Introduction
Nous avons vu des termes fantaisistes pour l'IA et l'apprentissage en profondeur, tels que les modèles pré-entraînés, l'apprentissage par transfert, etc. Laissez-moi vous éduquer avec une technologie largement utilisée et l'une des plus importantes et des plus efficaces : l'apprentissage par transfert avec YOLOv5.
You Only Look Once, ou YOLO est l'une des méthodes d'identification d'objets basées sur l'apprentissage en profondeur les plus largement utilisées. À l'aide d'un ensemble de données personnalisé, cet article vous montrera comment entraîner l'une de ses variantes les plus récentes, YOLOv5.
Objectifs d'apprentissage
- Cet article se concentrera principalement sur la formation du modèle YOLOv5 sur une implémentation de jeu de données personnalisée.
- Nous verrons ce que sont les modèles pré-entraînés et verrons ce qu'est l'apprentissage par transfert.
- Nous comprendrons ce qu'est YOLOv5 et pourquoi nous utilisons la version 5 de YOLO.
Alors, sans perdre de temps, commençons le processus
Table des matières
- Modèles pré-entraînés
- Transfert d'apprentissage
- Quoi et pourquoi YOLOv5 ?
- Étapes impliquées dans l'apprentissage par transfert
- Implémentation
- Quelques défis auxquels vous pouvez faire face
- Conclusion
Modèles pré-formés
Vous avez peut-être entendu des data scientists utiliser largement le terme « modèle pré-formé ». Après avoir expliqué ce que fait un modèle/réseau d'apprentissage en profondeur, j'expliquerai le terme. Un modèle d'apprentissage en profondeur est un modèle contenant différentes couches empilées de manière à servir un seul objectif, tel que la classification, la détection, etc. Les réseaux d'apprentissage en profondeur apprennent en découvrant des structures complexes dans les données qui leur sont fournies et en enregistrant les poids dans un fichier qui sont ensuite utilisés pour effectuer des tâches similaires. Les modèles pré-entraînés sont déjà des modèles d'apprentissage approfondi. Cela signifie qu'ils sont déjà formés sur un énorme ensemble de données contenant des millions d'images.
Voici comment le TensorFlow Le site Web définit des modèles pré-formés : Un modèle pré-formé est un réseau enregistré qui a été préalablement formé sur un grand ensemble de données, généralement sur une tâche de classification d'images à grande échelle.
Certains hautement optimisés et extraordinairement efficaces modèles pré-entraînés sont disponibles sur internet. Différents modèles sont utilisés pour effectuer différentes tâches. Certains des modèles pré-formés sont VGG-16, VGG-19, YOLOv5, YOLOv3 et ResNet 50.
Le modèle à utiliser dépend de la tâche que vous souhaitez effectuer. Par exemple, si je veux effectuer une détection d'objets tâche, j'utiliserai le modèle YOLOv5.
Transfert d'apprentissage
Transfert d'apprentissage est la technique la plus importante qui facilite la tâche d'un data scientist. La formation d'un modèle est une tâche lourde et chronophage ; si un modèle est formé à partir de zéro, il ne donne généralement pas de très bons résultats. Même si nous formons un modèle similaire à un modèle pré-formé, il ne fonctionnera pas aussi efficacement et l'entraînement d'un modèle peut prendre des semaines. Au lieu de cela, nous pouvons utiliser les modèles pré-formés et utiliser les poids déjà appris en les formant sur un ensemble de données personnalisé pour effectuer une tâche similaire. Ces modèles sont très efficaces et raffinés en termes d'architecture et de performances, et ils se sont frayé un chemin vers le sommet en se montrant plus performants dans différents concours. Ces modèles sont entraînés sur de très grandes quantités de données, ce qui les rend plus diversifiés en termes de connaissances.
Ainsi, l'apprentissage par transfert signifie essentiellement le transfert des connaissances acquises en entraînant le modèle sur des données précédentes pour aider le modèle à apprendre mieux et plus rapidement pour effectuer une tâche différente mais similaire.
Par exemple, en utilisant un YOLOv5 pour la détection d'objet, mais l'objet est autre chose que les données précédentes de l'objet utilisées.
Quoi et pourquoi YOLOv5 ?
YOLOv5 est un modèle pré-formé qui signifie que vous ne regardez qu'une fois que la version 5 est utilisée pour la détection d'objets en temps réel et s'est avérée très efficace en termes de précision et de temps d'inférence. Il existe d'autres versions de YOLO, mais comme on pouvait s'y attendre, YOLOv5 fonctionne mieux que les autres versions. YOLOv5 est rapide et facile à utiliser. Il est basé sur le framework PyTorch, qui a une communauté plus large que Yolo v4 Darknet.
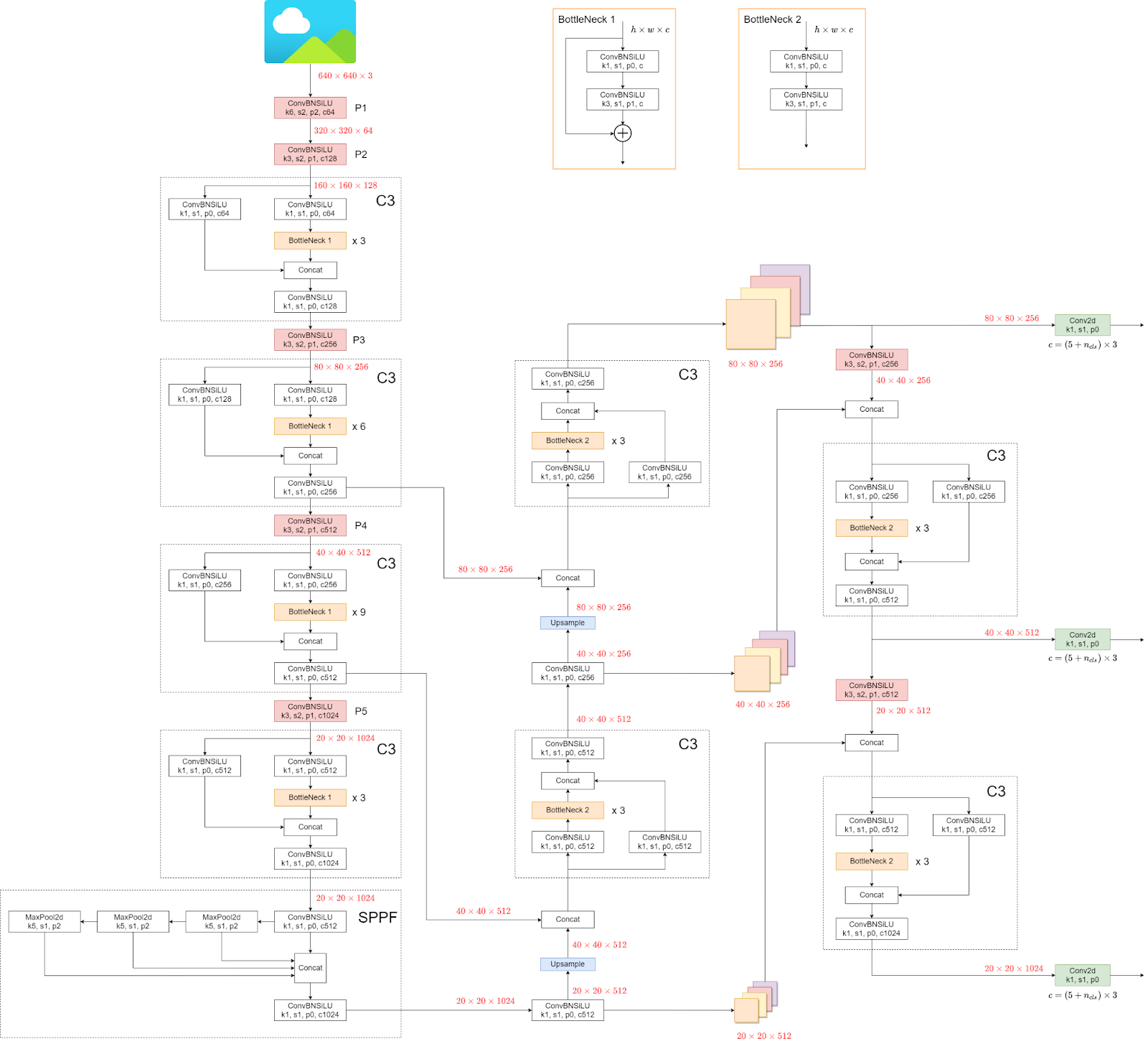
Nous allons maintenant nous intéresser à l'architecture de YOLOv5.
