Cet article a été publié dans le cadre du Blogathon sur la science des données.
Introduction
Dans l'apprentissage en profondeur, les fonctions d'activation sont l'un des paramètres essentiels de la formation et de la construction d'un modèle d'apprentissage en profondeur qui fait des prédictions précises. Choisir la meilleure fonction d'activation appropriée peut aider à obtenir de meilleurs résultats avec une qualité de données réduite ; par conséquent, les fonctions d'activation doivent être décidées en fonction de leurs caractéristiques et de leur comportement sur les données alimentées.
Cet article traitera de l'une des fonctions d'accusation les plus célèbres et les plus utilisées, la sigmoïde. Nous calculerons sa dérivée pour comprendre l'intuition de base et le mécanisme de travail qui la sous-tendent, et nous discuterons également des applications et des avantages de la fonction d'activation.
Let's plonger droit dans.
Fonction sigmoïde
La fonction sigmoïde est l'une des fonctions d'activation les plus utilisées en apprentissage automatique et en apprentissage profond. Il peut être utilisé dans les couches masquées, qui prennent la sortie de la couche précédente et amènent les valeurs d'entrée entre 0 et 1. Maintenant, tout en travaillant avec les réseaux de neurones, il faut calculer la dérivée de la fonction d'activation.
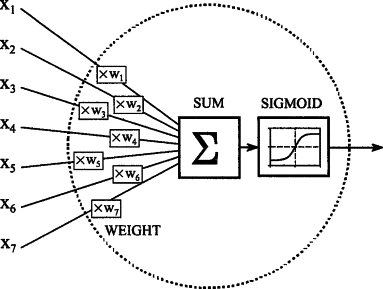
La formule de la fonction d'activation sigmoïde est :
F(x) = σ(x) = 1 ⁄ (1 + e-x)
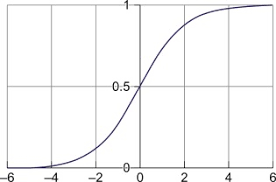
Le graphique de la fonction sigmoïde ressemble à une courbe en S, où la partie de la fonction est continue et différentielle en tout point de sa zone.
La fonction sigmoïde, également connue sous le nom de fonction d'écrasement, prend l'entrée de la couche précédemment masquée et la comprime entre 0 et 1. Ainsi, une valeur transmise à la fonction renverra toujours une valeur comprise entre 0 et 1, quelle que soit sa taille. l'affaire est fournie.
Graphiquement, la fonction sigmoïde ressemble à ceci,
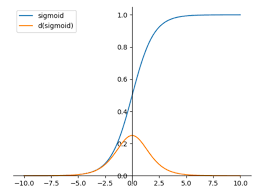
Dérivée de la fonction Siid
Dans les réseaux de neurones, les poids et les biais sont attribués de manière aléatoire dans les étapes initiales, et les poids et les biais sont mis à jour lors de la rétropropagation dans le réseau. Ici, lors de la rétropropagation, les dérivées sont calculées. En outre, la dérivée de la fonction d'activation est calculée. La fonction sigmoïde est la seule fonction d'activation qui possède sa propre fonction dans sa dérivée.
Essayons de dériver la même chose.
La formule de la fonction sigmoïde :
σ(x) = 1/1 + e-x
Étape 1 : Dérivation concernant x des deux côtés.
(x)» = d/dx {1/(1 + e-x)}
Étape 2 : Application de la règle de réciprocité.
σ(x)' = d/dx ( (1/1 + ex)-1)
σ(x)' = – 1/ (1 + e-x)2 d/dx(1+e-x)
σ(x)' = – 1/ (1 + e-x)2 d/dx (e-x)
σ(x)' = – e-x / ( 1+ e-x)2 d/dx (-x)
σ(x)' = e-x / ( 1 + e-x )
L'équation ci-dessus est connue sous le nom de dérivée de la fonction sigmoïde.
Modification de l'équation pour une forme plus généralisée.
σ(x)' = e-x / ( 1 + e-x) ( 1+ e-x)
σ(x)' = 1/ 1 + e-x ×e-x/1+e-x
σ(x)' = σ(x) × e-x/1+e-x
σ(x)' = σ(x) × ( 1 – 1/1+e-x)
σ(x)' = σ(x) ( 1- σ(x) )
L'équation ci-dessus est connue sous le nom de forme généralisée de la fonction sigmoïde.
