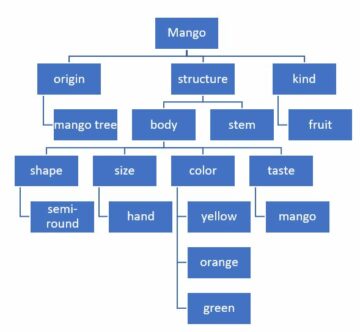
परिचय
हमने एआई और डीप लर्निंग के लिए कुछ फैंसी शब्द देखे हैं, जैसे कि पूर्व-प्रशिक्षित मॉडल, ट्रांसफर लर्निंग, आदि। मैं आपको व्यापक रूप से इस्तेमाल की जाने वाली तकनीक और सबसे महत्वपूर्ण और प्रभावी में से एक के साथ शिक्षित करता हूं: YOLOv5 के साथ ट्रांसफर लर्निंग।
यू ओनली लुक वंस, या योलो सबसे व्यापक रूप से उपयोग की जाने वाली गहन शिक्षण-आधारित वस्तु पहचान विधियों में से एक है। एक कस्टम डेटासेट का उपयोग करते हुए, यह आलेख आपको दिखाएगा कि इसकी सबसे हालिया विविधताओं में से एक YOLOv5 को कैसे प्रशिक्षित किया जाए।
सीखने के मकसद
- यह लेख मुख्य रूप से कस्टम डेटासेट कार्यान्वयन पर YOLOv5 मॉडल के प्रशिक्षण पर केंद्रित होगा।
- हम देखेंगे कि पूर्व-प्रशिक्षित मॉडल क्या हैं और देखें कि ट्रांसफर लर्निंग क्या है।
- हम समझेंगे कि YOLOv5 क्या है और हम YOLO के संस्करण 5 का उपयोग क्यों कर रहे हैं।
तो, बिना समय बर्बाद किए, चलिए प्रक्रिया शुरू करते हैं
टेबल ऑफ़ कंटेंट
- पूर्व प्रशिक्षित मॉडल
- लर्निंग ट्रांसफर
- क्या और क्यों YOLOv5?
- ट्रांसफर लर्निंग में शामिल कदम
- कार्यान्वयन
- कुछ चुनौतियाँ जिनका आप सामना कर सकते हैं
- निष्कर्ष
पूर्व प्रशिक्षित मॉडल
आपने सुना होगा कि डेटा वैज्ञानिक "पूर्व प्रशिक्षित मॉडल" शब्द का व्यापक रूप से उपयोग करते हैं। यह समझाने के बाद कि एक गहन शिक्षण मॉडल/नेटवर्क क्या करता है, मैं इस शब्द की व्याख्या करूँगा। एक डीप लर्निंग मॉडल एक ऐसा मॉडल है जिसमें विभिन्न परतें एक साथ खड़ी होती हैं ताकि एक ही उद्देश्य की पूर्ति हो सके, जैसे कि वर्गीकरण, पता लगाना, आदि। डीप लर्निंग नेटवर्क उन्हें खिलाए गए डेटा में जटिल संरचनाओं की खोज करके सीखते हैं और एक फाइल में वेट को सेव करते हैं जो बाद में इसी तरह के कार्यों को करने के लिए उपयोग किया जाता है। पूर्व-प्रशिक्षित मॉडल पहले से ही प्रशिक्षित डीप लर्निंग मॉडल हैं। इसका मतलब यह है कि वे पहले से ही लाखों छवियों वाले विशाल डेटासेट पर प्रशिक्षित हैं।
यहाँ है कैसे TensorFlow वेबसाइट पूर्व-प्रशिक्षित मॉडल को परिभाषित करती है: एक पूर्व-प्रशिक्षित मॉडल एक सहेजा गया नेटवर्क है जिसे पहले बड़े डेटासेट पर प्रशिक्षित किया गया था, आमतौर पर बड़े पैमाने पर छवि-वर्गीकरण कार्य पर।
कुछ अत्यधिक अनुकूलित और असाधारण रूप से कुशल पूर्व प्रशिक्षित मॉडल इंटरनेट पर उपलब्ध हैं। विभिन्न कार्यों को करने के लिए विभिन्न मॉडलों का उपयोग किया जाता है। कुछ पूर्व-प्रशिक्षित मॉडल हैं VGG-16, VGG-19, YOLOv5, YOLOv3, और रेसनेट 50.
किस मॉडल का उपयोग करना है यह उस कार्य पर निर्भर करता है जिसे आप करना चाहते हैं। उदाहरण के लिए, यदि मैं एक प्रदर्शन करना चाहता हूं वस्तु का पता लगाना कार्य, मैं YOLOv5 मॉडल का उपयोग करूंगा।
लर्निंग ट्रांसफर
लर्निंग ट्रांसफर सबसे महत्वपूर्ण तकनीक है जो डेटा वैज्ञानिक के कार्य को आसान बनाती है। एक मॉडल का प्रशिक्षण एक भारी और समय लेने वाला कार्य है; यदि किसी मॉडल को खरोंच से प्रशिक्षित किया जाता है, तो यह आमतौर पर बहुत अच्छे परिणाम नहीं देता है। यहां तक कि अगर हम एक पूर्व-प्रशिक्षित मॉडल के समान मॉडल को प्रशिक्षित करते हैं, तो यह उतना प्रभावी ढंग से प्रदर्शन नहीं करेगा, और एक मॉडल को प्रशिक्षित होने में कई सप्ताह लग सकते हैं। इसके बजाय, हम पूर्व-प्रशिक्षित मॉडल का उपयोग कर सकते हैं और समान कार्य करने के लिए कस्टम डेटासेट पर उन्हें प्रशिक्षित करके पहले से सीखे गए वज़न का उपयोग कर सकते हैं। ये मॉडल वास्तुकला और प्रदर्शन के मामले में अत्यधिक कुशल और परिष्कृत हैं, और उन्होंने विभिन्न प्रतियोगिताओं में बेहतर प्रदर्शन करके शीर्ष पर अपनी जगह बनाई है। इन मॉडलों को बहुत बड़ी मात्रा में डेटा पर प्रशिक्षित किया जाता है, जिससे उन्हें ज्ञान में अधिक विविधता मिलती है।
इसलिए सीखने को स्थानांतरित करने का मूल रूप से पिछले डेटा पर मॉडल को प्रशिक्षित करके प्राप्त ज्ञान को स्थानांतरित करना है ताकि मॉडल को एक अलग लेकिन समान कार्य करने के लिए बेहतर और तेज़ी से सीखने में मदद मिल सके।
उदाहरण के लिए, ऑब्जेक्ट डिटेक्शन के लिए YOLOv5 का उपयोग करना, लेकिन ऑब्जेक्ट ऑब्जेक्ट द्वारा उपयोग किए गए पिछले डेटा के अलावा कुछ और है।
क्या और क्यों YOLOv5?
