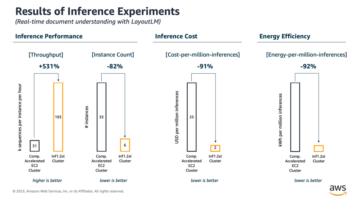
Cette série en trois parties montre comment utiliser les réseaux de neurones graphiques (GNN) et Amazone Neptune pour générer des recommandations de films à l'aide de IMDb et Box Office Mojo Films/TV/OTT un ensemble de données sous licence, qui fournit un large éventail de métadonnées de divertissement, y compris plus d'un milliard d'évaluations d'utilisateurs ; des crédits pour plus de 1 millions de membres de la distribution et de l'équipe ; 11 millions de titres de films, de télévision et de divertissement ; et des données de rapports sur le box-office mondial de plus de 9 pays. De nombreux clients de médias et de divertissement d'AWS autorisent les données IMDb via Échange de données AWS pour améliorer la découverte de contenu et accroître l'engagement et la fidélisation des clients.
In Partie 1, nous avons discuté des applications des GNN et de la façon de transformer et de préparer nos données IMDb pour l'interrogation. Dans cet article, nous discutons du processus d'utilisation de Neptune pour générer des représentations vectorielles continues utilisées pour effectuer notre recherche hors catalogue dans la partie 3 . Nous passons également Amazon Neptune ML, la fonctionnalité d'apprentissage automatique (ML) de Neptune et le code que nous utilisons dans notre processus de développement. Dans la partie 3 , nous expliquons comment appliquer nos représentations incorporées de graphes de connaissances à un cas d'utilisation de recherche hors catalogue.
Vue d'ensemble de la solution
Les grands ensembles de données connectés contiennent souvent des informations précieuses qui peuvent être difficiles à extraire à l'aide de requêtes basées uniquement sur l'intuition humaine. Les techniques de ML peuvent aider à trouver des corrélations cachées dans des graphiques avec des milliards de relations. Ces corrélations peuvent être utiles pour recommander des produits, prédire la solvabilité, identifier la fraude et de nombreux autres cas d'utilisation.
Neptune ML permet de créer et d'entraîner des modèles ML utiles sur de grands graphiques en quelques heures au lieu de plusieurs semaines. Pour ce faire, Neptune ML utilise la technologie GNN optimisée par Amazon Sage Maker et par Bibliothèque de graphes profonds (DGL) (lequel est open-source). Les GNN sont un domaine émergent de l'intelligence artificielle (pour un exemple, voir Une enquête complète sur les réseaux de neurones graphiques). Pour un tutoriel pratique sur l'utilisation des GNN avec le DGL, voir Apprentissage des réseaux de neurones de graphes avec Deep Graph Library.
Dans cet article, nous montrons comment utiliser Neptune dans notre pipeline pour générer des intégrations.
Le schéma suivant illustre le flux global des données IMDb, du téléchargement à la génération de l'intégration.
