Avez-vous déjà attendu ce colis coûteux qui indique « expédié », mais vous ne savez pas où il se trouve ? L'historique de suivi a cessé de se mettre à jour il y a cinq jours et vous avez presque perdu espoir. Mais attendez, 11 jours plus tard, vous l'avez à votre porte. Vous souhaitiez que la traçabilité soit meilleure pour vous soulager de toute attente anxieuse. C'est là que l'« observabilité » entre en jeu.
Dans un paysage technique, vous voudriez éviter que cela n'arrive à vos logiciels ou à vos systèmes de données. Et ainsi, vous adoptez des outils de surveillance, qui collectent les logs et les métriques de vos systèmes et vous informent de leur état interne. La surveillance fonctionne mieux lorsque vous souhaitez que vos systèmes vous informent de la nature de l'erreur, de l'endroit et du moment où elle s'est produite, mais elle ne vous indique pas comment résoudre l'erreur.
Il y a plus de dix ans, les outils de surveillance manquaient de contexte et de prévision des problèmes système sous-jacents et les équipes se limitaient à déboguer les erreurs opérationnelles quotidiennes. Aujourd'hui, nous travaillons et vivons dans un monde distribué de microservices et pipelines de données; même l'utilisation de plusieurs outils de surveillance ne vous aidera pas à répondre à vos questions professionnelles telles que « Pourquoi mon application est-elle toujours lente ? » ou "A quel stade le problème s'est-il produit et quelle est sa profondeur dans la pile ?" ou "Comment puis-je améliorer les performances globales de l'environnement ?" Il devient nécessaire d'être proactif dans la prise de ces décisions et d'avoir une visibilité globale sur vos systèmes, applications et données.
Ce blog récents par Etsy a été publié il y a dix ans, et il énonce le fait même dans le deuxième paragraphe :
"Les métriques d'application sont généralement les plus difficiles, mais les plus importantes, des trois. Ils sont très spécifiques à votre entreprise, et ils changent à mesure que vos applications changent (et Etsy change beaucoup).
Alors, comment mesure-t-on tout et n'importe quoi ? On commence par l'observabilité.
Qu'est-ce que l'observabilité ?
Le terme « observabilité » était inventé par Rudolf Emil Kálmán en 1960 dans son article d'ingénierie pour décrire les systèmes de contrôle mathématique. Il l'a défini comme une mesure de la façon dont les états internes d'un système peuvent être déduits de la connaissance de ses sorties externes. Mais cela ne ressemble-t-il pas à de la surveillance ? Fondamentalement, oui, c'est de la surveillance.
De nos jours, l'observabilité est devenue un sujet brûlant. Selon plusieurs études de marché, il s'agit d'une plateforme d'un milliard de dollars. De nombreuses organisations ont adopté le concept et l'ont utilisé comme cadre pour une visibilité de bout en bout de leurs systèmes et pipelines distribués. Cependant, l'observabilité est confondue avec la surveillance. Pour l'instant, je peux dire que la surveillance est un sous-ensemble de l'observabilité, où l'observabilité est un terme générique.
L'observabilité permet un traçage distribué via la collecte et l'agrégation de traces, de journaux et de métriques. Voyons ce que ceux-ci en déduisent :
- Traces: Lorsqu'un système reçoit une demande, les traces vous indiquent comment cette demande circule, tout au long de son cycle de vie, de la source à la destination. Les traces sont représentées par des « étendues ». Une trace est une arborescence d'étendues, et une étendue est une opération unique dans une trace. Ils vous aident à localiser les erreurs, la latence ou les goulots d'étranglement dans le système.
- Journaux Il s'agit d'événements horodatés générés par la machine qui vous informent des opérations ou des modifications qui se sont produites dans le système. Les journaux sont souvent utilisés pour interroger ces erreurs ou changements dans le système.
- Métrique: Ceux-ci fournissent des informations quantitatives sur le processeur, la mémoire, l'utilisation du disque et les performances du système sur une période donnée.
