परिचय
आरएजी (रिट्रीवल ऑगमेंटेड जेनरेशन) के आगमन के साथ और बड़े भाषा मॉडल (एलएलएम), दस्तावेज़ प्रश्न उत्तर जैसे ज्ञान-गहन कार्य, डाउनस्ट्रीम कार्यों को हल करने के लिए लागत-महंगे एलएलएम को ठीक करने की तत्काल आवश्यकता के बिना बहुत अधिक कुशल और मजबूत हो गए हैं। इस लेख में, हम Google के जेमिनी AI और लैंगचैन का उपयोग करके RAG-संचालित दस्तावेज़ QnA की दुनिया में उतरेंगे। इसके साथ-साथ, क्यूएनए के लिए एलएलएम का लाभ उठाते हुए बातचीत की स्मृति को संरक्षित करने के बारे में भी काफी चर्चा हुई है। इसे ध्यान में रखते हुए, हम यह भी सीखेंगे कि एक कस्टम सिमेंटिक मेमोरी कैसे बनाई जाए और एक संवादी इंटरफ़ेस की सहायता के लिए इसे अपने RAG के साथ एकीकृत किया जाए, जहां उपयोगकर्ता अनुवर्ती प्रश्न पूछ सकता है और चैट जारी रख सकता है। इसके साथ, आइए गहराई से जानें!
सीखने के मकसद
- जेमिनी एंबेडिंग का उपयोग करके वेक्टर स्टोर में पीडीएफ दस्तावेज़ पढ़ें और संग्रहीत करें।
- हमारी पसंद और उपयोग के मामले के आधार पर मेटाडेटा जानकारी सम्मिलित करने के लिए एक कस्टम पीडीएफ रीडर बनाएं।
- जेमिनी प्रो मॉडल की सहायता से उपयोगकर्ता प्रश्नों के लिए प्रतिक्रियाएँ उत्पन्न करें।
- प्रश्नों के एलएलएम प्रतिक्रियाओं को संग्रहीत करने और उन्हें समान क्वेरी प्रतिक्रियाओं के रूप में उपयोग करने के लिए सिमेंटिक कैशिंग लागू करें।
विषय - सूची
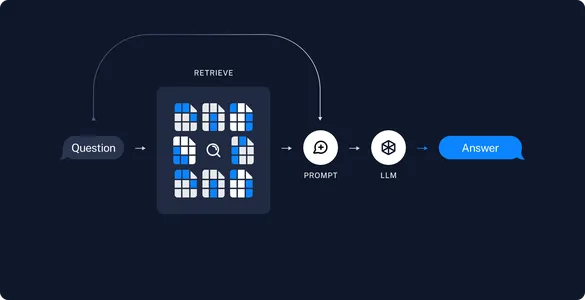
दस्तावेजों के साथ बातचीत
दस्तावेज़ प्रश्न उत्तर एप्लिकेशन बनाना एक साल पहले की तुलना में अब यह बहुत आसान है। ओपनएआई एपीआई अपने लॉन्च के बाद से अधिकांश आरएजी अनुप्रयोगों के लिए मुख्य विकल्प रहा है, लेकिन कम/बिना फंडिंग वाले छोटे अनुप्रयोगों के लिए, ओपनएआई एक महंगा विकल्प बन गया है। यहीं पर गूगल है जेमिनी एपीआई ध्यान आकर्षित करता है. एपीआई का मुफ्त संस्करण 60 क्यूपीएम तक का समर्थन करता है, जो कम लग सकता है लेकिन गैर-ग्राहक-केंद्रित अनुप्रयोगों या शौकीनों के लिए सहायक है जो अपनी परियोजनाओं पर डॉलर खर्च नहीं करना चाहते हैं।
इसके अतिरिक्त, इस लेख में, हम सिमेंटिक कैशिंग भी लागू करेंगे, जो उन अनुप्रयोगों के लिए सहायक होगा जो भुगतान किए गए संस्करण का उपयोग कर रहे हैं OpenAI एपीआई. अब, इससे पहले कि हम व्यावहारिक कार्रवाई शुरू करें, आइए समझें कि सिमेंटिक कैशिंग क्या है।
सिमेंटिक कैशिंग क्या है?
