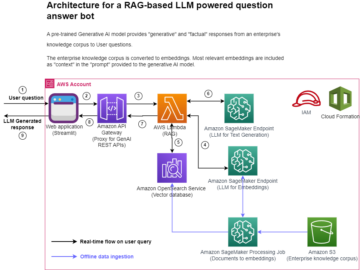
कंप्यूटर विज़न में, सिमेंटिक सेगमेंटेशन एक छवि में प्रत्येक पिक्सेल को लेबल के ज्ञात सेट से एक वर्ग के साथ वर्गीकृत करने का कार्य है, जैसे कि समान लेबल वाले पिक्सेल कुछ विशेषताओं को साझा करते हैं। यह इनपुट छवियों का एक विभाजन मुखौटा उत्पन्न करता है। उदाहरण के लिए, निम्नलिखित छवियां एक विभाजन मुखौटा दिखाती हैं cat लेबल।
 |
 |
नवम्बर 2018 में, अमेज़न SageMaker सेजमेकर सिमेंटिक सेगमेंटेशन एल्गोरिथम के लॉन्च की घोषणा की। इस एल्गोरिथम के साथ, आप अपने मॉडल को सार्वजनिक डेटासेट या अपने स्वयं के डेटासेट के साथ प्रशिक्षित कर सकते हैं। लोकप्रिय इमेज सेगमेंटेशन डेटासेट में कॉमन ऑब्जेक्ट इन कॉन्टेक्स्ट (COCO) डेटासेट और PASCAL विज़ुअल ऑब्जेक्ट क्लासेस (PASCAL VOC) शामिल हैं, लेकिन उनके लेबल की कक्षाएं सीमित हैं और आप लक्ष्य ऑब्जेक्ट पर एक मॉडल को प्रशिक्षित करना चाह सकते हैं जो इसमें शामिल नहीं हैं। सार्वजनिक डेटासेट। इस मामले में, आप उपयोग कर सकते हैं अमेज़ॅन सैजमेकर ग्राउंड ट्रुथ अपने स्वयं के डेटासेट को लेबल करने के लिए।
इस पोस्ट में, मैं निम्नलिखित समाधान प्रदर्शित करता हूं:
- सिमेंटिक सेगमेंटेशन डेटासेट को लेबल करने के लिए ग्राउंड ट्रुथ का उपयोग करना
- सेजमेकर बिल्ट-इन सिमेंटिक सेगमेंटेशन एल्गोरिथम के लिए ग्राउंड ट्रुथ से परिणामों को आवश्यक इनपुट प्रारूप में बदलना
- मॉडल को प्रशिक्षित करने और निष्कर्ष निकालने के लिए सिमेंटिक सेगमेंटेशन एल्गोरिदम का उपयोग करना
सिमेंटिक सेगमेंटेशन डेटा लेबलिंग
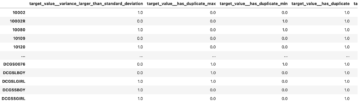
सिमेंटिक सेगमेंटेशन के लिए मशीन लर्निंग मॉडल बनाने के लिए, हमें एक डेटासेट को पिक्सेल स्तर पर लेबल करना होगा। ग्राउंड ट्रुथ आपको के माध्यम से मानव व्याख्याकारों का उपयोग करने का विकल्प देता है अमेज़ॅन मैकेनिकल तुर्क, तृतीय-पक्ष विक्रेता, या आपका अपना निजी कार्यबल। कार्यबल के बारे में अधिक जानने के लिए, देखें Workforces बनाएँ और प्रबंधित करें. यदि आप लेबलिंग कार्यबल को स्वयं प्रबंधित नहीं करना चाहते हैं, अमेज़न सेजमेकर ग्राउंड ट्रुथ प्लस नई टर्नकी डेटा लेबलिंग सेवा के रूप में एक और बढ़िया विकल्प है जो आपको उच्च-गुणवत्ता वाले प्रशिक्षण डेटासेट जल्दी से बनाने में सक्षम बनाता है और लागत को 40% तक कम करता है। इस पोस्ट के लिए, मैं आपको दिखाता हूं कि कैसे ग्राउंड ट्रुथ ऑटो-सेगमेंट फीचर के साथ डेटासेट को मैन्युअल रूप से लेबल करना है और मैकेनिकल तुर्क वर्कफोर्स के साथ क्राउडसोर्स लेबलिंग करना है।