La structure peut sembler déroutante, mais cela n'a pas d'importance car nous n'avons pas à regarder l'architecture au lieu d'utiliser directement le modèle et les poids.
Dans l'apprentissage par transfert, nous utilisons l'ensemble de données personnalisé, c'est-à-dire les données que le modèle n'a jamais vues auparavant OU les données sur lesquelles le modèle n'est pas formé. Étant donné que le modèle est déjà formé sur un grand ensemble de données, nous avons déjà les poids. Nous pouvons maintenant former le modèle pour un certain nombre d'époques sur les données sur lesquelles nous voulons travailler. Une formation est nécessaire car le modèle a vu les données pour la première fois et nécessitera certaines connaissances pour effectuer la tâche.
Étapes impliquées dans l'apprentissage par transfert
L'apprentissage par transfert est un processus simple, et nous pouvons le faire en quelques étapes simples :
- Préparation des données
- Le bon format pour les annotations
- Changez quelques calques si vous le souhaitez
- Réentraîner le modèle pour quelques itérations
- Valider/Tester
Préparation des données
La préparation des données peut prendre du temps si les données choisies sont un peu volumineuses. La préparation des données signifie annoter les images, qui est un processus où vous étiquetez les images en faisant une boîte autour de l'objet dans l'image. Ce faisant, les coordonnées de l'objet marqué seront enregistrées dans un fichier qui sera ensuite transmis au modèle pour l'entraînement. Il existe quelques sites Web, tels que makesens.ai ainsi que roboflow.com, qui peut vous aider à étiqueter les données.
Voici comment vous pouvez annoter les données du modèle YOLOv5 sur makesens.ai.
1. Visiter https://www.makesense.ai/.
2. Cliquez sur commencer en bas à droite de l'écran.
3. Sélectionnez les images que vous souhaitez étiqueter en cliquant sur la case en surbrillance au centre.
Chargez les images que vous souhaitez annoter et cliquez sur détection d'objet.
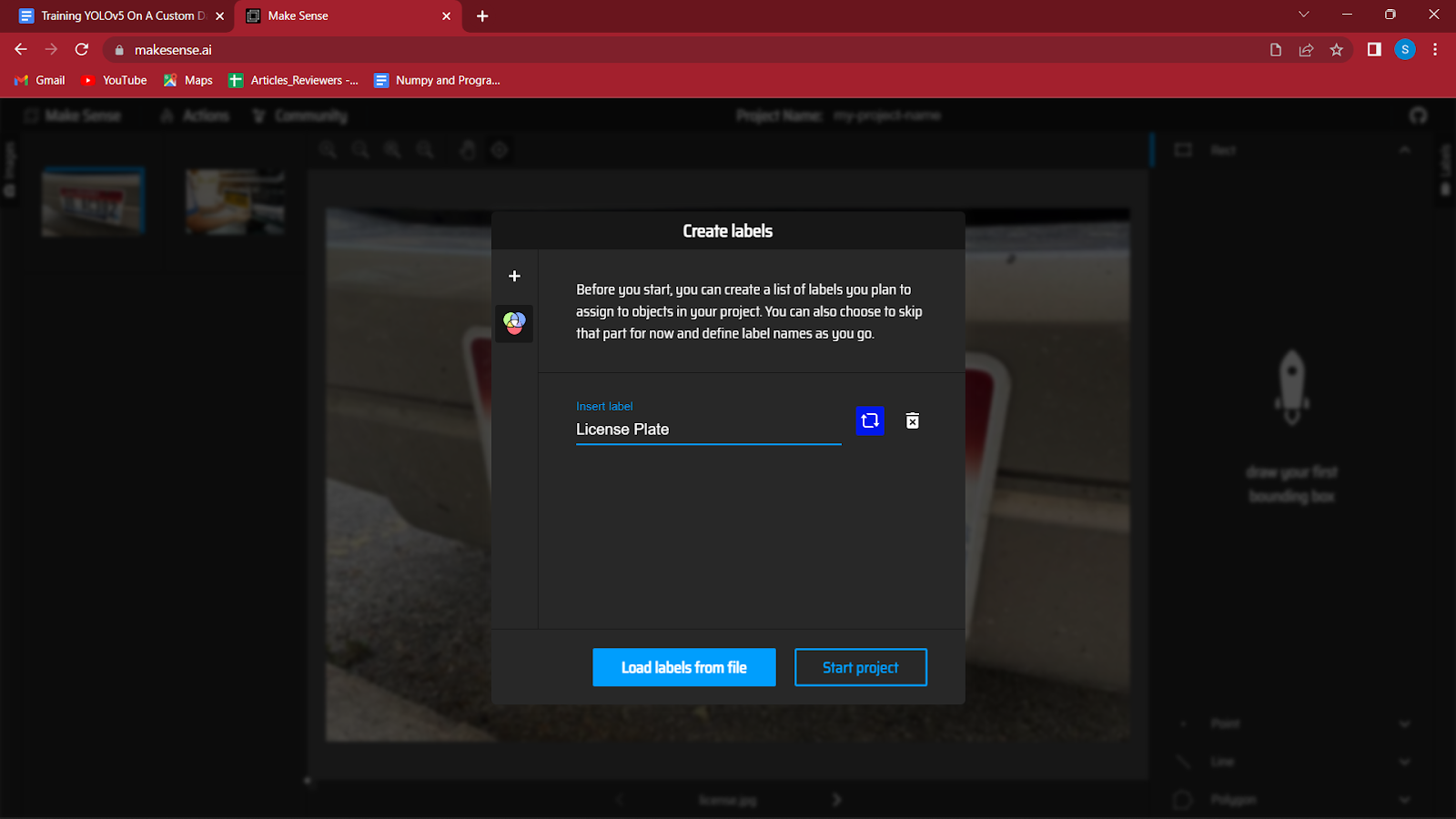
4. Après avoir chargé les images, il vous sera demandé de créer des étiquettes pour les différentes classes de votre jeu de données.
