Nous avons récemment annoncé le soutien à Formation AWS Lake politiques de contrôle d'accès affinées dans Amazone Athéna interroge les données stockées dans n'importe quel format de fichier pris en charge à l'aide de formats de table tels qu'Apache Iceberg, Apache Hudi et Apache Hive. AWS Lake Formation vous permet de définir et d'appliquer des politiques d'accès au niveau des bases de données, des tables et des colonnes pour interroger les tables Iceberg stockées dans Amazon S3. Lake Formation fournit une couche d'autorisation et de gouvernance sur les données stockées dans Amazon S3. Cette fonctionnalité nécessite que vous effectuiez une mise à niveau vers Moteur Athéna version 3.
Les grandes organisations ont souvent des lignes d'activités (LoBs) qui fonctionnent avec autonomie dans la gestion de leurs données commerciales. Cela rend le partage de données entre LoBs non trivial. Ces organisations ont adopté un modèle fédéré, chaque LoB ayant l'autonomie pour prendre des décisions sur ses données. Ils utilisent le modèle éditeur/consommateur avec une couche de gouvernance centralisée qui est utilisée pour appliquer les contrôles d'accès. Si vous souhaitez en savoir plus sur l'architecture de maillage de données, visitez Concevoir une architecture de maillage de données à l'aide d'AWS Lake Formation et d'AWS Glue. Avec la version 3 du moteur Athena, les clients peuvent utiliser les mêmes contrôles précis pour les infrastructures de données ouvertes telles qu'Apache Iceberg, Apache Hudi et Apache Hive.
Dans cet article, nous approfondissons un cas d'utilisation dans lequel vous disposez d'un modèle producteur/consommateur avec partage de données activé pour donner un accès restreint à une table Apache Iceberg que le consommateur peut interroger. Nous discuterons du filtrage des colonnes pour restreindre certaines lignes, du filtrage pour restreindre l'accès au niveau des colonnes, de l'évolution du schéma et du voyage dans le temps.
Vue d'ensemble de la solution
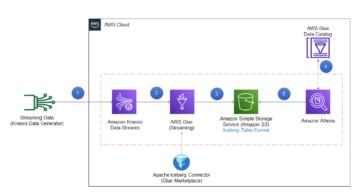
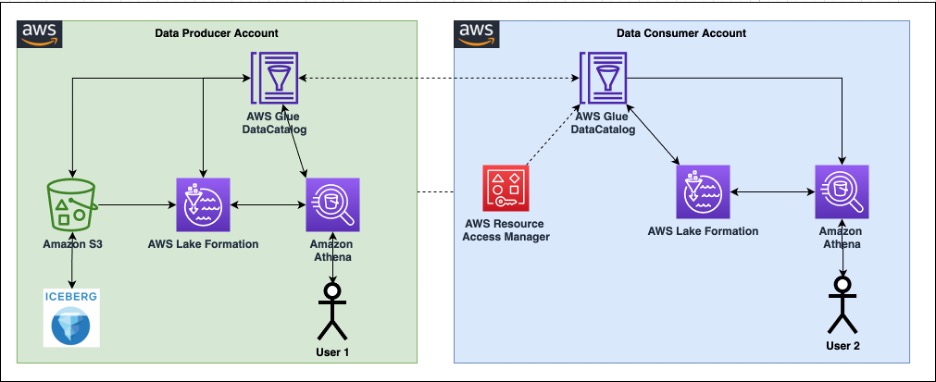
Pour illustrer la fonctionnalité des autorisations fines pour les tables Apache Iceberg avec Athena et Lake Formation, nous avons configuré les composants suivants :
- Dans le compte producteur :
- An Colle AWS Data Catalog pour enregistrer le schéma d'une table au format Apache Iceberg
- Lake Formation fournira un accès précis au compte client
- Athena pour vérifier les données du compte du producteur
- Dans le compte consommateur :
- Gestionnaire d'accès aux ressources AWS (AWS RAM) pour créer une poignée de main entre le producteur Data Catalog et le consommateur
- Lake Formation fournira un accès précis au compte client
- Athena vérifiera les données du compte du producteur
Le diagramme suivant illustre l'architecture.
Pré-requis
Avant de commencer, assurez-vous d'avoir les éléments suivants :
Configuration du producteur de données
Dans cette section, nous présentons les étapes de mise en place du producteur de données.
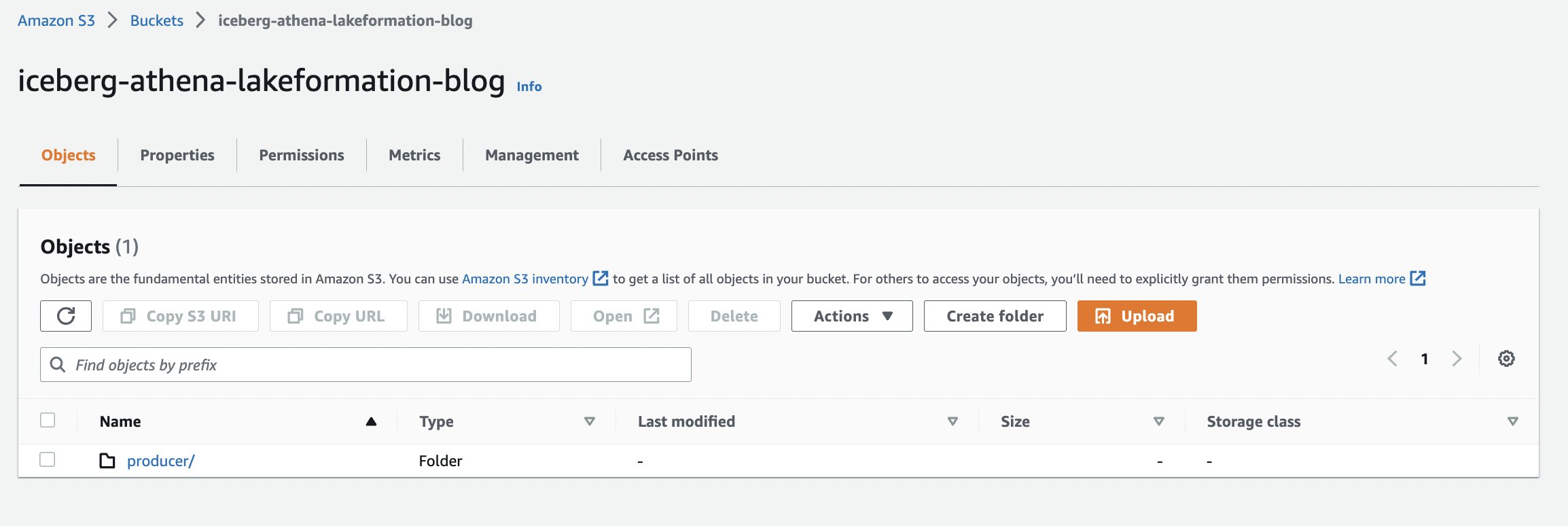
Créer un compartiment S3 pour stocker les données de la table
Nous créons un nouveau bucket S3 pour enregistrer les données de la table :
- Sur la console Amazon S3, créer un compartiment S3 avec un nom unique (pour ce post, nous utilisons
iceberg-athena-lakeformation-blog). - Créez le dossier du producteur dans le compartiment à utiliser pour la table.
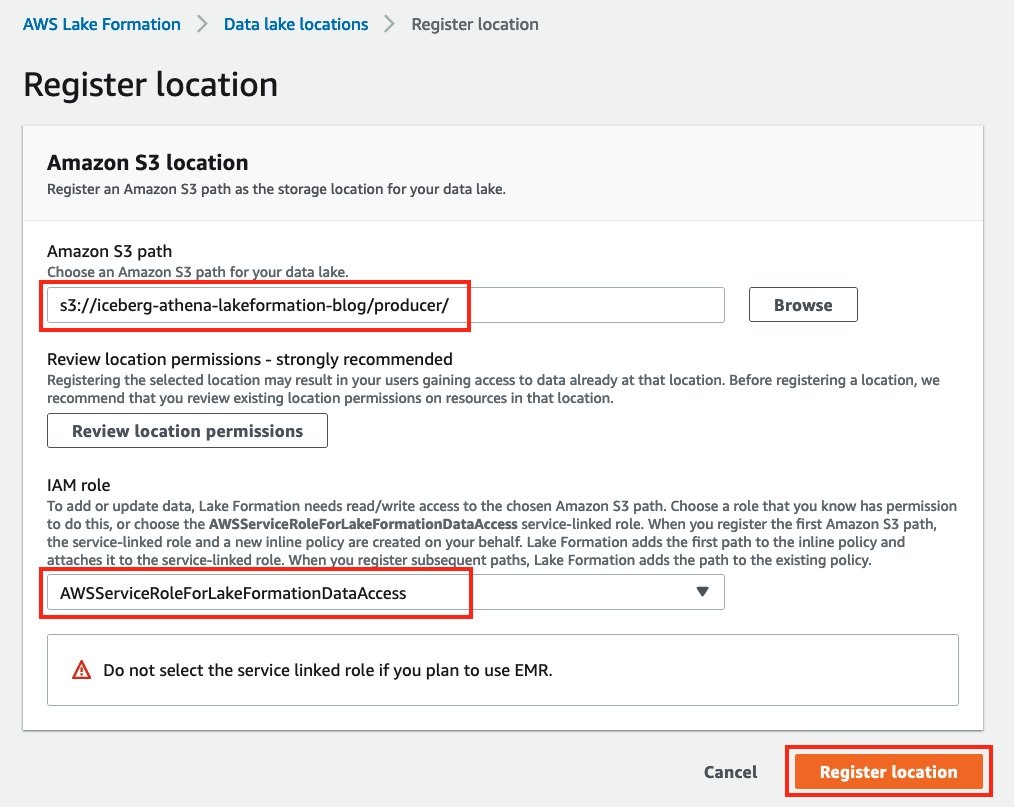
Enregistrez le chemin S3 stockant la table à l'aide de Lake Formation
Nous enregistrons le chemin complet S3 dans Lake Formation :
- Accédez à la console Lake Formation.
- Si vous vous connectez pour la première fois, vous êtes invité à créer un utilisateur administrateur.
- Dans le volet de navigation, sous S'inscrire et ingérer, choisissez Emplacements des lacs de données.
- Selectionnez Enregistrer l'emplacement, et indiquez le chemin d'accès au compartiment S3 que vous avez créé précédemment.
