अमेज़न SageMaker पूरी तरह से प्रबंधित मशीन लर्निंग (एमएल) सेवा है। सेजमेकर के साथ, डेटा वैज्ञानिक और डेवलपर एमएल मॉडल को जल्दी और आसानी से बना सकते हैं और प्रशिक्षित कर सकते हैं, और फिर उन्हें सीधे उत्पादन-तैयार होस्टेड वातावरण में तैनात कर सकते हैं। यह अन्वेषण और विश्लेषण के लिए आपके डेटा स्रोतों तक आसान पहुंच के लिए एक एकीकृत Jupyter संलेखन नोटबुक उदाहरण प्रदान करता है, इसलिए आपको सर्वर प्रबंधित करने की आवश्यकता नहीं है। यह सामान्य भी प्रदान करता है एमएल एल्गोरिदम जो एक वितरित वातावरण में अत्यधिक बड़े डेटा के विरुद्ध कुशलतापूर्वक चलाने के लिए अनुकूलित हैं।
SageMaker रीयल-टाइम अनुमान वर्कलोड के लिए आदर्श है जिसमें रीयल-टाइम, इंटरैक्टिव, कम-विलंबता आवश्यकताएं होती हैं। SageMaker रीयल-टाइम इंट्रेंस के साथ, आप REST एंडपॉइंट्स को तैनात कर सकते हैं जो एक विशिष्ट उदाहरण प्रकार द्वारा एक निश्चित मात्रा में कंप्यूट और मेमोरी के साथ समर्थित हैं। कई ग्राहकों के लिए उत्पादन के मार्ग में एक सैजमेकर रीयल-टाइम एंडपॉइंट को तैनात करना केवल पहला कदम है। हम विलंबता आवश्यकताओं का पालन करते हुए प्रति सेकंड (TPS) लक्ष्य लेनदेन प्राप्त करने के लिए समापन बिंदु के प्रदर्शन को अधिकतम करने में सक्षम होना चाहते हैं। अनुमान के लिए प्रदर्शन अनुकूलन का एक बड़ा हिस्सा यह सुनिश्चित कर रहा है कि आप उचित उदाहरण प्रकार का चयन करें और समापन बिंदु पर वापस गिनती करें।
यह पोस्ट उदाहरणों और आकार की संख्या के लिए सही कॉन्फ़िगरेशन खोजने के लिए एक सैजमेकर एंडपॉइंट लोड परीक्षण के लिए सर्वोत्तम प्रथाओं का वर्णन करती है। यह हमारी विलंबता और टीपीएस आवश्यकताओं को पूरा करने के लिए न्यूनतम प्रावधानित आवृत्ति आवश्यकताओं को समझने में हमारी सहायता कर सकता है। वहां से, हम इसमें गोता लगाते हैं कि आप कैसे सैजमेकर एंडपॉइंट के मेट्रिक्स और प्रदर्शन को ट्रैक और समझ सकते हैं अमेज़ॅन क्लाउडवॉच मैट्रिक्स।
टीपीएस की पहचान करने के लिए हम पहले अपने मॉडल के प्रदर्शन को एक उदाहरण पर बेंचमार्क करते हैं जो हमारी स्वीकार्य विलंबता आवश्यकताओं के अनुसार संभाल सकता है। फिर हम अपने उत्पादन ट्रैफ़िक को संभालने के लिए आवश्यक उदाहरणों की संख्या तय करने के लिए निष्कर्षों को एक्सट्रपलेशन करते हैं। अंत में, हम उत्पादन-स्तर के ट्रैफ़िक का अनुकरण करते हैं और हमारे समापन बिंदु की पुष्टि करने के लिए वास्तविक समय के सैजमेकर समापन बिंदु के लिए लोड परीक्षण सेट करते हैं, उत्पादन-स्तर के भार को संभाल सकते हैं। उदाहरण के लिए कोड का पूरा सेट निम्नलिखित में उपलब्ध है गिटहब भंडार.
