परिचय
आज की कारोबारी दुनिया में, ग्राहक सेवा सेवा वफादारी और ग्राहक संतुष्टि सुनिश्चित करने में महत्वपूर्ण भूमिका निभाती है। बातचीत के दौरान व्यक्त की गई भावनाओं को समझने और उनका विश्लेषण करने से ग्राहक सेवा की गुणवत्ता बढ़ाने में मदद मिल सकती है। ग्राहक सेवा ऑडियो डेटा पर भावना विश्लेषण इस लक्ष्य को प्राप्त करने के लिए एक शक्तिशाली उपकरण के रूप में कार्य करता है। इस व्यापक गाइड में, हम ग्राहक सेवा ऑडियो रिकॉर्डिंग पर भावना विश्लेषण करने की जटिलताओं का पता लगाएंगे, कार्यान्वयन के लिए एक विस्तृत रोडमैप प्रदान करेंगे।

सीखने के मकसद
- AWS का उपयोग करने वाला फ्लास्क वेब एप्लिकेशन बनाना सीखें।
- भावना विश्लेषण करने की प्रक्रिया सीखें।
- भावना विश्लेषण में शामिल गणनाएँ सीखें।
- समझें कि आवश्यक डेटा कैसे निकाला जाए और इस विश्लेषण से अंतर्दृष्टि प्राप्त करें।
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
भावना विश्लेषण करने की प्रक्रिया
चरण 1: डेटा तैयार करना
कार्य को समझना: उपलब्ध ग्राहक सेवा ऑडियो पर भावना विश्लेषण करना और परिणामों से अंतर्दृष्टि प्रदान करना।
फ्लास्क एप्लिकेशन बनाना: एक फ्लास्क वेब एप्लिकेशन का निर्माण जो विश्लेषण करने के लिए अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) का उपयोग करता है। यह एप्लिकेशन हमारे प्रोजेक्ट की नींव है।
ऑडियो रिकॉर्डिंग अपलोड करना: विश्लेषण शुरू करने के लिए कॉल रिकॉर्डिंग को AWS S3 बकेट जैसे डेटाबेस में संग्रहीत किया जाना चाहिए।
यूजर इंटरफ़ेस विकसित करना: उपयोगकर्ता के अनुकूल इंटरफ़ेस बनाना बहुत महत्वपूर्ण है। यह सीएसएस, एचटीएमएल और जावास्क्रिप्ट का उपयोग करके हासिल किया गया है। यह इंटरफ़ेस उपयोगकर्ताओं को नाम, दिनांक और समय चुनने में मदद करता है।
इनपुट प्राप्त करना: विश्लेषण प्रक्रिया को अनुकूलित करने के लिए नाम, आरंभ तिथि और समय, और समाप्ति तिथि और समय जैसे उपयोगकर्ता इनपुट कैप्चर किए जाते हैं।
रिकॉर्डिंग लायी जा रही हैं: चयनित समय अंतराल के भीतर S3 बकेट से रिकॉर्डिंग लाने का मार्गदर्शन दिया गया है।
ऑडियो ट्रांसक्रिप्शन: भावना विश्लेषण का हृदय लिखित पाठ में निहित है। यह अनुभाग पता लगाता है कि AWS ट्रांसक्राइब किस प्रकार उपलब्ध रिकॉर्डिंग से बोले गए शब्दों को टेक्स्ट में परिवर्तित करता है
विश्लेषण.
चरण 2: डेटा का विश्लेषण
भावना विश्लेषण करना: इस गाइड के लिए लिखित पाठ का विश्लेषण करना महत्वपूर्ण है। इस चरण का पहला चरण पाठ की बड़ी मात्रा को प्रबंधनीय भागों में विभाजित करना है। अगला कदम प्रत्येक टुकड़े पर भावना विश्लेषण करना है।
सेंटीमेंट मेट्रिक्स की गणना: अगला है सार्थक अंतर्दृष्टि प्राप्त करना। हम सभी सेंटीमेंट स्कोर के औसत की गणना करेंगे और नेट प्रमोटर स्कोर (एनपीएस) की गणना करेंगे। एनपीएस एक महत्वपूर्ण मीट्रिक है जो ग्राहक या कर्मचारी की वफादारी को मापता है। एनपीएस का फॉर्मूला इस प्रकार है:
एनपीएस = ((कुल सकारात्मक/कुल
अभिलेख) – (कुल नकारात्मक/कुल अभिलेख)) * 100
रुझान चार्ट बनाना: इससे समय के साथ रुझानों को समझने में मदद मिलती है। हम आपको विज़ुअल ट्रेंड चार्ट बनाने के लिए मार्गदर्शन करेंगे जो भावना स्कोर की प्रगति को दर्शाते हैं। ये चार्ट सकारात्मक, नकारात्मक, को कवर करेंगे
मिश्रित और तटस्थ मूल्य और एनपीएस।
परिणाम पृष्ठ: हमारे विश्लेषण के अंतिम चरण में, हम एक परिणाम पृष्ठ बनाएंगे जो हमारे विश्लेषण के परिणाम को प्रदर्शित करेगा। यह पेज सेंटीमेंट मेट्रिक्स, ट्रेंड चार्ट और कार्रवाई योग्य अंतर्दृष्टि पर एक रिपोर्ट प्रस्तुत करेगा
ग्राहक सेवा बातचीत से लिया गया।
आइए अब उपरोक्त प्रक्रिया का पालन करते हुए अपना भावना विश्लेषण शुरू करें।
आवश्यक पुस्तकालयों का आयात करना