ग्राउंड ट्रुथ के साथ मैनुअल लेबलिंग
दिसंबर 2019 में, ग्राउंड ट्रुथ ने लेबलिंग थ्रूपुट को बढ़ाने और सटीकता में सुधार करने के लिए सिमेंटिक सेगमेंटेशन लेबलिंग यूजर इंटरफेस में एक ऑटो-सेगमेंट फीचर जोड़ा। अधिक जानकारी के लिए देखें अमेज़ॅन सेजमेकर ग्राउंड ट्रुथ के साथ सिमेंटिक सेगमेंटेशन लेबलिंग करते समय ऑटो-सेगमेंटिंग ऑब्जेक्ट्स. इस नई सुविधा के साथ, आप विभाजन कार्यों पर अपनी लेबलिंग प्रक्रिया को तेज कर सकते हैं। किसी छवि में किसी ऑब्जेक्ट को कैप्चर करने के लिए कसकर फिटिंग वाले बहुभुज को खींचने या ब्रश टूल का उपयोग करने के बजाय, आप केवल चार बिंदुओं को आकर्षित करते हैं: ऑब्जेक्ट के सबसे ऊपर, सबसे नीचे, सबसे बाएं, और दाएं-अधिकांश बिंदुओं पर। ग्राउंड ट्रुथ इन चार बिंदुओं को इनपुट के रूप में लेता है और ऑब्जेक्ट के चारों ओर कसकर फिटिंग मास्क बनाने के लिए डीप एक्सट्रीम कट (DEXTR) एल्गोरिथम का उपयोग करता है। इमेज सिमेंटिक सेगमेंटेशन लेबलिंग के लिए ग्राउंड ट्रुथ का उपयोग करने वाले ट्यूटोरियल के लिए, देखें छवि शब्दार्थ विभाजनment. किसी ऑब्जेक्ट के चार चरम बिंदुओं को चुनने के बाद ऑटो-सेगमेंटेशन टूल स्वचालित रूप से सेगमेंटेशन मास्क कैसे उत्पन्न करता है, इसका एक उदाहरण निम्नलिखित है।


मैकेनिकल तुर्क कार्यबल के साथ क्राउडसोर्सिंग लेबलिंग
यदि आपके पास एक बड़ा डेटासेट है और आप स्वयं सैकड़ों या हजारों छवियों को मैन्युअल रूप से लेबल नहीं करना चाहते हैं, तो आप मैकेनिकल तुर्क का उपयोग कर सकते हैं, जो एक ऑन-डिमांड, स्केलेबल, मानव कार्यबल प्रदान करता है ताकि वह कार्य पूरा कर सके जो मनुष्य कंप्यूटर से बेहतर कर सकते हैं। मैकेनिकल तुर्क सॉफ्टवेयर अपनी सुविधानुसार टुकड़ों में काम करने के इच्छुक हजारों श्रमिकों को नौकरी के प्रस्तावों को औपचारिक रूप देता है। सॉफ़्टवेयर प्रदर्शन किए गए कार्य को भी पुनर्प्राप्त करता है और इसे आपके लिए संकलित करता है, अनुरोधकर्ता, जो श्रमिकों को संतोषजनक कार्य (केवल) के लिए भुगतान करता है। मैकेनिकल तुर्क के साथ आरंभ करने के लिए, देखें अमेज़न मैकेनिकल तुर्क का परिचय.
