यह तीन-भाग श्रृंखला दर्शाती है कि ग्राफ न्यूरल नेटवर्क (जीएनएन) का उपयोग कैसे करें और अमेज़न नेपच्यून का उपयोग करके मूवी अनुशंसाएँ उत्पन्न करने के लिए आईएमडीबी और बॉक्स ऑफिस मोजो मूवीज/टीवी/ओटीटी लाइसेंस योग्य डेटा पैकेज, जो मनोरंजन मेटाडेटा की एक विस्तृत श्रृंखला प्रदान करता है, जिसमें 1 बिलियन से अधिक उपयोगकर्ता रेटिंग शामिल हैं; 11 मिलियन से अधिक कलाकारों और चालक दल के सदस्यों के लिए क्रेडिट; 9 मिलियन फिल्म, टीवी और मनोरंजन शीर्षक; और 60 से अधिक देशों से वैश्विक बॉक्स ऑफिस रिपोर्टिंग डेटा। कई AWS मीडिया और मनोरंजन ग्राहक IMDb डेटा को लाइसेंस देते हैं AWS डेटा एक्सचेंज सामग्री की खोज में सुधार करने और ग्राहक जुड़ाव और प्रतिधारण बढ़ाने के लिए।
In भाग 1, हमने GNN के अनुप्रयोगों पर चर्चा की, और पूछताछ के लिए हमारे IMDb डेटा को कैसे रूपांतरित और तैयार किया जाए। इस पोस्ट में, हम नेप्च्यून का उपयोग करने की प्रक्रिया पर चर्चा करते हैं ताकि भाग 3 में हमारी आउट-ऑफ़-कैटलॉग खोज का संचालन करने के लिए उपयोग किया जा सके। हम भी जाते हैं अमेज़ॅन नेपच्यून एमएल, नेप्च्यून की मशीन लर्निंग (एमएल) सुविधा, और कोड जो हम अपनी विकास प्रक्रिया में उपयोग करते हैं। भाग 3 में, हम एक आउट-ऑफ़-कैटलॉग खोज उपयोग मामले में अपने नॉलेज ग्राफ़ एम्बेडिंग को लागू करने का तरीका बताते हैं।
समाधान अवलोकन
बड़े कनेक्टेड डेटासेट में अक्सर मूल्यवान जानकारी होती है जिसे अकेले मानव अंतर्ज्ञान के आधार पर प्रश्नों का उपयोग करके निकालना कठिन हो सकता है। एमएल तकनीक अरबों रिश्तों वाले ग्राफ में छिपे हुए सहसंबंधों को खोजने में मदद कर सकती है। ये सहसंबंध उत्पादों की सिफारिश करने, क्रेडिट योग्यता की भविष्यवाणी करने, धोखाधड़ी की पहचान करने और कई अन्य उपयोग मामलों के लिए सहायक हो सकते हैं।
नेप्च्यून एमएल हफ्तों के बजाय घंटों में बड़े ग्राफ़ पर उपयोगी एमएल मॉडल बनाना और प्रशिक्षित करना संभव बनाता है। इसे पूरा करने के लिए, Neptune ML द्वारा संचालित GNN तकनीक का उपयोग करता है अमेज़न SageMaker और डीप ग्राफ लाइब्रेरी (DGL) (जो है खुले स्रोत). जीएनएन आर्टिफिशियल इंटेलिजेंस में एक उभरता हुआ क्षेत्र है (उदाहरण के लिए, देखें ग्राफ तंत्रिका नेटवर्क पर एक व्यापक सर्वेक्षण). डीजीएल के साथ जीएनएन का उपयोग करने के बारे में व्यावहारिक ट्यूटोरियल के लिए, देखें डीप ग्राफ लाइब्रेरी के साथ लर्निंग ग्राफ न्यूरल नेटवर्क.