इस अनुभाग में, हम आवश्यक पायथन लाइब्रेरी आयात करते हैं जो हमारे फ्लास्क एप्लिकेशन के निर्माण, एडब्ल्यूएस सेवाओं के साथ बातचीत करने और विभिन्न अन्य कार्यों को करने के लिए मौलिक हैं।
from flask import Flask, render_template, request
import boto3
import json
import time
import urllib.request
import requests
import os
import pymysql
import re
import sys
import uuid
from datetime import datetime
import json
import csv
from io import StringIO
import urllibऑडियो रिकॉर्डिंग अपलोड करना
हमारी कॉल रिकॉर्डिंग विश्लेषण शुरू करने से पहले, रिकॉर्डिंग आसानी से पहुंच योग्य होनी चाहिए। रिकॉर्डिंग को AWS S3 बकेट जैसे स्थानों पर संग्रहीत करने से आसान पुनर्प्राप्ति में मदद मिलती है। इस अध्ययन में, हमने अपलोड किया है
कर्मचारी और ग्राहक की रिकॉर्डिंग एक ही फ़ोल्डर में अलग-अलग रिकॉर्डिंग के रूप में।
यूजर इंटरफ़ेस बनाना
सीएसएस, एचटीएमएल और जावास्क्रिप्ट का उपयोग करके, इस एप्लिकेशन के लिए एक आकर्षक यूजर इंटरफेस बनाया गया है। यह उपयोगकर्ता को दिए गए विजेट से नाम और दिनांक जैसे इनपुट का चयन करने में मदद करता है।
इनपुट मिल रहे हैं
हम उपयोगकर्ता से जानकारी प्राप्त करने के लिए अपने फ्लास्क एप्लिकेशन का उपयोग करते हैं। ऐसा करने के लिए, हम कर्मचारी के नाम और तिथि सीमा जैसे विवरण इकट्ठा करने के लिए POST पद्धति का उपयोग करते हैं। फिर हम कर्मचारी और ग्राहक दोनों की भावनाओं का विश्लेषण कर सकते हैं। अपने प्रदर्शन में, हम विश्लेषण के लिए कर्मचारी की कॉल रिकॉर्डिंग का उपयोग कर रहे हैं। हम कर्मचारी की कॉल के बजाय उन ग्राहकों की कॉल रिकॉर्डिंग का भी उपयोग कर सकते हैं जो कर्मचारी के साथ बातचीत करते हैं।
इसके लिए हम निम्नलिखित कोड का उपयोग कर सकते हैं।
@app.route('/fetch_data', methods=['POST'])
def fetch_data(): name = request.form.get('name') begin_date = request.form.get('begin_date') begin_time = request.form.get('begin_time') begin_datetime_str = f"{begin_date}T{begin_time}.000Z" print('Begin time:',begin_datetime_str) end_date = request.form.get('end_date') end_time = request.form.get('end_time') end_datetime_str = f"{end_date}T{end_time}.000Z"रिकॉर्डिंग लायी जा रही है
अपना विश्लेषण शुरू करने के लिए, हमें उनके संग्रहीत स्थान से ऑडियो रिकॉर्डिंग प्राप्त करने की आवश्यकता है। चाहे वे AWS S3 बकेट में हों या किसी अन्य डेटाबेस में, हमें इन रिकॉर्डिंग्स को प्राप्त करने के लिए कुछ चरणों का पालन करना होगा, विशेष रूप से एक विशिष्ट समय अवधि के लिए। हमें यह सुनिश्चित करना चाहिए कि हम कर्मचारियों या ग्राहकों की रिकॉर्डिंग वाले सही फ़ोल्डर प्रदान करें।
यह उदाहरण दिखाता है कि S3 बकेट से रिकॉर्डिंग कैसे प्राप्त करें।
# Initialize the S3 client
s3 = boto3.client('s3') # Specify the S3 bucket name and the prefix (directory) where your recordings are stored
bucket_name = 'your-s3-bucket-name'
prefix = 'recordings/' try: response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix) # Iterate through the objects and fetch them for obj in response.get('Contents', []): # Get the key (object path) key = obj['Key'] # Download the object to a local file local_filename = key.split('/')[-1] s3.download_file(bucket_name, key, local_filename) print(f"Downloaded {key} to {local_filename}")
except Exception as e: print(f"An error occurred: {e}")ऑडियो ट्रांसक्रिप्शन
