Introduction
Le monde de l'audit des données peut être complexe, avec de nombreux défis à relever. L'un des plus grands défis consiste à gérer les attributs catégoriels tout en traitant des ensembles de données. Dans cet article, nous plongerons dans le monde de l'audit des données, de la détection des anomalies et de l'impact de l'encodage des attributs catégoriels sur les modèles.
L'un des principaux défis associés à la détection d'anomalies pour les données d'audit est la gestion des attributs catégoriels. L'encodage des attributs catégoriels est obligatoire car les modèles ne peuvent pas interpréter la saisie de texte. Généralement, cela se fait à l'aide de l'encodage Label ou de l'encodage One Hot. Cependant, dans un grand ensemble de données, l'encodage One-hot peut entraîner de mauvaises performances du modèle en raison de la malédiction de la dimensionnalité.
Objectifs d'apprentissage
-
Comprendre le concept d'audit des données et le défi
- Évaluer différentes méthodes de détection d'anomalies profondes non supervisées.
- Comprendre l'impact de l'encodage des attributs catégoriels sur les modèles utilisés pour la détection des anomalies dans les données d'audit.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
- Qu'est-ce qu'Auata ?
- Qu'est-ce que la détection d'anomalies?
- Principaux défis rencontrés lors de l'audit des données
- Audit des ensembles de données pour la détection d'anomalies
- Encodage des attributs catégoriels
- Encodages catégoriels
- Modèles de détection d'anomalies non supervisées
- Comment l'encodage des attributs catégoriels impacte-t-il les modèles ?
8.1 Représentation t-SNE de l'ensemble de données d'assurance automobile
8.2 Représentation t-SNE de l'ensemble de données d'assurance automobile
8.3 Représentation t-SNE de l'ensemble de données Vehicle Claims - Conclusion
qu'est-ce que l'audit des données ?
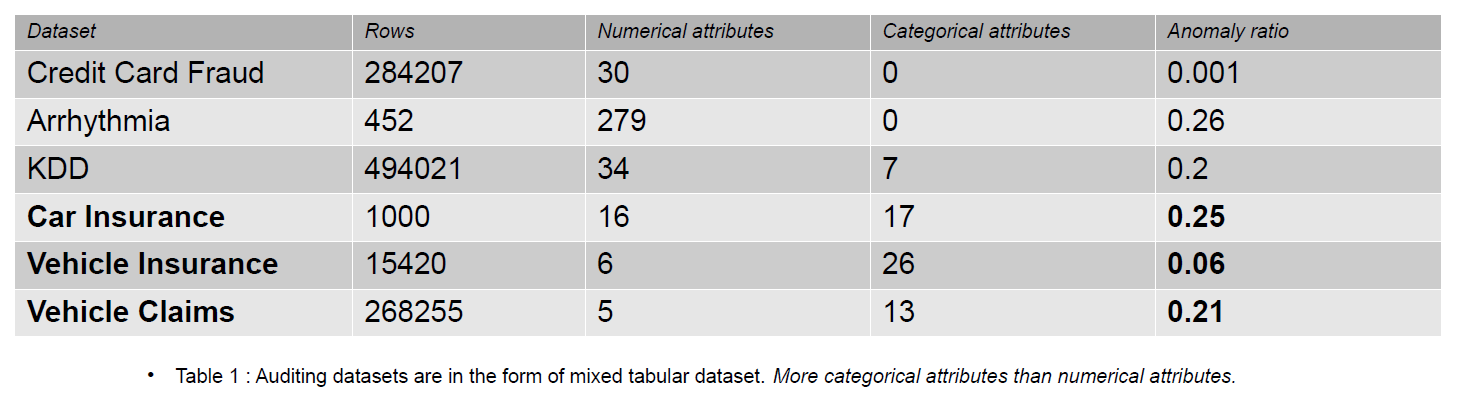
Les données d'audit peuvent inclure des journaux, des réclamations d'assurance et des données d'intrusion pour les systèmes d'information ; dans cet article, les exemples fournis sont des réclamations d'assurance de véhicules. Les réclamations d'assurance se distinguent des ensembles de données de détection d'anomalies, par exemple KDD, par un plus grand nombre de caractéristiques catégorielles.
