Ceci est un article invité co-écrit avec Raghu Boppanna de Vanguard.
At avant-garde, la ligne d'activité Enterprise Advice améliore les résultats des investisseurs grâce à un accès numérique à des conseils financiers de qualité supérieure, personnalisés et abordables. Ils ont rendu cela possible, en partie, en générant des économies d'échelle à travers le monde pour les investisseurs grâce à une plate-forme technique hautement résiliente et efficace. Vanguard a opté pour une architecture multirégionale pour cette charge de travail afin de se protéger contre les défaillances des services régionaux. À des fins de haute disponibilité, il est nécessaire de rendre les données utilisées par la charge de travail disponibles non seulement dans la région principale, mais également dans la région secondaire avec un délai de réplication minimal. En cas de défaillance du service dans la région principale, la solution doit pouvoir basculer vers la région secondaire avec le moins de perte de données possible et la possibilité de reprendre l'ingestion des données.
Vanguard Cloud Technology Office et AWS se sont associés pour créer une solution d'infrastructure sur AWS qui répondait à leurs exigences de résilience. La solution multi-régions permet un mécanisme de basculement robuste, avec observabilité et récupération intégrées. La solution prend également en charge la diffusion en continu de données provenant de plusieurs sources vers différents flux de données Kinesis. La solution est en cours de déploiement auprès des différentes équipes métiers pour améliorer la posture de résilience de leurs charges de travail.
Le cas d'utilisation décrit ici nécessite Change Data Capture (CDC) pour diffuser des données à partir d'une source de données distante (mainframe DB2) vers Flux de données Amazon Kinesis, car la capacité métier dépend de ces données. Kinesis Data Streams est un service de streaming entièrement géré, massivement évolutif, durable et peu coûteux qui peut capturer et diffuser en continu de grandes quantités de données à partir de plusieurs sources, et rend les données disponibles pour une consommation en quelques millisecondes. Le service est conçu pour être hautement résilient et utilise plusieurs zones de disponibilité pour traiter et stocker les données.
La solution décrite dans cet article explique comment AWS et Vanguard ont innové pour créer une architecture résiliente afin d'atteindre leurs objectifs de haute disponibilité.
Vue d'ensemble de la solution
La solution utilise AWS Lambda pour répliquer les données des flux de données Kinesis de la région principale vers une région secondaire. En cas de défaillance du service affectant le pipeline CDC, le processus de basculement promeut la région secondaire en région primaire pour les producteurs et les consommateurs. Nous utilisons Tables globales Amazon DynamoDB pour les points de contrôle de réplication qui permet de reprendre le flux de données à partir du point de contrôle et maintient également un indicateur de configuration de région primaire qui empêche une boucle de réplication infinie des mêmes données dans les deux sens.
La solution offre également la flexibilité aux consommateurs Kinesis Data Streams d'utiliser la région principale ou toute région secondaire au sein du même compte AWS.
Le schéma suivant illustre l'architecture de référence.
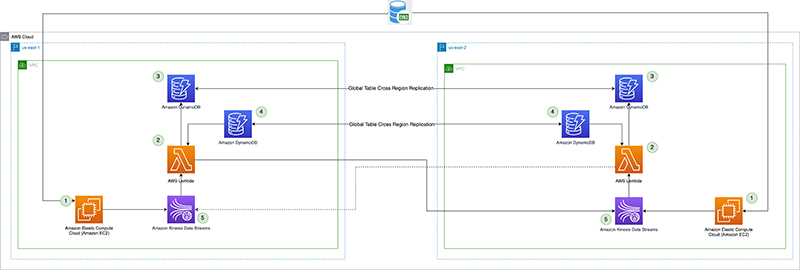
Regardons chaque composant en détail :
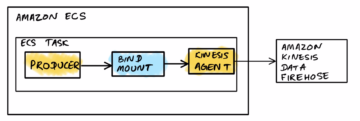
- Processeur CDC (producteur) – Dans cette architecture de référence, le producteur est déployé sur Cloud de calcul élastique Amazon (Amazon EC2) dans les régions principale et secondaire, et est actif dans la région principale et en mode veille dans la région secondaire. Il capture les données CDC à partir de la source de données externe (comme une base de données DB2, comme illustré dans l'architecture ci-dessus) et les diffuse vers Kinesis Data Streams dans la région principale. L'avant-garde utilise un 3rd l'outil de fête Qlik Replicate en tant que processeur CDC. Il produit une charge utile bien formée comprenant l'horodatage de validation DB2 dans le flux de données Kinesis, en plus des données de ligne réelles de la source de données distante. (