बोले गए शब्दों को ऑडियो से टेक्स्ट में बदलना चुनौतीपूर्ण है। इस कार्य को स्वचालित रूप से करने के लिए हम Amazon Web Services (AWS) ट्रांसक्राइब नामक एक उपयोगी टूल का उपयोग करते हैं। लेकिन उससे पहले, हम उन हिस्सों को हटाकर ऑडियो डेटा को साफ करते हैं जहां कोई बात नहीं कर रहा है और अन्य भाषाओं में बातचीत को अंग्रेजी में बदल देते हैं। इसके अलावा, यदि रिकॉर्डिंग में कई लोग बात कर रहे हैं, तो हमें उनकी आवाज़ों को अलग करना होगा और केवल उस पर ध्यान केंद्रित करना होगा जिसका हम विश्लेषण करना चाहते हैं।
हालाँकि, अनुवाद भाग के काम करने के लिए, हमें अपनी ऑडियो रिकॉर्डिंग्स को एक ऐसे प्रारूप में चाहिए जिसे वेब लिंक के माध्यम से एक्सेस किया जा सके। नीचे दिया गया कोड और स्पष्टीकरण दिखेगा
आप यह सब कैसे काम करता है।
कार्यान्वयन कोड:
transcribe = boto3.client('transcribe', region_name=AWS_REGION_NAME)
def transcribe_audio(audio_uri): job_name_suffix = str(uuid.uuid4()) # Generate a unique job name using timestamp timestamp = str(int(time.time())) transcription_job_name = f'Transcription_{timestamp}_{job_name_suffix}' settings = { 'ShowSpeakerLabels': True, 'MaxSpeakerLabels': 2 } response = transcribe.start_transcription_job( TranscriptionJobName=transcription_job_name, LanguageCode='en-US', Media={'MediaFileUri': audio_uri}, Settings=settings ) transcription_job_name = response['TranscriptionJob']['TranscriptionJobName'] # Wait for the transcription job to complete while True: response = transcribe.get_transcription_job( TranscriptionJobName=transcription_job_name) status = response['TranscriptionJob']['TranscriptionJobStatus'] if status in ['COMPLETED', 'FAILED']: break print("Transcription in progress...") time.sleep(5) transcript_text = None if status == 'COMPLETED': transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri'] with urllib.request.urlopen(transcript_uri) as url: transcript_json = json.loads(url.read().decode()) transcript_text = transcript_json['results']['transcripts'][0]['transcript'] print("Transcription completed successfully!") print('Transribed Text is:', transcript_text) else: print("Transcription job failed.") # Check if there are any transcripts (if empty, skip sentiment analysis) if not transcript_text: print("Transcript is empty. Skipping sentiment analysis.") return None return transcript_text
स्पष्टीकरण:
कार्य आरंभीकरण: AWS ट्रांसक्राइब कार्य आरंभ करने के लिए एक अद्वितीय नाम और भाषा कोड निर्दिष्ट करें (इस मामले में, अंग्रेजी के लिए 'en-US')।
प्रतिलेखन सेटिंग्स: हम ट्रांसक्रिप्शन कार्य के लिए सेटिंग्स परिभाषित करते हैं, जिसमें स्पीकर लेबल दिखाने और स्पीकर लेबल की अधिकतम संख्या निर्दिष्ट करने के विकल्प शामिल हैं (मल्टी-स्पीकर ऑडियो के लिए उपयोगी)।
प्रतिलेखन प्रारंभ करें: कार्य प्रारंभ_ट्रांसक्रिप्शन_जॉब विधि का उपयोग करके प्रारंभ किया जाएगा। यह दिए गए ऑडियो को एसिंक्रोनस रूप से ट्रांसक्राइब करता है।
नौकरी की प्रगति की निगरानी करें: हम समय-समय पर प्रतिलेखन कार्य की स्थिति की जांच करते हैं। यह प्रगति पर हो सकता है, पूर्ण हो सकता है, या विफल हो सकता है। आगे बढ़ने से पहले हम रुकते हैं और पूरा होने की प्रतीक्षा करते हैं।
एक्सेस ट्रांसक्रिप्शन टेक्स्ट: एक बार कार्य सफलतापूर्वक पूरा हो जाने पर, हम दिए गए प्रतिलेख यूआरआई से लिखित पाठ तक पहुँचते हैं। यह पाठ तब भावना विश्लेषण के लिए उपलब्ध है।
भावना विश्लेषण करना
