Cet article est co-écrit avec Mahima Agarwal, ingénieur en apprentissage machine, et Deepak Mettem, directeur principal de l'ingénierie, chez VMware Carbon Black
VMware noir de carbone est une solution de sécurité renommée offrant une protection contre l'ensemble des cyberattaques modernes. Avec les téraoctets de données générés par le produit, l'équipe d'analyse de la sécurité se concentre sur la création de solutions d'apprentissage automatique (ML) pour détecter les attaques critiques et mettre en évidence les menaces émergentes du bruit.
Il est essentiel pour l'équipe VMware Carbon Black de concevoir et de créer un pipeline MLOps de bout en bout personnalisé qui orchestre et automatise les flux de travail dans le cycle de vie ML et permet la formation, les évaluations et les déploiements de modèles.
La construction de ce pipeline a deux objectifs principaux : soutenir les scientifiques des données pour le développement de modèles à un stade avancé et faire des prévisions de modèles de surface dans le produit en servant des modèles en volume élevé et dans le trafic de production en temps réel. Par conséquent, VMware Carbon Black et AWS ont choisi de créer un pipeline MLOps personnalisé en utilisant Amazon Sage Maker pour sa facilité d'utilisation, sa polyvalence et son infrastructure entièrement gérée. Nous orchestrons nos pipelines de formation et de déploiement ML à l'aide Flux de travail gérés par Amazon pour Apache Airflow (Amazon MWAA), ce qui nous permet de nous concentrer davantage sur la création de workflows et de pipelines par programmation sans avoir à nous soucier de la mise à l'échelle automatique ou de la maintenance de l'infrastructure.
Avec ce pipeline, ce qui était autrefois la recherche ML basée sur les ordinateurs portables Jupyter est désormais un processus automatisé déployant des modèles en production avec peu d'intervention manuelle des scientifiques des données. Auparavant, le processus de formation, d'évaluation et de déploiement d'un modèle pouvait prendre plus d'une journée ; avec cette implémentation, tout n'est qu'à un déclencheur et a réduit le temps total à quelques minutes.
Dans cet article, les architectes VMware Carbon Black et AWS expliquent comment nous avons créé et géré des flux de travail ML personnalisés à l'aide Gitlab, Amazon MWAA et SageMaker. Nous discutons de ce que nous avons réalisé jusqu'à présent, des améliorations supplémentaires apportées au pipeline et des leçons apprises en cours de route.
Vue d'ensemble de la solution
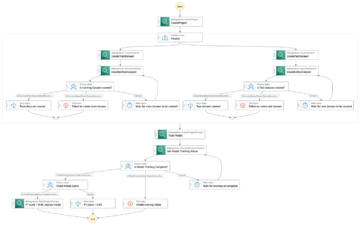
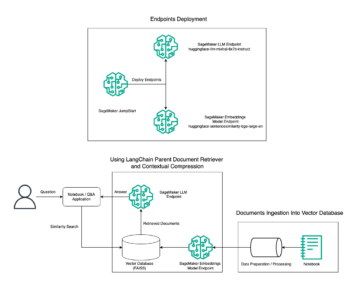
Le schéma suivant illustre l'architecture de la plate-forme ML.

Conception de solutions de haut niveau
Cette plate-forme ML a été imaginée et conçue pour être consommée par différents modèles dans divers référentiels de code. Notre équipe utilise GitLab comme outil de gestion de code source pour maintenir tous les référentiels de code. Toute modification du code source du référentiel modèle est intégrée en continu à l'aide du CI Gitlab, qui appelle les workflows suivants dans le pipeline (formation, évaluation et déploiement du modèle).
Le diagramme d'architecture suivant illustre le workflow de bout en bout et les composants impliqués dans notre pipeline MLOps.

Flux de travail de bout en bout
Les pipelines de formation, d'évaluation et de déploiement du modèle ML sont orchestrés à l'aide d'Amazon MWAA, appelé Graphique acyclique dirigé (DAG). Un DAG est une collection de tâches ensemble, organisées avec des dépendances et des relations pour indiquer comment elles doivent s'exécuter.
