परिचय
प्रत्येक डेटा वैज्ञानिक इस बड़े अजेय डेटा को संसाधित करने के लिए एक कुशल और विश्वसनीय उपकरण की मांग करता है। आज हम डेल्टा लेक नामक एक ऐसे उपकरण पर चर्चा करते हैं, जिसका उपयोग डेटा उत्साही अपनी डेटा प्रोसेसिंग पाइपलाइनों को अधिक कुशल और विश्वसनीय बनाने के लिए करते हैं।
मूल रूप से, डेल्टा लेक एक ओपन-सोर्स स्टोरेज परत है जो हमारे मौजूदा डेटा स्टोरेज इंफ्रास्ट्रक्चर के शीर्ष पर स्थित है और हमारे डेटा के लिए स्कीमा प्रवर्तन, संस्करण और एसीआईडी (परमाणुता, स्थिरता, अलगाव और स्थायित्व) लेनदेन को सक्षम बनाता है। डेल्टा लेक कई लाभ प्रदान करता है, जैसे डेटा की विशाल मात्रा को प्रबंधित करना, परिवर्तनों को आसानी से वापस लाने में सक्षम होना और कई स्पार्क सत्रों में डेटा स्थिरता प्रदान करना।
यदि आप डेल्टा लेक साक्षात्कार की तैयारी कर रहे हैं, तो आप सही ब्लॉग पर आये हैं। यहां हम सबसे अधिक बार पूछे जाने वाले डेल्टा लेक साक्षात्कार प्रश्नों पर चर्चा करते हैं।
सीखने के मकसद
इस ब्लॉग को ध्यान से पढ़ने के बाद हम नीचे क्या सीखेंगे:
- डेल्टा झील क्या है और तकनीकी युग में इसकी क्या भूमिका है, इसकी समझ।
- अपाचे स्पार्क के साथ इसके संबंध का ज्ञान।
- डेल्टा लेक में डेटा प्रविष्टि या लोडिंग प्रक्रिया की समझ।
- डेल्टा झील के घटकों और उनके ACID-अनुपालक गुणों की समझ।
- अप्सर्ट्स, डेटा पढ़ने के तरीके और डेल्टा लेक में बैच और स्ट्रीमिंग संचालन जैसी अवधारणाओं में अंतर्दृष्टि।
कुल मिलाकर, इस गाइड को पढ़कर, हम डेटा को संग्रहीत करने के लिए डेल्टा झील की व्यापक समझ प्राप्त करेंगे। इस ब्लॉग को पूरा करने के बाद, हमारे पास इस तकनीक का प्रभावी ढंग से उपयोग करने और सामान्य मध्यवर्ती-स्तरीय प्रश्नों का उत्तर देने के लिए पर्याप्त ज्ञान और क्षमता है, और आप अपने डेल्टा लेक साक्षात्कार में सफल हो सकते हैं।
.
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
Q1. डेल्टा झील अन्य लेन-देन भंडारण परतों से कैसे भिन्न है?
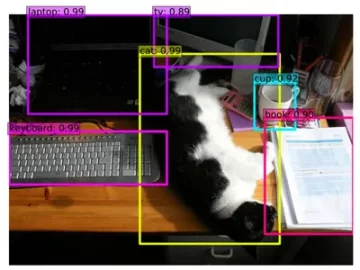
हालाँकि डेल्टा झील भी अन्य लेन-देन परतों द्वारा हल की गई समान चुनौतियों का समाधान करती है, लेकिन ऐसा नहीं है; इसके पास डेटा पारिस्थितिकी तंत्र में व्यापक उपयोग के मामले का कवरेज है, जो इसे प्रसिद्धि प्रदान करता है। डेल्टा लेक डेटा सुरक्षा, विश्वसनीयता और बेहतर प्रदर्शन प्रदान करता है और बैच और स्ट्रीमिंग वर्कलोड के लिए एक एकीकृत ढांचा प्रदान करता है। यह बीआई, एमएल, डेटा साइंस और डेटा ट्रांसफ़ॉर्मेशन पाइपलाइन जैसी विभिन्न डाउनस्ट्रीम गतिविधियों की दक्षता में सुधार करता है।