Des caractéristiques catégorielles sont discutées dans nos données qui peuvent être soit de type entier soit de type caractère. Les caractéristiques numériques sont des attributs continus dans nos données qui ont toujours une valeur réelle. Les ensembles de données avec des caractéristiques numériques sont populaires dans la communauté de détection d'anomalies comme les données de fraude par carte de crédit. La plupart des ensembles de données accessibles au public contiennent moins de caractéristiques catégorielles que les données sur les réclamations d'assurance. Les caractéristiques catégorielles sont plus nombreuses que les caractéristiques numériques dans les ensembles de données sur les réclamations d'assurance.
Une réclamation d'assurance comprend des caractéristiques telles que le modèle, la marque, le revenu, le coût, le problème, la couleur, etc. Le nombre de caractéristiques catégorielles est plus élevé dans les données d'audit que dans les ensembles de données de carte de crédit et KDD. Ces ensembles de données sont des références dans les méthodes de détection d'anomalies non supervisées. Comme le montre le tableau ci-dessous, les ensembles de données sur les réclamations d'assurance ont des caractéristiques plus catégorielles, qui sont importantes pour comprendre le comportement des données frauduleuses.
Les ensembles de données d'audit utilisés pour évaluer l'impact des encodages catégoriels sont l'assurance automobile, l'assurance automobile et les réclamations de véhicule.
Qu'est-ce que la détection d'anomalies?
Une anomalie est une observation située loin des données normales dans un jeu de données par une distance spécifique (seuil). En termes de données d'audit, nous préférons le terme de données frauduleuses. La détection d'anomalies fait la distinction entre les données normales et frauduleuses à l'aide d'un modèle d'apprentissage automatique ou d'apprentissage en profondeur. Différentes méthodes peut être utilisé pour la détection d'anomalies, comme l'estimation de la densité, l'erreur de reconstruction et les méthodes de classification.
- Estimation de la densité – Ces méthodes estiment la distribution normale des données et classent les données anormales si elles n'ont pas été échantillonnées à partir de la distribution apprise.
- Erreur de reconstitution – Les méthodes de reconstruction basées sur les erreurs reposent sur le principe selon lequel les données normales peuvent être reconstruites avec des pertes moindres que les données anormales. Plus la perte de reconstruction est élevée, plus les chances que les données soient une anomalie augmentent.
- Méthodes de classement - Les méthodes de classification comme Forêt aléatoire, Isolation Forest, One Class – Support Vector Machines et Local Outlier Factors peuvent être utilisés pour la détection des anomalies. La classification dans la détection d'anomalies consiste à identifier l'une des classes en tant qu'anomalie. Pourtant, les classes sont divisées en deux groupes (0 et 1) dans le scénario multi-classes, et la classe avec moins de données est la classe anormale.
Le résultat des méthodes ci-dessus est des scores d'anomalie ou des erreurs de reconstruction. Ensuite, nous devons décider d'un seuil, selon lequel nous classons les données anormales.
Principaux défis rencontrés lors de l'audit des données
- Gestion des attributs catégoriels : L'encodage des attributs catégoriels est obligatoire car le modèle ne peut pas interpréter l'entrée de texte. Ainsi, les valeurs sont encodées avec l'encodage Label ou l'encodage One Hot. Mais dans un grand ensemble de données, un encodage à chaud transforme les données en un espace de grande dimension en augmentant le nombre d'attributs. Le modèle fonctionne mal en raison de la malédiction de la dimensionnalité.
- Sélection du seuil de classification : Si les données ne sont pas étiquetées, il est difficile d'évaluer les performances du modèle car on ne connaît pas le nombre d'anomalies présentes dans le jeu de données. La connaissance préalable de l'ensemble de données facilite la détermination du seuil. Disons que nous avons 5 échantillons anormaux sur 10 dans nos données. Ainsi, nous pouvons sélectionner le seuil au score de 50 centiles.
- Ensembles de données publics : La plupart des ensembles de données d'audit sont confidentiels car ils appartiennent à des entreprises et contiennent des informations sensibles et personnelles. Une façon possible d'atténuer les problèmes de confidentialité est de s'entraîner à l'aide d'ensembles de données synthétiques (véhicules sinistres).