Je détecte des plaques d'immatriculation sur un véhicule, donc la seule étiquette que j'utiliserai est "Plaque d'immatriculation". Vous pouvez créer plus d'étiquettes en appuyant simplement sur Entrée en cliquant sur le bouton "+" sur le côté gauche de la boîte de dialogue.
Après avoir créé toutes les étiquettes, cliquez sur démarrer le projet.
Si vous avez manqué des étiquettes, vous pouvez les modifier ultérieurement en cliquant sur les actions, puis modifier les étiquettes.
5. Commencez à créer une boîte englobante autour de l'objet dans l'image. Cet exercice peut être un peu amusant au début, mais avec des données très volumineuses, il peut être fatigant.
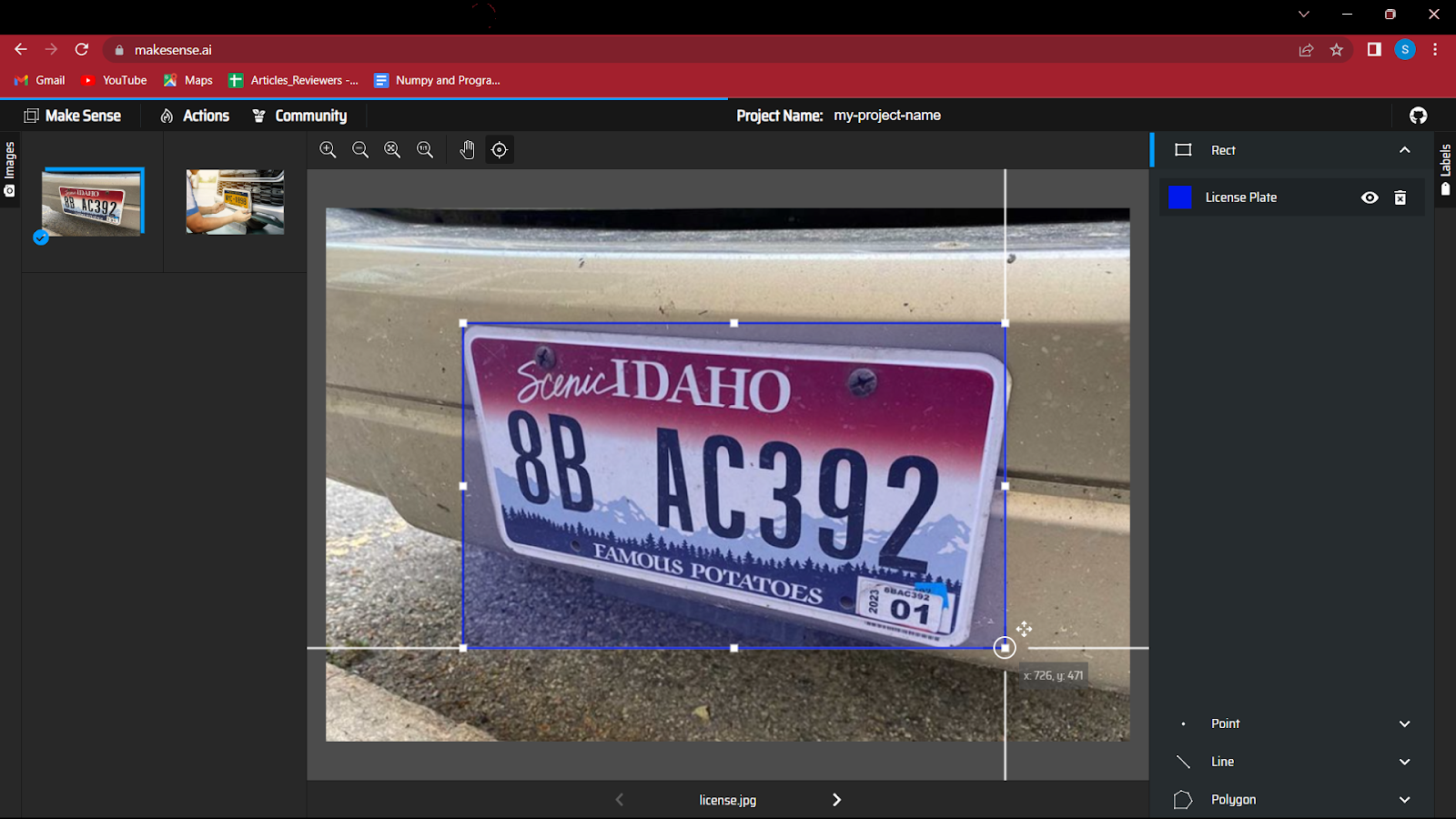
6. Après avoir annoté toutes les images, vous devez enregistrer le fichier qui contiendra les coordonnées des boîtes englobantes avec la classe.
Vous devez donc vous diriger vers le bouton Actions et cliquer sur Exporter les annotations. N'oubliez pas de cocher l'option "Un package zip contenant des fichiers au format YOLO", car cela enregistrera les fichiers dans le bon format, comme requis dans le modèle YOLO.