YOLOv5 एक पूर्व-प्रशिक्षित मॉडल है जो आपके लिए केवल एक बार देखने के लिए खड़ा है संस्करण 5 वास्तविक समय वस्तु का पता लगाने के लिए उपयोग किया जाता है और सटीकता और अनुमान समय के मामले में अत्यधिक कुशल साबित हुआ है। YOLO के अन्य संस्करण हैं, लेकिन जैसा कि कोई भविष्यवाणी करेगा, YOLOv5 अन्य संस्करणों की तुलना में बेहतर प्रदर्शन करता है। YOLOv5 तेज और उपयोग में आसान है। यह PyTorch फ्रेमवर्क पर आधारित है, जिसमें Yolo v4 Darknet से बड़ा समुदाय है।
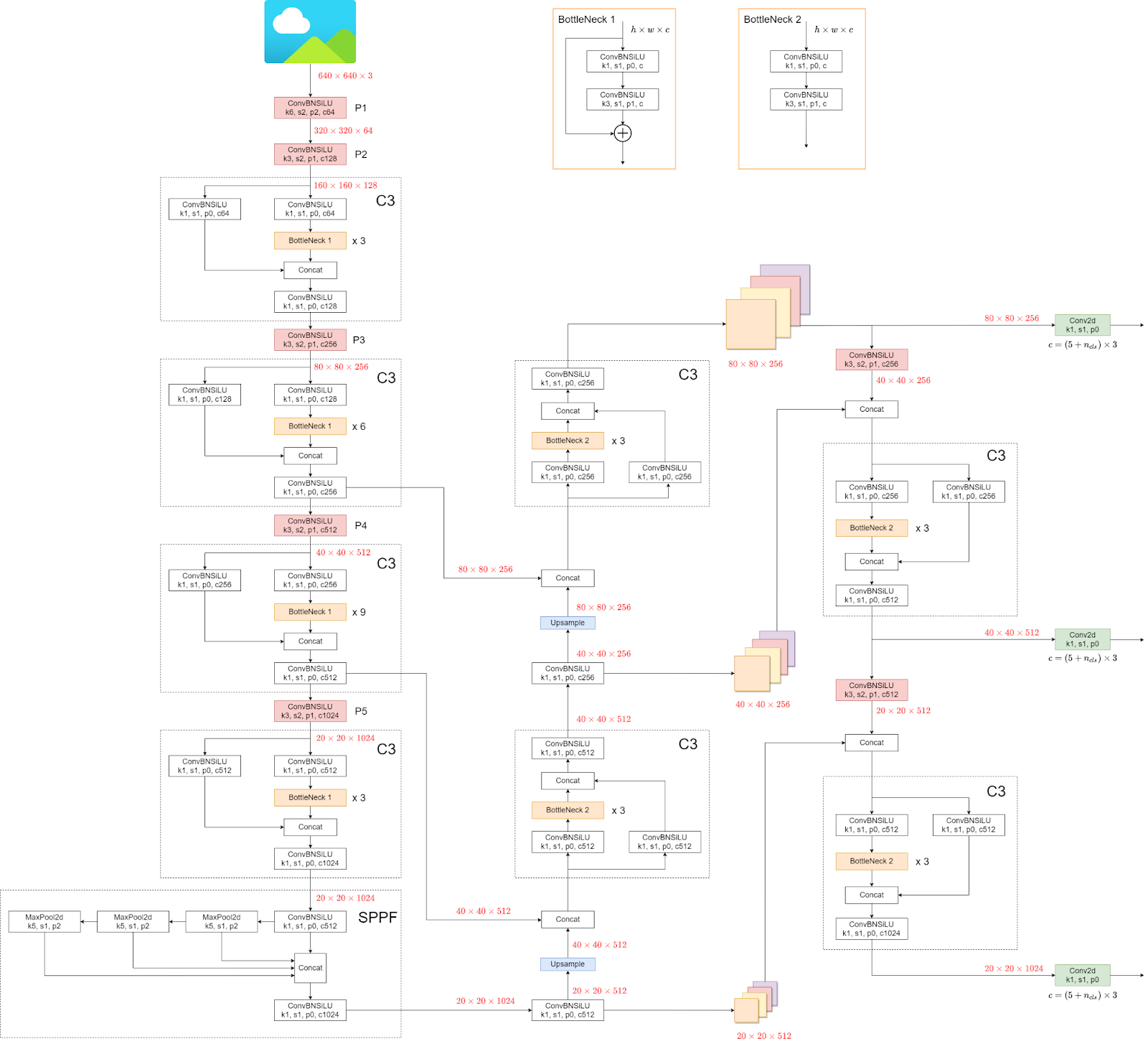
अब हम YOLOv5 के आर्किटेक्चर को देखेंगे।
संरचना भ्रामक लग सकती है, लेकिन इससे कोई फर्क नहीं पड़ता क्योंकि हमें आर्किटेक्चर को देखने के बजाय सीधे मॉडल और वज़न का उपयोग करना पड़ता है।
ट्रांसफर लर्निंग में, हम कस्टम डेटासेट का उपयोग करते हैं, यानी वह डेटा जिसे मॉडल ने पहले कभी नहीं देखा है या वह डेटा जिस पर मॉडल प्रशिक्षित नहीं है। चूंकि मॉडल पहले से ही बड़े डेटासेट पर प्रशिक्षित है, इसलिए हमारे पास पहले से ही वज़न है। अब हम जिस डेटा पर काम करना चाहते हैं, उस पर कई युगों के लिए मॉडल को प्रशिक्षित कर सकते हैं। प्रशिक्षण की आवश्यकता है क्योंकि मॉडल ने पहली बार डेटा देखा है और कार्य करने के लिए कुछ ज्ञान की आवश्यकता होगी।
ट्रांसफर लर्निंग में शामिल कदम
ट्रांसफर लर्निंग एक सरल प्रक्रिया है, और हम इसे कुछ सरल चरणों में कर सकते हैं:
- डेटा तैयारी
- एनोटेशन के लिए सही प्रारूप
- यदि आप चाहें तो कुछ परतें बदलें
- कुछ पुनरावृत्तियों के लिए मॉडल को पुनः प्रशिक्षित करें
- मान्य / परीक्षण
डेटा तैयारी
यदि आपका चुना हुआ डेटा थोड़ा बड़ा है तो डेटा तैयार करने में समय लग सकता है। डेटा तैयारी का अर्थ है छवियों की व्याख्या करना, जो एक ऐसी प्रक्रिया है जहाँ आप छवि में वस्तु के चारों ओर एक बॉक्स बनाकर छवियों को लेबल करते हैं। ऐसा करने से, चिन्हित वस्तु के निर्देशांक एक फ़ाइल में सहेजे जाएँगे जिसे बाद में प्रशिक्षण के लिए मॉडल को फीड किया जाएगा। कुछ वेबसाइटें हैं, जैसे अर्थ। एआई और roboflow.com, जो आपको डेटा को लेबल करने में मदद कर सकता है।
यहां बताया गया है कि आप YOLOv5 मॉडल के डेटा को Makesense.ai पर कैसे एनोटेट कर सकते हैं।