- Selectionnez
AWSServiceRoleForLakeFormationDataAccessen Rôle IAM.
Pour plus d'informations sur les rôles, reportez-vous à Conditions requises pour les rôles utilisés pour enregistrer des emplacements.
Si vous avez activé le chiffrement de votre compartiment S3, vous devez fournir des autorisations à Lake Formation pour effectuer des opérations de chiffrement et de déchiffrement. Faire référence à Enregistrement d'un emplacement Amazon S3 chiffré à titre indicatif.
- Selectionnez Enregistrer l'emplacement.
Créer une table Iceberg avec Athena
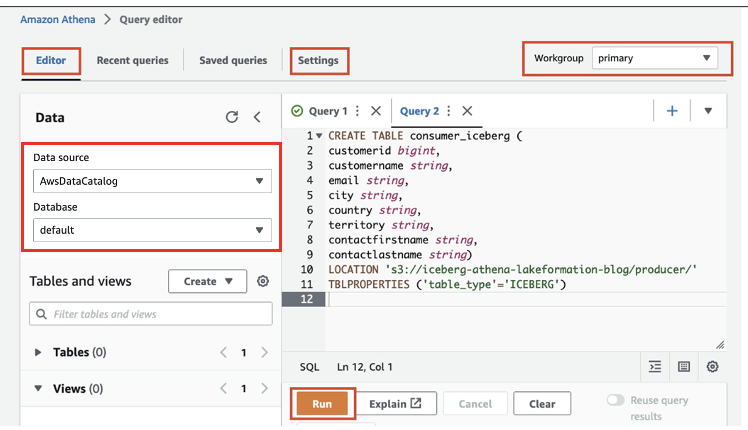
Créons maintenant la table en utilisant Athena soutenu par le format Apache Iceberg :
- Sur la console Athena, choisissez Éditeur de requête dans le volet de navigation.
- Si vous utilisez Athena pour la première fois, sous Paramètres, choisissez Gérer et entrez l'emplacement du compartiment S3 que vous avez créé précédemment (
iceberg-athena-lakeformation-blog/producer). - Selectionnez Épargnez.
- Dans l'éditeur de requête, saisissez la requête suivante (remplacez l'emplacement par le compartiment S3 que vous avez enregistré auprès de Lake Formation). Notez que nous utilisons la base de données par défaut, mais vous pouvez utiliser n'importe quelle autre base de données.
- Selectionnez Courir.
Partager la table avec le compte consommateur
Pour illustrer la fonctionnalité, nous implémentons les scénarios suivants :
- Donner accès aux colonnes sélectionnées
- Fournir un accès aux lignes sélectionnées en fonction d'un filtre
Effectuez les étapes suivantes:
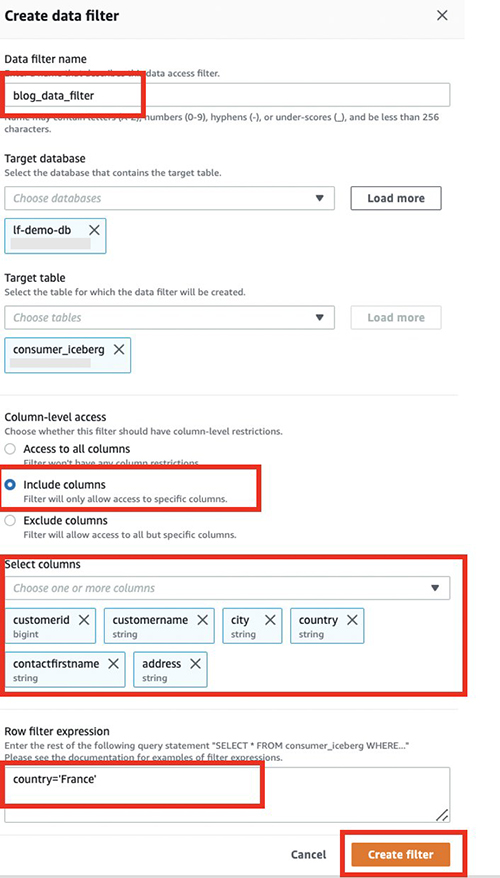
- Sur la console Lake Formation, dans le volet de navigation sous Catalogue de données, choisissez Filtres de données.
- Selectionnez Créer un nouveau filtre.
- Pour Nom du filtre de données, Entrer
blog_data_filter. - Pour Base de données cible, Entrer
lf-demo-db. - Pour Tableau cible, Entrer
consumer_iceberg. - Pour Accès au niveau des colonnes, sélectionnez Inclure les colonnes.
- Choisissez les colonnes à partager avec le consommateur :
country, address, contactfirstname, city, customerid,ainsi quecustomername. - Pour Expression de filtre de ligne, entrez le filtre
country='France'. - Selectionnez Créer un filtre.
Accordons maintenant l'accès au compte client sur le consumer_iceberg tableau.
- Dans le volet de navigation, choisissez Tables.
- Sélectionnez la table consumer_iceberg et choisissez Subvention sur le Actions menu.
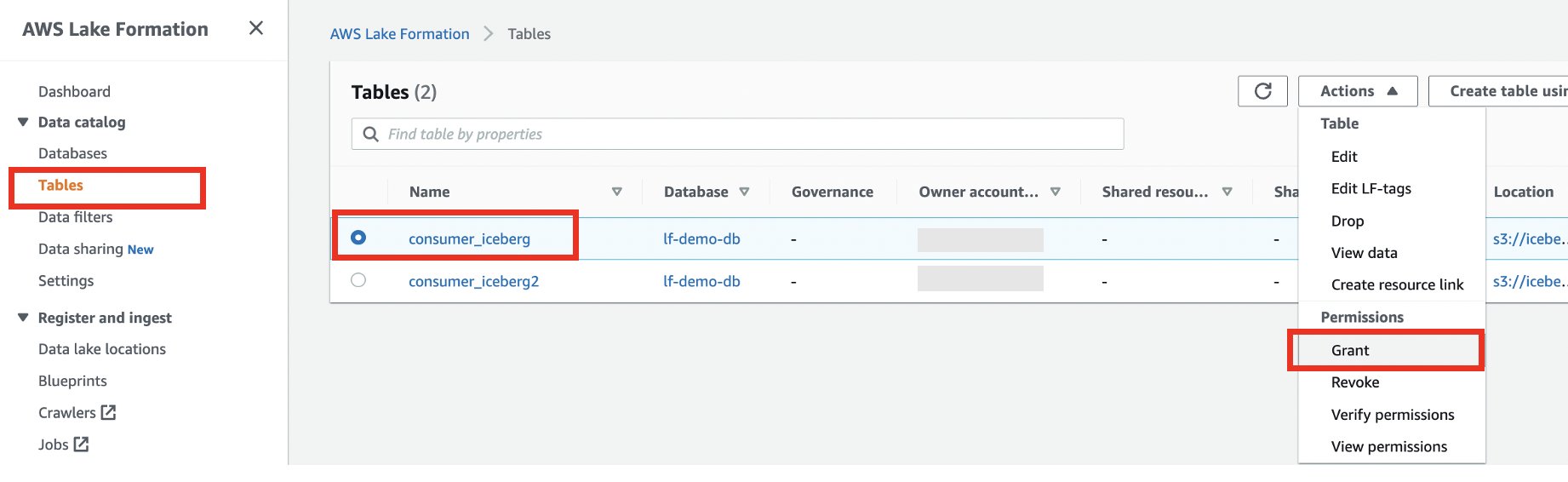
- Sélectionnez Comptes externes.
- Entrez l'ID de compte externe.
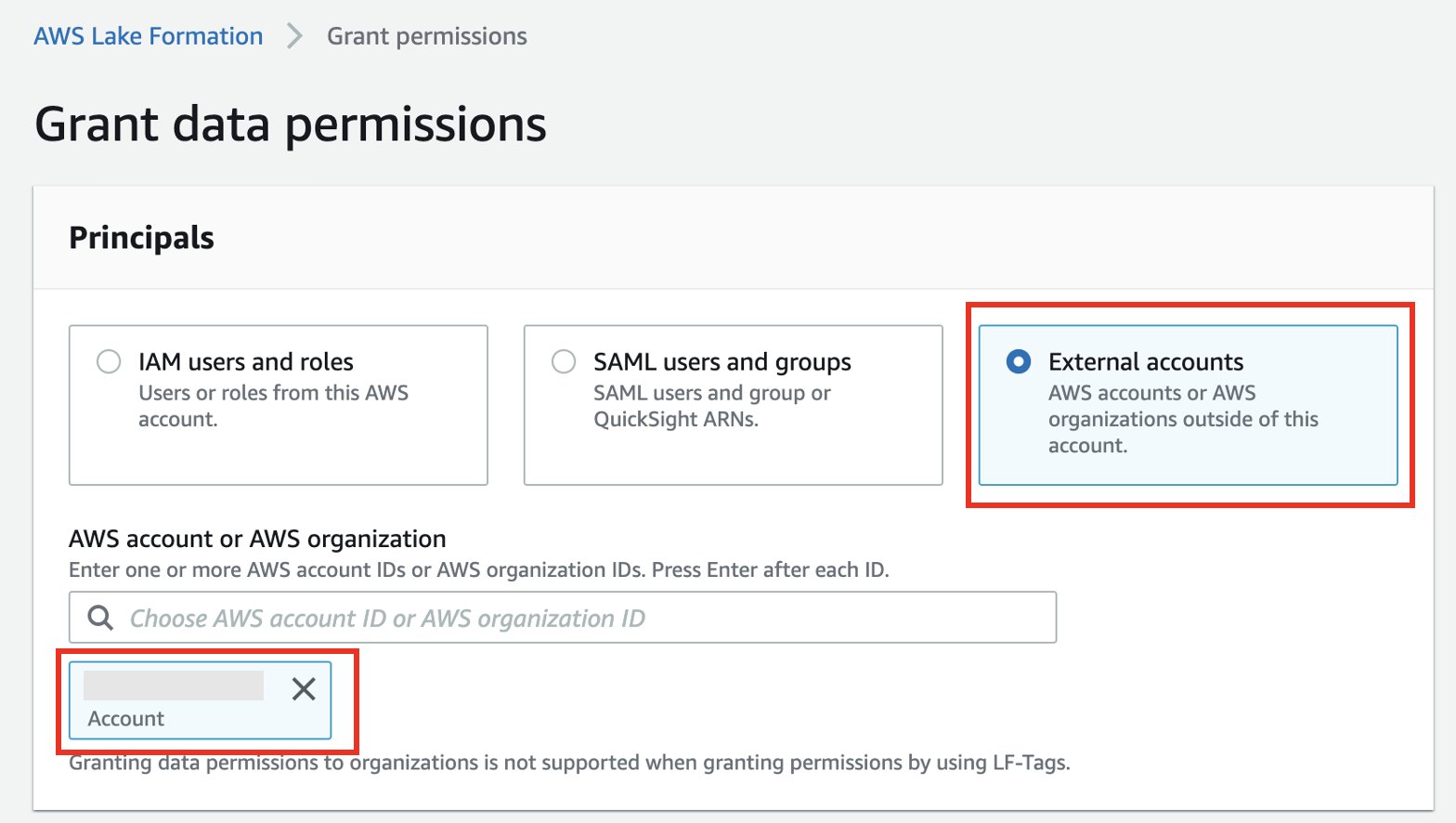
- Sélectionnez Ressources de catalogue de données nommées.