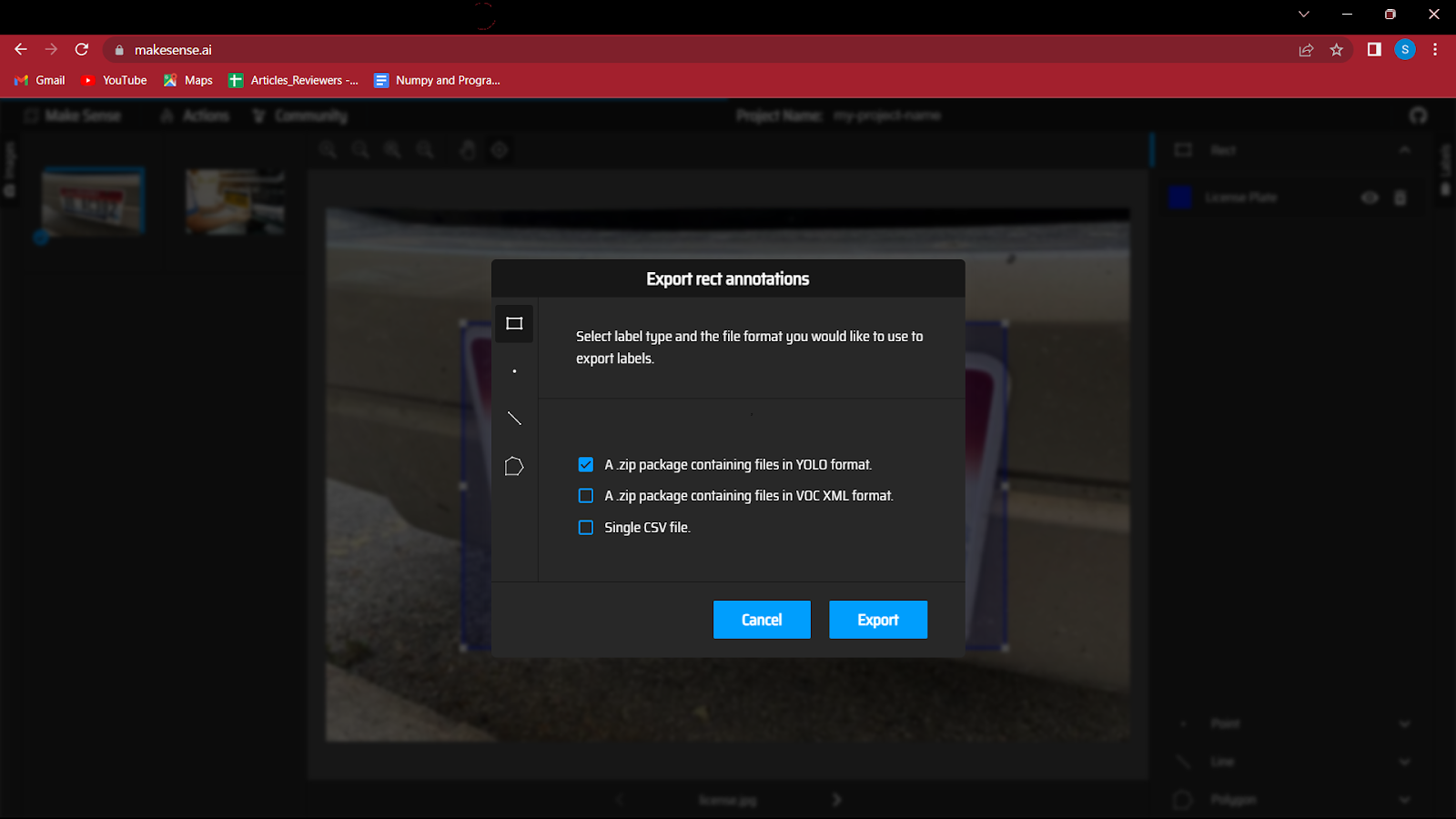
7. Il s'agit d'une étape importante, alors suivez-la attentivement.
Une fois que vous avez tous les fichiers et les images, créez un dossier avec n'importe quel nom. Cliquez sur le dossier et créez deux autres dossiers avec le nom des images et des étiquettes à l'intérieur du dossier. N'oubliez pas de nommer le dossier de la même manière que ci-dessus, car le modèle recherche automatiquement les étiquettes après avoir alimenté le chemin d'apprentissage dans la commande.
Pour vous donner une idée du dossier, j'ai créé un dossier nommé "CarsData" et dans ce dossier j'ai créé deux dossiers - "images" et "étiquettes".
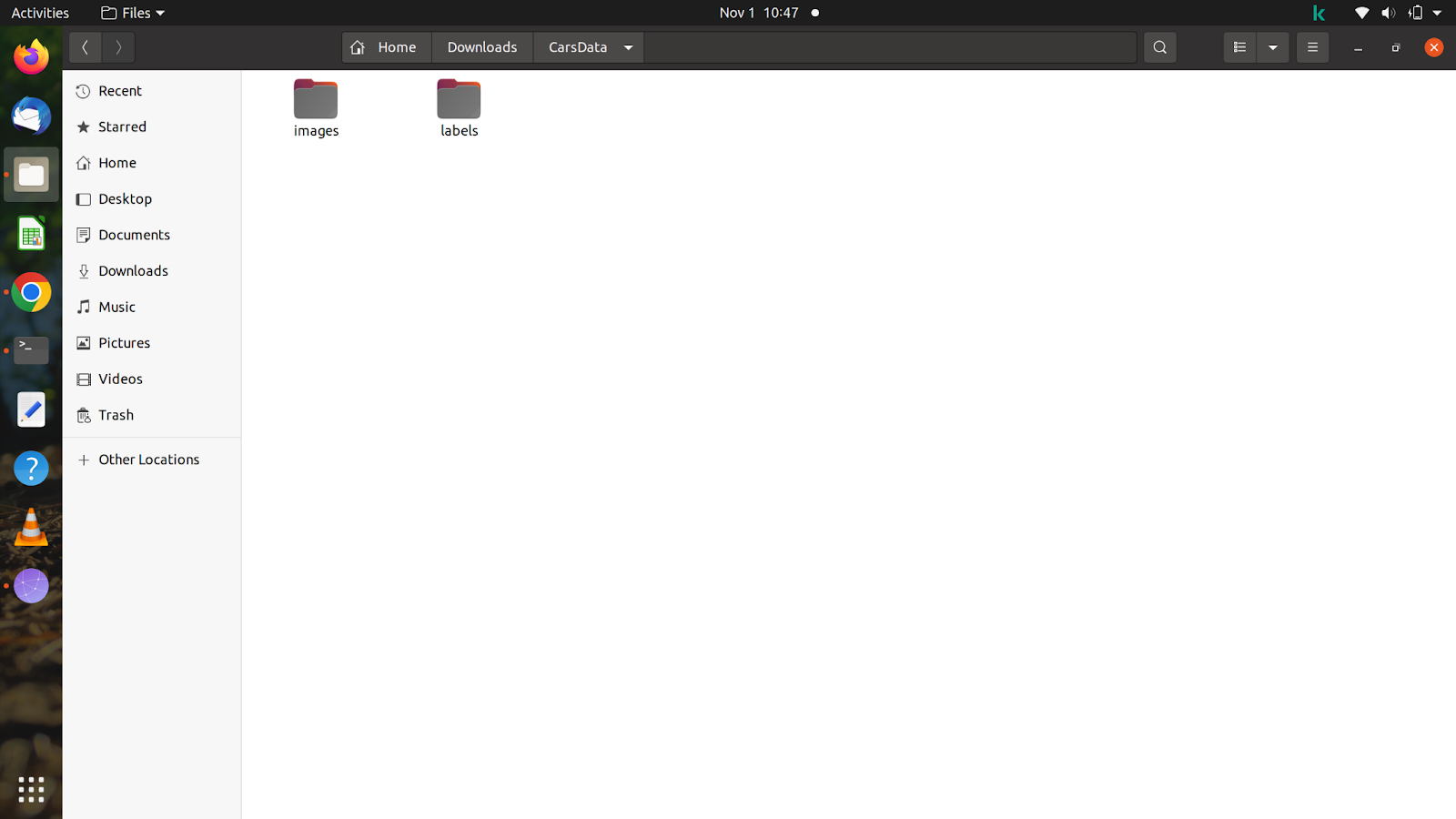
À l'intérieur des deux dossiers, vous devez créer deux autres dossiers nommés 'train' et 'val'. Dans le dossier images, vous pouvez diviser les images selon votre volonté, mais vous devez être prudent lors de la division de l'étiquette, car les étiquettes doivent correspondre aux images que vous avez divisées
8. Créez maintenant un fichier zip du dossier et téléchargez-le sur le lecteur afin que nous puissions l'utiliser dans colab.
Implémentation
Nous allons maintenant passer à la partie implémentation, qui est très simple mais délicate. Si vous ne savez pas exactement quels fichiers modifier, vous ne pourrez pas entraîner le modèle sur le jeu de données personnalisé.
Voici donc les codes que vous devez suivre pour former le modèle YOLOv5 sur un jeu de données personnalisé
Je vous recommande d'utiliser google colab pour ce tutoriel car il fournit également un GPU qui permet des calculs plus rapides.
1. !git clone https://github.com/ultralytics/yolov5
Cela fera une copie du référentiel YOLOv5 qui est un référentiel GitHub créé par ultralytics.
2. cd yolov5
Il s'agit d'une commande shell de ligne de commande utilisée pour remplacer le répertoire de travail actuel par le répertoire YOLOv5.
3. !pip install -r exigences.txt
Cette commande installera tous les packages et bibliothèques utilisés dans la formation du modèle.
