que vous avez configuré le cluster du producteur et du consommateur. Référez-vous à ceci poster pour savoir comment configurer le partage de données.
Tester la charge de travail du consommateur uniquement sur le cluster consommateur initial
Testez la charge de travail consommateur uniquement sur le nouveau cluster consommateur initial. Cela peut être fait en pointant les applications client, par exemple les outils ETL, les applications BI et les clients SQL, vers le nouveau cluster client et en réexécutant la charge de travail pour évaluer les performances par rapport à vos besoins.
Tester la charge de travail consommateur uniquement sur différentes configurations de cluster consommateur
Si le cluster consommateur de taille initiale atteint ou dépasse les exigences de performance de votre charge de travail, vous pouvez soit continuer à utiliser cette configuration de cluster, soit tester sur des configurations plus petites pour voir si vous pouvez réduire davantage le coût tout en obtenant les performances dont vous avez besoin.
D'un autre côté, si le cluster consommateur de taille initiale ne répond pas aux exigences de performances de votre charge de travail, vous pouvez tester davantage des configurations plus importantes pour obtenir la configuration qui répond à votre SLA.
En règle générale, augmentez progressivement la taille du cluster consommateur de 2 x la configuration initiale du cluster jusqu'à ce qu'il réponde aux exigences de votre charge de travail.
Une fois que vous avez planifié la configuration que vous souhaitez tester, utilisez le redimensionnement élastique pour redimensionner le cluster initial en fonction de la configuration du cluster cible. Une fois le redimensionnement élastique terminé, effectuez le même test de charge de travail et évaluez les performances par rapport à votre SLA. Sélectionnez la configuration qui répond à votre objectif de performance tarifaire.
Tester la charge de travail du producteur uniquement sur différentes configurations de cluster de producteur
Une fois que vous avez déplacé votre charge de travail consommateur vers le cluster consommateur avec les performances de prix optimales, il peut y avoir une opportunité de réduire la ressource de calcul sur le producteur pour économiser sur les coûts.
Pour ce faire, vous pouvez réexécuter la charge de travail du producteur uniquement sur 1/2 fois la taille du producteur d'origine et évaluer les performances de la charge de travail. Le redimensionnement du cluster vers le haut ou vers le bas dépend du résultat, puis vous sélectionnez la configuration minimale du producteur qui répond aux exigences de performances de votre charge de travail.
Réévaluer après une charge de travail complète exécutée dans le temps
À mesure qu'Amazon Redshift continue d'évoluer et qu'il existe des versions d'amélioration continue des performances et de l'évolutivité, les performances de partage de données continueront de s'améliorer. De plus, de nombreuses variables peuvent avoir un impact sur les performances des requêtes de partage de données. Voici quelques exemples :
- Taux d'ingestion et quantité de données modifiées
- Modèle de requête et caractéristique
- Modifications de la charge de travail
- Concurrency
- Activités de maintenance, par exemple vide, analyse et ATO
C'est pourquoi vous devez réévaluer le dimensionnement des clusters producteurs et consommateurs à l'aide de la stratégie ci-dessus à l'occasion, en particulier après un déploiement complet de la charge de travail, pour obtenir les nouvelles meilleures performances de prix à partir de la configuration de votre cluster.
Solutions de dimensionnement automatisé
Si votre environnement impliquait une architecture plus complexe, par exemple avec plusieurs outils ou applications (BI, ingestion ou streaming, ETL, science des données), il se peut qu'il ne soit pas possible d'utiliser la méthode manuelle des conseils génériques ci-dessus. Au lieu de cela, vous pouvez tirer parti des solutions de cette section pour relire automatiquement la charge de travail de votre cluster de production sur les clusters de consommateur et de producteur de test afin d'évaluer les performances.
Utilitaire de relecture simple sera utilisé comme solution automatisée pour vous guider tout au long du processus d'obtention de la bonne taille de clusters de producteurs et de consommateurs pour la meilleure performance de prix.