इस पोस्ट में, हम दिखाते हैं कि एम्बेडिंग उत्पन्न करने के लिए हमारी पाइपलाइन में नेपच्यून का उपयोग कैसे करें।
निम्नलिखित आरेख IMDb डेटा के समग्र प्रवाह को डाउनलोड से लेकर एम्बेडिंग पीढ़ी तक दर्शाता है।
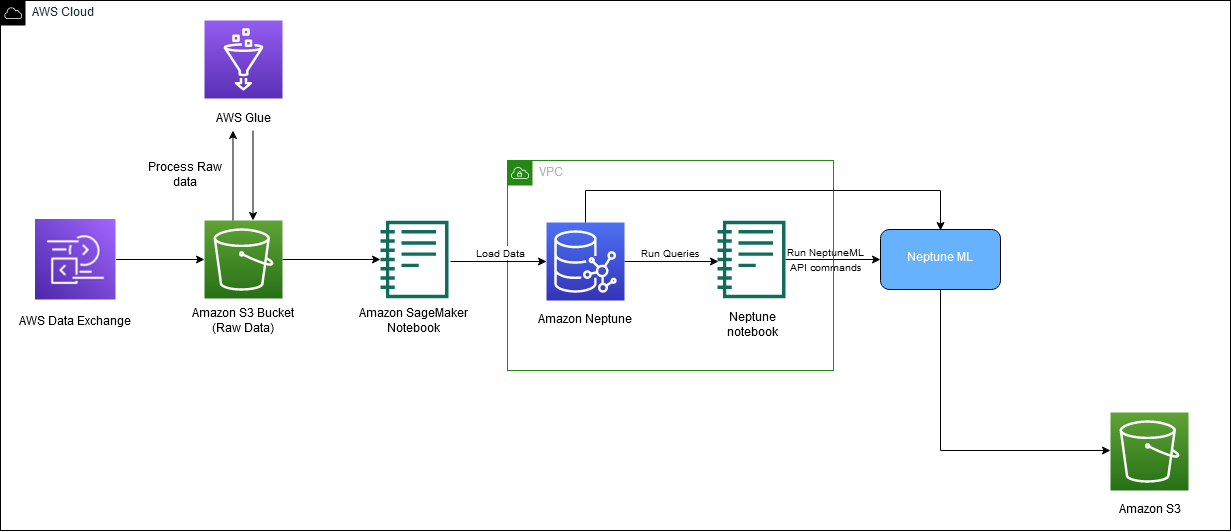
समाधान को लागू करने के लिए हम निम्नलिखित AWS सेवाओं का उपयोग करते हैं:
इस पोस्ट में, हम आपको निम्न उच्च-स्तरीय चरणों के बारे में बताते हैं:
- पर्यावरण चर सेट करें
- एक निर्यात कार्य बनाएँ।
- डेटा प्रोसेसिंग जॉब बनाएं।
- एक प्रशिक्षण कार्य सबमिट करें।
- एम्बेडिंग डाउनलोड करें।
नेप्च्यून एमएल कमांड के लिए कोड
हम इस समाधान को लागू करने के भाग के रूप में निम्नलिखित आदेशों का उपयोग करते हैं:
हम का उपयोग करें neptune_ml export स्थिति की जांच करने या नेप्च्यून एमएल निर्यात प्रक्रिया शुरू करने के लिए, और neptune_ml training नेप्च्यून एमएल मॉडल प्रशिक्षण कार्य की स्थिति शुरू करने और जांचने के लिए।
इन और अन्य आदेशों के बारे में अधिक जानकारी के लिए देखें नेप्च्यून वर्कबेंच मैजिक का उपयोग अपनी नोटबुक में करें.
