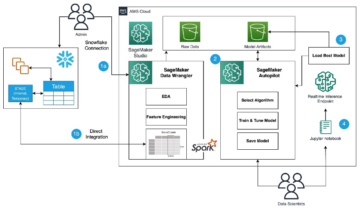
अमेज़न SageMaker का एक सूट प्रदान करता है अंतर्निहित एल्गोरिदम, पूर्व प्रशिक्षित मॉडल, तथा पूर्व-निर्मित समाधान टेम्पलेट्स डेटा वैज्ञानिकों और मशीन लर्निंग (एमएल) चिकित्सकों को प्रशिक्षण और एमएल मॉडल को जल्दी से तैनात करने में मदद करने के लिए। आप इन एल्गोरिदम और मॉडलों का उपयोग पर्यवेक्षित और अनुपयोगी दोनों तरह के शिक्षण के लिए कर सकते हैं। वे विभिन्न प्रकार के इनपुट डेटा को संसाधित कर सकते हैं, जिसमें सारणीबद्ध, छवि और पाठ शामिल हैं।
आज से, सेजमेकर चार नए अंतर्निहित सारणीबद्ध डेटा मॉडलिंग एल्गोरिदम प्रदान करता है: लाइटजीबीएम, कैटबॉस्ट, ऑटोग्लुऑन-टैबुलर और टैबट्रांसफॉर्मर। आप सारणीबद्ध वर्गीकरण और प्रतिगमन कार्यों दोनों के लिए इन लोकप्रिय, अत्याधुनिक एल्गोरिदम का उपयोग कर सकते हैं। वे के माध्यम से उपलब्ध हैं अंतर्निहित एल्गोरिदम सेजमेकर कंसोल पर और साथ ही के माध्यम से अमेज़न SageMaker जम्पस्टार्ट यूआई अंदर अमेज़ॅन सैजमेकर स्टूडियो.
निम्नलिखित चार नए बिल्ट-इन एल्गोरिदम की सूची है, उनके दस्तावेज़ीकरण, उदाहरण नोटबुक और स्रोत के लिंक के साथ।
निम्नलिखित अनुभागों में, हम प्रत्येक एल्गोरिथम का संक्षिप्त तकनीकी विवरण प्रदान करते हैं, और उदाहरण देते हैं कि कैसे सेजमेकर एसडीके या सेजमेकर जम्पस्टार्ट के माध्यम से एक मॉडल को प्रशिक्षित किया जाए।
लाइटजीबीएम
लाइटजीबीएम ग्रैडिएंट बूस्टिंग डिसीजन ट्री (GBDT) एल्गोरिथम का एक लोकप्रिय और कुशल ओपन-सोर्स कार्यान्वयन है। GBDT एक पर्यवेक्षित शिक्षण एल्गोरिथम है जो सरल और कमजोर मॉडल के सेट से अनुमानों के समूह को मिलाकर लक्ष्य चर का सटीक अनुमान लगाने का प्रयास करता है। लाइटजीबीएम पारंपरिक जीबीडीटी की दक्षता और मापनीयता में उल्लेखनीय सुधार के लिए अतिरिक्त तकनीकों का उपयोग करता है।
कैटबॉस्ट
कैटबॉस्ट GBDT एल्गोरिथ्म का एक लोकप्रिय और उच्च-प्रदर्शन वाला ओपन-सोर्स कार्यान्वयन है। कैटबॉस्ट में दो महत्वपूर्ण एल्गोरिथम अग्रिमों को पेश किया गया है: ऑर्डर किए गए बूस्टिंग का कार्यान्वयन, क्लासिक एल्गोरिथम के लिए एक क्रमपरिवर्तन-संचालित विकल्प, और श्रेणीबद्ध सुविधाओं को संसाधित करने के लिए एक अभिनव एल्गोरिथ्म। दोनों तकनीकों को एक विशेष प्रकार के लक्ष्य रिसाव के कारण होने वाली भविष्यवाणी बदलाव से लड़ने के लिए बनाया गया था, जो वर्तमान में ग्रेडिएंट बूस्टिंग एल्गोरिदम के सभी मौजूदा कार्यान्वयन में मौजूद है।