example-stream-1dans cet exemple). Le code suivant est un exemple de charge utile contenant uniquement la clé primaire de l'enregistrement qui a changé et l'horodatage de validation (pour plus de simplicité, le reste des données de la ligne du tableau n'est pas affiché ci-dessous) :{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }La valeur décodée en Base64 de
Dataest comme suit. L'enregistrement Kinesis réel contiendrait l'intégralité des données de ligne de la ligne de table modifiée, en plus de la clé primaire et de l'horodatage de validation.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}La
CommitTimestampdans l'Dataest utilisé dans le point de contrôle de réplication et est essentiel pour suivre avec précision la quantité de données de flux qui a été répliquée dans la région secondaire. Le point de contrôle peut ensuite être utilisé pour faciliter un basculement de processeur CDC (producteur) et reprendre avec précision la production de données à partir de l'horodatage du point de contrôle de réplication.L'alternative à l'utilisation d'une source de données distante
CommitTimestamp(si non disponible) est d'utiliser leApproximateArrivalTimestamp(qui est l'horodatage lorsque l'enregistrement est réellement écrit dans le flux de données). - Fonction Lambda de réplication entre régions – La fonction est déployée dans les régions primaires et secondaires. Il est configuré avec un mappage de source d'événement sur le flux de données contenant des données CDC. La même fonction peut être utilisée pour répliquer les données de plusieurs flux. Il est appelé avec un lot d'enregistrements de Kinesis Data Streams et réplique le lot dans une région de réplication cible (qui est fournie via l'environnement de configuration Lambda). Pour des considérations de coût, si les données CDC sont produites activement dans la région primaire uniquement, la simultanéité réservée de la fonction dans la région secondaire peut être définie sur zéro et modifiée lors du basculement régional. La fonction a Gestion des identités et des accès AWS (IAM) des autorisations de rôle pour effectuer les opérations suivantes :
- Lisez et écrivez dans les tables globales DynamoDB utilisées dans cette solution, au sein du même compte.
- Lire et écrire dans Kinesis Data Streams dans les deux régions au sein du même compte.
- Publiez des métriques personnalisées sur Amazon Cloud Watch dans les deux régions au sein du même compte.
- Point de contrôle de réplication – Le point de contrôle de réplication utilise la table globale DynamoDB dans les régions primaire et secondaire. Il est utilisé par la fonction Lambda de réplication entre régions pour conserver l'horodatage de validation du dernier enregistrement de réplication en tant que point de contrôle de réplication pour chaque flux configuré pour la réplication. Pour cet article, nous créons et utilisons une table globale appelée
kdsReplicationCheckpoint. - Configuration de la région active – La région active utilise la table globale DynamoDB dans les régions principale et secondaire. Il utilise la capacité de réplication interrégionale native de la table globale pour répliquer la configuration. Il est pré-rempli avec des données indiquant quelle est la région principale d'un flux, afin d'empêcher la réplication vers la région principale par la fonction Lambda dans la région de secours. Cette configuration peut ne pas être requise si la fonction Lambda dans la région de secours a une simultanéité réservée définie sur zéro, mais peut servir de contrôle de sécurité pour éviter une boucle de réplication infinie des données. Pour cet article, nous créons une table globale appelée
kdsActiveRegionConfiget mettre un élément avec les données suivantes :{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Flux de données Kinesis – Le flux auquel le processeur CDC produit les données. Pour cet article, nous utilisons un flux appelé
example-stream-1dans les deux régions, avec la même configuration de partition et les mêmes politiques d'accès.
Séquence d'étapes dans la réplication entre régions
Voyons brièvement comment l'architecture est exercée à l'aide du diagramme de séquence suivant.