स्रोत: kpipartners
इसके अलावा, अधिक लाभ प्राप्त करने के लिए हम डेल्टा लेक का भी उपयोग कर सकते हैं डाटब्रिक्स; यह सबसे लोकप्रिय बिजनेस इंटेलिजेंस टूल के लिए तेज़ देशी कनेक्टर्स के साथ व्यापक पारिस्थितिकी तंत्र समर्थन प्रदान करता है, डेल्टा इंजन के साथ बेहतर प्रदर्शन को सक्षम बनाता है, और बेहतर पहुंच नियंत्रण के साथ बेहतर सुरक्षा और शासन प्रदान करता है।
अंत में, आँकड़ों की बात करें तो, डेल्टा झीलें दैनिक आधार पर लगभग 3 पेटाबाइट डेटा ग्रहण करती हैं और 3 वर्षों से अधिक समय से उत्पादन में हैं; हजारों उपयोगकर्ता डेटाब्रिक्स पर डेल्टा लेक का उपयोग कर रहे हैं।
Q2. बताएं कि डेल्टा झीलें किस प्रकार ACID अनुरूप हैं।
डेल्टा झीलें हैं एसिड आज्ञाकारी क्योंकि:
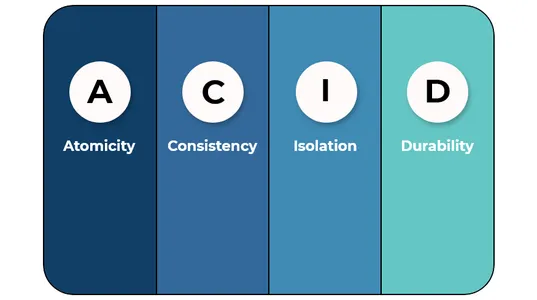
ए(परमाणुता)- डेल्टा लेक परमाणु लेनदेन की पेशकश करता है, जिसका अर्थ है कि डेल्टा तालिका में डेटा में सभी संशोधन या तो सभी प्रतिबद्ध हैं या सभी वापस ले लिए गए हैं।
सी(संगति)- डेल्टा लेक डेटा स्थिरता प्रदान करता है जिसका अर्थ है कि डेटा रीडर हमेशा उसी डेटा को पढ़ेंगे जब लेनदेन शुरू किया गया था।
मैं(आइसोलेशन)- समय यात्रा सुविधा की सहायता से, डेटा लेक अलगाव का समर्थन करता है और उपयोगकर्ताओं को डेटा को किसी भी समय मौजूद रूप में देखने की अनुमति देता है।
डी(स्थायित्व)- डेटा लेक सिस्टम विफलताओं के बावजूद सभी लेन-देन परिवर्तन दिखाकर स्थायित्व का समर्थन करता है।
Q3. अपाचे स्पार्क के साथ डेल्टा झील के संबंध को स्पष्ट करें।
डेल्टा झील के शीर्ष पर बना एक उपकरण है अपाचे स्पार्क और स्पार्क अनुप्रयोगों के लिए भंडारण को प्रबंधित करने और प्रदर्शन को बढ़ाने के लिए एक पथ प्रदान करता है। जब स्पार्क Parquet फ़ाइलों में डेटा संग्रहीत करके डेटा पढ़ता और लिखता है तो डेल्टा लेक प्रदर्शन को बढ़ाता है। यह एक स्तंभ प्रारूप का उपयोग करता है और डेटा स्थिरता सुनिश्चित करने के लिए, यह लेनदेन को प्रबंधित करने और डेटा संशोधनों पर नज़र रखने का एक तरीका प्रदान करता है।
Q4. यदि हम S3 या HDFS पर पैराक्वेट फॉर्मेट में डेटा स्टोर कर सकते हैं तो डेल्टा लेक का उपयोग क्यों करें?
