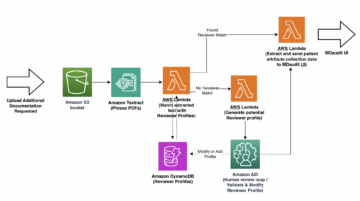
. OpenAI जुलाई 2020 में उनके मशीन लर्निंग (एमएल) मॉडल की तीसरी पीढ़ी को जारी किया, जो टेक्स्ट जनरेशन में माहिर थे, मुझे पता था कि कुछ अलग था। इस मॉडल ने एक तंत्रिका को मारा जैसे कि इससे पहले कोई नहीं आया था। अचानक मैंने मित्रों और सहकर्मियों को सुना, जो प्रौद्योगिकी में रुचि रखते हैं, लेकिन आमतौर पर एआई/एमएल क्षेत्र में नवीनतम प्रगति के बारे में ज्यादा परवाह नहीं करते हैं, इसके बारे में बात करें। गार्जियन ने भी लिखा एक लेख इसके बारे में। या, सटीक होने के लिए, आदर्श लेख लिखा और गार्जियन ने इसे संपादित और प्रकाशित किया। कोई इनकार नहीं कर रहा था - GPT-3 गेम चेंजर था।
मॉडल जारी होने के बाद, लोगों ने तुरंत इसके लिए संभावित अनुप्रयोगों के साथ आना शुरू कर दिया। कुछ ही हफ्तों में, कई प्रभावशाली डेमो बनाए गए, जो इस पर देखे जा सकते हैं जीपीटी-3 वेबसाइट. एक विशेष एप्लिकेशन जिसने मेरी आंख पकड़ी वह थी पाठ सारांश - किसी दिए गए पाठ को पढ़ने और उसकी सामग्री को सारांशित करने की कंप्यूटर की क्षमता। यह कंप्यूटर के लिए सबसे कठिन कार्यों में से एक है क्योंकि यह प्राकृतिक भाषा प्रसंस्करण (एनएलपी) के क्षेत्र में दो क्षेत्रों को जोड़ता है: समझ और पाठ पीढ़ी पढ़ना। यही कारण है कि मैं पाठ संक्षेपण के लिए GPT-3 डेमो से बहुत प्रभावित हुआ।
आप उन्हें इस पर एक कोशिश दे सकते हैं हगिंग फेस स्पेस वेबसाइट. इस समय मेरा पसंदीदा है an आवेदन जो इनपुट के रूप में केवल लेख के URL के साथ समाचार लेखों का सारांश तैयार करता है।
इस दो-भाग श्रृंखला में, मैं संगठनों के लिए एक व्यावहारिक मार्गदर्शिका का प्रस्ताव करता हूं ताकि आप अपने डोमेन के लिए पाठ सारांश मॉडल की गुणवत्ता का आकलन कर सकें।
ट्यूटोरियल अवलोकन
कई संगठन जिनके साथ मैं काम करता हूं (दान, कंपनियां, गैर सरकारी संगठन) के पास बड़ी मात्रा में पाठ हैं जिन्हें उन्हें पढ़ने और सारांशित करने की आवश्यकता है - वित्तीय रिपोर्ट या समाचार लेख, वैज्ञानिक शोध पत्र, पेटेंट आवेदन, कानूनी अनुबंध, और बहुत कुछ। स्वाभाविक रूप से, ये संगठन एनएलपी तकनीक के साथ इन कार्यों को स्वचालित करने में रुचि रखते हैं। संभव की कला का प्रदर्शन करने के लिए, मैं अक्सर पाठ सारांशीकरण डेमो का उपयोग करता हूं, जो लगभग कभी प्रभावित करने में विफल नहीं होता है।
लेकिन अब क्या?