- Choisissez votre base de données et votre table.
- Pour Filtres de données, choisissez le filtre de données que vous avez créé.
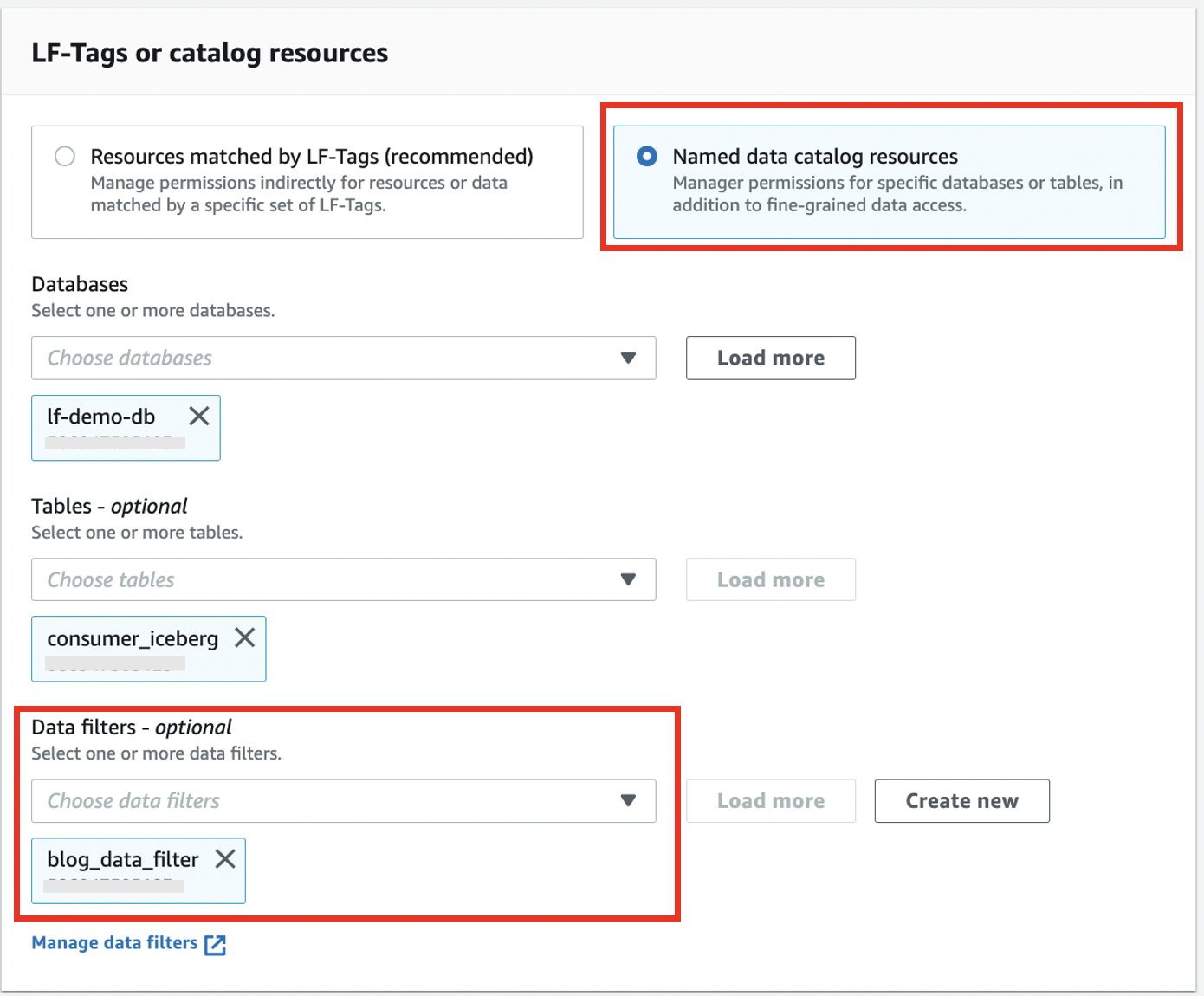
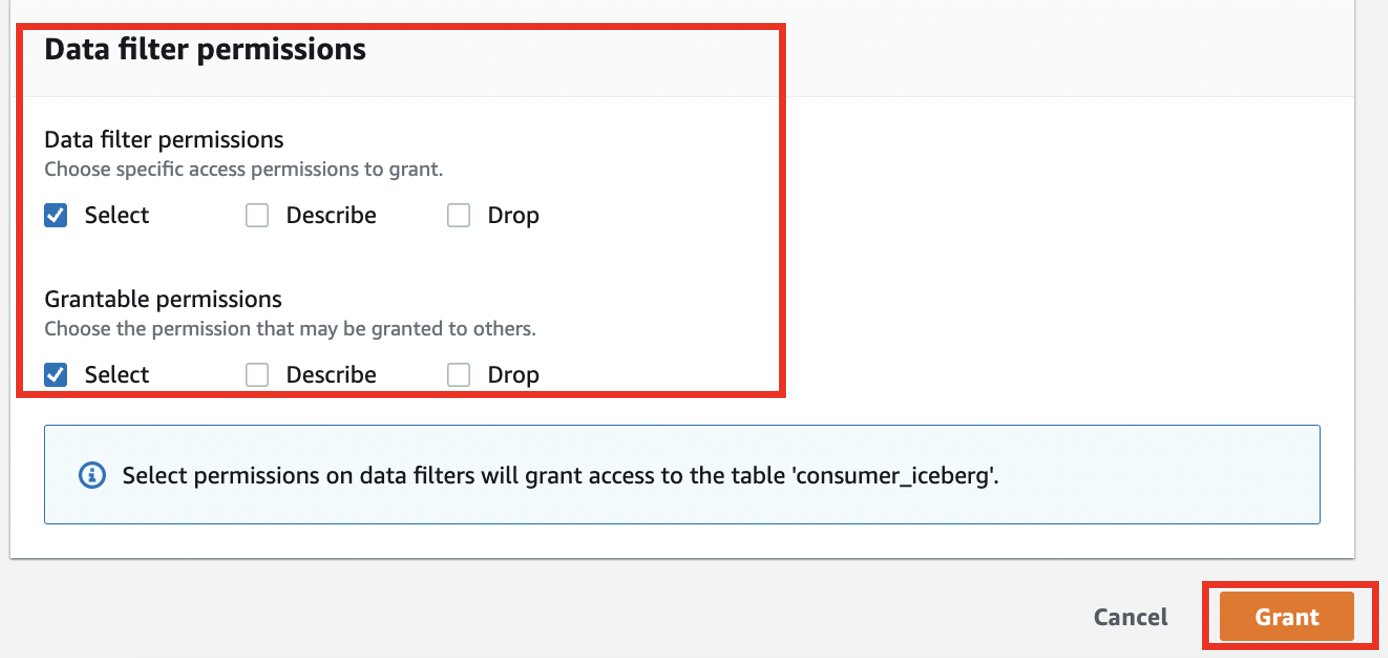
- Pour Autorisations de filtre de données ainsi que Autorisations accordables, sélectionnez Sélectionnez.
- Selectionnez Subvention.
Configuration du consommateur de données
Pour configurer le consommateur de données, nous acceptons le partage de ressources et créons une table à l'aide d'AWS RAM et de Lake Formation. Effectuez les étapes suivantes :
- Connectez-vous au compte consommateur et accédez à la console AWS RAM.
- Sous Partagé avec moi dans le volet de navigation, choisissez Partages de ressources.
- Choisissez votre partage de ressources.
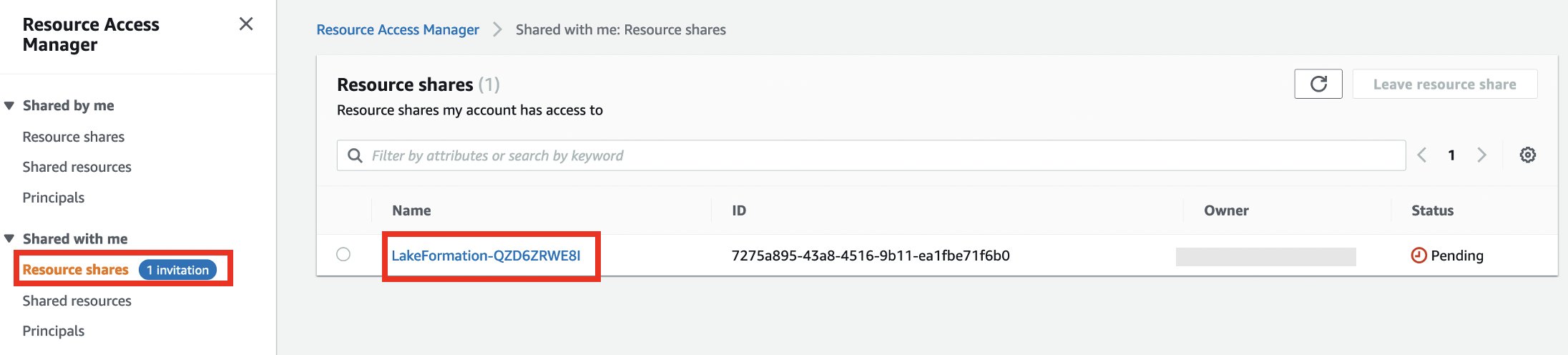
- Selectionnez Accepter le partage des ressources.
- Notez le nom du partage de ressources à utiliser dans les étapes suivantes.