जब हमें बड़े पैमाने पर डेटा प्रोसेसिंग करनी होती है तो डेल्टा लेक पारक्वेट की तुलना में एक अच्छा विकल्प है क्योंकि यह उच्च स्केलेबिलिटी और बेहतर प्रदर्शन प्रदान करता है। इसके अलावा, बिजली कटौती या हार्डवेयर विफलताओं के बावजूद, डेल्टा लेक्स के एसीआईडी-अनुपालक डिजाइन के कारण डेटा भ्रष्टाचार से सुरक्षित रहेगा।
Q5. डेल्टा झील में डेटा आयात करने की प्रक्रिया समझाइए।
हम केवल इसका उपयोग करके डेल्टा लेक में डेटा आयात कर सकते हैं डाटब्रिक्स ऑटो लोडर टूल या SQL के साथ COPY INTO कमांड; यह नई डेटा फ़ाइलों को डेल्टा लेक में स्वचालित रूप से ग्रहण करता है क्योंकि वे हमारे डेटा लेक में आते हैं (यानी, S3 या ADLS पर)। इसके अलावा, हम आवश्यक परिवर्तन करके और परिणाम को डेल्टा लेक में संग्रहीत करके अपने डेटा को बैच-रीड करने के लिए Apache SparkTM का उपयोग कर सकते हैं।
Q6. डेल्टा झील के मुख्य घटकों की व्याख्या करें।
डेल्टा झील में तीन महत्वपूर्ण घटक डेल्टा तालिका, डेल्टा लॉग और डेल्टा कैश शामिल हैं।
डेल्टा तालिका: यह केंद्रीय भंडारण भाग है जो डेल्टा झील के लिए संपूर्ण डेटा रखता है।
डेल्टा लॉग: डेल्टा तालिका में किए गए सभी संशोधनों को ट्रैक या मॉनिटर करने के लिए लेनदेन लॉग का उपयोग किया जाता है।
डेल्टा कैश: यह एक स्तंभ कैश है, और सामान्य कैश की तरह, यह डेटा के वर्तमान संस्करण को डेल्टा तालिका में संग्रहीत करता है।
Q7. हम डेल्टा झील में अपसर्ट कैसे प्रस्तुत करते हैं?
अप्सर्ट दो शब्दों/ऑपरेशंस का एक संयोजन है, अर्थात, अपडेट और इंसर्ट। हम MERGE और INSERT INTO कमांड का उपयोग करके डेल्टा झील में अप्सर्ट निष्पादित कर सकते हैं:
विलय: MERGE कमांड की मदद से, हम दी गई स्थिति के आधार पर किसी भी डेटा को डेल्टा टेबल में अपडेट या सम्मिलित कर सकते हैं। WHERE क्लॉज का उपयोग करते हुए, हम किसी भी कमांड पर एक शर्त लगाते हैं, और यदि शर्त का परिणाम सही होता है, तो अद्यतन कार्रवाई की जाती है; यदि स्थिति का परिणाम गलत होता है, तो INSERT कार्रवाई की जाती है।
सम्मिलित करें:INSERT INTO कमांड की सहायता से, हम डेटा को डेल्टा तालिका में सम्मिलित कर सकते हैं, लेकिन यह कमांड तालिका में केवल नई पंक्तियाँ सम्मिलित करेगा, मौजूदा पंक्तियों में कोई अपडेशन ऑपरेशन नहीं करेगा।
Q8. डेल्टा लेक टेबल से डेटा पढ़ने के लिए उपलब्ध विभिन्न तरीकों की व्याख्या करें।
डेल्टा लेक तालिका से डेटा पढ़ने के लिए, हमारे पास दो उपलब्ध मोड हैं:
1. पूर्ण स्कैन मोड: इस मोड का उपयोग डेल्टा लेक तालिका की संपूर्ण सामग्री को पढ़ने के लिए किया जाता है।
2. वृद्धिशील स्कैन मोड: इस मोड का उपयोग केवल पिछली बार डेल्टा तालिका पढ़ने के बाद से डाले गए या संशोधित डेटा को पढ़ने के लिए किया जाता है।
Q9. डेल्टा झील में बैच और स्ट्रीमिंग संचालन के महत्व को समझाइए।
हम जटिल, निरर्थक प्रणालियों और परिचालन चुनौतियों से बचते हुए, एकल सरलीकृत आर्किटेक्चर पर डेल्टा लेक के साथ बैच और स्ट्रीमिंग ऑपरेशन चला सकते हैं। डेल्टा लेक में, एक टेबल एक बैच टेबल और एक स्ट्रीमिंग स्रोत दोनों है।
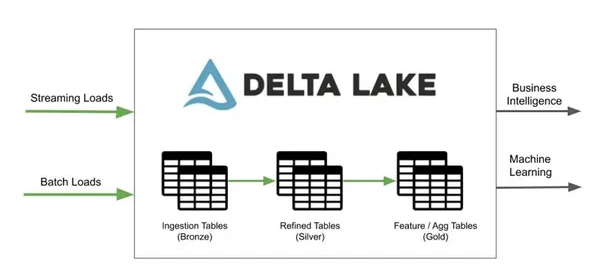
स्रोत: हेवोडाटा.कॉम
महत्व के संदर्भ में, इंटरएक्टिव क्वेरीज़, स्ट्रीमिंग डेटा अंतर्ग्रहण, और बैच ऐतिहासिक बैकफ़िल बॉक्स से बाहर काम करते हैं और सीधे स्पार्क स्ट्रक्चर्ड स्ट्रीमिंग के साथ एकीकृत होते हैं।
Q10. हम डेल्टा लेक में किसी अन्य फ़ाइल सिस्टम से डेटा को तालिका में कैसे लोड कर सकते हैं?