.. पूर्वापेक्षाएँ
इस पोस्ट के साथ अनुसरण करने के लिए, आपके पास निम्नलिखित होना चाहिए:
- An AWS खाता
- SageMaker, Amazon S3, और AWS CloudFormation के साथ परिचित
- नेप्च्यून क्लस्टर में लोड किया गया ग्राफ़ डेटा (देखें भाग 1 अधिक जानकारी के लिए)
पर्यावरण चर सेट करें
इससे पहले कि हम शुरू करें, आपको निम्नलिखित वेरिएबल्स सेट करके अपना परिवेश सेट अप करना होगा: s3_bucket_uri और processed_folder. s3_bucket_uri भाग 1 में प्रयुक्त बाल्टी का नाम है और processed_folder निर्यात कार्य से आउटपुट के लिए Amazon S3 स्थान है।
एक निर्यात कार्य बनाएँ
भाग 1 में, हमने अपने डेटा को नेप्च्यून DB क्लस्टर से Amazon S3 में आवश्यक प्रारूप में निर्यात करने के लिए एक SageMaker नोटबुक और निर्यात सेवा बनाई।
अब जब हमारा डेटा लोड हो गया है और निर्यात सेवा बन गई है, तो हमें इसे शुरू करने के लिए एक निर्यात कार्य बनाने की आवश्यकता है। ऐसा करने के लिए, हम उपयोग करते हैं NeptuneExportApiUri और निर्यात कार्य के लिए पैरामीटर बनाएं। निम्नलिखित कोड में, हम चर का उपयोग करते हैं expo और export_params। सेट expo अपने को NeptuneExportApiUri मूल्य, जो आप पर पा सकते हैं आउटपुट आपके CloudFormation स्टैक का टैब। के लिए export_params, हम आपके नेप्च्यून क्लस्टर के समापन बिंदु का उपयोग करते हैं और इसके लिए मान प्रदान करते हैं outputS3path, जो एक्सपोर्ट जॉब से आउटपुट के लिए Amazon S3 लोकेशन है।
निर्यात कार्य सबमिट करने के लिए निम्न आदेश का उपयोग करें:
निर्यात कार्य की स्थिति की जाँच करने के लिए निम्न आदेश का उपयोग करें:
आपका काम पूरा होने के बाद, सेट करें processed_folder संसाधित परिणामों के Amazon S3 स्थान प्रदान करने के लिए चर:
डेटा प्रोसेसिंग जॉब बनाएं
अब जबकि निर्यात पूरा हो गया है, हम नेप्च्यून एमएल प्रशिक्षण प्रक्रिया के लिए डेटा तैयार करने के लिए डेटा प्रोसेसिंग जॉब बनाते हैं। इसे कुछ अलग तरीकों से किया जा सकता है। इस चरण के लिए, आप बदल सकते हैं job_name और modelType चर, लेकिन अन्य सभी पैरामीटर समान रहना चाहिए। इस कोड का मुख्य भाग है modelType पैरामीटर, जो या तो विषम ग्राफ मॉडल हो सकता है (heterogeneous) या नॉलेज ग्राफ़ (kge).
एक्सपोर्ट जॉब भी शामिल है training-data-configuration.json. इस फ़ाइल का उपयोग उन नोड्स या किनारों को जोड़ने या हटाने के लिए करें जिन्हें आप प्रशिक्षण के लिए प्रदान नहीं करना चाहते हैं (उदाहरण के लिए, यदि आप दो नोड्स के बीच लिंक की भविष्यवाणी करना चाहते हैं, तो आप इस कॉन्फ़िगरेशन फ़ाइल में उस लिंक को हटा सकते हैं)। इस ब्लॉग पोस्ट के लिए हम मूल कॉन्फ़िगरेशन फ़ाइल का उपयोग करते हैं। अतिरिक्त जानकारी के लिए देखें एक प्रशिक्षण विन्यास फाइल का संपादन.