4. !décompressez '/content/drive/MyDrive/CarsData.zip'
Décompressez le dossier contenant les images et les étiquettes dans google colab
Voici l'étape la plus importante...
Vous avez maintenant effectué presque toutes les étapes et devez écrire une ligne de code supplémentaire qui formera le modèle, mais, avant cela, vous devez effectuer quelques étapes supplémentaires et modifier certains répertoires afin de donner le chemin de votre jeu de données personnalisé. et entraînez votre modèle sur ces données.
Voici ce que tu dois faire.
Après avoir effectué les 4 étapes ci-dessus, vous aurez le dossier yolov5 dans votre google colab. Allez dans le dossier yolov5 et cliquez sur le dossier 'data'. Vous verrez maintenant un dossier nommé 'coco128.yaml'.
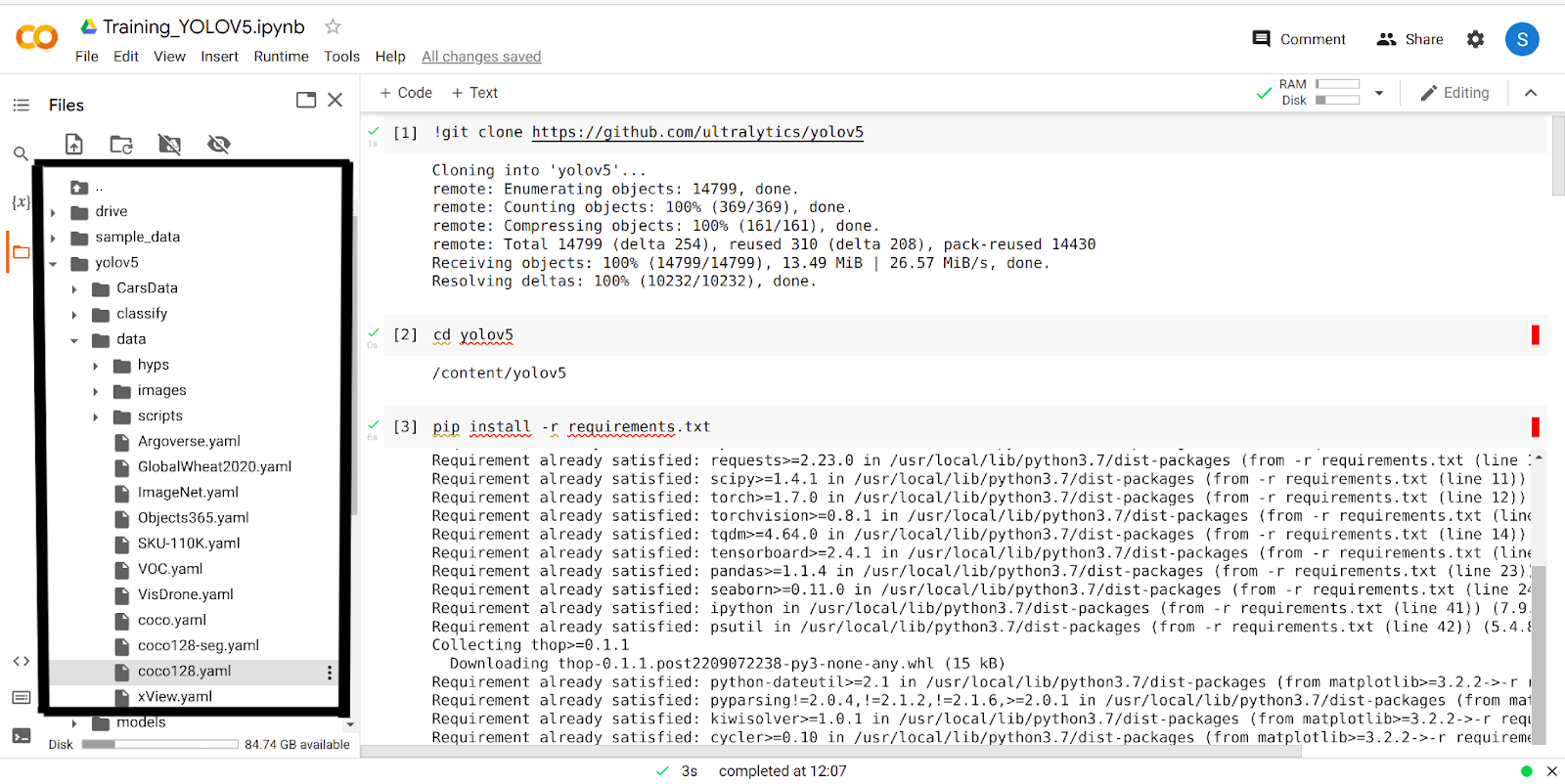
Allez-y et téléchargez ce dossier.
Une fois le dossier téléchargé, vous devez y apporter quelques modifications et le télécharger à nouveau dans le même dossier à partir duquel vous l'avez téléchargé.
Regardons maintenant le contenu du fichier que nous avons téléchargé, et il ressemblera à ceci.
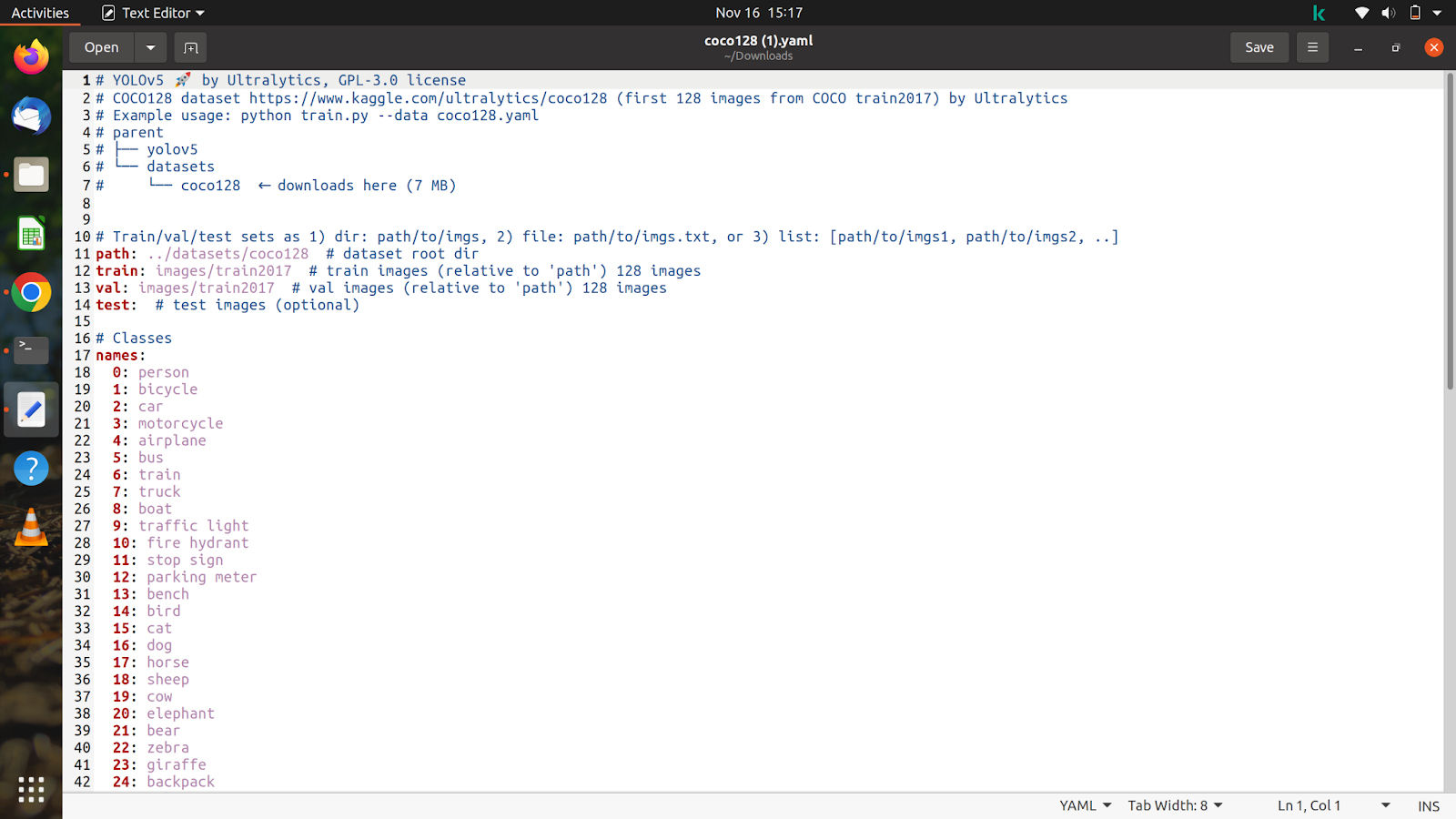
Nous allons personnaliser ce fichier en fonction de notre jeu de données et de nos annotations.