Ces attributs améliorent le cadre de surveillance avec traçabilité. La traçabilité vous fournit les lentilles pour tracer une requête qui appelle votre système, combien de temps il faut pour passer d'un composant à un autre, quels autres services il appelle, génère-t-il une erreur, quels journaux il produit, quel état il se trouve-t-il, quand a-t-il commencé et s'est-il terminé, quel est le délai dans lequel il est resté dans votre système, etc. Lorsque vous collectez, agrégez et analysez ces traces, vous êtes en mesure de prendre de précieuses décisions éclairées, telles que la chronologie des clients sur un site Web de commerce électronique. , combien de temps il leur a fallu pour rechercher un produit, combien de temps ils ont visualisé le produit, la page HTML a-t-elle chargé tous les détails comme des images ou des vidéos intégrées, combien de temps le système a mis pour s'authentifier et traiter le paiement, etc.
Que réalisons-nous avec l'observabilité dans un environnement distribué ?
L'évolution des systèmes distribués a commencé lorsque les organisations ont commencé à s'éloigner de leur architecture monolithique centralisée vers une architecture de microservice distribuée et décentralisée. Et c'est toujours un travail en cours où de nombreuses organisations adoptent la nature des microservices des systèmes et des applications. Et tout cela peut être attribué à le Big Data et mise à l'échelle. La gestion d'un environnement distribué nécessite un apprentissage continu, une main-d'œuvre supplémentaire, des changements dans les cadres et les politiques, la gestion informatique, etc. C'est effectivement un grand changement.
Auparavant, dans l'environnement monolithique limité, le matériel, les logiciels, les données et les bases de données vivaient tous sous un même toit. Avec l'avènement du Big Data dans les années 2000, les systèmes de surveillance et de mise à l'échelle ont commencé à devenir une préoccupation majeure. Souvent, les organisations utilisaient différents outils de surveillance pour répondre aux besoins de leurs diverses applications. En conséquence, il est rapidement devenu un surcoût opérationnel avec une résilience, une visibilité et une fiabilité médiocres.
Toutes ces questions ont donné lieu à l'adoption de l'observabilité. Aujourd'hui, plusieurs outils d'observabilité existent pour la sécurité, le réseau, les applications et les pipelines de données pour le traçage distribué dans un environnement complexe. Ils coexistent avec leur cousin, les outils de surveillance, et tirent parti de la collecte des informations de leur cousin et s'agrègent avec des informations supplémentaires à partir de ses propres données de trace.
Il y a beaucoup de composants mobiles dans tous ces systèmes, dont les traces, une fois capturées, peuvent illustrer l'histoire des 5 W : quand, où, pourquoi, quoi et comment. Par exemple, vous allez sur le site de DATAVERSITY à 1h43 pour lire des articles de blog. Lorsque vous cliquez sur dataversity.net, la requête HTTP est enregistrée dans le système. Vous commencez à rechercher un article de blog et accédez à un article sur la gouvernance des données, où vous passez 17 minutes à lire cet article, puis vous fermez votre onglet à 2h00.
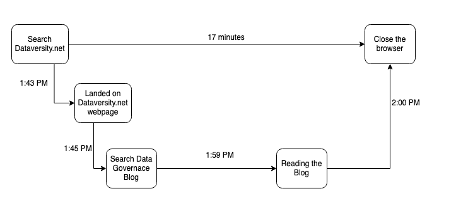
Il y aura également d'autres appels vers le système de réseau pour la capture de paquets réseau. Les outils d'observabilité collectent toutes les étendues et les unifient dans une trace ou des traces, vous permettant de voir le chemin qu'il a formé au cours de son cycle de vie. Si vous avez un problème comme la latence du réseau ou un défaut du système, il est maintenant plus facile de disséquer (peler l'oignon) et de déboguer le problème (erreur dans quelle couche).