सिमेंटिक कैशिंग एक प्रकार की कैशिंग है जिसका उपयोग एलएलएम प्रतिक्रियाओं को कैश करने के लिए किया जा सकता है। यह क्वेरी के लिए एलएलएम प्रतिक्रिया संग्रहीत करता है और समान क्वेरी या समान क्वेरी पूछे जाने पर वही प्रतिक्रिया देता है। इससे अनावश्यक एलएलएम कॉल को कम करने में मदद मिलती है और परिणामस्वरूप एपीआई लागत कम हो जाती है।
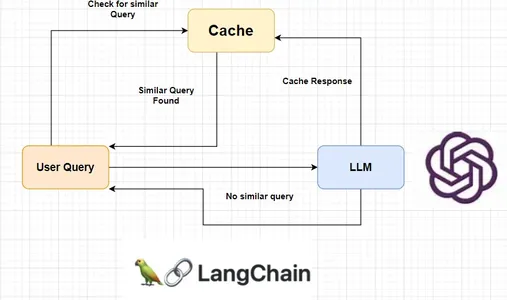
लैंगचैन एलएलएम कैश टूल की एक विस्तृत श्रृंखला प्रदान करता है जैसे रेडिस सिमेंटिक कैश, GPTCache, एस्ट्राडीबी, आदि। हालाँकि, वे समान प्रश्नों को सटीक रूप से पहचानने के मामले में सटीक नहीं हैं। ऐसा उन प्रश्नों के लिए उच्च समानता स्कोर के कारण होता है जो किसी संख्या या शब्द से भिन्न होते हैं। खैर, हम उसी अवधारणा का उपयोग करके अपना स्वयं का सिमेंटिक कैश सिस्टम बनाकर भी समस्या से निपटेंगे।
लैंगचेन के साथ हैंड्स-ऑन दस्तावेज़ QnA + सिमेंटिक कैशिंग के साथ जेमिनी प्रो
इस आरएजी प्रणाली के निर्माण में पहला कदम इन्जेशन पाइपलाइन का निर्माण है। अंतर्ग्रहण पाइपलाइन केवल उपयोगकर्ता को प्रश्न उत्तर के लिए दस्तावेज़ अपलोड करने की अनुमति देती है। हम एक वेक्टर स्टोर प्रारंभ करते हैं और फिर उसमें दस्तावेज़ सामग्री संग्रहीत करते हैं। हम वेक्टर स्टोर में दस्तावेज़ सामग्री, उनकी एम्बेडिंग और दस्तावेज़ मेटाडेटा जानकारी संग्रहीत करेंगे।
एम्बेडिंग के लिए, हम जेमिनी द्वारा प्रदान किए गए एम्बेडिंग मॉडल का उपयोग करेंगे। हम मेटाडेटा के भीतर पेज नंबर, फ़ाइल नाम इत्यादि जैसी अतिरिक्त जानकारी जोड़ने के लिए अपना पीडीएफ रीडर भी बनाएंगे। हम उपयोग करेंगे गहरी झील RAG के लिए दस्तावेज़ों को संग्रहीत करने के साथ-साथ बाद में QA श्रृंखला में सिमेंटिक कैशिंग के लिए वेक्टर स्टोर।
लैंगचैन + जेमिनी प्रो के साथ QnA दस्तावेज़ के लिए चरण-दर-चरण मार्गदर्शिका
आइए इस विस्तृत 4-चरणीय मार्गदर्शिका के साथ, Google जेमिनी प्रो और लैंगचैन का उपयोग करके दस्तावेज़ QnA सिस्टम बनाने की प्रक्रिया शुरू करें।
चरण 1: जेमिनी एपीआई कुंजी बनाना
पहला कदम जेमिनी एआई के लिए एपीआई कुंजी बनाना होगा। यदि आपके पास पहले से ही चाबी तैयार है तो आप इस चरण को छोड़ सकते हैं। अन्यथा, नई एपीआई कुंजी बनाने के लिए नीचे दिए गए चरणों का पालन करें:
- https://aistudio.google.com/app
- एपीआई कुंजी प्राप्त करें -> एपीआई कुंजी बनाएं पर क्लिक करें।
- `नए प्रोजेक्ट पर एपीआई कुंजी बनाएं` या `Google क्लाउड प्रोजेक्ट खोजें` पर क्लिक करें और एक प्रोजेक्ट चुनें। फिर कुंजी उत्पन्न होने तक प्रतीक्षा करें।
- उत्पन्न एपीआई कुंजी की प्रतिलिपि बनाएँ।
अब इस कुंजी को GOOGLE_API_KEY वेरिएबल में config.py फ़ाइल में रखें। अब हम जाने के लिए तैयार हैं। अपनी पसंद के टूल का उपयोग करके एक वर्चुअल वातावरण बनाएं और आवश्यक पैकेजों को स्थापित करने के लिए प्रदान की गई require.txt फ़ाइल का उपयोग करें। कृपया पैकेजों के दिए गए संस्करण को बदलने से बचें क्योंकि इससे आपका अंतिम एप्लिकेशन ख़राब हो सकता है।
यहां require.txt फ़ाइल की सामग्री दी गई है:
deeplake==3.8.19
langchain==0.1.3
langchain-community==0.0.20
langchain-core==0.1.23
langchain-google-genai==0.0.11
langsmith==0.0.87
lxml==4.9.4
nltk==3.8.1
numpy==1.26.2
openai==0.28.0
pydantic==2.5.3
pydantic_core==2.14.6
PyMuPDF==1.23.21
pypdf==3.17.4
pypdfium2==4.25.0
scipy==1.12.0
sentence-transformers==2.3.1
tiktoken==0.5.2
transformers==4.36.2सभी आवश्यक पैकेज स्थापित करने के लिए निम्नलिखित कोड चलाएँ:
# For linux and macOS systems:
pip install -r requirements.txt
# For Windows systems:
python -m pip install -r requirements.txtअंतर्ग्रहण पाइपलाइन के लिए संपूर्ण कोडबेस नीचे दिया गया है:
import config as cfg
from langchain.vectorstores.deeplake import DeepLake
from src.pdf_reader import PDFReader
from langchain_google_genai import (
GoogleGenerativeAIEmbeddings,
)
class Ingestion:
"""Ingestion class for ingesting documents to vectorstore."""