Nous avons déjà décompressé le jeu de données sur colab, nous allons donc copier le chemin de nos images de train et de validation. Après avoir copié le chemin des images du train, qui se trouvera dans le dossier du jeu de données et ressemblera à ceci '/content/yolov5/CarsData/images/train', collez-le dans le fichier coco128.yaml que nous venons de télécharger.
Faites de même avec les images de test et de validation.
Maintenant que nous en aurons fini avec cela, nous mentionnerons le nombre de classes comme 'nc: 1'. Le nombre de classes, dans ce cas, n'est que de 1. Nous mentionnerons ensuite le nom comme indiqué dans l'image ci-dessous. Supprimez toutes les autres classes et la partie commentée, qui n'est pas nécessaire, après quoi notre fichier devrait ressembler à ceci.
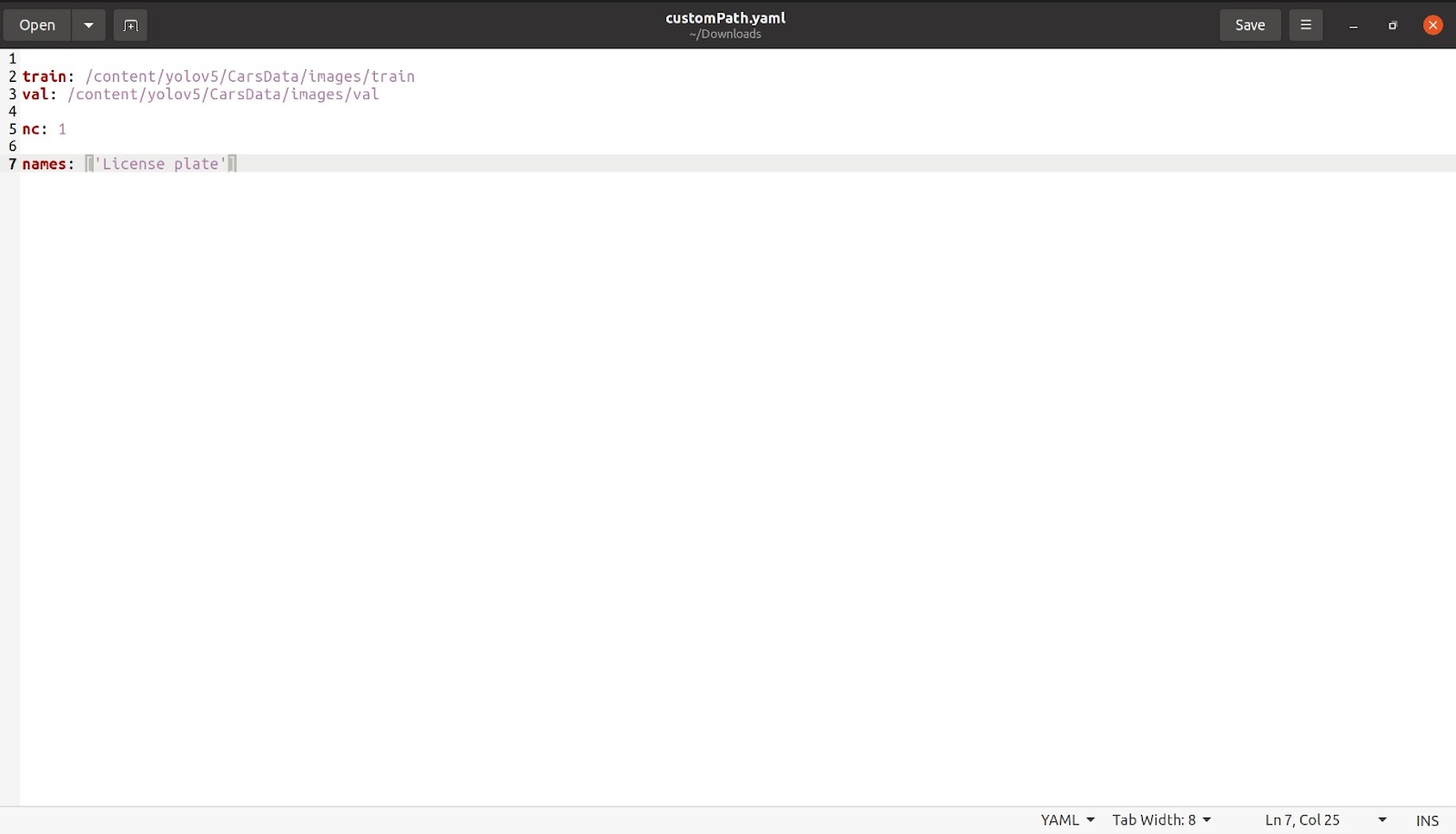
Enregistrez ce fichier avec le nom de votre choix. J'ai enregistré le fichier avec le nom customPath.yaml et je télécharge maintenant ce fichier sur le colab au même endroit où se trouvait coco128.yaml.
Nous en avons maintenant terminé avec la partie édition et sommes prêts à former le modèle.
Exécutez la commande suivante pour entraîner votre modèle à quelques interactions sur votre jeu de données personnalisé.
N'oubliez pas de changer le nom du fichier que vous avez téléchargé ('customPath.yaml). Vous pouvez également modifier le nombre d'époques pendant lesquelles vous souhaitez former le modèle. Dans ce cas, je vais former le modèle uniquement pour 3 époques.
5. !python train.py –img 640 –lot 16 –époques 10 –data /content/yolov5/customPath.yaml –weights yolov5s.pt
Gardez à l'esprit le chemin où vous téléchargez le dossier. Si le chemin est modifié, les commandes ne fonctionneront pas du tout.
Après avoir exécuté cette commande, votre modèle devrait commencer à s'entraîner et vous verrez quelque chose comme ça sur votre écran.
