इंटेलिजेंट डॉक्यूमेंट प्रोसेसिंग (आईडीपी) एक ऐसी तकनीक है जो टेक्स्ट, छवियों और वीडियो सहित उच्च मात्रा में असंरचित डेटा के प्रसंस्करण को स्वचालित करती है। आईडीपी लागत, त्रुटियों, कम सटीकता और सीमित स्केलेबिलिटी जैसी चुनौतियों का समाधान करके मैन्युअल तरीकों और विरासत ऑप्टिकल कैरेक्टर रिकग्निशन (ओसीआर) सिस्टम पर महत्वपूर्ण सुधार प्रदान करता है, जिससे अंततः संगठनों और हितधारकों के लिए बेहतर परिणाम मिलते हैं।
प्राकृतिक भाषा प्रसंस्करण (एनएलपी) आईडीपी में हाल के विकासों में से एक है जिसने सटीकता और उपयोगकर्ता अनुभव में सुधार किया है। हालाँकि, इन प्रगतियों के बावजूद, अभी भी चुनौतियों पर काबू पाना बाकी है। उदाहरण के लिए, कई आईडीपी सिस्टम उपयोगकर्ता के अनुकूल या उपयोगकर्ताओं द्वारा आसानी से अपनाने के लिए पर्याप्त सहज नहीं हैं। इसके अतिरिक्त, कई मौजूदा समाधानों में निरंतर सुधार और अपडेट के माध्यम से डेटा स्रोतों, विनियमों और उपयोगकर्ता आवश्यकताओं में बदलाव के अनुकूल होने की क्षमता का अभाव है।
संवाद के माध्यम से आईडीपी को बढ़ाने में आईडीपी प्रणालियों में संवाद क्षमताओं को शामिल करना शामिल है। उपयोगकर्ताओं को अधिक प्राकृतिक और सहज तरीके से आईडीपी सिस्टम के साथ बातचीत करने में सक्षम बनाकर, बहु-राउंड संवाद के माध्यम से गलत जानकारी को समायोजित करके या कार्य स्वचालन के साथ लापता जानकारी को जोड़कर, ये सिस्टम अधिक कुशल, सटीक और उपयोगकर्ता के अनुकूल बन सकते हैं।
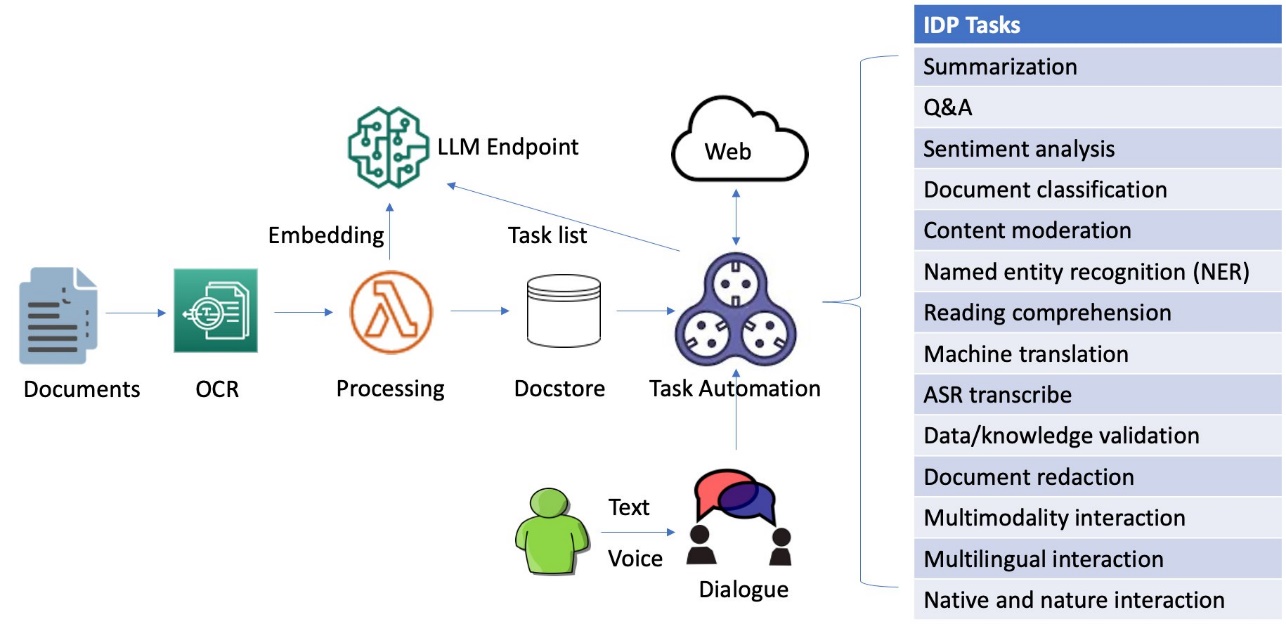
इस पोस्ट में, हम आईडीपी के लिए एक अभिनव दृष्टिकोण का पता लगाते हैं जो संवाद-निर्देशित क्वेरी समाधान का उपयोग करता है अमेज़ॅन फाउंडेशन मॉडल और सेजमेकर जम्पस्टार्ट.
समाधान अवलोकन
यह अभिनव समाधान सूचना निष्कर्षण के लिए ओसीआर, संवाद और स्वायत्त कार्य के लिए एक स्थानीय तैनात बड़े भाषा मॉडल (एलएलएम), उप-कार्यों को एम्बेड करने के लिए वेक्टरडीबी, और व्यवसायों की प्रक्रिया और दस्तावेज़ का विश्लेषण करने के तरीके को बदलने के लिए बाहरी डेटा स्रोतों के साथ एकीकरण के लिए लैंगचेन-आधारित कार्य स्वचालन को जोड़ता है। प्रसंग. जेनेरिक एआई प्रौद्योगिकियों का उपयोग करके, संगठन आईडीपी वर्कफ़्लो को सुव्यवस्थित कर सकते हैं, उपयोगकर्ता अनुभव को बढ़ा सकते हैं और समग्र दक्षता को बढ़ा सकते हैं।
निम्नलिखित वीडियो प्रसंस्करण द्वारा संवाद-निर्देशित आईडीपी प्रणाली पर प्रकाश डालता है एक लेख द्वारा लिखित फेडरल रिजर्व बोर्ड ऑफ गवर्नर्समार्च 2023 में सिलिकॉन वैली बैंक के पतन पर चर्चा।
सिस्टम छवियों, बड़े पीडीएफ और दस्तावेजों को अन्य प्रारूप में संसाधित करने और इंटरैक्टिव टेक्स्ट या वॉयस इनपुट के माध्यम से सामग्री से प्राप्त प्रश्नों का उत्तर देने में सक्षम है। यदि किसी उपयोगकर्ता को दस्तावेज़ के संदर्भ से परे पूछताछ करने की आवश्यकता है, तो संवाद-निर्देशित आईडीपी टेक्स्ट प्रॉम्प्ट से कार्यों की एक श्रृंखला बना सकता है और फिर प्रासंगिक उत्तरों के लिए बाहरी और अद्यतित डेटा स्रोतों का संदर्भ दे सकता है। इसके अतिरिक्त, यह बहु-दौर की बातचीत का समर्थन करता है और बहुभाषी आदान-प्रदान को समायोजित करता है, सभी को संवाद के माध्यम से प्रबंधित किया जाता है।
अमेज़ॅन फाउंडेशन मॉडल का उपयोग करके अपना खुद का एलएलएम तैनात करें
जेनेरिक एआई में सबसे आशाजनक विकासों में से एक एलएलएम का संवाद प्रणालियों में एकीकरण है, जो अधिक सहज और सार्थक आदान-प्रदान के लिए नए रास्ते खोलता है। एलएलएम एक प्रकार का एआई मॉडल है जिसे मानव-जैसे पाठ को समझने और उत्पन्न करने के लिए डिज़ाइन किया गया है। इन मॉडलों को भारी मात्रा में डेटा पर प्रशिक्षित किया जाता है और इसमें अरबों पैरामीटर शामिल होते हैं, जो उन्हें उच्च सटीकता के साथ विभिन्न भाषा-संबंधी कार्यों को करने की अनुमति देते हैं। यह परिवर्तनकारी दृष्टिकोण मानव अंतर्ज्ञान और मशीन बुद्धि के बीच की खाई को पाटते हुए अधिक प्राकृतिक और उत्पादक बातचीत की सुविधा प्रदान करता है। स्थानीय एलएलएम परिनियोजन का एक प्रमुख लाभ तीसरे पक्ष के एपीआई के बाहर डेटा सबमिट किए बिना डेटा सुरक्षा बढ़ाने की क्षमता में निहित है। इसके अलावा, आप अपने चुने हुए एलएलएम को डोमेन-विशिष्ट डेटा के साथ बेहतर बना सकते हैं, जिसके परिणामस्वरूप अधिक सटीक, संदर्भ-जागरूक और प्राकृतिक भाषा समझने का अनुभव प्राप्त होगा।
एआई2 लैब्स की जुरासिक-21 श्रृंखला, जो निर्देश-ट्यून किए गए 178-बिलियन-पैरामीटर जुरासिक-1 एलएलएम पर आधारित है, अमेज़ॅन फाउंडेशन मॉडल के अभिन्न अंग हैं जो इसके माध्यम से उपलब्ध हैं। अमेज़ॅन बेडरॉक. जुरासिक-2 निर्देश को विशेष रूप से उन संकेतों को प्रबंधित करने के लिए प्रशिक्षित किया गया था जो केवल निर्देश हैं, जिन्हें के रूप में जाना जाता है शून्य-गोली, उदाहरणों की आवश्यकता के बिना, या कुछ शॉट. यह विधि एलएलएम के साथ सबसे सहज इंटरैक्शन प्रदान करती है, और यह किसी भी उदाहरण की आवश्यकता के बिना आपके कार्य के लिए आदर्श आउटपुट को समझने का सबसे अच्छा तरीका है। आप पूर्व-प्रशिक्षित J2-जंबो-इंस्ट्रक्ट, या AWS मार्केटप्लेस पर उपलब्ध अन्य जुरासिक-2 मॉडल को अपने स्वयं के वर्चुअल प्राइवेट क्लाउड (VPC) में कुशलतापूर्वक तैनात कर सकते हैं। अमेज़न SageMaker। निम्नलिखित कोड देखें:
import ai21, sagemaker # Define endpoint name
endpoint_name = "sagemaker-soln-j2-jumbo-instruct"
# Define real-time inference instance type. You can also choose g5.48xlarge or p4de.24xlarge instance types
# Please request P instance quota increase via <a href="https://console.aws.amazon.com/servicequotas/home" target="_blank" rel="noopener">Service Quotas console</a> or your account manager
real_time_inference_instance_type = ("ml.p4d.24xlarge") # Create a Sgaemkaer endpoint then deploy a pre-trained J2-jumbo-instruct-v1 model from AWS Market Place.
