Les grands modèles de transformateurs basés sur l'attention ont obtenu des gains massifs sur le traitement du langage naturel (TAL). Cependant, la formation de ces réseaux gigantesques à partir de zéro nécessite une énorme quantité de données et de calcul. Pour les ensembles de données NLP plus petits, une stratégie simple mais efficace consiste à utiliser un transformateur pré-formé, généralement formé de manière non supervisée sur de très grands ensembles de données, et à l'affiner sur l'ensemble de données d'intérêt. Étreindre le visage maintient un grand zoo de modèles de ces transformateurs pré-formés et les rend facilement accessibles même pour les utilisateurs novices.
Cependant, le réglage fin de ces modèles nécessite toujours des connaissances d'expert, car ils sont assez sensibles à leurs hyperparamètres, tels que le taux d'apprentissage ou la taille des lots. Dans cet article, nous montrons comment optimiser ces hyperparamètres avec le framework open-source Synchronisation pour l'optimisation distribuée des hyperparamètres (HPO). Syne Tune nous permet de trouver une meilleure configuration d'hyperparamètres qui réalise une amélioration relative entre 1 et 4 % par rapport aux hyperparamètres par défaut sur les LA COLLE ensembles de données de référence. Le choix du modèle pré-entraîné lui-même peut également être considéré comme un hyperparamètre et donc être automatiquement sélectionné par Syne Tune. Sur un problème de classification de texte, cela conduit à une amélioration supplémentaire de la précision d'environ 5 % par rapport au modèle par défaut. Cependant, nous pouvons automatiser davantage de décisions qu'un utilisateur doit prendre ; nous le démontrons en exposant également le type d'instance en tant qu'hyperparamètre que nous utiliserons plus tard pour déployer le modèle. En sélectionnant le bon type d'instance, nous pouvons trouver des configurations qui offrent un compromis optimal entre coût et latence.
Pour une introduction à Syne Tune, veuillez consulter Exécutez des travaux de réglage d'hyperparamètres distribués et d'architecture neuronale avec Syne Tune.
Optimisation des hyperparamètres avec Syne Tune
Nous allons utiliser la LA COLLE benchmark suite, qui se compose de neuf ensembles de données pour les tâches de compréhension du langage naturel, telles que la reconnaissance d'implication textuelle ou l'analyse des sentiments. Pour cela, nous adaptons Hugging Face's run_glue.py scénario de formation. Les ensembles de données GLUE sont livrés avec un ensemble d'entraînement et d'évaluation prédéfini avec des étiquettes ainsi qu'un ensemble de test d'attente sans étiquettes. Par conséquent, nous divisons l'ensemble d'apprentissage en ensembles d'apprentissage et de validation (répartition 70 %/30 %) et utilisons l'ensemble d'évaluation comme ensemble de données de test d'exclusion. De plus, nous ajoutons une autre fonction de rappel à l'API Trainer de Hugging Face qui rapporte les performances de validation après chaque époque à Syne Tune. Voir le code suivant :
Nous commençons par optimiser les hyperparamètres d'entraînement typiques : le taux d'apprentissage, le taux d'échauffement pour augmenter le taux d'apprentissage et la taille du lot pour affiner un BERT pré-entraîné (bert-base-case), qui est le modèle par défaut dans l'exemple Hugging Face. Voir le code suivant :
Comme méthode HPO, nous utilisons ASHA, qui échantillonne les configurations d'hyperparamètres uniformément au hasard et arrête de manière itérative l'évaluation des configurations peu performantes. Bien que des méthodes plus sophistiquées utilisent un modèle probabiliste de la fonction objectif, tel que BO ou MoBster, nous utilisons ASHA pour cet article car il ne contient aucune hypothèse sur l'espace de recherche.