AutoGluon-सारणी
AutoGluon-सारणी अमेज़ॅन द्वारा विकसित और अनुरक्षित एक ओपन-सोर्स ऑटोएमएल प्रोजेक्ट है जो उन्नत डेटा प्रोसेसिंग, डीप लर्निंग और मल्टी-लेयर स्टैक एनसेंबलिंग करता है। यह टेक्स्ट फ़ील्ड की विशेष हैंडलिंग सहित मजबूत डेटा प्रीप्रोसेसिंग के लिए प्रत्येक कॉलम में डेटा प्रकार को स्वचालित रूप से पहचानता है। AutoGluon विभिन्न मॉडलों में फिट बैठता है, जो कि ऑफ-द-शेल्फ बूस्टेड ट्री से लेकर कस्टमाइज़्ड न्यूरल नेटवर्क मॉडल तक हैं। इन मॉडलों को एक नए तरीके से जोड़ा गया है: मॉडल को कई परतों में ढेर किया जाता है और एक परत-वार तरीके से प्रशिक्षित किया जाता है जो गारंटी देता है कि कच्चे डेटा को एक निश्चित समय की कमी के भीतर उच्च गुणवत्ता वाले पूर्वानुमानों में अनुवादित किया जा सकता है। आउट-ऑफ-फ़ोल्ड उदाहरणों की सावधानीपूर्वक ट्रैकिंग के साथ डेटा को विभिन्न तरीकों से विभाजित करके इस पूरी प्रक्रिया में ओवर-फिटिंग को कम किया जाता है। AutoGluon को प्रदर्शन के लिए अनुकूलित किया गया है, और इसके आउट-ऑफ-द-बॉक्स उपयोग ने डेटा विज्ञान प्रतियोगिताओं में कई शीर्ष -3 और शीर्ष -10 स्थान हासिल किए हैं।
टैबट्रांसफॉर्मर
टैबट्रांसफॉर्मर पर्यवेक्षित शिक्षण के लिए एक उपन्यास गहन सारणीबद्ध डेटा मॉडलिंग वास्तुकला है। TabTransformer आत्म-ध्यान आधारित ट्रांसफॉर्मर पर बनाया गया है। उच्च भविष्यवाणी सटीकता प्राप्त करने के लिए ट्रांसफॉर्मर परतें स्पष्ट विशेषताओं के एम्बेडिंग को मजबूत प्रासंगिक एम्बेडिंग में बदल देती हैं। इसके अलावा, TabTransformer से सीखी गई प्रासंगिक एम्बेडिंग लापता और शोर दोनों डेटा सुविधाओं के खिलाफ अत्यधिक मजबूत हैं, और बेहतर व्याख्यात्मकता प्रदान करती हैं। यह मॉडल हाल ही का उत्पाद है अमेज़ॅन साइंस अनुसंधान (काग़ज़ और आधिकारिक तौर पर ब्लॉग पोस्ट यहां) और एमएल समुदाय द्वारा व्यापक रूप से अपनाया गया है, विभिन्न तृतीय-पक्ष कार्यान्वयन के साथ (Keras, ऑटोग्लून,) और सोशल मीडिया सुविधाएँ जैसे tweets, डेटासाइंस की ओर, मध्यम, और Kaggle.