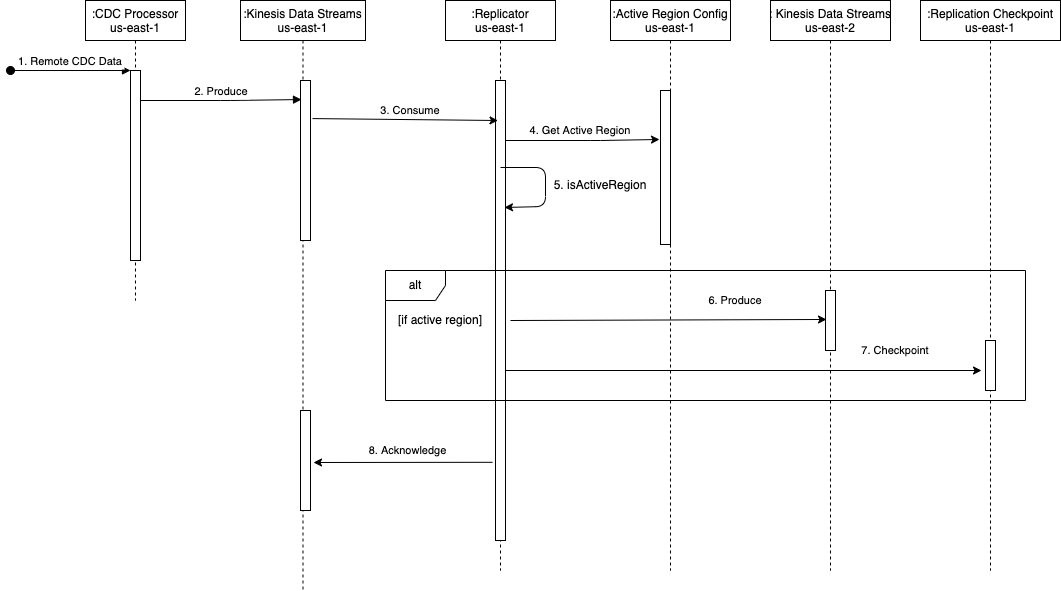
La séquence comprend les étapes suivantes :
- Le processeur CDC (en
us-east-1) lit les données CDC à partir de la source de données distante. - Le processeur CDC (en
us-east-1) diffuse les données CDC vers Kinesis Data Streams (enus-east-1). - La fonction Lambda de réplication entre régions (dans us-east-1) consomme les données du flux de données (dans
us-east-1). Le modèle de sortance amélioré est recommandé pour un débit dédié et accru pour la réplication entre régions. - La fonction Lambda du réplicateur (dans
us-east-1) valide sa région actuelle avec la configuration de région active pour le flux consommé, à l'aide dukdsActiveRegionConfigTable globale DynamoDBL'exemple de code suivant (en Java) peut aider à illustrer la condition en cours d'évaluation :// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - La fonction évalue la réponse de DynamoDB avec le code suivant :
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - En fonction de la réponse, la fonction effectue les actions suivantes :
- Si la réponse est
true, la fonction de réplicateur produit les enregistrements vers Kinesis Data Streams dansus-east-2de manière séquentielle.- En cas d'échec, le numéro de séquence de l'enregistrement est suivi et l'itération est interrompue. La fonction renvoie la liste des numéros de séquence ayant échoué. En renvoyant le numéro de séquence ayant échoué, la solution utilise la fonction de Point de contrôle Lambda pour pouvoir reprendre le traitement d'un lot d'enregistrements avec des échecs partiels. Ceci est utile lors de la gestion des défaillances de service, où la fonction tente de répliquer les données dans les régions pour garantir la parité des flux et aucune perte de données.
- S'il n'y a pas d'échec, une liste vide est renvoyée, ce qui indique que le lot a réussi.
- Si la réponse est
false, la fonction de réplication revient sans effectuer de réplication. Pour réduire le coût des appels Lambda, vous pouvez définir la simultanéité réservée de la fonction dans la région DR (us-east-2) à zéro. Cela empêchera l'appel de la fonction. Lorsque vous basculez, vous pouvez mettre à jour cette valeur à un nombre approprié en fonction du débit CDC et définir la simultanéité réservée de la fonction dansus-east-1à zéro pour l'empêcher de s'exécuter inutilement.
- Si la réponse est
- Une fois tous les enregistrements produits dans Kinesis Data Streams dans
us-east-2, la fonction de réplication vérifie les points dekdsReplicationCheckpointTable globale DynamoDB (dansus-east-1) avec les données suivantes :{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - La fonction revient après avoir traité avec succès le lot d'enregistrements.