Audit des ensembles de données pour la détection d'anomalies
Les réclamations d'assurance pour les véhicules incluent des informations sur les propriétés du véhicule, telles que le modèle, la marque, le prix, l'année et le type de carburant. Il comprend des informations sur le conducteur, sa date de naissance, son sexe et sa profession. De plus, la réclamation peut inclure des informations sur le coût total de la réparation. Les jeux de données utilisés dans cet article proviennent tous d'un seul domaine, mais ils varient en nombre d'attributs et en nombre d'instances.
-
L'ensemble de données Vehicle Claims est volumineux, contenant plus de 250,000 1171 lignes, et ses attributs catégoriels ont une cardinalité de XNUMX. En raison de sa grande taille, cet ensemble de données souffre de la malédiction de la dimensionnalité.
- L'ensemble de données d'assurance automobile est de taille moyenne, avec 15,420 151 lignes et XNUMX valeurs catégorielles uniques. Cela le rend moins susceptible de souffrir de la malédiction de la dimensionnalité.
- L'ensemble de données de l'assurance automobile est petit, avec des étiquettes et 25 % d'échantillons anormaux, et il contient un nombre similaire de caractéristiques numériques et catégorielles. Avec 169 catégories uniques, il ne souffre pas de la malédiction de la dimensionnalité.
Encodage des attributs catégoriels
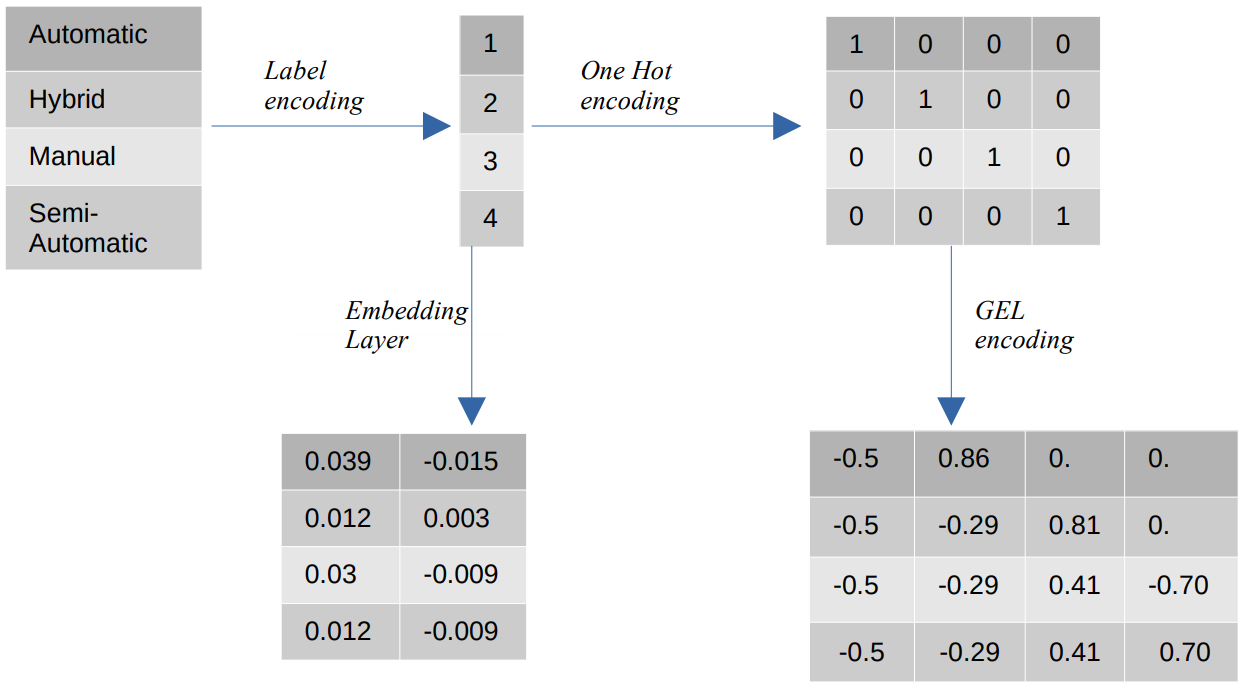
Différents encodages de valeurs catégorielles
- Encodage des étiquettes – Dans le codage des étiquettes, les valeurs catégorielles sont remplacées par des valeurs numériques entières comprises entre 1 et le nombre de catégories. L'encodage d'étiquette représente les catégories de la manière prévue pour les valeurs ordinales. Pourtant, lorsque les caractéristiques sont nominales, la représentation est incorrecte car les valeurs catégorielles ne sont pas conformes à un ordre spécifique.