Code pour implémenter la fonction Sigmund
Il faut écrire le code suivant pour implémenter la fonction sigmoïde en Python. Ce qui suit nécessitait que la valeur de x soit prédéfinie pour en tirer le trait sigmoïde.
Code Python :
Supposons que les poids d'entrée soient transmis aux couches et que les conséquences et les biais soient transmis à la couche suivante. Si la couche de sortie finale a une fonction sigmoïde, elle sera appliquée à la sortie et le résultat final sera affiché.
Par exemple,
Supposons que la sortie de la couche cachée est 1 ; alors, la valeur de x serait 1.
Sortie finale :
= 1 / 1 + e-x
= 1 / 1 + e-1
= 1/7
= 1 / 1.367
= 0.7315
Comme nous pouvons le voir ici, la sortie de la couche précédemment masquée était de 1, et la fonction en a fait 0.7315, où il est visible que le La fonction sigmoïde est une fonction de compression.
Applications de la fonction sigmoïde
1. Problèmes de classification binaire :
Nous pouvons utiliser la fonction sigmoïde dans les problèmes de classification binaire car elle renvoie la sortie entre 0 et 1.
2. Modèles probabilistes :
Nous pouvons utiliser la fonction sigmoïde lorsque nous devons travailler sur un modèle probabiliste car elle peut être utilisée pour calculer la probabilité d'une classe donnée entre 0 et 1.
3. Ensembles de données d'images et réseaux de neurones :
La fonction sigmoïde peut être utilisée pour les réseaux de neurones sur des ensembles de données d'images pour effectuer des tâches telles que les segmentations d'images, les classifications, etc.
Limitations de la fonction sigmoïde
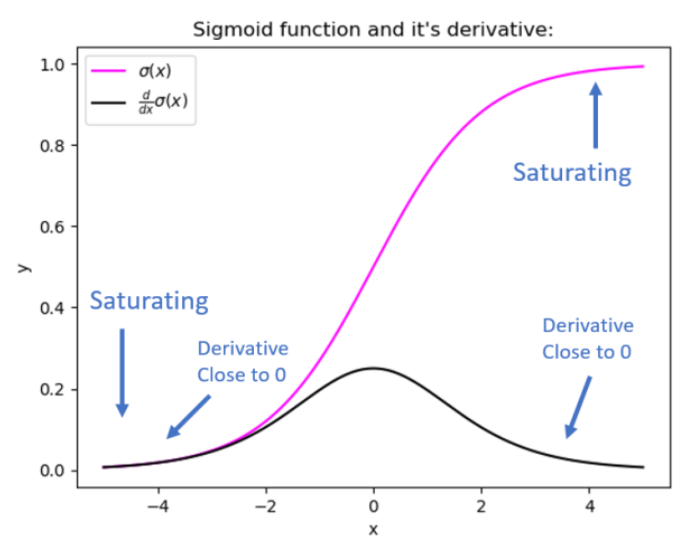
1. Problème de gradient de disparition :
L'un des problèmes importants avec le sigmoïde est le manque de mise à jour du poids. Par conséquent, la fonction renvoie parfois de petites valeurs en sortie, sans modifier les pondérations et les biais qui causent le problème du gradient de fuite.
2. Problème d'explosion des diplômés :
Il arrive aussi que le sigmoïde renvoie de très grandes valeurs en sortie, ce qui entraîne un problème de gradient explosif.
3. Une fonction de compression :
On note parfois que comme le sigmoïde est une fonction de compression, il rend les résultats de sortie entre 0 et 1, masquant ainsi l'essence ou la connaissance entre des nombres beaucoup plus élevés et beaucoup plus petits et rendant le modèle moins précis.
Foire aux Questions
1. Pourquoi la rétropropagation est-elle accessible à la fonction sigmoïde ?
Puisqu'il s'agit de la seule fonction d'activation qui apparaît dans la dérivée d'elle-même, elle aide les réseaux de neurones à mieux exécuter l'algorithme de rétropropagation, car la descente de gradient est utilisée pour mettre à jour les poids et les biais du modèle.