निम्नलिखित कोड के साथ अपना डेटा प्रोसेसिंग कार्य बनाएँ:
निर्यात कार्य की स्थिति की जाँच करने के लिए निम्न आदेश का उपयोग करें:
एक प्रशिक्षण कार्य सबमिट करें
प्रसंस्करण कार्य पूरा होने के बाद, हम अपना प्रशिक्षण कार्य शुरू कर सकते हैं, जहाँ हम अपने एम्बेडिंग बनाते हैं। हम ml.m5.24xlarge के उदाहरण प्रकार की अनुशंसा करते हैं, लेकिन आप इसे अपनी कंप्यूटिंग आवश्यकताओं के अनुरूप बदल सकते हैं। निम्नलिखित कोड देखें:
हम प्रशिक्षण कार्य के लिए आईडी प्राप्त करने के लिए प्रशिक्षण_परिणाम चर प्रिंट करते हैं। अपनी नौकरी की स्थिति की जांच करने के लिए निम्न आदेश का प्रयोग करें:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
एम्बेडिंग डाउनलोड करें
आपका प्रशिक्षण कार्य पूरा होने के बाद, अंतिम चरण अपने कच्चे एम्बेडिंग को डाउनलोड करना है। निम्न चरण आपको दिखाते हैं कि KGE का उपयोग करके बनाए गए एम्बेडिंग को कैसे डाउनलोड करें (आप RGCN के लिए समान प्रक्रिया का उपयोग कर सकते हैं)।
निम्नलिखित कोड में, हम उपयोग करते हैं neptune_ml.get_mapping() और get_embeddings() मैपिंग फ़ाइल डाउनलोड करने के लिए (mapping.info) और कच्ची एम्बेडिंग फ़ाइल (entity.npy). फिर हमें उपयुक्त एम्बेडिंग को उनकी संबंधित आईडी पर मैप करने की आवश्यकता है।
आरजीसीएन डाउनलोड करने के लिए, नए प्रशिक्षण कार्य के नाम के साथ उसी प्रक्रिया का पालन करें जिसमें डेटा को मॉडल टाइप पैरामीटर के साथ सेट किया गया हो। heterogeneous, फिर अपने मॉडल को मॉडलनेम पैरामीटर सेट के साथ प्रशिक्षित करें rgcn देखना यहाँ उत्पन्न करें अधिक जानकारी के लिए। एक बार जब यह समाप्त हो जाए, तो कॉल करें get_mapping और get_embeddings आपका नया डाउनलोड करने के लिए कार्य करता है मैपिंग.इन्फो और इकाई.npy फ़ाइलें। आपके पास इकाई और मैपिंग फ़ाइलें होने के बाद, CSV फ़ाइल बनाने की प्रक्रिया समान है।
अंत में, अपने एम्बेडिंग को अपने इच्छित Amazon S3 स्थान पर अपलोड करें:
सुनिश्चित करें कि आपको यह S3 स्थान याद है, आपको इसे भाग 3 में उपयोग करने की आवश्यकता होगी।
क्लीन अप
जब आप समाधान का उपयोग कर लें, तो चल रहे शुल्कों से बचने के लिए सभी संसाधनों को साफ करना सुनिश्चित करें।
निष्कर्ष
इस पोस्ट में, हमने IMDb डेटा से GNN एम्बेडिंग को प्रशिक्षित करने के लिए नेपच्यून ML का उपयोग करने के तरीके पर चर्चा की।