इन संगठनों के लिए चुनौती यह है कि वे कई, कई दस्तावेजों के सारांश के आधार पर पाठ सारांश मॉडल का आकलन करना चाहते हैं - एक समय में एक नहीं। वे एक इंटर्न को किराए पर नहीं लेना चाहते हैं जिसका एकमात्र काम आवेदन खोलना, दस्तावेज़ में पेस्ट करना, हिट करना है संक्षेप में प्रस्तुत करना बटन, आउटपुट की प्रतीक्षा करें, आकलन करें कि सारांश अच्छा है या नहीं, और हजारों दस्तावेज़ों के लिए इसे फिर से करें।
मैंने इस ट्यूटोरियल को चार सप्ताह पहले अपने पिछले स्व को ध्यान में रखते हुए लिखा था - यह वह ट्यूटोरियल है जो काश मैं उस समय वापस आ जाता जब मैंने इस यात्रा को शुरू किया था। इस अर्थ में, इस ट्यूटोरियल का लक्षित दर्शक वह है जो एआई / एमएल से परिचित है और पहले ट्रांसफॉर्मर मॉडल का उपयोग कर चुका है, लेकिन अपनी टेक्स्ट सारांश यात्रा की शुरुआत में है और इसमें गहराई से गोता लगाना चाहता है। क्योंकि यह "शुरुआती" द्वारा लिखा गया है और शुरुआती लोगों के लिए, मैं इस तथ्य पर जोर देना चाहता हूं कि यह ट्यूटोरियल है a प्रैक्टिकल गाइड - नहीं la व्यावहारिक गाइड। कृपया इसे मानो जॉर्ज ईपी बॉक्स कहा था:
![]()
इस ट्यूटोरियल में कितने तकनीकी ज्ञान की आवश्यकता है: इसमें पायथन में कुछ कोडिंग शामिल है, लेकिन ज्यादातर समय हम केवल एपीआई को कॉल करने के लिए कोड का उपयोग करते हैं, इसलिए किसी भी गहन कोडिंग ज्ञान की आवश्यकता नहीं होती है। एमएल की कुछ अवधारणाओं से परिचित होना सहायक होता है, जैसे कि इसका क्या अर्थ है रेलगाड़ी और तैनात एक मॉडल, की अवधारणाएं ट्रेनिंग, सत्यापन, तथा परीक्षण डेटासेट, और इसी तरह। के साथ डब किया जा रहा है ट्रांसफॉर्मर लाइब्रेरी पहले उपयोगी हो सकता है, क्योंकि हम इस पूरे ट्यूटोरियल में इस पुस्तकालय का व्यापक रूप से उपयोग करते हैं। मैं इन अवधारणाओं को आगे पढ़ने के लिए उपयोगी लिंक भी शामिल करता हूं।
चूंकि यह ट्यूटोरियल एक नौसिखिया द्वारा लिखा गया है, इसलिए मुझे उम्मीद नहीं है कि एनएलपी विशेषज्ञ और उन्नत डीप लर्निंग प्रैक्टिशनर्स इस ट्यूटोरियल का ज्यादा हिस्सा लेंगे। कम से कम तकनीकी दृष्टिकोण से नहीं - हालाँकि, आप अभी भी पढ़ने का आनंद ले सकते हैं, इसलिए कृपया अभी न छोड़ें! लेकिन आपको मेरे सरलीकरण के संबंध में धैर्य रखना होगा - मैंने इस ट्यूटोरियल में सब कुछ यथासंभव सरल बनाने की अवधारणा से जीने की कोशिश की, लेकिन सरल नहीं।
इस ट्यूटोरियल की संरचना
यह श्रृंखला दो पदों में विभाजित चार खंडों में फैली हुई है, जिसमें हम एक पाठ सारांश परियोजना के विभिन्न चरणों से गुजरते हैं। पहली पोस्ट (खंड 1) में, हम पाठ सारांशीकरण कार्यों के लिए एक मीट्रिक पेश करके शुरू करते हैं - प्रदर्शन का एक माप जो हमें यह आकलन करने की अनुमति देता है कि सारांश अच्छा है या बुरा। हम उस डेटासेट का भी परिचय देते हैं जिसे हम सारांशित करना चाहते हैं और एक नो-एमएल मॉडल का उपयोग करके आधार रेखा बनाना चाहते हैं - हम किसी दिए गए पाठ से सारांश उत्पन्न करने के लिए एक साधारण अनुमानी का उपयोग करते हैं। इस आधार रेखा का निर्माण किसी भी एमएल परियोजना में एक महत्वपूर्ण कदम है क्योंकि यह हमें यह निर्धारित करने में सक्षम बनाता है कि आगे जाकर एआई का उपयोग करके हम कितनी प्रगति करते हैं। यह हमें इस प्रश्न का उत्तर देने की अनुमति देता है "क्या यह वास्तव में एआई तकनीक में निवेश करने लायक है?"