हमारे विश्लेषण कार्य में भावना विश्लेषण एक बड़ी बात है। यह लिखित पाठ में भावनाओं और संदर्भ को समझने के बारे में है जो ऑडियो को शब्दों में बदलने से आता है। बहुत सारे टेक्स्ट को संभालने के लिए, हम उसे छोटे भागों में तोड़ देते हैं। फिर, हम AWS कॉम्प्रिहेंड नामक टूल का उपयोग करते हैं, जो यह पता लगाने में बहुत अच्छा है कि क्या पाठ सकारात्मक, नकारात्मक, तटस्थ लगता है, या यदि यह इन भावनाओं का मिश्रण है।
कार्यान्वयन कोड:
def split_text(text, max_length): # Split the text into chunks of maximum length chunks = [] start = 0 while start < len(text): end = start + max_length chunks.append(text[start:end]) start = end return chunks def perform_sentiment_analysis(transcript): transcript = str(transcript) # Define the maximum length for each chunk max_chunk_length = 5000 # Split the long text into smaller chunks text_chunks = split_text(transcript, max_chunk_length) # Perform sentiment analysis using AWS Comprehend comprehend = boto3.client('comprehend', region_name=AWS_REGION_NAME) sentiment_results = [] confidence_scores = [] # Perform sentiment analysis on each chunk for chunk in text_chunks: response = comprehend.detect_sentiment(Text=chunk, LanguageCode='en') sentiment_results.append(response['Sentiment']) confidence_scores.append(response['SentimentScore']) sentiment_counts = { 'POSITIVE': 0, 'NEGATIVE': 0, 'NEUTRAL': 0, 'MIXED': 0 } # Iterate over sentiment results for each chunk for sentiment in sentiment_results: sentiment_counts[sentiment] += 1 # Determine the majority sentiment aws_sentiment = max(sentiment_counts, key=sentiment_counts.get) # Calculate average confidence scores average_neutral_confidence = round( sum(score['Neutral'] for score in confidence_scores) / len(confidence_scores), 4) average_mixed_confidence = round( sum(score['Mixed'] for score in confidence_scores) / len(confidence_scores), 4) average_positive_confidence = round( sum(score['Positive'] for score in confidence_scores) / len(confidence_scores), 4) average_negative_confidence = round( sum(score['Negative'] for score in confidence_scores) / len(confidence_scores), 4) return { 'aws_sentiment': aws_sentiment, 'average_positive_confidence': average_positive_confidence, 'average_negative_confidence': average_negative_confidence, 'average_neutral_confidence': average_neutral_confidence, 'average_mixed_confidence': average_mixed_confidence }स्पष्टीकरण:
पाठ को तोड़ना: बहुत सारे पाठ को अधिक आसानी से संभालने के लिए, हम प्रतिलेख को छोटे भागों में विभाजित करते हैं जिन्हें हम बेहतर ढंग से प्रबंधित कर सकते हैं। फिर हम एक-एक करके इन छोटे हिस्सों पर गौर करेंगे।
भावनाओं को समझना: हम इन छोटे भागों में से प्रत्येक में भावनाओं (जैसे सकारात्मक, नकारात्मक, तटस्थ, मिश्रित) का पता लगाने के लिए एडब्ल्यूएस कॉम्प्रिहेंड का उपयोग करते हैं। यह हमें यह भी बताता है कि वह इन भावनाओं के बारे में कितना आश्वस्त है।
भावनाओं का हिसाब रखना: हम नोट करते हैं कि इन सभी छोटे भागों में प्रत्येक भावना कितनी बार आती है। इससे हमें यह जानने में मदद मिलती है कि अधिकांश लोग समग्र रूप से क्या महसूस कर रहे हैं।
आत्मविश्वास ढूँढना: हम औसत स्कोर की गणना करते हैं कि AWS कॉम्प्रिहेंड उन भावनाओं के बारे में कितना आश्वस्त है जो उसे मिलती है। इससे हमें यह देखने में मदद मिलती है कि सिस्टम अपने परिणामों को लेकर कितना आश्वस्त है।
सेंटीमेंट मेट्रिक्स की गणना
