Pilote automatique Amazon SageMaker est une solution d'apprentissage automatique (AutoML) qui exécute toutes les tâches dont vous avez besoin pour mener à bien un flux de travail d'apprentissage automatique (ML) de bout en bout. Il explore et prépare vos données, applique différents algorithmes pour générer un modèle et fournit de manière transparente des informations sur le modèle et des rapports d'explicabilité pour vous aider à interpréter les résultats. Le pilote automatique peut également créer un point de terminaison en temps réel pour l'inférence en ligne. Vous pouvez accéder aux fonctionnalités en un clic d'Autopilot dans Amazon SageMakerStudio ou en utilisant le AWS SDK pour Python (Boto3) ou le SDK SageMaker Python.
Dans cet article, nous montrons comment effectuer des prédictions par lots sur un ensemble de données sans étiquette à l'aide d'un modèle formé par Autopilot. Nous utilisons un ensemble de données généré de manière synthétique qui indique les types de fonctionnalités que vous voyez généralement lors de la prévision de l'attrition des clients.
Vue d'ensemble de la solution
Lot inférence, ou direct l'inférence, est le processus de génération de prédictions sur un lot d'observations. L'inférence par lots suppose que vous n'avez pas besoin d'une réponse immédiate à une demande de prédiction de modèle, comme vous le feriez lors de l'utilisation d'un point de terminaison de modèle en ligne en temps réel. Les prédictions hors ligne conviennent aux ensembles de données plus volumineux et dans les cas où vous pouvez vous permettre d'attendre plusieurs minutes ou plusieurs heures pour obtenir une réponse. En revanche, en ligne l'inférence génère des prédictions ML en temps réel, et est à juste titre appelée en temps réel inférence ou Dynamic inférence. En règle générale, ces prédictions sont générées sur une seule observation de données au moment de l'exécution.
Perdre des clients coûte cher à toute entreprise. L'identification précoce des clients mécontents vous permet de leur offrir des incitations à rester. Les opérateurs de téléphonie mobile disposent de données historiques sur les clients indiquant ceux qui ont abandonné et ceux qui ont maintenu le service. Nous pouvons utiliser ces informations historiques pour construire un modèle permettant de prédire si un client se désabonnera à l'aide de ML.
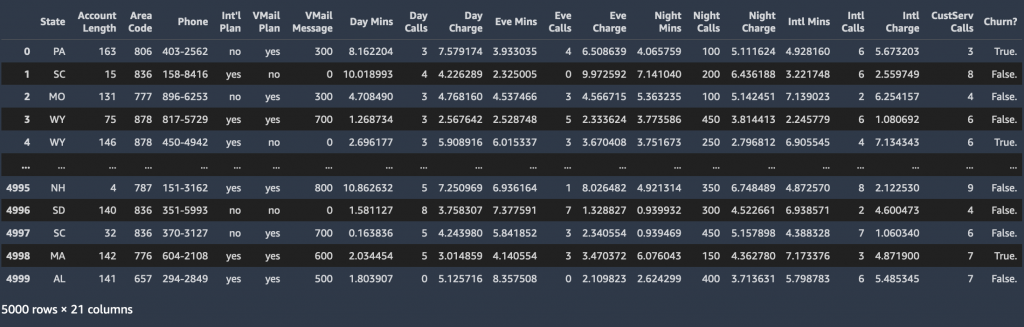
Après avoir formé un modèle ML, nous pouvons transmettre les informations de profil d'un client arbitraire (les mêmes informations de profil que nous avons utilisées pour la formation) au modèle, et faire en sorte que le modèle prédise si le client va ou non se désabonner. L'ensemble de données utilisé pour cet article est hébergé dans le dossier sagemaker-sample-files dans un Service de stockage simple Amazon (Amazon S3) compartiment public, que vous pouvez télécharger. Il se compose de 5,000 21 enregistrements, où chaque enregistrement utilise XNUMX attributs pour décrire le profil d'un client pour un opérateur mobile américain inconnu. Les attributs sont les suivants :
- Région – État américain dans lequel réside le client, indiqué par une abréviation à deux lettres ; par exemple, TX ou CA
- Durée du compte – Nombre de jours pendant lesquels ce compte a été actif
- Indicatif régional – Indicatif régional à trois chiffres du numéro de téléphone du client correspondant
- Téléphone – Numéro de téléphone à sept chiffres restant
- Plan international – Dispose d'un forfait d'appel international : Oui/Non