दूसरी पोस्ट में, हम एक मॉडल का उपयोग करते हैं जो पहले से ही सारांश (सेक्शन 2) उत्पन्न करने के लिए पूर्व-प्रशिक्षित है। यह एमएल में एक आधुनिक दृष्टिकोण के साथ संभव है जिसे कहा जाता है सीखने का स्थानांतरण. यह एक और उपयोगी कदम है क्योंकि हम मूल रूप से एक ऑफ-द-शेल्फ मॉडल लेते हैं और इसे अपने डेटासेट पर परीक्षण करते हैं। यह हमें एक और आधार रेखा बनाने की अनुमति देता है, जो हमें यह देखने में मदद करता है कि जब हम वास्तव में अपने डेटासेट पर मॉडल को प्रशिक्षित करते हैं तो क्या होता है। दृष्टिकोण कहा जाता है शून्य-शॉट संक्षेप, क्योंकि मॉडल का हमारे डेटासेट में शून्य एक्सपोजर रहा है।
उसके बाद, यह एक पूर्व-प्रशिक्षित मॉडल का उपयोग करने और इसे अपने स्वयं के डेटासेट (खंड 3) पर प्रशिक्षित करने का समय है। इसे भी कहा जाता है फ़ाइन ट्यूनिंग. यह मॉडल को हमारे डेटा के पैटर्न और विशिष्टताओं से सीखने और धीरे-धीरे इसके अनुकूल होने में सक्षम बनाता है। मॉडल को प्रशिक्षित करने के बाद, हम इसका उपयोग सारांश बनाने के लिए करते हैं (खंड 4)।
संक्षेप करने के लिए:
- भाग 1:
- धारा 1: आधार रेखा स्थापित करने के लिए नो-एमएल मॉडल का उपयोग करें
- भाग 2:
- धारा 2: शून्य-शॉट मॉडल के साथ सारांश उत्पन्न करें
- धारा 3: एक संक्षिप्तीकरण मॉडल को प्रशिक्षित करें
- धारा 4: प्रशिक्षित मॉडल का मूल्यांकन करें
इस ट्यूटोरियल का पूरा कोड निम्नलिखित में उपलब्ध है गीथहब रेपो.
इस ट्यूटोरियल के अंत तक हमने क्या हासिल किया होगा?
इस ट्यूटोरियल के अंत तक, हम नहीं होगा एक पाठ सारांश मॉडल है जिसका उपयोग उत्पादन में किया जा सकता है। हमारे पास एक भी नहीं होगा अच्छा सारांश मॉडल (यहां चीख इमोजी डालें)!
इसके बजाय हमारे पास परियोजना के अगले चरण के लिए एक प्रारंभिक बिंदु होगा, जो कि प्रयोग चरण है। यह वह जगह है जहां डेटा विज्ञान में "विज्ञान" आता है, क्योंकि अब यह विभिन्न मॉडलों और विभिन्न सेटिंग्स के साथ प्रयोग करने के बारे में है, यह समझने के लिए कि क्या उपलब्ध प्रशिक्षण डेटा के साथ एक अच्छा पर्याप्त सारांश मॉडल प्रशिक्षित किया जा सकता है।
और, पूरी तरह से पारदर्शी होने के लिए, एक अच्छा मौका है कि निष्कर्ष यह होगा कि तकनीक अभी पकी नहीं है और परियोजना को लागू नहीं किया जाएगा। और आपको उस संभावना के लिए अपने व्यापार हितधारकों को तैयार करना होगा। लेकिन यह एक और पोस्ट के लिए एक विषय है।
धारा 1: आधार रेखा स्थापित करने के लिए नो-एमएल मॉडल का उपयोग करें
टेक्स्ट सारांश प्रोजेक्ट सेट करने के बारे में यह हमारे ट्यूटोरियल का पहला भाग है। इस खंड में, हम वास्तव में एमएल का उपयोग किए बिना, एक बहुत ही सरल मॉडल का उपयोग करके एक आधार रेखा स्थापित करते हैं। यह किसी भी एमएल परियोजना में एक बहुत ही महत्वपूर्ण कदम है, क्योंकि यह हमें यह समझने की अनुमति देता है कि परियोजना के समय में एमएल कितना मूल्य जोड़ता है और यदि यह इसमें निवेश करने लायक है।
ट्यूटोरियल के लिए कोड निम्नलिखित में पाया जा सकता है गीथहब रेपो.