def __init__(self):
self.text_vectorstore = None
self.image_vectorstore = None
self.text_retriever = None
self.embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001",
google_api_key=cfg.GOOGLE_API_KEY,
)
def ingest_documents(
self,
file: str,
):
# Initialize the PDFReader and load the PDF as chunks
loader = PDFReader()
chunks = loader.load_pdf(file_path=file)
# Initialize the vector store
vstore = DeepLake(
dataset_path="database/text_vectorstore",
embedding=self.embeddings,
overwrite=True,
num_workers=4,
verbose=False,
)
# Ingest the chunks
_ = vstore.add_documents(chunks)आइए कोड को तोड़ें और प्रत्येक पंक्ति को शीघ्रता से समझें। हमारे पास एक अंतर्ग्रहण वर्ग है जिसे प्रारंभ किया जा सकता है। इसके कंस्ट्रक्टर में, हमने मॉडल नाम और एपीआई कुंजी का उपयोग करके जेमिनी एंबेडिंग को आरंभ किया है, जिसे हम कॉन्फ़िगरेशन फ़ाइल से आयात करते हैं। यह उल्लेखनीय है कि, हम यहां किसी भी एम्बेडिंग मॉडल का उपयोग कर सकते हैं और जेमिनी एंबेडिंग के उपयोग तक सीमित नहीं हैं।
फिर हम एक ingest_documents विधि बनाते हैं, जो दस्तावेज़ों को पढ़ती है और सामग्री को वेक्टर स्टोर में डंप करती है। हम अपने कस्टम पीडीएफ रीडर को आरंभ करके और फिर दस्तावेज़ को टुकड़ों में विभाजित करके ऐसा करते हैं। इसे हमारे पीडीएफ रीडर द्वारा आंतरिक रूप से नियंत्रित किया जाता है, जिस पर निम्नलिखित अनुभाग में चर्चा की जाएगी।
अब जब हमारे पास दस्तावेज़ के टुकड़े हैं तो हम उन्हें वेक्टर डेटाबेस में शामिल कर सकते हैं। हम पथ और एम्बेडिंग का उपयोग करके डीपलेक वेक्टर स्टोर को इनिशियलाइज़ करते हैं जिसे हमने पहले कंस्ट्रक्टर में इनिशियलाइज़ किया था। इसके अतिरिक्त, हम ओवरराइट पैरामीटर को ट्रू पर सेट करते हैं ताकि वेक्टर स्टोर में पिछली सामग्री ओवरराइट हो जाए। फिर हम दस्तावेज़ से निकाले गए हिस्सों को वेक्टर स्टोर में जोड़ते हैं।
चरण 2: पीडीएफ को पढ़ना, लोड करना और संसाधित करना
पीडीएफ रीडर जिसे हमने पहले शुरू किया था वह एक कस्टम पीडीएफ रीडर है जिसे हम अपने उपयोग के मामले में बनाएंगे। हम पीडीएफ दस्तावेज़ को लोड करने के लिए लैंगचैन के PyPDFLoader का उपयोग करेंगे और दस्तावेज़ को छोटे आकार के टुकड़ों में विभाजित करने के लिए कैरेक्टरटेक्स्टस्प्लिटर का उपयोग करेंगे। फिर हम पेज नंबर और फ़ाइल नाम जैसी अपनी पसंदीदा जानकारी का उपयोग करके टुकड़ों के मेटाडेटा को अपडेट करते हैं। पीडीएफ रीडर टूल के लिए संपूर्ण कोडबेस नीचे दिया गया है:
import os
import config as cfg
from langchain.document_loaders.pdf import PyPDFLoader
from langchain.text_splitter import (
CharacterTextSplitter,
)
from langchain.schema import Document
class PDFReader:
"""Custom PDF Loader to embed metadata with the pdfs."""
def __init__(self) -> None:
self.file_name = ""
self.total_pages = 0
def load_pdf(self, file_path):
# Get the filename from file path
self.file_name = os.path.basename(file_path)
# Initialize Langchain's PyPDFLoader to load the PDF pages
loader = PyPDFLoader(file_path)
# Initialize the text splitter
text_splitter = CharacterTextSplitter(
separator="n",
chunk_size=cfg.PDF_CHARSPLITTER_CHUNKSIZE,
chunk_overlap=cfg.PDF_CHARSPLITTER_CHUNK_OVERLAP,
)
# Load the pages from the document
pages = loader.load()
self.total_pages = len(pages)
chunks = []
# Loop through the pages
for idx, page in enumerate(pages):
# Append each page as Document object with modified metadata
chunks.append(
Document(
page_content=page.page_content,
metadata=dict(
{
"file_name": self.file_name,
"page_no": str(idx + 1),
"total_pages": str(self.total_pages),
}
),
)
)
# Split the documents using splitter
final_chunks = text_splitter.split_documents(chunks)
return final_chunksआइए कोड को तोड़ें और प्रत्येक पंक्ति को शीघ्रता से समझें। क्लास कंस्ट्रक्टर में दो स्थानीय वेरिएबल फ़ाइल_नाम और टोटल_पेज होते हैं जिन्हें क्रमशः खाली स्ट्रिंग और 0 के रूप में प्रारंभ किया जाता है। क्लास में एक मुख्य विधि है जिसे लोड_पीडीएफ कहा जाता है जो दस्तावेज़ सामग्री को लोड करता है और उन्हें छोटे टुकड़ों में विभाजित करता है। हम पहले फ़ाइल पथ का उपयोग करके लैंगचैन के PyPDFLoader को प्रारंभ करते हैं। फिर कैरेक्टर स्प्लिटर ऑब्जेक्ट को इनिशियलाइज़ करें जिसका उपयोग बाद में टुकड़ों को विभाजित करने के लिए किया जाएगा। कैरेक्टर स्प्लिटर 3 तर्क लेता है: विभाजक, खंड आकार, और खंड ओवरलैप।