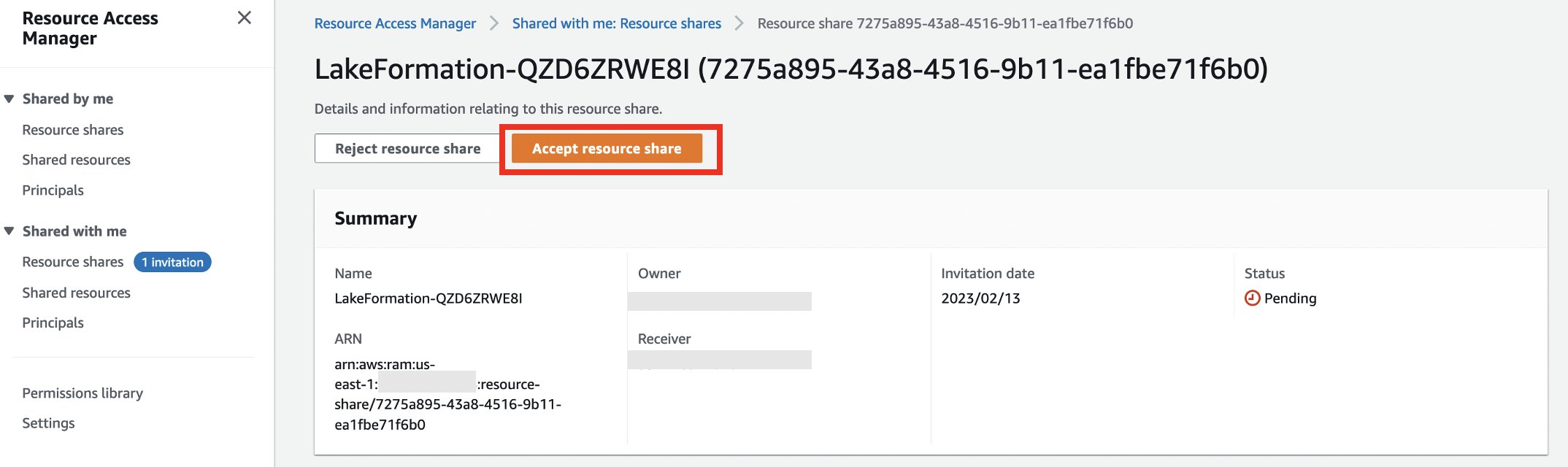
- Accédez à la console Lake Formation.
- Si vous vous connectez pour la première fois, vous êtes invité à créer un utilisateur administrateur.
- Selectionnez Bases de données dans le volet de navigation, puis choisissez votre base de données.
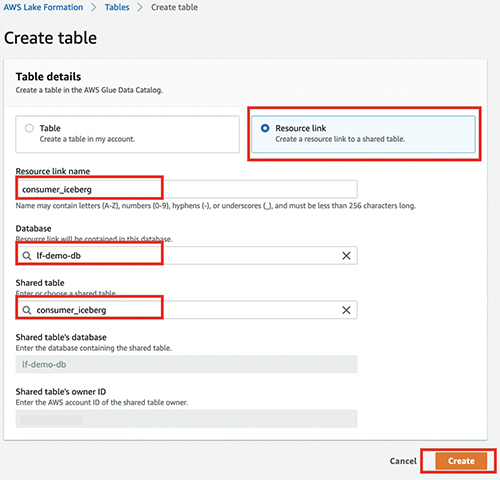
- Sur le Actions menu, choisissez Créer un lien de ressource.

- Pour Nom du lien de la ressource, entrez le nom de votre lien de ressource (par exemple,
consumer_iceberg). - Choisissez votre base de données et votre table partagée.
- Selectionnez Création.
Valider la solution
Nous pouvons maintenant exécuter différentes opérations sur les tables pour valider les contrôles d'accès précis.
Opération d'insertion
Insérons des données dans le consumer_iceberg table dans le compte producteur, et valider que le filtrage des données fonctionne comme prévu dans le compte consommateur.
- Connectez-vous au compte producteur.
- Sur la console Athena, choisissez Éditeur de requête dans le volet de navigation.
- Utilisez le SQL suivant pour écrire et insérer des données dans la table Iceberg. Utilisez l'éditeur de requête pour exécuter une requête à la fois. Vous pouvez mettre en surbrillance/sélectionner une requête à la fois et cliquer sur "Exécuter"/"Exécuter à nouveau :

- Utilisez le SQL suivant pour lire et sélectionner des données dans la table Iceberg :
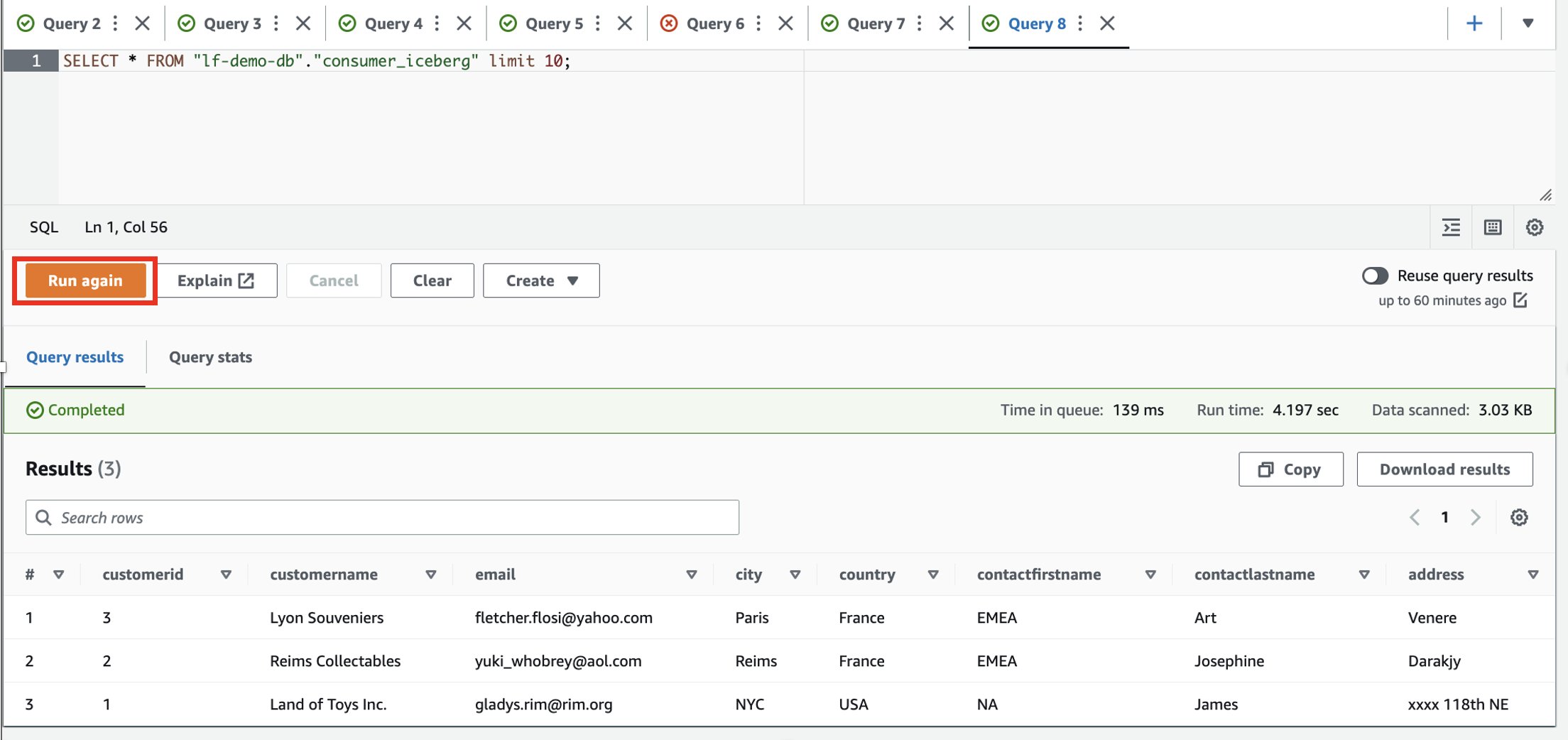
- Connectez-vous au compte consommateur.
- Dans l'éditeur de requête Athena, exécutez la requête SELECT suivante sur la table partagée :
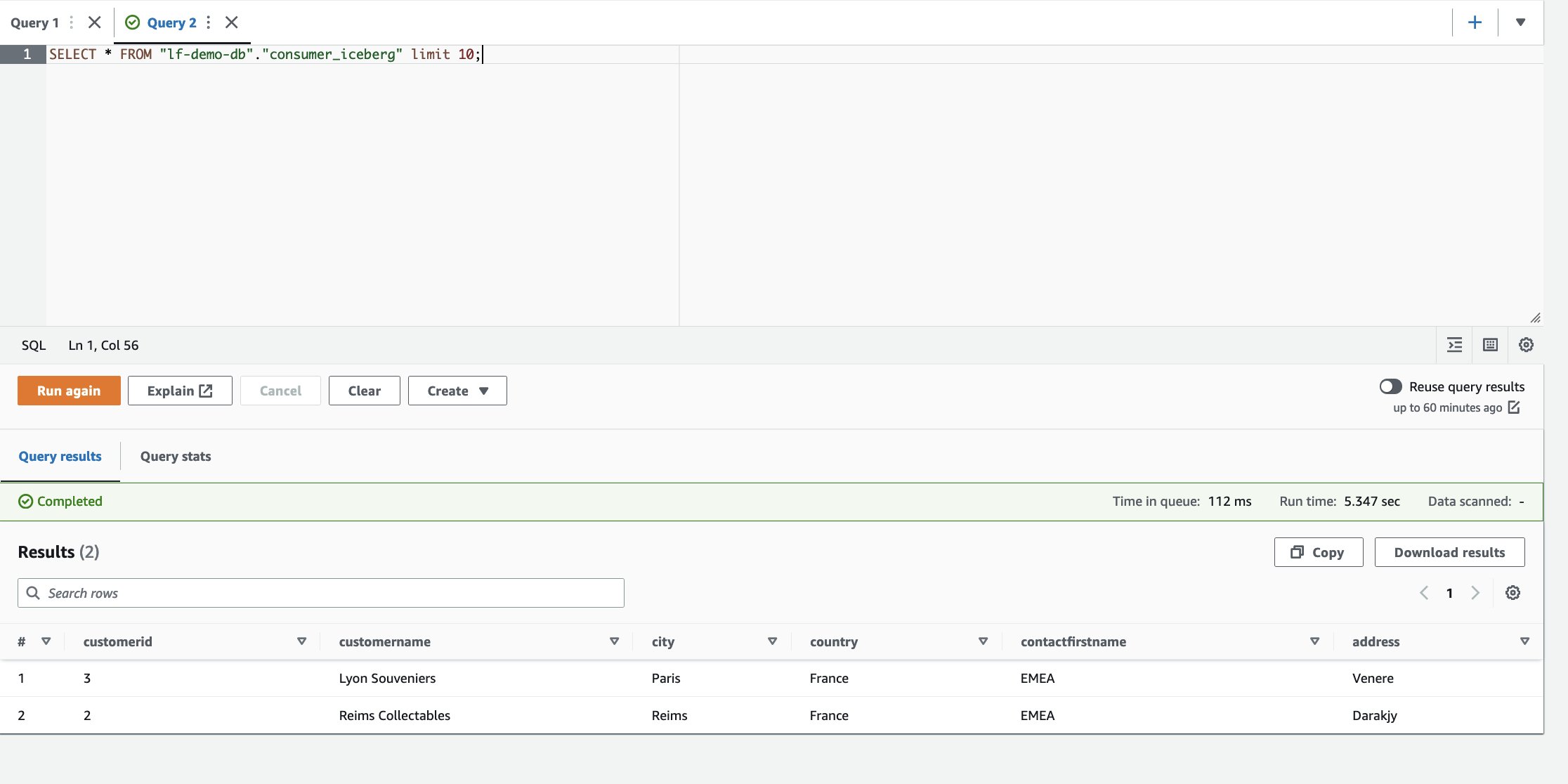
Sur la base des filtres, le consommateur a une visibilité sur un sous-ensemble de colonnes et de lignes où le pays est la France.