1. भेंट https://www.makesense.ai/.
2. स्क्रीन के नीचे दाईं ओर गेट स्टार्ट पर क्लिक करें।
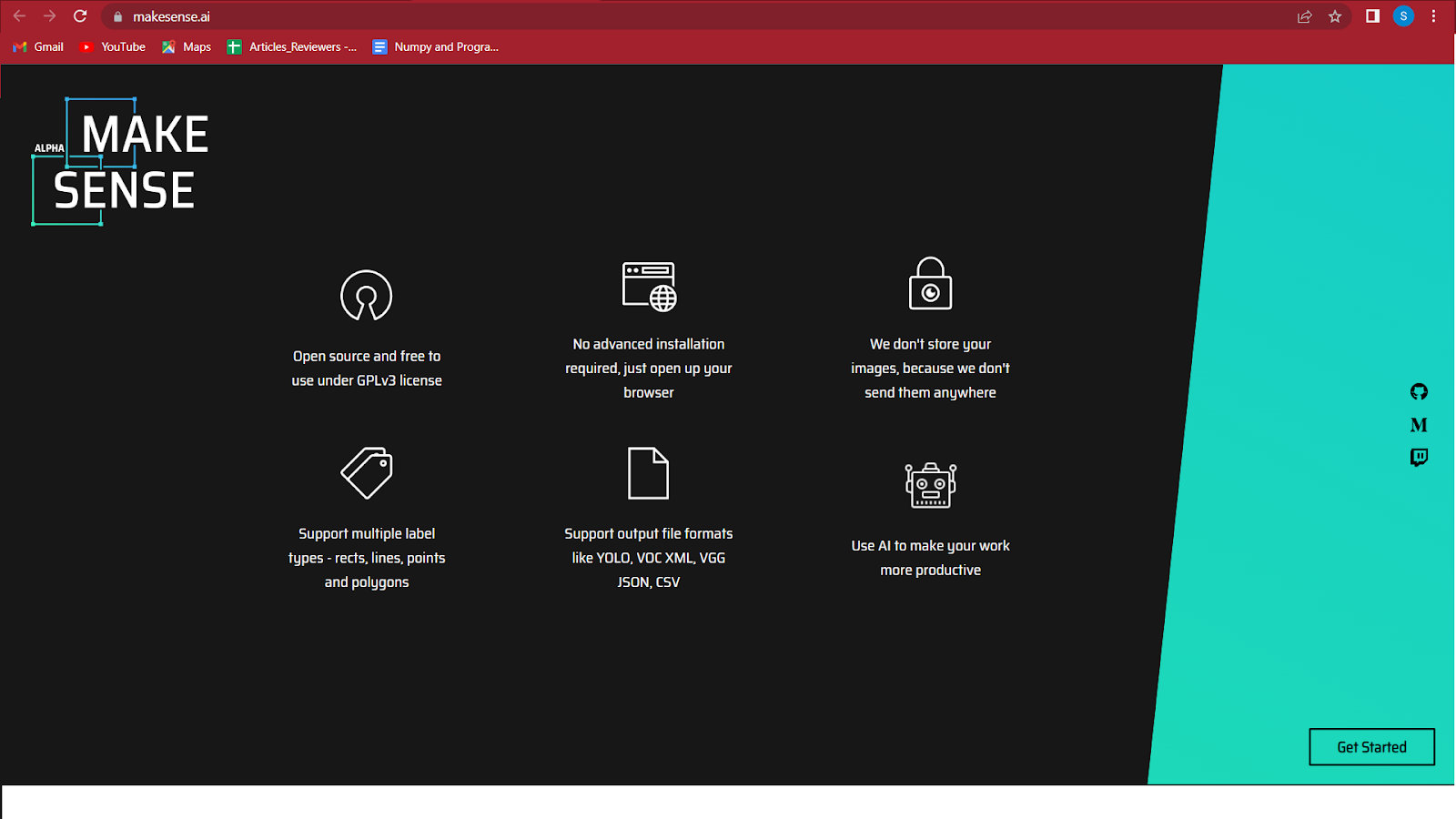
3. उन छवियों का चयन करें जिन्हें आप केंद्र में हाइलाइट किए गए बॉक्स पर क्लिक करके लेबल करना चाहते हैं।
उन छवियों को लोड करें जिन्हें आप एनोटेट करना चाहते हैं और ऑब्जेक्ट डिटेक्शन पर क्लिक करें।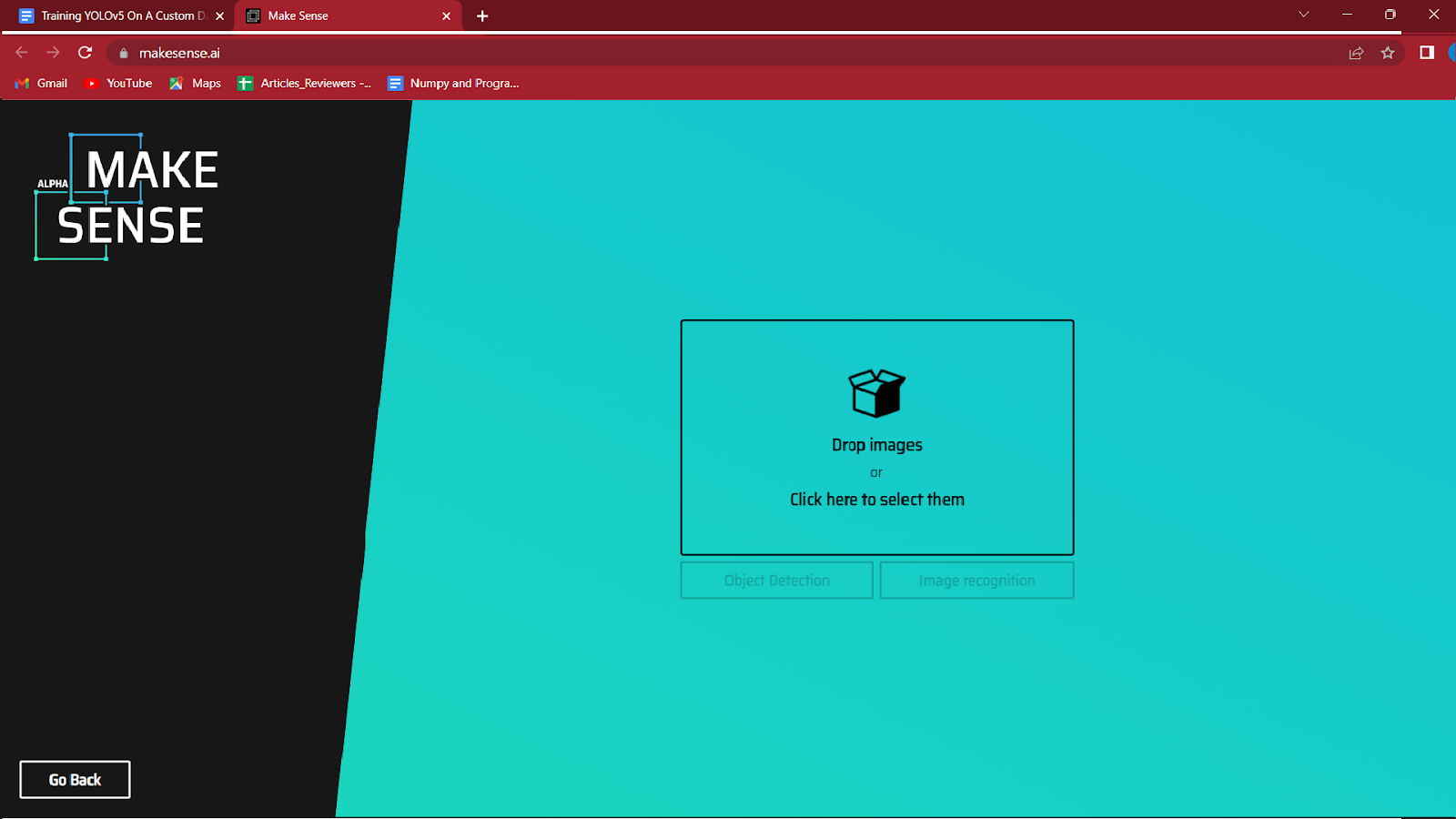
4. छवियों को लोड करने के बाद, आपको अपने डेटासेट के विभिन्न वर्गों के लिए लेबल बनाने के लिए कहा जाएगा।
मैं एक वाहन पर लाइसेंस प्लेट का पता लगा रहा हूं, इसलिए मैं केवल "लाइसेंस प्लेट" लेबल का उपयोग करूंगा। आप डायलॉग बॉक्स के बाईं ओर '+' बटन पर क्लिक करके केवल एंटर दबा कर और लेबल बना सकते हैं।
आपके द्वारा सभी लेबल बनाए जाने के बाद, स्टार्ट प्रोजेक्ट पर क्लिक करें।
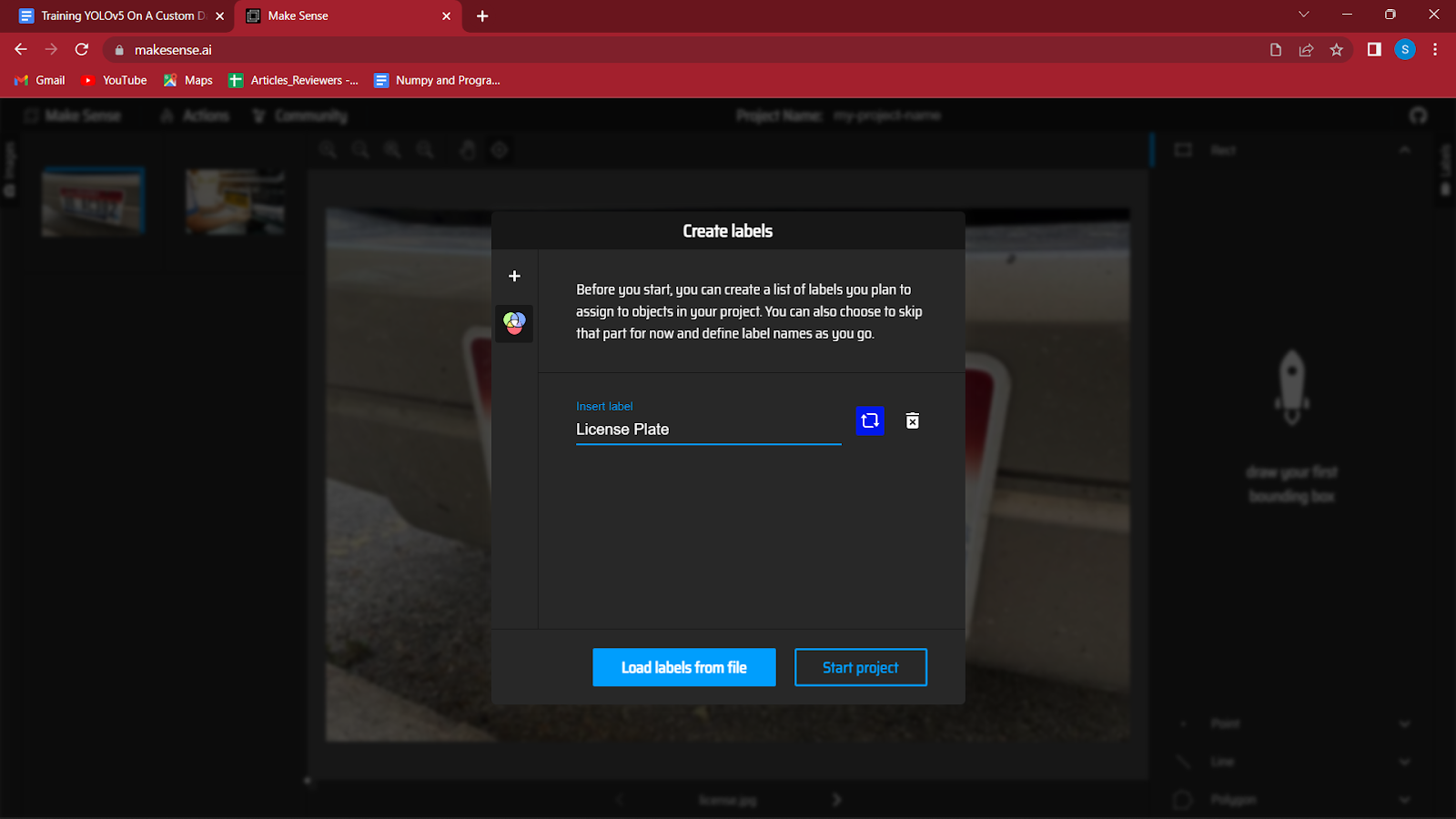
यदि आपसे कोई लेबल छूट गया है, तो आप उन्हें बाद में क्रियाओं पर क्लिक करके संपादित कर सकते हैं और फिर लेबल संपादित कर सकते हैं।
5. छवि में वस्तु के चारों ओर एक बाउंडिंग बॉक्स बनाना प्रारंभ करें। यह अभ्यास शुरू में थोड़ा मज़ेदार हो सकता है, लेकिन बहुत बड़े डेटा के साथ, यह थका देने वाला हो सकता है।
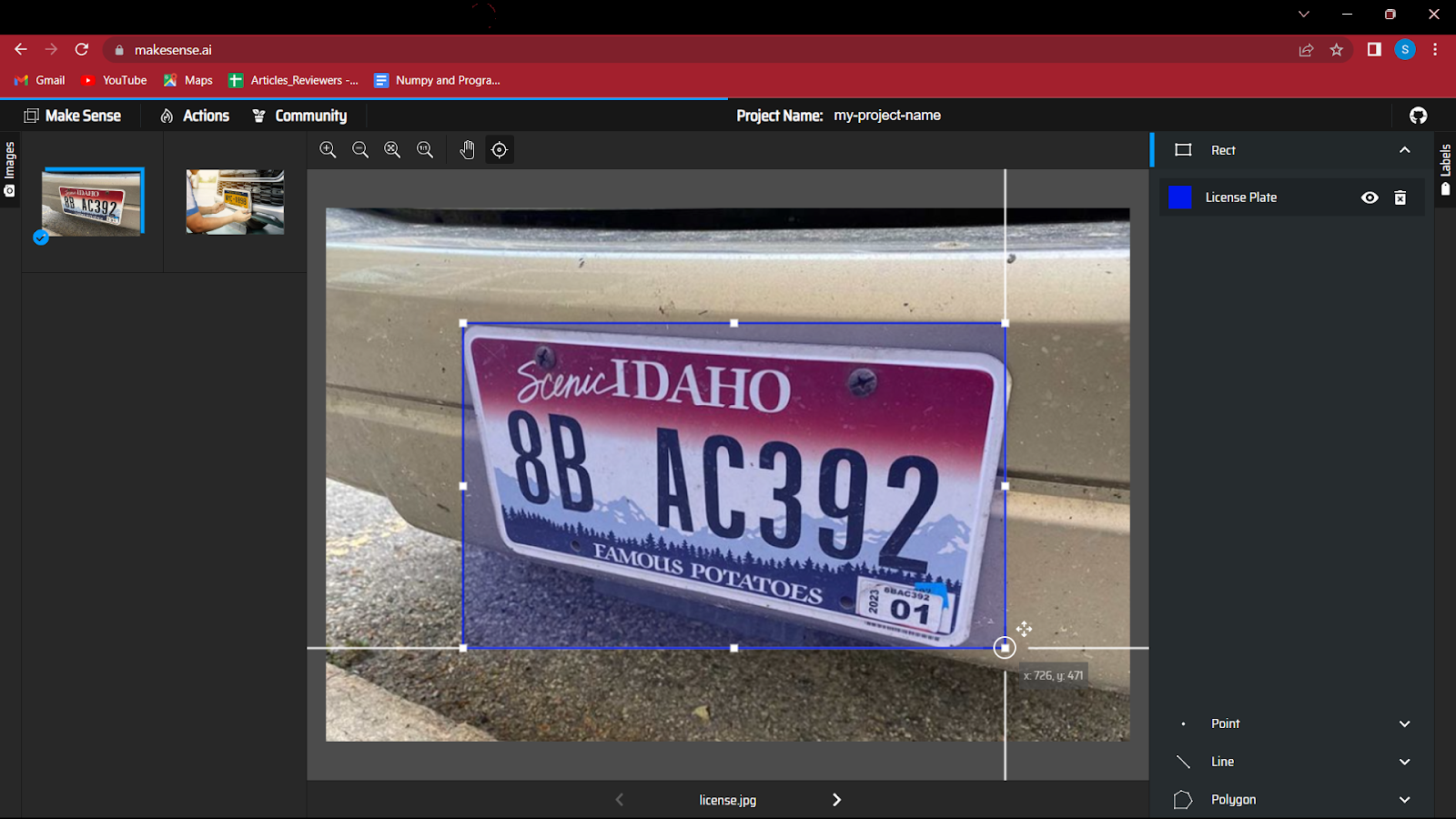
6. सभी छवियों को एनोटेट करने के बाद आपको उस फाइल को सेव करने की जरूरत है जिसमें क्लास के साथ बाउंडिंग बॉक्स के निर्देशांक होंगे।
इसलिए आपको एक्शन बटन पर जाना होगा और एक्सपोर्ट एनोटेशन पर क्लिक करना होगा, 'ए जिप पैकेज युक्त फाइल्स इन योलो फॉर्मेट' विकल्प को चेक करना न भूलें, क्योंकि यह फाइलों को सही फॉर्मेट में सेव करेगा जैसा कि योलो मॉडल में जरूरी है।
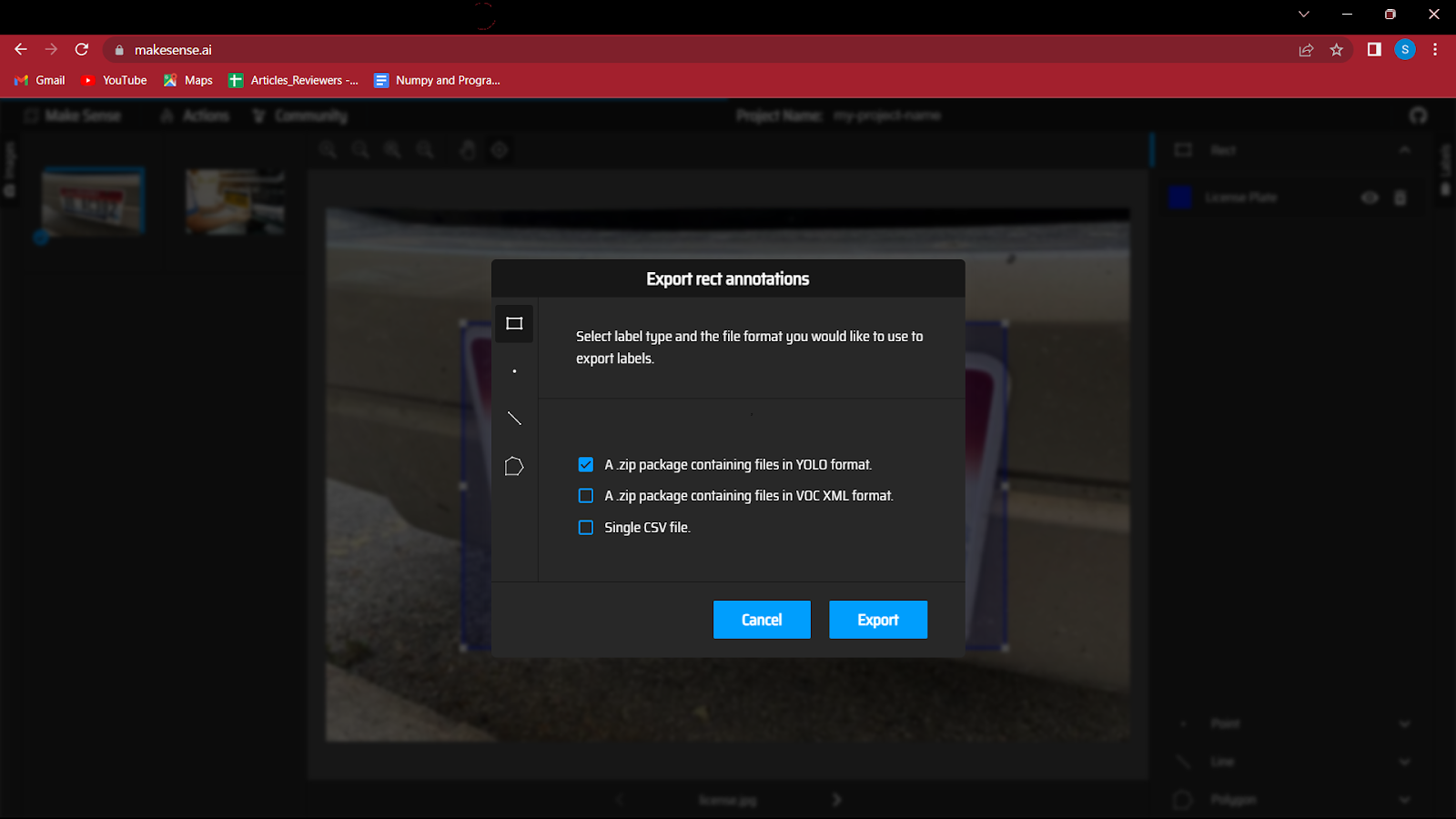
7. यह एक महत्वपूर्ण कदम है, इसलिए इसका सावधानी से पालन करें।
आपके पास सभी फाइलें और छवियां होने के बाद, किसी भी नाम से एक फ़ोल्डर बनाएं। फोल्डर पर क्लिक करें और फोल्डर के अंदर इमेज और लेबल नाम के साथ दो और फोल्डर बनाएं। फ़ोल्डर को ऊपर के समान नाम देना न भूलें, क्योंकि कमांड में प्रशिक्षण पथ फीड करने के बाद मॉडल स्वचालित रूप से लेबल की खोज करता है।