समाधान का अवलोकन
इस पद के लिए, हम एक पूर्व प्रशिक्षित तैनात करते हैं हगिंग फेस डिस्टिलबर्ट मॉडल से हगिंग फेस हब. यह मॉडल कई कार्य कर सकता है, लेकिन हम विशेष रूप से भाव विश्लेषण और पाठ वर्गीकरण के लिए एक पेलोड भेजते हैं। इस नमूना पेलोड के साथ, हम 1000 टीपीएस हासिल करने का प्रयास करते हैं।
रीयल-टाइम समापन बिंदु परिनियोजित करें
यह पोस्ट मानती है कि आप मॉडल को परिनियोजित करने के तरीके से परिचित हैं। को देखें अपना समापन बिंदु बनाएं और अपना मॉडल परिनियोजित करें समापन बिंदु को होस्ट करने के पीछे की आंतरिक बातों को समझने के लिए। अभी के लिए, हम जल्दी से इस मॉडल को हगिंग फेस हब में इंगित कर सकते हैं और निम्नलिखित कोड स्निपेट के साथ रीयल-टाइम एंडपॉइंट तैनात कर सकते हैं:
आइए नमूना पेलोड के साथ अपने समापन बिंदु का शीघ्रता से परीक्षण करें जिसे हम लोड परीक्षण के लिए उपयोग करना चाहते हैं:

ध्यान दें कि हम एकल का उपयोग करके समापन बिंदु का समर्थन कर रहे हैं अमेज़ॅन इलास्टिक कम्प्यूट क्लाउड (Amazon EC2) प्रकार ml.m5.12xlarge का उदाहरण, जिसमें 48 vCPU और 192 GiB मेमोरी है। वीसीपीयू की संख्या इस बात का एक अच्छा संकेत है कि उदाहरण किस संगामिति को संभाल सकता है। सामान्य तौर पर, यह सुनिश्चित करने के लिए विभिन्न उदाहरण प्रकारों का परीक्षण करने की अनुशंसा की जाती है कि हमारे पास एक ऐसा उदाहरण है जिसमें संसाधनों का उचित उपयोग किया गया है। SageMaker उदाहरणों की पूरी सूची और वास्तविक समय के अनुमान के लिए उनकी संगत गणना शक्ति को देखने के लिए देखें अमेज़न SageMaker मूल्य निर्धारण.
ट्रैक करने के लिए मेट्रिक्स
इससे पहले कि हम लोड परीक्षण में शामिल हों, यह समझना आवश्यक है कि आपके सैजमेकर एंडपॉइंट के प्रदर्शन ब्रेकडाउन को समझने के लिए कौन से मेट्रिक्स को ट्रैक करना है। CloudWatch प्राथमिक लॉगिंग टूल है जिसका उपयोग SageMaker आपके समापन बिंदु के प्रदर्शन का वर्णन करने वाले विभिन्न मेट्रिक्स को समझने में आपकी मदद करने के लिए करता है। आप अपने एंडपॉइंट इनवोकेशन को डीबग करने के लिए क्लाउडवॉच लॉग का उपयोग कर सकते हैं; आपके अनुमान कोड में मौजूद सभी लॉगिंग और प्रिंट स्टेटमेंट यहां कैप्चर किए गए हैं। अधिक जानकारी के लिए, देखें Amazon CloudWatch कैसे काम करती है.
SageMaker के लिए दो अलग-अलग प्रकार के मेट्रिक्स क्लाउडवॉच कवर हैं: उदाहरण-स्तर और मंगलाचरण मेट्रिक्स।
उदाहरण-स्तर मेट्रिक्स
विचार करने के लिए पैरामीटर का पहला सेट इंस्टेंस-लेवल मेट्रिक्स है: CPUUtilization और MemoryUtilization (जीपीयू-आधारित उदाहरणों के लिए, GPUUtilization)। के लिये CPUUtilization, आप शुरू में CloudWatch में 100% से अधिक प्रतिशत देख सकते हैं। के लिए जानना जरूरी है CPUUtilization, सभी CPU कोर का योग प्रदर्शित किया जा रहा है। उदाहरण के लिए, यदि आपके समापन बिंदु के पीछे के उदाहरण में 4 वीसीपीयू हैं, तो इसका मतलब है कि उपयोग की सीमा 400% तक है। MemoryUtilizationदूसरी ओर, 0-100% की सीमा में है।
विशेष रूप से, आप उपयोग कर सकते हैं CPUUtilization यदि आपके पास पर्याप्त या अधिक मात्रा में हार्डवेयर है, तो इसकी गहन समझ प्राप्त करने के लिए। यदि आपके पास कम उपयोग किया गया उदाहरण (30% से कम) है, तो आप संभावित रूप से अपने उदाहरण प्रकार को कम कर सकते हैं। इसके विपरीत, यदि आप लगभग 80-90% उपयोग कर रहे हैं, तो अधिक कंप्यूट/मेमोरी के साथ एक उदाहरण चुनने में लाभ होगा। हमारे परीक्षणों से, हम आपके हार्डवेयर के लगभग 60-70% उपयोग का सुझाव देते हैं।