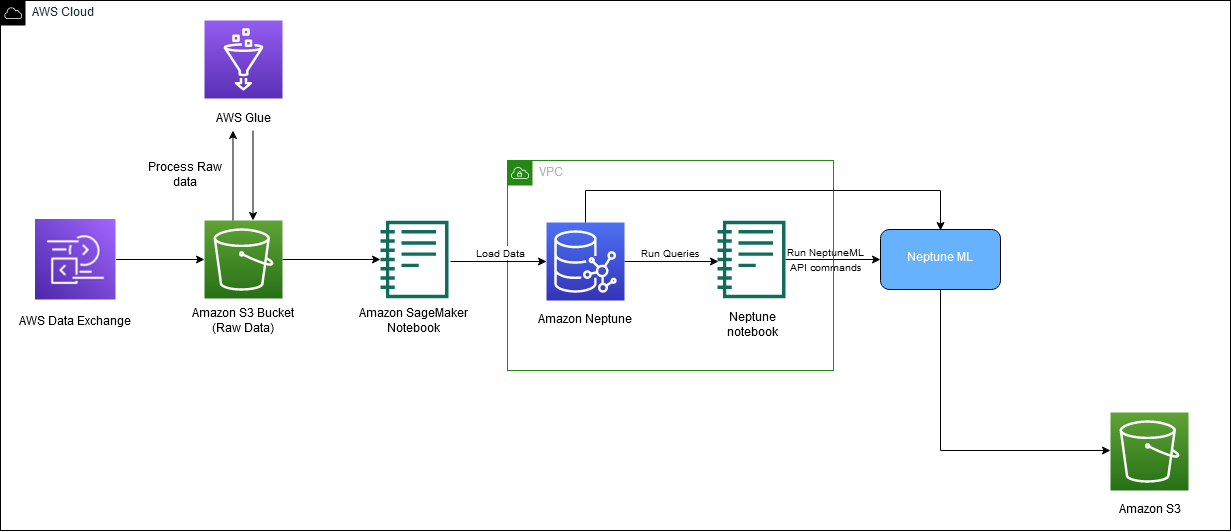
Nous utilisons les services AWS suivants pour mettre en œuvre la solution :
Dans cet article, nous vous expliquons les étapes de haut niveau suivantes :
- Configurer les variables d'environnement
- Créez une tâche d'exportation.
- Créez une tâche de traitement de données.
- Soumettre une tâche de formation.
- Télécharger les intégrations.
Code pour les commandes Neptune ML
Nous utilisons les commandes suivantes dans le cadre de la mise en œuvre de cette solution :
Nous utilisons neptune_ml export pour vérifier l'état ou démarrer un processus d'exportation Neptune ML, et neptune_ml training pour démarrer et vérifier l'état d'une tâche d'entraînement de modèle Neptune ML.
Pour plus d'informations sur ces commandes et d'autres, reportez-vous à Utiliser les magies de l'établi Neptune dans vos cahiers.
Pré-requis
Pour suivre cet article, vous devriez avoir les éléments suivants :
- An Compte AWS
- Familiarité avec SageMaker, Amazon S3 et AWS CloudFormation
- Données de graphe chargées dans le cluster Neptune (voir Partie 1 pour plus d'informations)
Configurer les variables d'environnement
Avant de commencer, vous devez configurer votre environnement en définissant les variables suivantes : s3_bucket_uri ainsi que processed_folder. s3_bucket_uri est le nom du seau utilisé dans la partie 1 et processed_folder est l'emplacement Amazon S3 pour la sortie de la tâche d'exportation.
Créer une tâche d'exportation
Dans la partie 1, nous avons créé un bloc-notes SageMaker et un service d'exportation pour exporter nos données du cluster Neptune DB vers Amazon S3 dans le format requis.
Maintenant que nos données sont chargées et que le service d'exportation est créé, nous devons créer une tâche d'exportation pour la démarrer. Pour ce faire, nous utilisons NeptuneExportApiUri et créer des paramètres pour la tâche d'exportation. Dans le code suivant, nous utilisons les variables expo ainsi que export_params. Ensemble expo à ta NeptuneExportApiUri valeur, que vous pouvez trouver sur le Sortie onglet de votre pile CloudFormation. Pour export_params, nous utilisons le point de terminaison de votre cluster Neptune et fournissons la valeur pour outputS3path, qui est l'emplacement Amazon S3 pour la sortie de la tâche d'exportation.
Pour envoyer la tâche d'exportation, utilisez la commande suivante :
Pour vérifier l'état de la tâche d'exportation, utilisez la commande suivante :
Une fois votre travail terminé, définissez le processed_folder variable pour fournir l'emplacement Amazon S3 des résultats traités :
Créer une tâche de traitement de données
Maintenant que l'exportation est terminée, nous créons une tâche de traitement de données pour préparer les données pour le processus de formation Neptune ML. Cela peut être fait de différentes manières. Pour cette étape, vous pouvez modifier le job_name ainsi que modelType variables, mais tous les autres paramètres doivent rester les mêmes. La partie principale de ce code est la modelType paramètre, qui peut être soit des modèles de graphes hétérogènes (heterogeneous) ou des graphes de connaissances (kge).