Par exemple, si nous avons des catégories telles que Automatique, Hybride, Manuel et Semi-Automatique dans une fonctionnalité, l'encodage des étiquettes transforme ces valeurs en {1 : Automatique, 2 : Hybride, 3 : Manuel, 4 : Semi-Automatique}. Cette représentation ne fournit aucune information sur les valeurs catégorielles, mais une représentation telle que {0 : Faible, 1 : Moyen, 2 : Élevé} fournit une représentation claire car la variable de caractéristique Faible se voit attribuer une valeur numérique inférieure. Par conséquent, le codage des étiquettes est meilleur pour les valeurs ordinales mais désavantageux pour les valeurs nominales. - Un encodage à chaud – Un codage à chaud est utilisé pour résoudre le problème des valeurs de codage nominales, qui transforme chaque valeur catégorique en une caractéristique distincte dans l'ensemble de données composé de valeurs binaires. Par exemple, dans le cas de quatre catégories différentes encodées comme {1, 2, 3, 4}, l'encodage One Hot créerait de nouvelles fonctionnalités telles que {Automatic : [1,0,0,0], Hybrid : [0,1,0,0 ,0,0,1,0], Manuel : [0,0,0,1], Semi-automatique : [XNUMX]}.
La dimension du jeu de données dépend alors directement du nombre de catégories présentes dans le jeu de données. En conséquence, l'encodage One Hot peut conduire à la malédiction de la dimensionnalité, qui est un inconvénient de cette méthode d'encodage. - Encodage GEL – L'encodage GEL est une technique d'intégration qui peut être utilisée dans des méthodes d'apprentissage supervisées et non supervisées. Il est basé sur le principe de l'encodage One Hot et peut être utilisé pour diminuer la dimensionnalité des caractéristiques catégorielles qui ont été encodées à l'aide de l'encodage One Hot.
- Couche d'intégration - Les incorporations de mots permettent d'utiliser une représentation compacte et dense dans laquelle des mots similaires ont des encodages similaires. Une incorporation est un vecteur dense de valeurs à virgule flottante qui sont des paramètres entraînables. Les incorporations de mots peuvent aller de 8 dimensions (pour les petits ensembles de données) à 1024 dimensions (pour les grands ensembles de données).
Une intégration dimensionnelle plus élevée peut capturer des relations plus détaillées entre les mots, mais elle nécessite plus de données pour apprendre. La couche d'intégration est une table de correspondance qui convertit chaque mot présent dans la matrice en un vecteur d'une taille spécifique.
Modèles de détection d'anomalies non supervisées
Dans le monde réel, les données ne sont pas étiquetées dans la plupart des cas, et l'étiquetage des données est coûteux et prend du temps. Par conséquent, nous utiliserons des modèles non supervisés pour nos évaluations.
- SOM - La carte auto-organisatrice (SOM) est une méthode d'apprentissage compétitif où les poids des neurones sont mis à jour de manière compétitive plutôt que d'utiliser l'apprentissage par rétropropagation. SOM consiste en une carte de neurones, chacun avec un vecteur de poids de la même taille que le vecteur d'entrée. Le vecteur de poids est initialisé avec des poids aléatoires avant le début de l'entraînement. Au cours de la formation, chaque entrée est comparée aux neurones de la carte en fonction d'une métrique de distance (par exemple, la distance euclidienne) et est mappée à la meilleure unité de correspondance (BMU), qui est le neurone avec la distance minimale au vecteur d'entrée.