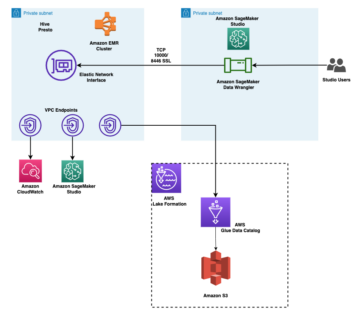
Dans la figure suivante, nous comparons l'amélioration relative de l'erreur de test par rapport à la configuration d'hyperparamètres par défaut de Hugging Faces.
![]()
Pour plus de simplicité, nous limitons la comparaison à MRPC, COLA et STSB, mais nous observons également des améliorations similaires également pour d'autres ensembles de données GLUE. Pour chaque ensemble de données, nous exécutons ASHA sur un seul ml.g4dn.xlarge Amazon Sage Maker instance avec un budget d'exécution de 1,800 13 secondes, ce qui correspond à environ 7, 9 et 1 évaluations de fonctions complètes sur ces ensembles de données, respectivement. Pour tenir compte du caractère aléatoire intrinsèque du processus de formation, par exemple causé par l'échantillonnage par mini-lots, nous exécutons à la fois ASHA et la configuration par défaut pour cinq répétitions avec une graine indépendante pour le générateur de nombres aléatoires et signalons la moyenne et l'écart type du amélioration relative au fil des répétitions. Nous pouvons voir que, dans tous les ensembles de données, nous pouvons en fait améliorer les performances prédictives de 3 à XNUMX % par rapport aux performances de la configuration par défaut soigneusement sélectionnée.
Automatisez la sélection du modèle pré-formé
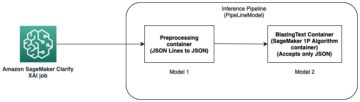
Nous pouvons utiliser HPO non seulement pour trouver des hyperparamètres, mais également pour sélectionner automatiquement le bon modèle pré-formé. Pourquoi voulons-nous faire cela ? Étant donné qu'aucun modèle ne surpasse tous les ensembles de données, nous devons sélectionner le bon modèle pour un ensemble de données spécifique. Pour le démontrer, nous évaluons une gamme de modèles de transformateurs populaires de Hugging Face. Pour chaque ensemble de données, nous classons chaque modèle en fonction de ses performances de test. Le classement des ensembles de données (voir la figure suivante) change et pas un seul modèle qui obtient le score le plus élevé sur chaque ensemble de données. À titre de référence, nous montrons également les performances de test absolues de chaque modèle et ensemble de données dans la figure suivante.
Pour sélectionner automatiquement le bon modèle, nous pouvons convertir le choix du modèle en paramètres catégoriels et l'ajouter à notre espace de recherche d'hyperparamètres :
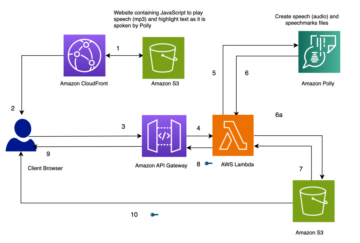
Bien que l'espace de recherche soit désormais plus grand, cela ne signifie pas nécessairement qu'il est plus difficile à optimiser. La figure suivante montre l'erreur de test de la meilleure configuration observée (basée sur l'erreur de validation) sur l'ensemble de données MRPC d'ASHA au fil du temps lorsque nous recherchons dans l'espace d'origine (ligne bleue) (avec un modèle pré-formé basé sur BERT ) ou dans le nouvel espace de recherche augmentée (ligne orange). Avec le même budget, ASHA est capable de trouver une configuration d'hyperparamètres beaucoup plus performante dans l'espace de recherche étendu que dans l'espace plus petit.
![]()
Automatiser la sélection du type d'instance
En pratique, nous ne nous soucions peut-être pas seulement d'optimiser les performances prédictives. Nous pouvons également nous soucier d'autres objectifs, tels que le temps de formation, le coût (en dollars), la latence ou les mesures d'équité. Nous devons également faire d'autres choix au-delà des hyperparamètres du modèle, par exemple en sélectionnant le type d'instance.