Considérations relatives aux performances
Les performances attendues de la solution doivent être comprises par rapport aux facteurs suivants :
- Sélection de la région - La latence de réplication est directement proportionnelle à la distance parcourue par les données, alors comprenez votre sélection de région
- Vitesse – La vitesse d'entrée des données ou le volume de données en cours de réplication
- Taille de la charge utile – La taille de la charge utile en cours de réplication
Surveiller la réplication entre régions
Il est recommandé de suivre et d'observer la réplication au fur et à mesure qu'elle se produit. Vous pouvez personnaliser la fonction Lambda pour publier des métriques personnalisées sur CloudWatch avec les métriques suivantes à la fin de chaque appel. La publication de ces métriques à la fois dans les régions primaires et secondaires vous aide à vous protéger des déficiences affectant l'observabilité dans la région primaire.
- Cadence de production – La taille actuelle du lot d'appel Lambda
- ReplicationLagSeconds – La différence entre l'horodatage actuel (après traitement de tous les enregistrements) et le
ApproximateArrivalTimestampdu dernier enregistrement qui a été répliqué
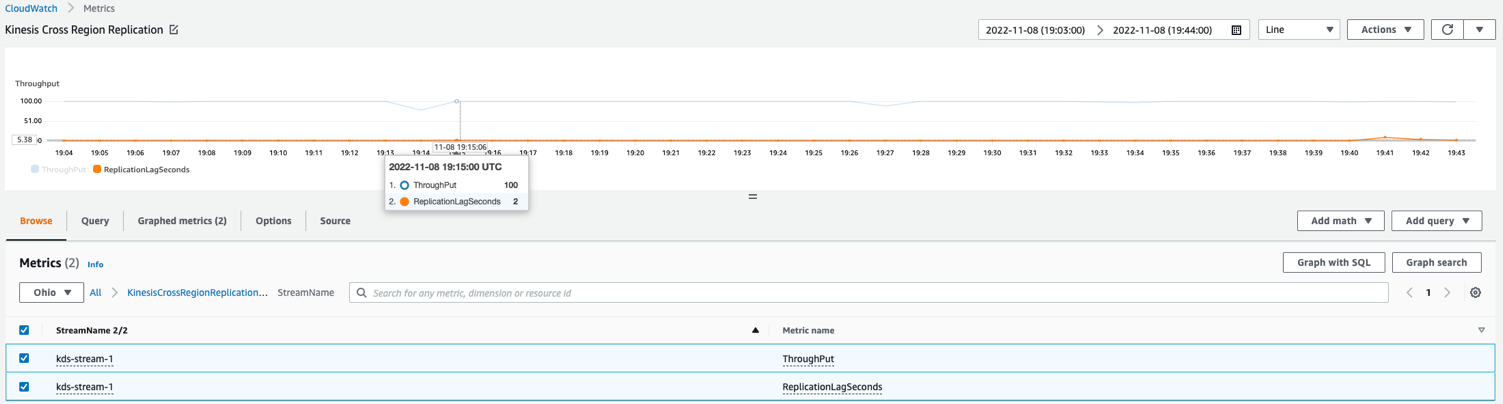
L'exemple de graphique de métrique CloudWatch suivant montre que le décalage de réplication moyen était de 2 secondes avec un débit de 100 enregistrements répliqués à partir de us-east-1 à us-east-2.
Stratégie de basculement commune
Lors de toute défaillance affectant le pipeline CDC dans la région primaire, les besoins de continuité des activités ou de reprise après sinistre peuvent dicter un basculement du pipeline vers la région secondaire (de secours). Cela signifie que certaines choses doivent être faites dans le cadre de ce processus de basculement :
- Si possible, arrêtez toutes les tâches CDC dans l'outil de processeur CDC dans
us-east-1. - Le processeur CDC doit être basculé vers la région secondaire, afin qu'il puisse lire les données CDC à partir de la source de données distante tout en fonctionnant hors de la région de secours.
- La
kdsActiveRegionConfigLa table globale DynamoDB doit être mise à jour. Par exemple, pour le fluxexample-stream-1utilisé dans notre exemple, la région active est changée enus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Tous les points de contrôle de flux doivent être lus à partir du
kdsReplicationCheckpointTable globale DynamoDB (dansus-east-2), et les horodatages de chacun des points de contrôle sont utilisés pour démarrer les tâches CDC dans l'outil producteur dansus-east-2Région. Cela minimise les risques de perte de données et reprend avec précision la diffusion des données CDC à partir de la source de données distante à partir de l'horodatage du point de contrôle. - Si vous utilisez la simultanéité réservée pour contrôler les appels Lambda, définissez la valeur sur zéro dans la région principale (
us-east-1) et à une valeur non nulle appropriée dans la région secondaire (us-east-2).