Les poids de la BMU sont mis à jour avec les poids du vecteur d'entrée, et les neurones voisins sont mis à jour en fonction du rayon de voisinage (sigma). Étant donné que les neurones sont en concurrence les uns avec les autres pour être la meilleure unité correspondante, ce processus est connu sous le nom d'apprentissage compétitif. Au final, les neurones des échantillons normaux sont plus proches que les neurones anormaux. Les scores d'anomalie sont définis par l'erreur de quantification, qui est la différence entre l'échantillon d'entrée et les poids de l'unité la mieux correspondante. Une erreur de quantification plus élevée indique une probabilité plus élevée que l'échantillon soit une anomalie. - DAGMM – Le Deep Autoencoding Gaussian Mixture Model (DAGMM) est une méthode d'estimation de la densité qui suppose que les anomalies se situent dans une région à faible probabilité. Le réseau est divisé en deux parties : un réseau de compression, qui sert à projeter les données dans des dimensions inférieures à l'aide d'un auto-encodeur, et un réseau d'estimation, qui sert à estimer les paramètres du modèle de mélange gaussien. DAGMM estime k nombre de mélanges gaussiens, où k peut être n'importe quel nombre de 1 à N (le nombre de points de données), et on suppose que les points normaux se trouvent dans une région à haute densité, ce qui signifie que la probabilité d'être échantillonné à partir d'un Le mélange gaussien est plus élevé pour les points normaux que pour les échantillons anormaux. Les scores d'anomalie sont définis par l'énergie estimée de l'échantillon.
- RSRAE – La couche de récupération de surface robuste pour la détection d'anomalies non supervisée est une méthode d'erreur de reconstruction qui projette d'abord les données dans une dimension inférieure à l'aide d'un auto-encodeur. La représentation latente est ensuite soumise à une projection orthogonale sur un sous-espace linéaire robuste aux valeurs aberrantes. Le décodeur reconstruit ensuite la sortie du sous-espace linéaire. Dans cette méthode, une erreur de reconstruction plus élevée indique une probabilité plus élevée que l'échantillon soit une anomalie.
- SOM-DAGMM- Une carte auto-organisatrice (SOM) - Deep Autoencoding Gaussian Mixture Model (DAGMM) est également un modèle d'estimation de la densité. Comme DAGMM, il estime également la distribution de probabilité des points de données normaux et classe un point de données comme une anomalie s'il a une faible probabilité d'être échantillonné à partir de la distribution apprise. La principale différence entre SOM-DAGMM et DAGMM est que SOM-DAGMM inclut les coordonnées normalisées de SOM pour l'échantillon d'entrée, qui fournit les informations topologiques manquantes dans le cas de DAGMM au réseau d'estimation. L'objectif est également similaire à DAGMM en ce que les scores d'anomalie sont définis par l'énergie estimée de l'échantillon, et une faible énergie indique une probabilité plus élevée que l'échantillon soit une anomalie.