model_package_arn = "arn:aws:sagemaker:us-east-1:865070037744:model-package/j2-jumbo-instruct-v1-0-20-8b2be365d1883a15b7d78da7217cdeab"
model = ModelPackage(
role=sagemaker.get_execution_role(),
model_package_arn=model_package_arn,
sagemaker_session=sagemaker.Session()
) # Deploy the model
predictor = model.deploy(1, real_time_inference_instance_type,
endpoint_name=endpoint_name,
model_data_download_timeout=3600,
container_startup_health_check_timeout=600,
)आपके स्वयं के वीपीसी के भीतर समापन बिंदु को सफलतापूर्वक तैनात किए जाने के बाद, आप यह सत्यापित करने के लिए एक अनुमान कार्य शुरू कर सकते हैं कि तैनात एलएलएम प्रत्याशित रूप से कार्य कर रहा है:
response_jumbo_instruct = ai21.Completion.execute(
sm_endpoint=endpoint_name,
prompt="Explain deep learning algorithms to 8th graders",
numResults=1,
maxTokens=100,
temperature=0.01 #subject to reduce “hallucination” by using common words.
)दस्तावेज़ प्रसंस्करण, एम्बेडिंग और अनुक्रमणिका
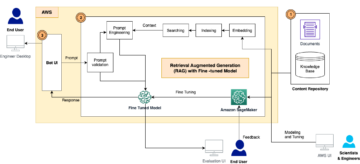
हम एक कुशल और प्रभावी खोज सूचकांक बनाने की प्रक्रिया में गहराई से उतरते हैं, जो दस्तावेज़ प्रसंस्करण को निर्देशित करने के लिए बुद्धिमान और उत्तरदायी संवादों की नींव बनाता है। आरंभ करने के लिए, हम OCR का उपयोग करके विभिन्न प्रारूपों के दस्तावेज़ों को पाठ्य सामग्री में परिवर्तित करते हैं अमेज़न टेक्सट्रेक. फिर हम इस सामग्री को पढ़ते हैं और इसे छोटे टुकड़ों में विभाजित करते हैं, आदर्श रूप से प्रत्येक एक वाक्य के आकार का होता है। यह विस्तृत दृष्टिकोण अधिक सटीक और प्रासंगिक खोज परिणामों की अनुमति देता है, क्योंकि यह संपूर्ण दस्तावेज़ के बजाय किसी पृष्ठ के अलग-अलग खंडों के विरुद्ध प्रश्नों के बेहतर मिलान को सक्षम बनाता है। प्रक्रिया को और बेहतर बनाने के लिए, हम एम्बेडिंग जैसे का उपयोग करते हैं हगिंग फेस से वाक्य ट्रांसफार्मर लाइब्रेरी, जो प्रत्येक वाक्य का वेक्टर प्रतिनिधित्व (एन्कोडिंग) उत्पन्न करता है। ये वेक्टर मूल पाठ के एक संक्षिप्त और सार्थक प्रतिनिधित्व के रूप में कार्य करते हैं, जो कुशल और सटीक अर्थ मिलान कार्यक्षमता को सक्षम करते हैं। अंत में, हम समानता खोज के लिए इन वैक्टरों को एक वेक्टर डेटाबेस में संग्रहीत करते हैं। तकनीकों का यह संयोजन एक नवीन दस्तावेज़ प्रसंस्करण ढांचे के लिए आधार तैयार करता है जो उपयोगकर्ताओं के लिए सटीक और सहज परिणाम प्रदान करता है। निम्नलिखित चित्र इस वर्कफ़्लो को दर्शाता है।

ओसीआर समाधान में एक महत्वपूर्ण तत्व के रूप में कार्य करता है, जो स्कैन किए गए दस्तावेज़ों या चित्रों से पाठ की पुनर्प्राप्ति की अनुमति देता है। हम पीडीएफ या छवि फ़ाइलों से टेक्स्ट निकालने के लिए अमेज़ॅन टेक्स्टट्रैक्ट का उपयोग कर सकते हैं। यह प्रबंधित ओसीआर सेवा बहु-पृष्ठ दस्तावेज़ों में पाठ की पहचान और जांच करने में सक्षम है, जिसमें पीडीएफ, जेपीईजी या टीआईएफएफ प्रारूप जैसे चालान और रसीदें शामिल हैं। बहु-पृष्ठ दस्तावेज़ों का प्रसंस्करण अतुल्यकालिक रूप से होता है, जिससे यह व्यापक, बहु-पृष्ठ दस्तावेज़ों को संभालने के लिए लाभप्रद हो जाता है। निम्नलिखित कोड देखें:
def pdf_2_text(input_pdf_file, history):
history = history or []
key = 'input-pdf-files/{}'.format(os.path.basename(input_pdf_file.name))
try:
response = s3_client.upload_file(input_pdf_file.name, default_bucket_name, key)
except ClientError as e:
print("Error uploading file to S3:", e)
s3_object = {'Bucket': default_bucket_name, 'Name': key}
response = textract_client.start_document_analysis(
DocumentLocation={'S3Object': s3_object},
FeatureTypes=['TABLES', 'FORMS']
)
job_id = response['JobId']
while True:
response = textract_client.get_document_analysis(JobId=job_id)
status = response['JobStatus']
if status in ['SUCCEEDED', 'FAILED']:
break
time.sleep(5) if status == 'SUCCEEDED':
with open(output_file, 'w') as output_file_io:
for block in response['Blocks']:
if block['BlockType'] in ['LINE', 'WORD']:
output_file_io.write(block['Text'] + 'n')
with open(output_file, "r") as file:
first_512_chars = file.read(512).replace("n", "").replace("r", "").replace("[", "").replace("]", "") + " [...]"
history.append(("Document conversion", first_512_chars))
return history, historyबड़े दस्तावेज़ों के साथ काम करते समय, आसान प्रसंस्करण के लिए उन्हें अधिक प्रबंधनीय टुकड़ों में तोड़ना महत्वपूर्ण है। लैंगचेन के मामले में, इसका मतलब है कि प्रत्येक दस्तावेज़ को छोटे खंडों में विभाजित करना, जैसे कि 1,000 टोकन के ओवरलैप के साथ प्रति टुकड़ा 100 टोकन। इसे सुचारू रूप से प्राप्त करने के लिए, लैंगचेन इस उद्देश्य के लिए विशेष रूप से डिज़ाइन किए गए विशेष स्प्लिटर्स का उपयोग करता है:
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
separator = 'n'
overlap_count = 100. # overlap count between the splits
chunk_size = 1000 # Use a fixed split unit size
loader = TextLoader(output_file)
documents = loader.load()
text_splitter = CharacterTextSplitter(separator=separator, chunk_overlap=overlap_count, chunk_size=chunk_size, length_function=len)
texts = text_splitter.split_documents(documents)एम्बेडिंग के लिए आवश्यक अवधि दस्तावेज़ के आकार के आधार पर भिन्न हो सकती है; उदाहरण के लिए, इसे ख़त्म होने में लगभग 10 मिनट लग सकते हैं। हालाँकि किसी एक दस्तावेज़ के साथ काम करते समय यह समय सीमा पर्याप्त नहीं हो सकती है, लेकिन केवल सैकड़ों मेगाबाइट के विपरीत सैकड़ों गीगाबाइट को अनुक्रमित करते समय प्रभाव अधिक उल्लेखनीय हो जाते हैं। एम्बेडिंग प्रक्रिया में तेजी लाने के लिए, आप शार्डिंग लागू कर सकते हैं, जो समानांतरीकरण को सक्षम बनाता है और परिणामस्वरूप दक्षता बढ़ाता है:
from langchain.document_loaders import ReadTheDocsLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from sentence_transformers import SentenceTransformer
import numpy as np
import ray
from embeddings import LocalHuggingFaceEmbeddings # Define number of splits
db_shards = 10 loader = TextLoader(output_file)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 100,
length_function = len,
) @ray.remote()
def process_shard(shard):
embeddings = LocalHuggingFaceEmbeddings('multi-qa-mpnet-base-dot-v1')
result = Chroma.from_documents(shard, embeddings)
return result # Read the doc content and split them into chunks.