Désormais, dans un vaste environnement distribué, lorsque vos applications reçoivent des millions de requêtes, les données de trace augmentent en volume. La collecte et l'analyse de ces traces sont coûteuses en termes de consommation de stockage et de transfert de données. Ainsi, pour réduire les coûts, les données de trace sont échantillonnées, car dans la plupart des cas, les équipes d'ingénierie n'ont besoin que de certaines pièces pour déterminer ce qui n'a pas fonctionné ou quel est le modèle d'erreur.
Avec ce petit exemple, nous comprenons que nous obtenons des informations beaucoup plus approfondies sur nos systèmes. Ainsi, en considérant une plus grande échelle de systèmes, les équipes d'ingénierie peuvent capturer et travailler sur les données échantillonnées pour améliorer la structure actuelle du système, appliquer ou retirer de nouveaux composants, ajouter une autre couche de sécurité, supprimer les goulots d'étranglement, etc.
Les organisations doivent-elles choisir l'observabilité ?
Nous devons tous comprendre que les objectifs finaux sont une meilleure expérience utilisateur et une plus grande satisfaction des utilisateurs. Et le chemin vers la réalisation de ces objectifs peut être facilité grâce à un cadre d'observabilité automatisé et proactif. L'établissement d'une culture d'amélioration continue et d'optimisation est considéré comme l'approche commerciale et de leadership optimale.
À l'ère de la transformation numérique, l'observabilité est devenue un incontournable pour qu'une entreprise réussisse son parcours numérique. En vous fournissant des traces perspicaces, l'observabilité vous permet également d'être informé par les données plutôt que simplement piloté par les données.
Conclusion
Bien que nous ayons utilisé les termes surveillance et observabilité de manière interchangeable, nous avons vu que si la surveillance vous aide à obtenir des informations sur la santé du système et les événements qui s'y produisent, l'observabilité vous permet de faire des inférences basées sur des preuves recueillies à partir de couches plus profondes d'une fin- environnement de bout en bout.
L'observabilité est et peut également être perçue comme une composante du cadre de gouvernance des données. Dans cette génération, où le volume de données sans cesse croissant réside sur un réseau de matériel de base, il est essentiel de garder les architectures aussi simples que possible. Et évidemment, il devient impossible de gérer l'environnement sur toute la ligne. Ainsi, la mise en œuvre de politiques et de règles de gouvernance appropriées et automatisées pour garder votre vaste maillage de systèmes, de pipelines et de données désencombré appelle à l'action le plus tôt possible.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- Capable
- À propos
- Selon
- atteindre
- la réalisation de
- Action
- Supplémentaire
- renseignements supplémentaires
- adopter
- adopté
- Adoption
- avènement
- Tous
- permet
- toujours
- il analyse
- l'analyse
- ainsi que
- Une autre
- répondre
- Candidature
- applications
- Appliquer
- une approche
- approprié
- architecture
- attributs
- authentifier
- Automatisation
- éviter
- basé
- En gros
- car
- devenez
- devient
- a commencé
- LES MEILLEURS
- Améliorée
- Big
- Big Data
- Blog
- Blogue
- goulets d'étranglement
- la performance des entreprises
- Appelez-nous
- Appels
- capturer
- cas
- centralisée
- Change
- Modifications
- Selectionnez
- Fermer
- recueillir
- Collecte
- marchandise
- complet
- complexe
- composant
- composants électriques
- concept
- PROBLÈMES DE PEAU
- confus
- considéré
- considérant
- consommation
- contexte
- continu
- des bactéries
- Costs
- pourriez
- Processeur
- Culture
- Courant
- des clients
- données
- data-driven
- bases de données
- DATAVERSITÉ
- jour après jour
- jours
- décennie
- Décentralisé
- décisions
- profond
- profond
- défini
- décrire
- destination
- détails
- DID
- différent
- numérique
- Transformation numérique
- distribué
- systèmes distribués
- Ne fait pas
- down
- pendant
- e-commerce
- plus facilement
- intégré
- embrassement
- permettant
- end-to-end
- ENGINEERING
- Environment
- erreur
- Erreurs
- établissement
- etc
- Pourtant, la
- événements
- JAMAIS
- de plus en plus
- peut
- preuve
- évolution
- exemple
- cher
- Découvrez
- externe
- facilite
- Flux
- formé
- Framework
- cadres
- de
- génération
- obtenez
- Go
- Objectifs
- gouvernance
- plus grand
- Pousse
- arrivé
- EN COURS
- Matériel
- Santé
- aider
- aide
- Histoire
- Frappé
- d'espérance
- HOT
- Comment
- How To
- Cependant
- HTML
- HTTPS
- majeur
- satellite
- la mise en œuvre
- important
- impossible
- améliorer
- amélioration
- in
- d'information
- Actualités
- idées.