मंगलाचरण मेट्रिक्स
जैसा कि नाम से पता चलता है, इनवोकेशन मेट्रिक्स वह जगह है जहां हम आपके एंडपॉइंट पर किसी भी इनवॉइस के एंड-टू-एंड लेटेंसी को ट्रैक कर सकते हैं। आप इनवोकेशन मेट्रिक्स का उपयोग त्रुटि गणना और किस प्रकार की त्रुटियों (5xx, 4xx, और इसी तरह) को कैप्चर करने के लिए कर सकते हैं जो आपके एंडपॉइंट का अनुभव हो सकता है। इससे भी महत्वपूर्ण बात यह है कि आप अपने एंडपॉइंट कॉल्स के लेटेंसी ब्रेकडाउन को समझ सकते हैं। इसके साथ बहुत कुछ पकड़ा जा सकता है ModelLatency और OverheadLatency मेट्रिक्स, जैसा कि निम्नलिखित आरेख में दिखाया गया है।

RSI ModelLatency मीट्रिक उस समय को कैप्चर करता है जो एक SageMaker समापन बिंदु के पीछे मॉडल कंटेनर के भीतर अनुमान लगाता है। ध्यान दें कि मॉडल कंटेनर में कोई कस्टम अनुमान कोड या स्क्रिप्ट भी शामिल है जिसे आपने अनुमान के लिए पारित किया है। यह इकाई एक मंगलाचरण मीट्रिक के रूप में माइक्रोसेकंड में कैप्चर की जाती है, और आम तौर पर आप यह देखने के लिए CloudWatch (p99, p90, और इसी तरह) पर एक प्रतिशतक ग्राफ़ कर सकते हैं कि आप अपने लक्ष्य विलंबता को पूरा कर रहे हैं या नहीं। ध्यान दें कि कई कारक मॉडल और कंटेनर विलंबता को प्रभावित कर सकते हैं, जैसे कि निम्नलिखित:
- कस्टम अनुमान स्क्रिप्ट – चाहे आपने अपने स्वयं के कंटेनर को लागू किया हो या कस्टम अनुमान संचालकों के साथ एक SageMaker-आधारित कंटेनर का उपयोग किया हो, किसी भी ऑपरेशन को पकड़ने के लिए अपनी स्क्रिप्ट को प्रोफाइल करना सबसे अच्छा अभ्यास है जो विशेष रूप से आपके विलंबता में बहुत अधिक समय जोड़ रहा है।
- संचार प्रोटोकॉल - मॉडल कंटेनर के भीतर मॉडल सर्वर से REST बनाम gRPC कनेक्शन पर विचार करें।
- मॉडल ढांचे का अनुकूलन - यह ढांचा विशिष्ट है, उदाहरण के लिए TensorFlow, ऐसे कई पर्यावरण चर हैं जिन्हें आप ट्यून कर सकते हैं जो TF सर्विंग विशिष्ट हैं। यह जांचना सुनिश्चित करें कि आप किस कंटेनर का उपयोग कर रहे हैं और यदि कोई ढांचा-विशिष्ट अनुकूलन है जिसे आप स्क्रिप्ट के भीतर या कंटेनर में इंजेक्ट करने के लिए पर्यावरण चर के रूप में जोड़ सकते हैं।
OverheadLatency SageMaker द्वारा अनुरोध प्राप्त करने के समय से मापा जाता है जब तक कि वह क्लाइंट को प्रतिसाद नहीं देता है, मॉडल विलंबता को घटा देता है। यह हिस्सा काफी हद तक आपके नियंत्रण से बाहर है और SageMaker ओवरहेड्स द्वारा लिए गए समय के अंतर्गत आता है।
पूरी तरह से एंड-टू-एंड विलंबता विभिन्न प्रकार के कारकों पर निर्भर करती है और यह जरूरी नहीं है कि इसका योग हो ModelLatency प्लस OverheadLatency. उदाहरण के लिए, यदि आप ग्राहक बना रहे हैं InvokeEndpoint इंटरनेट पर एपीआई कॉल, क्लाइंट के नजरिए से, एंड-टू-एंड लेटेंसी इंटरनेट + होगी ModelLatency + OverheadLatency. इसलिए, जब एंडपॉइंट को सटीक रूप से बेंचमार्क करने के लिए अपने एंडपॉइंट का लोड परीक्षण करते हैं, तो एंडपॉइंट मेट्रिक्स पर ध्यान केंद्रित करने की सिफारिश की जाती है (ModelLatency, OverheadLatency, तथा InvocationsPerInstance) SageMaker समापन बिंदु को सटीक रूप से बेंचमार्क करने के लिए। एंड-टू-एंड लेटेंसी से संबंधित किसी भी मुद्दे को अलग से अलग किया जा सकता है।
एंड-टू-एंड लेटेंसी पर विचार करने के लिए कुछ प्रश्न:
- वह क्लाइंट कहां है जो आपके समापन बिंदु का आह्वान कर रहा है?
- क्या आपके क्लाइंट और सेजमेकर रनटाइम के बीच कोई मध्यस्थ स्तर हैं?