À un niveau élevé, l'architecture de la solution comprend trois composants principaux :
- Référentiel de code de pipeline ML
- Pipeline de formation et d'évaluation des modèles de ML
- Pipeline de déploiement de modèle ML
Voyons comment ces différents composants sont gérés et comment ils interagissent les uns avec les autres.
Référentiel de code de pipeline ML
Une fois que le référentiel de modèle intègre le référentiel MLOps en tant que pipeline en aval et qu'un scientifique des données valide le code dans son référentiel de modèle, un exécuteur GitLab effectue la validation et les tests de code standard définis dans ce référentiel et déclenche le pipeline MLOps en fonction des modifications de code. Nous utilisons le pipeline multi-projets de Gitlab pour activer ce déclencheur sur différents référentiels.
Le pipeline MLOps GitLab exécute un certain ensemble d'étapes. Il effectue une validation de code de base à l'aide de pylint, regroupe le code d'entraînement et d'inférence du modèle dans l'image Docker et publie l'image du conteneur sur Registre des conteneurs élastiques Amazon (Amazon ECR). Amazon ECR est un registre de conteneurs entièrement géré offrant un hébergement hautes performances, ce qui vous permet de déployer de manière fiable des images d'application et des artefacts n'importe où.
Pipeline de formation et d'évaluation des modèles de ML
Une fois l'image publiée, elle déclenche la formation et l'évaluation Flux d'air Apache pipeline à travers le AWS Lambda fonction. Lambda est un service de calcul sans serveur et piloté par les événements qui vous permet d'exécuter du code pour pratiquement n'importe quel type d'application ou de service backend sans provisionner ni gérer de serveurs.
Une fois le pipeline déclenché avec succès, il exécute le DAG de formation et d'évaluation, qui à son tour démarre la formation du modèle dans SageMaker. À la fin de ce pipeline de formation, le groupe d'utilisateurs identifié reçoit une notification avec les résultats de la formation et de l'évaluation du modèle par e-mail via Service de notification simple d'Amazon (Amazon SNS) et Slack. Amazon SNS est un service pub/sub entièrement géré pour la messagerie A2A et A2P.
Après une analyse méticuleuse des résultats de l'évaluation, le data scientist ou l'ingénieur ML peut déployer le nouveau modèle si les performances du modèle nouvellement formé sont meilleures par rapport à la version précédente. Les performances des modèles sont évaluées en fonction des métriques spécifiques au modèle (telles que le score F1, la MSE ou la matrice de confusion).
Pipeline de déploiement de modèle ML
Pour démarrer le déploiement, l'utilisateur démarre la tâche GitLab qui déclenche le DAG de déploiement via la même fonction Lambda. Une fois le pipeline exécuté avec succès, il crée ou met à jour le point de terminaison SageMaker avec le nouveau modèle. Cela envoie également une notification avec les détails du point de terminaison par e-mail à l'aide d'Amazon SNS et de Slack.
En cas de panne de l'un ou l'autre des pipelines, les utilisateurs sont avertis sur les mêmes canaux de communication.
SageMaker offre une inférence en temps réel idéale pour les charges de travail d'inférence avec une faible latence et des exigences de débit élevées. Ces points de terminaison sont entièrement gérés, équilibrés en charge et mis à l'échelle automatiquement, et peuvent être déployés sur plusieurs zones de disponibilité pour une haute disponibilité. Notre pipeline crée un tel point de terminaison pour un modèle après son exécution réussie.
Dans les sections suivantes, nous développons les différents composants et plongeons dans les détails.
GitLab : empaquetez des modèles et déclenchez des pipelines
Nous utilisons GitLab comme référentiel de code et pour le pipeline afin de conditionner le code du modèle et de déclencher les DAG Airflow en aval.