- Forfait VMail – Possède une fonction de messagerie vocale : Oui/Non
- Message VMail – Nombre moyen de messages vocaux par mois
- Minutes du jour – Nombre total de minutes d'appel utilisées dans la journée
- Appels de jour – Nombre total d'appels passés pendant la journée
- Frais de jour – Coût facturé des appels de jour
- Eve Mins, Eve Calls, Eve Charge – Coût facturé pour les appels passés pendant la soirée
- Minutes de nuit, Appels de nuit, Frais de nuit – Coût facturé pour les appels passés pendant la nuit
- Minutes internationales, appels internationaux, frais internationaux – Coût facturé pour les appels internationaux
- Appels CustServ – Nombre d'appels passés au service client
- Baratte? – Le client a quitté le service : Vrai/Faux
Le dernier attribut, Churn ?, est l'attribut cible que nous voulons que le modèle ML prédise. Étant donné que l'attribut cible est binaire, notre modèle effectue une prédiction binaire, également appelée classement binaire.
Pré-requis
Téléchargez le jeu de données dans votre environnement de développement local et explorez-le en exécutant la commande de copie S3 suivante avec la Interface de ligne de commande AWS (AWS CLI) :
Vous pouvez ensuite copier l'ensemble de données dans un compartiment S3 au sein de votre propre compte AWS. Il s'agit de l'emplacement d'entrée pour le pilote automatique. Vous pouvez copier l'ensemble de données sur Amazon S3 en le chargeant manuellement dans votre compartiment ou en exécutant la commande suivante à l'aide de l'AWS CLI :
Créer une expérience de pilote automatique
Lorsque l'ensemble de données est prêt, vous pouvez initialiser une expérience Autopilot dans SageMaker Studio. Pour des instructions complètes, reportez-vous à Créer une expérience Amazon SageMaker Autopilot.
Sous Paramètres de base, vous pouvez facilement créer une expérience Autopilot en fournissant un nom d'expérience, les emplacements d'entrée et de sortie des données et en spécifiant les données cibles à prédire. Si vous le souhaitez, vous pouvez spécifier le type de problème de ML que vous souhaitez résoudre. Sinon, utilisez le Automatique et Autopilot détermine automatiquement le modèle en fonction des données que vous fournissez.

Vous pouvez également exécuter une expérience Autopilot avec du code à l'aide du kit SDK AWS pour Python (Boto3) ou du kit SDK Python SageMaker. L'extrait de code suivant montre comment initialiser une expérience Autopilot à l'aide du SDK Python SageMaker. Nous utilisons le Classe AutoML du SDK SageMaker Python.
Une fois qu'Autopilot a commencé une expérience, le service inspecte automatiquement les données d'entrée brutes, applique des processeurs de fonctionnalités et sélectionne le meilleur ensemble d'algorithmes. Après avoir choisi un algorithme, Autopilot optimise ses performances à l'aide d'un processus de recherche d'optimisation d'hyperparamètres. Ceci est souvent appelé formation et réglage du modèle. Cela aide finalement à produire un modèle capable de faire des prédictions précises sur des données qu'il n'a jamais vues. Le pilote automatique suit automatiquement les performances du modèle, puis classe les modèles finaux en fonction de métriques décrivant l'exactitude et la précision d'un modèle.

Vous avez également la possibilité de déployer l'un des modèles classés soit en choisissant le modèle (clic droit) et en choisissant Déployer le modèle, ou en sélectionnant le modèle dans la liste classée et en choisissant Déployer le modèle.