लोड ऑपरेशन करने के लिए, डेल्टा लेक "अप्सर्ट्स" नामक एक प्रक्रिया का समर्थन करता है। यह किसी अन्य मौजूदा फ़ाइल सिस्टम से डेटा को डेल्टा तालिका में लोड करता है। इस प्रक्रिया में, सबसे पहले, हम जाँचते हैं कि समान प्राथमिक कुंजी वाली पंक्ति तालिका में पहले से मौजूद है या नहीं। यदि पंक्ति मौजूद है, तो यह नए डेटा के साथ अद्यतन हो जाती है; अन्यथा, यह तालिका में सम्मिलित हो जाता है।
निष्कर्ष
यह ब्लॉग अक्सर पूछे जाने वाले कुछ डेल्टा लेक साक्षात्कार प्रश्नों को शामिल करता है जो डेटा विज्ञान और बड़े डेटा डेवलपर साक्षात्कार में पूछे जा सकते हैं। संदर्भ के रूप में इन डेल्टा लेक साक्षात्कार प्रश्नों का उपयोग करके, आप अवधारणाओं को बेहतर ढंग से समझ सकते हैं और आगामी साक्षात्कारों के लिए प्रभावी उत्तर तैयार कर सकते हैं। इस डेल्टा लेक ब्लॉग की मुख्य बातें इस प्रकार हैं:-
- डेल्टा लेक एक एसीआईडी-संगत ओपन-सोर्स स्टोरेज परत है जो हमारे मौजूदा डेटा स्टोरेज इंफ्रास्ट्रक्चर के शीर्ष पर स्थित है।
- डेल्टा लेक हमें विशाल डेटा के प्रबंधन और कई स्पार्क सत्रों में डेटा स्थिरता बनाए रखने में सुविधा प्रदान करती है।
- डेल्टा झील विभिन्न लेन-देन भंडारण परतों की तुलना में बेहतर है
- हमने अप्सर्ट्स, डेटा लेक तालिकाओं में डेटा लोड करने का एक तरीका, पर चर्चा की।
- इस ब्लॉग में, हमने टेबल, लॉग और डेल्टा कैश सहित डेल्टा झील के घटकों पर भी चर्चा की।
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/02/ace-your-interview-with-top-10-interview-questions-on-delta-lake/
- 10
- 11
- a
- क्षमता
- योग्य
- पहुँच
- के पार
- कार्य
- गतिविधियों
- बाद
- सब
- पहले ही
- हमेशा
- विश्लेषिकी
- एनालिटिक्स विधा
- और
- अन्य
- जवाब
- अपाचे
- अपाचे स्पार्क
- अनुप्रयोगों
- स्थापत्य
- चारों ओर
- लेख
- स्वत:
- स्वतः
- उपलब्ध
- से बचने
- वापस
- आधार
- क्योंकि
- जा रहा है
- लाभ
- बेहतर
- बड़ा
- बड़ा डेटा
- ब्लॉग
- ब्लॉगथॉन
- मुक्केबाज़ी
- व्यापक
- बनाया गया
- व्यापार
- व्यापारिक सूचना
- कैश
- बुलाया
- सावधानी से
- मामला
- केंद्रीय
- चुनौतियों
- परिवर्तन
- चेक
- चुनाव
- संयोजन
- कैसे
- अ रहे है
- प्रतिबद्ध
- सामान्य
- पूरा
- जटिल
- आज्ञाकारी
- घटकों
- व्यापक
- अवधारणाओं
- निष्कर्ष
- शर्त
- अंतर्वस्तु
- नियंत्रण
- भ्रष्टाचार
- सका
- व्याप्ति
- शामिल किया गया
- वर्तमान
- दैनिक
- तिथि
- डेटा लेक
- डेटा संसाधन
- डेटा विज्ञान
- आँकड़े वाला वैज्ञानिक
- डाटा सुरक्षा
- डेटा भंडारण
- डाटब्रिक्स
- डेल्टा
- मांग
- निर्भर करता है
- डिज़ाइन
- के बावजूद
- डेवलपर
- अलग