डिफ़ॉल्ट विभाजक 'एनएन' है जो चंक ओवरलैप का उपयोग करते समय सहायक नहीं है, इसलिए हम इसे 'एन' पर सेट करते हैं। हम अपनी पसंद का चंक आकार और चंक ओवरलैप रख सकते हैं। इस उदाहरण के लिए, हम उन्हें क्रमशः 1000 और 200 पर सेट कर सकते हैं। फिर हम लोडर इंस्टेंस का उपयोग करके दस्तावेज़ को लोड करते हैं और पृष्ठों की कुल संख्या प्राप्त करते हैं।
फिर हम पीडीएफ से लोड किए गए पृष्ठों पर पुनरावृति करते हैं और पेज_कंटेंट और हमारी मेटाडेटा जानकारी का उपयोग करके दस्तावेज़ ऑब्जेक्ट की एक नई सूची बनाते हैं। इस स्तर पर, हमारे पास अतिरिक्त मेटाडेटा के साथ दस्तावेज़ के हिस्सों की एक सूची है। फिर हम टेक्स्ट स्प्लिटर का उपयोग करके टुकड़ों को विभाजित करने और उन्हें वापस करने के लिए आगे बढ़ते हैं।
चरण 3: सिमेंटिक कैश का निर्माण
इसके बाद, आइए एलएलएम प्रतिक्रियाओं को संग्रहीत करने और उन्हें समान प्रश्नों के लिए प्रतिक्रियाओं के रूप में उपयोग करने के लिए हमारी सिमेंटिक कैश सेवा का निर्माण करें। CustomGPTCache टूल के लिए कोड नीचे दिया गया है:
from typing import List
import config as cfg
from langchain.schema import Document
from langchain.vectorstores.deeplake import DeepLake
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
class CustomGPTCache:
def __init__(self) -> None:
# Initialize the embeddings model and cache vector store
self.embeddings = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L12-v2"
)
self.response_cache_store = DeepLake(
dataset_path="database/cache_vectorstore",
embedding=self.embeddings,
read_only=False,
num_workers=4,
verbose=False,
)
def cache_query_response(self, query: str, response: str):
# Create a Document object using query as the content and it's
# response as metadata
doc = Document(
page_content=query,
metadata={"response": response},
)
# Insert the Document object into cache vectorstore
_ = self.response_cache_store.add_documents(documents=[doc])
def find_similar_query_response(self, query: str, threshold: int):
try:
# Find similar query based on the input query
sim_response = self.response_cache_store.similarity_search_with_score(
query=query, k=1
)
# Return the response from the fetched entry if it's score is more
# than threshold
return [
{
"response": res[0].metadata["response"],
}
for res in sim_response
if res[1] > threshold
]
except Exception as e:
raise Exception(e)आइए देखें कि हम कैश सिस्टम का निर्माण कैसे कर रहे हैं। हम कैश के लिए एम्बेडिंग बनाने के लिए सेंटेंस ट्रांसफॉर्मर्स से ऑल-मिनीएलएम-एल12-वी2 मॉडल का उपयोग कर रहे हैं। इस दृष्टिकोण के लिए प्रेरणा यह थी कि: उच्च आयाम के एम्बेडिंग के लिए, हमें असमान प्रश्नों के बीच समानता स्कोर की एक उच्च श्रृंखला मिलती है जिसके परिणामस्वरूप कैश का गलत ट्रिगर होता है।
व्यापक शोध से, मैंने देखा है कि निचले आयामों के एम्बेडिंग का उपयोग करते हुए, 256 कहें, हमें 0.3 से 1.0 के बीच समानता स्कोर की एक विस्तृत श्रृंखला मिलती है। कोड पर वापस आते हुए, हम मॉडल नाम निर्दिष्ट करके लैंगचैन के सेंटेंसट्रांसफॉर्मरएम्बेडिंग का उपयोग करके एम्बेडिंग प्रारंभ करते हैं। इसके बाद, हम डीपलेक वेक्टर स्टोर को आरंभ करते हैं जहां क्वेरी और प्रतिक्रियाएं संग्रहीत की जाएंगी।
ध्यान दें कि कैश वेक्टर स्टोर को आरंभ करते समय हम ओवरराइट पैरामीटर को सही पर सेट नहीं करते हैं क्योंकि यह प्रति-सहज ज्ञान युक्त होगा। हम CustomGPTCache क्लास में दो विधियाँ जोड़ेंगे: कैश_क्वेरी_रेस्पॉन्स और फाइंड_समान_क्वेरी_रेस्पॉन्स। आइए उनके बारे में चर्चा करें.
1. कैश_क्वेरी_रिस्पॉन्स: जब एलएलएम प्रतिक्रिया उत्पन्न होती है तो इस विधि को QAChain में बुलाया जाता है। पेज_कंटेंट में क्वेरी और मेटाडेटा फ़ील्ड में प्रतिक्रिया के साथ एक दस्तावेज़ ऑब्जेक्ट बनाया जाता है। फिर, उस दस्तावेज़ ऑब्जेक्ट को वेक्टर स्टोर में जोड़ा जाता है।
2. समान_क्वेरी_प्रतिक्रिया ढूंढें: इस विधि को प्रत्येक रन के लिए QAChain में कहा जाता है। यह प्रतिक्रियाओं वाले शब्दकोशों की एक सूची लौटाता है। प्रत्येक रन के लिए उपयोगकर्ता क्वेरी को इस विधि में पास किया जाता है। यह कैश वेक्टर स्टोर पर समानता खोज करने के लिए क्वेरी का उपयोग करता है ताकि कैश्ड सबसे समान क्वेरी ढूंढी जा सके। हम वेक्टर स्टोर से केवल एक समान प्रविष्टि प्राप्त करते हैं। फिर हम उन प्रतिक्रियाओं की एक सूची बनाते हैं और अप्रासंगिक प्रतिक्रियाओं को रोकने के लिए समानता स्कोर पर एक सीमा डालते हैं।
चरण 4: क्यूएचेन का उपयोग करके दस्तावेज़ प्रश्न और उत्तर देना