पाठ के अलग-अलग हिस्सों पर भावना विश्लेषण करने के बाद, हम सार्थक भावना मेट्रिक्स की गणना करने के लिए आगे बढ़ते हैं। ये मेट्रिक्स समग्र भावना और ग्राहक या कर्मचारी धारणा में अंतर्दृष्टि प्रदान करते हैं।
कार्यान्वयन कोड:
result = perform_sentiment_analysis(transcript)
def sentiment_metrics(result): # Initialize variables to store cumulative scores total_sentiment_value = '' total_positive_score = 0 total_negative_score = 0 total_neutral_score = 0 total_mixed_score = 0 # Counters for each sentiment category count_positive = 0 count_negative = 0 count_neutral = 0 count_mixed = 0 # Process the fetched data and calculate metrics for record in result: sentiment_value = aws_sentiment positive_score = average_positive_confidence negative_score = average_negative_confidence neutral_score = average_neutral_confidence mixed_score = average_mixed_confidence # Count occurrences of each sentiment category if sentiment_value == 'POSITIVE': count_positive += 1 elif sentiment_value == 'NEGATIVE': count_negative += 1 elif sentiment_value == 'NEUTRAL': count_neutral += 1 elif sentiment_value == 'MIXED': count_mixed += 1 # Calculate cumulative scores total_sentiment_value = max(sentiment_value) total_positive_score += positive_score total_negative_score += negative_score total_neutral_score += neutral_score total_mixed_score += mixed_score # Calculate averages total_records = len(result) overall_sentiment = total_sentiment_value average_positive = total_positive_score / total_records if total_records > 0 else 0 average_negative = total_negative_score / total_records if total_records > 0 else 0 average_neutral = total_neutral_score / total_records if total_records > 0 else 0 average_mixed = total_mixed_score / total_records if total_records > 0 else 0 # Calculate NPS only if there are records if total_records > 0: NPS = ((count_positive/total_records) - (count_negative/total_records)) * 100 NPS_formatted = "{:.2f}%".format(NPS) else: NPS_formatted = "N/A" # Create a dictionary to store the calculated metrics metrics = { "total_records": total_records, "overall_sentiment": overall_sentiment, "average_positive": average_positive, "average_negative": average_negative, "average_neutral": average_neutral, "average_mixed": average_mixed, "count_positive": count_positive, "count_negative": count_negative, "count_neutral": count_neutral, "count_mixed": count_mixed, "NPS": NPS_formatted } return metrics
स्पष्टीकरण:
संचयी स्कोर: हम सकारात्मक, नकारात्मक, तटस्थ और मिश्रित भावनाओं के कुल स्कोर पर नज़र रखने के लिए कुछ चर स्थापित करके शुरुआत करते हैं। जैसे-जैसे हम सभी विश्लेषित भागों को पढ़ेंगे, ये अंक जुड़ते जाएंगे।
भावनाओं की गिनती: हम गिनते रहते हैं कि प्रत्येक प्रकार की भावना कितनी बार प्रकट होती है, ठीक वैसे ही जैसे हमने तब किया था जब हम पहले भावनाओं का पता लगा रहे थे।
औसत ढूँढना: अधिकांश लोग क्या महसूस कर रहे हैं उसके आधार पर हम भावनाओं और समग्र मनोदशा के औसत स्कोर का पता लगाते हैं। हम नेट प्रमोटर स्कोर (एनपीएस) नामक एक विशेष सूत्र का उपयोग करके भी गणना करते हैं जिसका हमने पहले उल्लेख किया था।
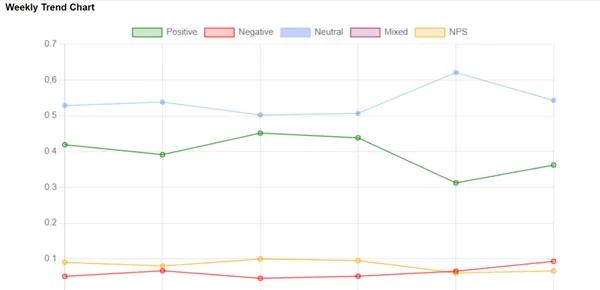
ट्रेंड चार्ट बनाना