Stratégie de basculement en plusieurs étapes de Vanguard
Certains des outils tiers utilisés par Vanguard ont un processus CDC en deux étapes de diffusion de données d'une source de données distante vers une destination. L'outil de choix de Vanguard pour son processeur CDC suit cette approche en deux étapes :
- La première étape consiste à configurer une tâche de flux de journaux qui lit les données à partir de la source de données distante et les conserve dans un emplacement intermédiaire.
- La deuxième étape consiste à configurer des tâches de consommateur individuelles qui lisent les données à partir de l'emplacement intermédiaire, qui peut être sur Système de fichiers Amazon Elastic (AmazonEFS) ou Amazon FSx, par exemple, et diffusez-le vers la destination. La flexibilité ici est que chacune de ces tâches de consommateur peut être déclenchée pour diffuser à partir de différents horodatages de validation. La tâche de flux de journaux commence généralement à lire les données à partir du minimum de tous les horodatages de validation utilisés par les tâches de consommateur.
Prenons un exemple pour expliquer le scénario :
- La tâche consommateur A diffuse des données à partir d'un horodatage de validation à partir du 2022-07-19T20:00:00 vers
example-stream-1. - La tâche consommateur B diffuse des données à partir d'un horodatage de validation à partir du 2022-07-19T21:00:00 vers
example-stream-2. - Dans cette situation, le flux de journaux doit lire les données de la source de données distante à partir du minimum des horodatages utilisés par les tâches client, à savoir 2022-07-19T20:00:00.
Le diagramme de séquence suivant illustre les étapes exactes à exécuter lors d'un basculement vers us-east-2 (la région de veille).
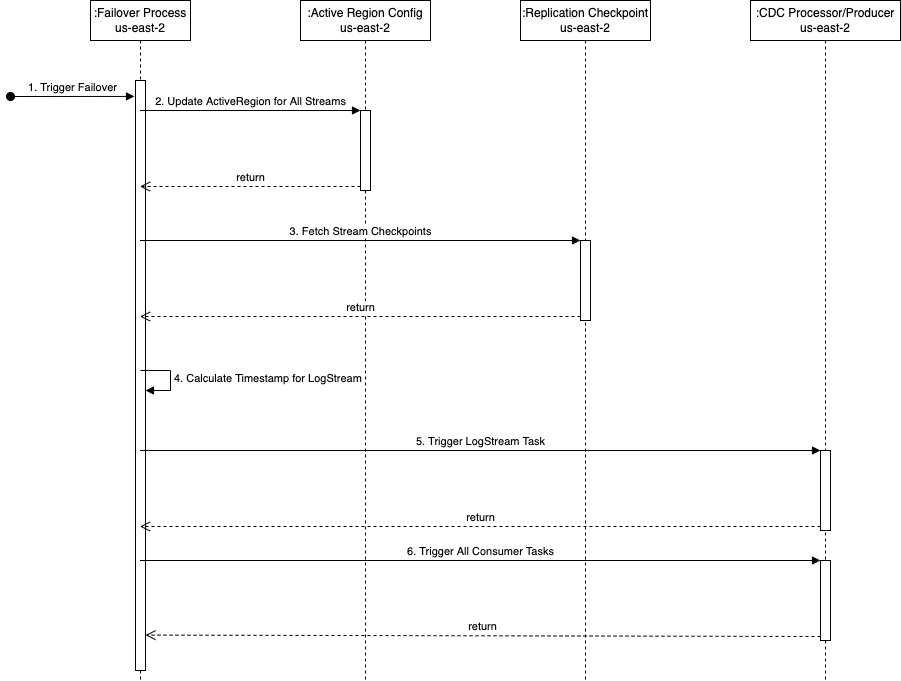
Les étapes sont les suivantes:
- Le processus de basculement est déclenché dans la région de veille (
us-east-2dans cet exemple) si nécessaire. Notez que le déclencheur peut être automatisé à l'aide de vérifications complètes de l'état du pipeline dans la région principale. - Le processus de basculement met à jour la table globale kdsActiveRegionConfig DynamoDB avec la nouvelle valeur de la région comme
us-east-2pour tous les noms de flux. - L'étape suivante consiste à récupérer tous les points de contrôle de flux à partir du
kdsReplicationCheckpointTable globale DynamoDB (dansus-east-2). - Une fois les informations de point de contrôle lues, le processus de basculement trouve le minimum de tous les
lastReplicatedTimestamp. - La tâche de flux de journaux dans l'outil de processeur CDC est démarrée dans
us-east-2avec l'horodatage trouvé à l'étape 4. Il commence à lire les données CDC à partir de la source de données distante à partir de cet horodatage et les conserve dans l'emplacement intermédiaire sur AWS. - L'étape suivante consiste à démarrer toutes les tâches du consommateur pour lire les données à partir de l'emplacement intermédiaire et les diffuser vers le flux de données de destination. C'est là que chaque tâche consommateur reçoit l'horodatage approprié du
kdsReplicationCheckpointtableau selon lestreamNameauquel la tâche transmet les données.