नॉलेज ग्राफ़ एम्बेडिंग के कुछ संबंधित एप्लिकेशन आउट-ऑफ़-कैटलॉग खोज, सामग्री अनुशंसाएं, लक्षित विज्ञापन, लापता लिंक की भविष्यवाणी, सामान्य खोज और कोहोर्ट विश्लेषण जैसी अवधारणाएं हैं। आउट ऑफ़ कैटलॉग सर्च, उस सामग्री को खोजने की प्रक्रिया है, जिसके आप मालिक नहीं हैं, और आपके कैटलॉग में ऐसी सामग्री ढूँढ़ने या उसकी सिफारिश करने की प्रक्रिया है, जो उपयोगकर्ता द्वारा की गई खोज के जितना संभव हो उतना करीब हो। हम भाग 3 में आउट-ऑफ़-कैटलॉग खोज में गहराई से जाते हैं।
लेखक के बारे में
 मैथ्यू रोड्स एक डेटा साइंटिस्ट है, मैं अमेज़न एमएल सॉल्यूशंस लैब में काम कर रहा हूं। वह मशीन लर्निंग पाइपलाइन बनाने में माहिर हैं जिसमें नेचुरल लैंग्वेज प्रोसेसिंग और कंप्यूटर विजन जैसी अवधारणाएं शामिल हैं।
मैथ्यू रोड्स एक डेटा साइंटिस्ट है, मैं अमेज़न एमएल सॉल्यूशंस लैब में काम कर रहा हूं। वह मशीन लर्निंग पाइपलाइन बनाने में माहिर हैं जिसमें नेचुरल लैंग्वेज प्रोसेसिंग और कंप्यूटर विजन जैसी अवधारणाएं शामिल हैं।
 दिव्या भार्गवी अमेज़न एमएल सॉल्यूशंस लैब में डेटा साइंटिस्ट और मीडिया एंड एंटरटेनमेंट वर्टिकल लीड हैं, जहां वह मशीन लर्निंग का उपयोग करके AWS ग्राहकों के लिए उच्च-मूल्य वाली व्यावसायिक समस्याओं को हल करती हैं। वह छवि/वीडियो समझ, नॉलेज ग्राफ अनुशंसा प्रणाली, भविष्य कहनेवाला विज्ञापन उपयोग मामलों पर काम करती है।
दिव्या भार्गवी अमेज़न एमएल सॉल्यूशंस लैब में डेटा साइंटिस्ट और मीडिया एंड एंटरटेनमेंट वर्टिकल लीड हैं, जहां वह मशीन लर्निंग का उपयोग करके AWS ग्राहकों के लिए उच्च-मूल्य वाली व्यावसायिक समस्याओं को हल करती हैं। वह छवि/वीडियो समझ, नॉलेज ग्राफ अनुशंसा प्रणाली, भविष्य कहनेवाला विज्ञापन उपयोग मामलों पर काम करती है।
 गौरव रेले अमेज़ॅन एमएल सॉल्यूशन लैब में डेटा साइंटिस्ट हैं, जहां वे विभिन्न वर्टिकल में एडब्ल्यूएस ग्राहकों के साथ काम करते हैं ताकि मशीन लर्निंग और एडब्ल्यूएस क्लाउड सेवाओं के उपयोग में तेजी लाकर उनकी व्यावसायिक चुनौतियों का समाधान किया जा सके।
गौरव रेले अमेज़ॅन एमएल सॉल्यूशन लैब में डेटा साइंटिस्ट हैं, जहां वे विभिन्न वर्टिकल में एडब्ल्यूएस ग्राहकों के साथ काम करते हैं ताकि मशीन लर्निंग और एडब्ल्यूएस क्लाउड सेवाओं के उपयोग में तेजी लाकर उनकी व्यावसायिक चुनौतियों का समाधान किया जा सके।
 करण सिंदवानी अमेज़ॅन एमएल सॉल्यूशंस लैब में डेटा साइंटिस्ट हैं, जहां वे डीप लर्निंग मॉडल बनाते और तैनात करते हैं। वह कंप्यूटर विजन के क्षेत्र में माहिर हैं। अपने खाली समय में वह लंबी पैदल यात्रा का आनंद लेते हैं।
करण सिंदवानी अमेज़ॅन एमएल सॉल्यूशंस लैब में डेटा साइंटिस्ट हैं, जहां वे डीप लर्निंग मॉडल बनाते और तैनात करते हैं। वह कंप्यूटर विजन के क्षेत्र में माहिर हैं। अपने खाली समय में वह लंबी पैदल यात्रा का आनंद लेते हैं।