अंत में, हम देखेंगे कि QAChain उपयोगकर्ता प्रश्नों के उत्तर उत्पन्न करने के लिए कैश वेक्टर स्टोर और डॉकस्टोर का उपयोग कैसे करता है। हम मॉडल नाम, एपीआई कुंजी इत्यादि जैसे आवश्यक पैरामीटर का उपयोग करके क्लास कंस्ट्रक्टर में जेमिनी एम्बेडिंग और जेमिनी मॉडल को इनिशियलाइज़ करते हैं। हम यहां कैश को भी इनिशियलाइज़ करते हैं जिसका उपयोग अन्य तरीकों में किया जाएगा। फिर, हम उपयोगकर्ता प्रश्नों को संभालने के लिए QAChain क्लास में दो तरीके जोड़ेंगे: जेनरेट_रेस्पॉन्स और आस्क_क्वेश्चन।
1. जनरेट_रेस्पॉन्स: यह विधि QAChain के LLM प्रतिक्रिया भाग को संभालती है। यह बस एक उपयोगकर्ता क्वेरी लेता है और लैंगचैन की रिट्रीवलक्यूए चेन का उपयोग करके क्वेरी के लिए प्रतिक्रिया उत्पन्न करता है। प्रतिक्रिया उत्पन्न होने के बाद, इसे CustomGPTCache की कैशे_क्वेरी_रेस्पॉन्स विधि का उपयोग करके कैश किया जाता है, और प्रतिक्रिया वापस कर दी जाती है।
2. प्रश्न पूछें: इस विधि को प्रत्येक उपयोगकर्ता प्रतिक्रिया के लिए बुलाया जाता है। सबसे पहले, CustomGPTCache की find_similar_query_response विधि को उपयोगकर्ता क्वेरी का उपयोग करके कॉल किया जाता है। यदि यह प्रतिक्रियाओं की एक सूची लौटाता है, तो प्रतिक्रिया लौटा दी जाती है, अन्यथा, उपयोगकर्ता क्वेरी का उपयोग करके generate_response विधि को कॉल किया जाता है। इसके अतिरिक्त, यदि कैश पक्ष से कोई अपवाद उठाया जाता है तो generate_response विधि को कॉल किया जाता है। संदर्भ के लिए QAChain पाइपलाइन के लिए कोडबेस नीचे दिया गया है।
import config as cfg
from src.cache import CustomGPTCache
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.vectorstores.deeplake import DeepLake
from langchain_google_genai import (
GoogleGenerativeAIEmbeddings,
ChatGoogleGenerativeAI
)
class QAChain:
def __init__(self) -> None:
# Initialize Gemini Embeddings
self.embeddings = GoogleGenerativeAIEmbeddings(
model="models/embedding-001",
google_api_key=cfg.GOOGLE_API_KEY,
task_type="retrieval_query",
)
# Initialize Gemini Chat model
self.model = ChatGoogleGenerativeAI(
model="gemini-pro",
temperature=0.3,
google_api_key=cfg.GOOGLE_API_KEY,
convert_system_message_to_human=True,
)
# Initialize GPT Cache
self.cache = CustomGPTCache()
self.text_vectorstore = None
self.text_retriever = None
def ask_question(self, query):
try:
# Search for similar query response in cache
cached_response = self.cache.find_similar_query_response(
query=query, threshold=cfg.CACHE_THRESHOLD
)
# If similar query response is present,vreturn it
if len(cached_response) > 0:
print("Using cache")
result = cached_response[0]["response"]
# Else generate response for the query
else:
print("Generating response")
result = self.generate_response(query=query)
except Exception as _:
print("Exception raised. Generating response.")
result = self.generate_response(query=query)
return result
def generate_response(self, query: str):
# Initialize the vectorstore and retriever object
vstore = DeepLake(
dataset_path="database/text_vectorstore",
embedding=self.embeddings,
read_only=True,
num_workers=4,
verbose=False,
)
retriever = vstore.as_retriever(search_type="similarity")
retriever.search_kwargs["distance_metric"] = "cos"
retriever.search_kwargs["fetch_k"] = 20
retriever.search_kwargs["k"] = 15
# Write prompt to guide the LLM to generate response
prompt_template = """
<YOUR PROMPT HERE>
Context: {context}
Question: {question}
Answer:
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
# Create Retrieval QA chain
qa = RetrievalQA.from_chain_type(
llm=self.model,
retriever=retriever,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
)
# Run the QA chain and store the response in cache
result = qa({"query": query})["result"]
self.cache.cache_query_response(query=query, response=result)
return resultअब जब हमारे पास पूरी पाइपलाइन तैयार है, तो आइए अपने एप्लिकेशन का परीक्षण करने के लिए उनका उपयोग करें। पहला कदम दस्तावेज़ को अंतर्ग्रहण करना है। हम Ingestion ऑब्जेक्ट को इनिशियलाइज़ करते हैं और संग्रहीत किए जाने वाले दस्तावेज़ के लिए फ़ाइल पथ का उपयोग करके ingest_document विधि को कॉल करते हैं।
from src.ingestion import Ingestion
ingestion = Ingestion()
file = "Apple 10k.pdf"
ingestion.ingest_documents(
file=file
)दस्तावेज़ के अंतर्ग्रहण के बाद, हम QAChain ऑब्जेक्ट को आरंभ करेंगे। फिर हम प्रतिक्रिया उत्पन्न करने के लिए उपयोगकर्ता क्वेरी का उपयोग करके Ask_question विधि को कॉल करते हैं।
from src.qachain import QAChain
qna = QAChain()
%%time
query = "What were the highlights for 2nd quarter of FY2023?"