chunks = text_splitter.create_documents([doc.page_content for doc in documents], metadatas=[doc.metadata for doc in documents])
# Embed the doc chunks into vectors.
shards = np.array_split(chunks, db_shards)
futures = [process_shard.remote(shards[i]) for i in range(db_shards)]
texts = ray.get(futures)अब जब हमने छोटे खंड प्राप्त कर लिए हैं, तो हम उन्हें एम्बेडिंग के माध्यम से वैक्टर के रूप में प्रस्तुत करना जारी रख सकते हैं। एंबेडिंग, एनएलपी में एक तकनीक, टेक्स्ट प्रॉम्प्ट का वेक्टर प्रतिनिधित्व उत्पन्न करती है। एंबेडिंग क्लास विभिन्न एंबेडिंग प्रदाताओं के साथ बातचीत के लिए एक एकीकृत इंटरफ़ेस के रूप में कार्य करता है, जैसे SageMaker, जुटना, गले लगना, तथा OpenAI, जो विभिन्न प्लेटफार्मों पर प्रक्रिया को सुव्यवस्थित करता है। ये एम्बेडिंग विचारों के संख्यात्मक चित्रण हैं जो संख्या अनुक्रमों में परिवर्तित हो जाते हैं, जिससे कंप्यूटर इन विचारों के बीच के संबंधों को आसानी से समझ पाते हैं। निम्नलिखित कोड देखें:
# Choose a SageMaker deployed local LLM endpoint for embedding
llm_embeddings = SagemakerEndpointEmbeddings(
endpoint_name=<endpoint_name>,
region_name=<region>,
content_handler=content_handler
)एम्बेडिंग बनाने के बाद, हमें वैक्टर को स्टोर करने के लिए एक वेक्टरस्टोर का उपयोग करने की आवश्यकता है। वेक्टरस्टोर्स जैसे क्रोमा बाद में उच्च-आयामी स्थानों में त्वरित खोजों के लिए अनुक्रमणिका बनाने के लिए विशेष रूप से इंजीनियर किए गए हैं, जो उन्हें हमारे उद्देश्यों के लिए पूरी तरह उपयुक्त बनाते हैं। एक विकल्प के रूप में, आप उपयोग कर सकते हैं FAISS, वैक्टर संग्रहीत करने के लिए एक ओपन-सोर्स वेक्टर क्लस्टरिंग समाधान। निम्नलिखित कोड देखें:
from langchain.vectorstores import Chroma
# Store vectors in Chroma vectorDB
docsearch_chroma = Chroma.from_documents(texts, llm_embeddings)
# Alternatively you can choose FAISS vectorstore
from langchain.vectorstores import FAISS
docsearch_faiss = FAISS.from_documents(texts, llm_embeddings)आप भी उपयोग कर सकते हैं अमेज़ॅन केंद्र उद्यम सामग्री को अनुक्रमित करने और सटीक उत्तर देने के लिए। पूरी तरह से प्रबंधित सेवा के रूप में, अमेज़ॅन केंद्र उन्नत दस्तावेज़ और पैसेज रैंकिंग के लिए उपयोग में आसान सिमेंटिक खोज सुविधाएँ प्रदान करता है। अमेज़ॅन केंद्र में उच्च सटीकता वाली खोज के साथ, आप अपने पेलोड की गुणवत्ता को अनुकूलित करने के लिए सबसे प्रासंगिक सामग्री और दस्तावेज़ प्राप्त कर सकते हैं। इसके परिणामस्वरूप पारंपरिक या कीवर्ड-केंद्रित खोज विधियों की तुलना में बेहतर एलएलएम प्रतिक्रियाएं मिलती हैं। अधिक जानकारी के लिए देखें Amazon Kendra, LangChain और बड़े भाषा मॉडल का उपयोग करके एंटरप्राइज़ डेटा पर उच्च-सटीकता जनरेटिव AI अनुप्रयोगों का त्वरित निर्माण करें.
इंटरएक्टिव बहुभाषी आवाज इनपुट
दस्तावेज़ खोज में इंटरैक्टिव वॉयस इनपुट को शामिल करने से असंख्य लाभ मिलते हैं जो उपयोगकर्ता अनुभव को बढ़ाते हैं। उपयोगकर्ताओं को खोज शब्दों को मौखिक रूप से स्पष्ट करने में सक्षम बनाने से, दस्तावेज़ खोज अधिक स्वाभाविक और सहज हो जाती है, जिससे उपयोगकर्ताओं के लिए उनकी ज़रूरत की जानकारी ढूंढना आसान और तेज़ हो जाता है। ध्वनि इनपुट खोज परिणामों की सटीकता को बढ़ा सकता है, क्योंकि बोले गए खोज शब्दों में वर्तनी या व्याकरण संबंधी त्रुटियों की संभावना कम होती है। इंटरएक्टिव वॉयस इनपुट दस्तावेज़ खोज को अधिक समावेशी बनाता है, जो विभिन्न भाषा बोलने वालों और संस्कृति पृष्ठभूमि वाले उपयोगकर्ताओं के व्यापक स्पेक्ट्रम को पूरा करता है।
RSI अमेज़ॅन ट्रांसक्राइब स्ट्रीमिंग एसडीके आपको ऑडियो बाइट्स की एक स्ट्रीम और एक बुनियादी हैंडलर के साथ अमेज़ॅन ट्रांसक्राइब के साथ सीधे एकीकृत करके ऑडियो-टू-स्पीच पहचान करने में सक्षम बनाता है। एक विकल्प के रूप में, आप इसे तैनात कर सकते हैं फुसफुसाहट-बड़ा हगिंग फेस का उपयोग करके स्थानीय स्तर पर मॉडल SageMaker, जो बेहतर डेटा सुरक्षा और बेहतर प्रदर्शन प्रदान करता है। विवरण के लिए, देखें नमूना नोटबुक GitHub रेपो पर प्रकाशित।
# Choose ASR using a locally deployed Whisper-large model from Hugging Face
image = sagemaker.image_uris.retrieve(
framework='pytorch',
region=region,
image_scope='inference',
version='1.12',
instance_type='ml.g4dn.xlarge',
) model_name = f'sagemaker-soln-whisper-model-{int(time.time())}'
whisper_model_sm = sagemaker.model.Model(
model_data=model_uri,
image_uri=image,
role=sagemaker.get_execution_role(),
entry_point="inference.py",
source_dir='src',
name=model_name,
) # Audio transcribe
transcribe = whisper_endpoint.predict(audio.numpy())उपरोक्त प्रदर्शन वीडियो दिखाता है कि कैसे वॉयस कमांड, टेक्स्ट इनपुट के साथ मिलकर, इंटरैक्टिव बातचीत के माध्यम से दस्तावेज़ सारांश के कार्य को सुविधाजनक बना सकता है।
बहु-दौरीय बातचीत के माध्यम से एनएलपी कार्यों का मार्गदर्शन करना
भाषा मॉडल में मेमोरी उपयोगकर्ता की बातचीत के दौरान स्थिति की अवधारणा को बनाए रखती है। इसमें ज्ञान निकालने और बदलने के लिए चैट संदेशों के अनुक्रम को संसाधित करना शामिल है। मेमोरी के प्रकार अलग-अलग होते हैं, लेकिन प्रत्येक को स्टैंडअलोन फ़ंक्शंस का उपयोग करके और एक श्रृंखला के भीतर समझा जा सकता है। मेमोरी कई डेटा बिंदुओं, जैसे हाल के संदेश या संदेश सारांश, को स्ट्रिंग या सूचियों के रूप में लौटा सकती है। यह पोस्ट सबसे सरल मेमोरी फॉर्म, बफर मेमोरी पर केंद्रित है, जो सभी पूर्व संदेशों को संग्रहीत करता है, और मॉड्यूलर उपयोगिता कार्यों और श्रृंखलाओं के साथ इसके उपयोग को प्रदर्शित करता है।
लैंगचेन चैटमैसेजइतिहास क्लास मेमोरी मॉड्यूल के लिए एक महत्वपूर्ण उपयोगिता है, जो पिछले सभी चैट इंटरैक्शन को याद करके मानव और एआई संदेशों को सहेजने और पुनर्प्राप्त करने के लिए सुविधाजनक तरीके प्रदान करता है। यह एक श्रृंखला से बाह्य रूप से मेमोरी को प्रबंधित करने के लिए आदर्श है। निम्नलिखित कोड एक सरल अवधारणा को एक श्रृंखला में प्रस्तुत करके लागू करने का एक उदाहरण है कन्वर्सेशनबफरमेमोरी, के लिए एक आवरण ChatMessageHistory. यह रैपर संदेशों को एक वेरिएबल में निकालता है, जिससे उन्हें एक स्ट्रिंग के रूप में दर्शाया जा सकता है:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(return_messages=True)लैंगचेन कई लोकप्रिय एलएलएम प्रदाताओं जैसे एआई21 लैब्स, ओपनएआई, कोहेयर, हगिंग फेस और अन्य के साथ काम करता है। इस उदाहरण के लिए, हम SageMaker का उपयोग करके स्थानीय रूप से तैनात AI21 लैब्स के जुरासिक-2 LLM रैपर का उपयोग करते हैं। AI21 स्टूडियो जुरासिक-2 एलएलएम को एपीआई एक्सेस भी प्रदान करता है।
from langchain import PromptTemplate, SagemakerEndpoint
from langchain.llms.sagemaker_endpoint import ContentHandlerBase
from langchain.chains.question_answering import load_qa_chain prompt= PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