डेटा, डेटा, डेटा
हर एमएल प्रोजेक्ट डेटा से शुरू होता है! यदि संभव हो, तो हमें हमेशा उस डेटा से संबंधित डेटा का उपयोग करना चाहिए जिसे हम टेक्स्ट सारांश प्रोजेक्ट के साथ प्राप्त करना चाहते हैं। उदाहरण के लिए, यदि हमारा लक्ष्य पेटेंट आवेदनों को संक्षेप में प्रस्तुत करना है, तो हमें मॉडल को प्रशिक्षित करने के लिए पेटेंट आवेदनों का भी उपयोग करना चाहिए। एक एमएल परियोजना के लिए एक बड़ी चेतावनी यह है कि प्रशिक्षण डेटा को आमतौर पर लेबल करने की आवश्यकता होती है। पाठ संक्षेपण के संदर्भ में, इसका अर्थ है कि हमें पाठ को संक्षेप में प्रस्तुत करने के साथ-साथ सारांश (लेबल) प्रदान करने की आवश्यकता है। केवल दोनों प्रदान करके ही मॉडल सीख सकता है कि एक अच्छा सारांश कैसा दिखता है।
इस ट्यूटोरियल में, हम सार्वजनिक रूप से उपलब्ध डेटासेट का उपयोग करते हैं, लेकिन यदि हम कस्टम या निजी डेटासेट का उपयोग करते हैं तो चरण और कोड बिल्कुल समान रहते हैं। और फिर, यदि आपके मन में अपने पाठ सारांश मॉडल का कोई उद्देश्य है और आपके पास संबंधित डेटा है, तो कृपया इसका अधिकतम लाभ उठाने के लिए अपने डेटा का उपयोग करें।
हम जिस डेटा का उपयोग करते हैं वह है arXiv डेटासेट, जिसमें arXiv पेपर के सार के साथ-साथ उनके शीर्षक भी शामिल हैं। हमारे उद्देश्य के लिए, हम सार का उपयोग उस पाठ के रूप में करते हैं जिसे हम सारांशित करना चाहते हैं और शीर्षक को संदर्भ सारांश के रूप में उपयोग करते हैं। डेटा को डाउनलोड करने और प्रीप्रोसेस करने के सभी चरण निम्नलिखित में उपलब्ध हैं: नोटबुक. हमें एक की आवश्यकता है AWS पहचान और अभिगम प्रबंधन (IAM) भूमिका जो डेटा को लोड करने की अनुमति देती है अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) इस नोटबुक को सफलतापूर्वक चलाने के लिए। डेटासेट को कागज के हिस्से के रूप में विकसित किया गया था डेटासेट के रूप में ArXiv के उपयोग पर और के तहत लाइसेंस प्राप्त है क्रिएटिव कॉमन्स CC0 1.0 यूनिवर्सल पब्लिक डोमेन डेडिकेशन.
