तंत्रिका नेटवर्क संख्याओं के माध्यम से सीखते हैं, इसलिए प्रत्येक शब्द को एक विशेष शब्द का प्रतिनिधित्व करने के लिए वैक्टर में मैप किया जाएगा। एम्बेडिंग परत को एक लुकअप टेबल के रूप में सोचा जा सकता है जो शब्द एम्बेडिंग को संग्रहीत करता है और सूचकांकों का उपयोग करके उन्हें पुनः प्राप्त करता है।
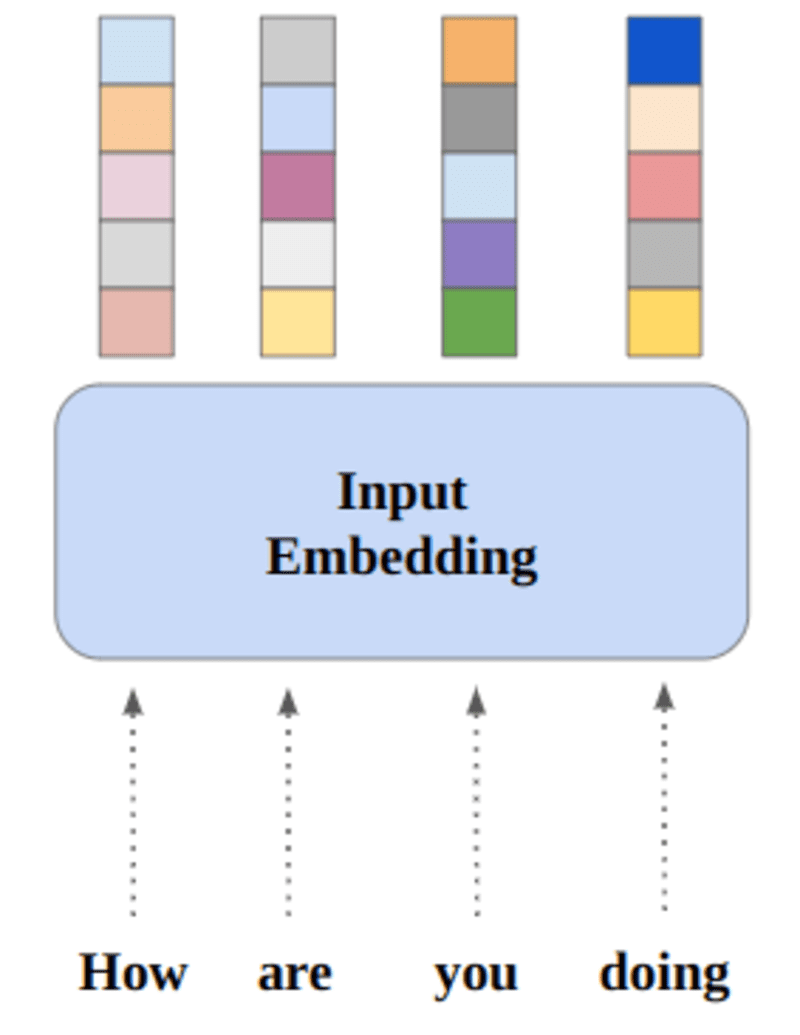
जिन शब्दों का अर्थ समान है वे यूक्लिडियन दूरी/कोसाइन समानता के संदर्भ में करीब होंगे। उदाहरण के लिए, नीचे दिए गए शब्द प्रतिनिधित्व में, "शनिवार", "रविवार", और "सोमवार" एक ही अवधारणा से जुड़े हैं, इसलिए हम देख सकते हैं कि शब्दों का परिणाम समान है।

शब्द की स्थिति का निर्धारण, हमें शब्द की स्थिति निर्धारित करने की आवश्यकता क्यों है? क्योंकि, ट्रांसफार्मर एनकोडर में आवर्ती तंत्रिका नेटवर्क की तरह कोई पुनरावृत्ति नहीं होती है, हमें इनपुट एम्बेडिंग में स्थिति के बारे में कुछ जानकारी जोड़नी होगी। यह स्थितीय एन्कोडिंग का उपयोग करके किया जाता है। पेपर के लेखकों ने किसी शब्द की स्थिति को मॉडल करने के लिए निम्नलिखित कार्यों का उपयोग किया।
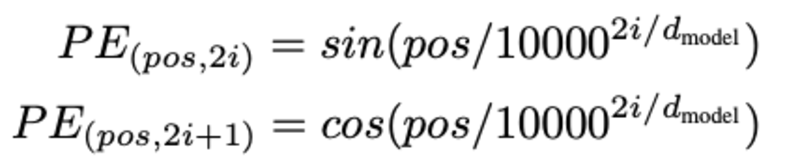
हम स्थितीय एन्कोडिंग को समझाने का प्रयास करेंगे।