) class ContentHandler(ContentHandlerBase):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs: Dict) -- bytes:
input_str = json.dumps({prompt: prompt, **model_kwargs})
return input_str.encode('utf-8') def transform_output(self, output: bytes) -- str:
response_json = json.loads(output.read().decode("utf-8"))
return response_json[0]["generated_text"]
content_handler = ContentHandler()
llm_ai21=SagemakerEndpoint(
endpoint_name=endpoint_name,
credentials_profile_name=f'aws-credentials-profile-name',
region_name="us-east-1",
model_kwargs={"temperature":0},
content_handler=content_handler) qa_chain = VectorDBQA.from_chain_type(
llm=llm_ai21,
chain_type='stuff',
vectorstore=docsearch,
verbose=True,
memory=ConversationBufferMemory(return_messages=True)
) response = qa_chain(
{'query': query_input},
return_only_outputs=True
)ऐसी स्थिति में जब प्रक्रिया किसी उपयोगकर्ता की पूछताछ के जवाब में मूल दस्तावेजों से उचित प्रतिक्रिया का पता लगाने में असमर्थ होती है, तो बाहरी डेटा स्रोतों के साथ तीसरे पक्ष के यूआरएल या आदर्श रूप से कार्य-संचालित स्वायत्त एजेंट का एकीकरण सिस्टम की क्षमता को महत्वपूर्ण रूप से बढ़ाता है। जानकारी की एक विशाल श्रृंखला तक पहुंच, अंततः संदर्भ में सुधार और अधिक सटीक और वर्तमान परिणाम प्रदान करना।
AI21 की पूर्व-कॉन्फ़िगर सारांश रन विधि के साथ, एक क्वेरी एक पूर्व निर्धारित URL तक पहुंच सकती है, इसकी सामग्री को संक्षिप्त कर सकती है, और फिर सारांशित जानकारी के आधार पर प्रश्न और उत्तर कार्य कर सकती है:
# Call AI21 API to query the context of a specific URL for Q&A
ai21.api_key = "<YOUR_API_KEY>"
url_external_source = "<your_source_url>"
response_url = ai21.Summarize.execute(
source=url_external_source,
sourceType="URL" )
context = "<concate_document_and_response_url>"
question = "<query>"
response = ai21.Answer.execute(
context=context,
question=question,
sm_endpoint=endpoint_name,
maxTokens=100,
)अतिरिक्त विवरण और कोड उदाहरणों के लिए, देखें लैंगचेन एलएलएम एकीकरण दस्तावेज़ के रूप में अच्छी तरह के रूप में कार्य-विशिष्ट API दस्तावेज़ AI21 द्वारा प्रदान किया गया।
बेबीएजीआई का उपयोग करके कार्य स्वचालन
कार्य स्वचालन तंत्र सिस्टम को जटिल प्रश्नों को संसाधित करने और प्रासंगिक प्रतिक्रियाएं उत्पन्न करने की अनुमति देता है, जो दस्तावेज़ प्रसंस्करण की वैधता और प्रामाणिकता में काफी सुधार करता है। लैंगकैन की बेबीएजीआई एक शक्तिशाली एआई-संचालित कार्य प्रबंधन प्रणाली है जो स्वायत्त रूप से कार्यों को बना सकती है, प्राथमिकता दे सकती है और चला सकती है। प्रमुख विशेषताओं में से एक सूचना के बाहरी स्रोतों, जैसे वेब, डेटाबेस और एपीआई के साथ इंटरफेस करने की इसकी क्षमता है। इस सुविधा का उपयोग करने का एक तरीका बेबीएजीआई को एकीकृत करना है सर्पापी, एक खोज इंजन एपीआई जो खोज इंजन तक पहुंच प्रदान करता है। यह एकीकरण बेबीएजीआई को कार्यों से संबंधित जानकारी के लिए वेब पर खोज करने की अनुमति देता है, जिससे बेबीएजीआई को इनपुट दस्तावेजों से परे ढेर सारी जानकारी तक पहुंचने की अनुमति मिलती है।
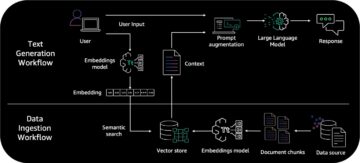
बेबीएजीआई की स्वायत्त कार्य क्षमता को एलएलएम, एक वेक्टर खोज डेटाबेस, बाहरी लिंक के लिए एक एपीआई रैपर और लैंगचेन फ्रेमवर्क द्वारा ईंधन दिया जाता है, जो इसे विभिन्न डोमेन में कार्यों के व्यापक स्पेक्ट्रम को चलाने की अनुमति देता है। यह सिस्टम को उपयोगकर्ता इंटरैक्शन के आधार पर सक्रिय रूप से कार्य करने में सक्षम बनाता है, बाहरी स्रोतों को शामिल करने वाली दस्तावेज़ प्रसंस्करण पाइपलाइन को सुव्यवस्थित करता है और अधिक कुशल, सहज अनुभव बनाता है। निम्नलिखित चित्र कार्य स्वचालन प्रक्रिया को दर्शाता है।

इस प्रक्रिया में निम्नलिखित घटक शामिल हैं:
- याद - मेमोरी वह सारी जानकारी संग्रहीत करती है जिसकी बेबीएजीआई को अपने कार्यों को पूरा करने के लिए आवश्यकता होती है। इसमें स्वयं कार्य, साथ ही बेबीएजीआई द्वारा उत्पन्न कोई भी मध्यवर्ती परिणाम या डेटा शामिल है।
- निष्पादन एजेंट - निष्पादन एजेंट मेमोरी में संग्रहीत कार्यों को पूरा करने के लिए जिम्मेदार है। यह मेमोरी तक पहुंच कर, प्रासंगिक जानकारी प्राप्त करके और फिर कार्य को पूरा करने के लिए आवश्यक कदम उठाकर ऐसा करता है।
- कार्य निर्माण एजेंट - कार्य निर्माण एजेंट बेबीएजीआई को पूरा करने के लिए नए कार्य तैयार करने के लिए जिम्मेदार है। यह स्मृति की वर्तमान स्थिति का विश्लेषण करके और ज्ञान या समझ में किसी भी अंतराल की पहचान करके ऐसा करता है। जब एक अंतर की पहचान की जाती है, तो कार्य निर्माण एजेंट एक नया कार्य उत्पन्न करता है जो बेबीएजीआई को उस अंतर को भरने में मदद करेगा।
- कार्य कतार - कार्य कतार उन सभी कार्यों की एक सूची है जिन्हें बेबीएजीआई को सौंपा गया है। कार्यों को कतार में उसी क्रम में जोड़ा जाता है जिस क्रम में वे प्राप्त हुए थे।
- कार्य प्राथमिकताकरण एजेंट - कार्य प्राथमिकता एजेंट उस क्रम को निर्धारित करने के लिए जिम्मेदार है जिसमें बेबीएजीआई को अपने कार्यों को पूरा करना चाहिए। यह कतार में कार्यों का विश्लेषण करके और सबसे महत्वपूर्ण या जरूरी कार्यों की पहचान करके ऐसा करता है। जो कार्य सबसे महत्वपूर्ण हैं उन्हें कतार में सबसे आगे रखा गया है और जो कार्य सबसे कम महत्वपूर्ण हैं उन्हें कतार में सबसे पीछे रखा गया है।
निम्नलिखित कोड देखें:
from babyagi import BabyAGI
from langchain.docstore import InMemoryDocstore
import faiss
# Set temperatur=0 to generate the most frequent words, instead of more “poetically free” behavior.
new_query = """
What happened to the First Republic Bank? Will the FED take the same action as it did on SVB's failure? """
# Enable verbose logging and use a fixed embedding size.
verbose = True
embedding_size = 1536 # Using FAISS vector cluster for vectore store
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(llm_embeddings.embed_query, index, InMemoryDocstore({}), {}) # Choose 1 iteration for demo and 1>N>10 for real. If None, it will loop indefinitely
max_iterations: Optional[int] = 2 # Call bayagi class for task automation
baby_agi = BabyAGI.from_llm(
llm=llm_embedding, vectorstore=vectorstore, verbose=verbose, max_iterations=max_iterations<br />) response = baby_agi({"objective": new_query})आइए उपयोगकर्ता की पूछताछ के जवाब में उद्देश्य को पूरा करने के लिए, प्रदर्शन उद्देश्यों के लिए उपयोग किए गए एकल पुनरावृत्ति से एकत्र किए गए कार्यों और उनके परिणामों की जांच करें। बेबीएजीआई निम्नलिखित चरणों के एक सतत चक्र के माध्यम से संचालित होता है:
- एक कार्य निर्माण एजेंट एक नया कार्य तैयार करता है।
- नया कार्य कार्य कतार में शामिल किया गया है।
- कार्य प्राथमिकताकरण एजेंट उस क्रम को स्थापित करता है जिसमें कार्यों को निपटाया जाना चाहिए।
- रन एजेंट कार्य पूरा करता है।
- कार्य का परिणाम स्मृति में सहेजा जाता है.