आपको फोल्डर का अंदाजा देने के लिए, मैंने 'कार्सडाटा' नाम का एक फोल्डर बनाया है और उस फोल्डर में दो फोल्डर - 'इमेज' और 'लेबल' बनाए हैं।
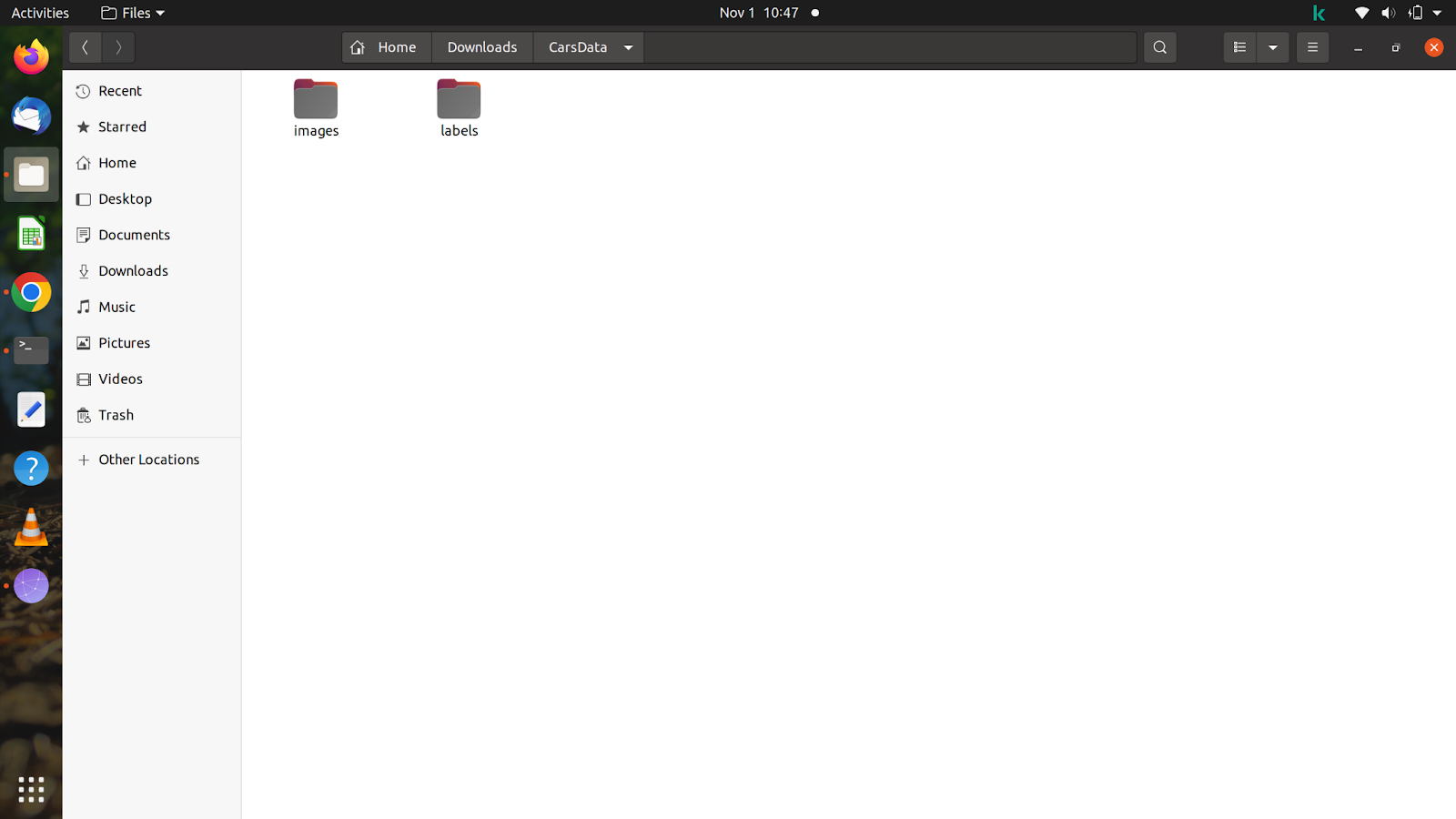
दो फोल्डर के अंदर आपको 'ट्रेन' और 'वैल' नाम के दो और फोल्डर बनाने हैं। इमेज फ़ोल्डर में, आप अपनी इच्छा के अनुसार छवियों को विभाजित कर सकते हैं, लेकिन लेबल को विभाजित करते समय आपको सावधान रहना होगा, क्योंकि लेबल आपके द्वारा विभाजित की गई छवियों से मेल खाना चाहिए
8. अब फोल्डर की एक जिप फाइल बनाएं और ड्राइव में अपलोड करें ताकि हम इसे कोलाब में इस्तेमाल कर सकें।
कार्यान्वयन
अब हम कार्यान्वयन भाग पर आएंगे, जो बहुत ही सरल लेकिन पेचीदा है। यदि आप नहीं जानते हैं कि कौन सी फाइलें वास्तव में बदलनी हैं, तो आप मॉडल को कस्टम डेटासेट पर प्रशिक्षित नहीं कर पाएंगे।
तो यहां वे कोड हैं जिनका आपको कस्टम डेटासेट पर YOLOv5 मॉडल को प्रशिक्षित करने के लिए पालन करना चाहिए
मेरा सुझाव है कि आप इस ट्यूटोरियल के लिए google colab का उपयोग करें क्योंकि यह GPU भी प्रदान करता है जो तेज़ संगणना प्रदान करता है।
1. गिट क्लोन https://github.com/ultralytics/yolov5
यह YOLOv5 रिपॉजिटरी की एक प्रति बना देगा जो अल्ट्रालाइटिक्स द्वारा बनाई गई GitHub रिपॉजिटरी है।
2. सीडी योलोव5
यह एक कमांड-लाइन शेल कमांड है जिसका उपयोग वर्तमान कार्यशील निर्देशिका को YOLOv5 निर्देशिका में बदलने के लिए किया जाता है।
3. पाइप इंस्टाल -r आवश्यकताएँ.txt
यह आदेश मॉडल के प्रशिक्षण में उपयोग किए जाने वाले सभी संकुल और पुस्तकालयों को स्थापित करेगा।
4. !unzip '/content/drive/MyDrive/CarsData.zip'
Google colab में छवियों और लेबल वाले फ़ोल्डर को अनज़िप करना
यहाँ सबसे महत्वपूर्ण कदम आता है ...
आपने अब लगभग सभी चरण पूरे कर लिए हैं और कोड की एक और पंक्ति लिखने की आवश्यकता है जो मॉडल को प्रशिक्षित करेगी, लेकिन, इससे पहले, आपको अपने कस्टम डेटासेट का पथ देने के लिए कुछ और चरणों को पूरा करने और कुछ निर्देशिकाओं को बदलने की आवश्यकता है और उस डेटा पर अपने मॉडल को प्रशिक्षित करें।
यहाँ है आपको क्या करने की जरूरत है।