Simple Replay est un outil permettant d'effectuer une analyse de simulation et d'évaluer les performances de votre charge de travail dans différents scénarios. Par exemple, vous pouvez utiliser l'outil pour comparer votre charge de travail réelle sur un nouveau type d'instance comme RA3, évaluer une nouvelle fonctionnalité ou évaluer différentes configurations de cluster. Il inclut également une prise en charge améliorée de la relecture des pipelines d'ingestion et d'exportation de données avec les instructions COPY et UNLOAD. Pour commencer et rejouer vos charges de travail, téléchargez l'outil depuis le Référentiel Amazon Redshift GitHub.
Ici, nous passons en revue les étapes pour extraire vos journaux de charge de travail du cluster de production source et les relire dans un environnement isolé. Cela vous permet d'effectuer une comparaison directe entre ces clusters Amazon Redshift de manière transparente et de sélectionner la configuration de clusters qui répond le mieux à votre objectif de performance de prix.
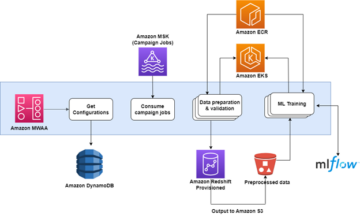
Le diagramme suivant montre l'architecture de la solution.
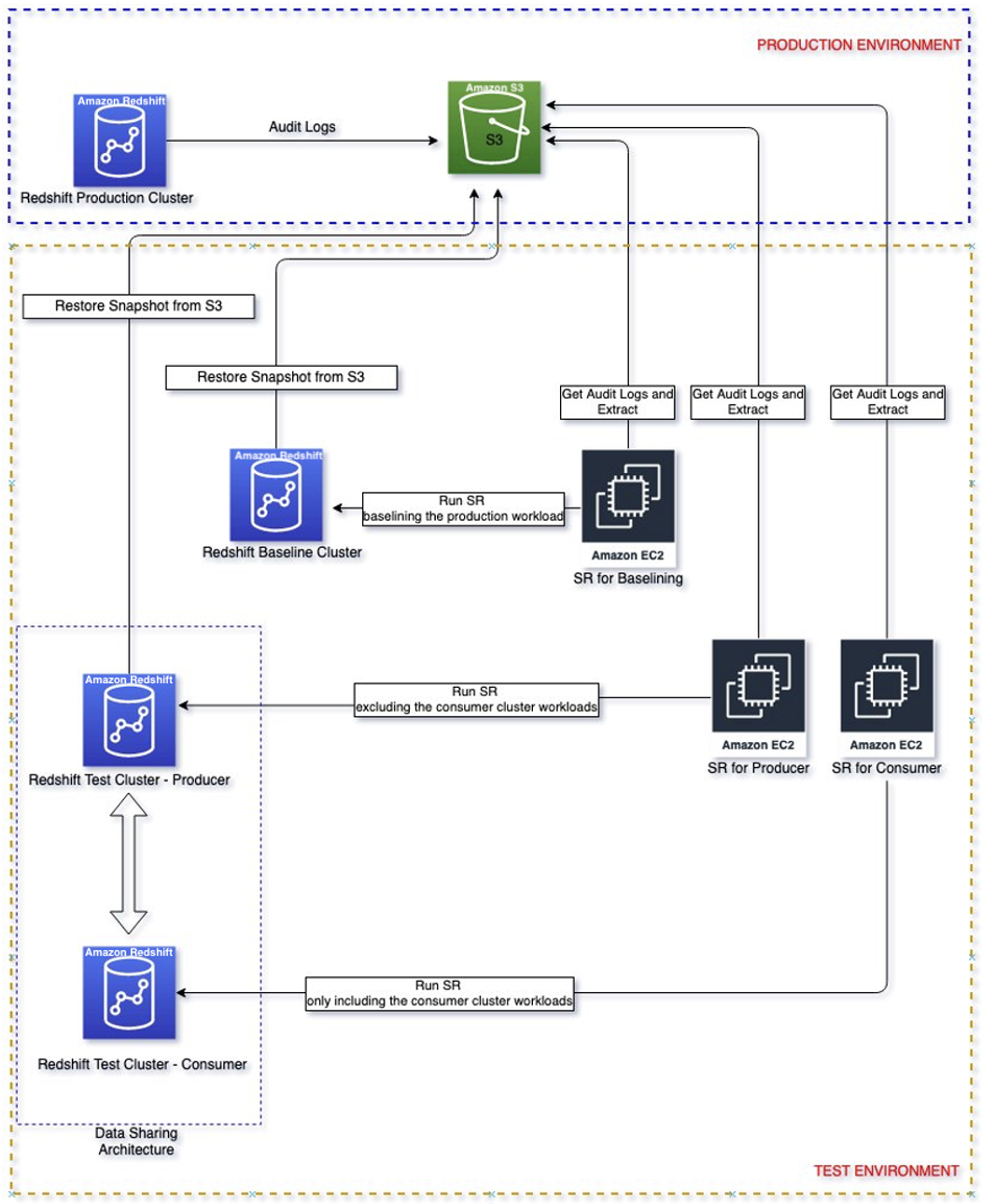
Procédure pas à pas de la solution
Suivez ces étapes pour parcourir la solution afin de dimensionner vos clusters de consommateurs et de producteurs.
Dimensionnez votre cluster de production
Vous devez toujours vous assurer de dimensionner correctement votre cluster de production existant pour obtenir les performances dont vous avez besoin pour répondre aux exigences de votre charge de travail. Vous pouvez tirer parti du calculateur de dimensionnement de la console Amazon Redshift pour obtenir une recommandation sur le cluster de production en fonction de la taille de vos données et des caractéristiques de la requête. Chercher Aide moi à choisir sur la console dans les régions AWS qui prennent en charge les types de nœuds RA3 pour utiliser ce calculateur de dimensionnement. Notez qu'il ne s'agit que d'une première recommandation pour commencer. Vous devez tester l'exécution de votre charge de travail complète sur le cluster de taille initiale et redimensionner élastiquement le cluster en conséquence pour obtenir les meilleures performances de prix.
Identifier la charge de travail à isoler