- चक्र दोहराता है।
यह पुनरावृत्तीय प्रक्रिया बेबीएजीआई को समय के साथ सीखने और विकसित होने में सक्षम बनाती है। जैसे-जैसे यह बढ़ती संख्या में कार्यों को सफलतापूर्वक पूरा करता है, बेबीएजीआई का दुनिया के बारे में ज्ञान और समझ का विस्तार होता है। नतीजतन, यह अधिक जटिल और उन्नत कार्यों को उत्पन्न और कुशलतापूर्वक चला सकता है। पुनरावृत्ति गणना को बढ़ाकर, आप कार्य सूची के पुनर्गठन के माध्यम से परिणाम को बढ़ा सकते हैं, जो लक्ष्य और पिछले कार्यों के परिणाम पर ध्यान केंद्रित करता है, अंततः अधिक प्रासंगिक और सटीक प्रतिक्रिया देता है।
निम्नलिखित उदाहरण आउटपुट देखें:
*****TASK LIST*****
1: Make a todo list
*****NEXT TASK*****
1: Make a todo list
> Entering new AgentExecutor chain...
Thought: I need to research the First Republic Bank and the FED's action
Action: Search
Action Input: What happened to the First Republic Bank? Will the FED take the same action as it did on SVB's failure?
Observation: First Republic's failure was due to a run on deposits following the collapse of Silicon Valley Bank and Signature Bank. JPMorgan Chase acquired
First Republic Bank on May 1, 2023. If you had insured or uninsured money in First Republic accounts, your funds are safe and now managed by JPMorgan Chase.
Thought: I need to research the FED's action on SVB's failure
Action: Search
Action Input: What action did the FED take on SVB's failure?
Observation: The Hutchins Center explains how the Federal Reserve has responded to the March 2023 failures of Silicon Valley Bank and Signature Bank.
Thought: I now know the final answer
Final Answer: The FED responded to the March 2023 failures of Silicon Valley Bank and <br />Signature Bank by providing liquidity to the banking system. JPMorgan Chase acquired First Republic Bank on May 1, 2023, and if you had insured or uninsured money in First Republic accounts, your funds are safe and now managed by JPMorgan Chase.
> Finished chain.
*****TASK RESULT*****
The Federal Reserve responded to the March 2023 failures of Silicon Valley Bank and Signature Bank by providing liquidity to the banking system. It is unclear what action the FED will take in response to the failure of First Republic Bank. ***TASK LIST*** 2: Research the timeline of First Republic Bank's failure.
3: Analyze the Federal Reserve's response to the failure of Silicon Valley Bank and Signature Bank.
4: Compare the Federal Reserve's response to the failure of Silicon Valley Bank and Signature Bank to the Federal Reserve's response to the failure of First Republic Bank.
5: Investigate the potential implications of the Federal Reserve's response to the failure of First Republic Bank.
6: Identify any potential risks associated with the Federal Reserve's response to the failure of First Republic Bank.<br />*****NEXT TASK***** 2: Research the timeline of First Republic Bank's failure. > Entering new AgentExecutor chain...
Will the FED take the same action as it did on SVB's failure?
Thought: I should search for information about the timeline of First Republic Bank's failure and the FED's action on SVB's failure.
Action: Search
Action Input: Timeline of First Republic Bank's failure and FED's action on SVB's failure
Observation: March 20: The FDIC decides to break up SVB and hold two separate auctions for its traditional deposits unit and its private bank after failing ...
Thought: I should look for more information about the FED's action on SVB's failure.
Action: Search
Action Input: FED's action on SVB's failure
Observation: The Fed blamed failures on mismanagement and supervisory missteps, compounded by a dose of social media frenzy.
Thought: I now know the final answer.
Final Answer: The FED is likely to take similar action on First Republic Bank's failure as it did on SVB's failure, which was to break up the bank and hold two separate auctions for its traditional deposits unit and its private bank.</p><p>> Finished chain. *****TASK RESULT*****
The FED responded to the March 2023 failures of ilicon Valley Bank and Signature Bank by providing liquidity to the banking system. JPMorgan Chase acquired First Republic Bank on May 1, 2023, and if you had insured or uninsured money in First Republic accounts, your funds are safe and now managed by JPMorgan Chase.*****TASK ENDING*****कार्य स्वचालन के लिए बेबीएजीआई के साथ, संवाद-निर्देशित आईडीपी प्रणाली ने फर्स्ट रिपब्लिक बैंक की विफलता के संबंध में फेडरल रिजर्व की संभावित कार्रवाइयों के बारे में उपयोगकर्ता की क्वेरी को संबोधित करने के लिए मूल दस्तावेज़ के संदर्भ से परे जाकर अपनी प्रभावशीलता प्रदर्शित की, जो एक महीने बाद अप्रैल 2023 के अंत में हुई थी। नमूना प्रकाशनएसवीबी की विफलता की तुलना में। इसे प्राप्त करने के लिए, सिस्टम ने एक कार्य सूची तैयार की और कार्यों को क्रमिक रूप से पूरा किया। इसने फर्स्ट रिपब्लिक बैंक की विफलता के आसपास की परिस्थितियों की जांच की, फेडरल रिजर्व की प्रतिक्रिया से जुड़े संभावित जोखिमों को इंगित किया और इसकी तुलना एसवीबी की विफलता की प्रतिक्रिया से की।
हालाँकि बेबीएजीआई का कार्य प्रगति पर है, यह मशीन इंटरैक्शन, आविष्कारशील सोच और समस्या समाधान में क्रांति लाने का वादा करता है। जैसे-जैसे बेबीएजीआई की सीख और उन्नति जारी रहेगी, यह अधिक सटीक, व्यावहारिक और आविष्कारशील प्रतिक्रियाएँ देने में सक्षम होगी। मशीनों को सीखने और स्वायत्त रूप से विकसित होने के लिए सशक्त बनाकर, बेबीएजीआई रोजमर्रा के कामों से लेकर जटिल समस्या-समाधान तक, कार्यों के व्यापक स्पेक्ट्रम में उनकी सहायता की सुविधा प्रदान कर सकता है।
बाधाएँ और सीमाएँ
संवाद-निर्देशित आईडीपी दस्तावेज़ विश्लेषण और निष्कर्षण की दक्षता और प्रभावशीलता को बढ़ाने के लिए एक आशाजनक दृष्टिकोण प्रदान करता है। हालाँकि, हमें इसकी वर्तमान बाधाओं और सीमाओं को स्वीकार करना चाहिए, जैसे डेटा पूर्वाग्रह से बचने की आवश्यकता, मतिभ्रम शमन, जटिल और अस्पष्ट भाषा को संभालने की चुनौती, और संदर्भ को समझने या लंबी बातचीत में सुसंगतता बनाए रखने में कठिनाइयाँ।
इसके अतिरिक्त, एआई-जनित प्रतिक्रियाओं में भ्रम और मतिभ्रम पर विचार करना महत्वपूर्ण है, जिससे गलत या मनगढ़ंत जानकारी का निर्माण हो सकता है। इन चुनौतियों का समाधान करने के लिए, चल रहे विकास बेहतर प्राकृतिक भाषा समझ क्षमताओं के साथ एलएलएम को परिष्कृत करने, डोमेन-विशिष्ट ज्ञान को शामिल करने और अधिक मजबूत संदर्भ-जागरूक मॉडल विकसित करने पर ध्यान केंद्रित कर रहे हैं। शुरुआत से एलएलएम बनाना महंगा और समय लेने वाला हो सकता है; हालाँकि, आप मौजूदा मॉडलों को बेहतर बनाने के लिए कई रणनीतियाँ अपना सकते हैं:
- अधिक सटीक और प्रासंगिक आउटपुट के लिए विशिष्ट डोमेन पर पूर्व-प्रशिक्षित एलएलएम को फाइन-ट्यून करना
- उन्नत प्रासंगिक समझ के लिए अनुमान के दौरान सुरक्षित माने जाने वाले बाहरी डेटा स्रोतों को एकीकृत करना
- मॉडल से अधिक सटीक प्रतिक्रिया प्राप्त करने के लिए बेहतर संकेत डिज़ाइन करना
- एकाधिक एलएलएम से आउटपुट को संयोजित करने के लिए एन्सेम्बल मॉडल का उपयोग करना, त्रुटियों का औसत निकालना और मतिभ्रम की संभावना को कम करना
- मॉडलों को अवांछित क्षेत्रों में जाने से रोकने के लिए रेलिंग का निर्माण करना, साथ ही यह सुनिश्चित करना कि ऐप्स सटीक और उचित जानकारी के साथ प्रतिक्रिया दें
- मानवीय प्रतिक्रिया के साथ पर्यवेक्षित फाइन-ट्यूनिंग का संचालन करना, बढ़ी हुई सटीकता और कम मतिभ्रम के लिए मॉडल को पुनरावृत्त रूप से परिष्कृत करना।
इन दृष्टिकोणों को अपनाकर, AI-जनित प्रतिक्रियाओं को अधिक विश्वसनीय और मूल्यवान बनाया जा सकता है।
कार्य-संचालित स्वायत्त एजेंट विभिन्न अनुप्रयोगों में महत्वपूर्ण क्षमता प्रदान करता है, लेकिन प्रौद्योगिकी को अपनाने से पहले प्रमुख जोखिमों पर विचार करना महत्वपूर्ण है। इन जोखिमों में शामिल हैं:
- चयनित एलएलएम प्रदाता और वेक्टरडीबी पर निर्भरता के कारण डेटा गोपनीयता और सुरक्षा उल्लंघन
- पक्षपातपूर्ण या हानिकारक सामग्री निर्माण से उत्पन्न होने वाली नैतिक चिंताएँ
- मॉडल सटीकता पर निर्भरता, जिसके कारण अप्रभावी कार्य पूरा हो सकता है या अवांछित परिणाम हो सकते हैं
- यदि कार्य निर्माण समय से पहले पूरा हो जाता है, तो सिस्टम अधिभार और स्केलेबिलिटी समस्याएँ उत्पन्न होती हैं, जिसके लिए उचित कार्य अनुक्रमण और समानांतर प्रबंधन की आवश्यकता होती है
- कार्य महत्व की एलएलएम की समझ के आधार पर कार्य प्राथमिकता की गलत व्याख्या
- वेब से प्राप्त डेटा की प्रामाणिकता
जिम्मेदार और सफल अनुप्रयोग के लिए इन जोखिमों को संबोधित करना महत्वपूर्ण है, जिससे हम संभावित जोखिमों को कम करते हुए एआई-संचालित भाषा मॉडल के लाभों को अधिकतम कर सकते हैं।
निष्कर्ष
आईडीपी के लिए संवाद-निर्देशित समाधान ओसीआर, स्वचालित वाक् पहचान, एलएलएम, कार्य स्वचालन और बाहरी डेटा स्रोतों को एकीकृत करके दस्तावेज़ प्रसंस्करण के लिए एक अभूतपूर्व दृष्टिकोण प्रस्तुत करता है। यह व्यापक समाधान व्यवसायों को अपने दस्तावेज़ प्रसंस्करण वर्कफ़्लो को सुव्यवस्थित करने में सक्षम बनाता है, जिससे वे अधिक कुशल और सहज बन जाते हैं। इन अत्याधुनिक तकनीकों को शामिल करके, संगठन न केवल अपनी दस्तावेज़ प्रबंधन प्रक्रियाओं में क्रांतिकारी बदलाव ला सकते हैं, बल्कि निर्णय लेने की क्षमताओं को भी बढ़ा सकते हैं और समग्र उत्पादकता को काफी बढ़ा सकते हैं। यह समाधान व्यवसायों के लिए उनके दस्तावेज़ वर्कफ़्लो की पूरी क्षमता को अनलॉक करने के लिए एक परिवर्तनकारी और अभिनव साधन प्रदान करता है, जो अंततः जेनरेटिव एआई के युग में विकास और सफलता को बढ़ावा देता है। को देखें सेजमेकर जम्पस्टार्ट अन्य समाधानों के लिए और अमेज़ॅन बेडरॉक अतिरिक्त जेनेरिक एआई मॉडल के लिए।
लेखक इस काम में उनके बहुमूल्य इनपुट और योगदान के लिए रयान किलपैट्रिक, आशीष लाल और क्रिस्टीन पीयर्स के प्रति ईमानदारी से अपनी सराहना व्यक्त करना चाहते हैं। वे जीथब पर उपलब्ध कराए गए कोड नमूने के लिए क्ले एल्मोर को भी स्वीकार करते हैं।
लेखक के बारे में
 अल्फ्रेड शेन AWS में एक वरिष्ठ AI/ML विशेषज्ञ हैं। वह सिलिकॉन वैली में स्वास्थ्य सेवा, वित्त और उच्च तकनीक सहित विभिन्न क्षेत्रों में तकनीकी और प्रबंधकीय पदों पर काम कर रहे हैं। वह सीवी, एनएलपी और मल्टीमॉडलिटी पर ध्यान केंद्रित करने वाला एक समर्पित एप्लाइड एआई/एमएल शोधकर्ता है। उनके काम को ईएमएनएलपी, आईसीएलआर और पब्लिक हेल्थ जैसे प्रकाशनों में प्रदर्शित किया गया है।
अल्फ्रेड शेन AWS में एक वरिष्ठ AI/ML विशेषज्ञ हैं। वह सिलिकॉन वैली में स्वास्थ्य सेवा, वित्त और उच्च तकनीक सहित विभिन्न क्षेत्रों में तकनीकी और प्रबंधकीय पदों पर काम कर रहे हैं। वह सीवी, एनएलपी और मल्टीमॉडलिटी पर ध्यान केंद्रित करने वाला एक समर्पित एप्लाइड एआई/एमएल शोधकर्ता है। उनके काम को ईएमएनएलपी, आईसीएलआर और पब्लिक हेल्थ जैसे प्रकाशनों में प्रदर्शित किया गया है।
 डॉ विवेक मदनी अमेज़ॅन सेजमेकर जम्पस्टार्ट टीम के साथ एक अनुप्रयुक्त वैज्ञानिक है। उन्होंने अर्बाना-शैंपेन में इलिनोइस विश्वविद्यालय से पीएचडी प्राप्त की और जॉर्जिया टेक में पोस्ट डॉक्टरेट शोधकर्ता थे। वह मशीन लर्निंग और एल्गोरिथम डिज़ाइन में एक सक्रिय शोधकर्ता हैं और उन्होंने EMNLP, ICLR, COLT, FOCS और SODA सम्मेलनों में पेपर प्रकाशित किए हैं।
डॉ विवेक मदनी अमेज़ॅन सेजमेकर जम्पस्टार्ट टीम के साथ एक अनुप्रयुक्त वैज्ञानिक है। उन्होंने अर्बाना-शैंपेन में इलिनोइस विश्वविद्यालय से पीएचडी प्राप्त की और जॉर्जिया टेक में पोस्ट डॉक्टरेट शोधकर्ता थे। वह मशीन लर्निंग और एल्गोरिथम डिज़ाइन में एक सक्रिय शोधकर्ता हैं और उन्होंने EMNLP, ICLR, COLT, FOCS और SODA सम्मेलनों में पेपर प्रकाशित किए हैं।
 डॉ. ली झांग के लिए एक प्रधान उत्पाद प्रबंधक-तकनीकी है अमेज़न SageMaker जम्पस्टार्ट और अमेज़ॅन सेजमेकर बिल्ट-इन एल्गोरिदम, एक ऐसी सेवा जो डेटा वैज्ञानिकों और मशीन लर्निंग प्रैक्टिशनर्स को उनके मॉडल और उपयोग के प्रशिक्षण और तैनाती के साथ आरंभ करने में मदद करती है सुदृढीकरण सीखना अमेज़न सैजमेकर के साथ। आईबीएम रिसर्च में प्रिंसिपल रिसर्च स्टाफ सदस्य और मास्टर आविष्कारक के रूप में उनके पिछले काम ने जीत हासिल की है टाइम पेपर पुरस्कार का परीक्षण आईईईई इन्फोकॉम में।
डॉ. ली झांग के लिए एक प्रधान उत्पाद प्रबंधक-तकनीकी है अमेज़न SageMaker जम्पस्टार्ट और अमेज़ॅन सेजमेकर बिल्ट-इन एल्गोरिदम, एक ऐसी सेवा जो डेटा वैज्ञानिकों और मशीन लर्निंग प्रैक्टिशनर्स को उनके मॉडल और उपयोग के प्रशिक्षण और तैनाती के साथ आरंभ करने में मदद करती है सुदृढीकरण सीखना अमेज़न सैजमेकर के साथ। आईबीएम रिसर्च में प्रिंसिपल रिसर्च स्टाफ सदस्य और मास्टर आविष्कारक के रूप में उनके पिछले काम ने जीत हासिल की है टाइम पेपर पुरस्कार का परीक्षण आईईईई इन्फोकॉम में।
 डॉ. चांग्शा मा AWS में AI/ML विशेषज्ञ हैं। वह कंप्यूटर विज्ञान में पीएचडी, शिक्षा मनोविज्ञान में मास्टर डिग्री और डेटा विज्ञान और एआई/एमएल में स्वतंत्र परामर्श के साथ वर्षों का अनुभव रखने वाली एक प्रौद्योगिकीविद् हैं। उन्हें मशीन और मानव बुद्धि के लिए पद्धतिगत दृष्टिकोण पर शोध करने का शौक है। काम के अलावा, उसे लंबी पैदल यात्रा करना, खाना बनाना, भोजन की तलाश करना, उद्यमिता के लिए कॉलेज के छात्रों को सलाह देना और दोस्तों और परिवारों के साथ समय बिताना पसंद है।
डॉ. चांग्शा मा AWS में AI/ML विशेषज्ञ हैं। वह कंप्यूटर विज्ञान में पीएचडी, शिक्षा मनोविज्ञान में मास्टर डिग्री और डेटा विज्ञान और एआई/एमएल में स्वतंत्र परामर्श के साथ वर्षों का अनुभव रखने वाली एक प्रौद्योगिकीविद् हैं। उन्हें मशीन और मानव बुद्धि के लिए पद्धतिगत दृष्टिकोण पर शोध करने का शौक है। काम के अलावा, उसे लंबी पैदल यात्रा करना, खाना बनाना, भोजन की तलाश करना, उद्यमिता के लिए कॉलेज के छात्रों को सलाह देना और दोस्तों और परिवारों के साथ समय बिताना पसंद है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- मिंटिंग द फ्यूचर डब्ल्यू एड्रिएन एशले। यहां पहुंचें।