सेजमेकर बिल्ट-इन एल्गोरिदम के लाभ
अपनी विशेष प्रकार की समस्या और डेटा के लिए एल्गोरिथम का चयन करते समय, सेजमेकर बिल्ट-इन एल्गोरिथम का उपयोग करना सबसे आसान विकल्प है, क्योंकि ऐसा करने से निम्नलिखित प्रमुख लाभ मिलते हैं:
- बिल्ट-इन एल्गोरिदम को प्रयोग चलाना शुरू करने के लिए किसी कोडिंग की आवश्यकता नहीं होती है। आपको केवल डेटा, हाइपरपैरामीटर और कंप्यूट संसाधन प्रदान करने की आवश्यकता है। यह आपको ट्रैकिंग परिणामों और कोड परिवर्तनों के लिए कम ओवरहेड के साथ प्रयोग अधिक तेज़ी से चलाने की अनुमति देता है।
- अंतर्निहित एल्गोरिदम कई गणना उदाहरणों में समानांतरता के साथ आते हैं और सभी लागू एल्गोरिदम के लिए GPU समर्थन बॉक्स से बाहर है (कुछ एल्गोरिदम अंतर्निहित सीमाओं के कारण शामिल नहीं हो सकते हैं)। यदि आपके पास अपने मॉडल को प्रशिक्षित करने के लिए बहुत अधिक डेटा है, तो अधिकांश अंतर्निहित एल्गोरिदम मांग को पूरा करने के लिए आसानी से स्केल कर सकते हैं। यहां तक कि अगर आपके पास पहले से ही एक पूर्व-प्रशिक्षित मॉडल है, तब भी सेजमेकर में इसके कोरोलरी का उपयोग करना आसान हो सकता है और उन हाइपरपैरामीटर को इनपुट कर सकता है जिन्हें आप पहले से जानते हैं बजाय इसे पोर्ट करने और खुद एक प्रशिक्षण स्क्रिप्ट लिखने के लिए।
- आप परिणामी मॉडल कलाकृतियों के स्वामी हैं। आप उस मॉडल को ले सकते हैं और इसे सेजमेकर पर कई अलग-अलग अनुमान पैटर्न के लिए तैनात कर सकते हैं (सभी देखें उपलब्ध परिनियोजन प्रकार) और आसान समापन बिंदु स्केलिंग और प्रबंधन, या आप इसे कहीं भी तैनात कर सकते हैं जहां आपको इसकी आवश्यकता है।
आइए अब देखें कि इन बिल्ट-इन एल्गोरिदम में से किसी एक को कैसे प्रशिक्षित किया जाए।
सेजमेकर एसडीके का उपयोग करके एक अंतर्निहित एल्गोरिदम को प्रशिक्षित करें
किसी चयनित मॉडल को प्रशिक्षित करने के लिए, हमें उस मॉडल का URI, साथ ही प्रशिक्षण स्क्रिप्ट और प्रशिक्षण के लिए उपयोग की जाने वाली कंटेनर छवि प्राप्त करने की आवश्यकता होती है। शुक्र है, ये तीन इनपुट पूरी तरह से मॉडल के नाम, संस्करण पर निर्भर करते हैं (उपलब्ध मॉडलों की सूची के लिए, देखें जम्पस्टार्ट उपलब्ध मॉडल तालिका), और जिस प्रकार का उदाहरण आप प्रशिक्षित करना चाहते हैं। यह निम्नलिखित कोड स्निपेट में प्रदर्शित किया गया है:
RSI train_model_id में परिवर्तन lightgbm-regression-model अगर हम एक प्रतिगमन समस्या से निपट रहे हैं। इस पोस्ट में पेश किए गए अन्य सभी मॉडलों की आईडी निम्न तालिका में सूचीबद्ध हैं।
| आदर्श | समस्या का प्रकार | मॉडल आईडी |
| लाइटजीबीएम | वर्गीकरण | lightgbm-classification-model |
| . | प्रतीपगमन | lightgbm-regression-model |
| कैटबॉस्ट | वर्गीकरण | catboost-classification-model |
| . | प्रतीपगमन | catboost-regression-model |
| AutoGluon-सारणी | वर्गीकरण | autogluon-classification-ensemble |
| . | प्रतीपगमन | autogluon-regression-ensemble |
| टैबट्रांसफॉर्मर | वर्गीकरण | pytorch-tabtransformerclassification-model |
| . | प्रतीपगमन | pytorch-tabtransformerregression-model |
फिर हम परिभाषित करते हैं कि हमारा इनपुट कहां चालू है अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस 3)। हम इस उदाहरण के लिए एक सार्वजनिक नमूना डेटासेट का उपयोग कर रहे हैं। हम यह भी परिभाषित करते हैं कि हम अपने आउटपुट को कहाँ जाना चाहते हैं, और चयनित मॉडल को प्रशिक्षित करने के लिए आवश्यक हाइपरपैरामीटर की डिफ़ॉल्ट सूची को पुनः प्राप्त करते हैं। आप उनके मूल्य को अपनी पसंद के अनुसार बदल सकते हैं।
अंत में, हम एक सेजमेकर को इंस्टेंट करते हैं Estimator सभी पुनर्प्राप्त इनपुट के साथ और प्रशिक्षण कार्य शुरू करें .fit, इसे हमारे प्रशिक्षण डेटासेट URI पास कर रहा है। entry_point प्रदान की गई स्क्रिप्ट का नाम है transfer_learning.py (अन्य कार्यों और एल्गोरिदम के लिए समान), और इनपुट डेटा चैनल को पास किया गया .fit नाम होना चाहिए training.