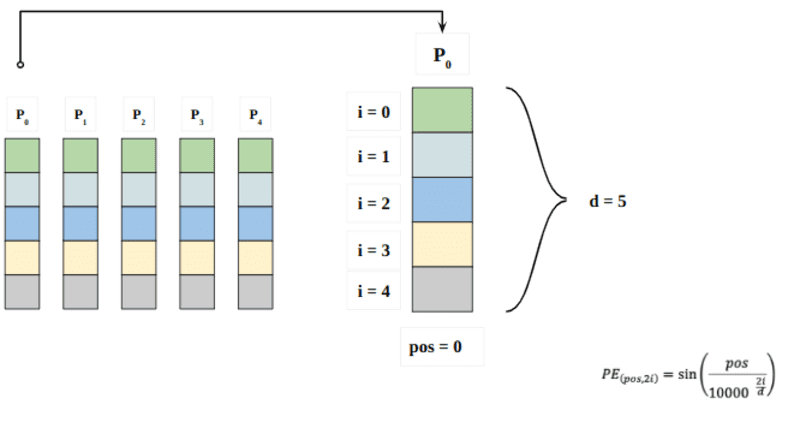
यहां "पॉज़" अनुक्रम में "शब्द" की स्थिति को संदर्भित करता है। P0 पहले शब्द की स्थिति एम्बेडिंग को संदर्भित करता है; "डी" का अर्थ शब्द/टोकन एम्बेडिंग का आकार है। इस उदाहरण में d=5. अंत में, "i" एम्बेडिंग के 5 अलग-अलग आयामों में से प्रत्येक को संदर्भित करता है (यानी 0, 1,2,3,4)
यदि उपरोक्त समीकरण में "i" भिन्न है, तो आपको अलग-अलग आवृत्तियों वाले वक्रों का एक समूह मिलेगा। विभिन्न आवृत्तियों के विरुद्ध स्थिति एम्बेडिंग मानों को पढ़ना, P0 और P4 के लिए अलग-अलग एम्बेडिंग आयामों पर अलग-अलग मान देना।
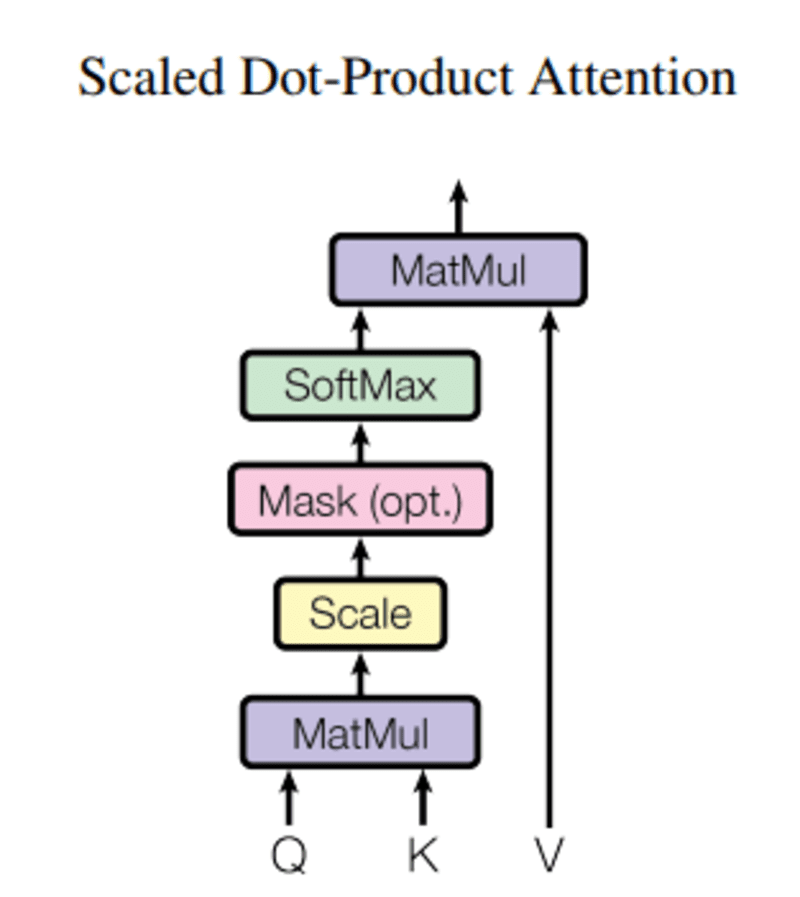
इस में प्रश्न, प्र एक सदिश शब्द का प्रतिनिधित्व करता है, the चाबियाँ के वाक्य में अन्य सभी शब्द हैं, और मूल्य वी शब्द के वेक्टर का प्रतिनिधित्व करता है।
ध्यान का उद्देश्य एक ही व्यक्ति/वस्तु या अवधारणा से संबंधित क्वेरी शब्द की तुलना में मुख्य शब्द के महत्व की गणना करना है।
हमारे मामले में, V, Q के बराबर है।
ध्यान तंत्र हमें वाक्य में शब्द का महत्व बताता है।
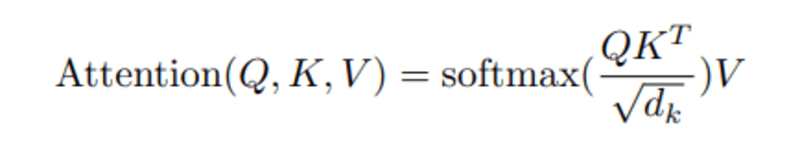