- PREIPO® के साथ PRE-IPO कंपनियों में शेयर खरीदें और बेचें। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/dialogue-guided-intelligent-document-processing-with-foundation-models-on-amazon-sagemaker-jumpstart/
- :हैस
- :है
- :नहीं
- ][पी
- $यूपी
- 000
- 1
- 10
- 100
- 12
- 20
- 2023
- 8th
- a
- क्षमता
- About
- ऊपर
- स्वीकार करता है
- पहुँच
- तक पहुँचने
- पूरा
- लेखा
- अकौन्टस(लेखा)
- शुद्धता
- सही
- पाना
- स्वीकार करना
- प्राप्त
- के पार
- कार्य
- कार्रवाई
- सक्रिय
- अनुकूलन
- जोड़ा
- जोड़ने
- अतिरिक्त
- इसके अतिरिक्त
- पता
- को संबोधित
- अपनाने
- दत्तक ग्रहण
- उन्नत
- अग्रिमों
- लाभ
- लाभदायक
- फायदे
- बाद
- के खिलाफ
- एजेंट
- AI
- ऐ संचालित
- ऐ / एमएल
- कलन विधि
- एल्गोरिदम
- सब
- की अनुमति दे
- की अनुमति देता है
- भी
- वैकल्पिक
- हालांकि
- वीरांगना
- अमेज़ॅन केंद्र
- अमेज़न SageMaker
- अमेज़न SageMaker जम्पस्टार्ट
- अमेज़न टेक्सट्रेक
- Amazon Transcribe
- अमेज़ॅन वेब सेवा
- राशियाँ
- an
- विश्लेषण
- विश्लेषण करें
- का विश्लेषण
- और
- जवाब
- जवाब
- प्रत्याशित
- कोई
- एपीआई
- एपीआई एक्सेस
- एपीआई
- आवेदन
- अनुप्रयोगों
- लागू
- लागू
- प्रशंसा
- दृष्टिकोण
- दृष्टिकोण
- उपयुक्त
- क्षुधा
- अप्रैल
- हैं
- क्षेत्रों के बारे में जानकारी का उपयोग करके ट्रेडिंग कर सकते हैं।
- चारों ओर
- ऐरे
- AS
- सौंपा
- सहायता
- जुड़े
- At
- नीलामी
- ऑडियो
- प्रामाणिकता
- लेखकों
- ऑटोमेटा
- स्वचालित
- स्वचालन
- स्वायत्त
- स्वायत्त
- उपलब्ध
- औसत
- एडब्ल्यूएस
- एडब्ल्यूएस बाज़ार
- वापस
- पृष्ठभूमि
- बैंक
- बैंकिंग
- बैंकिंग सिस्टम
- आधारित
- बुनियादी
- BE
- क्योंकि
- बन
- हो जाता है
- किया गया
- से पहले
- शुरू करना
- लाभ
- BEST
- बेहतर
- के बीच
- परे
- पूर्वाग्रह
- झुका हुआ
- अरबों
- खंड
- ब्लॉक
- मंडल
- सिलेंडर
- बढ़ावा
- उल्लंघनों
- टूटना
- ब्रिजिंग
- विस्तृत
- व्यापक
- बफर
- निर्माण
- इमारत
- में निर्मित
- व्यवसायों
- लेकिन
- by
- कॉल
- कर सकते हैं
- क्षमताओं
- सक्षम
- क्षमता
- ले जाना
- ले जाने के
- मामला
- केंद्र
- श्रृंखला
- चेन
- चुनौती
- चुनौतियों
- परिवर्तन
- चरित्र
- चरित्र पहचान
- पीछा
- चुनें
- करने के लिए चुना
- हालत
- कक्षा
- बादल
- समूह
- गुच्छन
- कोड
- संक्षिप्त करें
- कॉलेज
- संयोजन
- गठबंधन
- जोड़ती
- सामान्य
- तुलना
- तुलना
- तुलना
- पूरा
- पूरा
- पूरा करता है
- समापन
- जटिल
- घटकों
- समझना
- व्यापक
- कंप्यूटर
- कम्प्यूटर साइंस
- कंप्यूटर्स
- संकल्पना
- चिंताओं
- सम्मेलनों
- कनेक्शन
- इसके फलस्वरूप
- विचार करना
- काफी
- की कमी
- निर्माण
- परामर्श
- सामग्री
- प्रसंग
- संदर्भों
- प्रासंगिक
- जारी रखने के
- निरंतर
- योगदान
- सुविधाजनक
- कन्वर्सेशन (Conversation)
- बातचीत
- रूपांतरण
- बदलना
- खाना पकाने
- लागत
- महंगा
- सका
- बनाना
- बनाना
- निर्माण
- महत्वपूर्ण
- संस्कृति
- वर्तमान
- वर्तमान स्थिति
- अग्रणी
- अत्याधुनिक तकनीक
- चक्र
- तिथि
- डेटा पूर्वाग्रह
- डेटा अंक
- डेटा विज्ञान
- डाटा सुरक्षा
- डाटाबेस
- डेटाबेस
- व्यवहार
- निर्णय
- समर्पित
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- डिग्री
- बचाता है
- डेमो
- दर्शाता
- तैनात
- तैनात
- तैनाती
- तैनाती
- जमा
- निकाली गई
- डिज़ाइन
- बनाया गया
- के बावजूद
- विवरण
- निर्धारित करने
- विकसित करना
- विकासशील
- के घटनाक्रम
- बातचीत
- dict
- डीआईडी
- विभिन्न
- कठिनाइयों
- सीधे
- पर चर्चा
- कई
- दस्तावेज़
- दस्तावेज़ प्रबंधन
- दस्तावेजों
- कर देता है
- डोमेन
- नीचे
- ड्राइविंग
- दो
- अवधि
- दौरान
- e
- से प्रत्येक
- आसान
- आसान
- शिक्षा
- प्रभावी
- प्रभावशीलता
- दक्षता
- कुशल
- कुशलता
- तत्व
- एम्बेड
- embedding
- सशक्त बनाने के लिए
- सक्षम
- सक्षम बनाता है
- समर्थकारी
- endpoint
- इंजन
- इंजन
- बढ़ाना
- वर्धित
- बढ़ाता है
- बढ़ाने
- पर्याप्त
- सुनिश्चित
- में प्रवेश
- उद्यम
- संपूर्ण
- उद्यमशीलता
- युग
- त्रुटि
- त्रुटियाँ
- स्थापित करता
- ईथर (ईटीएच)
- कार्यक्रम
- विकसित करना
- की जांच
- जांच
- उदाहरण
- उदाहरण
- सिवाय
- एक्सचेंजों
- निष्पादन
- मौजूदा
- विस्तार
- अनुभव
- समझाना
- बताते हैं
- का पता लगाने
- व्यक्त
- व्यापक
- बाहरी
- बाहर से
- उद्धरण
- निष्कर्षण
- अर्क
- चेहरा
- की सुविधा
- की सुविधा
- विफल रहे
- में नाकाम रहने
- विफलता
- परिवारों
- एफडीआईसी
- Feature
- विशेषताएं
- फेड
- संघीय
- फेडरल रिजर्व
- फेडरल रिजर्व का
- प्रतिक्रिया
- पट्टिका
- फ़ाइलें
- भरना
- अंतिम
- अंत में
- वित्त
- खोज
- खत्म
- प्रथम
- तय
- उतार चढ़ाव
- केंद्रित
- ध्यान केंद्रित
- निम्नलिखित
- भोजन
- के लिए
- प्रपत्र
- प्रारूप
- रूपों
- बुनियाद
- फ्रेम
- ढांचा
- उन्माद
- बारंबार
- मित्रों
- से
- सामने
- शह
- पूर्ण
- पूरी तरह से
- कार्यक्षमता
- कामकाज
- कार्यों
- धन
- आगे
- भावी सौदे
- अन्तर
- अंतराल
- इकट्ठा
- उत्पन्न
- उत्पन्न
- उत्पन्न करता है
- सृजन
- पीढ़ी
- उत्पादक
- जनरेटिव एआई
- जॉर्जिया
- मिल
- GitHub
- लक्ष्य
- जा
- बहुत
- अभूतपूर्व
- नींव
- विकास
- गाइड
- था
- हैंडलिंग
- हुआ
- हानिकारक
- दोहन
- है
- he
- स्वास्थ्य
- स्वास्थ्य सेवा
- मदद
- मदद करता है
- हाई
- हाइलाइट
- हाइकिंग
- उसके
- इतिहास
- पकड़
- पकड़े
- कैसे
- तथापि
- एचटीएमएल
- HTTPS
- मानव
- मानव बुद्धि
- सैकड़ों
- शिकार
- i
- आईबीएम
- आईसीएलआर
- आदर्श
- विचारों
- पहचान
- पहचान करना
- पहचान
- आईईईई
- if
- इलेनॉइस
- दिखाता है
- की छवि
- छवियों
- लागू करने के
- निहितार्थ
- आयात
- महत्वपूर्ण
- में सुधार
- उन्नत
- सुधार
- सुधार
- में सुधार लाने
- in
- अन्य में
- ग़लत
- शामिल
- शामिल
- सहित
- सम्मिलित
- निगमित
- को शामिल किया गया
- शामिल
- बढ़ना
- वृद्धि हुई
- बढ़ती
- स्वतंत्र
- अनुक्रमणिका
- अनुक्रमणिका
- व्यक्ति
- करें-
- जानकारी निकासी
- आरंभ
- अभिनव
- निवेश
- निविष्टियां
- पूछताछ
- जांच
- उदाहरण
- बजाय
- निर्देश
- अभिन्न
- एकीकृत
- घालमेल
- एकीकरण
- बुद्धि
- बुद्धिमान
- बुद्धिमान दस्तावेज़ प्रसंस्करण
- बातचीत
- बातचीत
- बातचीत
- बातचीत
- इंटरैक्टिव
- इंटरफेस
- मध्यवर्ती
- में
- शुरू करने
- अंतर्ज्ञान
- सहज ज्ञान युक्त
- जांच
- शामिल
- मुद्दों
- IT
- यात्रा
- आईटी इस
- खुद
- जेपीजी
- जेपी मॉर्गन
- जेपी मॉर्गन चेस
- JSON
- केवल
- कुंजी
- जानना
- ज्ञान
- जानने वाला
- लैब्स
- रंग
- भाषा
- बड़ा
- देर से
- बाद में
- लेज
- नेतृत्व
- प्रमुख
- जानें
- सीख रहा हूँ
- कम से कम
- विरासत
- कम
- li
- पुस्तकालय
- झूठ
- पसंद
- संभावित
- सीमाओं
- सीमित
- लाइन
- लिंक
- चलनिधि
- सूची
- सूचियाँ
- लोडर
- स्थानीय
- स्थानीय स्तर पर
- लॉगिंग
- लंबे समय तक
- देखिए
- प्यार करता है
- निम्न
- मशीन
- यंत्र अधिगम
- मशीनें
- बनाया गया
- का कहना है
- बनाना
- निर्माण
- प्रबंधन
- कामयाब
- प्रबंध
- प्रबंधन प्रणाली
- प्रबंधक
- प्रबंधकीय
- प्रबंध
- गाइड
- बहुत
- मार्च
- बाजार
- बाजार
- विशाल
- मास्टर
- मास्टर की
- मिलान
- अधिकतम करने के लिए
- मई..