Pipeline multi-projets
La fonctionnalité de pipeline GitLab multi-projets est utilisée lorsque le pipeline parent (en amont) est un référentiel modèle et le pipeline enfant (en aval) est le référentiel MLOps. Chaque référentiel gère un .gitlab-ci.yml, et le bloc de code suivant activé dans le pipeline en amont déclenche le pipeline MLOps en aval.
Le pipeline en amont envoie le code du modèle au pipeline en aval où les tâches CI de packaging et de publication sont déclenchées. Le code permettant de conteneuriser le code du modèle et de le publier sur Amazon ECR est maintenu et géré par le pipeline MLOps. Il envoie les variables comme ACCESS_TOKEN (peut être créé sous Paramètres, Accès), JOB_ID (pour accéder aux artefacts en amont) et $CI_PROJECT_ID (l'ID de projet du dépôt de modèle), afin que le pipeline MLOps puisse accéder aux fichiers de code du modèle. Avec le artefacts de travail fonctionnalité de Gitlab, le dépôt en aval accède aux artefacts distants à l'aide de la commande suivante :
Le référentiel de modèles peut consommer des pipelines en aval pour plusieurs modèles du même référentiel en étendant l'étape qui le déclenche à l'aide du S'étend mot-clé de GitLab, qui vous permet de réutiliser la même configuration à différentes étapes.
Après avoir publié l'image du modèle sur Amazon ECR, le pipeline MLOps déclenche le pipeline de formation Amazon MWAA à l'aide de Lambda. Après l'approbation de l'utilisateur, il déclenche également le pipeline Amazon MWAA de déploiement du modèle à l'aide de la même fonction Lambda.
Versionnement sémantique et passage de versions en aval
Nous avons développé un code personnalisé pour versionner les images ECR et les modèles SageMaker. Le pipeline MLOps gère la logique de version sémantique pour les images et les modèles dans le cadre de l'étape où le code du modèle est conteneurisé et transmet les versions aux étapes ultérieures en tant qu'artefacts.
Reconversion
Parce que le recyclage est un aspect crucial d'un cycle de vie ML, nous avons mis en place des capacités de recyclage dans le cadre de notre pipeline. Nous utilisons l'API de modèles de liste SageMaker pour identifier s'il s'agit d'un recyclage en fonction du numéro de version et de l'horodatage du modèle de recyclage.
Nous gérons le planning quotidien du pipeline de reconversion à l'aide de Pipelines de planification de GitLab.
Terraform : configuration de l'infrastructure
Outre un cluster Amazon MWAA, des référentiels ECR, des fonctions Lambda et une rubrique SNS, cette solution utilise également Gestion des identités et des accès AWS (IAM) rôles, utilisateurs et stratégies ; Service de stockage simple Amazon (Amazon S3) compartiments, et un Amazon Cloud Watch transitaire de journal.
Pour rationaliser la configuration et la maintenance de l'infrastructure pour les services impliqués tout au long de notre pipeline, nous utilisons Terraform pour implémenter l'infrastructure en tant que code. Chaque fois que des mises à jour infra sont nécessaires, les modifications de code déclenchent un pipeline GitLab CI que nous mettons en place, qui valide et déploie les modifications dans divers environnements (par exemple, l'ajout d'une autorisation à une politique IAM dans les comptes dev, stage et prod).
Amazon ECR, Amazon S3 et Lambda : facilitation du pipeline
Nous utilisons les services clés suivants pour faciliter notre pipeline :
- ECR d'Amazon – Pour maintenir et permettre des récupérations pratiques des images de conteneurs de modèles, nous les marquons avec des versions sémantiques et les téléchargeons dans des référentiels ECR configurés par
${project_name}/${model_name}via Terraform. Cela permet une bonne couche d'isolation entre différents modèles et nous permet d'utiliser des algorithmes personnalisés et de formater les demandes d'inférence et les réponses pour inclure les informations de manifeste de modèle souhaitées (nom du modèle, version, chemin des données de formation, etc.). - Amazon S3 – Nous utilisons des compartiments S3 pour conserver les données de formation du modèle, les artefacts de modèle formés par modèle, les DAG de flux d'air et d'autres informations supplémentaires requises par les pipelines.