ऑटो स्केलिंग
हम इस पोस्ट में विशेष रूप से ऑटो स्केलिंग को कवर नहीं करते हैं, लेकिन कार्यभार के आधार पर उदाहरणों की सही संख्या का प्रावधान करने के लिए यह एक महत्वपूर्ण विचार है। आपके ट्रैफ़िक पैटर्न के आधार पर, आप एक संलग्न कर सकते हैं ऑटो स्केलिंग नीति अपने SageMaker समापन बिंदु पर। अलग-अलग स्केलिंग विकल्प हैं, जैसे TargetTrackingScaling, SimpleScaling, तथा StepScaling. यह आपके ट्रैफ़िक पैटर्न के आधार पर आपके एंडपॉइंट को स्वचालित रूप से स्केल इन और आउट करने की अनुमति देता है।
एक सामान्य विकल्प लक्ष्य ट्रैकिंग है, जहां आप क्लाउडवॉच मीट्रिक या कस्टम मीट्रिक निर्दिष्ट कर सकते हैं जिसे आपने परिभाषित किया है और उसके आधार पर स्केल आउट कर सकते हैं। ऑटो स्केलिंग का लगातार उपयोग ट्रैक कर रहा है InvocationsPerInstance मीट्रिक। एक निश्चित टीपीएस पर अड़चन की पहचान करने के बाद, आप अक्सर ट्रैफ़िक के चरम भार को संभालने में सक्षम होने के लिए अधिक संख्या में उदाहरणों को मापने के लिए एक मीट्रिक के रूप में उपयोग कर सकते हैं। ऑटो स्केलिंग SageMaker एंडपॉइंट्स का गहन विश्लेषण प्राप्त करने के लिए, देखें Amazon SageMaker में ऑटोस्केलिंग इंट्रेंस एंडपॉइंट्स को कॉन्फ़िगर करना.
लोड परीक्षण
यद्यपि हम यह प्रदर्शित करने के लिए टिड्डी का उपयोग करते हैं कि हम परीक्षण को बड़े पैमाने पर कैसे लोड कर सकते हैं, यदि आप अपने समापन बिंदु के पीछे के उदाहरण को सही आकार देने का प्रयास कर रहे हैं, सेजमेकर अनुमान अनुशंसाकर्ता अधिक कुशल विकल्प है। तृतीय-पक्ष लोड परीक्षण उपकरण के साथ, आपको विभिन्न उदाहरणों में मैन्युअल रूप से समापन बिंदुओं को परिनियोजित करना होगा। अनुमान अनुशंसाकर्ता के साथ, आप बस उन उदाहरणों की एक सरणी पास कर सकते हैं जिनके खिलाफ आप परीक्षण लोड करना चाहते हैं, और SageMaker घूमेगा नौकरियों इनमें से प्रत्येक उदाहरण के लिए।
टिड्डी
इस उदाहरण के लिए, हम उपयोग करते हैं टिड्डी, एक ओपन-सोर्स लोड टेस्टिंग टूल जिसे आप पायथन का उपयोग करके लागू कर सकते हैं। टिड्डी कई अन्य ओपन-सोर्स लोड टेस्टिंग टूल्स के समान है, लेकिन इसके कुछ विशिष्ट लाभ हैं:
- स्थापित करने के लिए आसान - जैसा कि हम इस पोस्ट में प्रदर्शित करते हैं, हम एक साधारण पायथन स्क्रिप्ट पास करेंगे जिसे आपके विशिष्ट एंडपॉइंट और पेलोड के लिए आसानी से रिफैक्टर किया जा सकता है।
- वितरित और स्केलेबल – टिड्डी घटना आधारित है और इसका उपयोग करती है गीवेंट हुड के नीचे। अत्यधिक समवर्ती कार्यभार का परीक्षण करने और हजारों समवर्ती उपयोगकर्ताओं का अनुकरण करने के लिए यह बहुत उपयोगी है। टिड्डे को चलाने वाली एकल प्रक्रिया से आप उच्च टीपीएस प्राप्त कर सकते हैं, लेकिन इसमें एक भी है वितरित लोड पीढ़ी सुविधा जो आपको कई प्रक्रियाओं और क्लाइंट मशीनों को स्केल करने में सक्षम बनाती है, जैसा कि हम इस पोस्ट में देखेंगे।
- टिड्डी मेट्रिक्स और यूआई - टिड्डे एक मीट्रिक के रूप में एंड-टू-एंड लेटेंसी को भी कैप्चर करता है। यह आपके क्लाउडवॉच मेट्रिक्स को आपके परीक्षणों की पूरी तस्वीर पेंट करने के लिए पूरक करने में मदद कर सकता है। यह सब टिड्डी यूआई में कैप्चर किया गया है, जहां आप समवर्ती उपयोगकर्ताओं, श्रमिकों और अन्य को ट्रैक कर सकते हैं।
टिड्डी को और समझने के लिए, उनकी जाँच करें दस्तावेज़ीकरण.
अमेज़न EC2 सेटअप
आप टिड्डे को आपके अनुकूल किसी भी वातावरण में खड़ा कर सकते हैं। इस पोस्ट के लिए, हमने एक EC2 इंस्टेंस सेट अप किया और अपने परीक्षण करने के लिए टिड्डी को वहां स्थापित किया। हम c5.18xlarge EC2 उदाहरण का उपयोग करते हैं। क्लाइंट-साइड कंप्यूट पावर भी कुछ विचार करने योग्य है। कभी-कभी जब आप क्लाइंट की ओर से कंप्यूट पावर से बाहर हो जाते हैं, तो इसे अक्सर कैप्चर नहीं किया जाता है, और इसे SageMaker समापन बिंदु त्रुटि के रूप में गलत माना जाता है। अपने क्लाइंट को पर्याप्त कंप्यूट पावर वाले स्थान पर रखना महत्वपूर्ण है जो आपके द्वारा परीक्षण किए जा रहे लोड को संभाल सके। हमारे EC2 उदाहरण के लिए, हम उबंटू डीप लर्निंग एएमआई का उपयोग करते हैं, लेकिन आप किसी भी एएमआई का उपयोग तब तक कर सकते हैं जब तक आप मशीन पर टिड्डे को ठीक से सेट कर सकते हैं। अपने EC2 इंस्टेंस को लॉन्च करने और कनेक्ट करने के तरीके को समझने के लिए, ट्यूटोरियल देखें Amazon EC2 Linux इंस्टेंस के साथ आरंभ करें.