Bien que le type d'instance n'influence pas les performances prédictives, il a un impact important sur le coût (en dollars), la durée d'exécution de la formation et la latence. Ce dernier devient particulièrement important lorsque le modèle est déployé. Nous pouvons formuler HPO comme un problème d'optimisation multi-objectifs, où nous visons à optimiser plusieurs objectifs simultanément. Cependant, aucune solution unique n'optimise toutes les métriques en même temps. Au lieu de cela, nous visons à trouver un ensemble de configurations qui équilibrent de manière optimale un objectif par rapport à l'autre. C'est ce qu'on appelle le Ensemble de Pareto.
Pour approfondir l'analyse de ce paramètre, nous ajoutons le choix du type d'instance comme hyperparamètre catégoriel supplémentaire à notre espace de recherche :
Nous utilisons MO-ASHA, qui adapte ASHA au scénario multi-objectifs en utilisant un tri non dominé. À chaque itération, MO-ASHA sélectionne également pour chaque configuration le type d'instance sur lequel nous voulons l'évaluer. Pour exécuter HPO sur un ensemble hétérogène d'instances, Syne Tune fournit le backend SageMaker. Avec ce backend, chaque essai est évalué comme une tâche de formation SageMaker indépendante sur sa propre instance. Le nombre de travailleurs définit le nombre de tâches SageMaker que nous exécutons en parallèle à un moment donné. L'optimiseur lui-même, MO-ASHA dans notre cas, s'exécute soit sur la machine locale, soit sur un ordinateur portable Sagemaker, soit sur une tâche de formation SageMaker distincte. Voir le code suivant :
Les figures suivantes montrent la latence par rapport à l'erreur de test à gauche et la latence par rapport au coût à droite pour des configurations aléatoires échantillonnées par MO-ASHA (nous limitons l'axe pour la visibilité) sur l'ensemble de données MRPC après l'avoir exécuté pendant 10,800 XNUMX secondes sur quatre travailleurs. La couleur indique le type d'instance. La ligne noire en pointillés représente l'ensemble de Pareto, c'est-à-dire l'ensemble des points qui dominent tous les autres points dans au moins un objectif.
Nous pouvons observer un compromis entre la latence et l'erreur de test, ce qui signifie que la meilleure configuration avec l'erreur de test la plus faible n'atteint pas la latence la plus faible. En fonction de vos préférences, vous pouvez sélectionner une configuration d'hyperparamètres qui sacrifie les performances de test mais qui s'accompagne d'une latence plus faible. Nous voyons également le compromis entre la latence et le coût. En utilisant une instance ml.g4dn.xlarge plus petite, par exemple, nous n'augmentons que légèrement la latence, mais payons un quart du coût d'une instance ml.g4dn.8xlarge.
Conclusion
Dans cet article, nous avons discuté de l'optimisation des hyperparamètres pour affiner les modèles de transformateurs pré-formés de Hugging Face basés sur Syne Tune. Nous avons vu qu'en optimisant les hyperparamètres tels que le taux d'apprentissage, la taille du lot et le taux de préchauffage, nous pouvons améliorer la configuration par défaut soigneusement choisie. Nous pouvons également étendre cela en sélectionnant automatiquement le modèle pré-formé via l'optimisation des hyperparamètres.
Avec l'aide du backend SageMaker de Syne Tune, nous pouvons traiter le type d'instance comme un hyperparamètre. Bien que le type d'instance n'affecte pas les performances, il a un impact significatif sur la latence et le coût. Par conséquent, en définissant HPO comme un problème d'optimisation multi-objectifs, nous sommes en mesure de trouver un ensemble de configurations qui établissent un compromis optimal entre un objectif et l'autre. Si vous voulez essayer vous-même, consultez notre exemple de cahier.
À propos des auteurs
![]() Aaron Klein est scientifique appliquée chez AWS.
Aaron Klein est scientifique appliquée chez AWS.
![]() Matthias Seeger est chercheur principal appliqué chez AWS.
Matthias Seeger est chercheur principal appliqué chez AWS.
