Ce billet de blog est co-écrit avec le Dr Ebtesam Almazrouei, directeur exécutif-chercheur en chef par intérim de l'IA-Cross Center Unit et chef de projet pour les projets LLM au TII.
Émirats arabes unis (EAU) Institut d'innovation technologique (TII), le pilier de la recherche appliquée d'Abu Dhabi Conseil de recherche sur les technologies avancées, a lancé Falcon LLM, un modèle fondamental de grand langage (LLM) avec 40 milliards de paramètres. TII est un centre de recherche mondial de premier plan dédié à repousser les frontières de la connaissance. L'équipe de scientifiques, de chercheurs et d'ingénieurs de TII travaille pour fournir des découvertes scientifiques et des technologies transformatrices. Le travail de TII se concentre sur les percées qui assureront la pérennité de notre société. Formé sur 1 XNUMX milliards de jetons, TII Falcon LLM offre des performances de premier ordre tout en restant incroyablement rentable. Falcon-40B correspond aux performances d'autres LLM hautes performances et est le modèle open source le mieux classé dans le public Classement Hugging Face Open LLM. Il est disponible en open source dans deux tailles différentes - Falcon-40B et Falcon-7B et a été construit à partir de zéro en utilisant des tâches de prétraitement des données et de formation de modèles basées sur Amazon Sage Maker. L'open source Falcon 40B permet aux utilisateurs de construire et de personnaliser des outils d'IA qui répondent aux besoins uniques des utilisateurs, facilitant une intégration transparente et garantissant la préservation à long terme des actifs de données. Les poids du modèle peuvent être téléchargés, inspectés et déployés n'importe où.
À partir du 7 juin, les deux Falcon LLM seront également disponibles dans Amazon SageMaker JumpStart, le hub d'apprentissage automatique (ML) de SageMaker qui propose des modèles pré-formés, des algorithmes intégrés et des modèles de solution prédéfinis pour vous aider à démarrer rapidement avec ML. Vous pouvez déployer et utiliser les Falcon LLM en quelques clics dans Studio SageMaker ou par programmation via le Kit de développement logiciel (SDK) SageMaker Python. Pour déployer et exécuter l'inférence sur les Falcon LLM, reportez-vous au Introduction à SageMaker JumpStart - Génération de texte avec Falcon LLM exemple de cahier.

Le Dr Ebtesam Almazrouei, directeur exécutif-chercheur en chef par intérim en IA de l'unité AI-Cross Center et chef de projet pour les projets LLM au TII, partage :
« Nous sommes fiers d'annoncer la sortie officielle en open source de Falcon-40B, le modèle de langage open source le mieux classé au monde. Falcon-40B est un modèle open-source exceptionnel avec des paramètres 40B, spécifiquement conçu comme un modèle de décodeur causal uniquement. Il a été formé sur un vaste ensemble de données de 1,000 2.0 milliards de jetons, y compris RefinedWeb amélioré avec des corpus organisés. Le modèle est mis à disposition sous la licence Apache 40, garantissant son accessibilité et sa convivialité. Le Falcon-65B a dépassé des modèles renommés comme LLaMA-40B, StableLM et MPT dans le classement public maintenu par Hugging Face. L'architecture du Falcon-XNUMXB est optimisée pour l'inférence, intégrant FlashAttention et les techniques multirequêtes. »
« Cette étape reflète notre volonté de repousser les limites de l'innovation en IA et du niveau de préparation technologique pour l'engagement communautaire, l'éducation, les applications du monde réel et la collaboration. poursuit le Dr Ebtesam. « En lançant le Falcon-40B en tant que modèle open source, nous offrons aux chercheurs, aux entrepreneurs et aux organisations la possibilité d'exploiter ses capacités exceptionnelles et de faire progresser les solutions basées sur l'IA, des soins de santé à l'espace, de la finance, de la fabrication à la biotechnologie ; les possibilités de solutions basées sur l'IA sont illimitées. Pour accéder au Falcon-40B et explorer son remarquable potentiel, veuillez visiter FalconLLM.tii.ae. Rejoignez-nous pour tirer parti de la puissance du Falcon-40B pour façonner l'avenir de l'IA et révolutionner les industries »
Dans cet article, nous approfondissons avec le Dr Almazrouei la formation Falcon LLM sur SageMaker, la conservation des données, l'optimisation, les performances et les prochaines étapes.