Faire des prédictions par lots à l'aide d'un modèle d'Autopilot
Lorsque votre expérience Autopilot est terminée, vous pouvez utiliser le modèle formé pour exécuter des prédictions par lots sur votre ensemble de données de test ou d'exclusion à des fins d'évaluation. Vous pouvez ensuite comparer les étiquettes prédites aux étiquettes attendues si votre ensemble de données de test ou d'exclusion est pré-étiqueté. Il s'agit essentiellement d'un moyen de comparer les prédictions d'un modèle à la vérité. Si davantage de prédictions du modèle correspondent aux véritables étiquettes, nous pouvons généralement catégoriser le modèle comme performant. Vous pouvez également exécuter des prédictions par lots pour étiqueter les données sans étiquette. Vous pouvez facilement accomplir la même chose en utilisant le SDK Python SageMaker de haut niveau avec quelques lignes de code.
Décrire un test AutoPilot précédemment exécuté
Nous devons d'abord extraire les informations d'une expérience de pilote automatique précédemment terminée. Nous pouvons utiliser la classe AutoML du SDK Python SageMaker pour créer un objet automl qui encapsule les informations d'une précédente expérience Autopilot. Vous pouvez utiliser le nom de l'expérience que vous avez défini lors de l'initialisation de l'expérience AutoPilot. Voir le code suivant :
Avec l'objet automl, nous pouvons facilement décrire et recréer le meilleur modèle entraîné, comme illustré dans les extraits suivants :
Dans certains cas, vous souhaiterez peut-être utiliser un modèle autre que le meilleur modèle classé par Autopilot. Pour trouver un tel modèle candidat, vous pouvez utiliser l'objet automl et parcourir la liste de tous ou des N meilleurs modèles candidats et choisir le modèle que vous souhaitez recréer. Pour cet article, nous utilisons une simple boucle Python For pour parcourir une liste de modèles candidats :
Personnaliser la réponse d'inférence
Lors de la recréation du meilleur ou de tout autre modèle entraîné d'Autopilot, nous pouvons personnaliser la réponse d'inférence pour le modèle en ajoutant le paramètre supplémentaire inference_response_keys, comme illustré dans l'exemple précédent. Vous pouvez utiliser ce paramètre pour les types de problème de classification binaire ou multiclasse :
- étiquette_prédite – La classe prédite.
- probabilité – Dans la classification binaire, la probabilité que le résultat soit prédit comme la deuxième classe ou la vraie classe dans la colonne cible. Dans la classification multiclasse, la probabilité de la classe gagnante.
- qui – Une liste de toutes les classes possibles.
- probabilités – Une liste de toutes les probabilités pour toutes les classes (l'ordre correspond aux étiquettes).
Étant donné que le problème que nous abordons dans cet article est la classification binaire, nous définissons ce paramètre comme suit dans les extraits précédents lors de la création des modèles :
Créer un transformateur et exécuter des prédictions par lots
Enfin, après avoir recréé les modèles candidats, nous pouvons créer un transformateur pour démarrer le travail de prédictions par lots, comme indiqué dans les deux extraits de code suivants. Lors de la création du transformateur, nous définissons les spécifications du cluster pour exécuter le travail par lots, telles que le nombre et le type d'instance. L'entrée et la sortie par lots sont les emplacements Amazon S3 où nos entrées et sorties de données sont stockées. La tâche de prédiction par lots est optimisée par Transformation par lots SageMaker.
Lorsque le travail est terminé, nous pouvons lire la sortie du lot et effectuer des évaluations et d'autres actions en aval.
Résumé
Dans cet article, nous avons montré comment effectuer rapidement et facilement des prédictions par lots à l'aide de modèles formés par Autopilot pour vos évaluations post-formation. Nous avons utilisé SageMaker Studio pour initialiser une expérience de pilote automatique afin de créer un modèle de prédiction de l'attrition des clients. Ensuite, nous avons référencé le meilleur modèle d'Autopilot pour exécuter des prédictions par lots à l'aide de la classe automl avec le SDK Python SageMaker. Nous avons également utilisé le SDK pour effectuer des prédictions par lots avec d'autres modèles candidats. Avec Autopilot, nous avons automatiquement exploré et prétraité nos données, puis créé plusieurs modèles ML en un seul clic, laissant SageMaker s'occuper de gérer l'infrastructure nécessaire pour former et ajuster nos modèles. Enfin, nous avons utilisé la transformation par lots pour faire des prédictions avec notre modèle en utilisant un code minimal.