एक लेबलिंग कार्य बनाएँ
समुद्री कछुए डेटासेट के लिए मैकेनिकल तुर्क लेबलिंग नौकरी का एक उदाहरण निम्नलिखित है। समुद्री कछुआ डेटासेट कागल प्रतियोगिता से है समुद्री कछुआ चेहरा पहचान, और मैंने प्रदर्शन उद्देश्यों के लिए डेटासेट की 300 छवियों का चयन किया। सार्वजनिक डेटासेट में समुद्री कछुआ एक सामान्य वर्ग नहीं है, इसलिए यह एक ऐसी स्थिति का प्रतिनिधित्व कर सकता है जिसके लिए बड़े पैमाने पर डेटासेट को लेबल करने की आवश्यकता होती है।
- SageMaker कंसोल पर, चुनें नौकरियों पर लेबल लगाना नेविगेशन फलक में
- चुनें लेबलिंग कार्य बनाएँ.
- अपनी नौकरी के लिए एक नाम दर्ज करें।
- के लिए इनपुट डेटा सेटअप, चुनते हैं स्वचालित डेटा सेटअप.
यह इनपुट डेटा का एक मेनिफेस्ट उत्पन्न करता है। - के लिए इनपुट डेटासेट के लिए S3 स्थान, डेटासेट के लिए पथ दर्ज करें।

- के लिए कार्य श्रेणी, चुनें छवि.
- के लिए कार्य चयन, चुनते हैं शब्दार्थ विभाजन.

- के लिए कार्यकर्ता प्रकार, चुनते हैं अमेज़ॅन मैकेनिकल तुर्क.
- कार्य समयबाह्य, कार्य समाप्ति समय और मूल्य प्रति कार्य के लिए अपनी सेटिंग्स कॉन्फ़िगर करें।

- एक लेबल जोड़ें (इस पोस्ट के लिए,
sea turtle), और लेबलिंग निर्देश प्रदान करें। - चुनें बनाएं.

लेबलिंग कार्य सेट करने के बाद, आप सेजमेकर कंसोल पर लेबलिंग प्रगति की जांच कर सकते हैं। जब इसे पूर्ण के रूप में चिह्नित किया जाता है, तो आप परिणामों की जांच करने के लिए कार्य चुन सकते हैं और अगले चरणों के लिए उनका उपयोग कर सकते हैं।

डेटासेट परिवर्तन
ग्राउंड ट्रुथ से आउटपुट प्राप्त करने के बाद, आप इस डेटासेट पर एक मॉडल को प्रशिक्षित करने के लिए सेजमेकर बिल्ट-इन एल्गोरिदम का उपयोग कर सकते हैं। सबसे पहले, आपको सेजमेकर सिमेंटिक सेगमेंटेशन एल्गोरिथम के लिए अनुरोधित इनपुट इंटरफ़ेस के रूप में लेबल किए गए डेटासेट को तैयार करने की आवश्यकता है।
अनुरोधित इनपुट डेटा चैनल
सेजमेकर सिमेंटिक सेगमेंटेशन आपके प्रशिक्षण डेटासेट को संग्रहीत करने की अपेक्षा करता है अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस 3)। Amazon S3 में डेटासेट को दो चैनलों में प्रस्तुत किए जाने की उम्मीद है, एक के लिए train और एक के लिए validation, चार निर्देशिकाओं का उपयोग करते हुए, दो छवियों के लिए और दो एनोटेशन के लिए। एनोटेशन के असम्पीडित PNG छवियों के होने की उम्मीद है। डेटासेट में एक लेबल मैप भी हो सकता है जो बताता है कि एनोटेशन मैपिंग कैसे स्थापित की जाती है। यदि नहीं, तो एल्गोरिथ्म डिफ़ॉल्ट का उपयोग करता है। अनुमान के लिए, एक समापन बिंदु a . के साथ छवियों को स्वीकार करता है image/jpeg सामग्री प्रकार। डेटा चैनलों की आवश्यक संरचना निम्नलिखित है:
ट्रेन और सत्यापन निर्देशिका में प्रत्येक JPG छवि में समान नाम के साथ संबंधित PNG लेबल छवि होती है train_annotation और validation_annotation निर्देशिका। यह नामकरण परंपरा एल्गोरिथ्म को प्रशिक्षण के दौरान एक लेबल को उसकी संगत छवि के साथ जोड़ने में मदद करती है। ट्रेन, train_annotation, सत्यापन, और validation_annotation चैनल अनिवार्य हैं। एनोटेशन सिंगल-चैनल PNG इमेज हैं। प्रारूप तब तक काम करता है जब तक छवि में मेटाडेटा (मोड) एल्गोरिदम को एनोटेशन छवियों को एकल-चैनल 8-बिट अहस्ताक्षरित पूर्णांक में पढ़ने में मदद करता है।
ग्राउंड ट्रुथ लेबलिंग जॉब से आउटपुट
ग्राउंड ट्रुथ लेबलिंग जॉब से उत्पन्न आउटपुट में निम्नलिखित फ़ोल्डर संरचना होती है:
विभाजन मास्क में सहेजे जाते हैं s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. प्रत्येक एनोटेशन छवि एक .png फ़ाइल होती है जिसका नाम स्रोत छवि के सूचकांक और उस समय के नाम पर रखा जाता है जब यह छवि लेबलिंग पूरी हुई थी। उदाहरण के लिए, मैकेनिकल तुर्क वर्कफोर्स (1_0-2022-02T10:17:41.png) द्वारा उत्पन्न सोर्स इमेज (Image_04.724225.jpg) और इसका सेगमेंटेशन मास्क निम्नलिखित हैं। ध्यान दें कि मुखौटा का सूचकांक स्रोत छवि नाम की संख्या से भिन्न होता है।
 |
 |
लेबलिंग जॉब से आउटपुट मेनिफेस्ट में है /manifests/output/output.manifest फ़ाइल। यह एक JSON फ़ाइल है, और प्रत्येक पंक्ति स्रोत छवि और उसके लेबल और अन्य मेटाडेटा के बीच मैपिंग रिकॉर्ड करती है। निम्न JSON लाइन दिखाए गए स्रोत छवि और उसके एनोटेशन के बीच मैपिंग रिकॉर्ड करती है:
स्रोत छवि को Image_1.jpg कहा जाता है, और एनोटेशन का नाम 0_2022-02-10T17:41: 04.724225.png है। डेटा को सेजमेकर सिमेंटिक सेगमेंटेशन एल्गोरिथम के आवश्यक डेटा चैनल प्रारूपों के रूप में तैयार करने के लिए, हमें एनोटेशन नाम बदलने की आवश्यकता है ताकि इसका नाम स्रोत जेपीजी छवियों के समान हो। और हमें डेटासेट को भी विभाजित करने की आवश्यकता है train और validation स्रोत छवियों और एनोटेशन के लिए निर्देशिका।
ग्राउंड ट्रुथ लेबलिंग जॉब से आउटपुट को अनुरोधित इनपुट फॉर्मेट में बदलना
आउटपुट बदलने के लिए, निम्न चरणों को पूरा करें:
- Amazon S3 से स्थानीय निर्देशिका में लेबलिंग कार्य से सभी फ़ाइलें डाउनलोड करें:
- मेनिफेस्ट फ़ाइल पढ़ें और एनोटेशन के नामों को स्रोत छवियों के समान नामों में बदलें:
- ट्रेन और सत्यापन डेटासेट को विभाजित करें:
- सिमेंटिक सेगमेंटेशन एल्गोरिथम डेटा चैनल के लिए आवश्यक प्रारूप में एक निर्देशिका बनाएं:
- ट्रेन और सत्यापन छवियों और उनके एनोटेशन को बनाई गई निर्देशिकाओं में ले जाएं।