Une nouvelle génération de LLM
Les LLM sont des algorithmes logiciels formés pour compléter des séquences de texte naturelles. En raison de leur taille et du volume de données de formation avec lesquelles ils interagissent, les LLM ont des capacités de traitement de texte impressionnantes, notamment la synthèse, la réponse aux questions, l'apprentissage en contexte, etc.
Début 2020, les organismes de recherche du monde entier ont mis l'accent sur la taille du modèle, observant que la précision était corrélée au nombre de paramètres. Par exemple, GPT-3 (2020) et BLOOM (2022) comportent environ 175 milliards de paramètres, Gopher (2021) a 230 milliards de paramètres et MT-NLG (2021) 530 milliards de paramètres. En 2022, Hoffmann et al. a observé que l'équilibre actuel du calcul entre les paramètres du modèle et la taille de l'ensemble de données était sous-optimal, et a publié des lois de mise à l'échelle empiriques suggérant qu'équilibrer le budget de calcul vers des modèles plus petits formés sur plus de données pourrait conduire à des modèles plus performants. Ils ont mis en œuvre leurs conseils dans le modèle Chinchilla (70) à paramètre 2022B, qui a surpassé des modèles beaucoup plus grands.
Formation LLM sur SageMaker
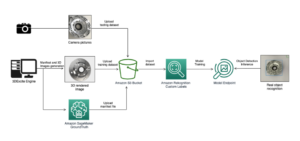
SageMaker est une collection d'API gérées pour le développement, la formation, le réglage et l'hébergement de modèles d'apprentissage automatique (ML), y compris les LLM. De nombreux clients font confiance à SageMaker pour leurs charges de travail LLM, telles que IA de stabilité, Laboratoires AI21, Étreindre le visageet une LG AI. Formation SageMaker fournit des clusters de calcul avec une configuration matérielle et un code définis par l'utilisateur. Les tâches de calcul sont facturées par exécution, au prorata de la seconde, ce qui signifie que les utilisateurs ne sont pas facturés pour la capacité GPU lorsqu'ils n'utilisent pas le service. TII a utilisé des clusters transitoires fournis par l'API de formation SageMaker pour former le Falcon LLM, jusqu'à 48 instances ml.p4d.24xlarge, cumulées dans 384 GPU NVIDIA A100. Maintenant, TII forme le prochain Falcon LLM et a étendu sa formation à 3,136 100 GPU A392 (4 instances ml.pXNUMXd).
Une quantité sans précédent d'innovations personnalisées est entrée dans toutes les couches du projet afin d'élever la barre de la qualité scientifique et de la vitesse de formation. Dans les sections suivantes, nous décrivons les optimisations TII menées à toutes les couches du système de formation en apprentissage profond (DL).