डेटा को तीन डेटासेट में विभाजित किया गया है: प्रशिक्षण, सत्यापन और परीक्षण डेटा। यदि आप अपने स्वयं के डेटा का उपयोग करना चाहते हैं, तो सुनिश्चित करें कि यह मामला भी है। निम्नलिखित आरेख दिखाता है कि हम विभिन्न डेटासेट का उपयोग कैसे करते हैं।
![]()
स्वाभाविक रूप से, इस बिंदु पर एक सामान्य प्रश्न है: हमें कितने डेटा की आवश्यकता है? जैसा कि आप शायद पहले से ही अनुमान लगा सकते हैं, उत्तर है: यह निर्भर करता है। यह इस बात पर निर्भर करता है कि डोमेन कितना विशिष्ट है (समाचार लेखों को सारांशित करने से पेटेंट आवेदनों का सारांश काफी अलग है), उपयोगी होने के लिए मॉडल को कितना सटीक होना चाहिए, मॉडल के प्रशिक्षण की लागत कितनी होनी चाहिए, और इसी तरह। हम इस प्रश्न पर बाद में वापस आते हैं जब हम वास्तव में मॉडल को प्रशिक्षित करते हैं, लेकिन इसका छोटा हिस्सा यह है कि जब हम परियोजना के प्रयोग चरण में होते हैं तो हमें विभिन्न डेटासेट आकारों को आज़माना पड़ता है।
एक अच्छा मॉडल क्या बनाता है?
कई एमएल परियोजनाओं में, मॉडल के प्रदर्शन को मापना काफी आसान है। ऐसा इसलिए है क्योंकि आमतौर पर इस बारे में बहुत कम अस्पष्टता होती है कि मॉडल का परिणाम सही है या नहीं। डेटासेट में लेबल अक्सर बाइनरी (सही/गलत, हां/नहीं) या श्रेणीबद्ध होते हैं। किसी भी मामले में, इस परिदृश्य में मॉडल के आउटपुट की तुलना लेबल से करना और इसे सही या गलत के रूप में चिह्नित करना आसान है।
पाठ उत्पन्न करते समय, यह अधिक चुनौतीपूर्ण हो जाता है। सारांश (लेबल) जो हम अपने डेटासेट में प्रदान करते हैं, वह पाठ को सारांशित करने का केवल एक ही तरीका है। लेकिन किसी दिए गए पाठ को संक्षेप में प्रस्तुत करने की कई संभावनाएं हैं। इसलिए, भले ही मॉडल हमारे लेबल 1:1 से मेल नहीं खाता हो, फिर भी आउटपुट एक मान्य और उपयोगी सारांश हो सकता है। तो हम अपने द्वारा प्रदान किए गए मॉडल के सारांश की तुलना कैसे करते हैं? एक मॉडल की गुणवत्ता को मापने के लिए पाठ सारांशीकरण में सबसे अधिक बार उपयोग किया जाने वाला मीट्रिक है रूज स्कोर. इस मीट्रिक के यांत्रिकी को समझने के लिए देखें एनएलपी में अंतिम प्रदर्शन मीट्रिक. संक्षेप में, ROUGE स्कोर के ओवरलैप को मापता है एन-ग्रामgram (सन्निहित अनुक्रम n आइटम) मॉडल के सारांश (उम्मीदवार सारांश) और संदर्भ सारांश (वह लेबल जो हम अपने डेटासेट में प्रदान करते हैं) के बीच। लेकिन, ज़ाहिर है, यह एक सही उपाय नहीं है। इसकी सीमाओं को समझने के लिए देखें रूज को या नहीं रूज को?