La tâche d'exportation comprend également training-data-configuration.json. Utilisez ce fichier pour ajouter ou supprimer des nœuds ou des arêtes que vous ne souhaitez pas fournir pour la formation (par exemple, si vous souhaitez prédire le lien entre deux nœuds, vous pouvez supprimer ce lien dans ce fichier de configuration). Pour cet article de blog, nous utilisons le fichier de configuration d'origine. Pour plus d'informations, voir Modification d'un fichier de configuration d'entraînement.
Créez votre tâche de traitement de données avec le code suivant :
Pour vérifier l'état de la tâche d'exportation, utilisez la commande suivante :
Soumettre une tâche de formation
Une fois le travail de traitement terminé, nous pouvons commencer notre travail de formation, où nous créons nos représentations vectorielles continues. Nous recommandons un type d'instance ml.m5.24xlarge, mais vous pouvez le modifier en fonction de vos besoins informatiques. Voir le code suivant :
Nous imprimons la variable training_results pour obtenir l'ID de la tâche d'entraînement. Utilisez la commande suivante pour vérifier l'état de votre tâche :
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Télécharger les intégrations
Une fois votre tâche d'entraînement terminée, la dernière étape consiste à télécharger vos représentations vectorielles brutes. Les étapes suivantes vous montrent comment télécharger les intégrations créées à l'aide de KGE (vous pouvez utiliser le même processus pour RGCN).
Dans le code suivant, nous utilisons neptune_ml.get_mapping() ainsi que get_embeddings() pour télécharger le fichier de mappage (mapping.info) et le fichier d'incorporations brutes (entity.npy). Ensuite, nous devons mapper les incorporations appropriées à leurs ID correspondants.
Pour télécharger les RGCN, suivez le même processus avec un nouveau nom de tâche d'entraînement en traitant les données avec le paramètre modelType défini sur heterogeneous, puis entraînez votre modèle avec le paramètre modelName défini sur rgcn sur le lien ici pour plus de détails. Une fois cela terminé, appelez le get_mapping ainsi que get_embeddings fonctions pour télécharger votre nouveau mappage.info ainsi que entité.npy des dossiers. Une fois que vous avez les fichiers d'entité et de mappage, le processus de création du fichier CSV est identique.
Enfin, chargez vos intégrations à l'emplacement Amazon S3 de votre choix :
Assurez-vous de vous souvenir de cet emplacement S3, vous devrez l'utiliser dans la partie 3.
Nettoyer
Lorsque vous avez terminé d'utiliser la solution, assurez-vous de nettoyer toutes les ressources pour éviter les frais permanents.
Conclusion
Dans cet article, nous avons expliqué comment utiliser Neptune ML pour former les intégrations GNN à partir des données IMDb.
Certaines applications connexes des incorporations de graphes de connaissances sont des concepts tels que la recherche hors catalogue, les recommandations de contenu, la publicité ciblée, la prédiction des liens manquants, la recherche générale et l'analyse de cohorte. La recherche hors catalogue est le processus de recherche de contenu qui ne vous appartient pas et de recherche ou de recommandation de contenu dans votre catalogue qui est aussi proche que possible de ce que l'utilisateur a recherché. Nous approfondissons la recherche hors catalogue dans la partie 3.
À propos des auteurs
 Matthieu Rhodes est un Data Scientist qui travaille au Amazon ML Solutions Lab. Il se spécialise dans la construction de pipelines d'apprentissage automatique qui impliquent des concepts tels que le traitement du langage naturel et la vision par ordinateur.
Matthieu Rhodes est un Data Scientist qui travaille au Amazon ML Solutions Lab. Il se spécialise dans la construction de pipelines d'apprentissage automatique qui impliquent des concepts tels que le traitement du langage naturel et la vision par ordinateur.