results = qna.ask_question(
query=query
)
print(results)
# OUTPUT:
# Generating response
# The highlights for the second quarter of FY2023 were:
# • MacBook Pro 14”, MacBook Pro 16” and Mac mini; and
# • Second-generation HomePod.
# CPU times: total: 2.94 s
# Wall time: 11.4 s
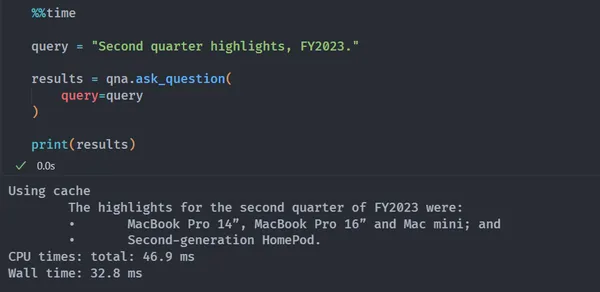
%%time
query = "Second quarter highlights, FY2023."
results = qna.ask_question(
query=query
)
print(results)
# OUTPUT:
# Using cache
# The highlights for the second quarter of FY2023 were:
# • MacBook Pro 14”, MacBook Pro 16” and Mac mini; and
# • Second-generation HomePod.
# CPU times: total: 46.9 ms
# Wall time: 32.8 ms
अनुप्रयोग प्रदर्शन और सीमाएँ
कई आरएजी मूल्यांकन लाइब्रेरी हैं जिनका उपयोग एप्लिकेशन के प्रदर्शन का मूल्यांकन करने के लिए किया जा सकता है। दो सबसे लोकप्रिय हैं RAGAS और टॉनिक वैलिडेट मेट्रिक्स। दोनों उत्तर समानता स्कोर, रिट्रीवल प्रिसिजन, ऑग्मेंटेशन प्रिसिजन, ऑग्मेंटेशन सटीकता/प्रासंगिकता और रिट्रीवल के-रिकॉल जैसे समान मेट्रिक्स प्रदान करते हैं, जो एप्लिकेशन के प्रदर्शन का मूल्यांकन करने में मदद करते हैं। हालाँकि उपरोक्त कोडबेस में कुछ अपवादों को नियंत्रित किया जाता है, फिर भी कुछ मामले ऐसे हैं जहाँ एप्लिकेशन क्रैश हो सकता है। पीडीएफरीडर के पास वर्तमान में इनपुट फ़ाइल प्रकार पर कोई जांच नहीं है जिसे संभालने की आवश्यकता है।
यह एप्लिकेशन चिकित्सा, वित्तीय, औद्योगिक, ई-कॉमर्स इत्यादि जैसे व्यावसायिक उपयोग के मामलों की एक विस्तृत श्रृंखला में बड़े पैमाने पर पुन: प्रयोज्य है। चिकित्सा उद्योगों में, आरएजी पाइपलाइन उपकरण विफलताओं के त्वरित निवारण, चिकित्सा स्थिति के लिए सही दवा का निर्णय लेने आदि में मदद कर सकती है। आरएजी पाइपलाइनें पलक झपकते ही वित्तीय दस्तावेजों के एक बड़े भंडार से प्रश्नों का उत्तर देने में मदद कर सकती हैं। उनकी त्वरित पुनर्प्राप्ति और उत्तर देने की क्षमताएं उन्हें बड़े डेटासेट पर प्रश्नों के उत्तर देने के लिए आदर्श बनाती हैं। आरएजी पाइपलाइन किसी विषय की पिछली शोध प्रगति की त्वरित समीक्षा करने और आगे के शोध दायरे का सुझाव देने में भी सक्षम हो सकती है।
हालाँकि हमारी वर्तमान पाइपलाइन किसी भी उपयोग के मामले में उपयोग के लिए तैयार है, लेकिन कुछ सीमाएँ हैं। जेमिनी प्रो मॉडल की वर्तमान संदर्भ लंबाई 32k है जो बड़े ज्ञान आधारों के लिए उपयुक्त नहीं हो सकती है। एक वैकल्पिक सुझाव का उपयोग करना होगा जेमिनी प्रो 1.5 मॉडल जो 1 मिलियन तक की संदर्भ लंबाई का समर्थन करता है। वर्तमान पाइपलाइन में कोई चैट मेमोरी नहीं है, इसलिए, मॉडल में पिछली बातचीत का संदर्भ नहीं होगा। लैंगचैन कई मेमोरी विकल्प (मेमोरी डॉक्स) प्रदान करता है जिन्हें आसानी से पाइपलाइन में एकीकृत किया जा सकता है।
कोड पुन: प्रयोज्य
- अंतर्ग्रहण पाइपलाइन कोड का उपयोग अन्य अनुप्रयोगों के लिए अंतर्ग्रहण सिस्टम बनाने के लिए पुन: उपयोग किया जा सकता है जिनके लिए दस्तावेज़ भंडारण और पुनर्प्राप्ति की आवश्यकता होती है।
- पीडीएफ रीडर टूल को अन्य अनुप्रयोगों के लिए पुन: उपयोग किया जा सकता है जिनके लिए पीडीएफ दस्तावेजों से प्रसंस्करण और मेटाडेटा निष्कर्षण की आवश्यकता होती है।
- एलएलएम प्रतिक्रियाओं या इसी तरह के उपयोग के मामलों की कुशल कैशिंग और पुनर्प्राप्ति को लागू करने के लिए CustomGPTCache कोड का उपयोग अन्य परियोजनाओं में किया जा सकता है।
- QAChain वर्ग को अन्य प्रश्न-उत्तर प्रणालियों के लिए अनुकूलित किया जा सकता है जो दस्तावेज़ भंडार और कैशिंग तंत्र का उपयोग करते हैं।
निष्कर्ष
तो, दोस्तों, इस तरह आप जेमिनी प्रो और लैंगचैन का उपयोग करके आरएजी-संचालित प्रश्न उत्तर और सिमेंटिक कैशिंग के माध्यम से अपने दस्तावेज़ों के साथ संवाद कर सकते हैं!