- सार्थक
- साधन
- तंत्र
- मीडिया
- सदस्य
- याद
- सलाह
- message
- संदेश
- मेटाडाटा
- तरीका
- तरीकों
- कम से कम
- मिनट
- कुप्रबंध
- लापता
- शमन
- ML
- आदर्श
- मॉडल
- मॉड्यूलर
- मॉड्यूल
- धन
- महीना
- अधिक
- अधिक कुशल
- और भी
- अधिकांश
- विभिन्न
- चाहिए
- नाम
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा को समझना
- आवश्यक
- आवश्यकता
- जरूरत
- की जरूरत है
- नया
- NLP
- प्रसिद्ध
- उपन्यास
- अभी
- संख्या
- numpy
- उद्देश्य
- उद्देश्य
- प्राप्त
- प्राप्त
- हुआ
- ओसीआर
- of
- बंद
- ऑफर
- on
- ONE
- लोगों
- चल रहे
- केवल
- खुला स्रोत
- OpenAI
- उद्घाटन
- संचालित
- विरोधी
- प्रकाशीय
- ऑप्टिकल कैरेक्टर पहचान
- ऑप्टिमाइज़ करें
- or
- आदेश
- संगठनों
- मूल
- OS
- अन्य
- हमारी
- आउट
- परिणाम
- परिणामों
- उत्पादन
- बाहर
- के ऊपर
- कुल
- काबू
- अपना
- पृष्ठ
- काग़ज़
- कागजात
- समानांतर
- पैरामीटर
- भागों
- आवेशपूर्ण
- अतीत
- पथ
- पीडीएफ
- निष्पादन
- प्रदर्शन
- तस्वीरें
- टुकड़े
- पाइपलाइन
- जगह
- प्लेटफार्म
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- कृप्या अ
- अंक
- लोकप्रिय
- पदों
- पद
- संभावित
- शक्तिशाली
- ठीक
- शुद्धता
- Predictor
- प्रस्तुत
- को रोकने के
- पिछला
- प्रिंसिपल
- पूर्व
- प्राथमिकता
- प्राथमिकता
- एकांत
- गोपनीयता और सुरक्षा
- निजी
- मुसीबत
- समस्या को सुलझाना
- प्रक्रिया
- प्रक्रियाओं
- प्रसंस्करण
- उत्पादन
- एस्ट्रो मॉल
- उत्पादक
- उत्पादकता
- प्रगति
- वादा
- होनहार
- उचित
- बशर्ते
- प्रदाता
- प्रदाताओं
- प्रदान करता है
- प्रदान कर
- मनोविज्ञान (साइकोलॉजी)
- सार्वजनिक
- सार्वजनिक स्वास्थ्य
- प्रकाशनों
- प्रकाशित
- उद्देश्य
- प्रयोजनों
- pytorch
- क्यू एंड ए
- गुणवत्ता
- प्रश्नों
- प्रश्न
- प्रशन
- त्वरित
- तेज
- लेकर
- रैंकिंग
- बल्कि
- रे
- पढ़ना
- वास्तविक
- वास्तविक समय
- प्राप्तियों
- प्राप्त
- हाल
- मान्यता
- को कम करने
- घटी
- रिफाइनिंग
- नियम
- सम्बंधित
- प्रासंगिक
- विश्वसनीय
- रिलायंस
- बाकी है
- याद रखने के
- renders
- पुनर्निर्माण
- प्रतिनिधित्व
- प्रतिनिधित्व
- प्रतिनिधित्व
- गणतंत्र
- का अनुरोध
- आवश्यकताएँ
- अनुसंधान
- शोधकर्ता
- रिज़र्व
- भंडार
- संकल्प
- प्रतिक्रिया
- प्रतिक्रिया
- प्रतिक्रियाएं
- जिम्मेदार
- उत्तरदायी
- परिणाम
- जिसके परिणामस्वरूप
- परिणाम
- वापसी
- क्रांतिकारी बदलाव
- क्रांति
- जोखिम
- मजबूत
- लगभग
- रन
- रयान
- s
- सुरक्षित
- sagemaker
- वही
- सहेजें
- अनुमापकता
- विज्ञान
- वैज्ञानिक
- वैज्ञानिकों
- खरोंच
- Search
- search engine
- खोज इंजन
- सेक्टर्स
- सुरक्षा
- सुरक्षा उल्लंघनों
- देखना
- खंड
- चयनित
- स्व
- वरिष्ठ
- वाक्य
- अलग
- अनुक्रम
- अनुक्रमण
- कई
- सेवा
- कार्य करता है
- सेवा
- सेवाएँ
- सेट
- कई
- sharding
- वह
- चाहिए
- प्रदर्शन
- दिखाता है
- हस्ताक्षर
- महत्वपूर्ण
- काफी
- सिलिकॉन
- सिलिकॉन वैली
- सिलिकॉन वैली बैंक
- समान
- सरल
- केवल
- एक
- आकार
- छोटे
- सुचारू रूप से
- सोशल मीडिया
- सोशल मीडिया
- समाधान
- समाधान ढूंढे
- सूत्रों का कहना है
- रिक्त स्थान
- वक्ताओं
- विशेषज्ञ
- विशेषीकृत
- विशेष रूप से
- विशिष्ट
- विशेष रूप से
- स्पेक्ट्रम
- भाषण
- वाक् पहचान
- खर्च
- विभाजित
- विभाजन
- कर्मचारी
- हितधारकों
- स्टैंडअलोन
- शुरू
- राज्य
- स्थिति
- कदम
- फिर भी
- की दुकान
- संग्रहित
- भंडार
- रणनीतियों
- धारा
- स्ट्रीमिंग
- सुवीही
- व्यवस्थित बनाने
- तार
- छात्र
- स्टूडियो
- पर्याप्त
- सफलता
- सफल
- सफलतापूर्वक
- ऐसा
- संक्षेप में प्रस्तुत करना
- बेहतर
- समर्थन करता है
- आसपास के
- उपयुक्त
- कृपया
- प्रणाली
- सिस्टम
- लेना
- ले जा
- कार्य
- कार्य
- टीम
- तकनीक
- तकनीकी
- तकनीक
- टेक्नोलॉजीज
- टैकनोलजिस्ट
- टेक्नोलॉजी
- शर्तों
- से
- कि
- RSI
- खिलाया
- जानकारी
- दुनिया
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- विचारधारा
- तीसरे दल
- इसका
- उन
- विचार
- यहाँ
- भर
- बंधा होना
- पहर
- बहुत समय लगेगा
- समय
- सेवा मेरे
- टोकन
- परंपरागत
- प्रशिक्षित
- प्रशिक्षण
- बदालना
- परिवर्तनकारी
- तब्दील
- ट्रान्सफ़ॉर्मर
- <strong>उद्देश्य</strong>
- कोशिश
- दो
- टाइप
- प्रकार
- अंत में
- असमर्थ
- समझना
- समझ
- समझ लिया
- एकीकृत
- इकाई
- विश्वविद्यालय
- अनलॉक
- आधुनिकतम
- अपडेट
- अपलोड हो रहा है
- अति आवश्यक
- यूआरएल
- us
- प्रयोग
- उपयोग
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ता अनुभव
- उपयोगकर्ता के अनुकूल
- उपयोगकर्ताओं
- का उपयोग
- उपयोगिता
- उपयोग
- इस्तेमाल
- वैधता
- घाटी
- मूल्यवान
- विभिन्न
- व्यापक
- सत्यापित
- के माध्यम से
- वीडियो
- वीडियो
- वास्तविक
- महत्वपूर्ण
- आवाज़
- मौखिक आदेश
- संस्करणों
- W
- था
- मार्ग..
- we
- धन
- वेब
- वेब सेवाओं
- कुंआ
- थे
- क्या
- कब
- कौन कौन से
- जब
- मर्जी
- साथ में
- अंदर
- बिना
- जीत लिया
- शब्द
- शब्द
- काम
- वर्कफ़्लो
- workflows
- काम कर रहे
- कार्य
- विश्व
- होगा
- साल
- नर्म
- इसलिए आप
- आपका
- जेफिरनेट