जब हम क्वेरी और कुंजियों के बीच सामान्यीकृत डॉट उत्पाद की गणना करते हैं, तो हमें एक टेंसर मिलता है जो क्वेरी के लिए एक दूसरे शब्द के सापेक्ष महत्व को दर्शाता है।
Q और K.T के बीच डॉट उत्पाद की गणना करते समय, हम यह अनुमान लगाने का प्रयास करते हैं कि वेक्टर (अर्थात् क्वेरी और कुंजियों के बीच के शब्द) कैसे संरेखित होते हैं और वाक्य में प्रत्येक शब्द के लिए एक भार लौटाते हैं।
फिर, हम d_k के परिणाम वर्ग को सामान्यीकृत करते हैं और सॉफ्टमैक्स फ़ंक्शन शर्तों को नियमित करता है और उन्हें 0 और 1 के बीच पुनः स्केल करता है।
अंत में, हम गैर-प्रासंगिक शब्दों के महत्व को कम करने और केवल सबसे महत्वपूर्ण शब्दों पर ध्यान केंद्रित करने के लिए परिणाम (यानी वजन) को मूल्य (यानी सभी शब्दों) से गुणा करते हैं।
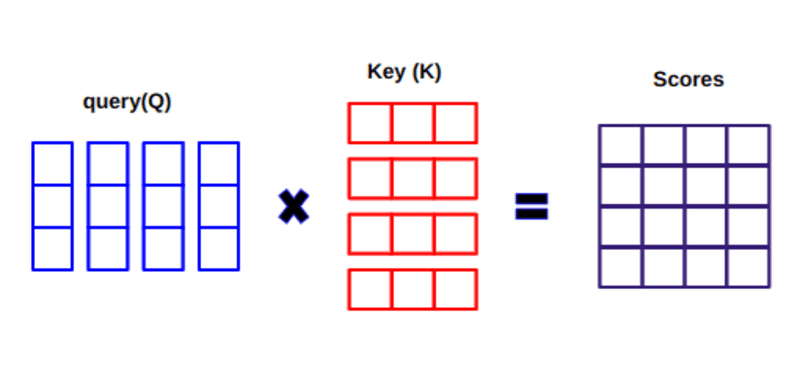
मल्टी-हेडेड अटेंशन आउटपुट वेक्टर को मूल स्थितीय इनपुट एम्बेडिंग में जोड़ा जाता है। इसे अवशिष्ट कनेक्शन/स्किप कनेक्शन कहा जाता है। अवशिष्ट कनेक्शन का आउटपुट परत सामान्यीकरण के माध्यम से जाता है। सामान्यीकृत अवशिष्ट आउटपुट को आगे की प्रक्रिया के लिए बिंदुवार फ़ीड-फ़ॉरवर्ड नेटवर्क के माध्यम से पारित किया जाता है।
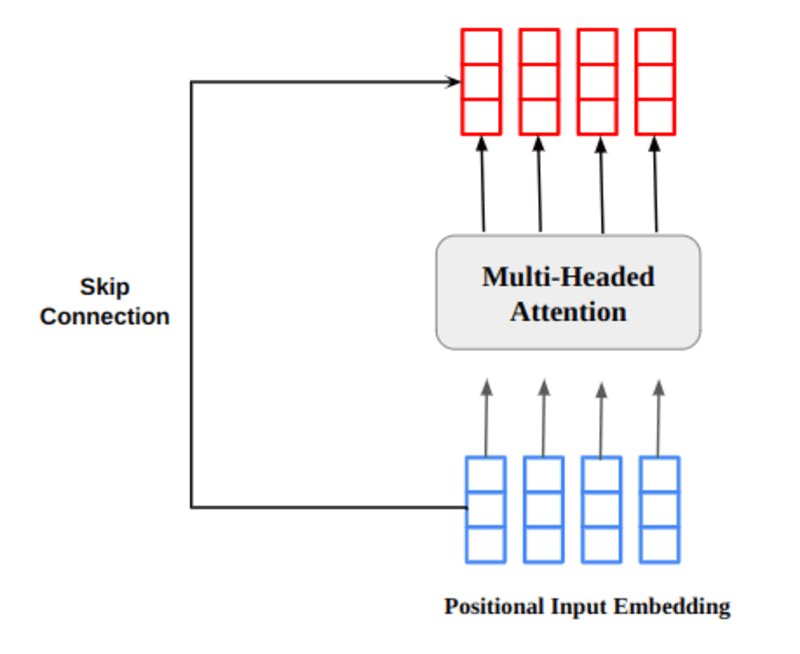