यह देखने के लिए कि समय के साथ भावनाएँ कैसे बदलती हैं, हम ट्रेंड चार्ट बनाते हैं। ये उन चित्रों की तरह हैं जो स्पष्ट रूप से दर्शाते हैं कि भावनाएँ बढ़ रही हैं या घट रही हैं। वे कंपनियों को किसी भी पैटर्न की पहचान करने में मदद करते हैं और डेटा के आधार पर स्मार्ट निर्णय लेने के लिए इस जानकारी का उपयोग करते हैं।
प्रक्रिया:
डेटा एकत्रीकरण: हम प्रत्येक सप्ताह के लिए औसत भावना स्कोर और एनपीएस मूल्यों की गणना करते हैं। ये मान शब्दकोश प्रारूप में सहेजे गए हैं और ट्रेंड चार्ट बनाने के लिए उपयोग किए जाएंगे।
सप्ताह संख्या की गणना: प्रत्येक ऑडियो रिकॉर्डिंग के लिए, हम वह सप्ताह निर्धारित करते हैं जिसमें यह घटित हुई थी। डेटा को साप्ताहिक रुझानों में व्यवस्थित करने के लिए यह महत्वपूर्ण है।
औसत की गणना: हम प्रत्येक सप्ताह के लिए औसत भावना स्कोर और एनपीएस मूल्यों की गणना करते हैं। इन मूल्यों का उपयोग ट्रेंड चार्ट बनाने के लिए किया जाएगा।
भावना विश्लेषण का परिणाम
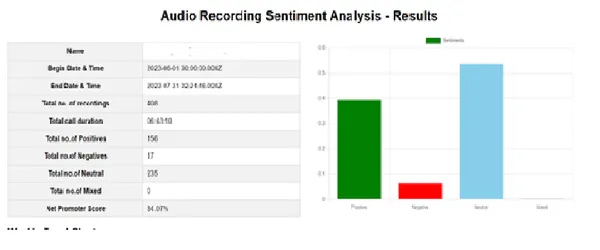
विश्लेषण के बाद, हम परिणाम पृष्ठ बना सकते हैं, जैसा कि नीचे दिखाया गया है। यह पृष्ठ समग्र रिपोर्ट देता है, जैसे रिकॉर्डिंग की कुल संख्या, कुल कॉल अवधि, आदि। साथ ही, यह औसत स्कोर और रुझानों का प्रतिनिधित्व करने वाले चार्ट भी प्रदर्शित करता है। हम नकारात्मक स्कोर और उनके विवरण भी अलग से कैप्चर कर सकते हैं।
निष्कर्ष
आज की तेज़-तर्रार व्यापारिक दुनिया में, यह समझना महत्वपूर्ण है कि ग्राहक क्या महसूस करते हैं। यह ग्राहकों को खुश करने के लिए एक गुप्त उपकरण की तरह है। ऑडियो कॉल रिकॉर्डिंग का भावना विश्लेषण ग्राहक इंटरैक्शन में अंतर्दृष्टि प्राप्त करने में मदद करता है। इस लेख में ऑडियो को टेक्स्ट में बदलने से लेकर ट्रेंड चार्ट बनाने तक भावना विश्लेषण करने के चरणों के बारे में बताया गया है।
सबसे पहले, हमने इन ऑडियो ट्रांसक्रिप्शन से बोले गए शब्दों को पढ़ने योग्य टेक्स्ट में बदलने में मदद के लिए AWS ट्रांसक्राइब जैसे टूल का उपयोग किया। भावना विश्लेषण ने तब भावनाओं और संदर्भ का आकलन किया और उन्हें सकारात्मक, नकारात्मक, तटस्थ या मिश्रित भावनाओं के रूप में वर्गीकृत किया।
सेंटीमेंट मेट्रिक्स में स्कोर एकत्र करना और नेट प्रमोटर स्कोर (एनपीएस) की गणना करना शामिल था, जिसे मुद्दों की पहचान करने, प्रगति की निगरानी करने और वफादारी में सुधार करने के लिए चार्ट और ग्राफ़ पर प्लॉट किया जा सकता था।
चाबी छीन लेना
- भावनाओं का विश्लेषण व्यवसायों के लिए फीडबैक को समझने, सुधार करने और ग्राहक अनुभव प्रदान करने का एक शक्तिशाली उपकरण है।
- समय के साथ भावनाओं में बदलाव को ट्रेंड चार्ट द्वारा देखा जा सकता है, जिससे संगठनों को डेटा-संचालित निर्णय लेने में मदद मिलती है।
आम सवाल-जवाब
उत्तर. भावना विश्लेषण एनएलपी तकनीक का उपयोग करके पाठ डेटा के भावनात्मक स्वर और संदर्भ को निर्धारित करता है। ग्राहक सेवा में, इस प्रकार का विश्लेषण संगठनों को यह समझने में मदद करता है कि ग्राहक उनके उत्पादों या सेवाओं के बारे में कैसा महसूस करते हैं। यह महत्वपूर्ण है क्योंकि यह ग्राहकों की संतुष्टि में कार्रवाई योग्य अंतर्दृष्टि प्रदान करता है और व्यवसायों को ग्राहक प्रतिक्रिया के आधार पर अपनी सेवाओं में सुधार करने में सक्षम बनाता है। इससे यह देखने में मदद मिलती है कि कर्मचारी ग्राहकों के साथ कैसे बातचीत कर रहे हैं।
उत्तर. ऑडियो ट्रांसक्रिप्शन ऑडियो में बोले गए शब्दों को लिखित पाठ में परिवर्तित करने की प्रक्रिया है। भावना विश्लेषण में, यह पहला काम है जो हम करते हैं। कॉल में लोग जो कहते हैं उसे कंप्यूटर द्वारा समझे जा सकने वाले शब्दों में बदलने के लिए हम AWS ट्रांसक्राइब जैसे टूल का उपयोग करते हैं। उसके बाद, हम शब्दों को देख सकते हैं कि लोग कैसा महसूस करते हैं।