Différentes charges de travail peuvent s'exécuter sur votre cluster d'origine, mais la première étape consiste à identifier la charge de travail la plus critique pour l'entreprise que nous souhaitons isoler. En effet, nous voulons nous assurer que la nouvelle architecture peut répondre à vos exigences de charge de travail. Cette poster est une bonne référence sur un cas d'utilisation d'isolation de charge de travail de partage de données qui peut vous aider à décider quelle charge de travail peut être isolée.
Configuration de la relecture simple
Une fois que vous connaissez votre charge de travail critique, vous devez activer la journalisation d'audit dans votre cluster de production où la charge de travail critique identifiée ci-dessus s'exécute pour capturer les activités de requête et stocker dans Service de stockage simple Amazon (Amazon S3). Notez que la livraison des journaux d'audit à Amazon S3 peut prendre jusqu'à trois heures. Une fois le journal d'audit disponible, passez à configurer la relecture simple et alors extrait la charge de travail critique à partir du journal d'audit. Notez que start_time et end_time peuvent être utilisés comme paramètres pour filtrer la charge de travail critique si ces charges de travail s'exécutent à certaines périodes, par exemple de 9 h à 11 h. Sinon, il extraira toutes les activités enregistrées.
Charge de travail de base
Créez un cluster de référence avec la même configuration que le cluster producteur en restaurant à partir de l'instantané de production. Le but de commencer avec la même configuration est de baser les performances avec un environnement isolé.
Une fois le cluster de référence disponible, rejouer la charge de travail extraite dans le cluster de référence. La sortie de cette rediffusion sera la ligne de base utilisée pour comparer avec les rediffusions ultérieures sur différentes configurations de consommateurs.
Configurer les clusters de test de producteurs et de consommateurs initiaux
Créez un cluster producteur avec la même configuration de cluster de production en restaurant à partir de l'instantané de production. Créez un cluster de consommateurs avec la taille de consommateur initiale recommandée à partir des conseils précédents. En outre, configurez le partage de données entre le producteur et le consommateur.