- Lambda – Étant donné que notre cluster Airflow est déployé dans un VPC distinct pour des raisons de sécurité, les DAG ne sont pas accessibles directement. Par conséquent, nous utilisons une fonction Lambda, également gérée avec Terraform, pour déclencher tous les DAG spécifiés par le nom du DAG. Avec une configuration IAM appropriée, la tâche GitLab CI déclenche la fonction Lambda, qui passe par les configurations jusqu'aux DAG de formation ou de déploiement demandés.
Amazon MWAA : pipelines de formation et de déploiement
Comme mentionné précédemment, nous utilisons Amazon MWAA pour orchestrer les pipelines de formation et de déploiement. Nous utilisons les opérateurs SageMaker disponibles dans le Forfait fournisseur Amazon pour Airflow à intégrer à SageMaker (pour éviter les modèles jinja).
Nous utilisons les opérateurs suivants dans ce pipeline de formation (illustré dans le diagramme de flux de travail suivant) :

Pipeline de formation MWAA
Nous utilisons les opérateurs suivants dans le pipeline de déploiement (illustrés dans le diagramme de workflow suivant) :

Pipeline de déploiement de modèle
Nous utilisons Slack et Amazon SNS pour publier les messages d'erreur/succès et les résultats d'évaluation dans les deux pipelines. Slack propose un large éventail d'options pour personnaliser les messages, notamment :
- SnsPublishOpérateur - Nous utilisons SnsPublishOpérateur pour envoyer des notifications de succès/échec aux e-mails des utilisateurs
- API Slack – Nous avons créé le URL du webhook entrant pour obtenir les notifications de pipeline sur le canal souhaité
CloudWatch et VMware Wavefront : surveillance et journalisation
Nous utilisons un tableau de bord CloudWatch pour configurer la surveillance et la journalisation des terminaux. Il permet de visualiser et de suivre diverses mesures de performances opérationnelles et de modèle spécifiques à chaque projet. En plus des politiques de mise à l'échelle automatique mises en place pour suivre certaines d'entre elles, nous surveillons en permanence les changements d'utilisation du processeur et de la mémoire, les requêtes par seconde, les latences de réponse et les métriques de modèle.
CloudWatch est même intégré à un tableau de bord VMware Tanzu Wavefront afin de pouvoir visualiser les métriques des points de terminaison du modèle ainsi que d'autres services au niveau du projet.
Avantages pour l'entreprise et prochaines étapes
Les pipelines ML sont très cruciaux pour les services et fonctionnalités ML. Dans cet article, nous avons discuté d'un cas d'utilisation ML de bout en bout utilisant les fonctionnalités d'AWS. Nous avons créé un pipeline personnalisé à l'aide de SageMaker et d'Amazon MWAA, que nous pouvons réutiliser dans tous les projets et modèles, et automatisé le cycle de vie ML, ce qui a réduit le temps entre la formation du modèle et le déploiement en production à seulement 10 minutes.
Avec le transfert de la charge du cycle de vie ML vers SageMaker, il a fourni une infrastructure optimisée et évolutive pour la formation et le déploiement du modèle. La diffusion de modèles avec SageMaker nous a aidés à faire des prédictions en temps réel avec des latences en millisecondes et des capacités de surveillance. Nous avons utilisé Terraform pour la facilité d'installation et pour gérer l'infrastructure.
Les prochaines étapes de ce pipeline seraient d'améliorer le pipeline de formation de modèles avec des capacités de recyclage, qu'elles soient planifiées ou basées sur la détection de dérive de modèle, de prendre en charge le déploiement de l'ombre ou les tests A/B pour un déploiement de modèle plus rapide et qualifié, et le suivi de la lignée ML. Nous prévoyons également d'évaluer Pipelines Amazon SageMaker car l'intégration de GitLab est désormais prise en charge.