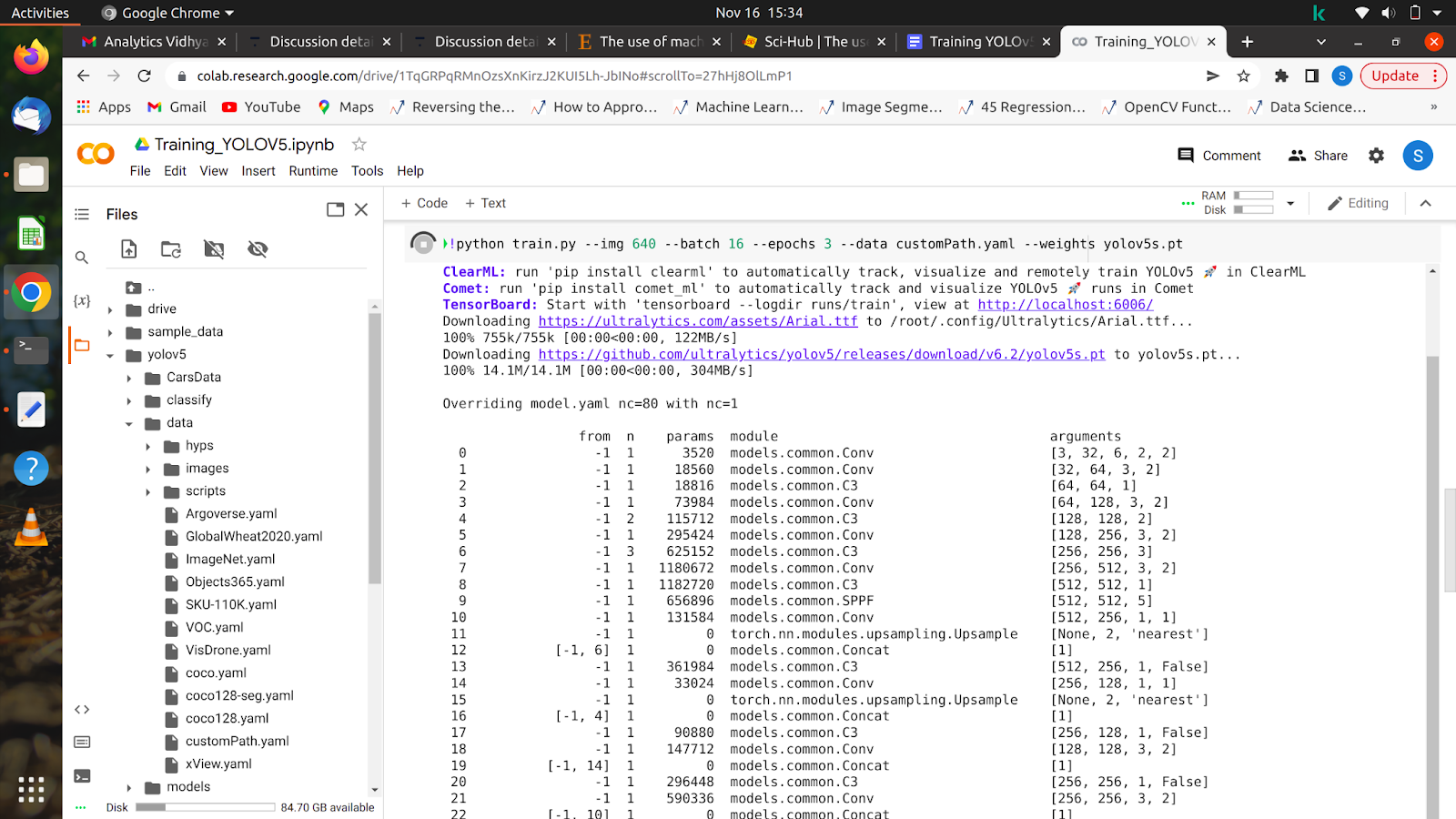
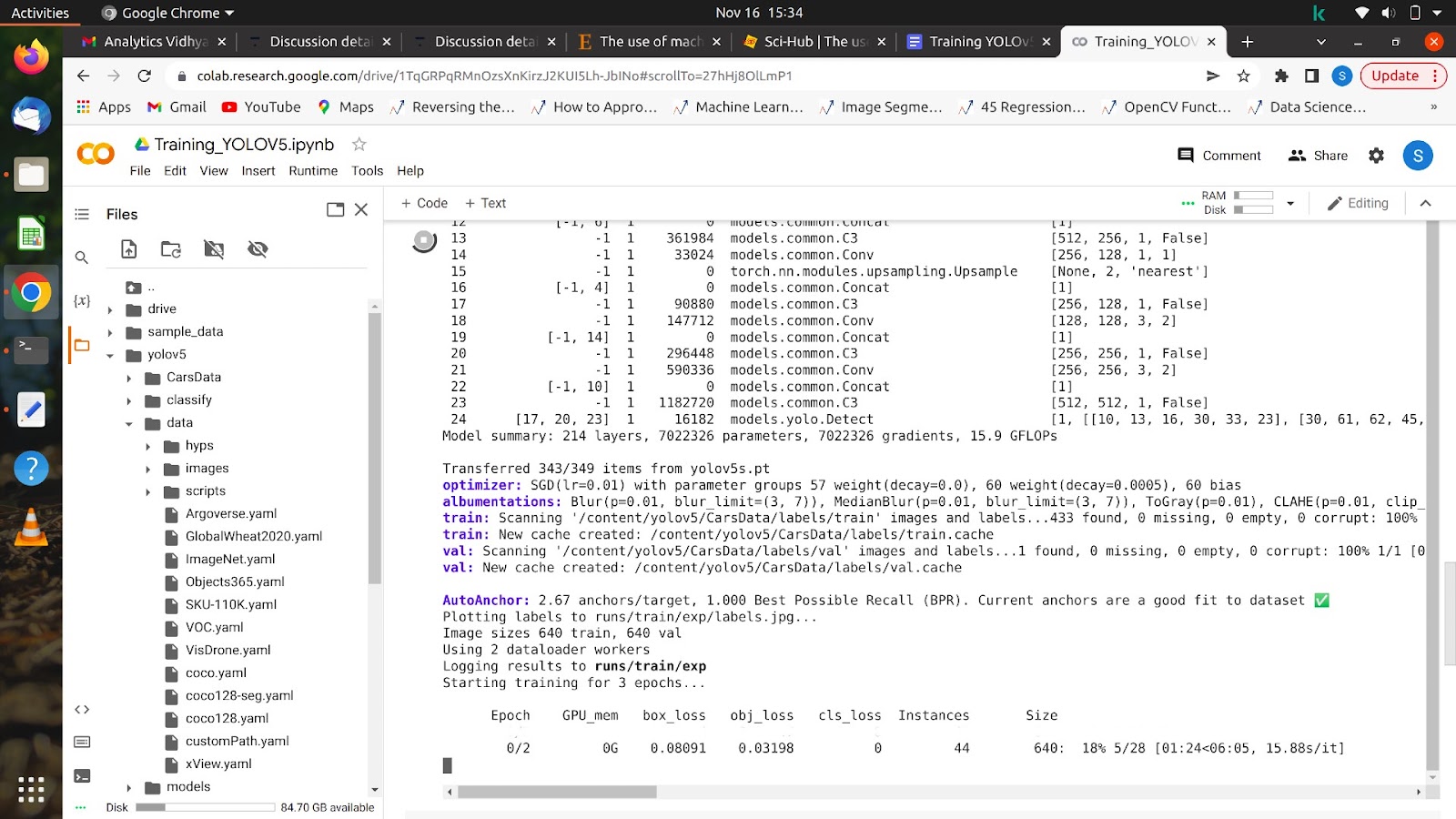
Une fois toutes les époques terminées, votre modèle peut être testé sur n'importe quelle image.