Une fois toutes les tâches client démarrées, les données sont produites dans les flux de données Kinesis dans us-east-2. À partir de là, le processus de réplication entre régions est le même que celui décrit précédemment - la fonction Lambda de réplication dans us-east-2 commence à répliquer les données dans le flux de données dans us-east-1.
Les applications grand public qui lisent les données des flux doivent être idempotentes pour pouvoir gérer les doublons. Des doublons peuvent être introduits dans le flux pour de nombreuses raisons, dont certaines sont décrites ci-dessous.
- Le producteur ou le processeur CDC introduit des doublons dans le flux lors de la relecture des données CDC lors d'un basculement
- DynamoDB Global Table utilise la réplication asynchrone des données entre les régions et si le
kdsReplicationCheckpointles données de la table ont un décalage de réplication, le processus de basculement peut potentiellement utiliser un horodatage de point de contrôle plus ancien pour relire les données CDC.
En outre, les applications grand public doivent vérifier le CommitTimestamp du dernier enregistrement consommé. Ceci afin de faciliter une meilleure surveillance et récupération.
Chemin vers la maturité : récupération automatisée
L'état idéal consiste à automatiser entièrement le processus de basculement, en réduisant le temps de récupération et en respectant l'objectif de niveau de service (SLO) de résilience. Cependant, dans la plupart des organisations, la décision de basculer, de restaurer et de déclencher le basculement nécessite une intervention manuelle pour évaluer la situation et décider du résultat. La création d'une automatisation scriptée pour effectuer le basculement qui peut être exécuté par un humain est un bon point de départ.
Vanguard a automatisé toutes les étapes du basculement, mais les humains décident toujours quand l'invoquer. Vous pouvez personnaliser la solution pour répondre à vos besoins et en fonction de l'outil de processeur CDC que vous utilisez dans votre environnement.
Conclusion
Dans cet article, nous avons décrit comment Vanguard a innové et créé une solution pour répliquer les données entre les régions dans Kinesis Data Streams afin de rendre les données hautement disponibles. Nous avons également démontré une stratégie de point de contrôle robuste pour faciliter un basculement régional du processus de réplication en cas de besoin. La solution a également illustré comment utiliser les tables globales DynamoDB pour suivre les points de contrôle et la configuration de la réplication. Grâce à cette architecture, Vanguard a pu déployer des charges de travail en fonction des données CDC dans plusieurs régions pour répondre aux besoins commerciaux de haute disponibilité face aux défaillances de service affectant les pipelines CDC dans la région principale.
Si vous avez des commentaires, veuillez laisser un commentaire dans la section Commentaires ci-dessous.
À propos des auteurs
 Raghu Boppanna travaille comme architecte d'entreprise au Chief Technology Office de Vanguard. Raghu est spécialisé dans l'analyse de données, la migration/réplication de données, y compris les pipelines CDC, la reprise après sinistre et les bases de données. Il a obtenu plusieurs certifications AWS, notamment AWS Certified Security - Specialty et AWS Certified Data Analytics - Specialty.
Raghu Boppanna travaille comme architecte d'entreprise au Chief Technology Office de Vanguard. Raghu est spécialisé dans l'analyse de données, la migration/réplication de données, y compris les pipelines CDC, la reprise après sinistre et les bases de données. Il a obtenu plusieurs certifications AWS, notamment AWS Certified Security - Specialty et AWS Certified Data Analytics - Specialty.
 Parameswaran V Vaidyanathan est architecte senior en résilience cloud chez Amazon Web Services. Il aide les grandes entreprises à atteindre leurs objectifs commerciaux en concevant et en créant des solutions évolutives et résilientes sur le cloud AWS.