इस लेख में, हमने एक पाइपलाइन विकसित की है जो बुद्धिमान QnA के लिए दस्तावेज़ों को संभालने के लिए एक व्यापक दृष्टिकोण दिखाती है। Google की जेमिनी एम्बेडिंग, एक कस्टम पीडीएफ रीडर और सिमेंटिक कैशिंग को एकीकृत करके, यह RAG प्रणाली उपयोगकर्ता के प्रश्नों के उत्तर प्रदान करने में दक्षता और सटीकता बनाए रखती है। इसके अलावा, कोडबेस अत्यधिक अनुकूलनीय, स्केलेबल और न्यूनतम कोड परिवर्तनों के साथ विभिन्न QnA उपयोग मामलों के लिए विश्वसनीय है!
चाबी छीन लेना
- आरएजी प्रणाली में प्रश्न-उत्तर के लिए दस्तावेजों को अपलोड करने और संग्रहीत करने के लिए एक अंतर्ग्रहण पाइपलाइन का निर्माण शामिल है।
- अंतर्ग्रहण पाइपलाइन दस्तावेज़ एम्बेडिंग के लिए जेमिनी एम्बेडिंग और मेटाडेटा निष्कर्षण के लिए एक कस्टम पीडीएफ रीडर का उपयोग करती है।
- समान प्रश्नों के लिए एलएलएम प्रतिक्रियाओं को कुशलतापूर्वक संग्रहीत और पुनर्प्राप्त करने के लिए एक कस्टम सिमेंटिक कैश सेवा लागू की गई है।
- QAChain वर्ग उपयोगकर्ता प्रश्नों के उत्तर उत्पन्न करने और कैश और वेक्टर स्टोर का उपयोग करने के लिए जिम्मेदार है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2024/03/rag-powered-document-qna-semantic-caching-with-gemini-pro/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 1.3
- 10K
- 11
- 12
- 14
- 15% तक
- 17
- 19
- 2%
- 20
- 200
- 21
- 23
- 25
- 26
- 28
- 2nd
- 32
- 36
- 4
- 4 कदम
- 46
- 5
- 6
- 60
- 8
- 87
- 9
- a
- About
- ऊपर
- शुद्धता
- सही
- सही रूप में
- कार्रवाई
- अनुकूलित
- जोड़ना
- जोड़ा
- अतिरिक्त
- इसके अतिरिक्त
- प्रगति
- आगमन
- बाद
- पूर्व
- AI
- सहायता
- सब
- की अनुमति देता है
- साथ - साथ
- पहले ही
- भी
- हालांकि
- an
- और
- जवाब
- जवाब दे
- जवाब
- कोई
- एपीआई
- Apple
- आवेदन
- अनुप्रयोगों
- दृष्टिकोण
- हैं
- तर्क
- चारों ओर
- लेख
- AS
- पूछना
- पूछा
- At
- ध्यान
- संवर्धित
- से बचने
- वापस
- आधारित
- BE
- बन
- हो जाता है
- किया गया
- से पहले
- शुरू करना
- नीचे
- के बीच
- झपकी
- के छात्रों
- टूटना
- निर्माण
- इमारत
- व्यापार
- लेकिन
- by
- कैश
- कैशिंग
- कॉल
- बुलाया
- कॉल
- कर सकते हैं
- क्षमताओं
- मामला
- मामलों
- कुछ
- श्रृंखला
- चेन
- बदलना
- चरित्र
- बातचीत
- चेक
- चुनाव
- कक्षा
- बादल
- कोड
- codebase
- अ रहे है
- संवाद
- व्यापक
- संकल्पना
- शर्त
- इसके फलस्वरूप
- युक्त
- सामग्री
- अंतर्वस्तु
- प्रसंग
- संवादी
- बातचीत
- मूल
- सही
- गाड़ी
- लागत
- सी पी यू
- Crash
- बनाना
- बनाया
- बनाना
- वर्तमान
- वर्तमान में
- रिवाज
- डाटाबेस
- डेटासेट
- निर्णय लेने से
- डीईएफ़
- चूक
- विस्तृत
- विकसित
- अलग
- डीआईजी
- आयाम
- आयाम
- चर्चा करना
- चर्चा की
- चर्चा
- डुबकी
- do
- डॉक्स
- दस्तावेज़
- दस्तावेजों
- डॉलर
- dont
- नीचे
- दो
- e
- ई - कॉमर्स
- से प्रत्येक
- पूर्व
- आसान
- दक्षता
- कुशल
- कुशलता
- अनायास
- अन्य
- एम्बेड
- खाली
- सक्षम
- संपूर्ण
- प्रविष्टि
- वातावरण
- आदि
- ईथर (ईटीएच)
- मूल्यांकन करें
- मूल्यांकन
- प्रत्येक
- उदाहरण
- सिवाय
- अपवाद
- महंगा
- व्यापक
- बड़े पैमाने पर
- अतिरिक्त
- निष्कर्षण
- आंख
- विफलताओं
- लाए गए
- कुछ
- खेत
- पट्टिका
- अंतिम
- वित्तीय
- खोज
- प्रथम
- का पालन करें
- निम्नलिखित
- के लिए
- मुक्त
- से
- निधिकरण
- आगे
- मिथुन राशि
- उत्पन्न
- उत्पन्न
- उत्पन्न करता है
- सृजन
- पीढ़ी
- मिल
- Go
- जा
- अच्छा
- गूगल
- Google मेघ
- गूगल की
- गाइड
- संभालना
- संभाला
- हैंडल
- हैंडलिंग
- हाथों पर
- हो जाता
- है
- मदद
- सहायक