 Divya Bhargavi est Data Scientist et Media and Entertainment Vertical Lead au Amazon ML Solutions Lab, où elle résout des problèmes commerciaux de grande valeur pour les clients AWS à l'aide de Machine Learning. Elle travaille sur la compréhension des images/vidéos, les systèmes de recommandation de graphes de connaissances, les cas d'utilisation de la publicité prédictive.
Divya Bhargavi est Data Scientist et Media and Entertainment Vertical Lead au Amazon ML Solutions Lab, où elle résout des problèmes commerciaux de grande valeur pour les clients AWS à l'aide de Machine Learning. Elle travaille sur la compréhension des images/vidéos, les systèmes de recommandation de graphes de connaissances, les cas d'utilisation de la publicité prédictive.
 Gaurav Relé est un Data Scientist au Amazon ML Solution Lab, où il travaille avec les clients AWS dans différents secteurs verticaux pour accélérer leur utilisation de l'apprentissage automatique et des services AWS Cloud pour résoudre leurs défis commerciaux.
Gaurav Relé est un Data Scientist au Amazon ML Solution Lab, où il travaille avec les clients AWS dans différents secteurs verticaux pour accélérer leur utilisation de l'apprentissage automatique et des services AWS Cloud pour résoudre leurs défis commerciaux.
 Karan Sindwani est Data Scientist chez Amazon ML Solutions Lab, où il construit et déploie des modèles d'apprentissage en profondeur. Il est spécialisé dans le domaine de la vision par ordinateur. Dans ses temps libres, il aime faire de la randonnée.
Karan Sindwani est Data Scientist chez Amazon ML Solutions Lab, où il construit et déploie des modèles d'apprentissage en profondeur. Il est spécialisé dans le domaine de la vision par ordinateur. Dans ses temps libres, il aime faire de la randonnée.
 Soji Adeshina est un scientifique appliqué chez AWS où il développe des modèles basés sur des réseaux de neurones graphiques pour l'apprentissage automatique sur des tâches de graphes avec des applications à la fraude et à l'abus, aux graphes de connaissances, aux systèmes de recommandation et aux sciences de la vie. Dans ses temps libres, il aime lire et cuisiner.
Soji Adeshina est un scientifique appliqué chez AWS où il développe des modèles basés sur des réseaux de neurones graphiques pour l'apprentissage automatique sur des tâches de graphes avec des applications à la fraude et à l'abus, aux graphes de connaissances, aux systèmes de recommandation et aux sciences de la vie. Dans ses temps libres, il aime lire et cuisiner.
 Vidya Sagar Ravipati est responsable chez Amazon ML Solutions Lab, où il met à profit sa vaste expérience des systèmes distribués à grande échelle et sa passion pour l'apprentissage automatique pour aider les clients AWS de différents secteurs verticaux à accélérer leur adoption de l'IA et du cloud.
Vidya Sagar Ravipati est responsable chez Amazon ML Solutions Lab, où il met à profit sa vaste expérience des systèmes distribués à grande échelle et sa passion pour l'apprentissage automatique pour aider les clients AWS de différents secteurs verticaux à accélérer leur adoption de l'IA et du cloud.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Qui sommes-nous ?