Opérations de mise à jour/suppression
Maintenant, mettons à jour l'une des lignes et supprimons-en une du jeu de données partagé avec le consommateur.
- Connectez-vous au compte producteur.
- Mises à jour
city='Paris' WHERE city='Reims'et supprimer la lignecustomerid = 3;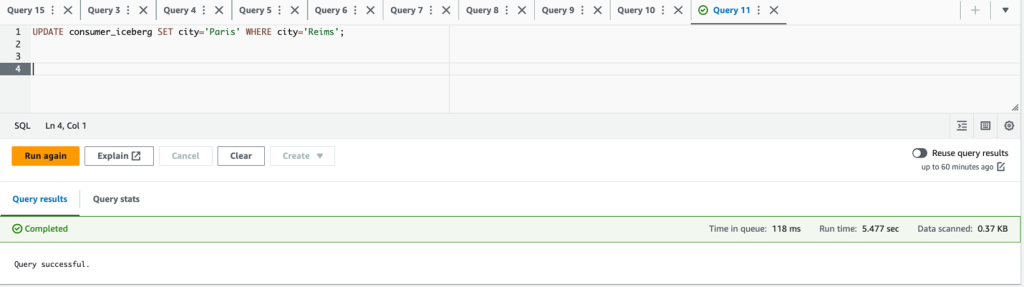

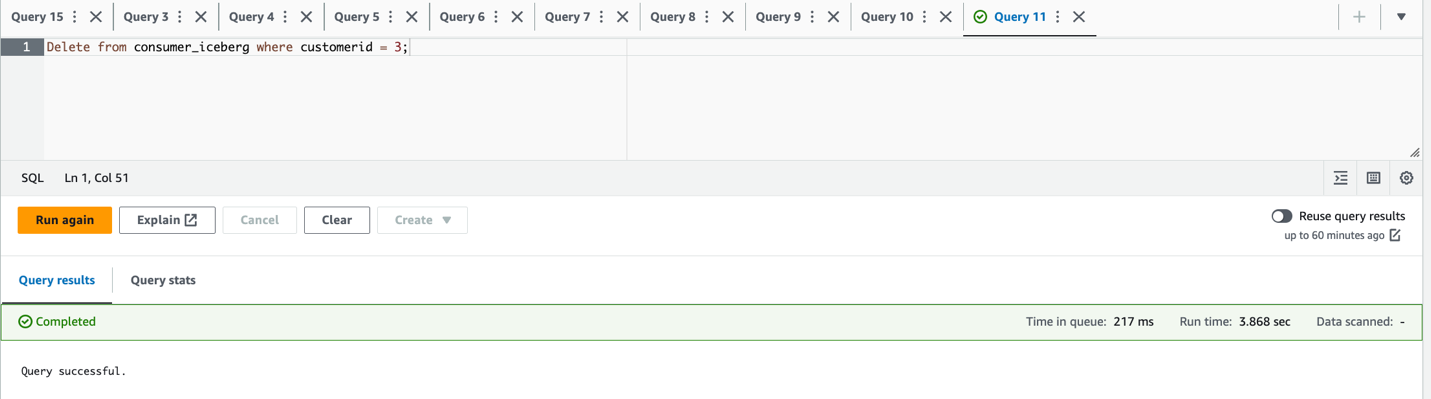
- Vérifiez l'ensemble de données mis à jour et supprimé :
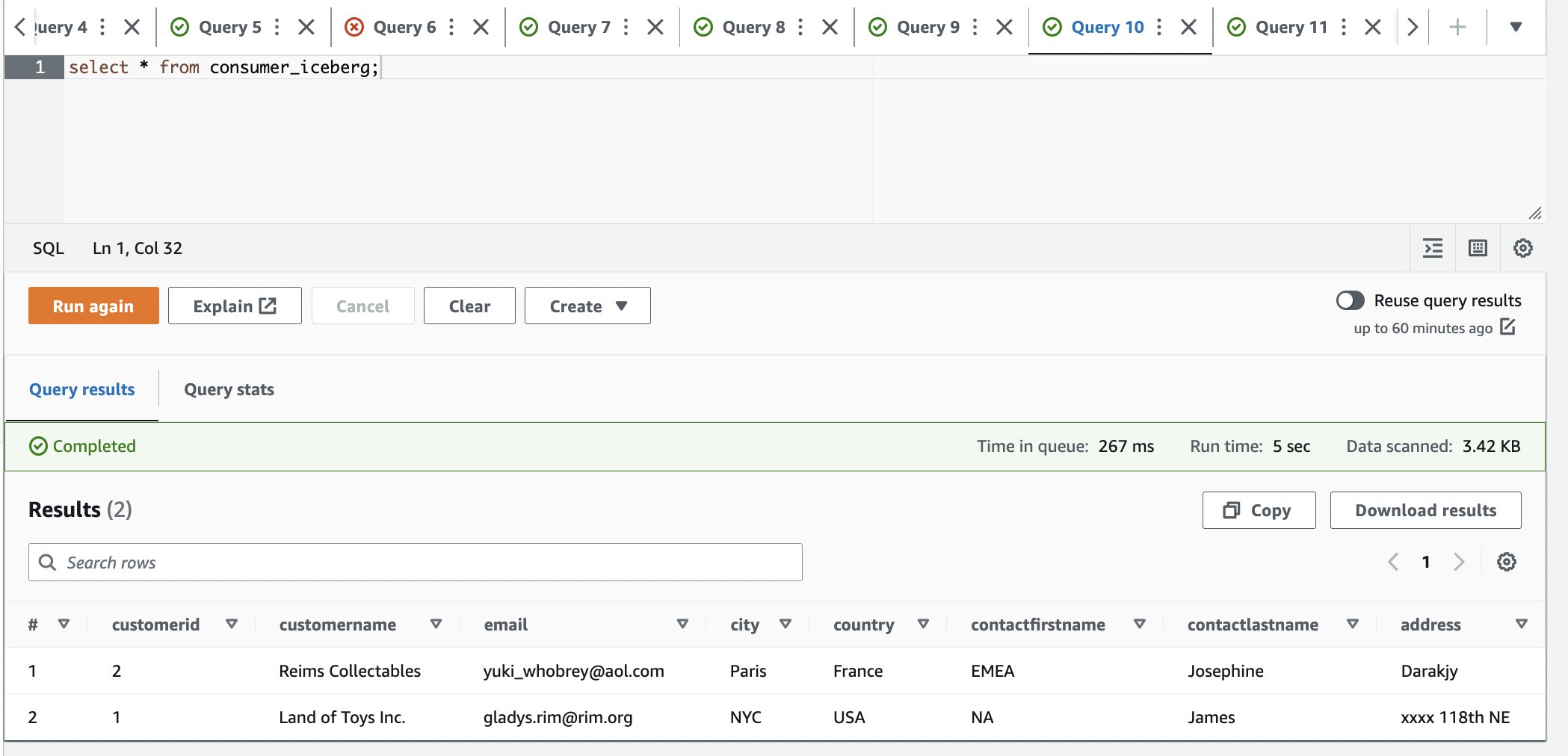
- Connectez-vous au compte consommateur.