Ensuite, nous aborderons le défi de la gestion des attributs catégoriques.
Comment l'encodage des attributs catégoriels impacte-t-il les modèles ?
Pour comprendre l'impact des différents encodages sur les ensembles de données, nous utiliserons t-SNE pour visualiser les représentations de faible dimension des données pour différents encodages. t-SNE projette des données de grande dimension dans un espace de dimension inférieure, ce qui facilite la visualisation. En comparant les visualisations t-SNE et les résultats numériques de différents encodages du même ensemble de données, la différence est observée dans les représentations résultantes et la compréhension de l'impact de l'encodage sur l'ensemble de données.
Représentation t-SNE de l'ensemble de données d'assurance automobile
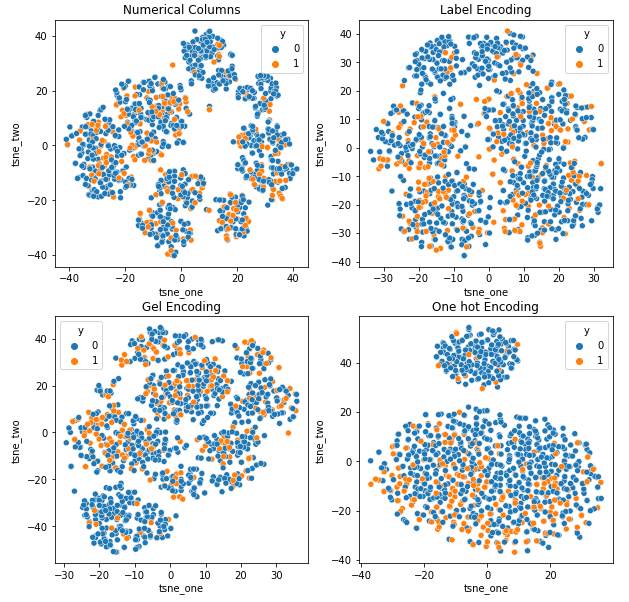
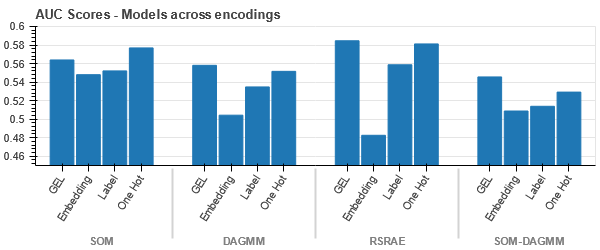
Représentation t-SNE de l'ensemble de données d'assurance automobile
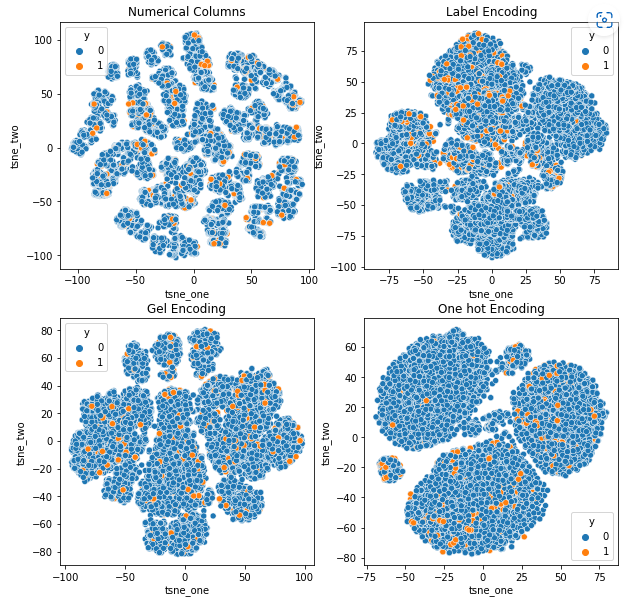
-
Les données sont plus proches les unes des autres car le nombre de lignes est plus élevé que dans l'ensemble de données Car Insurance. Il devient difficile de séparer avec une dimensionnalité accrue dans l'encodage One Hot.
-
L'encodage GEL est meilleur que l'encodage One Hot dans tous les cas sauf DAGMM.
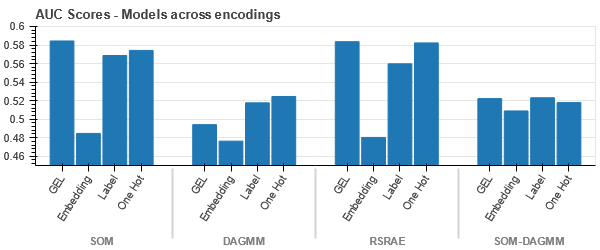
Représentation t-SNE de l'ensemble de données Vehicle Claims
-
Les données sont étroitement liées dans tous les cas, ce qui rend difficile la séparation avec une dimensionnalité accrue. C'est l'une des raisons des mauvaises performances des modèles dues à une dimensionnalité accrue.
- SOM surpasse tous les autres modèles pour cet ensemble de données. Néanmoins, la couche d'intégration est plus adaptée dans la plupart des cas, ce qui nous permet une alternative à l'encodage attributs catégoriels pour la détection d'anomalies.
Conclusion
Cet article présente un bref aperçu des données d'audit, de la détection des anomalies et des encodages catégoriels. Il est important de comprendre que la gestion des attributs catégoriels dans les données d'audit est difficile. En comprenant l'impact de l'encodage des attributs sur les modèles, nous pouvons améliorer la précision de la détection des anomalies dans les ensembles de données. Les principaux points à retenir de cet article sont :
- À mesure que la taille des données augmente, il est important d'utiliser des approches de codage alternatives pour les attributs catégoriels, comme le codage GEL et les couches d'intégration, car le codage One Hot ne convient pas.
- Un modèle ne fonctionne pas pour tous les ensembles de données. Pour les ensembles de données tabulaires, la connaissance du domaine est extrêmement importante.
- Le choix de la méthode de codage dépend du choix du modèle.