Parameswaran V Vaidyanathan est architecte senior en résilience cloud chez Amazon Web Services. Il aide les grandes entreprises à atteindre leurs objectifs commerciaux en concevant et en créant des solutions évolutives et résilientes sur le cloud AWS.
 Richa Kaul est un leader principal des solutions client au service des clients des services financiers. Elle est basée à New York. Elle possède une vaste expérience dans la transformation cloud à grande échelle, l'excellence des employés et les solutions numériques de nouvelle génération. Elle et son équipe se concentrent sur l'optimisation de la valeur du cloud en créant des solutions performantes, résilientes et agiles. Richa aime les sports multiples comme les triathlons, la musique et l'apprentissage des nouvelles technologies.
Richa Kaul est un leader principal des solutions client au service des clients des services financiers. Elle est basée à New York. Elle possède une vaste expérience dans la transformation cloud à grande échelle, l'excellence des employés et les solutions numériques de nouvelle génération. Elle et son équipe se concentrent sur l'optimisation de la valeur du cloud en créant des solutions performantes, résilientes et agiles. Richa aime les sports multiples comme les triathlons, la musique et l'apprentissage des nouvelles technologies.
 Mithil Prasad est responsable principal des solutions client chez Amazon Web Services. Dans son rôle, Mithil travaille avec les clients pour stimuler la réalisation de la valeur du cloud, fournir un leadership éclairé pour aider les entreprises à atteindre la vitesse, l'agilité et l'innovation.
Mithil Prasad est responsable principal des solutions client chez Amazon Web Services. Dans son rôle, Mithil travaille avec les clients pour stimuler la réalisation de la valeur du cloud, fournir un leadership éclairé pour aider les entreprises à atteindre la vitesse, l'agilité et l'innovation.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
- 1
- 100
- 2022
- 28
- a
- capacité
- Capable
- À propos
- au dessus de
- accès
- Selon
- Compte
- avec précision
- atteindre
- à travers
- actes
- infection
- activement
- actually
- ajout
- conseils
- affectant
- abordables
- Après
- à opposer à
- agile
- Tous
- permet
- alternative
- Amazon
- Amazon EC2
- Amazon Kinésis
- Amazon Web Services
- quantités
- analytique
- ainsi que
- applications
- une approche
- approprié
- architecture
- automatiser
- Automatisation
- Automation
- disponibilité
- disponibles
- moyen
- éviter
- AWS
- Certifié AWS
- RETOUR
- basé
- car
- va
- ci-dessous
- Améliorée
- jusqu'à XNUMX fois
- brièvement
- Cassé
- construire
- Développement
- construit
- intégré
- la performance des entreprises
- continuité de l'activité
- entreprises
- appelé
- capturer
- captures
- maisons
- CDC
- certifications
- Support et maintenance de Salesforce
- chances
- Change
- vérifier
- Contrôles
- chef
- le choix
- le cloud
- TECHNOLOGIE CLOUD
- code
- commentaire
- commentaires
- commettre
- composant
- complet
- calcul
- condition
- configuration
- considérations
- consommées
- consommateur
- Les consommateurs
- consommation
- continuellement
- des bactéries
- Prix
- pourriez
- Couples
- engendrent
- La création
- critique
- Courant
- Lecture
- Customiser
- des clients
- Solutions clients
- Clients
- personnaliser
- données
- Analyse de Donnée
- La perte de données
- Base de données
- bases de données
- Décider
- décision
- dévoué
- démontré
- démontre
- Selon
- dépend
- déployer
- déployé
- décrit
- destination
- détail
- différence
- différent
- numérique
- directement
- catastrophe
- discuté
- distance
- motivation
- conduite
- doublons
- pendant
- chacun
- Plus tôt
- Notre expertise
- économies
- Économies d'échelle
- efficace
- Employés
- permet
- améliorée
- assurer
- Entreprise
- entreprises
- Tout
- Environment
- Ether (ETH)
- évaluer
- évalué
- événement