उत्तर. भावनाओं को आमतौर पर चार मुख्य श्रेणियों में वर्गीकृत किया जाता है: सकारात्मक, नकारात्मक, तटस्थ और मिश्रित। "सकारात्मक" एक सकारात्मक भावना या संतुष्टि को दर्शाता है। "नकारात्मक" असंतोष या नकारात्मक भावना को दर्शाता है। "तटस्थ" का अर्थ है सकारात्मक और नकारात्मक भावनाओं का अभाव, और "मिश्रित" का अर्थ है पाठ में सकारात्मक और नकारात्मक भावनाओं का मिश्रण।
उत्तर. एनपीएस एक संख्या है जो हमें बताती है कि लोग किसी कंपनी या सेवा को कितना पसंद करते हैं। हम इसे पसंद करने वाले लोगों का प्रतिशत (सकारात्मक) लेकर और इसे पसंद नहीं करने वाले (नकारात्मक) लोगों का प्रतिशत घटाकर पाते हैं। सूत्र इस तरह दिखता है: एनपीएस = ((सकारात्मक लोग / कुल लोग) - (नकारात्मक लोग / कुल लोग)) * 100। उच्च एनपीएस का मतलब है अधिक खुश ग्राहक।
उत्तर. ट्रेंड चार्ट चित्रों की तरह होते हैं जो दिखाते हैं कि समय के साथ लोगों की भावनाएँ कैसे बदलती हैं। वे कंपनियों को यह देखने में मदद करते हैं कि ग्राहक अधिक खुश हो रहे हैं या दुखी। कंपनियां पैटर्न खोजने के लिए ट्रेंड चार्ट का उपयोग कर सकती हैं और देख सकती हैं कि उनके सुधार काम करते हैं या नहीं। ट्रेंड चार्ट कंपनियों को स्मार्ट विकल्प चुनने में मदद करते हैं और ग्राहकों को खुश करने के लिए उनके परिवर्तनों की जांच कर सकते हैं।
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/09/decoding-customer-care-sentiments-comprehensive-audio-analysis-guide/
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 10
- 100
- 11
- 12
- 14
- 5000
- a
- About
- ऊपर
- पहुँच
- पहुँचा
- सुलभ
- हासिल
- प्राप्त करने
- कार्य करता है
- जोड़ना
- बाद
- एकत्रीकरण
- सब
- भी
- वीरांगना
- अमेज़ॅन वेब सेवा
- अमेज़ॅन वेब सेवा (एडब्ल्यूएस)
- an
- विश्लेषण
- विश्लेषिकी
- एनालिटिक्स विधा
- विश्लेषण करें
- विश्लेषण किया
- का विश्लेषण
- और
- कोई
- आकर्षक
- आवेदन
- हैं
- लेख
- AS
- पूछा
- आकलन किया
- At
- ऑडियो
- स्वतः
- उपलब्ध
- औसत
- एडब्ल्यूएस
- आधारित
- BE
- क्योंकि
- से पहले
- शुरू करना
- शुरू
- नीचे
- लाभ
- बेहतर
- बड़ा
- ब्लॉगथॉन
- के छात्रों
- टूटना
- निर्माण
- इमारत
- व्यापार
- व्यवसायों
- लेकिन
- by
- गणना
- परिकलित
- परिकलन
- गणना
- कॉल
- बुलाया
- कॉल
- कर सकते हैं
- कब्जा
- पर कब्जा कर लिया
- कौन
- मामला
- श्रेणियाँ
- वर्ग
- कुछ
- चुनौतीपूर्ण
- परिवर्तन
- परिवर्तन
- बदलना
- चार्ट
- चेक
- विकल्प
- ग्राहक
- कोड
- आता है
- कंपनियों
- कंपनी
- पूरा
- पूरा
- समापन
- जटिलताओं
- समझना
- व्यापक
- कंप्यूटर
- का आयोजन
- आत्मविश्वास
- आश्वस्त
- अंतर्वस्तु
- प्रसंग
- बातचीत
- बदलना
- परिवर्तित
- सका
- काउंटरों
- गिनती
- आवरण
- बनाना
- बनाया
- बनाना
- महत्वपूर्ण
- महत्वपूर्ण
- सीएसएस
- ग्राहक
- ग्राहक संतुष्टि
- ग्राहक
- अनुकूलित
- तिथि
- डेटा विज्ञान
- डेटा पर ही आधारित
- डाटाबेस
- तारीख
- खजूर
- दिनांक और समय
- सौदा
- निर्णय
- डिकोडिंग
- परिभाषित
- उद्धार
- विस्तृत
- विवरण
- निर्धारित करना
- निर्धारित
- डीआईडी
- विवेक
- प्रदर्शित करता है
- विभाजित
- do
- कर देता है
- dont
- नीचे
- डाउनलोड
- अवधि
- दौरान
- e
- से प्रत्येक
- पूर्व
- आसानी
- आसान
- अन्य
- भावना
- भावुक
- भावनाओं
- कर्मचारी
- कर्मचारियों
- खाली
- सक्षम बनाता है
- समाप्त
- अंग्रेज़ी
- बढ़ाना
- सुनिश्चित
- त्रुटि
- विशेष रूप से
- आवश्यक
- आदि
- ईथर (ईटीएच)
- उदाहरण
- सिवाय
- अपवाद
- अनुभव
- समझाया
- स्पष्टीकरण
- का पता लगाने
- पड़ताल
- व्यक्त
- उद्धरण
- विफल रहे
- तेजी से रफ़्तार
- प्रतिक्रिया
- लग रहा है
- भावनाओं
- लाए गए
- आकृति
- पट्टिका
- अंतिम
- खोज
- पाता
- प्रथम
- फोकस
- का पालन करें
- निम्नलिखित