तो, हम ROUGE स्कोर की गणना कैसे करते हैं? इस मीट्रिक की गणना करने के लिए वहां कुछ पायथन पैकेज हैं। निरंतरता सुनिश्चित करने के लिए, हमें अपने पूरे प्रोजेक्ट में एक ही विधि का उपयोग करना चाहिए। क्योंकि हम इस ट्यूटोरियल में बाद के बिंदु पर, ट्रांसफॉर्मर्स लाइब्रेरी से एक प्रशिक्षण स्क्रिप्ट का उपयोग करेंगे, न कि अपना खुद का लिखने के, हम केवल इसमें देख सकते हैं स्रोत कोड स्क्रिप्ट का और उस कोड को कॉपी करें जो ROUGE स्कोर की गणना करता है:
स्कोर की गणना करने के लिए इस पद्धति का उपयोग करके, हम यह सुनिश्चित करते हैं कि हम हमेशा पूरे प्रोजेक्ट में सेब की तुलना सेब से करें।
यह फ़ंक्शन कई ROUGE स्कोर की गणना करता है: rouge1, rouge2, rougeL, तथा rougeLsum. में "योग" rougeLsum इस तथ्य को संदर्भित करता है कि इस मीट्रिक की गणना संपूर्ण सारांश पर की जाती है, जबकि rougeL व्यक्तिगत वाक्यों पर औसत के रूप में गणना की जाती है। तो, हमें अपने प्रोजेक्ट के लिए किस ROUGE स्कोर का उपयोग करना चाहिए? फिर से, हमें प्रयोग के चरण में विभिन्न दृष्टिकोणों को आजमाना होगा। इसके लायक क्या है, मूल रूज पेपर बताता है कि "ROUGE-2 और ROUGE-L ने एकल दस्तावेज़ सारांश कार्यों में अच्छा काम किया" जबकि "ROUGE-1 और ROUGE-L संक्षिप्त सारांशों का मूल्यांकन करने में अच्छा प्रदर्शन करते हैं।"
आधार रेखा बनाएं
आगे हम एक सरल, नो-एमएल मॉडल का उपयोग करके आधार रेखा बनाना चाहते हैं। इसका क्या मतलब है? पाठ संक्षेपण के क्षेत्र में, कई अध्ययन एक बहुत ही सरल दृष्टिकोण का उपयोग करते हैं: वे पहला लेते हैं n पाठ के वाक्य और इसे उम्मीदवार सारांश घोषित करें। फिर वे संदर्भ सारांश के साथ उम्मीदवार के सारांश की तुलना करते हैं और ROUGE स्कोर की गणना करते हैं। यह एक सरल लेकिन शक्तिशाली तरीका है जिसे हम कोड की कुछ पंक्तियों में लागू कर सकते हैं (इस भाग के लिए संपूर्ण कोड निम्नलिखित में है नोटबुक):
हम इस मूल्यांकन के लिए परीक्षण डेटासेट का उपयोग करते हैं। यह समझ में आता है क्योंकि मॉडल को प्रशिक्षित करने के बाद, हम अंतिम मूल्यांकन के लिए उसी परीक्षण डेटासेट का भी उपयोग करते हैं। हम इसके लिए अलग-अलग नंबर भी आजमाते हैं n: हम उम्मीदवार सारांश के रूप में केवल पहले वाक्य से शुरू करते हैं, फिर पहले दो वाक्य, और अंत में पहले तीन वाक्य।
निम्न स्क्रीनशॉट हमारे पहले मॉडल के परिणाम दिखाता है।
![]()
उम्मीदवार सारांश के रूप में केवल पहला वाक्य के साथ, ROUGE स्कोर उच्चतम हैं। इसका अर्थ यह है कि एक से अधिक वाक्य लेने से सारांश बहुत अधिक क्रियात्मक हो जाता है और कम अंक प्राप्त होता है। तो इसका मतलब है कि हम अपनी आधार रेखा के रूप में एक-वाक्य सारांश के लिए स्कोर का उपयोग करेंगे।