Curation de données évolutive
Les LLM de dernière génération tirent leur force de la taille et de la qualité des données de formation. L'équipe a apporté un soin particulier à la création d'un ensemble de données d'un billion de jetons de haute qualité. Plusieurs tâches de CPU SageMaker Training ont transformé des pétaoctets de données Web bon marché et évolutives en un ensemble de données de formation organisé et sécurisé. Des systèmes automatisés ont filtré et dédupliqué les données ; par exemple, des classificateurs ML ont été utilisés pour filtrer les grossièretés. Les tâches CPU exécutées sur ml.c5.18xlarge (72 vCPU, 144 Go de RAM) ont été instanciées dans quelques appels d'API via SageMaker Training pour exécuter des tâches de transformation de données. L'équipe a utilisé des tâches CPU à instance unique et multi-instance pour différents cas d'utilisation. Certaines de ces tâches utilisaient des centaines de tâches parallèles d'architecture sans partage (SNA), chacune sur une seule machine, et pour les tâches nécessitant une synchronisation inter-travailleurs, l'équipe a lancé des tâches multi-instances, cumulées dans des dizaines d'instances et des milliers de vCPU. Pour l'anecdote, sur une tâche de préparation d'ensemble de données en aval, l'équipe est montée à 257 ml.c5.18xlarge dans une seule tâche SageMaker Training, cumulant 18,504 37 vCPU et XNUMX To de mémoire.
Maximiser le débit de formation
Pour minimiser à la fois les coûts de formation et le délai de mise sur le marché, l'équipe a poursuivi plusieurs directions d'optimisation pour accélérer la vitesse de formation proportionnelle aux jetons de formation traités par seconde et mesurés en TFLOP/GPU. L'équipe a utilisé un cadre de formation LLM 3D parallèle entièrement personnalisé, avec des couches optimisées personnalisées écrites dans un code GPU compilé. L'équipe est allée jusqu'à écrire sa propre implémentation de multiplication matricielle personnalisée pour gagner en vitesse ! L'équipe a également développé une logique qui adapte la communication parallèle à la topologie du réseau sous-jacent. Au cours de leurs expériences de mise à l'échelle initiales, TII a pu atteindre 166 TFLOP/GPU sur un modèle 147B sur 256 GPU, et 173 TFLOP/GPU sur un modèle 13B sur 16 GPU, à notre connaissance le modèle TFLOP le plus rapide réalisé dans le cloud à le moment du test fin 2022.
Stockage sans serveur
La formation LLM nécessite beaucoup de stockage; plusieurs téraoctets de données d'entraînement doivent être acheminés vers le cluster d'entraînement, et plusieurs téraoctets de points de contrôle de modèle reviennent régulièrement du cluster au stockage permanent. Les points de contrôle doivent également atteindre le cluster de formation le plus rapidement possible en cas de redémarrage du travail. Dans le calcul haute performance (HPC) traditionnel, les nœuds de calcul sont connectés à des systèmes de fichiers distribués, qui fournissent des E/S et un débit hautes performances via une interface de type POSIX. Dans AWS, les clients utilisent régulièrement le Amazon FSx pour Lustre système de fichiers à cet effet (pour plus de détails, reportez-vous à Accélérez la formation sur Amazon SageMaker à l'aide d'Amazon FSx pour Luster et des systèmes de fichiers Amazon EFS), et nous avons également documenté l'utilisation autogérée de BeeGFS dans une étude de cas de vision par ordinateur distribuée. En raison de leur concentration sur les coûts et la simplicité opérationnelle, l'équipe a décidé de ne pas implémenter et exploiter des serveurs de système de fichiers, mais a plutôt relevé le défi de construire exclusivement sur le stockage d'objets sans serveur. Service de stockage simple Amazon (Amazon S3). Une classe d'ensemble de données S3 personnalisée a été créée à l'aide du kit AWS SDK pour Python (Boto3) et a fourni des performances satisfaisantes tout en permettant aux scientifiques d'itérer de manière autonome sur l'ingénierie des E/S et la science des modèles au sein de la même base de code.
Innovation côté client
Un projet LLM se compose rarement d'un seul emploi de formation; de nombreux travaux sont nécessaires pour effectuer les premiers tests et expériences. Au cours de la formation principale en production, plusieurs tâches peuvent être enchaînées, par exemple pour mettre à jour la configuration ou les versions logicielles, déployer des correctifs ou récupérer des pannes. Les scientifiques de TII ont mené une ingénierie importante pour créer des clients personnalisés adaptés à la formation LLM. Un client de lancement a été construit au-dessus du SDK de formation SageMaker afin de regrouper plusieurs fonctionnalités en une seule commande, par exemple la gestion des versions de code, la création d'images Docker et le lancement de tâches. De plus, un AWS Lambda La fonction de calcul sans serveur a été conçue pour surveiller, surveiller et intervenir sur les travaux selon les besoins.