- इस प्रकार है
- के लिए
- प्रपत्र
- प्रारूप
- सूत्र
- बुनियाद
- चार
- से
- मौलिक
- लाभ
- इकट्ठा
- उत्पन्न
- मिल
- मिल रहा
- दी
- देता है
- Go
- लक्ष्य
- रेखांकन
- महान
- मार्गदर्शन
- गाइड
- संभालना
- सुविधाजनक
- खुश
- खुश
- है
- होने
- दिल
- मदद
- मदद
- मदद करता है
- उच्चतर
- कैसे
- How To
- एचटीएमएल
- HTTPS
- पहचान करना
- if
- कार्यान्वयन
- आयात
- महत्वपूर्ण
- में सुधार
- सुधार
- in
- अन्य में
- सहित
- बढ़ती
- इंगित करता है
- व्यक्ति
- करें-
- आरंभ
- निविष्टियां
- अंतर्दृष्टि
- बजाय
- बातचीत
- बातचीत
- बातचीत
- इंटरफेस
- में
- शामिल
- मुद्दों
- IT
- आईटी इस
- जावास्क्रिप्ट
- काम
- JSON
- केवल
- रखना
- कुंजी
- जानना
- लेबल
- रंग
- भाषा
- भाषाऐं
- बड़ा
- लंबाई
- पुस्तकालयों
- झूठ
- पसंद
- LINK
- स्थानीय
- स्थान
- स्थानों
- लंबा
- देखिए
- लग रहा है
- लॉट
- बहुत सारे
- निष्ठा
- मुख्य
- बहुमत
- बनाना
- प्रबंधन
- प्रबंधनीय
- बहुत
- अधिकतम
- सार्थक
- साधन
- मीडिया
- उल्लेख किया
- तरीका
- मीट्रिक
- मेट्रिक्स
- मिश्रण
- मिश्रित
- मिश्रण
- मॉनिटर
- मनोदशा
- अधिक
- अधिकांश
- बहुत
- विभिन्न
- चाहिए
- नाम
- नामों
- आवश्यक
- आवश्यकता
- नकारात्मक
- नकारात्मक
- जाल
- तटस्थ
- अगला
- NLP
- नहीं
- कोई नहीं
- नोट
- संख्या
- वस्तु
- वस्तुओं
- हुआ
- of
- प्रस्ताव
- on
- एक बार
- ONE
- केवल
- ऑप्शंस
- or
- संगठनों
- आयोजन
- OS
- अन्य
- हमारी
- आउट
- के ऊपर
- कुल
- स्वामित्व
- पृष्ठ
- भाग
- भागों
- पथ
- पैटर्न उपयोग करें
- विराम
- स्टाफ़
- लोगों की
- प्रतिशतता
- धारणा
- निष्पादन
- प्रदर्शन
- अवधि
- चरण
- तस्वीरें
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- निभाता
- सकारात्मक
- पद
- शक्तिशाली
- तैयारी
- वर्तमान
- प्रक्रिया
- बढ़ना
- प्रक्रिया
- उत्पाद
- प्रगति
- परियोजना
- प्रदान करना
- बशर्ते
- प्रदान करता है
- प्रदान कर
- प्रकाशित
- अजगर
- गुणवत्ता
- परिमाणित करता है
- RE
- रिकॉर्ड
- रिकॉर्डिंग
- अभिलेख
- दर्शाता है
- हटाने
- रिपोर्ट
- प्रतिनिधित्व
- का प्रतिनिधित्व
- का अनुरोध
- अनुरोधों
- अपेक्षित
- प्रतिक्रिया
- परिणाम
- परिणाम
- वापसी
- सही
- रोडमैप
- भूमिका
- संतोष
- बचाया
- कहना
- कहते हैं
- विज्ञान
- स्कोर
- स्कोर
- गुप्त
- अनुभाग
- देखना
- लगता है
- चयनित
- भावुकता
- भावनाओं
- अलग
- अलग
- सेवा
- सेवाएँ
- की स्थापना
- सेटिंग्स
- चाहिए
- दिखाना
- दिखाया
- दिखाता है
- एक
- छोटे
- स्मार्ट
- कुछ
- कुछ
- वक्ता
- विशेष
- विशिष्ट
- विभाजित
- बात
- प्रारंभ
- शुरू
- शुरुआत में
- स्थिति
- कदम
- कदम
- की दुकान
- संग्रहित
- अध्ययन
- सफलतापूर्वक
- ऐसा
- निश्चित
- प्रणाली
- ले जा
- में बात कर
- कार्य
- कार्य
- बताता है
- टेक्स्ट
- कि
- RSI
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- बात
- इसका
- यहाँ
- पहर
- बार
- टाइमस्टैम्प
- सेवा मेरे
- आज का दि
- स्वर
- साधन
- उपकरण
- कुल
- ट्रैक
- प्रतिलेख
- अनुवाद करें
- प्रवृत्ति
- रुझान
- <strong>उद्देश्य</strong>
- कोशिश
- मोड़
- टाइप
- आम तौर पर
- समझना
- समझ
- अद्वितीय
- अपलोड की गई
- यूआरआइ
- यूआरएल
- us
- उपयोग
- प्रयुक्त
- उपयोगी
- उपयोगकर्ता
- यूजर इंटरफेस
- उपयोगकर्ता के अनुकूल
- उपयोगकर्ताओं
- का उपयोग करता है
- का उपयोग
- आमतौर पर
- मान
- चर
- विभिन्न
- बहुत
- नेत्रहीन
- आवाज
- संस्करणों
- प्रतीक्षा
- करना चाहते हैं
- था
- we
- वेब
- वेब एप्लीकेशन
- वेब सेवाओं
- webp
- सप्ताह
- साप्ताहिक
- थे
- क्या
- एचएमबी क्या है?
- कब
- या
- कौन कौन से
- जब
- कौन
- क्यों
- मर्जी
- साथ में
- अंदर
- शब्द
- काम
- कार्य
- विश्व
- लिखा हुआ
- इसलिए आप
- आपका
- जेफिरनेट