यह ध्यान रखना महत्वपूर्ण है कि, इस तरह के एक सरल दृष्टिकोण के लिए, ये संख्याएं वास्तव में काफी अच्छी हैं, खासकर के लिए rouge1 स्कोर। इन नंबरों को संदर्भ में रखने के लिए, हम इसका उल्लेख कर सकते हैं पेगासस मॉडल, जो विभिन्न डेटासेट के लिए एक अत्याधुनिक मॉडल के स्कोर को दर्शाता है।
निष्कर्ष और आगे क्या है
हमारी श्रृंखला के भाग 1 में, हमने उस डेटासेट को पेश किया जिसका उपयोग हम सारांश परियोजना के साथ-साथ सारांशों का मूल्यांकन करने के लिए एक मीट्रिक के रूप में करते हैं। फिर हमने एक सरल, नो-एमएल मॉडल के साथ निम्नलिखित आधार रेखा बनाई।
![]()
में अगली पोस्ट, हम एक शून्य-शॉट मॉडल का उपयोग करते हैं - विशेष रूप से, एक ऐसा मॉडल जिसे विशेष रूप से सार्वजनिक समाचार लेखों पर पाठ सारांश के लिए प्रशिक्षित किया गया है। हालांकि, इस मॉडल को हमारे डेटासेट पर बिल्कुल भी प्रशिक्षित नहीं किया जाएगा (इसलिए नाम "शून्य-शॉट")।
यह अनुमान लगाने के लिए कि यह शून्य-शॉट मॉडल हमारी बहुत ही सरल आधार रेखा की तुलना में कैसा प्रदर्शन करेगा, मैं इसे आपके होमवर्क के रूप में छोड़ देता हूं। एक ओर, यह बहुत अधिक परिष्कृत मॉडल होगा (यह वास्तव में एक तंत्रिका नेटवर्क है)। दूसरी ओर, इसका उपयोग केवल समाचार लेखों को सारांशित करने के लिए किया जाता है, इसलिए यह उन प्रतिमानों के साथ संघर्ष कर सकता है जो arXiv डेटासेट में निहित हैं।
लेखक के बारे में
![]() हाइको हॉट्ज़ो एआई और मशीन लर्निंग के लिए एक वरिष्ठ समाधान वास्तुकार है और एडब्ल्यूएस के भीतर प्राकृतिक भाषा प्रसंस्करण (एनएलपी) समुदाय का नेतृत्व करता है। इस भूमिका से पहले, वह Amazon की EU ग्राहक सेवा के लिए डेटा साइंस के प्रमुख थे। Heiko हमारे ग्राहकों को AWS पर उनकी AI/ML यात्रा में सफल होने में मदद करता है और बीमा, वित्तीय सेवाओं, मीडिया और मनोरंजन, हेल्थकेयर, उपयोगिताओं और विनिर्माण सहित कई उद्योगों में संगठनों के साथ काम किया है। अपने खाली समय में Heiko जितना संभव हो उतना यात्रा करता है।
हाइको हॉट्ज़ो एआई और मशीन लर्निंग के लिए एक वरिष्ठ समाधान वास्तुकार है और एडब्ल्यूएस के भीतर प्राकृतिक भाषा प्रसंस्करण (एनएलपी) समुदाय का नेतृत्व करता है। इस भूमिका से पहले, वह Amazon की EU ग्राहक सेवा के लिए डेटा साइंस के प्रमुख थे। Heiko हमारे ग्राहकों को AWS पर उनकी AI/ML यात्रा में सफल होने में मदद करता है और बीमा, वित्तीय सेवाओं, मीडिया और मनोरंजन, हेल्थकेयर, उपयोगिताओं और विनिर्माण सहित कई उद्योगों में संगठनों के साथ काम किया है। अपने खाली समय में Heiko जितना संभव हो उतना यात्रा करता है।
- कॉइनस्मार्ट। यूरोप का सर्वश्रेष्ठ बिटकॉइन और क्रिप्टो एक्सचेंज।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। नि: शुल्क प्रवेश।
- क्रिप्टोहॉक। Altcoin रडार। मुफ्त परीक्षण।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/part-1-set-up-a-text-summarization-project-with-hugging-face-transformers/