मास्क एक मैट्रिक्स है जिसका आकार ध्यान स्कोर के समान होता है जो 0 और नकारात्मक अनंत के मान से भरा होता है।
मास्क का कारण यह है कि एक बार जब आप मास्क्ड स्कोर का सॉफ्टमैक्स लेते हैं, तो नकारात्मक अनन्तता शून्य हो जाती है, जिससे भविष्य के टोकन के लिए शून्य ध्यान स्कोर रह जाता है।
यह मॉडल को उन शब्दों पर कोई ध्यान केंद्रित नहीं करने के लिए कहता है।
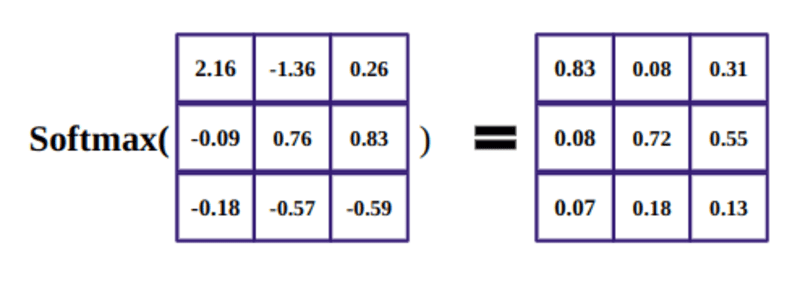
सॉफ्टमैक्स फ़ंक्शन का उद्देश्य वास्तविक संख्याओं (सकारात्मक और नकारात्मक) को पकड़ना और उन्हें सकारात्मक संख्याओं में बदलना है जिनका योग 1 होता है।
रविकुमार नाडुविन PyTorch का उपयोग करके NLP कार्यों को बनाने और समझने में व्यस्त है।
मूल। अनुमति के साथ पुनर्प्रकाशित।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- About
- ऊपर
- जोड़ा
- के खिलाफ
- गठबंधन
- सब
- और
- जुड़े
- ध्यान
- लेखकों
- क्योंकि
- से पहले
- नीचे
- के बीच
- इमारत
- गुच्छा
- बुलाया
- मामला
- समापन
- तुलना
- गणना करना
- कंप्यूटिंग
- संकल्पना
- अवधारणाओं
- संबंध
- निर्धारित करना
- निर्धारित करने
- विभिन्न
- आयाम
- DOT
- से प्रत्येक
- आकलन
- उदाहरण
- समझाना
- भरा हुआ
- अंत में
- प्रथम
- फोकस
- निम्नलिखित