Locust UI को पोर्ट 8089 के माध्यम से एक्सेस किया जा सकता है। हम EC2 इंस्टेंस के लिए अपने इनबाउंड सुरक्षा समूह नियमों को समायोजित करके इसे खोल सकते हैं। हम पोर्ट 22 भी खोलते हैं ताकि हम EC2 उदाहरण में SSH कर सकें। स्रोत को उस विशिष्ट IP पते तक सीमित करने पर विचार करें, जिससे आप EC2 उदाहरण तक पहुंच बना रहे हैं।

आपके EC2 इंस्टेंस से कनेक्ट होने के बाद, हम Python वर्चुअल वातावरण सेट अप करते हैं और CLI के माध्यम से ओपन-सोर्स Locust API इंस्टॉल करते हैं:
अब हम अपने एंडपॉइंट की लोड टेस्टिंग के लिए टिड्डे के साथ काम करने के लिए तैयार हैं।
टिड्डी परीक्षण
सभी टिड्डियों के भार परीक्षण के आधार पर आयोजित किए जाते हैं टिड्डी फ़ाइल कि आप प्रदान करते हैं। यह टिड्डी फ़ाइल लोड टेस्ट के लिए एक कार्य को परिभाषित करती है; यहीं पर हम अपने Boto3 को परिभाषित करते हैं इनवोक_एंडपॉइंट एपीआई कॉल। निम्नलिखित कोड देखें:
पूर्ववर्ती कोड में, अपने विशिष्ट मॉडल मंगलाचरण के अनुरूप अपने इनवोक समापन बिंदु कॉल मापदंडों को समायोजित करें। हम उपयोग करते हैं InvokeEndpoint लोकस्ट फ़ाइल में निम्नलिखित कोड का उपयोग करके एपीआई; यह हमारा लोड टेस्ट रन पॉइंट है। हम जिस टिड्डी फ़ाइल का उपयोग कर रहे हैं वह है टिड्डे_स्क्रिप्ट.py.
अब जब हमारे पास अपनी टिड्डी स्क्रिप्ट तैयार है, तो हम यह पता लगाने के लिए अपने एकल उदाहरण के तनाव परीक्षण के लिए वितरित टिड्डी परीक्षण चलाना चाहते हैं कि हमारा उदाहरण कितना ट्रैफ़िक संभाल सकता है।
टिड्डी वितरित मोड एकल-प्रक्रिया टिड्डी परीक्षण की तुलना में थोड़ा अधिक सूक्ष्म है। वितरित मोड में, हमारे पास एक प्राथमिक और कई कर्मचारी हैं। प्राथमिक कार्यकर्ता श्रमिकों को निर्देश देता है कि अनुरोध भेजने वाले समवर्ती उपयोगकर्ताओं को कैसे स्पॉन और नियंत्रित किया जाए। हमारे में वितरित.श स्क्रिप्ट, हम डिफ़ॉल्ट रूप से देखते हैं कि 240 उपयोगकर्ताओं को 60 श्रमिकों में वितरित किया जाएगा। ध्यान दें कि --headless टिड्डी सीएलआई में झंडा टिड्डी की यूआई सुविधा को हटा देता है।
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
हम पहले समापन बिंदु का समर्थन करते हुए एकल उदाहरण पर वितरित परीक्षण चलाते हैं। यहाँ विचार यह है कि हम अपनी विलंबता आवश्यकताओं के भीतर रहते हुए अपने लक्ष्य TPS को प्राप्त करने के लिए आवश्यक आवृत्ति गणना को समझने के लिए एक उदाहरण को पूरी तरह से अधिकतम करना चाहते हैं। ध्यान दें कि यदि आप यूआई का उपयोग करना चाहते हैं, तो इसे बदलें Locust_UI पर्यावरण चर को ट्रू पर सेट करें और अपने EC2 इंस्टेंस का सार्वजनिक IP लें और URL पर पोर्ट 8089 मैप करें।
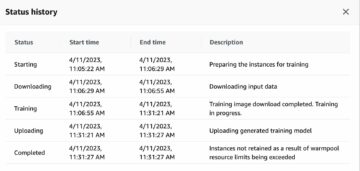
निम्न स्क्रीनशॉट हमारे CloudWatch मेट्रिक्स को दिखाता है।

आखिरकार, हमने देखा कि हालांकि हम शुरू में 200 का टीपीएस प्राप्त करते हैं, हम अपने ईसी5 क्लाइंट-साइड लॉग में 2xx त्रुटियों को नोटिस करना शुरू करते हैं, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
हम विशेष रूप से अपने इंस्टेंस-लेवल मेट्रिक्स को देखकर भी इसे सत्यापित कर सकते हैं CPUUtilization.