- विभिन्न
- सीधे
- विवेक
- चर्चा करना
- चर्चा की
- सहनशीलता
- आसानी
- पारिस्थितिकी तंत्र
- प्रभावी
- प्रभावी रूप से
- दक्षता
- कुशल
- भी
- सक्षम बनाता है
- प्रवर्तन
- इंजन
- बढ़ाता है
- पर्याप्त
- सुनिश्चित
- उत्साही
- संपूर्ण
- युग
- मौजूदा
- मौजूद
- समझाना
- की सुविधा
- प्रसिद्धि
- और तेज
- Feature
- पट्टिका
- फ़ाइलें
- प्रथम
- प्रारूप
- ढांचा
- अक्सर
- से
- पूर्ण
- लाभ
- मिल
- दी
- अच्छा
- शासन
- गाइड
- हार्डवेयर
- मदद
- यहाँ उत्पन्न करें
- हाई
- ऐतिहासिक
- कैसे
- HTTPS
- विशाल
- आयात
- महत्वपूर्ण
- का आयात
- सुधार
- in
- सहित
- इंफ्रास्ट्रक्चर
- एकीकृत
- बुद्धि
- इंटरैक्टिव
- साक्षात्कार
- साक्षात्कार सवाल
- साक्षात्कार
- परिचय
- अलगाव
- IT
- रखना
- कुंजी
- ज्ञान
- झील
- बड़े पैमाने पर
- पिछली बार
- परत
- परतों
- जानें
- भार
- लोडर
- लोड हो रहा है
- भार
- बनाया गया
- मुख्य
- बनाना
- प्रबंधन
- प्रबंध
- प्रबंध
- मीडिया
- मर्ज
- ML
- मोड
- मोड
- संशोधनों
- संशोधित
- मॉनिटर
- अधिक
- अधिक कुशल
- अधिकांश
- सबसे लोकप्रिय
- विभिन्न
- देशी
- निवल परिसंपत्ति मूल्य
- आवश्यक
- नया
- साधारण
- ऑफर
- ONE
- खुला स्रोत
- आपरेशन
- परिचालन
- संचालन
- अन्य
- अन्यथा
- की कटौती
- परिणाम
- स्वामित्व
- भाग
- पथ
- निष्पादन
- प्रदर्शन
- प्रदर्शन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- लोकप्रिय
- बिजली
- तैयारी
- प्राथमिक
- प्रक्रिया
- प्रसंस्करण
- उत्पादन
- गुण
- प्रदान करता है
- प्रदान कर
- प्रकाशित
- रखना
- Q1
- Q2
- Q3
- प्रशन
- पढ़ना
- पाठकों
- पढ़ना
- संबंध
- विश्वसनीयता
- विश्वसनीय
- रहना
- प्रतिक्रिया
- परिणाम
- भूमिका
- रोल
- लुढ़का हुआ
- आरओडब्ल्यू
- रन
- सुरक्षित
- वही
- अनुमापकता
- स्कैन
- विज्ञान
- वैज्ञानिक
- सुरक्षा
- सत्र
- कई
- दिखाया
- महत्व
- सरलीकृत
- के बाद से
- एक
- हल करती है
- कुछ
- स्रोत
- स्पार्क
- एसक्यूएल
- शुरू
- आँकड़े
- भंडारण
- की दुकान
- डेटा स्टोर करें
- भंडार
- स्ट्रीमिंग
- संरचित
- ऐसा
- समर्थन
- समर्थन करता है
- प्रणाली
- सिस्टम
- तालिका
- Takeaways
- तकनीकी
- शर्तों
- RSI
- मर्ज
- लेकिन हाल ही
- हजारों
- तीन
- पहर
- समय यात्रा
- सेवा मेरे
- आज
- साधन
- उपकरण
- ऊपर का
- शीर्ष 10
- ट्रैक
- ट्रांजेक्शन
- लेन-देन संबंधी
- लेनदेन
- परिवर्तन
- यात्रा
- <strong>उद्देश्य</strong>
- समझना
- समझ
- एकीकृत
- अजेय।
- आगामी
- अपडेट
- अद्यतन
- us
- उपयोग
- उदाहरण
- उपयोगकर्ताओं
- विभिन्न
- संस्करण
- देखें
- आयतन
- क्या
- या
- कौन कौन से
- मर्जी
- काम
- व्यायाम
- साल
- आपका
- जेफिरनेट