ध्यान दें कि आप बिल्ट-इन एल्गोरिदम को प्रशिक्षित कर सकते हैं SageMaker स्वचालित मॉडल ट्यूनिंग इष्टतम हाइपरपैरामीटर का चयन करने और मॉडल के प्रदर्शन में और सुधार करने के लिए।
सेजमेकर जम्पस्टार्ट का उपयोग करके एक अंतर्निहित एल्गोरिथम को प्रशिक्षित करें
आप सेजमेकर जम्पस्टार्ट यूआई के माध्यम से कुछ क्लिक के साथ इनमें से किसी भी अंतर्निहित एल्गोरिदम को प्रशिक्षित कर सकते हैं। जम्पस्टार्ट एक सेजमेकर फीचर है जो आपको ग्राफिकल इंटरफेस के माध्यम से विभिन्न एमएल फ्रेमवर्क और मॉडल हब से अंतर्निहित एल्गोरिदम और पूर्व-प्रशिक्षित मॉडल को प्रशिक्षित और तैनात करने की अनुमति देता है। यह आपको पूरी तरह से विकसित एमएल समाधानों को तैनात करने की अनुमति देता है जो लक्षित उपयोग के मामले को हल करने के लिए एमएल मॉडल और विभिन्न अन्य एडब्ल्यूएस सेवाओं को एक साथ जोड़ते हैं।
अधिक जानकारी के लिए, देखें TensorFlow हब और हगिंग फेस मॉडल का उपयोग करके Amazon SageMaker जम्पस्टार्ट के साथ टेक्स्ट वर्गीकरण चलाएँ.
निष्कर्ष
इस पोस्ट में, हमने सेजमेकर पर अब उपलब्ध सारणीबद्ध डेटासेट पर एमएल के लिए चार शक्तिशाली नए बिल्ट-इन एल्गोरिदम के लॉन्च की घोषणा की। हमने इन एल्गोरिदम का तकनीकी विवरण प्रदान किया है, साथ ही सेजमेकर एसडीके का उपयोग करके लाइटजीबीएम के लिए एक उदाहरण प्रशिक्षण कार्य प्रदान किया है।
अपना खुद का डेटासेट लाएं और सेजमेकर पर इन नए एल्गोरिदम को आजमाएं, और उपलब्ध बिल्ट-इन एल्गोरिदम का उपयोग करने के लिए नमूना नोटबुक देखें। GitHub.
लेखक के बारे में
![]() डॉ शिन हुआंग अमेज़ॅन सेजमेकर जम्पस्टार्ट और अमेज़ॅन सेजमेकर बिल्ट-इन एल्गोरिदम के लिए एक अनुप्रयुक्त वैज्ञानिक है। वह स्केलेबल मशीन लर्निंग एल्गोरिदम विकसित करने पर ध्यान केंद्रित करता है। उनकी शोध रुचियां प्राकृतिक भाषा प्रसंस्करण, सारणीबद्ध डेटा पर व्याख्या योग्य गहरी शिक्षा और गैर-पैरामीट्रिक स्पेस-टाइम क्लस्टरिंग के मजबूत विश्लेषण के क्षेत्र में हैं। उन्होंने एसीएल, आईसीडीएम, केडीडी सम्मेलनों और रॉयल स्टैटिस्टिकल सोसाइटी: सीरीज ए जर्नल में कई पत्र प्रकाशित किए हैं।
डॉ शिन हुआंग अमेज़ॅन सेजमेकर जम्पस्टार्ट और अमेज़ॅन सेजमेकर बिल्ट-इन एल्गोरिदम के लिए एक अनुप्रयुक्त वैज्ञानिक है। वह स्केलेबल मशीन लर्निंग एल्गोरिदम विकसित करने पर ध्यान केंद्रित करता है। उनकी शोध रुचियां प्राकृतिक भाषा प्रसंस्करण, सारणीबद्ध डेटा पर व्याख्या योग्य गहरी शिक्षा और गैर-पैरामीट्रिक स्पेस-टाइम क्लस्टरिंग के मजबूत विश्लेषण के क्षेत्र में हैं। उन्होंने एसीएल, आईसीडीएम, केडीडी सम्मेलनों और रॉयल स्टैटिस्टिकल सोसाइटी: सीरीज ए जर्नल में कई पत्र प्रकाशित किए हैं।