Pour plus d'informations sur le pilote automatique et ses fonctionnalités avancées, reportez-vous à Automatisez le développement de modèles avec Amazon SageMaker Autopilot. Pour une présentation détaillée de l'exemple dans le post, jetez un oeil à ce qui suit exemple de cahier.
À propos des auteurs
 Arunprasath Shankar est un architecte de solutions spécialisé en intelligence artificielle et apprentissage automatique (AI / ML) avec AWS, qui aide les clients du monde entier à faire évoluer leurs solutions d'IA de manière efficace et efficiente dans le cloud. Dans ses temps libres, Arun aime regarder des films de science-fiction et écouter de la musique classique.
Arunprasath Shankar est un architecte de solutions spécialisé en intelligence artificielle et apprentissage automatique (AI / ML) avec AWS, qui aide les clients du monde entier à faire évoluer leurs solutions d'IA de manière efficace et efficiente dans le cloud. Dans ses temps libres, Arun aime regarder des films de science-fiction et écouter de la musique classique.
 Pierre Chung est un architecte de solutions pour AWS et se passionne pour aider les clients à découvrir des informations à partir de leurs données. Il a développé des solutions pour aider les organisations à prendre des décisions basées sur les données dans les secteurs public et privé. Il détient toutes les certifications AWS ainsi que deux certifications GCP. Il aime le café, cuisiner, rester actif et passer du temps avec sa famille.
Pierre Chung est un architecte de solutions pour AWS et se passionne pour aider les clients à découvrir des informations à partir de leurs données. Il a développé des solutions pour aider les organisations à prendre des décisions basées sur les données dans les secteurs public et privé. Il détient toutes les certifications AWS ainsi que deux certifications GCP. Il aime le café, cuisiner, rester actif et passer du temps avec sa famille.
- "
- 000
- 100
- Qui sommes-nous
- accès
- Compte
- actes
- infection
- Avancée
- AI
- algorithme
- algorithmes
- Tous
- Amazon
- Réservé
- artificiel
- intelligence artificielle
- L'INTELLIGENCE ARTIFICIELLE ET LE MACHINE LEARNING
- Automatisation
- moyen
- AWS
- LES MEILLEURS
- frontière
- Développement
- la performance des entreprises
- les soins
- cas
- classification
- le cloud
- code
- Café
- Colonne
- La création
- Clients
- données
- déployer
- Développement
- différent
- "Early Bird"
- même
- Endpoint
- Environment
- exemple
- exécution
- attendu
- expérience
- famille
- Fonctionnalité
- Fonctionnalités:
- Prénom
- Abonnement
- plein
- générer
- Global
- aider
- aide
- historique
- détient
- Comment
- How To
- HTTPS
- Immédiat
- d'information
- Infrastructure
- idées.
- Intelligence
- International
- IT
- Emploi
- Emplois
- connu
- Etiquettes
- plus importantes
- apprentissage
- Gamme
- Liste
- Écoute
- locales
- emplacement
- emplacements
- click
- machine learning
- les gérer
- manuellement
- Match
- Métrique
- ML
- Breeze Mobile
- modèle
- numériques jumeaux (digital twin models)
- Films
- Musique
- nombre
- code
- en ligne
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Option
- de commander
- organisations
- Autre
- autrement
- performant
- possible
- prédiction
- Prédictions
- Privé
- Problème
- processus
- produire
- Profil
- fournir
- fournit
- public
- vite.
- raw
- en temps réel
- record
- Articles
- Rapports
- réponse
- Résultats
- Courir
- pour le running
- Escaliers intérieurs
- Sdk
- Rechercher
- Secteurs
- service
- set
- mise
- étapes
- Solutions
- RÉSOUDRE
- Dépenses
- Commencer
- Région
- rester
- storage
- studio
- Target
- tâches
- tester
- Avec
- fiable
- top
- Formation
- Transformer
- TX
- devoiler
- us
- utilisé
- Voix
- attendez
- que
- WHO
- dans les