- Dans l'éditeur de requête Athena, exécutez la requête SELECT suivante sur la table partagée :
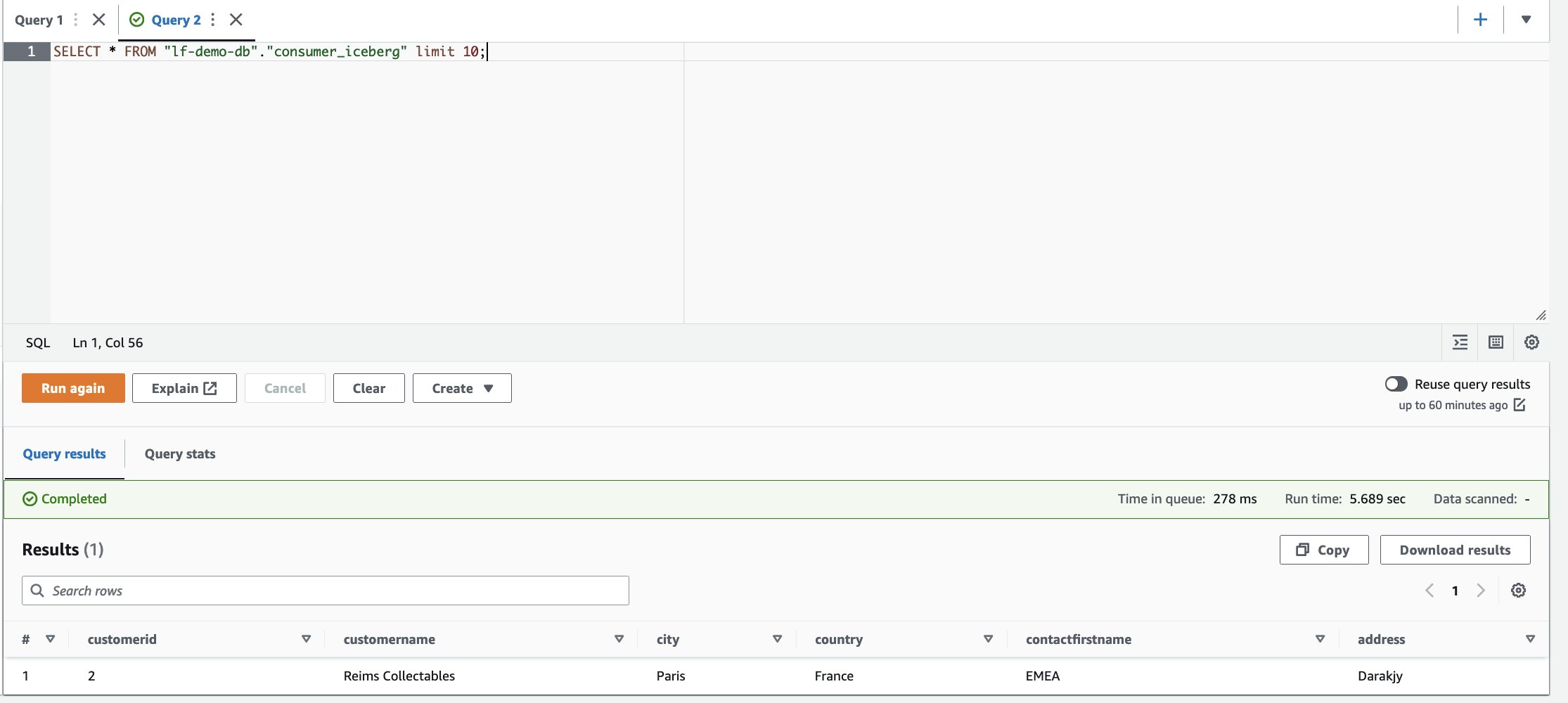
Nous pouvons observer qu'une seule ligne est disponible et la ville est mise à jour à Paris.
Évolution du schéma : ajouter une nouvelle colonne
Mettons à jour l'une des lignes et supprimons-en une du jeu de données partagé avec le consommateur.
- Connectez-vous au compte producteur.
- Ajouter une nouvelle colonne appelée
geo_locdans le tableau Iceberg. Utilisez l'éditeur de requête pour exécuter une requête à la fois. Vous pouvez mettre en surbrillance/sélectionner une requête à la fois et cliquer sur "Exécuter"/"Exécuter à nouveau :
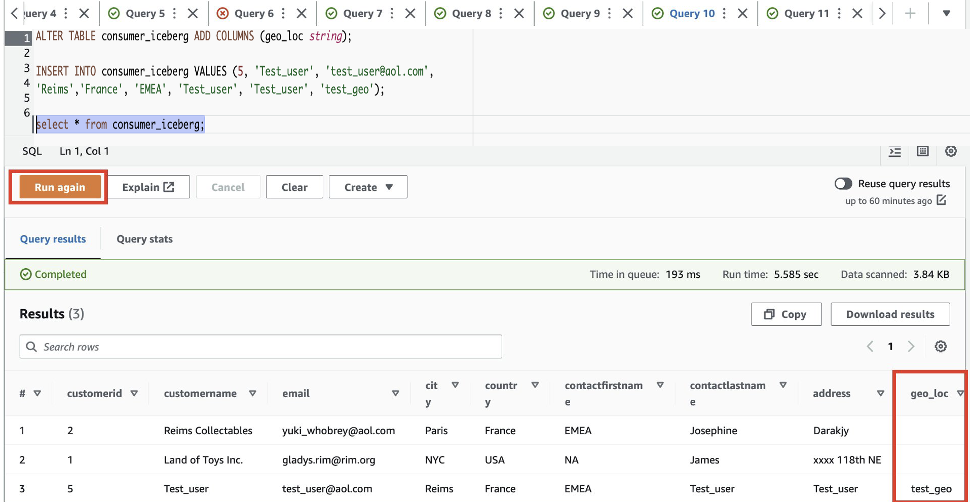
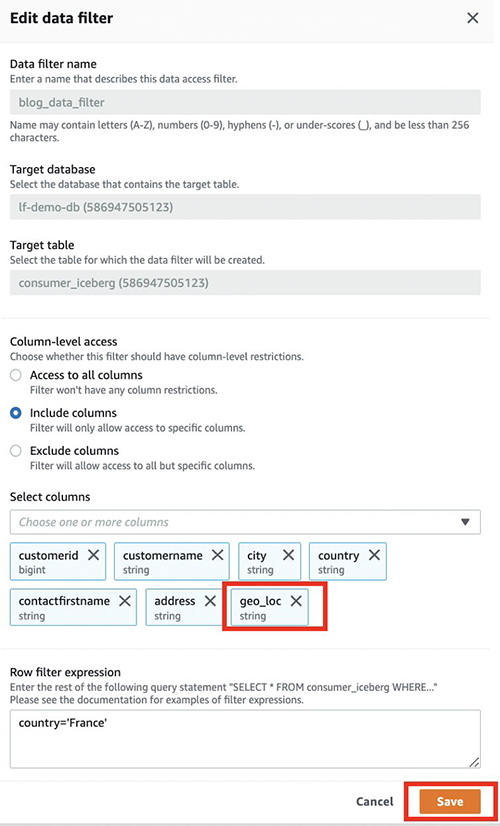
Pour donner de la visibilité aux nouveaux geo_loc colonne, nous devons mettre à jour le filtre de données Lake Formation.
- Sur la console Lake Formation, choisissez Filtres de données dans le volet de navigation.
- Sélectionnez votre filtre de données et choisissez Modifier.

- Sous Accès au niveau des colonnes, ajoutez la nouvelle colonne (
geo_loc). - Selectionnez Épargnez.
- Connectez-vous au compte consommateur.
- Dans l'éditeur de requête Athena, exécutez la commande suivante
SELECTrequête sur la table partagée :
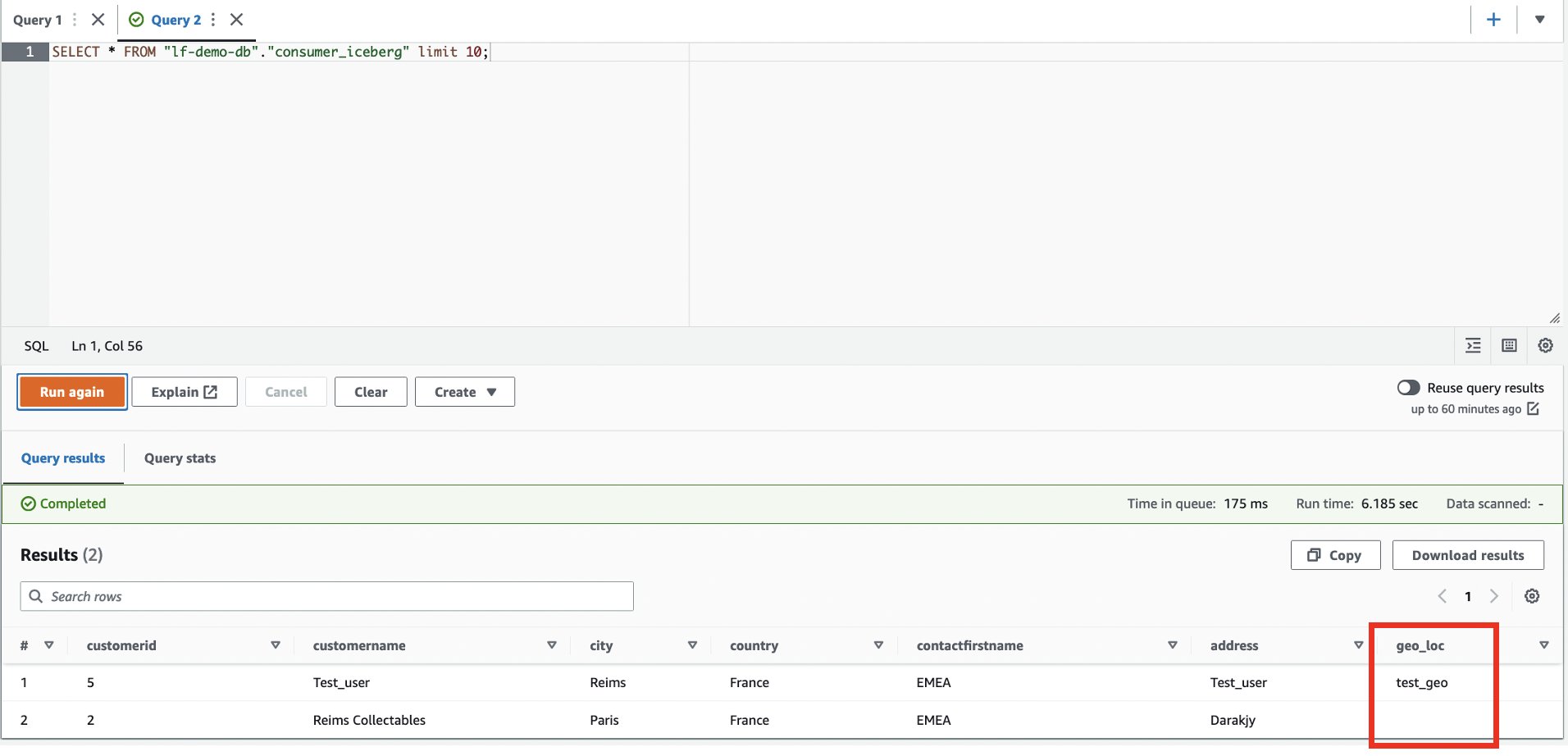
La nouvelle colonne geo_loc est visible et une ligne supplémentaire.
Évolution du schéma : Supprimer la colonne
Mettons à jour l'une des lignes et supprimons-en une du jeu de données partagé avec le consommateur.
- Connectez-vous au compte producteur.
- Modifiez la table pour supprimer la colonne d'adresse de la table Iceberg. Utilisez l'éditeur de requête pour exécuter une requête à la fois. Vous pouvez mettre en surbrillance/sélectionner une requête à la fois et cliquer sur "Exécuter"/"Exécuter à nouveau :

Nous pouvons observer que l'adresse de la colonne n'est pas présente dans le tableau.