Utilisation des bots Slack pour les audits de qualité d'inférence
Vers la fin de la formation, l'équipe a déployé le modèle en interne Point de terminaison GPU d'hébergement SageMaker pour une interaction en temps réel. L'équipe est allée jusqu'à créer un bot Slack avec lequel dialoguer, obtenir des retours réalistes et réaliser des audits qualitatifs de qualité du modèle.
Formation et suivi des performances
La formation d'un LLM nécessite de grandes quantités de ressources de calcul, y compris des ressources CPU, GPU et mémoire. Par conséquent, TII devait surveiller les performances et le temps d'inactivité de la tâche de formation pour garantir une utilisation optimale des ressources de calcul et leur rentabilité.
Pour créer une solution de surveillance automatisée, TII a utilisé Amazon Cloud Watch des alarmes pour surveiller l'utilisation du GPU, du CPU et de la mémoire pour les tâches de formation. CloudWatch collecte les données brutes et les traite en métriques lisibles en temps quasi réel à partir des instances de conteneur sous-jacentes utilisées dans la tâche de formation SageMaker. Après cela, nous fixons des seuils pour chacune de ces métriques, et si une métrique tombe en dessous du seuil, une alarme est déclenchée. Cette alarme informe l'équipe de TII de la faible utilisation des ressources, leur permettant de prendre des mesures correctives pour rectifier les contraintes d'utilisation des ressources.
Outre la surveillance de l'utilisation des ressources, TII peut également surveiller le temps d'inactivité des ressources de la tâche de formation. Si les ressources de la tâche de formation étaient inactives pendant une période prolongée, cela pourrait indiquer un goulot d'étranglement à n'importe quelle étape du cycle de formation et nécessiter une enquête manuelle. Dans certains cas, l'utilisation des ressources était encore relativement optimale, mais le processus de formation lui-même ne progressait pas. Dans ces cas, TII a intégré les alarmes CloudWatch aux fonctions Lambda pour interroger et lire les journaux de formation générés, puis prendre des actions automatiques en fonction de l'erreur générée ou de l'inactivité du processus de génération de journaux (le cluster est arrêté). L'alarme déclenche une action pour arrêter la tâche de formation, ce qui garantit que TII n'encourt pas de coûts inutiles lorsque les ressources ne sont pas utilisées.
Conclusion
En utilisant SageMaker associé à une innovation propriétaire et personnalisée, TII a pu former un modèle à la pointe de la technologie dans de multiples dimensions : percée technologique, qualité scientifique, vitesse de formation, mais aussi simplicité opérationnelle.
"La sortie du Falcon 40B des EAU, le modèle d'IA Open Source le mieux classé au monde, illustre le leadership technologique et ouvre la voie à l'innovation alimentée par l'IA dans le region » indique le Dr Ebtesam Almazrouei ; ajoutant que "nous démontrons notre engagement envers les objectifs énoncés dans la Stratégie nationale sur l'IA 2031. Notre participation active aux avancées technologiques mondiales, représentée par le Falcon-40B, joue un rôle crucial dans notre quête d'une économie fondée sur la connaissance. Grâce à des investissements et au développement de solutions d'IA, nous visons à créer de nouvelles opportunités de croissance économique, de progrès social et de progrès éducatifs.
« La nature open source du Falcon-40B reflète notre engagement envers la collaboration, la transparence, l'innovation et la recherche dans le domaine de l'IA. Nous croyons en la démocratisation des capacités technologiques avancées de l'IA, rendant le Falcon-40B accessible aux chercheurs et aux organisations du monde entier.