 सोजी आदेश: एडब्ल्यूएस में एक एप्लाइड साइंटिस्ट है जहां वह धोखाधड़ी और दुरुपयोग, ज्ञान ग्राफ, अनुशंसा प्रणाली और जीवन विज्ञान के अनुप्रयोगों के साथ ग्राफ कार्यों पर मशीन लर्निंग के लिए ग्राफ न्यूरल नेटवर्क-आधारित मॉडल विकसित करता है। अपने खाली समय में उन्हें पढ़ना और खाना बनाना अच्छा लगता है।
सोजी आदेश: एडब्ल्यूएस में एक एप्लाइड साइंटिस्ट है जहां वह धोखाधड़ी और दुरुपयोग, ज्ञान ग्राफ, अनुशंसा प्रणाली और जीवन विज्ञान के अनुप्रयोगों के साथ ग्राफ कार्यों पर मशीन लर्निंग के लिए ग्राफ न्यूरल नेटवर्क-आधारित मॉडल विकसित करता है। अपने खाली समय में उन्हें पढ़ना और खाना बनाना अच्छा लगता है।
 विद्या सागर रविपति अमेज़ॅन एमएल सॉल्यूशंस लैब में एक प्रबंधक है, जहां वह बड़े पैमाने पर वितरित सिस्टम में अपने विशाल अनुभव का लाभ उठाता है और विभिन्न उद्योग वर्टिकल में एडब्ल्यूएस ग्राहकों को उनके एआई और क्लाउड अपनाने में तेजी लाने में मदद करने के लिए मशीन लर्निंग के लिए उनका जुनून है।
विद्या सागर रविपति अमेज़ॅन एमएल सॉल्यूशंस लैब में एक प्रबंधक है, जहां वह बड़े पैमाने पर वितरित सिस्टम में अपने विशाल अनुभव का लाभ उठाता है और विभिन्न उद्योग वर्टिकल में एडब्ल्यूएस ग्राहकों को उनके एआई और क्लाउड अपनाने में तेजी लाने में मदद करने के लिए मशीन लर्निंग के लिए उनका जुनून है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- About
- गाली
- में तेजी लाने के
- के पार
- अतिरिक्त
- अतिरिक्त जानकारी
- दत्तक ग्रहण
- विज्ञापन
- बाद
- AI
- सब
- अकेला
- वीरांगना
- अमेज़न एमएल सॉल्यूशंस लैब
- विश्लेषण
- और
- अनुप्रयोगों
- लागू
- लागू करें
- उपयुक्त
- क्षेत्र
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- एडब्ल्यूएस
- आधारित
- के बीच
- बिलियन
- अरबों
- ब्लॉग
- मुक्केबाज़ी
- बॉक्स ऑफिस
- निर्माण
- इमारत
- बनाता है
- व्यापार
- कॉल
- मामला
- मामलों
- सूची
- चुनौतियों
- परिवर्तन
- प्रभार
- चेक
- समापन
- बादल
- बादल को गोद लेना
- क्लाउड सेवाएं
- समूह
- कोड
- जत्था
- पूरा
- व्यापक
- कंप्यूटर
- Computer Vision
- कंप्यूटिंग
- अवधारणाओं
- आचरण
- विन्यास
- जुड़ा हुआ
- सामग्री
- इसी
- देशों
- बनाना
- बनाया
- श्रेय
- क्रेडिट्स
- ग्राहक
- ग्राहक अनुबंध
- ग्राहक
- तिथि
- डेटा संसाधन
- आँकड़े वाला वैज्ञानिक
- डेटासेट
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- और गहरा
- तैनात
- विवरण
- विकास
- विकसित
- डीजीएलई
- विभिन्न
- खोज
- चर्चा करना
- चर्चा की
- वितरित
- वितरित प्रणाली
- dont
- डाउनलोड
- भी