- छवियों के लिए, निम्न कोड का उपयोग करें:
- एनोटेशन के लिए, निम्न कोड का उपयोग करें:
- Amazon S3 पर ट्रेन और सत्यापन डेटासेट और उनके एनोटेशन डेटासेट अपलोड करें:
सेजमेकर सिमेंटिक सेगमेंटेशन मॉडल ट्रेनिंग
इस खंड में, हम आपके सिमेंटिक सेगमेंटेशन मॉडल को प्रशिक्षित करने के चरणों के माध्यम से चलते हैं।
नमूना नोटबुक का पालन करें और डेटा चैनल सेट करें
आप में निर्देशों का पालन कर सकते हैं सिमेंटिक सेगमेंटेशन एल्गोरिथम अब अमेज़न सेजमेकर में उपलब्ध है अपने लेबल किए गए डेटासेट में सिमेंटिक सेगमेंटेशन एल्गोरिदम लागू करने के लिए। यह नमूना नोटबुक एल्गोरिदम का परिचय देने वाला एक एंड-टू-एंड उदाहरण दिखाता है। नोटबुक में, आप सीखते हैं कि पूरी तरह से दृढ़ नेटवर्क का उपयोग करके सिमेंटिक सेगमेंटेशन मॉडल को कैसे प्रशिक्षित और होस्ट किया जाए (FCN) एल्गोरिथ्म का उपयोग कर पास्कल वीओसी डेटासेट प्रशिक्षण के लिए। चूंकि मैं पास्कल वीओसी डेटासेट से किसी मॉडल को प्रशिक्षित करने की योजना नहीं बना रहा हूं, इसलिए मैंने इस नोटबुक में चरण 3 (डेटा तैयारी) को छोड़ दिया है। इसके बजाय, मैंने सीधे बनाया train_channel, train_annotation_channe, validation_channel, तथा validation_annotation_channel S3 स्थानों का उपयोग करके जहाँ मैंने अपनी छवियों और टिप्पणियों को संग्रहीत किया है:
SageMaker अनुमानक में अपने स्वयं के डेटासेट के लिए हाइपरपैरामीटर समायोजित करें
मैंने नोटबुक का अनुसरण किया और एक सेजमेकर अनुमानक वस्तु बनाई (ss_estimator) मेरे विभाजन एल्गोरिथ्म को प्रशिक्षित करने के लिए। एक चीज़ जिसे हमें नए डेटासेट के लिए अनुकूलित करने की आवश्यकता है वह है ss_estimator.set_hyperparameters: हमें बदलने की जरूरत है num_classes=21 सेवा मेरे num_classes=2 (turtle और background), और मैं भी बदल गया epochs=10 सेवा मेरे epochs=30 क्योंकि 10 केवल डेमो उद्देश्यों के लिए है। तब मैंने सेटिंग द्वारा मॉडल प्रशिक्षण के लिए p3.2xlarge उदाहरण का उपयोग किया instance_type="ml.p3.2xlarge". प्रशिक्षण 8 मिनट में पूरा हुआ। सबसे अच्छा एमआईओयू (संघ पर औसत चौराहे) 0.846 के युग 11 में प्राप्त किया जाता है a pix_acc (आपकी छवि में पिक्सेल का प्रतिशत जो सही ढंग से वर्गीकृत किया गया है) 0.925 है, जो इस छोटे डेटासेट के लिए एक बहुत अच्छा परिणाम है।
मॉडल अनुमान परिणाम
मैंने मॉडल को कम लागत वाले ml.c5.xlarge उदाहरण पर होस्ट किया:
अंत में, मैंने प्रशिक्षित विभाजन मॉडल के निष्कर्ष परिणाम देखने के लिए 10 कछुआ छवियों का एक परीक्षण सेट तैयार किया:
निम्नलिखित छवियां परिणाम दिखाती हैं।