Le code pour l'évaluation des modèles est disponible sur GitHub.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- Qui sommes-nous
- au dessus de
- Selon
- précision
- En outre
- propos
- Tous
- permet
- alternative
- toujours
- analytique
- Analytique Vidhya
- ainsi que
- Détection d'une anomalie
- approches
- article
- attribué
- associé
- assumé
- attributs
- audit
- Automatique
- disponibles
- basé
- car
- devient
- before
- va
- ci-dessous
- repères
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Le plus grand
- lié
- brand
- ne peut pas
- capturer
- fournisseur
- assurance voiture
- carte
- maisons
- cas
- catégories
- challenge
- globaux
- difficile
- chances
- caractère
- le choix
- réclamer
- prétentions
- classe
- les classes
- classification
- Classer
- clair
- plus
- code
- Couleur
- communément
- Communautés
- Sociétés
- par rapport
- comparant
- rivaliser
- compétitif
- complexe
- concept
- confidentialité
- Qui consiste
- contient
- continu
- Entreprises
- Prix
- engendrent
- crédit
- carte de crédit
- données
- points de données
- ensembles de données
- Date
- traitement
- diminuer
- profond
- l'apprentissage en profondeur
- dépend
- détaillé
- Détection
- Déterminer
- différence
- différent
- difficile
- Dimension
- dimensions
- directement
- discrétion
- distance
- distinct
- distribution
- divisé
- domaine
- driver
- pendant
- chacun
- plus facilement
- non plus
- énergie
- erreur
- Erreurs
- estimation
- estimé
- estimations
- etc
- évaluer
- évaluation
- évaluations
- exemple
- exemples
- Sauf
- cher
- extrêmement
- face
- facteurs
- Fonctionnalité
- Fonctionnalités:
- Prénom
- forêt
- fraude
- frauduleux
- de
- Carburant
- Genre
- Groupes
- Maniabilité
- Haute
- augmentation
- HOT
- Cependant
- HTTPS
- Hybride
- identifier
- Impact
- important
- améliorer
- in
- comprendre
- inclut
- passif
- increased
- Augmente
- croissant
- indique
- d'information
- Systèmes D'Information
- contribution
- Assurance
- seul
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- ACTIVITES
- Savoir
- spécialisées
- connu
- Libellé
- l'étiquetage
- Etiquettes
- gros
- plus importantes
- couche
- poules pondeuses
- conduire
- APPRENTISSAGE
- savant
- apprentissage
- locales
- situé
- rechercher
- perte
- pertes
- Faible
- click
- machine learning
- Les machines
- Entrée
- FAIT DU
- Fabrication
- obligatoire
- Manuel
- de nombreuses
- Localisation
- assorti
- Matrice
- sens
- Médias
- moyenne
- méthode
- méthodes
- métrique
- minimum
- manquant
- Réduire les
- mélange
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- réseau et
- Neurones
- Nouveauté
- Nouvelles fonctionnalités
- Ordinaire
- nombre
- objectif
- ONE
- de commander
- Autre
- Surperforme
- Overcome
- vue d'ensemble
- propriété
- paramètres
- partie
- les pièces
- performant
- effectue
- personnel
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- des notes bonus
- pauvres
- Populaire
- possible
- préfère
- représentent
- cadeaux
- prix
- principe
- Avant
- probabilité
- Problème
- processus
- profession
- Projet
- données du projet
- Projection
- projets
- propriétés
- fournir
- à condition de
- fournit
- publié
- aléatoire
- gamme
- réal
- monde réel
- Les raisons
- récupération
- région
- Les relations
- réparation
- remplacé
- représentation
- représente
- a besoin
- résultat
- résultant
- Résultats
- robuste
- même
- Sciences
- sensible
- séparé
- montré
- Sigma
- similaires
- depuis
- unique
- Taille
- petit
- faibles
- So
- Space
- groupe de neurones
- départs
- Encore
- tel
- Souffre
- convient
- Support
- Surface
- haute
- Système
- table
- Points clés à retenir
- conditions
- Les
- le monde
- donc
- порог
- fermement
- long
- à
- Total
- Train
- Formation
- comprendre
- compréhension
- unique
- unité
- apprentissage non supervisé
- a actualisé
- us
- utilisé
- Plus-value
- Valeurs
- véhicule
- Véhicules
- poids
- Quoi
- Qu’est ce qu'
- qui
- tout en
- sera
- Word
- des mots
- Activités principales
- world
- pourra
- an
- zéphyrnet