उपरोक्त 4 चरणों को पूरा करने के बाद, आपके google colab में yolov5 फ़ोल्डर होगा। Yolov5 फोल्डर में जाएं, और 'डेटा' फोल्डर पर क्लिक करें। अब आपको 'coco128.yaml' नाम का फोल्डर दिखाई देगा।
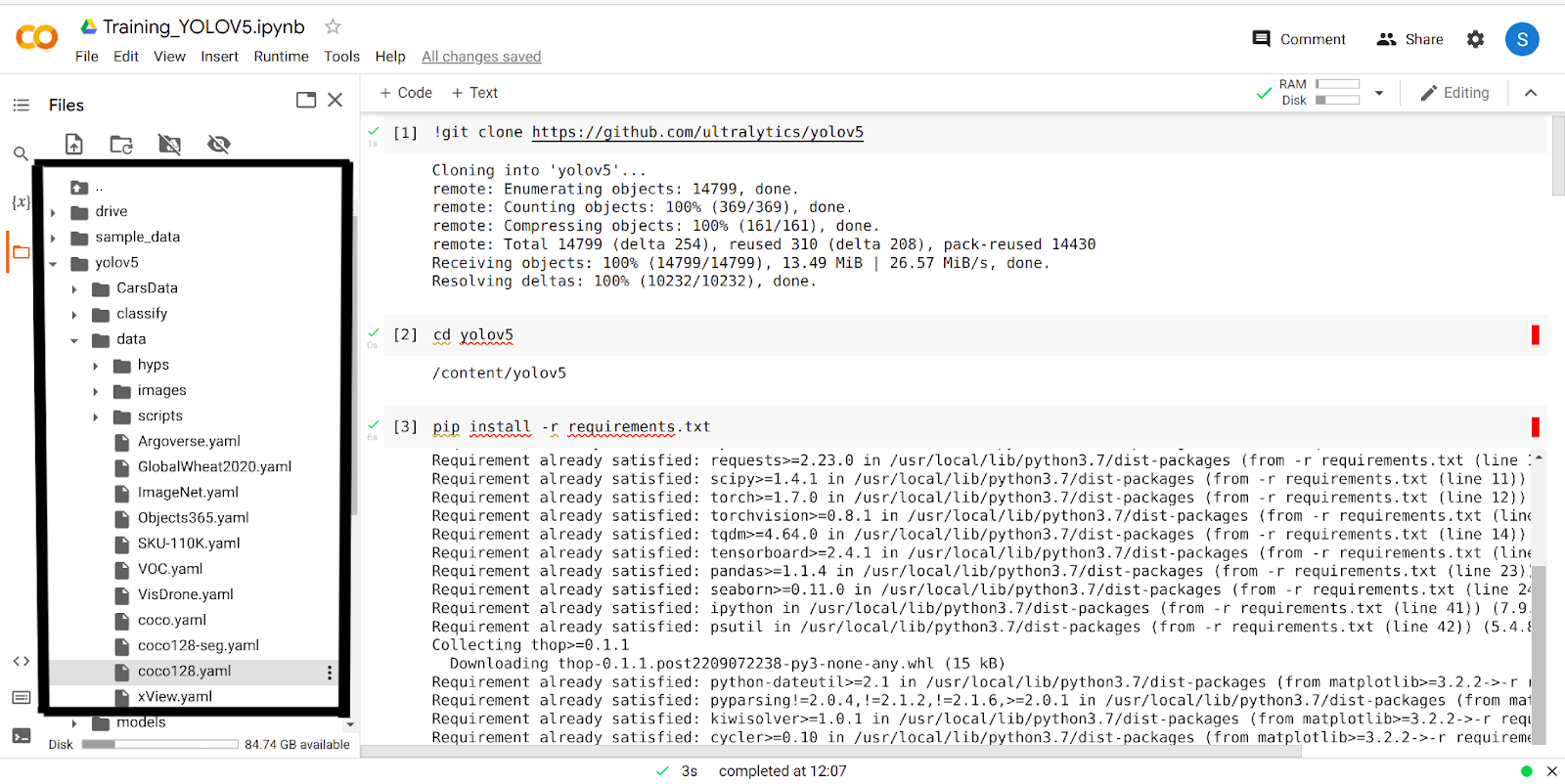
आगे बढ़ो और इस फ़ोल्डर को डाउनलोड करें।
फोल्डर डाउनलोड हो जाने के बाद, आपको इसमें कुछ बदलाव करने होंगे और इसे वापस उसी फोल्डर में अपलोड करना होगा, जिससे आपने इसे डाउनलोड किया था।
आइए अब हमारे द्वारा डाउनलोड की गई फ़ाइल की सामग्री को देखें, और यह कुछ इस तरह दिखेगी।
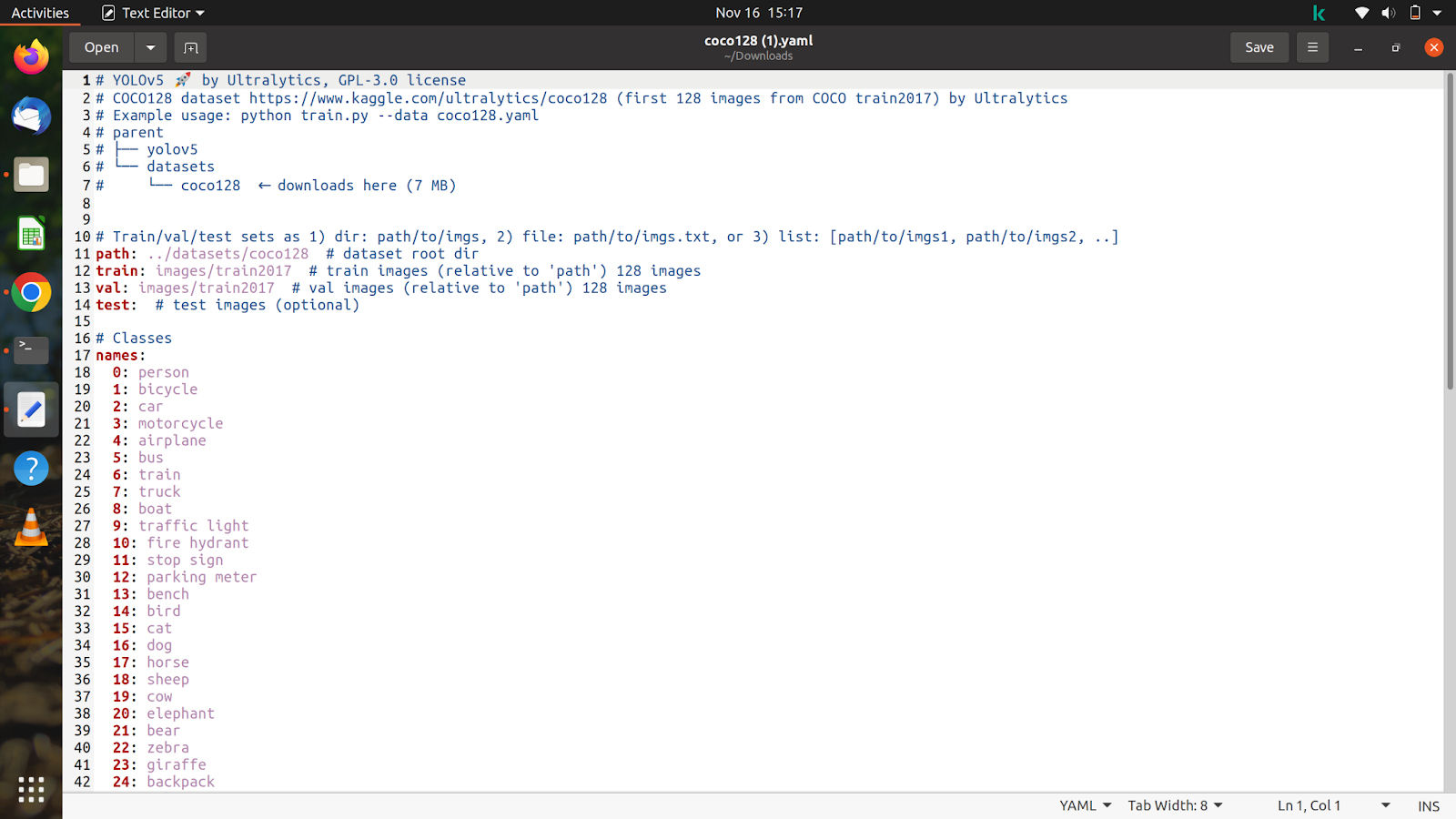
हम इस फ़ाइल को अपने डेटासेट और एनोटेशन के अनुसार कस्टमाइज़ करने जा रहे हैं।
हमने पहले ही कोलाब पर डेटासेट को अनज़िप कर दिया है, इसलिए हम अपनी ट्रेन के पाथ और वैलिडेशन इमेज को कॉपी करने जा रहे हैं। ट्रेन छवियों के पथ को कॉपी करने के बाद, जो डेटासेट फ़ोल्डर में होगा और कुछ इस तरह दिखता है '/content/yolov5/CarsData/images/train', इसे coco128.yaml फ़ाइल में पेस्ट करें, जिसे हमने अभी डाउनलोड किया है।
परीक्षण और सत्यापन छवियों के साथ भी ऐसा ही करें।
अब इसे पूरा करने के बाद, हम 'nc: 1' जैसे वर्गों की संख्या का उल्लेख करेंगे। इस मामले में वर्गों की संख्या केवल 1 है। फिर हम नाम का उल्लेख करेंगे जैसा कि नीचे दी गई छवि में दिखाया गया है। अन्य सभी वर्गों और टिप्पणी वाले भाग को हटा दें, जिसकी आवश्यकता नहीं है, जिसके बाद हमारी फ़ाइल कुछ इस तरह दिखनी चाहिए।
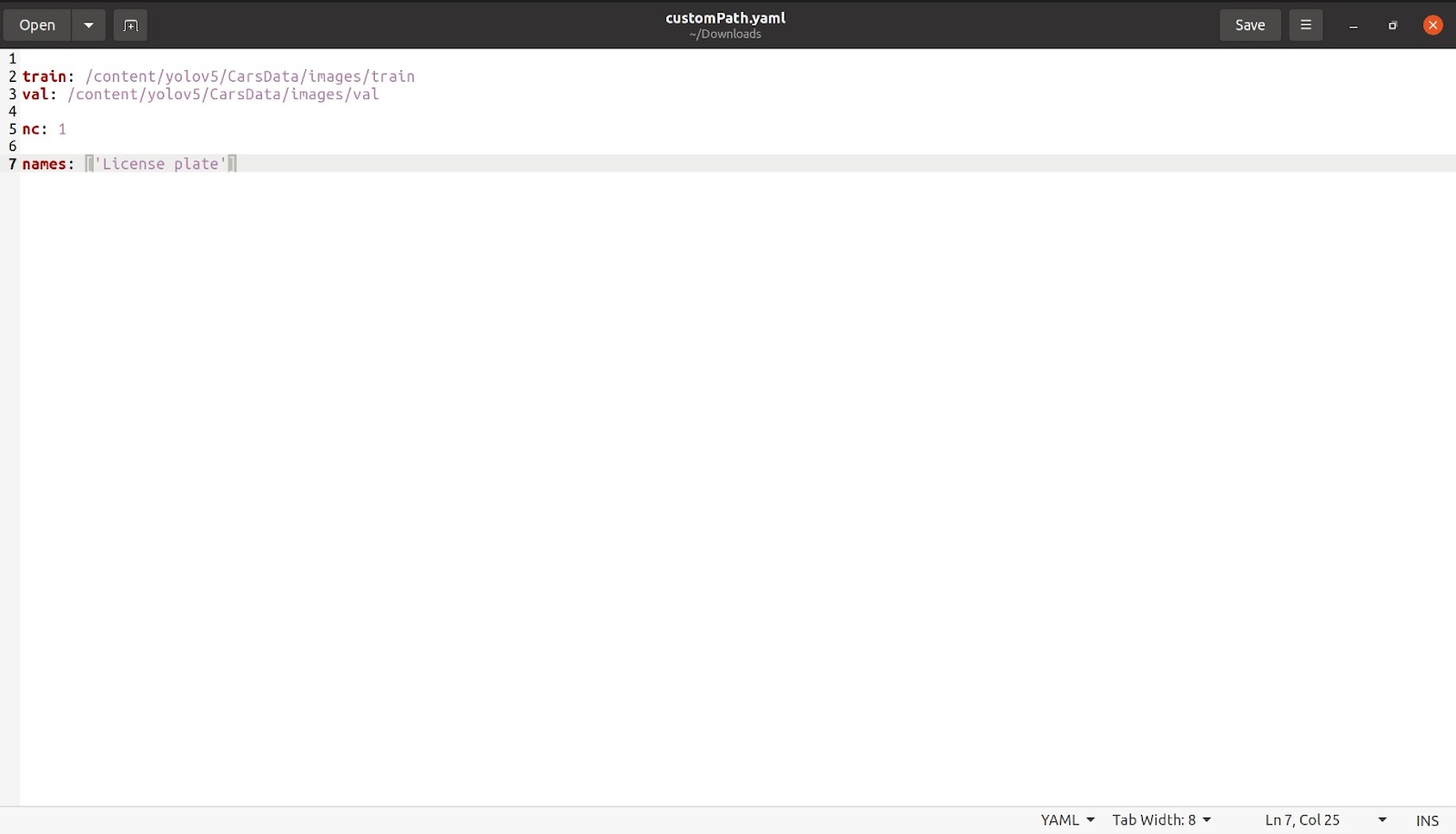
इस फाइल को अपने मनचाहे नाम से सेव करें। मैंने फ़ाइल को CustomPath.yaml नाम से सहेजा है और अब इस फ़ाइल को कोलाब में वापस उसी स्थान पर अपलोड करें जहाँ coco128.yaml था।
अब हम संपादन भाग के साथ कर चुके हैं और मॉडल को प्रशिक्षित करने के लिए तैयार हैं।
अपने कस्टम डेटासेट पर कुछ इंटरैक्शन के लिए अपने मॉडल को प्रशिक्षित करने के लिए निम्न कमांड चलाएँ।
आपके द्वारा अपलोड की गई फ़ाइल ('customPath.yaml) का नाम बदलना न भूलें। आप उन युगों की संख्या भी बदल सकते हैं जिन्हें आप मॉडल को प्रशिक्षित करना चाहते हैं। इस मामले में, मैं केवल 3 युगों के लिए मॉडल को प्रशिक्षित करने जा रहा हूँ।
5. अजगर train.py –img 640 –बैच 16 –epochs 10 –data /content/yolov5/customPath.yaml – weights yolov5s.pt