Vous pouvez personnaliser davantage le fichier detect.py sur ce que vous souhaitez enregistrer et ce que vous n'aimez pas, les détections où les plaques d'immatriculation sont détectées, etc.
6. !python detect.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
Vous pouvez utiliser cette commande pour tester la prédiction du modèle sur certaines images.
Quelques défis auxquels vous pouvez faire face
Bien que les étapes expliquées ci-dessus soient correctes, vous pouvez rencontrer certains problèmes si vous ne les suivez pas exactement.
- Mauvais chemin : Cela peut être un mal de tête ou un problème. Si vous avez entré le mauvais chemin quelque part lors de la formation de l'image, il peut être difficile de l'identifier et vous ne pourrez pas former le modèle.
- Mauvais format d'étiquettes : il s'agit d'un problème répandu auquel sont confrontés les utilisateurs lors de la formation d'un YOLOv5. Le modèle n'accepte qu'un format dans lequel chaque image a son propre fichier texte avec le format souhaité à l'intérieur. Souvent, un fichier au format XLS ou un seul fichier CSV est transmis au réseau, ce qui entraîne une erreur. Si vous téléchargez les données quelque part, au lieu d'annoter chaque image, il peut y avoir un format de fichier différent dans lequel les étiquettes sont enregistrées. Voici un article pour convertir le format XLS au format YOLO. (lien après la fin de l'article).
- Ne pas nommer correctement les fichiers : Ne pas nommer correctement le fichier entraînera à nouveau une erreur. Faites attention aux étapes lors de la nomination des dossiers et évitez cette erreur.
Conclusion
Dans cet article, nous avons appris ce qu'est l'apprentissage par transfert et le modèle pré-formé. Nous avons appris quand et pourquoi utiliser le modèle YOLOv5 et comment former le modèle sur un ensemble de données personnalisé. Nous sommes passés par chaque étape, de la préparation de l'ensemble de données à la modification des chemins et enfin à leur transmission au réseau dans la mise en œuvre de la technique, et avons parfaitement compris les étapes. Nous avons également examiné les problèmes courants rencontrés lors de la formation d'un YOLOv5 et leur solution. J'espère que cet article vous a aidé à former votre premier YOLOv5 sur un jeu de données personnalisé et que vous aimez l'article.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- Capable
- au dessus de
- Accepte
- Selon
- précision
- actes
- Après
- devant
- AI
- Tous
- déjà
- quantités
- ainsi que
- architecture
- autour
- article
- précaution
- automatiquement
- disponibles
- éviter
- RETOUR
- basé
- En gros
- before
- ci-dessous
- Améliorée
- Bit
- Bas et Leggings
- Box
- boîtes
- bouton (dans la fenêtre de contrôle qui apparaît maintenant)
- prudent
- prudemment
- maisons
- CD
- Canaux centraux
- globaux
- Change
- Modifications
- en changeant
- vérifier
- choisi
- classe
- les classes
- classification
- code
- comment
- commenté
- Commun
- Communautés
- Complété
- achèvement
- compliqué
- calculs
- confusion
- contient
- contenu
- convertir
- copier
- correctement
- engendrent
- créée
- La création
- Courant
- Customiser
- personnalisation
- personnaliser
- Darknet
- données
- Préparation des données
- Data Scientist
- profond
- l'apprentissage en profondeur
- Définit
- dépend
- détecté
- Détection
- Dialogue
- différent
- directement
- répertoires
- découverte
- plusieurs
- faire
- Ne pas
- download
- motivation
- chacun
- Facilite
- éduquer
- Efficace
- de manière efficace
- efficace
- Entrer
- entré
- époques
- erreur
- etc
- Pourtant, la
- Chaque
- exactement
- exemple
- Exercises
- Expliquer
- expliqué
- expliquant
- Exporter
- extraordinairement
- Visage
- face
- RAPIDE
- plus rapide
- Fed
- alimentation
- few
- Déposez votre dernière attestation
- Fichiers
- finalement
- Prénom
- première fois
- Focus
- suivre
- Abonnement
- le format
- Framework
- de
- amusement
- obtenez
- GitHub
- Donner
- Go
- aller
- Bien
- GPU
- front
- entendu
- aider
- a aidé
- ici
- Surbrillance
- très
- frappe
- d'espérance
- Comment
- How To
- HTTPS
- majeur
- idée
- Identification
- identifier
- image
- satellite
- la mise en oeuvre
- important
- in
- possible
- installer
- plutôt ;
- interactions
- Internet
- impliqué
- IT
- Savoir
- spécialisées
- Libellé
- Etiquettes
- gros
- grande échelle
- plus importantes
- poules pondeuses
- conduire
- APPRENTISSAGE
- savant
- apprentissage
- bibliothèques
- Licence
- Gamme
- LINK
- chargement
- Style
- regardé
- LOOKS
- LES PLANTES
- faire
- Fabrication
- marqué
- Match
- Matière
- largeur maximale
- veux dire
- méthodes
- pourrait
- des millions
- l'esprit
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- prénom
- Nommé
- nommage
- Besoin
- nécessaire
- réseau et
- réseaux
- nombre
- objet
- Détection d'objet
- ONE
- optimisé
- Option
- de commander
- Autre
- propre
- paquet
- Forfaits
- partie
- chemin
- Payer
- Personnes
- effectuer
- performant
- effectuer
- effectue
- Place
- Platon
- Intelligence des données Platon
- PlatonDonnées
- prévoir
- prédiction
- en train de préparer
- précédent
- précédemment
- Problème
- d'ouvrabilité
- processus
- Projet
- proven
- fournit
- but
- pytorch
- solutions
- en temps réel
- récent
- recommander
- raffiné
- supprimez
- dépôt
- exigent
- conditions
- Exigences
- résultant
- Résultats
- Courir
- même
- Épargnez
- économie
- Scientifique
- scientifiques
- pour écran
- besoin
- coquillage
- devrait
- montrer
- montré
- significative
- similaires
- étapes
- simplement
- depuis
- unique
- So
- sur mesure
- quelques
- quelque chose
- quelque part
- scission
- empilé
- peuplements
- Commencer
- j'ai commencé
- étapes
- Étapes
- structure
- tel
- Prenez
- Tâche
- tâches
- Technologie
- conditions
- tester
- La
- leur
- complètement
- Avec
- fiable
- long
- à
- ensemble
- top
- Train
- qualifié
- Formation
- transférer
- Transfert
- tutoriel
- typiquement
- comprendre
- compris
- utilisé
- d'habitude
- validation
- divers
- véhicule
- version
- Site Web
- sites Internet
- Semaines
- Quoi
- qui
- tout en
- largement
- répandu
- sera
- sans
- Activités:
- de travail
- pourra
- écrire
- faux
- yaml
- Yolo
- Votre
- zéphyrnet
- Zip