 यहाँ हम देखते हैं
यहाँ हम देखते हैं CPUUtilization लगभग 4,800% पर। हमारे एमएल.एम5.12x.बड़े उदाहरण में 48 वीसीपीयू (48 * 100 = 4800~) हैं। यह पूरे उदाहरण को संतृप्त कर रहा है, जो हमारी 5xx त्रुटियों को समझाने में भी मदद करता है। में भी बढ़ोतरी देखने को मिल रही है ModelLatency.
ऐसा लगता है जैसे हमारा एकल उदाहरण गिर रहा है और 200 टीपीएस से अधिक भार को बनाए रखने की गणना नहीं है जिसे हम देख रहे हैं। हमारा लक्ष्य TPS 1000 है, इसलिए आइए अपनी आवृत्ति संख्या को 5 तक बढ़ाने का प्रयास करें। उत्पादन सेटिंग में यह और भी अधिक हो सकता है, क्योंकि हम एक निश्चित बिंदु के बाद 200 TPS पर त्रुटियाँ देख रहे थे।

हम Locust UI और CloudWatch लॉग दोनों में देखते हैं कि हमारे पास लगभग 1000 का TPS है जिसमें पाँच उदाहरण समापन बिंदु का समर्थन करते हैं।

 यदि आप इस हार्डवेयर सेटअप के साथ भी त्रुटियों का अनुभव करने लगते हैं, तो निगरानी करना सुनिश्चित करें
यदि आप इस हार्डवेयर सेटअप के साथ भी त्रुटियों का अनुभव करने लगते हैं, तो निगरानी करना सुनिश्चित करें CPUUtilization अपने एंडपॉइंट होस्टिंग के पीछे की पूरी तस्वीर को समझने के लिए। यह देखने के लिए अपने हार्डवेयर उपयोग को समझना महत्वपूर्ण है कि क्या आपको स्केल अप या डाउन करने की आवश्यकता है। कभी-कभी कंटेनर-स्तर की समस्याएं 5xx त्रुटियों का कारण बनती हैं, लेकिन यदि CPUUtilization कम है, यह इंगित करता है कि यह आपका हार्डवेयर नहीं है, बल्कि कंटेनर या मॉडल स्तर पर कुछ है जो इन मुद्दों का कारण बन सकता है (उदाहरण के लिए, श्रमिकों की संख्या के लिए उचित पर्यावरण चर सेट नहीं है)। दूसरी ओर, यदि आप देखते हैं कि आपका उदाहरण पूरी तरह से संतृप्त हो रहा है, तो यह एक संकेत है कि आपको या तो वर्तमान आवृत्ति बेड़े को बढ़ाने या छोटे बेड़े के साथ एक बड़ा उदाहरण आज़माने की आवश्यकता है।
हालांकि हमने 5 टीपीएस को हैंडल करने के लिए इंस्टेंस काउंट को बढ़ाकर 100 कर दिया है, लेकिन हम देख सकते हैं कि ModelLatency मीट्रिक अभी भी उच्च है। यह उदाहरणों के संतृप्त होने के कारण है। सामान्य तौर पर, हमारा सुझाव है कि उदाहरण के संसाधनों का 60–70% के बीच उपयोग करने का लक्ष्य रखें।
क्लीन अप
लोड परीक्षण के बाद, उन संसाधनों को साफ करना सुनिश्चित करें जिनका आप SageMaker कंसोल या इसके माध्यम से उपयोग नहीं करेंगे delete_endpoint Boto3 एपीआई कॉल। इसके अलावा, अपने EC2 इंस्टेंस या जो भी क्लाइंट सेटअप है उसे बंद करना सुनिश्चित करें ताकि वहां भी कोई और शुल्क न लगे।
सारांश
इस पोस्ट में, हमने बताया कि कैसे आप अपने सैजमेकर रीयल-टाइम एंडपॉइंट का परीक्षण लोड कर सकते हैं। हमने इस बात पर भी चर्चा की कि आपके प्रदर्शन विश्लेषण को समझने के लिए आपके एंडपॉइंट का लोड परीक्षण करते समय आपको किन मेट्रिक्स का मूल्यांकन करना चाहिए। जांच करना सुनिश्चित करें सेजमेकर अनुमान अनुशंसाकर्ता उदाहरण को सही आकार देने और अधिक प्रदर्शन अनुकूलन तकनीकों को और समझने के लिए।
लेखक के बारे में
 मार्क कारपो सेजमेकर सर्विस टीम के साथ एमएल आर्किटेक्ट हैं। वह ग्राहकों को बड़े पैमाने पर एमएल वर्कलोड के डिजाइन, तैनाती और प्रबंधन में मदद करने पर ध्यान केंद्रित करता है। अपने खाली समय में, उन्हें यात्रा करना और नई जगहों की खोज करना पसंद है।