Rejouer la charge de travail sur le producteur et le consommateur initiaux
Replay la charge de travail du producteur uniquement sur le cluster de producteur de taille initiale. Ceci peut être réalisé en utilisant le paramètre de filtre "Exclure" pour exclure les requêtes des consommateurs, par exemple l'utilisateur qui exécute les requêtes des consommateurs.
Replay la charge de travail consommateur uniquement sur le cluster consommateur de taille initiale. Ceci peut être réalisé en utilisant le paramètre de filtre "Inclure" pour exclure les requêtes des consommateurs, par exemple l'utilisateur qui exécute les requêtes des consommateurs.
Évaluez les performances de ces relectures par rapport aux exigences de performance de référence et de charge de travail.
Rejouer la charge de travail des consommateurs sur différentes configurations
Si le cluster consommateur de taille initiale atteint ou dépasse les exigences de performances de votre charge de travail, vous pouvez soit utiliser cette configuration de cluster, soit suivre ces étapes pour tester sur des configurations plus petites afin de voir si vous pouvez réduire davantage les coûts tout en obtenant les performances dont vous avez besoin.
Comparez les résultats initiaux des performances des consommateurs aux exigences de votre charge de travail :
- Si le résultat dépasse les exigences de performances de votre charge de travail, vous pouvez réduire progressivement la taille du cluster consommateur, en commençant par 1/2x, réessayer la relecture et évaluer les performances, puis redimensionner en fonction du résultat jusqu'à ce qu'il corresponde à votre charge de travail. conditions. Le but est d'obtenir un point idéal où vous êtes à l'aise avec les exigences de performance et d'obtenir le prix le plus bas possible.
- Si le résultat ne répond pas aux exigences de performances de votre charge de travail, vous pouvez augmenter la taille du cluster de manière incrémentielle, en commençant par 2 fois la taille d'origine, réessayer la relecture et évaluer les performances jusqu'à ce qu'elles répondent aux exigences de performances de votre charge de travail.
Rejouer la charge de travail du producteur sur différentes configurations
Une fois que vous avez réparti vos charges de travail sur des clusters consommateurs, la charge sur le cluster producteur doit être réduite et vous devez évaluer les performances de charge de travail de votre cluster producteur pour rechercher l'opportunité de réduire la taille pour économiser sur les coûts.
Les étapes sont similaires à celles de la relecture client. Elastic redimensionne progressivement le cluster de producteur en commençant par 1/2 fois la taille d'origine, rejoue la charge de travail du producteur uniquement et évalue les performances, puis redimensionne à la hausse ou à la baisse jusqu'à ce qu'il réponde aux exigences de performances de votre charge de travail. L'objectif est d'obtenir un point idéal où vous êtes à l'aise avec les exigences de performance de la charge de travail et d'obtenir le prix le plus bas possible. Une fois que vous avez la configuration de cluster de producteur souhaitée, réessayez de relire les charges de travail de consommateur sur le cluster de consommateur pour vous assurer que les performances n'ont pas été affectées par les modifications de configuration du cluster de producteur. Enfin, vous devez relire simultanément les charges de travail du producteur et du consommateur pour vous assurer que les performances sont atteintes dans un scénario de charge de travail complète.
Réévaluer après une charge de travail complète exécutée dans le temps
Comme pour les conseils génériques, vous devez réévaluer occasionnellement le dimensionnement des clusters producteur et consommateur à l'aide de la stratégie précédente, en particulier après le déploiement complet de la charge de travail, afin d'obtenir les nouvelles meilleures performances de prix à partir de la configuration de votre cluster.
Nettoyer
L'exécution de ces tests de dimensionnement dans votre compte AWS peut avoir des implications financières, car elle provisionne de nouveaux clusters Amazon Redshift, qui peuvent être facturés en tant qu'instances à la demande si vous n'avez pas d'instances réservées. Lorsque vous terminez vos évaluations, nous vous recommandons de supprimer les clusters Amazon Redshift pour réduire les coûts. Nous vous recommandons également de suspendre vos clusters lorsqu'ils ne sont pas utilisés.