उस पथ को ध्यान में रखें जहाँ आप फ़ोल्डर अपलोड करते हैं। अगर रास्ता बदल दिया गया है, तो आदेश बिल्कुल काम नहीं करेंगे।
आपके द्वारा इस आदेश को चलाने के बाद, आपके मॉडल को प्रशिक्षण देना शुरू कर देना चाहिए और आपको अपनी स्क्रीन पर ऐसा कुछ दिखाई देगा।
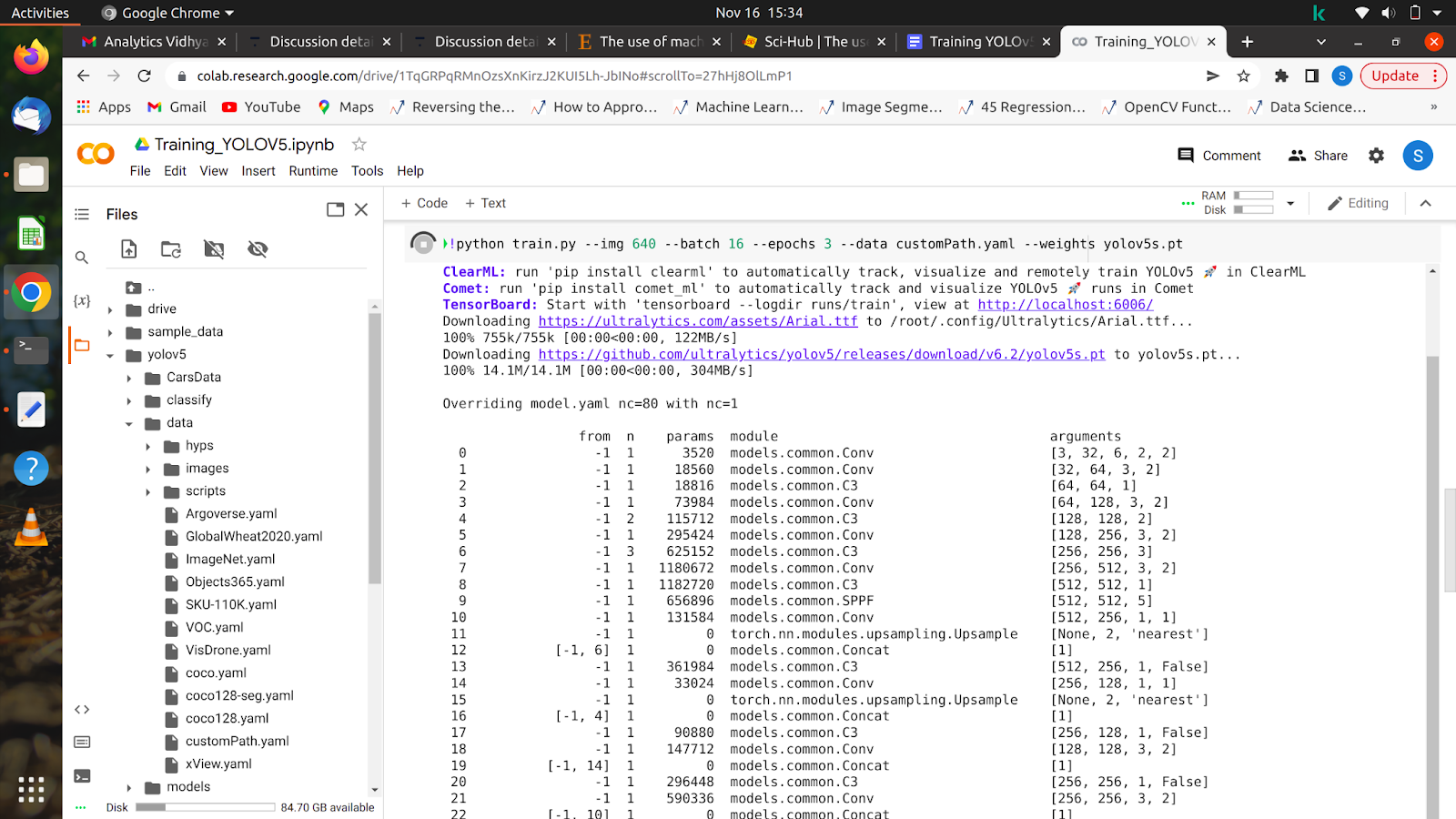
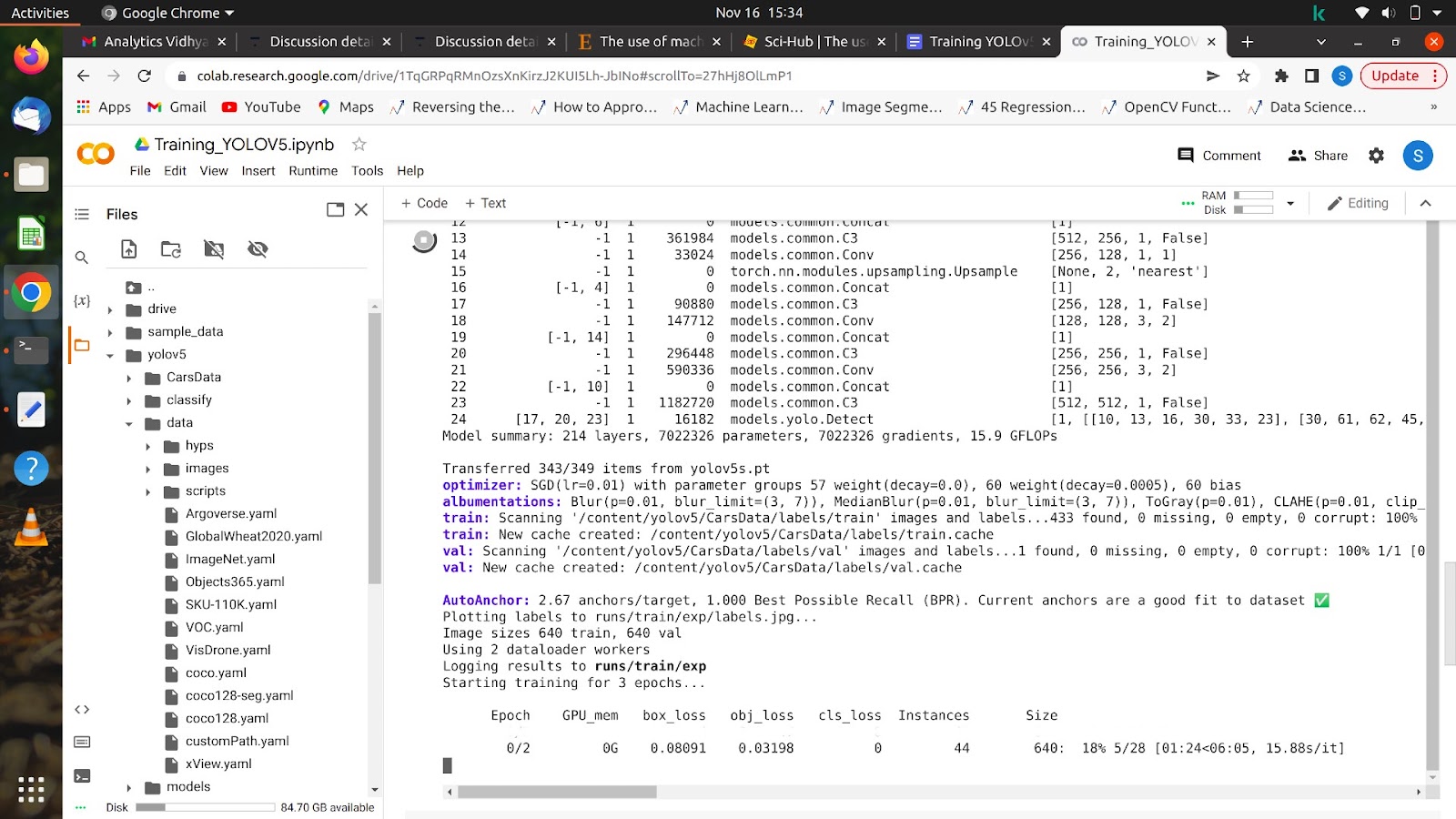
सभी युगों के पूरा होने के बाद, आपके मॉडल का परीक्षण किसी भी छवि पर किया जा सकता है।
आप क्या सहेजना चाहते हैं और क्या पसंद नहीं करते हैं, जहां लाइसेंस प्लेट का पता लगाया जाता है, आदि पर आप Detect.py फ़ाइल में कुछ और अनुकूलन कर सकते हैं।
6. अजगर का पता लगाने।
आप कुछ छवियों पर मॉडल की भविष्यवाणी का परीक्षण करने के लिए इस आदेश का उपयोग कर सकते हैं।
कुछ चुनौतियाँ जिनका आप सामना कर सकते हैं
हालाँकि ऊपर बताए गए कदम सही हैं, लेकिन अगर आप उनका ठीक से पालन नहीं करते हैं तो कुछ समस्याएं हैं जिनका आप सामना कर सकते हैं।
- गलत रास्ता: यह सिरदर्द या समस्या हो सकती है। यदि आपने छवि को प्रशिक्षित करने में कहीं गलत रास्ते पर प्रवेश किया है, तो इसे पहचानना आसान नहीं होगा और आप मॉडल को प्रशिक्षित नहीं कर पाएंगे।
- लेबल का गलत प्रारूप: यह एक YOLOv5 को प्रशिक्षित करते समय लोगों द्वारा सामना की जाने वाली एक व्यापक समस्या है। मॉडल केवल एक प्रारूप को स्वीकार करता है जिसमें प्रत्येक छवि की अपनी टेक्स्ट फ़ाइल होती है जिसमें वांछित प्रारूप होता है। अक्सर, एक XLS प्रारूप फ़ाइल या एक एकल CSV फ़ाइल नेटवर्क को फीड की जाती है, जिसके परिणामस्वरूप त्रुटि होती है। यदि आप कहीं से डेटा डाउनलोड कर रहे हैं, तो प्रत्येक छवि को एनोटेट करने के बजाय, एक अलग फ़ाइल स्वरूप हो सकता है जिसमें लेबल सहेजे जाते हैं। यहाँ XLS प्रारूप को YOLO प्रारूप में बदलने के लिए एक लेख दिया गया है। (लेख पूरा होने के बाद लिंक)।
- फाइलों का सही नामकरण नहीं करना: फाइल का सही नामकरण नहीं करने से फिर से एक त्रुटि हो जाएगी। फ़ोल्डर्स का नामकरण करते समय चरणों पर ध्यान दें और इस त्रुटि से बचें।
निष्कर्ष