- interne
- enquêter
- invoque
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- Gestion du parc informatique
- chemin
- XNUMX éléments à
- spécialisées
- paysage d'été
- gros
- plus importantes
- Latence
- couche
- poules pondeuses
- Leadership
- apprentissage
- lentilles
- Levier
- vos produits
- limité
- Gamme
- le travail
- charge
- Location
- Lot
- LES PLANTES
- faire
- FAIT DU
- Fabrication
- gérer
- gestion
- les gérer
- de nombreuses
- Marché
- mathématique
- largeur maximale
- mesurer
- Mémoire
- Métrique
- microservices
- des millions
- minutes
- Stack monitoring
- Monolithique
- (en fait, presque toutes)
- Bougez
- en mouvement
- plusieurs
- Doit avoir
- Nature
- nécessaire
- Besoin
- Besoins
- net
- réseau et
- système de réseau
- Nouveauté
- ONE
- opération
- opérationnel
- Opérations
- optimaux
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- organisations
- Autre
- global
- propre
- Papier
- chemin
- Patron de Couture
- Paiement
- perçu
- performant
- effectuer
- période
- pièces
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- politiques
- pauvres
- possible
- Post
- Poteaux
- Cybersécurité
- Problème
- processus
- Produit
- Progrès
- fournir
- fournit
- aportando
- publié
- quantitatif
- fréquemment posées
- plutôt
- Lire
- en cours
- recevoir
- reçoit
- fiabilité
- supprimez
- représenté
- nécessaire
- demandes
- a besoin
- la résilience
- limité
- résultat
- Augmenter
- toit
- client
- Épargnez
- Escaliers intérieurs
- mise à l'échelle
- Rechercher
- recherche
- Deuxièmement
- sécurité
- Services
- plusieurs
- devrait
- Spectacles
- étapes
- unique
- lent
- petit
- So
- Logiciels
- RÉSOUDRE
- quelques
- disponible
- Son
- Identifier
- travées
- groupe de neurones
- passer
- empiler
- Étape
- Commencer
- j'ai commencé
- Région
- États
- séjourné
- Encore
- arrêté
- storage
- Histoire
- structure
- réussi
- combustion propre
- Système
- Prenez
- prend
- Tâche
- équipes
- Technique
- conditions
- La
- les informations
- La Source
- leur
- ainsi
- trois
- Avec
- tout au long de
- fiable
- calendrier
- à
- aujourd'hui
- les outils
- sujet
- tracer
- Traçabilité
- Traçant
- Tracking
- transférer
- De La Carrosserie
- parapluie
- sous
- sous-jacent
- comprendre
- la mise à jour
- Utilisation
- Utilisateur
- Expérience utilisateur
- d'habitude
- Précieux
- divers
- Vidéos
- définition
- vital
- le volume
- attendez
- Attendre
- Site Web
- Quoi
- Qu’est ce qu'
- qui
- tout en
- sera
- dans les
- Activités:
- Workforce
- vos contrats
- world
- pourra
- faux
- Votre
- zéphyrnet