Application d'Amazon Redshift et des meilleures pratiques de partage de données
Un dimensionnement approprié de vos clusters de producteurs et de consommateurs vous donnera un bon départ pour obtenir les meilleures performances de prix de votre déploiement Amazon Redshift. Cependant, la taille n'est pas le seul facteur qui peut maximiser vos performances. Dans ce cas, comprendre et suivre les meilleures pratiques sont tout aussi importants.
Les meilleures pratiques générales de réglage des performances d'Amazon Redshift s'appliquent au déploiement du partage de données. Assurez-vous que votre déploiement suit ces les meilleures pratiques.
Il existe de nombreuses meilleures pratiques spécifiques de partage de données que vous devez suivre pour vous assurer de maximiser les performances. Référez-vous à ceci poster pour plus de détails.
Résumé
Il n'y a pas de recommandation unique sur la taille des grappes de producteurs et de consommateurs. Cela varie en fonction des charges de travail et de votre SLA de performance. Le but de cet article est de vous fournir des conseils sur la façon dont vous pouvez évaluer les performances spécifiques de votre charge de travail de partage de données afin de déterminer les tailles de cluster consommateur et producteur afin d'obtenir les meilleures performances de prix. Envisagez de tester vos charges de travail sur le producteur et le consommateur en utilisant une relecture simple avant de l'adopter en production pour obtenir les meilleures performances de prix.
À propos des auteurs
 BP Yau est chef de produit senior chez AWS. Il se passionne pour aider les clients à concevoir des solutions Big Data pour traiter les données à grande échelle. Avant AWS, il a aidé Amazon.com Supply Chain Optimization Technologies à migrer son entrepôt de données Oracle vers Amazon Redshift et à créer sa plate-forme d'analyse de données volumineuses de nouvelle génération à l'aide des technologies AWS.
BP Yau est chef de produit senior chez AWS. Il se passionne pour aider les clients à concevoir des solutions Big Data pour traiter les données à grande échelle. Avant AWS, il a aidé Amazon.com Supply Chain Optimization Technologies à migrer son entrepôt de données Oracle vers Amazon Redshift et à créer sa plate-forme d'analyse de données volumineuses de nouvelle génération à l'aide des technologies AWS.
 Sidhanth Muralidhar est responsable de compte technique principal chez AWS. Il travaille avec de grandes entreprises clientes qui exécutent leurs charges de travail sur AWS. Il est passionné par le travail avec les clients et les aide à concevoir des charges de travail pour les coûts, la fiabilité, les performances et l'excellence opérationnelle à grande échelle dans leur parcours vers le cloud. Il a également un vif intérêt pour l'analyse de données.
Sidhanth Muralidhar est responsable de compte technique principal chez AWS. Il travaille avec de grandes entreprises clientes qui exécutent leurs charges de travail sur AWS. Il est passionné par le travail avec les clients et les aide à concevoir des charges de travail pour les coûts, la fiabilité, les performances et l'excellence opérationnelle à grande échelle dans leur parcours vers le cloud. Il a également un vif intérêt pour l'analyse de données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- À propos
- au dessus de
- en conséquence
- Compte
- hybrides
- atteindre
- atteint
- à travers
- activités
- ajoutée
- L'adoption d'
- Après
- à opposer à
- Tous
- permet
- toujours
- Amazon
- -
- montant
- selon une analyse de l’Université de Princeton
- analytique
- il analyse
- ainsi que
- Une autre
- en vigueur
- applications
- une approche
- architecture
- audit