इस लेख में, हमने सीखा कि ट्रांसफर लर्निंग क्या है और पूर्व-प्रशिक्षित मॉडल क्या है। हमने सीखा कि कब और क्यों YOLOv5 मॉडल का उपयोग करना है और मॉडल को कस्टम डेटासेट पर कैसे प्रशिक्षित करना है। हम डेटासेट तैयार करने से लेकर पथ बदलने और अंत में तकनीक के कार्यान्वयन में नेटवर्क को फीड करने तक, प्रत्येक चरण से गुजरे, और चरणों को अच्छी तरह से समझा। हमने YOLOv5 को प्रशिक्षित करते समय आने वाली सामान्य समस्याओं और उनके समाधान पर भी ध्यान दिया। मुझे उम्मीद है कि इस लेख ने आपको अपने पहले YOLOv5 को एक कस्टम डेटासेट पर प्रशिक्षित करने में मदद की और आपको लेख पसंद आया।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- योग्य
- ऊपर
- स्वीकार करता है
- अनुसार
- शुद्धता
- कार्रवाई
- बाद
- आगे
- AI
- सब
- पहले ही
- राशियाँ
- और
- स्थापत्य
- चारों ओर
- लेख
- ध्यान
- स्वतः
- उपलब्ध
- से बचने
- वापस
- आधारित
- मूल रूप से
- से पहले
- नीचे
- बेहतर
- बिट
- तल
- मुक्केबाज़ी
- बक्से
- बटन
- सावधान
- सावधानी से
- मामला
- CD
- केंद्र
- चुनौतियों
- परिवर्तन
- परिवर्तन
- बदलना
- चेक
- करने के लिए चुना
- कक्षा
- कक्षाएं
- वर्गीकरण
- कोड
- कैसे
- टिप्पणी
- सामान्य
- समुदाय
- पूरा
- समापन
- जटिल
- संगणना
- भ्रमित
- शामिल हैं
- सामग्री
- बदलना
- नकल
- ठीक प्रकार से
- बनाना
- बनाया
- बनाना
- वर्तमान
- रिवाज
- अनुकूलन
- अनुकूलित
- darknet
- तिथि
- डेटा तैयारी
- आँकड़े वाला वैज्ञानिक
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- परिभाषित करता है
- निर्भर करता है
- पता चला
- खोज
- बातचीत
- विभिन्न
- सीधे
- निर्देशिकाओं
- खोज
- कई
- कर
- dont
- डाउनलोड
- ड्राइव
- से प्रत्येक
- आसान बनाता है
- शिक्षित करना
- प्रभावी
- प्रभावी रूप से
- कुशल
- दर्ज
- घुसा
- अवधियों को
- त्रुटि
- आदि
- और भी
- प्रत्येक
- ठीक ठीक
- उदाहरण
- व्यायाम
- समझाना
- समझाया
- समझा
- निर्यात
- असाधारण ढंग से
- चेहरा
- का सामना करना पड़ा
- फास्ट
- और तेज
- फेड
- भोजन
- कुछ
- पट्टिका
- फ़ाइलें
- अंत में
- प्रथम
- पहली बार
- फोकस
- का पालन करें
- निम्नलिखित
- प्रारूप
- ढांचा
- से
- मज़ा
- मिल
- GitHub
- देना
- Go
- जा
- अच्छा
- गूगल
- GPU
- सिर
- सुना
- मदद
- मदद की