![]() डॉ आशीष खेतानी अमेज़ॅन सेजमेकर जम्पस्टार्ट और अमेज़ॅन सेजमेकर बिल्ट-इन एल्गोरिदम के साथ एक वरिष्ठ अनुप्रयुक्त वैज्ञानिक हैं और मशीन लर्निंग एल्गोरिदम विकसित करने में मदद करते हैं। वह मशीन लर्निंग और सांख्यिकीय अनुमान में एक सक्रिय शोधकर्ता हैं और उन्होंने न्यूरआईपीएस, आईसीएमएल, आईसीएलआर, जेएमएलआर, एसीएल और ईएमएनएलपी सम्मेलनों में कई पत्र प्रकाशित किए हैं।
डॉ आशीष खेतानी अमेज़ॅन सेजमेकर जम्पस्टार्ट और अमेज़ॅन सेजमेकर बिल्ट-इन एल्गोरिदम के साथ एक वरिष्ठ अनुप्रयुक्त वैज्ञानिक हैं और मशीन लर्निंग एल्गोरिदम विकसित करने में मदद करते हैं। वह मशीन लर्निंग और सांख्यिकीय अनुमान में एक सक्रिय शोधकर्ता हैं और उन्होंने न्यूरआईपीएस, आईसीएमएल, आईसीएलआर, जेएमएलआर, एसीएल और ईएमएनएलपी सम्मेलनों में कई पत्र प्रकाशित किए हैं।
 जोआओ मौरा Amazon वेब सर्विसेज में AI/ML स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट हैं। वह ज्यादातर एनएलपी उपयोग के मामलों पर केंद्रित है और ग्राहकों को डीप लर्निंग मॉडल प्रशिक्षण और तैनाती को अनुकूलित करने में मदद करता है। वह लो-कोड एमएल सॉल्यूशंस और एमएल-स्पेशलाइज्ड हार्डवेयर के सक्रिय प्रस्तावक भी हैं।
जोआओ मौरा Amazon वेब सर्विसेज में AI/ML स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट हैं। वह ज्यादातर एनएलपी उपयोग के मामलों पर केंद्रित है और ग्राहकों को डीप लर्निंग मॉडल प्रशिक्षण और तैनाती को अनुकूलित करने में मदद करता है। वह लो-कोड एमएल सॉल्यूशंस और एमएल-स्पेशलाइज्ड हार्डवेयर के सक्रिय प्रस्तावक भी हैं।
- कॉइनस्मार्ट। यूरोप का सर्वश्रेष्ठ बिटकॉइन और क्रिप्टो एक्सचेंज।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। नि: शुल्क प्रवेश।
- क्रिप्टोहॉक। Altcoin रडार। मुफ्त परीक्षण।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/new-built-in-amazon-sagemaker-algorithms-for-tabular-data-modeling-lightgbm-catboost-autogluon-tabular-and-tabtransformer/
- "
- 100
- a
- पाना
- हासिल
- के पार
- सक्रिय
- अतिरिक्त
- उन्नत
- अग्रिमों
- के खिलाफ
- कलन विधि
- एल्गोरिथम
- एल्गोरिदम
- सब
- की अनुमति देता है
- पहले ही
- वैकल्पिक
- वीरांगना
- अमेज़ॅन वेब सेवा
- विश्लेषण
- की घोषणा
- उपयुक्त
- लागू
- स्थापत्य
- क्षेत्र
- स्वचालित
- स्वतः
- उपलब्ध
- एडब्ल्यूएस
- क्योंकि
- लाभ
- बेहतर