- मदद करता है
- यहाँ उत्पन्न करें
- हाई
- उच्चतर
- हाइलाइट
- अत्यधिक
- शौक रखने वालों
- कैसे
- How To
- तथापि
- HTTPS
- i
- आदर्श
- IDX
- if
- तत्काल
- लागू करने के
- कार्यान्वित
- कार्यान्वयन
- आयात
- in
- अन्य में
- औद्योगिक
- उद्योगों
- करें-
- निवेश
- स्थापित
- उदाहरण
- साधन
- एकीकृत
- एकीकृत
- घालमेल
- बुद्धिमान
- इंटरफेस
- के भीतर
- में
- शामिल
- मुद्दा
- IT
- आईटी इस
- छलांग
- रखना
- कुंजी
- बच्चा
- ज्ञान
- भाषा
- बड़ा
- बाद में
- लांच
- जानें
- लंबाई
- कम
- लाभ
- पुस्तकालयों
- पसंद
- सीमाओं
- सीमित
- लाइन
- लिनक्स
- सूची
- एलएलएम
- भार
- लोडर
- लोड हो रहा है
- भार
- स्थानीय
- देखिए
- लॉट
- कम
- मैक
- मैकबुक
- MacOS
- मुख्य
- का कहना है
- बनाना
- तंत्र
- मेडिकल
- दवा
- याद
- मेटाडाटा
- तरीका
- तरीकों
- मेट्रिक्स
- हो सकता है
- दस लाख
- मन
- कम से कम
- आदर्श
- संशोधित
- अधिक
- अधिक कुशल
- और भी
- अधिकांश
- सबसे लोकप्रिय
- अभिप्रेरण
- MS
- बहुत
- नाम
- नामों
- आवश्यक
- आवश्यकता
- की जरूरत है
- नया
- अगला
- नहीं
- कोई नहीं
- ध्यान देने योग्य
- अभी
- संख्या
- संख्या
- वस्तु
- वस्तुओं
- मनाया
- of
- प्रस्ताव
- on
- ONE
- लोगों
- केवल
- OpenAI
- ऑप्शंस
- or
- OS
- अन्य
- अन्यथा
- हमारी
- उत्पादन
- के ऊपर
- ओवरलैप
- अपना
- संकुल
- पृष्ठ
- पृष्ठों
- प्रदत्त
- प्राचल
- पैरामीटर
- भाग
- पारित कर दिया
- पथ
- पीडीएफ
- प्रदर्शन
- पाइपलाइन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- कृप्या अ
- लोकप्रिय
- संचालित
- शुद्धता
- वरीय
- वर्तमान
- संरक्षण
- को रोकने के
- पिछला
- प्रति
- बढ़ना
- प्रक्रिया
- प्रसंस्करण
- परियोजना
- परियोजनाओं
- संकेतों
- बशर्ते
- प्रदान करता है
- प्रदान कर
- रखना
- अजगर
- क्यू एंड ए
- तिमाही
- प्रश्नों
- सवाल
- प्रश्न
- प्रशन
- त्वरित
- जल्दी से
- खपरैल
- उठाना
- उठाया
- रेंज
- पाठक
- पढ़ना
- तैयार
- मान्यता देना
- को कम करने
- कम कर देता है
- संदर्भ
- विश्वसनीय
- की आवश्यकता होती है
- अपेक्षित
- आवश्यकताएँ
- अनुसंधान
- प्रतिक्रिया
- प्रतिक्रियाएं
- जिम्मेदार
- परिणाम
- परिणाम
- बहाली
- वापसी
- लौटने
- रिटर्न
- पुन: प्रयोज्य
- पुन: उपयोग
- की समीक्षा
- मजबूत
- रन
- s
- वही
- कहना
- स्केलेबल
- क्षेत्र
- स्कोर
- स्कोर
- Search
- दूसरा
- द्वितीय तिमाही
- अनुभाग
- लगता है
- चयन
- स्व
- अर्थ
- वाक्य
- सेवा
- सेट
- कई
- शोकेस
- पक्ष
- समान
- केवल
- के बाद से
- आकार
- छोटा
- छोटे
- So
- हल
- निर्दिष्ट करना
- बिताना
- विभाजित
- विभाजन
- ट्रेनिंग
- कदम
- कदम
- भंडारण
- की दुकान
- संग्रहित
- भंडार
- भंडारण
- तार
- सुझाव
- उपयुक्त
- समर्थन करता है
- प्रणाली
- सिस्टम
- लेता है
- कार्य
- शर्तों
- परीक्षण
- टेक्स्ट
- से
- कि
- RSI
- दुनिया
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- वे
- इसका
- उन
- द्वार
- यहाँ
- पहर
- बार
- सेवा मेरे
- साधन
- उपकरण
- विषय
- कुल
- ट्रान्सफ़ॉर्मर
- <strong>उद्देश्य</strong>
- कोशिश
- दो
- टाइप
- समझना
- अनावश्यक
- अपडेट
- प्रयोग
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ता
- का उपयोग करता है
- का उपयोग
- इस्तेमाल
- उपयोग
- सत्यापित करें
- परिवर्तनशील
- चर
- विविधता
- वेक्टर
- संस्करण
- वास्तविक
- प्रतीक्षा
- चलना
- दीवार
- करना चाहते हैं
- था
- we
- webp
- कुंआ
- थे
- क्या
- कब
- कौन कौन से
- जब
- कौन
- चौड़ा
- विस्तृत श्रृंखला
- व्यापक
- मर्जी
- खिड़कियां
- साथ में
- अंदर
- बिना
- शब्द
- विश्व
- होगा
- लिखना
- वर्ष
- इसलिए आप
- आपका
- यूट्यूब
- जेफिरनेट