"Pour l'avenir, nous continuerons à contribuer aux progrès de l'IA et de la technologie, avec des modèles à venir dans le pipeline. De plus, nous promouvrons activement l'adoption de la technologie avancée de l'IA au sein des organisations et des entreprises de notre pays, favorisant la croissance et la prospérité conformément à nos objectifs stratégiques.– Dr Almazrouei
Pour en savoir plus sur Falcon LLM, consultez le site Web FalconLLM.tii.ae et les la carte modèle sur Hugging Face!
À propos des auteurs
 Dr Ebtesam Almazrouei est le directeur exécutif-chercheur en chef par intérim en IA et fondateur de l'unité Al-Cross Center du Technology Innovation Institute (TII). En tant que fondateur de l'unité Al-Cross Center du Technology Innovation Institute (TII), le Dr Almazrouei a joué un rôle central dans l'élaboration des capacités d'IA de TII. Sa vision stratégique et son expertise en IA et en apprentissage automatique lui ont permis de mener des initiatives de recherche révolutionnaires et de favoriser des collaborations interfonctionnelles, ce qui a permis de fournir des solutions d'IA innovantes dans de nombreux secteurs.
Dr Ebtesam Almazrouei est le directeur exécutif-chercheur en chef par intérim en IA et fondateur de l'unité Al-Cross Center du Technology Innovation Institute (TII). En tant que fondateur de l'unité Al-Cross Center du Technology Innovation Institute (TII), le Dr Almazrouei a joué un rôle central dans l'élaboration des capacités d'IA de TII. Sa vision stratégique et son expertise en IA et en apprentissage automatique lui ont permis de mener des initiatives de recherche révolutionnaires et de favoriser des collaborations interfonctionnelles, ce qui a permis de fournir des solutions d'IA innovantes dans de nombreux secteurs.
L'une des réalisations notables du Dr Almazrouei est son rôle déterminant dans le développement du Falcon 40B, un LLM de pointe qui a acquis une reconnaissance mondiale. Les performances exceptionnelles du Falcon 40B l'ont classé au premier rang mondial des LLM dans le classement de Hugging Face en mai 2023. De plus, elle a dirigé le développement de Noor, le plus grand modèle de grande langue arabe (LLM) au monde, publié en avril 2022.
Le Dr Almazrouei est reconnue dans le monde entier pour ses contributions à l'IA et figurait dans la liste Leading AI Women in the World in 2023, aux côtés d'autres femmes éminentes dans le domaine. Elle est également une défenseure de la durabilité et des initiatives AI for Good, ainsi que présidente générale d'Abu Dhabi AI Connect et présidente TPC de nombreuses conférences internationales IEEE.
Ses contributions vont au-delà de son travail chez TII où elle dirige le sous-comité d'experts en mégadonnées du Conseil des Émirats arabes unis pour l'IA et la Blockchain et est membre du comité directeur mondial du Wireless World Research Forum (WWRF). Elle est une auteure scientifique, une inventrice de brevets, une entrepreneure et une conférencière renommée, connue pour ses discours liminaires lors de sommets prestigieux tels que le AI Summit à Londres, le World AI Cannes Festival et les sommets Tech.
 Will Badr est un Sr. Manager AI/ML Solutions Architects basé à Dubaï - Émirats Arabes Unis qui travaille au sein de l'équipe mondiale Amazon Machine Learning. Will est passionné par l'utilisation de la technologie de manière innovante pour avoir un impact positif sur la communauté. Dans ses temps libres, il aime faire de la plongée, jouer au football et explorer les îles du Pacifique.
Will Badr est un Sr. Manager AI/ML Solutions Architects basé à Dubaï - Émirats Arabes Unis qui travaille au sein de l'équipe mondiale Amazon Machine Learning. Will est passionné par l'utilisation de la technologie de manière innovante pour avoir un impact positif sur la communauté. Dans ses temps libres, il aime faire de la plongée, jouer au football et explorer les îles du Pacifique.