2. Pourquoi la fonction d'activation sigmoïde est-elle une fonction de compression ?
Lorsque la fonction d'activation comprime les valeurs d'entrée transmises aux couches masquées, la fonction renvoie la sortie entre 0 et 1. Ainsi, peu importe la façon dont les nombres positifs ou négatifs sont fournis à la couche, cette fonction la comprime entre 0 et 1.
3. Quel est le principal problème avec la fonction sigmoïde lors de la rétropropagation ?
Le principal problème lié à la fonction d'activation est lorsque l'algorithme de descente de gradient calcule les nouveaux poids et biais ; si ces valeurs sont minimales, alors les mises à jour des conséquences et des préférences seront également maigres et donc, ce qui se traduit par un problème de gradient de fuite, où le modèle ne s'appuiera sur rien.
Conclusion
Dans cet article, nous avons discuté de la fonction sigmoïde et de sa dérivée, de son mécanisme de travail et de l'intuition centrale derrière celle-ci avec ses applications associées aux avantages et aux inconvénients. Connaître ces concepts clés vous aidera à mieux comprendre les mathématiques derrière la fonction et vous aidera à répondre efficacement à toutes les questions d'entrevue connexes.
Certain Key A emporter de cet article sont:
1. La fonction sigmoïde est une fonction de compression qui résulte de la sortie entre 0 et 1.
2. Le sigmoïde peut être utilisé efficacement pour les problèmes de classification binaire, car il renvoie la sortie entre 0 et 1.
3. La fonction renvoie parfois des valeurs beaucoup plus grandes ou plus petites, ce qui entraîne des problèmes de gradient qui disparaissent ou explosent.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2022/12/sigmoid-function-derivative-and-working-mechanism/
- 1
- a
- au dessus de
- accessible
- Selon
- Avec cette connaissance vient le pouvoir de prendre
- Activation
- avantages
- algorithme
- toujours
- analytique
- ainsi que
- répondre
- applications
- appliqué
- Application
- approprié
- Réservé
- article
- attribué
- associé
- derrière
- va
- ci-dessous
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Big
- Des deux côtés
- apporter
- Développement
- calculé
- calcule
- Causes
- Modifications
- caractéristiques
- choose
- classe
- classification
- code
- concepts
- Conséquences
- continu
- Core
- courbe
- données
- ensembles de données
- affaire
- décidé
- profond
- l'apprentissage en profondeur
- Dérivés
- discrétion
- discuter
- discuté
- pendant
- efficacement
- essence
- essential
- etc
- Ether (ETH)
- exemple
- célèbre
- Fed
- finale
- Abonnement
- formulaire
- formule
- de
- fonction
- fonctions
- obtenez
- gif
- donné
- les gradients
- graphique
- arrive
- aider
- aide
- ici
- caché
- augmentation
- Comment
- HTTPS
- image
- Mettre en oeuvre
- in
- initiale
- contribution
- Interview
- questions d'interview
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- lui-même
- ACTIVITES
- connaissance
- spécialisées
- connu
- Peindre
- gros
- plus importantes
- couche
- apprentissage
- recherchez-
- LOOKS
- click
- machine learning
- LES PLANTES
- Entrée
- FAIT DU
- Fabrication
- mathématiques
- Matière
- mécanisme
- Médias
- minimal
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- nécessaire
- négatif
- réseau et
- réseaux
- les réseaux de neurones
- Nouveauté
- next
- noté
- numéros
- ONE
- propre
- propriété
- paramètres
- partie
- passé
- effectuer
- effectuer
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- positif
- Prédictions
- préférences
- précédent
- précédemment
- Problème
- d'ouvrabilité
- à condition de
- publié
- Python
- qualité
- fréquemment posées
- Prix Réduit
- en relation
- représentation
- conditions
- résultat
- résultant
- Résultats
- retourner
- Retours
- Règle
- même
- Sciences
- devrait
- montré
- Accompagnements
- significative
- petit
- faibles
- So
- étapes
- Prenez
- prend
- tâches
- Les
- la Fed
- leur
- ainsi
- donc
- à
- Formation
- comprendre
- a actualisé
- Actualités
- la mise à jour
- utilisé
- Plus-value
- Valeurs
- visible
- poids
- Quoi
- Qu’est ce qu'
- qui
- tout en
- sera
- Activités principales
- de travail
- pourra
- écrire
- X
- zéphyrnet