- Chaque
- exemple
- Excellence
- exécution
- attentes
- attendu
- Découvrez
- Expliquer
- Explique
- les
- externe
- Visage
- faciliter
- facteurs
- FAIL
- Échoué
- Échec
- Fonctionnalité
- Réactions
- champ
- Déposez votre dernière attestation
- la traduction de documents financiers
- services financiers
- trouve
- Prénom
- Flexibilité
- Focus
- Abonnement
- suit
- Pour les investisseurs
- trouvé
- de
- d’étiquettes électroniques entièrement
- fonction
- génération
- Global
- globe
- Objectifs
- Bien
- graphique
- GUEST
- Invité Message
- manipuler
- Maniabilité
- arrive
- Santé
- aider
- aide
- ici
- Haute
- très
- Comment
- How To
- Cependant
- HTTPS
- humain
- Les êtres humains
- IAM
- idéal
- Active
- détérioration
- améliorer
- améliore
- in
- Y compris
- Nouveau
- increased
- indique
- individuel
- d'information
- Infrastructure
- Innovation
- instance
- intervention
- introduit
- Introduit
- investor
- Investisseurs
- implique
- IT
- itération
- Java
- Juillet
- clés / KEY :
- Flux de données Kinesis
- gros
- Nom de famille
- Latence
- leader
- Leadership
- apprentissage
- Laisser
- Niveau
- Gamme
- lignes
- Liste
- peu
- emplacement
- Style
- perte
- LES PLANTES
- maintient
- faire
- FAIT DU
- gérés
- manager
- manière
- Manuel
- de nombreuses
- cartographie
- massivement
- maturité
- veux dire
- mécanisme
- Découvrez
- réunion
- métrique
- Métrique
- minimal
- minimum
- Mode
- modifié
- Stack monitoring
- (en fait, presque toutes)
- multi
- plusieurs
- Musique
- prénom
- noms
- indigène
- Besoin
- nécessaire
- Besoins
- Nouveauté
- Les nouvelles technologies
- New York
- next
- nombre
- numéros
- objectif
- observer
- Bureaux
- d'exploitation
- l'optimisation
- organisations
- Résultat
- parité
- partie
- en partenariat
- fête
- Patron de Couture
- effectuer
- performant
- effectuer
- autorisations
- persiste
- Personnalisé
- pipeline
- Place
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- politiques
- possible
- Post
- l'éventualité
- empêcher
- primaire
- Directeur
- processus
- traitement
- Processeur
- Produit
- producteur
- Nos producteurs
- favorise
- protéger
- fournir
- à condition de
- fournit
- publier
- Édition
- des fins
- mettre
- Lire
- en cours
- la concrétisation
- Les raisons
- recommandé
- record
- Articles
- Récupérer
- récupération
- réduire
- réduire
- région
- régional
- régions
- éloigné
- répliquées
- réplique
- réplication
- conditions
- Exigences
- a besoin
- réservé
- la résilience
- résilient
- réponse
- REST
- CV
- retourner
- retour
- Retours
- robuste
- Rôle
- Roulés
- RANGÉE
- Courir
- Sécurité
- même
- évolutive
- Escaliers intérieurs
- scénario
- Deuxièmement
- secondaire
- secondes
- Section
- sécurité
- supérieur
- Séquence
- besoin
- service
- Services
- service
- set
- mise
- plusieurs
- devrait
- montré
- Spectacles
- simplicité
- situation
- Taille
- So
- sur mesure
- Solutions
- quelques
- Identifier
- Sources
- spécialise
- Hébergement spécial
- vitesse
- Sports
- mise en scène
- Commencer
- j'ai commencé
- départs
- Région
- étapes
- Étapes
- Encore
- Arrêter
- Boutique
- de Marketing
- courant
- streaming
- service de diffusion
- flux
- réussi
- Avec succès
- convient
- haut
- fourni
- Les soutiens
- combustion propre
- table
- prend
- Target
- Tâche
- tâches
- équipe
- équipes
- Technique
- Les technologies
- Technologie
- La
- leur
- des choses
- des tiers.
- pensée
- leadership éclairé
- Avec
- débit
- fiable
- horodatage
- à
- outil
- les outils
- suivre
- Tracking
- De La Carrosserie
- voyage
- déclencher
- déclenché
- comprendre
- compris
- inutilement
- Mises à jour
- a actualisé
- Actualités
- utilisé
- cas d'utilisation
- d'habitude
- UTC
- Plus-value
- avant-garde
- Rapidité
- via
- le volume
- web
- services Web
- qui
- tout en
- sera
- dans les
- sans
- vos contrats
- pourra
- écrire
- code écrit
- Votre
- vous-même
- zéphyrnet
- zéro
- zones