 Olivier Cruchant est un architecte de solutions spécialiste de l'apprentissage automatique chez AWS, basé en France. Olivier aide les clients d'AWS, des petites startups aux grandes entreprises, à développer et déployer des applications d'apprentissage automatique de niveau production. Dans ses temps libres, il aime lire des articles de recherche et explorer la nature sauvage avec ses amis et sa famille.
Olivier Cruchant est un architecte de solutions spécialiste de l'apprentissage automatique chez AWS, basé en France. Olivier aide les clients d'AWS, des petites startups aux grandes entreprises, à développer et déployer des applications d'apprentissage automatique de niveau production. Dans ses temps libres, il aime lire des articles de recherche et explorer la nature sauvage avec ses amis et sa famille.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/technology-innovation-institute-trains-the-state-of-the-art-falcon-llm-40b-foundation-model-on-amazon-sagemaker/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 100
- 16
- 2020
- 2021
- 2022
- 2023
- 2031
- 24
- 28
- 40
- 72
- 7ème
- a
- A100
- capacités
- Capable
- A Propos
- abu
- abu dhabi
- accélérer
- accès
- accessibilité
- accessible
- précision
- atteint
- réalisations
- à travers
- Action
- actes
- infection
- activement
- adapté
- s'adapte
- ajoutant
- ajout
- En outre
- Adoption
- Avancée
- progrès
- avocat
- Après
- à opposer à
- devant
- AI
- IA et blockchain
- Stratégie de l'IA
- Alimenté par l'IA
- AI / ML
- objectif
- AL
- alarme
- algorithmes
- aligné
- Tous
- Permettre
- aux côtés de
- aussi
- Amazon
- Amazon FSx
- Apprentissage automatique d'Amazon
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon Web Services
- montant
- quantités
- an
- et les
- Annoncer
- tous
- de n'importe où
- Apache
- api
- Apis
- applications
- appliqué
- Avril
- Arabe
- architecture
- SONT
- autour
- AS
- Outils
- At
- audits
- auteur
- Automatisation
- Automatique
- de manière autonome
- disponibles
- AWS
- RETOUR
- Balance
- équilibrage
- barre
- basé
- BE
- va
- CROYONS
- ci-dessous
- Améliorée
- jusqu'à XNUMX fois
- Au-delà
- Big
- Big Data
- plus gros
- Milliards
- biotech
- blockchain
- Blog
- Bloom
- planche
- bénéficie d'
- Bot
- tous les deux
- les robots
- frontières
- Illimité
- percée
- percées
- budget
- construire
- Développement
- construit
- intégré
- entreprises
- mais
- by
- Appels
- CAN
- capacités
- Compétences
- carte
- les soins
- maisons
- cas
- répondre
- Canaux centraux
- enchaîné
- Président
- challenge
- accusé
- pas cher
- vérifier
- chef
- classe
- client
- CLIENTS
- le cloud
- Grappe
- code
- Base de code
- collaboration
- collaborations
- collection
- recueille
- engagement
- Communication
- Communautés
- complet
- calcul
- ordinateur
- Vision par ordinateur
- informatique
- Conduire
- menée
- conférences
- configuration
- NOUS CONTACTER
- connecté
- consiste
- contraintes
- construire
- Contenant
- continuer
- contribuer
- contributions
- corrélée
- rentable
- Costs
- pourriez
- Conseil
- Pays
- cours
- Processeur
- élaborer
- engendrent
- La création
- crucial
- organisée
- curation
- Courant
- Customiser
- Clients
- personnaliser
- En investissant dans une technologie de pointe, les restaurants peuvent non seulement rester compétitifs dans un marché en constante évolution, mais aussi améliorer significativement l'expérience de leurs clients.
- cycle
- données
- décidé
- dévoué
- dédicace
- profond
- l'apprentissage en profondeur
- livrer
- page de livraison.