- कस्र्न पत्थर
- endpoint
- सगाई
- मनोरंजन
- सत्ता
- वातावरण
- ईथर (ईटीएच)
- उदाहरण
- अनुभव
- निर्यात
- उद्धरण
- Feature
- कुछ
- खेत
- पट्टिका
- फ़ाइलें
- खोज
- खोज
- प्रवाह
- का पालन करें
- निम्नलिखित
- प्रारूप
- धोखा
- से
- पूर्ण
- कार्यों
- सामान्य जानकारी
- उत्पन्न
- पीढ़ी
- मिल
- वैश्विक
- Go
- ग्राफ
- रेखांकन
- हाथों पर
- कठिन
- मदद
- सहायक
- छिपा हुआ
- उच्च स्तर
- घंटे
- कैसे
- How To
- एचटीएमएल
- HTTPS
- मानव
- समान
- पहचान
- लागू करने के
- कार्यान्वयन
- में सुधार
- in
- शामिल
- सहित
- बढ़ना
- अनुक्रमणिका
- उद्योग
- पता
- करें-
- उदाहरण
- बजाय
- बुद्धि
- शामिल करना
- IT
- काम
- JSON
- कुंजी
- ज्ञान
- प्रयोगशाला
- भाषा
- बड़ा
- बड़े पैमाने पर
- पिछली बार
- नेतृत्व
- सीख रहा हूँ
- leverages
- पुस्तकालय
- लाइसेंस
- जीवन
- जीवन विज्ञान
- LINK
- लिंक
- स्थान
- मशीन
- यंत्र अधिगम
- मुख्य
- बनाता है
- प्रबंधक
- बहुत
- नक्शा
- मानचित्रण
- मीडिया
- मध्यम
- सदस्य
- मेटाडाटा
- दस लाख
- लापता
- ML
- आदर्श
- मॉडल
- अधिक
- चलचित्र
- नाम
- प्राकृतिक
- प्राकृतिक भाषा संसाधन
- आवश्यकता
- की जरूरत है
- वरूण
- संजाल आधारित
- नेटवर्क
- तंत्रिका जाल
- नया
- नोड्स
- नोटबुक
- Office
- चल रहे
- मूल
- अन्य
- कुल
- अपना
- पैकेज
- प्राचल
- पैरामीटर
- भाग
- जुनून
- पाइपलाइन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- संभव
- पद
- बिजली
- संचालित
- भविष्यवाणी करना
- की भविष्यवाणी
- तैयार करना
- छाप
- समस्याओं
- प्रक्रिया
- प्रसंस्करण
- उत्पाद
- प्रोफाइल
- प्रदान करना
- प्रदान करता है
- रेंज
- रेटिंग
- कच्चा
- पढ़ना
- की सिफारिश
- सिफारिश
- सिफारिशें
- की सिफारिश
- सम्बंधित
- रिश्ते
- रहना
- याद
- हटाना
- रिपोर्टिंग
- अपेक्षित
- उपयुक्त संसाधन चुनें
- परिणाम
- प्रतिधारण
- sagemaker
- वही
- विज्ञान
- वैज्ञानिक
- Search
- खोज
- कई
- सेवा
- सेवाएँ
- सेट
- की स्थापना
- चाहिए
- दिखाना
- समाधान
- समाधान ढूंढे
- हल
- हल करती है
- माहिर
- धुआँरा
- प्रारंभ
- स्थिति
- कदम
- कदम
- की दुकान
- प्रस्तुत
- ऐसा
- सूट
- सर्वेक्षण
- सिस्टम
- लक्षित
- कार्य
- तकनीक
- टेक्नोलॉजी
- RSI
- क्षेत्र
- लेकिन हाल ही
- यहाँ
- पहर
- खिताब
- सेवा मेरे
- रेलगाड़ी
- प्रशिक्षण
- बदालना
- <strong>उद्देश्य</strong>
- ट्यूटोरियल
- tv
- समझ
- उपयोग
- उदाहरण
- उपयोगकर्ता
- मूल्यवान
- मूल्य
- व्यापक
- संस्करण
- कार्यक्षेत्र
- दृष्टि
- तरीके
- सप्ताह
- क्या
- कौन कौन से
- चौड़ा
- विस्तृत श्रृंखला
- मर्जी
- काम कर रहे
- कार्य
- आपका
- जेफिरनेट