- बढ़ाया
- बढ़ाने
- मुक्केबाज़ी
- में निर्मित
- सावधान
- मामला
- के कारण होता
- परिवर्तन
- क्लासिक
- वर्गीकरण
- कोड
- कोडन
- स्तंभ
- कैसे
- समुदाय
- प्रतियोगिताएं
- गणना करना
- सम्मेलनों
- कंसोल
- कंटेनर
- बनाना
- बनाया
- महत्वपूर्ण
- वर्तमान में
- रिवाज
- ग्राहक
- तिथि
- डेटा संसाधन
- डेटा विज्ञान
- व्यवहार
- निर्णय
- गहरा
- मांग
- साबित
- तैनात
- तैनाती
- तैनाती
- विवरण
- विकसित करना
- विकसित
- विकासशील
- विभिन्न
- डाक में काम करनेवाला मज़दूर
- से प्रत्येक
- आसानी
- दक्षता
- कुशल
- endpoint
- अनुमान
- उदाहरण
- उदाहरण
- मौजूदा
- चेहरा
- Feature
- विशेषताएं
- फ़ील्ड
- ध्यान केंद्रित
- केंद्रित
- निम्नलिखित
- चौखटे
- से
- आगे
- और भी
- GPU
- हैंडलिंग
- हार्डवेयर
- ऊंचाई
- मदद
- मदद
- मदद करता है
- यहाँ उत्पन्न करें
- उच्च गुणवत्ता
- उच्चतर
- अत्यधिक
- कैसे
- How To
- HTTPS
- हब
- की छवि
- कार्यान्वयन
- में सुधार
- शामिल
- सहित
- करें-
- निहित
- अभिनव
- निवेश
- उदाहरण
- रुचियों
- इंटरफेस
- IT
- काम
- पत्रिका
- जानना
- भाषा
- लांच
- सीखा
- सीख रहा हूँ
- लिंक
- सूची
- सूचीबद्ध
- मशीन
- यंत्र अधिगम
- प्रमुख
- प्रबंध
- ढंग
- मीडिया
- मध्यम
- ML
- आदर्श
- मॉडल
- अधिक
- अधिकांश
- विभिन्न
- प्राकृतिक
- नेटवर्क
- ऑप्टिमाइज़ करें
- अनुकूलित
- विकल्प
- अन्य
- अपना
- मालिक
- विशेष
- पासिंग
- पीडीएफ
- प्रदर्शन
- लोकप्रिय
- शक्तिशाली
- भविष्यवाणी करना
- भविष्यवाणी
- भविष्यवाणियों
- वर्तमान
- मुसीबत
- प्रक्रिया
- प्रसंस्करण
- एस्ट्रो मॉल
- परियोजना
- प्रदान करना
- बशर्ते
- प्रदान करता है
- सार्वजनिक
- प्रकाशित
- जल्दी से
- लेकर
- कच्चा
- पहचानता
- क्षेत्र
- की आवश्यकता होती है
- अनुसंधान
- उपयुक्त संसाधन चुनें
- जिसके परिणामस्वरूप
- परिणाम
- रन
- दौड़ना
- वही
- अनुमापकता
- स्केलेबल
- स्केल
- स्केलिंग
- विज्ञान
- वैज्ञानिक
- वैज्ञानिकों
- एसडीके
- चयनित
- कई
- श्रृंखला ए
- सेवाएँ
- सेट
- कई
- पाली
- सरल
- So
- सोशल मीडिया
- सोशल मीडिया
- समाज
- समाधान
- समाधान ढूंढे
- हल
- कुछ
- विशेष
- विशेषज्ञ
- धुआँरा
- प्रारंभ
- शुरू
- राज्य के-the-कला
- सांख्यिकीय
- फिर भी
- भंडारण
- समर्थन
- लक्ष्य
- लक्षित
- कार्य
- तकनीकी
- तकनीक
- RSI
- तीसरे दल
- तीन
- यहाँ
- भर
- पहर
- आज
- एक साथ
- ट्रैकिंग
- रेलगाड़ी
- प्रशिक्षण
- बदालना
- प्रकार
- ui
- अद्वितीय
- उपयोग
- बक्सों का इस्तेमाल करें
- मूल्य
- विभिन्न
- संस्करण
- तरीके
- वेब
- वेब सेवाओं
- क्या
- अंदर
- आपका