समुद्री कछुओं के विभाजन के मुखौटे सटीक दिखते हैं और मैं मैकेनिकल तुर्क श्रमिकों द्वारा लेबल किए गए 300-छवि डेटासेट पर प्रशिक्षित इस परिणाम से खुश हूं। आप अन्य उपलब्ध नेटवर्कों को भी एक्सप्लोर कर सकते हैं जैसे कि पिरामिड-सीन-पार्सिंग नेटवर्क (PSP) or डीपलैब-वी3 अपने डेटासेट के साथ नमूना नोटबुक में।
क्लीन अप
निरंतर लागतों से बचने के लिए जब आप समापन बिंदु को समाप्त कर लें तो उसे हटा दें:
निष्कर्ष
इस पोस्ट में, मैंने दिखाया कि सेजमेकर का उपयोग करके सिमेंटिक सेगमेंटेशन डेटा लेबलिंग और मॉडल प्रशिक्षण को कैसे अनुकूलित किया जाए। सबसे पहले, आप ऑटो-सेगमेंटेशन टूल के साथ एक लेबलिंग जॉब सेट कर सकते हैं या मैकेनिकल तुर्क वर्कफोर्स (साथ ही अन्य विकल्प) का उपयोग कर सकते हैं। यदि आपके पास 5,000 से अधिक ऑब्जेक्ट हैं, तो आप स्वचालित डेटा लेबलिंग का भी उपयोग कर सकते हैं। फिर आप अपने ग्राउंड ट्रुथ लेबलिंग जॉब से आउटपुट को सेजमेकर बिल्ट-इन सिमेंटिक सेगमेंटेशन ट्रेनिंग के लिए आवश्यक इनपुट फॉर्मेट में बदल देते हैं। उसके बाद, आप निम्नलिखित के साथ सिमेंटिक सेगमेंटेशन मॉडल को प्रशिक्षित करने के लिए एक त्वरित कंप्यूटिंग इंस्टेंस (जैसे पी 2 या पी 3) का उपयोग कर सकते हैं नोटबुक और मॉडल को अधिक लागत प्रभावी उदाहरण (जैसे ml.c5.xlarge) पर परिनियोजित करें। अंत में, आप कोड की कुछ पंक्तियों के साथ अपने परीक्षण डेटासेट पर अनुमान परिणामों की समीक्षा कर सकते हैं।
सेजमेकर सिमेंटिक सेगमेंटेशन के साथ शुरुआत करें डेटा लेबलिंग और मॉडल प्रशिक्षण अपने पसंदीदा डेटासेट के साथ!
लेखक के बारे में
 कारा यांगो एडब्ल्यूएस प्रोफेशनल सर्विसेज में डेटा साइंटिस्ट हैं। वह AWS क्लाउड सेवाओं के साथ ग्राहकों को उनके व्यावसायिक लक्ष्यों को प्राप्त करने में मदद करने के लिए उत्साहित हैं। उन्होंने विनिर्माण, ऑटोमोटिव, पर्यावरणीय स्थिरता और एयरोस्पेस जैसे कई उद्योगों में संगठनों को एमएल समाधान बनाने में मदद की है।
कारा यांगो एडब्ल्यूएस प्रोफेशनल सर्विसेज में डेटा साइंटिस्ट हैं। वह AWS क्लाउड सेवाओं के साथ ग्राहकों को उनके व्यावसायिक लक्ष्यों को प्राप्त करने में मदद करने के लिए उत्साहित हैं। उन्होंने विनिर्माण, ऑटोमोटिव, पर्यावरणीय स्थिरता और एयरोस्पेस जैसे कई उद्योगों में संगठनों को एमएल समाधान बनाने में मदद की है।
- कॉइनस्मार्ट। यूरोप का सर्वश्रेष्ठ बिटकॉइन और क्रिप्टो एक्सचेंज।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। नि: शुल्क प्रवेश।
- क्रिप्टोहॉक। Altcoin रडार। मुफ्त परीक्षण।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- About
- में तेजी लाने के
- त्वरित
- सही
- पाना
- हासिल
- के पार
- जोड़ा
- एयरोस्पेस
- कलन विधि