Les leçons apprises
Dans le cadre de la création de cette solution, nous avons appris que vous devez généraliser tôt, mais ne généralisez pas trop. Lorsque nous avons terminé la conception de l'architecture pour la première fois, nous avons essayé de créer et d'appliquer des modèles de code pour le code du modèle en tant que meilleure pratique. Cependant, il était si tôt dans le processus de développement que les modèles étaient soit trop généraux, soit trop détaillés pour être réutilisables pour de futurs modèles.
Après avoir livré le premier modèle via le pipeline, les modèles sont sortis naturellement sur la base des informations de nos travaux précédents. Un pipeline ne peut pas tout faire dès le premier jour.
L'expérimentation et la production de modèles ont souvent des exigences très différentes (voire parfois contradictoires). Il est crucial d'équilibrer ces exigences dès le début en tant qu'équipe et d'établir des priorités en conséquence.
De plus, vous n'aurez peut-être pas besoin de toutes les fonctionnalités d'un service. L'utilisation des fonctionnalités essentielles d'un service et une conception modulaire sont les clés d'un développement plus efficace et d'un pipeline flexible.
Conclusion
Dans cet article, nous avons montré comment nous avons construit une solution MLOps à l'aide de SageMaker et d'Amazon MWAA qui automatise le processus de déploiement des modèles en production, avec peu d'intervention manuelle des data scientists. Nous vous encourageons à évaluer divers services AWS tels que SageMaker, Amazon MWAA, Amazon S3 et Amazon ECR pour créer une solution MLOps complète.
*Apache, Apache Airflow et Airflow sont soit des marques déposées, soit des marques commerciales de Apache Software Foundation aux États-Unis et/ou dans d'autres pays.
À propos des auteurs
 Deepak Mettem est directeur principal de l'ingénierie chez VMware, unité Carbon Black. Lui et son équipe travaillent à la création d'applications et de services basés sur le streaming qui sont hautement disponibles, évolutifs et résilients pour apporter aux clients des solutions basées sur l'apprentissage automatique en temps réel. Lui et son équipe sont également responsables de la création des outils nécessaires aux scientifiques des données pour construire, former, déployer et valider leurs modèles ML en production.
Deepak Mettem est directeur principal de l'ingénierie chez VMware, unité Carbon Black. Lui et son équipe travaillent à la création d'applications et de services basés sur le streaming qui sont hautement disponibles, évolutifs et résilients pour apporter aux clients des solutions basées sur l'apprentissage automatique en temps réel. Lui et son équipe sont également responsables de la création des outils nécessaires aux scientifiques des données pour construire, former, déployer et valider leurs modèles ML en production.
 Mahima Agarwal est ingénieur en apprentissage machine chez VMware, unité Carbon Black.
Mahima Agarwal est ingénieur en apprentissage machine chez VMware, unité Carbon Black.
Elle travaille à la conception, à la construction et au développement des composants et de l'architecture de base de la plate-forme d'apprentissage automatique pour la SBU VMware CB.
 Vamshi Krishna Enabothala est architecte spécialiste senior en IA appliquée chez AWS. Il travaille avec des clients de différents secteurs pour accélérer les initiatives de données, d'analyse et d'apprentissage automatique à fort impact. Il est passionné par les systèmes de recommandation, le NLP et les domaines de la vision par ordinateur en IA et ML. En dehors du travail, Vamshi est un passionné de RC, construisant des équipements RC (avions, voitures et drones) et aime également jardiner.
Vamshi Krishna Enabothala est architecte spécialiste senior en IA appliquée chez AWS. Il travaille avec des clients de différents secteurs pour accélérer les initiatives de données, d'analyse et d'apprentissage automatique à fort impact. Il est passionné par les systèmes de recommandation, le NLP et les domaines de la vision par ordinateur en IA et ML. En dehors du travail, Vamshi est un passionné de RC, construisant des équipements RC (avions, voitures et drones) et aime également jardiner.