- Connectez-vous au compte consommateur.
- Dans l'éditeur de requête Athena, exécutez la requête SELECT suivante sur la table partagée :
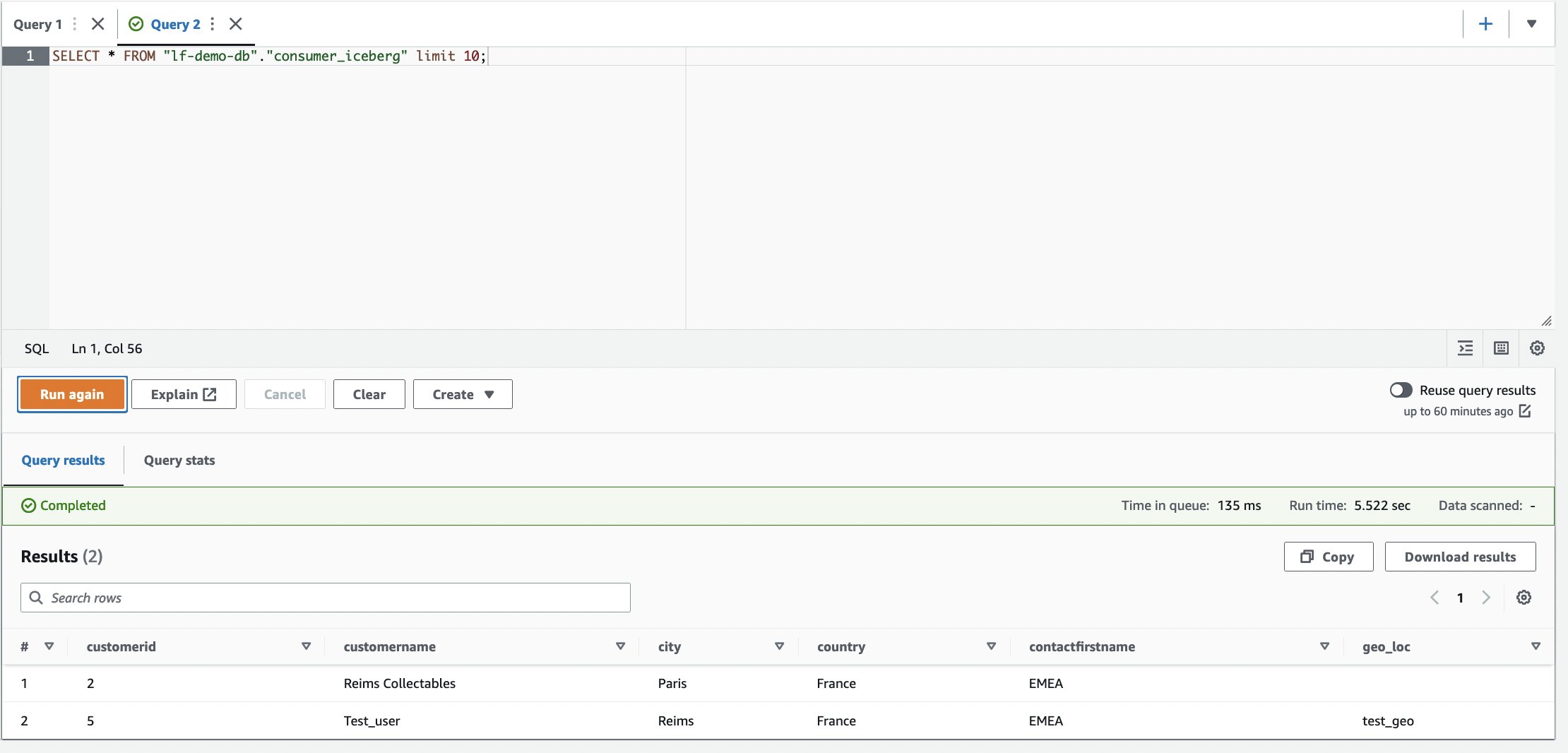
L'adresse de la colonne n'est pas présente dans la table.
Voyage dans le temps
Nous avons maintenant changé la table Iceberg plusieurs fois. La table Iceberg assure le suivi des instantanés. Effectuez les étapes suivantes pour explorer la fonctionnalité de voyage dans le temps :
- Connectez-vous au compte producteur.
- Interrogez la table système :
Nous pouvons observer que nous avons généré plusieurs instantanés.
- Notez l'un des
committed_atvaleurs à utiliser dans les étapes suivantes (pour cet exemple,2023-01-29 21:35:02.176 UTC).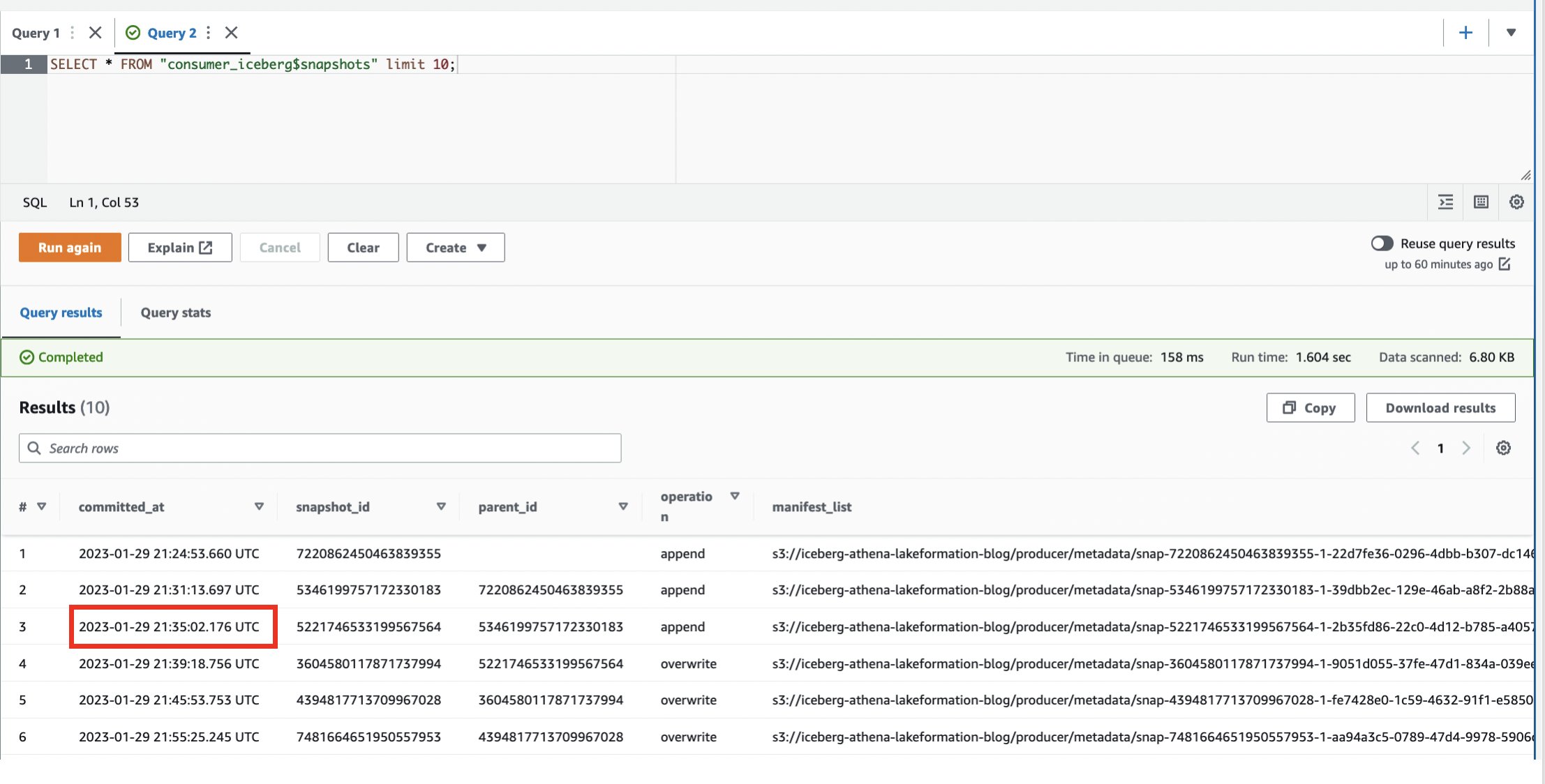
- Utilisez le voyage dans le temps pour trouver l'instantané de la table. Utilisez l'éditeur de requête pour exécuter une requête à la fois. Vous pouvez mettre en surbrillance/sélectionner une requête à la fois et cliquer sur "Exécuter"/"Exécuter à nouveau :
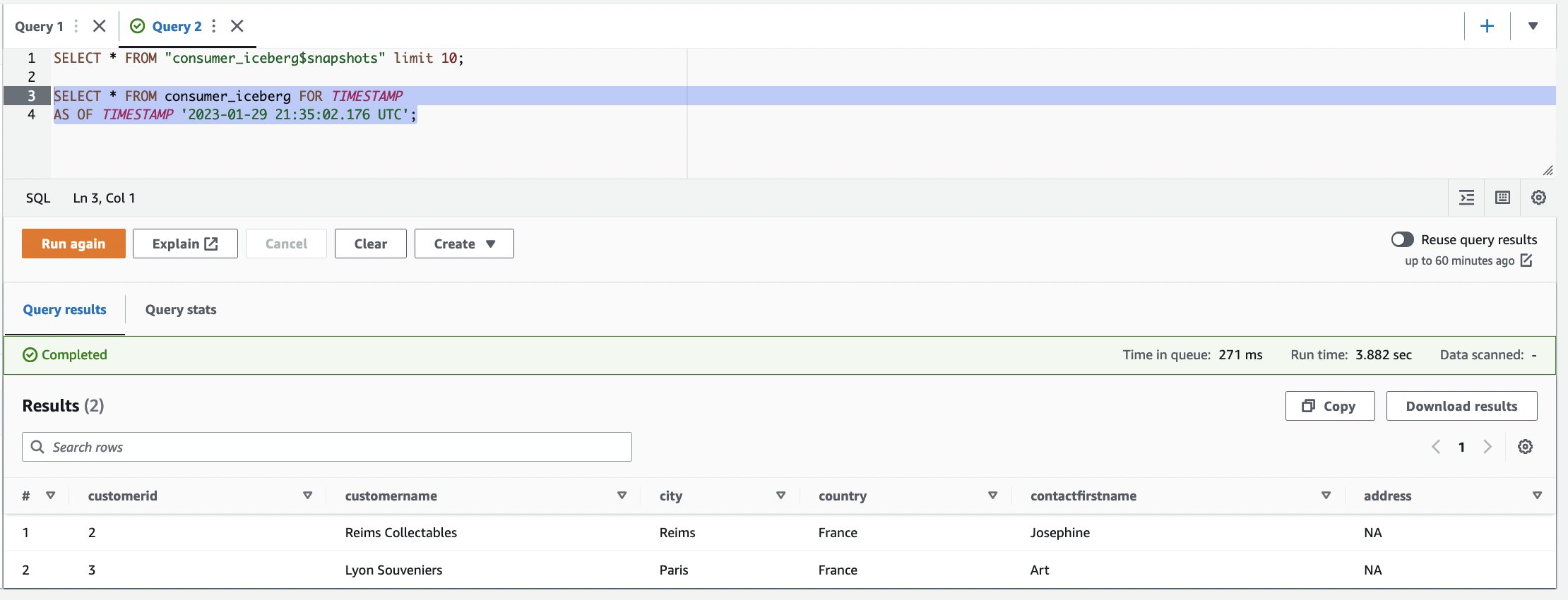
Nettoyer
Effectuez les étapes suivantes pour éviter d'encourir des frais futurs :
- Sur la console Amazon S3, supprimez le bucket de stockage de table (pour cet article, iceberg-athena-lakeformation-blog).