- एल्गोरिदम
- सब
- वीरांगना
- की घोषणा
- अन्य
- चारों ओर
- सहयोगी
- स्वचालित
- स्वतः
- मोटर वाहन
- उपलब्ध
- एडब्ल्यूएस
- पृष्ठभूमि
- क्योंकि
- BEST
- बेहतर
- के बीच
- निर्माण
- में निर्मित
- व्यापार
- कब्जा
- मामला
- कुछ
- परिवर्तन
- चैनलों
- चुनें
- कक्षा
- कक्षाएं
- वर्गीकृत
- बादल
- क्लाउड सेवाएं
- कोड
- सामान्य
- प्रतियोगिता
- पूरा
- कंप्यूटर
- कंप्यूटर्स
- कंप्यूटिंग
- आत्मविश्वास
- कंसोल
- सामग्री
- सुविधा
- इसी
- प्रभावी लागत
- लागत
- बनाना
- बनाया
- ग्राहक
- अनुकूलित
- तिथि
- आँकड़े वाला वैज्ञानिक
- गहरा
- दिखाना
- तैनात
- विभिन्न
- सीधे
- ड्राइंग
- दौरान
- से प्रत्येक
- सक्षम बनाता है
- शुरू से अंत तक
- endpoint
- दर्ज
- ambiental
- स्थापित
- उदाहरण
- सिवाय
- अपेक्षित
- उम्मीद
- का पता लगाने
- चरम
- चेहरा
- Feature
- प्रथम
- का पालन करें
- निम्नलिखित
- प्रारूप
- से
- उत्पन्न
- लक्ष्यों
- अच्छा
- ग्रे
- महान
- खुश
- मदद की
- मदद
- मदद करता है
- उच्च गुणवत्ता
- मेजबानी
- कैसे
- How To
- HTTPS
- मानव
- मनुष्य
- सैकड़ों
- की छवि
- छवियों
- लागू करने के
- में सुधार
- शामिल
- शामिल
- बढ़ना
- अनुक्रमणिका
- उद्योगों
- करें-
- निवेश
- उदाहरण
- इंटरफेस
- प्रतिच्छेदन
- शुरू करने
- IT
- काम
- नौकरियां
- जानने वाला
- लेबल
- लेबलिंग
- लेबल
- बड़ा
- लांच
- जानें
- सीख रहा हूँ
- स्तर
- सीमित
- लाइन
- पंक्तियां
- सूची
- स्थानीय
- स्थान
- स्थानों
- लंबा
- देखिए
- मशीन
- यंत्र अधिगम
- प्रबंधन
- अनिवार्य
- मैन्युअल
- विनिर्माण
- नक्शा
- मानचित्रण
- मुखौटा
- मास्क
- विशाल
- यांत्रिक
- हो सकता है
- ML
- आदर्श
- मॉडल
- अधिक
- विभिन्न
- नामों
- नामकरण
- पथ प्रदर्शन
- नेटवर्क
- नेटवर्क
- अगला
- नोटबुक
- संख्या
- ऑफर
- विकल्प
- ऑप्शंस
- संगठनों
- अन्य
- अपना
- आवेशपूर्ण
- प्रतिशत
- प्रदर्शन
- अंक
- बहुभुज
- लोकप्रिय
- तैयार करना
- सुंदर
- मूल्य
- निजी
- प्रक्रिया
- उत्पादन
- पेशेवर
- प्रदान करना
- प्रदान करता है
- सार्वजनिक
- प्रयोजनों
- जल्दी से
- RE
- अभिलेख
- प्रतिनिधित्व
- अपेक्षित
- की आवश्यकता होती है
- परिणाम
- की समीक्षा
- वही
- स्केलेबल
- वैज्ञानिक
- एसईए
- विभाजन
- चयनित
- सेवा
- सेवाएँ
- सेट
- की स्थापना
- Share
- दिखाना
- दिखाया
- सरल
- स्थिति
- छोटा
- So
- सॉफ्टवेयर
- समाधान ढूंढे
- विभाजित
- शुरू
- भंडारण
- स्थिरता
- लक्ष्य
- कार्य
- टीम
- परीक्षण
- RSI
- स्रोत
- बात
- तीसरे दल
- हजारों
- यहाँ
- THROUGHPUT
- पहर
- साधन
- रेलगाड़ी
- प्रशिक्षण
- बदालना
- संघ
- उपयोग
- सत्यापन
- विक्रेताओं
- दृष्टि
- कौन
- काम
- श्रमिकों
- कार्यबल
- कार्य
- आपका