मार्क कारपो सेजमेकर सर्विस टीम के साथ एमएल आर्किटेक्ट हैं। वह ग्राहकों को बड़े पैमाने पर एमएल वर्कलोड के डिजाइन, तैनाती और प्रबंधन में मदद करने पर ध्यान केंद्रित करता है। अपने खाली समय में, उन्हें यात्रा करना और नई जगहों की खोज करना पसंद है।
 राम वेगीराजु सेजमेकर सर्विस टीम के साथ एमएल आर्किटेक्ट हैं। वह Amazon SageMaker पर ग्राहकों को उनके AI/ML समाधान बनाने और उनका अनुकूलन करने में मदद करने पर ध्यान केंद्रित करता है। अपने खाली समय में, उन्हें यात्रा करना और लिखना पसंद है।
राम वेगीराजु सेजमेकर सर्विस टीम के साथ एमएल आर्किटेक्ट हैं। वह Amazon SageMaker पर ग्राहकों को उनके AI/ML समाधान बनाने और उनका अनुकूलन करने में मदद करने पर ध्यान केंद्रित करता है। अपने खाली समय में, उन्हें यात्रा करना और लिखना पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- योग्य
- ऊपर
- स्वीकार्य
- पहुँच
- सुलभ
- तक पहुँचने
- सही रूप में
- पाना
- के पार
- इसके अलावा
- पता
- बाद
- के खिलाफ
- ऐ / एमएल
- एमिंग
- सब
- की अनुमति देता है
- हालांकि
- वीरांगना
- अमेज़ॅन EC2
- अमेज़न SageMaker
- राशि
- विश्लेषण
- और
- एपीआई
- चारों ओर
- ऐरे
- संलग्न करना
- संलेखन
- स्वत:
- स्वतः
- उपलब्ध
- एडब्ल्यूएस
- वापस
- अस्तरवाला
- समर्थन
- आधारित
- क्योंकि
- पीछे
- जा रहा है
- बेंचमार्क
- लाभ
- लाभ
- BEST
- सर्वोत्तम प्रथाओं
- के बीच
- परिवर्तन
- विश्लेषण
- निर्माण
- सी + +
- कॉल
- कॉल
- पा सकते हैं
- कब्जा
- कब्जा
- कुश्ती
- कुछ
- परिवर्तन
- प्रभार
- चेक
- कक्षा
- वर्गीकरण
- ग्राहक
- कोड
- सामान्य
- संगत
- गणना करना
- समवर्ती
- आचरण
- विन्यास
- पुष्टि करें
- जुडिये
- जुड़ा हुआ
- कनेक्शन
- विचार करना
- विचार
- कंसोल
- कंटेनर
- शामिल हैं
- प्रसंग
- नियंत्रण
- इसी
- सका
- आवरण
- शामिल किया गया
- सी पी यू
- बनाना
- महत्वपूर्ण
- वर्तमान
- रिवाज
- ग्राहक
- तिथि
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- और गहरा
- चूक
- परिभाषित करता है
- दिखाना
- निर्भर करता है
- निर्भर करता है
- तैनात
- तैनाती
- वर्णन
- वर्णित
- डिज़ाइन
- डेवलपर्स
- विभिन्न
- सीधे
- चर्चा की
- डिस्प्ले
- वितरित
- नहीं करता है
- dont
- नीचे
- से प्रत्येक
- आसानी
- कुशल
- कुशलता
- भी
- सक्षम बनाता है
- शुरू से अंत तक
- endpoint
- संपूर्ण
- वातावरण
- त्रुटि
- त्रुटियाँ
- आवश्यक
- ईथर (ईटीएच)
- और भी
- उदाहरण
- अपवाद
- निष्पादित
- सामना
- समझाना
- अन्वेषण
- का पता लगाने
- तलाश
- निर्यात
- अत्यंत
- चेहरा
- कारकों
- फॉल्स
- परिचित
- Feature
- कुछ
- पट्टिका
- अंत में
- खोज
- प्रथम
- बेड़ा
- फोकस
- केंद्रित
- निम्नलिखित
- प्रारूप
- ढांचा
- बारंबार
- से
- पूर्ण
- पूरी तरह से
- आगे
- सामान्य जानकारी
- आम तौर पर
- मिल
- मिल रहा
- अच्छा
- ग्राफ
- अधिक से अधिक
- समूह
- समूह की
- संभालना
- खुश
- हार्डवेयर
- मदद
- मदद
- मदद करता है
- यहाँ उत्पन्न करें
- हाई
- अत्यधिक
- हुड
- मेजबान
- मेजबानी
- होस्टिंग
- कैसे