 Sahil Thapar est un architecte de solutions d'entreprise. Il travaille avec les clients pour les aider à créer des applications hautement disponibles, évolutives et résilientes sur le cloud AWS. Il se concentre actuellement sur les conteneurs et les solutions d'apprentissage automatique.
Sahil Thapar est un architecte de solutions d'entreprise. Il travaille avec les clients pour les aider à créer des applications hautement disponibles, évolutives et résilientes sur le cloud AWS. Il se concentre actuellement sur les conteneurs et les solutions d'apprentissage automatique.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :est
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- Qui sommes-nous ?
- accélérer
- accès
- accédé
- en conséquence
- hybrides
- atteint
- à travers
- acyclique
- ajout
- Supplémentaire
- renseignements supplémentaires
- Après
- à opposer à
- AI
- algorithmes
- Tous
- permet
- Amazon
- Amazon Sage Maker
- selon une analyse de l’Université de Princeton
- analytique
- ainsi que
- de n'importe où
- Apache
- api
- Application
- applications
- appliqué
- IA appliquée
- approbation
- architecture
- SONT
- domaines
- AS
- d'aspect
- At
- Attaques
- création
- auto
- Automatisation
- Automates
- disponibilité
- disponibles
- éviter
- AWS
- backend
- Balance
- basé
- Essentiel
- BE
- car
- Début
- avantages.
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Noir
- Block
- Branche
- apporter
- construire
- Développement
- construit
- fardeau
- by
- CAN
- ne peut pas
- capacités
- carbone
- voitures
- maisons
- CB
- certaines
- Modifications
- Voies
- enfant
- choisir
- le cloud
- Grappe
- code
- collection
- Communication
- par rapport
- complet
- composants électriques
- calcul
- ordinateur
- Vision par ordinateur
- conduit
- configuration
- les configurations
- Contradictoire
- confusion
- considérations
- consommer
- consommées
- Contenant
- Conteneurs
- continuellement
- Pratique
- Core
- pourriez
- d'exportation
- Processeur
- engendrent
- créée
- crée des
- La création
- critique
- crucial
- Lecture
- Customiser
- Clients
- personnaliser
- cyber-attaques
- JOUR
- Tous les jours
- tableau de bord
- données
- Data Scientist
- journée
- défini
- livrer
- déployer
- déployé
- déployer
- déploiement
- déploiements
- déploie
- Conception
- un
- conception
- détaillé
- détails
- Détection
- dev
- développé
- développement
- Développement
- différent
- directement
- discuter
- discuté
- Docker
- Ne pas
- down
- Drones
- chacun
- Plus tôt
- "Early Bird"
- facilité d'utilisation
- efficace
- non plus
- économies émergentes.
- permettre
- activé
- permet
- encourager
- end-to-end
- Endpoint
- ingénieur
- ENGINEERING
- Entreprise
- Solutions d'entreprise
- passionné
- environnements
- l'équipements
- essential
- Ether (ETH)
- évaluer
- évalué
- évaluer
- évaluation
- évaluations
- Pourtant, la
- événement
- Chaque
- peut
- exemple
- Développer vous
- extension
- f1
- faciliter
- Échec
- loin
- plus rapide
- Fonctionnalité
- Fonctionnalités:
- few
- Fichiers
- Prénom
- flexible
- Focus
- concentré
- se concentre
- Abonnement
- Pour
- le format
- de
- plein
- spectre complet
- d’étiquettes électroniques entièrement
- fonction
- fonctions
- plus
- avenir
- généré
- obtenez
- Bien
- Réservation de groupe
- Vous avez
- ayant
- aider
- a aidé
- aide
- Haute
- haute performance
- très
- hébergement
- Comment
- Cependant
- HTML
- http
- HTTPS
- IAM
- ID
- idéal
- identifié
- identifier
- Active
- image
- satellite
- Mettre en oeuvre
- la mise en oeuvre
- mis en œuvre
- in
- comprendre
- inclut
- Y compris
- d'information
- Infrastructure
- les initiatives
- idées.