- abus
- accélérer
- à travers
- Supplémentaire
- renseignements supplémentaires
- Adoption
- Numérique
- Après
- AI
- Tous
- seul
- Amazon
- Laboratoire de solutions Amazon ML
- selon une analyse de l’Université de Princeton
- ainsi que
- applications
- appliqué
- Appliquer
- approprié
- Réservé
- artificiel
- intelligence artificielle
- AWS
- basé
- jusqu'à XNUMX fois
- Milliards
- milliards
- Blog
- Box
- box-office
- construire
- Développement
- construit
- la performance des entreprises
- Appelez-nous
- maisons
- cas
- catalogue
- globaux
- Change
- des charges
- vérifier
- Fermer
- le cloud
- adoption du cloud
- services de cloud computing
- Grappe
- code
- Cohorte
- complet
- complet
- ordinateur
- Vision par ordinateur
- informatique
- concepts
- Conduire
- configuration
- connecté
- contenu
- Correspondant
- d'exportation
- engendrent
- créée
- crédit
- Crédits
- des clients
- L'engagement des clients
- Clients
- données
- informatique
- Data Scientist
- ensembles de données
- profond
- l'apprentissage en profondeur
- profond
- déploie
- détails
- Développement
- développe
- aimer
- différent
- découverte
- discuter
- discuté
- distribué
- systèmes distribués
- Ne pas
- download
- non plus
- économies émergentes.
- Endpoint
- participation
- Divertissement
- entité
- Environment
- Ether (ETH)
- exemple
- Découvrez
- Exporter
- extrait
- Fonctionnalité
- few
- champ
- Déposez votre dernière attestation
- Fichiers
- Trouvez
- trouver
- flux
- suivre
- Abonnement
- le format
- fraude
- de
- plein
- fonctions
- Général
- générer
- génération
- obtenez
- Global
- Go
- graphique
- graphiques
- hands-on
- Dur
- aider
- utile
- caché
- de haut niveau
- HEURES
- Comment
- How To
- HTML
- HTTPS
- humain
- identique
- identifier
- Mettre en oeuvre
- la mise en œuvre
- améliorer
- in
- inclut
- Y compris
- Améliore
- indice
- industrie
- info
- d'information
- instance
- plutôt ;
- Intelligence
- impliquer
- IT
- Emploi
- json
- ACTIVITES
- spécialisées
- laboratoire
- langue
- gros
- grande échelle
- Nom de famille
- conduire
- apprentissage
- les leviers
- Bibliothèque
- Licence
- VIE
- Life Sciences
- LINK
- Gauche
- emplacement
- click
- machine learning
- Entrée
- FAIT DU
- manager
- de nombreuses
- Localisation
- cartographie
- Médias
- moyenne
- Membres
- Métadonnées
- million
- manquant
- ML
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- film
- prénom
- Nature
- Traitement du langage naturel
- Besoin
- Besoins
- Neptune
- basé sur le réseau
- réseaux
- les réseaux de neurones
- Nouveauté
- nœuds
- cahier
- Bureaux
- en cours
- original
- Autre
- global
- propre
- paquet
- paramètre
- paramètres
- partie
- passion
- pipeline
- Platon
- Intelligence des données Platon
- PlatonDonnées
- possible
- Post
- power
- alimenté
- prévoir
- prévoir
- Préparer
- Imprimé
- d'ouvrabilité
- processus
- traitement
- Produits
- Profil
- fournir
- fournit
- gamme
- votes
- raw
- en cours
- recommander
- Recommandation
- recommandations
- recommander
- en relation
- Les relations
- rester
- rappeler
- supprimez
- Rapports
- conditions
- Ressources
- Résultats
- rétention
- sagemaker
- même
- STARFLEET SCIENCES
- Scientifique
- Rechercher
- recherche
- Série
- service
- Services
- set
- mise
- devrait
- montrer
- sur mesure
- Solutions
- RÉSOUDRE
- Résout
- spécialise
- empiler
- Commencer
- Statut
- étapes
- Étapes
- Boutique
- soumettre
- tel
- Combinaison
- Sondage
- Système
- des campagnes marketing ciblées,
- tâches
- techniques
- Technologie
- La
- La Région
- leur
- Avec
- fiable
- titres
- à
- Train
- Formation
- Transformer
- oui
- tutoriel
- tv
- compréhension
- utilisé
- cas d'utilisation
- Utilisateur
- Précieux
- Plus-value
- Vaste
- version
- verticales
- vision
- façons
- Semaines
- Quoi
- qui
- large
- Large gamme
- sera
- de travail
- vos contrats
- Votre
- zéphyrnet