- '
- "
- &
- 100
- 2020
- About
- अमूर्त
- पहुँच
- सही
- हासिल
- उन्नत
- प्रगति
- AI
- सब
- पहले ही
- वीरांगना
- अस्पष्टता
- राशियाँ
- अन्य
- एपीआई
- आवेदन
- अनुप्रयोगों
- दृष्टिकोण
- चारों ओर
- कला
- लेख
- लेख
- दर्शक
- उपलब्ध
- औसत
- एडब्ल्यूएस
- आधारभूत
- मूल रूप से
- शुरू
- जा रहा है
- व्यापार
- कॉल
- कौन
- पकड़ा
- चुनौती
- कोड
- कोडन
- सामान्य
- समुदाय
- कंपनियों
- तुलना
- पूरी तरह से
- गणना करना
- संकल्पना
- शामिल हैं
- सामग्री
- ठेके
- बनाना
- रिवाज
- ग्राहक सेवा
- ग्राहक
- तिथि
- डेटा विज्ञान
- और गहरा
- विकसित
- विभिन्न
- दस्तावेजों
- नहीं करता है
- डोमेन
- मनोरंजन
- विशेष रूप से
- स्थापित करना
- EU
- सब कुछ
- उदाहरण
- उम्मीद
- विशेषज्ञों
- आंख
- चेहरा
- फ़ील्ड
- अंत में
- वित्तीय
- वित्तीय सेवाओं
- प्रथम
- निम्नलिखित
- आगे
- पाया
- समारोह
- आगे
- खेल
- उत्पन्न
- पीढ़ी
- लक्ष्य
- जा
- अच्छा
- महान
- अभिभावक
- गाइड
- होने
- सिर
- स्वास्थ्य सेवा
- सहायक
- मदद करता है
- यहाँ उत्पन्न करें
- किराया
- कैसे
- HTTPS
- विशाल
- पहचान
- लागू करने के
- कार्यान्वित
- महत्वपूर्ण
- शामिल
- सहित
- व्यक्ति
- उद्योगों
- बीमा
- शुरू करने
- निवेश करना
- IT
- काम
- जुलाई
- कुंजी
- ज्ञान
- लेबल
- भाषा
- ताज़ा
- बिक्रीसूत्र
- जानें
- सीख रहा हूँ
- छोड़ना
- कानूनी
- पुस्तकालय
- लाइसेंस - प्राप्त
- लिंक
- थोड़ा
- मशीन
- यंत्र अधिगम
- बनाता है
- निर्माण
- विनिर्माण
- निशान
- मैच
- माप
- मीडिया
- मन
- ML
- आदर्श
- मॉडल
- अधिक
- अधिकांश
- प्राकृतिक
- नेटवर्क
- समाचार
- नोटबुक
- संख्या
- खुला
- आदेश
- संगठनों
- अन्य
- काग़ज़
- पेटेंट
- पीडीएफ
- स्टाफ़
- प्रदर्शन
- परिप्रेक्ष्य
- चरण
- बिन्दु
- संभावनाओं
- संभावना
- संभव
- पोस्ट
- संभावित
- शक्तिशाली
- निजी
- उत्पादन
- परियोजना
- परियोजनाओं
- प्रस्ताव
- प्रदान करना
- प्रदान कर
- सार्वजनिक
- उद्देश्य
- गुणवत्ता
- प्रश्न
- रेंज
- RE
- पढ़ना
- रिपोर्ट
- की आवश्यकता होती है
- अपेक्षित
- अनुसंधान
- परिणाम
- रन
- कहा
- विज्ञान
- भावना
- कई
- सेवा
- सेवाएँ
- सेट
- की स्थापना
- कम
- सरल
- So
- समाधान ढूंढे
- कोई
- कुछ
- परिष्कृत
- अंतरिक्ष
- रिक्त स्थान
- विशेषीकृत
- माहिर
- विशेष रूप से
- विभाजित
- प्रारंभ
- शुरू
- शुरू होता है
- राज्य के-the-कला
- राज्य
- भंडारण
- तनाव
- पढ़ाई
- सफल
- सफलतापूर्वक
- बातचीत
- लक्ष्य
- कार्य
- तकनीकी
- टेक्नोलॉजी
- परीक्षण
- हजारों
- यहाँ
- भर
- पहर
- शीर्षक
- प्रशिक्षण
- पारदर्शी
- उपचार
- परम
- समझना
- सार्वभौम
- us
- उपयोग
- आमतौर पर
- मूल्य
- प्रतीक्षा
- क्या
- या
- कौन
- विकिपीडिया
- अंदर
- बिना
- काम
- काम किया
- लायक
- लिख रहे हैं
- X
- शून्य