- intégrer
- des services
- Intègre
- l'intégration
- interagir
- intervention
- invoque
- impliqué
- seul
- IT
- SES
- Emploi
- Emplois
- jpg
- XNUMX éléments à
- ACTIVITES
- clés
- Latence
- couche
- savant
- apprentissage
- Cours
- Leçons apprises
- Allons-y
- Niveau
- vos produits
- comme
- peu
- charge
- Faible
- click
- machine learning
- Entrée
- maintenir
- maintient
- facile
- faire
- gérer
- gérés
- gestion
- manager
- gère
- les gérer
- Manuel
- Matrice
- Mémoire
- mentionné
- messages
- messagerie
- Métrique
- pourrait
- milliseconde
- minutes
- ML
- MLOps
- modèle
- numériques jumeaux (digital twin models)
- Villas Modernes
- Surveiller
- Stack monitoring
- PLUS
- plus efficace
- plusieurs
- prénom
- naturellement
- nécessaire
- Besoin
- Nouveauté
- next
- nlp
- Bruit
- déclaration
- Notifications
- nombre
- of
- offrant
- Offres Speciales
- on
- ONE
- opérationnel
- opérateurs
- optimisé
- Options
- orchestrée
- Organisé
- Autre
- au contrôle
- global
- paquet
- Forfaits
- l'emballage
- partie
- passes
- En passant
- passionné
- chemin
- performant
- autorisation
- pipeline
- plan
- Plans
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- politiques
- politique
- Post
- pratique
- Prédictions
- précédent
- Prioriser
- processus
- Produit
- Vidéo
- Projet
- projets
- correct
- protection
- à condition de
- de voiture.
- fournit
- publier
- publié
- Publie
- Édition
- des fins
- qualifié
- gamme
- en temps réel
- Recommandation
- Prix Réduit
- visée
- inscrit
- enregistrement
- Les relations
- éloigné
- Célèbre
- dépôt
- demandé
- demandes
- conditions
- Exigences
- un article
- résilient
- réponse
- responsables
- Résultats
- recyclage
- réutilisable
- rôle
- Courir
- coureur
- sagemaker
- même
- évolutive
- mise à l'échelle
- calendrier
- prévu
- Scientifique
- scientifiques
- Deuxièmement
- les sections
- Secteurs
- sécurité
- supérieur
- séparé
- Sans serveur
- Serveurs
- service
- Services
- service
- set
- installation
- Shadow
- DÉPLACEMENT
- devrait
- montré
- étapes
- mou
- So
- jusqu'à présent
- Logiciels
- sur mesure
- Solutions
- quelques
- Identifier
- code source
- spécialiste
- groupe de neurones
- spécifié
- Spectre
- Spotlight
- Étape
- étapes
- Standard
- Commencer
- départs
- États
- Étapes
- storage
- de Marketing
- streaming
- rationaliser
- ultérieur
- Avec succès
- tel
- Support
- Appareils
- Surface
- Système
- TAG
- Prenez
- tâches
- équipe
- modèles
- Terraform
- Essais
- qui
- La
- leur
- Les
- donc
- Ces
- des menaces
- trois
- Avec
- tout au long de
- débit
- fiable
- horodatage
- à
- ensemble
- trop
- outil
- les outils
- top
- sujet
- suivre
- Tracking
- marques
- circulation
- Train
- qualifié
- Formation
- déclencher
- déclenché
- TOUR
- sous
- unité
- Uni
- États-Unis
- Actualités
- us
- Utilisation
- utilisé
- cas d'utilisation
- Utilisateur
- utilisateurs
- VALIDER
- validation
- les variables
- divers
- version
- pratiquement
- vision
- visualiser
- vmware
- le volume
- Façon..
- WELL
- Quoi
- que
- qui
- large
- Large gamme
- avec
- dans les
- sans
- Activités principales
- workflow
- workflows
- vos contrats
- pourra
- zéphyrnet
- Zip
- zones