- Démocratiser
- démontrer
- déployer
- déployé
- décrire
- un
- détails
- développer
- développé
- développement
- Développement
- Dhabi
- dialogue
- différence
- différent
- dimensions
- découverte
- Distingué
- distribué
- Docker
- documenté
- Ne fait pas
- download
- des dizaines
- dr
- motivation
- Dubai
- deux
- pendant
- E & T
- chacun
- "Early Bird"
- Économique
- Croissance économique
- économie
- Éducation
- pédagogique
- non plus
- l'accent
- empowered
- permet
- permettant
- fin
- participation
- ENGINEERING
- Les ingénieurs
- améliorée
- assurer
- Assure
- assurer
- entreprises
- Entrepreneur
- les entrepreneurs
- erreur
- Ether (ETH)
- événement
- exemple
- exceptionnel
- uniquement au
- exécutif
- Expériences
- expériences
- expert
- nous a permis de concevoir
- explorez
- Explorer
- étendre
- Visage
- faciliter
- faucon
- Chutes
- famille
- loin
- RAPIDE
- Fonctionnalité
- en vedette
- Doté d'
- Réactions
- FESTIVAL
- few
- champ
- Déposez votre dernière attestation
- une fonction filtre
- finance
- Focus
- se concentre
- Pour
- Forum
- Accueillir
- favoriser
- Fondation
- fondateur
- Framework
- France
- amis
- De
- Frontières
- d’étiquettes électroniques entièrement
- fonction
- fonctionnalités
- fonctions
- plus
- avenir
- L'avenir de l'IA
- Gain
- Général
- généré
- génération
- obtenez
- Global
- À l'échelle mondiale
- Go
- Objectifs
- Bien
- gaufre
- GPU
- GPU
- révolutionnaire
- Croissance
- l'orientation
- Matériel
- harnais
- Vous avez
- he
- la médecine
- vous aider
- aide
- ici
- haute performance
- haute performance
- de haute qualité
- sa
- hébergement
- hpc
- HTML
- http
- HTTPS
- Moyeu
- Des centaines
- Idle
- IEEE
- if
- illustre
- image
- Impact
- Mettre en oeuvre
- la mise en oeuvre
- mis en œuvre
- impressionnant
- in
- Y compris
- incorporation
- incroyablement
- indiquer
- indique
- secteurs
- initiale
- les initiatives
- Innovation
- innovations
- technologie innovante
- plutôt ;
- Institut
- instrumental
- des services
- l'intégration
- interagir
- l'interaction
- Interfaces
- interne
- International
- intervenir
- développement
- enquête
- Investissements
- participation
- Îles
- IT
- SES
- lui-même
- Emploi
- Emplois
- rejoindre
- Rejoignez-nous
- jpg
- juin
- Tonique
- spécialisées
- connu
- langue
- gros
- Grandes entreprises
- le plus grand
- En retard
- lancer
- lancé
- Lois
- poules pondeuses
- conduire
- Leadership
- conduisant
- Conduit
- APPRENTISSAGE
- apprentissage
- LED
- Niveau
- en tirant parti
- Licence
- comme
- Liste
- enregistrer
- logique
- London
- long-term
- Faible
- click
- machine learning
- LES PLANTES
- Entrée
- Fabrication
- gérés
- manager
- Manuel
- fabrication
- de nombreuses
- Matrice
- Mai..