- Automatisation
- automatiquement
- disponibles
- AWS
- basé
- Baseline
- car
- before
- référence
- LES MEILLEURS
- les meilleures pratiques
- Améliorée
- jusqu'à XNUMX fois
- Big
- Big Data
- construire
- la performance des entreprises
- capturer
- maisons
- cas
- certaines
- chaîne
- Modifications
- caractéristique
- caractéristiques
- accusé
- CLIENTS
- le cloud
- Grappe
- COM
- confortable
- Commun
- comparer
- Comparaison
- complet
- Complété
- complexe
- complexité
- calcul
- conduite
- configuration
- Considérer
- cohérent
- Console
- consommateur
- continuer
- continue
- continu
- Prix
- Costs
- pourriez
- engendrent
- critique
- Clients
- données
- Analyse de Donnée
- science des données
- partage de données
- livré
- dépend
- déploiement
- détails
- Déterminer
- différent
- Ne pas
- down
- download
- pendant
- même
- non plus
- permet
- améliorée
- Entreprise
- Environment
- également
- notamment
- Ether (ETH)
- évaluer
- évaluations
- évolution
- exemple
- exemples
- dépasse
- Excellence
- existant
- Exporter
- extrait
- échoue
- RAPIDE
- réalisable
- Fonctionnalité
- une fonction filtre
- finalement
- Prénom
- Flexibilité
- suivre
- Abonnement
- suit
- de
- plein
- fondamentalement
- plus
- En outre
- Gain
- généralement
- génération
- obtenez
- obtention
- GitHub
- Donner
- Go
- Bien
- guide
- aider
- a aidé
- aider
- HEURES
- Comment
- How To
- Cependant
- HTTPS
- identifié
- identifier
- Impact
- impact
- mis en œuvre
- implications
- important
- amélioration
- l'amélioration de
- in
- inclut
- Améliore
- initiale
- possible
- instance
- plutôt ;
- intérêt
- impliqué
- isolé
- seul
- IT
- chemin
- Vif
- Savoir
- gros
- plus importantes
- lancé
- Allons-y
- Levier
- le travail
- charge
- Style
- facile
- faire
- manager
- Manuel
- Maximisez
- Découvrez
- Se rencontre
- méthode
- pourrait
- émigrer
- minimum
- modèle
- PLUS
- (en fait, presque toutes)
- Bougez
- mouvement
- plusieurs
- Besoin
- besoin
- Besoins
- Nouveauté
- next
- nœud
- nombreux
- occasions
- Débuter
- ONE
- opérationnel
- Opportunités
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- optimum
- oracle
- original
- Autre
- autrement
- paramètre
- paramètres
- passionné
- Patron de Couture
- effectuer
- performant
- effectue
- périodes
- plan
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- possible
- Post
- pratiques
- précédent
- prix
- Directeur
- processus
- producteur
- Produit
- chef de produit
- Vidéo
- correctement
- fournir
- fournit
- but
- fréquemment posées
- Tarif
- recommander
- Recommandation
- recommandé
- réduire
- Prix Réduit
- régions
- de Presse
- fiabilité
- Exigences
- réservé
- ressource
- restauration
- résultat
- Résultats
- Règle
- Courir
- pour le running
- même
- Épargnez
- Évolutivité
- évolutive
- Escaliers intérieurs
- scénarios
- Sciences
- de façon transparente
- Section
- sécurisé
- en toute sécurité
- Chercher
- service
- installation
- Partager
- partage
- devrait
- montrer
- Spectacles
- similaires
- étapes
- Taille
- tailles
- faibles
- Instantané
- sur mesure
- Solutions
- quelques
- Identifier
- groupe de neurones
- scission
- Spot
- Standard
- Commencer
- j'ai commencé
- Commencez
- déclarations
- étapes
- Étapes
- Encore
- storage
- Boutique
- de Marketing
- streaming
- ultérieur
- la quantité
- chaîne d'approvisionnement
- Optimisation de la chaîne d'approvisionnement
- Support
- sucré
- Prenez
- Target
- Technique
- Les technologies
- tester
- Essais
- tests
- La
- La Source
- leur
- trois
- Avec
- fiable
- à
- outil
- les outils
- types
- compréhension
- utilisé
- cas d'utilisation
- Utilisateur
- Vide
- Quoi
- qui
- WHO
- sera
- sans
- de travail
- vos contrats
- Votre
- zéphyrnet