![]() David Salinas est scientifique appliquée senior chez AWS.
David Salinas est scientifique appliquée senior chez AWS.
![]() Emilie Webber a rejoint AWS juste après le lancement de SageMaker et essaie d'en parler au monde depuis ! En dehors de la création de nouvelles expériences ML pour les clients, Emily aime méditer et étudier le bouddhisme tibétain.
Emilie Webber a rejoint AWS juste après le lancement de SageMaker et essaie d'en parler au monde depuis ! En dehors de la création de nouvelles expériences ML pour les clients, Emily aime méditer et étudier le bouddhisme tibétain.
![]() Cédric Archambeau est chercheur appliqué principal chez AWS et membre du laboratoire européen pour l'apprentissage et les systèmes intelligents.
Cédric Archambeau est chercheur appliqué principal chez AWS et membre du laboratoire européen pour l'apprentissage et les systèmes intelligents.
- Coinsmart. Le meilleur échange Bitcoin et Crypto d'Europe.
- Platoblockchain. Intelligence métaverse Web3. Connaissance amplifiée. ACCÈS LIBRE.
- CryptoHawk. Radar Altcoins. Essai gratuit.
- Source : https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- Description
- Absolute
- accessible
- Compte
- atteindre
- à travers
- Supplémentaire
- affecter
- Tous
- permet
- Bien que
- Amazon
- montant
- selon une analyse de l’Université de Princeton
- il analyse
- Une autre
- api
- appliqué
- d'environ
- architecture
- augmentée
- automatiser
- automatiquement
- moyen
- AWS
- Axis
- car
- référence
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Au-delà
- Noir
- goupille
- renforcer
- budget
- Développement
- les soins
- maisons
- causé
- le choix
- choix
- choisi
- classe
- classification
- code
- comment
- par rapport
- calcul
- configuration
- des bactéries
- Clients
- données
- décisions
- démontrer
- déployer
- déployé
- distribué
- Ne fait pas
- Dollar
- chacun
- même
- Efficace
- du
- évaluer
- évaluation
- exemple
- Expériences
- expert
- étendre
- Visage
- Mode
- Figure
- Abonnement
- Framework
- de
- plein
- fonction
- plus
- En outre
- générateur
- aider
- ici
- Comment
- How To
- Cependant
- HTTPS
- Impact
- important
- améliorer
- amélioration
- Améliore
- indépendant
- influencer
- instance
- Intelligent
- intérêt
- IT
- lui-même
- Emploi
- Emplois
- rejoint
- spécialisées
- laboratoire
- Etiquettes
- langue
- gros
- plus importantes
- lancé
- Conduit
- apprentissage
- LIMIT
- Gamme
- locales
- click
- faire
- FAIT DU
- massif
- sens
- méthodes
- Métrique
- pourrait
- ML
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- plusieurs
- Nature
- nécessairement
- Besoins
- réseaux
- cahier
- nombre
- objectifs
- obtenu
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Optimiser
- l'optimisation
- original
- Autre
- propre
- particulièrement
- Payer
- performant
- effectuer
- veuillez cliquer
- des notes bonus
- Populaire
- pratique
- Directeur
- Problème
- processus
- traitement
- fournit
- gamme
- Classement
- rapport
- journaliste
- Rapports
- représente
- a besoin
- Résultats
- Courir
- pour le running
- même
- Scientifique
- Rechercher
- secondes
- seed
- choisi
- sentiment
- set
- mise
- montrer
- significative
- similaires
- étapes
- unique
- Taille
- sur mesure
- sophistiqué
- Space
- groupe de neurones
- scission
- Standard
- Commencer
- Région
- Encore
- de Marketing
- Système
- tâches
- tester
- La
- le monde
- donc
- fiable
- commerce
- Formation
- traiter
- énorme
- procès
- compréhension
- us
- utilisé
- utilisateurs
- d'habitude
- utiliser
- validation
- définition
- Wikipédia
- sans
- ouvriers
- world
- Votre