- sens
- mesuré
- membre
- Mémoire
- métrique
- Métrique
- minimiser
- ML
- modèle
- numériques jumeaux (digital twin models)
- Surveiller
- Stack monitoring
- PLUS
- Par ailleurs
- beaucoup
- plusieurs
- Nationales
- Nature
- Nature
- Besoin
- nécessaire
- Besoins
- réseau et
- Nouveauté
- next
- nœuds
- notable
- cahier
- maintenant
- nombre
- nombreux
- Nvidia
- objet
- Stockage d'objets
- objectifs
- observée
- of
- Offres Speciales
- officiel
- Olivier
- on
- ONE
- ouvert
- open source
- fonctionner
- opérationnel
- Opportunités
- Opportunités
- optimaux
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- optimisé
- or
- de commander
- organisations
- Autre
- nos
- ande
- décrit
- plus de
- propre
- Pacifique
- PACK
- apparié
- papiers
- Parallèle
- paramètre
- paramètres
- partie
- passionné
- Patches
- brevet
- performant
- effectuer
- période
- permanent
- Pilier
- pipeline
- pivot
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- joué
- joue
- veuillez cliquer
- possibilités
- possible
- Post
- défaillances
- power
- préparation
- préservation
- prestigieux
- processus
- traité
- les process
- traitement
- Vidéo
- IMPIÉTÉ
- Progrès
- progressant
- Projet
- projets
- promouvoir
- propriétaire
- prospérité
- fièrement
- fournir
- à condition de
- public
- publié
- but
- poursuite
- Poussant
- mettre
- Python
- qualitatif
- qualité
- question
- vite.
- augmenter
- RAM
- classé
- raw
- les données brutes
- nous joindre
- Lire
- Préparation
- en cours
- monde réel
- en temps réel
- réaliste
- reconnaissance
- reconnu
- Récupérer
- reflète
- régulièrement
- relativement
- libérer
- libéré
- libération
- compter
- restant
- remarquables
- Célèbre
- représenté
- exigent
- a besoin
- un article
- chercheur
- chercheurs
- ressource
- Resources
- résultant
- révolutionner
- Rôle
- Courir
- pour le running
- des
- sagemaker
- même
- évolutive
- mise à l'échelle
- Sciences
- sur une base scientifique
- scientifiques
- gratter
- Sdk
- fluide
- Deuxièmement
- les sections
- Sans serveur
- Serveurs
- service
- Services
- set
- plusieurs
- Forme
- mise en forme
- Partages
- elle
- significative
- étapes
- simplicité
- unique
- Taille
- tailles
- mou
- petit
- faibles
- Football
- Réseaux sociaux
- Société
- Logiciels
- sur mesure
- Solutions
- quelques
- Identifier
- Space
- Speaker
- spécialiste
- groupe de neurones
- spécifiquement
- discours
- vitesse
- Étape
- j'ai commencé
- Startups
- state-of-the-art
- étapes
- Étapes
- Encore
- Arrêter
- storage
- Stratégique
- de Marketing
- force
- sous-comité
- tel
- Sommet
- Sommets
- surpassé
- Durabilité
- synchronisation
- combustion propre
- Système
- Prenez
- Tâche
- tâches
- équipe
- technologie
- techniques
- technologique
- Les technologies
- Technologie
- innovation technologique
- modèles
- tester
- tests
- génération de texte
- qui
- Le
- El futuro
- le monde
- leur
- Les
- puis
- donc
- Ces
- l'ont
- this
- milliers
- порог
- Avec
- débit
- fiable
- à
- ensemble
- Tokens
- a
- les outils
- top
- vers
- traditionnel
- Train
- qualifié
- Formation
- les trains
- De La Carrosserie
- transformation
- transformé
- Transparence
- Voyage
- déclenché
- Billion
- deux
- UAE
- sous
- sous-jacent
- expérience unique et authentique
- unité
- sans précédent
- prochain
- Mises à jour
- us
- convivialité
- utilisé
- d'utiliser
- utilisateurs
- en utilisant
- utilisé
- Vaste
- via
- vision
- le volume
- était
- Montres
- Façon..
- façons
- we
- web
- services Web
- Site Web
- WELL
- est allé
- ont été
- quand
- qui
- tout en
- WHO
- sera
- sans fil
- comprenant
- dans les
- Femme
- activités principales
- vos contrats
- world
- monde
- partout dans le monde
- écriture
- code écrit
- you
- Youtube
- zéphyrnet