- समारोह
- कार्यों
- आगे
- भविष्य
- मिल
- मिल रहा
- GitHub
- देता है
- देते
- चला जाता है
- पकड़ लेना
- कैसे
- HTTPS
- महत्व
- महत्वपूर्ण
- in
- Indices
- व्यक्ति
- करें-
- निवेश
- केडनगेट्स
- कुंजी
- Instagram पर
- जानना
- परत
- जानें
- छोड़ने
- लिंक्डइन
- लुकअप
- मुखौटा
- मैट्रिक्स
- अर्थ
- साधन
- तंत्र
- आदर्श
- अधिकांश
- आवश्यकता
- नकारात्मक
- नेटवर्क
- नेटवर्क
- तंत्रिका
- तंत्रिका जाल
- NLP
- संख्या
- मूल
- अन्य
- काग़ज़
- विशेष
- पारित कर दिया
- अनुमति
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- स्थिति
- पदों
- सकारात्मक
- प्रसंस्करण
- एस्ट्रो मॉल
- उद्देश्य
- रखना
- pytorch
- पढ़ना
- वास्तविक
- कारण
- पुनरावृत्ति
- को कम करने
- संदर्भित करता है
- सम्बंधित
- प्रतिनिधित्व
- प्रतिनिधित्व
- का प्रतिनिधित्व करता है
- परिणाम
- जिसके परिणामस्वरूप
- वापसी
- वही
- वाक्य
- अनुक्रम
- चाहिए
- समान
- आकार
- So
- कुछ
- चौकोर
- भंडार
- तालिका
- लेना
- कार्य
- बताता है
- शर्तों
- RSI
- विचार
- यहाँ
- सेवा मेरे
- टोकन
- ट्रान्सफ़ॉर्मर
- मोड़
- समझ
- us
- मूल्य
- मान
- भार
- कौन कौन से
- मर्जी
- शब्द
- शब्द
- जेफिरनेट
- शून्य