- Dans le compte producteur de la console Athena, exécutez les commandes suivantes pour supprimer les tables que vous avez créées :
- Dans le compte producteur sur la console Lake Formation, révoquez les autorisations du compte consommateur.
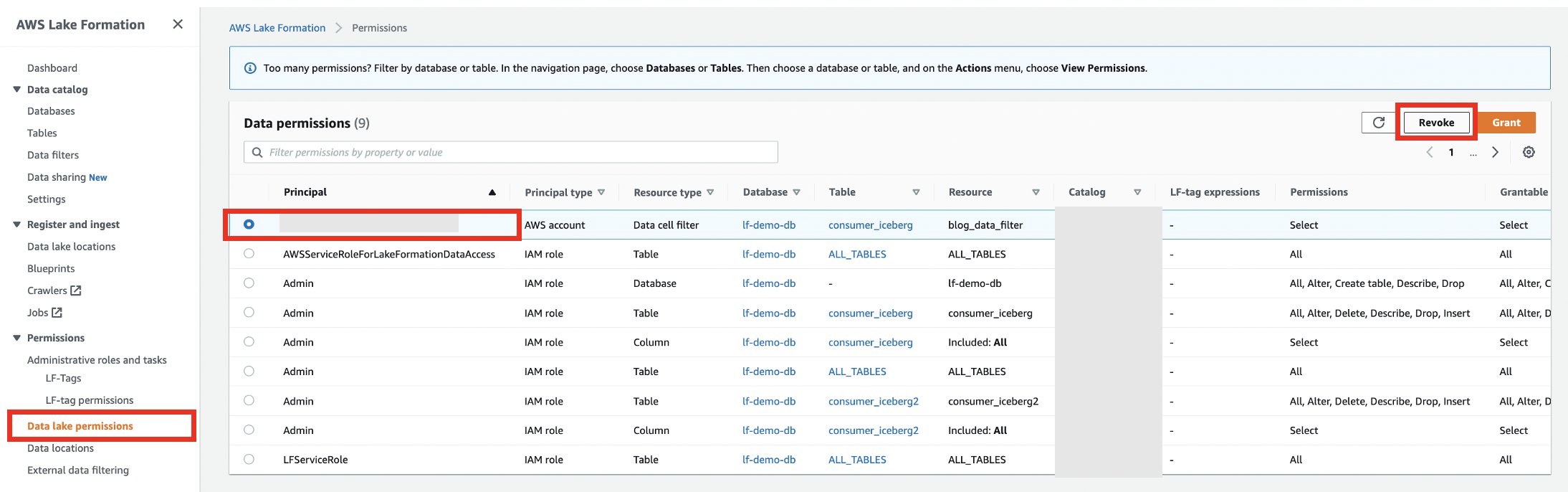
- Supprimez le compartiment S3 utilisé pour l'emplacement des résultats de la requête Athena du compte client.
Conclusion
Grâce à la prise en charge des politiques de contrôle d'accès à granularité fine entre comptes pour des formats tels qu'Iceberg, vous avez la possibilité de travailler avec n'importe quel format pris en charge par Athena. La possibilité d'effectuer des opérations CRUD sur les données de votre lac de données S3, combinée aux contrôles d'accès précis de Lake Formation pour toutes les tables et tous les formats pris en charge par Athena, offre des opportunités d'innover et de simplifier votre stratégie de données. Nous serions ravis d'entendre vos commentaires !
À propos des auteurs
 Kishore Dhamodaran est architecte de solutions senior chez AWS. Kishore aide ses clients stratégiques dans leur stratégie d'entreprise cloud et leur parcours de migration, en s'appuyant sur ses années d'expérience dans l'industrie et le cloud.
Kishore Dhamodaran est architecte de solutions senior chez AWS. Kishore aide ses clients stratégiques dans leur stratégie d'entreprise cloud et leur parcours de migration, en s'appuyant sur ses années d'expérience dans l'industrie et le cloud.
 Jack Ye est ingénieur logiciel de l'équipe Athena Data Lake and Storage chez AWS. Il est Apache Iceberg Committer et membre PMC.
Jack Ye est ingénieur logiciel de l'équipe Athena Data Lake and Storage chez AWS. Il est Apache Iceberg Committer et membre PMC.
 Chris Olson est ingénieur en développement logiciel chez AWS.
Chris Olson est ingénieur en développement logiciel chez AWS.
 Xiao Xuan Li est ingénieur en développement logiciel chez AWS.
Xiao Xuan Li est ingénieur en développement logiciel chez AWS.
 Rahul Sonawane est un architecte principal de solutions d'analyse chez AWS avec l'IA/ML et l'analyse comme domaine de spécialité.
Rahul Sonawane est un architecte principal de solutions d'analyse chez AWS avec l'IA/ML et l'analyse comme domaine de spécialité.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/interact-with-apache-iceberg-tables-using-amazon-athena-and-cross-account-fine-grained-permissions-using-aws-lake-formation/
- :est
- $UP
- 1
- 10
- 100
- 7
- a
- capacité
- À propos
- Accepter
- accès
- Compte
- à travers
- ajoutée
- Supplémentaire
- renseignements supplémentaires
- propos
- admin
- adopté
- à opposer à
- AI / ML
- Tous
- permet
- Amazon
- Amazone Athéna
- analytique
- ainsi que
- Apache
- architecture
- SONT
- Réservé
- L'art
- AS
- At
- autorisation
- disponibles
- éviter
- AWS
- Formation AWS Lake
- soutenu
- basé
- jusqu'à XNUMX fois
- la performance des entreprises
- entreprises
- by
- appelé
- CAN
- catalogue
- centralisée
- certaines
- Change
- des charges
- Selectionnez
- Ville
- cliquez
- le cloud
- Colonne
- Colonnes
- COM
- combiné
- complet
- composants électriques
- Console
- consommateur
- des bactéries
- contrôles
- Pays
- engendrent
- créée
- La création
- création
- Cross
- Clients
- données
- Lac de données
- partage de données
- stratégie de données
- Base de données
- décisions
- profond
- plongée profonde
- Réglage par défaut
- Développement
- différent
- discuter
- down
- Goutte
- chacun
- Plus tôt
- éditeur
- EMEA
- activé
- crypté
- chiffrement
- Moteur
- ingénieur
- Entrer
- Entreprise
- Ether (ETH)
- évolution
- exemple
- attendu
- Découvrez
- explorez
- externe
- Déposez votre dernière attestation
- une fonction filtre
- filtration
- filtres
- Trouvez
- Prénom
- première fois
- Flexibilité
- Abonnement
- Pour
- le format
- formation
- cadres
- France
- de
- plein
- avenir
- généré
- obtenez
- Donner
- gouvernance
- subvention
- l'orientation
- Vous avez
- ayant
- entendre
- aide
- Ruche
- HTML
- http
- HTTPS
- ID
- Mettre en oeuvre
- in
- Inc
- industrie
- d'information
- innovons
- interagir
- intéressé
- IT
- chemin
- jpg
- lac
- Transport routier
- couche
- apprentissage
- Niveau
- en tirant parti
- LIMIT
- lignes
- LINK
- emplacement
- love
- Lyon
- faire
- FAIT DU
- les gérer
- membre
- Menu
- migration
- modèle
- PLUS
- plusieurs
- prénom
- NAVIGUER
- Navigation
- Besoin
- Nouveauté
- next
- NYC
- observer
- of
- on
- ONE
- ouvert
- données ouvertes
- fonctionner
- Opérations
- Opportunités
- organisations
- Autre
- pain
- Paris
- chemin
- effectuer
- autorisations
- Platon
- Intelligence des données Platon
- PlatonDonnées
- politiques
- Post
- représentent
- Directeur
- producteur
- fournir
- fournit
- RAM
- Lire
- récemment
- reflété
- S'inscrire
- inscrit
- remplacer
- a besoin
- ressource
- restreindre
- limité
- résultat
- Rôle
- rôle
- RANGÉE
- Courir
- même
- Épargnez
- scénarios
- Section
- choisi
- supérieur
- set
- Partager
- commun
- partage
- simplifier
- Instantané
- Logiciels
- développement de logiciels
- Software Engineer
- Solutions
- Hébergement spécial
- SQL
- j'ai commencé
- Étapes
- storage
- Boutique
- stockée
- Stratégique
- de Marketing
- Chaîne
- tel
- Support
- Appareils
- combustion propre
- table
- équipe
- qui
- La
- leur
- Ces
- fiable
- voyage dans le temps
- fois
- horodatage
- à
- suivre
- Voyage
- sous
- unique
- Mises à jour
- a actualisé
- améliorer
- États-Unis
- utilisé
- Utilisateur
- UTC
- VALIDER
- Valeurs
- vérifier
- version
- définition
- visible
- Visiter
- avec
- Activités:
- vos contrats
- écrire
- années
- Votre
- zéphyrnet