- यहाँ उत्पन्न करें
- हाइलाइट
- अत्यधिक
- मार
- आशा
- कैसे
- How To
- HTTPS
- विशाल
- विचार
- पहचान
- पहचान करना
- की छवि
- छवियों
- कार्यान्वयन
- महत्वपूर्ण
- in
- शुरू में
- स्थापित
- बजाय
- बातचीत
- इंटरनेट
- शामिल
- IT
- जानना
- ज्ञान
- लेबल
- लेबल
- बड़ा
- बड़े पैमाने पर
- बड़ा
- परतों
- नेतृत्व
- जानें
- सीखा
- सीख रहा हूँ
- पुस्तकालयों
- लाइसेंस
- लाइन
- LINK
- लोड हो रहा है
- देखिए
- देखा
- लग रहा है
- बनाया गया
- बनाना
- निर्माण
- चिह्नित
- मैच
- बात
- अधिकतम-चौड़ाई
- साधन
- तरीकों
- हो सकता है
- लाखों
- मन
- आदर्श
- मॉडल
- अधिक
- अधिकांश
- नाम
- नामांकित
- नामकरण
- आवश्यकता
- जरूरत
- नेटवर्क
- नेटवर्क
- संख्या
- वस्तु
- ऑब्जेक्ट डिटेक्शन
- ONE
- अनुकूलित
- विकल्प
- आदेश
- अन्य
- अपना
- पैकेज
- संकुल
- भाग
- पथ
- वेतन
- स्टाफ़
- निष्पादन
- प्रदर्शन
- प्रदर्शन
- प्रदर्शन
- जगह
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- भविष्यवाणी करना
- भविष्यवाणी
- तैयारी
- पिछला
- पहले से
- मुसीबत
- समस्याओं
- प्रक्रिया
- परियोजना
- साबित
- प्रदान करता है
- उद्देश्य
- pytorch
- तैयार
- वास्तविक समय
- हाल
- की सिफारिश
- परिष्कृत
- हटाना
- कोष
- की आवश्यकता होती है
- अपेक्षित
- आवश्यकताएँ
- जिसके परिणामस्वरूप
- परिणाम
- रन
- वही
- सहेजें
- बचत
- वैज्ञानिक
- वैज्ञानिकों
- स्क्रीन
- सेवा
- खोल
- चाहिए
- दिखाना
- दिखाया
- महत्वपूर्ण
- समान
- सरल
- केवल
- के बाद से
- एक
- So
- समाधान
- कुछ
- कुछ
- कहीं न कहीं
- विभाजित
- खड़ी
- खड़ा
- प्रारंभ
- शुरू
- कदम
- कदम
- संरचना
- ऐसा
- लेना
- कार्य
- कार्य
- टेक्नोलॉजी
- शर्तों
- परीक्षण
- RSI
- लेकिन हाल ही
- बिलकुल
- यहाँ
- पहर
- बहुत समय लगेगा
- सेवा मेरे
- एक साथ
- ऊपर का
- रेलगाड़ी
- प्रशिक्षित
- प्रशिक्षण
- स्थानांतरण
- स्थानांतरित कर रहा है
- ट्यूटोरियल
- आम तौर पर
- समझना
- समझ लिया
- उपयोग
- आमतौर पर
- सत्यापन
- विभिन्न
- वाहन
- संस्करण
- वेबसाइट
- वेबसाइटों
- सप्ताह
- क्या
- कौन कौन से
- जब
- व्यापक रूप से
- बड़े पैमाने पर
- मर्जी
- बिना
- काम
- काम कर रहे
- होगा
- लिखना
- गलत
- यमलो
- Yolo
- आपका
- जेफिरनेट
- ज़िप