- How To
- एचटीएमएल
- HTTPS
- हब
- विचार
- आदर्श
- पहचान
- पहचान करना
- प्रभाव
- लागू करने के
- कार्यान्वित
- आयात
- महत्वपूर्ण
- in
- शामिल
- बढ़ना
- वृद्धि हुई
- इंगित करता है
- संकेत
- करें-
- शुरू में
- स्थापित
- उदाहरण
- एकीकृत
- इंटरैक्टिव
- इंटरनेट
- का आह्वान
- IP
- आईपी एड्रेस
- पृथक
- मुद्दों
- IT
- खुद
- JSON
- बड़ा
- बड़े पैमाने पर
- बड़ा
- विलंब
- लांच
- परतों
- नेतृत्व
- प्रमुख
- सीख रहा हूँ
- स्तर
- लिनक्स
- सूची
- थोड़ा
- भार
- भार
- स्थान
- लंबा
- देख
- लॉट
- निम्न
- मशीन
- यंत्र अधिगम
- मशीनें
- बनाना
- निर्माण
- प्रबंधन
- कामयाब
- मैन्युअल
- बहुत
- नक्शा
- अधिकतम करने के लिए
- साधन
- मिलना
- बैठक
- याद
- मीट्रिक
- मेट्रिक्स
- हो सकता है
- न्यूनतम
- ML
- मोड
- आदर्श
- मॉडल
- मॉनिटर
- अधिक
- अधिक कुशल
- विभिन्न
- नाम
- लगभग
- अनिवार्य रूप से
- आवश्यकता
- नया
- नोटबुक
- संख्या
- ONE
- खुला
- खुला स्रोत
- संचालन
- इष्टतमीकरण
- ऑप्टिमाइज़ करें
- अनुकूलित
- विकल्प
- ऑप्शंस
- आदेश
- अन्य
- बाहर
- अपना
- रंग
- पैरामीटर
- भाग
- पारित कर दिया
- अतीत
- पथ
- पैटर्न
- पैटर्न उपयोग करें
- शिखर
- निष्पादन
- प्रदर्शन
- परिप्रेक्ष्य
- चुनना
- चित्र
- टुकड़ा
- जगह
- गंतव्य
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्लस
- बिन्दु
- पद
- संभावित
- बिजली
- अभ्यास
- प्रथाओं
- Predictor
- प्राथमिक
- छाप
- समस्याओं
- प्रक्रिया
- प्रक्रियाओं
- उत्पादन
- प्रोफाइल
- उचित
- अच्छी तरह
- प्रदान करना
- प्रदान करता है
- प्रावधान
- सार्वजनिक
- अजगर
- प्रशन
- जल्दी से
- रेंज
- तैयार
- वास्तविक समय
- महसूस करना
- प्राप्त
- की सिफारिश की
- क्षेत्र
- सम्बंधित
- का अनुरोध
- आवश्यकताएँ
- उपयुक्त संसाधन चुनें
- प्रतिक्रिया
- बाकी
- परिणाम
- परिणाम
- रिटर्न
- नियम
- रन
- दौड़ना
- sagemaker
- सेजमेकर अनुमान
- स्केल
- स्केलिंग
- वैज्ञानिकों
- स्कोपिंग
- लिपियों
- दूसरा
- सुरक्षा
- लगता है
- स्व
- भेजना
- भावुकता
- सेवा
- सेवारत
- सेट
- की स्थापना
- सेटिंग्स
- व्यवस्था
- कई
- चाहिए
- दिखाया
- दिखाता है
- हस्ताक्षर
- समान
- सरल
- केवल
- एक
- आकार
- छोटे
- So
- समाधान ढूंढे
- कुछ
- स्रोत
- सूत्रों का कहना है
- स्पोन
- विशिष्ट
- विशेष रूप से
- स्पिन
- मानक
- प्रारंभ
- शुरू
- बयान
- कदम
- फिर भी
- रुकें
- तनाव
- प्रयास करना
- ऐसा
- पर्याप्त
- सूट
- सुपर
- परिशिष्ट
- लेना
- लेता है
- लक्ष्य
- कार्य
- कार्य
- टीम
- तकनीक
- परीक्षण
- परीक्षण चालन
- परीक्षण
- परीक्षण
- पाठ वर्गीकरण
- RSI
- स्रोत
- लेकिन हाल ही
- तीसरे दल
- हजारों
- यहाँ
- पहर
- बार
- सेवा मेरे
- साधन
- उपकरण
- टी पी एस
- ट्रैक
- ट्रैकिंग
- यातायात
- रेलगाड़ी
- लेनदेन
- यात्रा का
- <strong>उद्देश्य</strong>
- ट्यूटोरियल
- प्रकार
- Ubuntu
- ui
- के अंतर्गत
- समझना
- समझ
- इकाई
- यूआरएल
- us
- उपयोग
- उपयोगकर्ताओं
- उपयोग
- उपयोग किया
- इस्तेमाल
- उपयोग
- विविधता
- सत्यापित
- के माध्यम से
- वास्तविक
- क्या
- या
- कौन कौन से
- जब
- मर्जी
- अंदर
- काम
- कामगार
- श्रमिकों
- होगा
- लिख रहे हैं
- आपका
- जेफिरनेट