परिचय
संगीत उद्योग अधिक लोकप्रिय हो गया है, और लोग संगीत कैसे सुनते हैं यह जंगल की आग की तरह बदल रहा है। संगीत स्ट्रीमिंग सेवाओं के विकास ने स्वत: संगीत वर्गीकरण और अनुशंसा प्रणाली की मांग में वृद्धि की है। Spotify, दुनिया की अग्रणी संगीत स्ट्रीमिंग साइटों में से एक है, जिसके लाखों ग्राहक हैं और एक विशाल गीत सूची है। फिर भी, ग्राहकों को एक व्यक्तिगत संगीत अनुभव प्राप्त करने के लिए, Spotify को उन ट्रैकों की अनुशंसा करनी चाहिए जो उनकी प्राथमिकताओं के अनुकूल हों। Spotify मशीन लर्निंग एल्गोरिदम का उपयोग शैली के आधार पर संगीत को निर्देशित और वर्गीकृत करने के लिए करता है।

स्रोत: www.analyticsvidhya.com
यह प्रोजेक्ट Spotify Multiclass Genre Classification समस्या पर ध्यान केंद्रित करेगा, जहाँ हम कागल से डेटासेट डाउनलोड करते हैं।
लक्ष्य - इस प्रोजेक्ट का उद्देश्य एक ऐसा मॉडल विकसित करना है जो उस शैली को वर्गीकृत करता है जो Spotify पर संगीत ट्रैक की शैली की सटीक भविष्यवाणी कर सके।
सीखने के मकसद
- Spotify और उनकी ध्वनिक विशेषताओं पर संगीत शैलियों के बीच लिंक की जांच करने के लिए।
- किसी दिए गए गीत की शैली की भविष्यवाणी करने के लिए श्रवण विशेषताओं के आधार पर एक वर्गीकरण मॉडल बनाना।
- डेटासेट में विभिन्न Spotify संगीत शैलियों के वितरण की जांच करने के लिए।
- मॉडलिंग के लिए इसे तैयार करने के लिए डेटा को साफ और प्रीप्रोसेस करना।
- वर्गीकरण मॉडल के प्रदर्शन का आकलन करने और इसकी सटीकता में सुधार करने के लिए।
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन.
विषय - सूची
.. पूर्वापेक्षाएँ
कार्यान्वयन शुरू करने से पहले, हमें कुछ पुस्तकालयों को स्थापित और आयात करना होगा। नीचे सूचीबद्ध पुस्तकालयों की आवश्यकता है:
पांडा: डेटा हेरफेर और विश्लेषण के लिए एक पुस्तकालय।
Numpy: मैट्रिक्स संगणनाओं के लिए उपयोग किया जाने वाला एक वैज्ञानिक कंप्यूटिंग पैकेज।
matplotlib: पायथन प्रोग्रामिंग भाषा के लिए एक प्लॉटिंग लाइब्रेरी।
Sजन्म: matplotlib पर आधारित डेटा विज़ुअलाइज़ेशन लाइब्रेरी।
स्केलेर्न: वर्गीकरण के लिए मॉडल बनाने के लिए एक मशीन लर्निंग लाइब्रेरी
TensorFlow: गहन शिक्षण मॉडल के निर्माण और प्रशिक्षण के लिए एक लोकप्रिय ओपन-सोर्स लाइब्रेरी।
इन्हें स्थापित करने के लिए, हम यह कमांड चलाते हैं।
!pip install pandas !pip install numpy
!pip install matplotlib
!pip install seaborn
!pip install sklearn
!pip install tensorflowप्रोजेक्ट पाइपलाइन
डेटा प्रीप्रोसेसिंग: मशीन लर्निंग के लिए तैयार करने के लिए "genres_v2" डेटासेट को साफ और प्रीप्रोसेस करें।
फ़ीचर इंजीनियरिंग: ऑडियो फाइलों से सार्थक विशेषताएँ निकालें जो हमारे मॉडल को प्रशिक्षित करने में हमारी मदद करेंगी।
मॉडल चयन: सबसे अच्छा प्रदर्शन करने वाले मॉडल को खोजने के लिए कई मशीन लर्निंग एल्गोरिदम का मूल्यांकन करें।
मॉडल प्रशिक्षण: चयनित मॉडल को प्रीप्रोसेस्ड डेटासेट पर प्रशिक्षित करें और उसके प्रदर्शन का मूल्यांकन करें।
मॉडल परिनियोजन: प्रशिक्षित मॉडल को एक ऑनलाइन एप्लिकेशन में तैनात करें जो उपयोगकर्ता की प्राथमिकताओं के आधार पर Spotify पर संगीत ट्रैक की सिफारिश कर सकता है
तो चलिए कुछ कोड करना शुरू करते हैं।
परियोजना
सबसे पहले, हमें डेटा सेट डाउनलोड करना होगा। आप डेटासेट को कागल से डाउनलोड कर सकते हैं। हमें अपने कार्यों को करने के लिए आवश्यक पुस्तकालयों को आयात करने की आवश्यकता है।
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn import preprocessing
from sklearn import metrics
import numpy as np
import tensorflow as tf
from tensorflow import keras
from sklearn.decomposition import PCA, KernelPCA, TruncatedSVD
from sklearn.manifold import Isomap, TSNE, MDS
import random
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
import warnings warnings.simplefilter("ignore")डेटासेट लोड करें
हम पांडा read_csv का उपयोग करके डेटासेट लोड करते हैं, और डेटा सेट में 42305 पंक्तियाँ और 22 कॉलम होते हैं और इसमें 18000+ ट्रैक होते हैं।
data = pd.read_csv("Desktop/genres_v2.csv")
data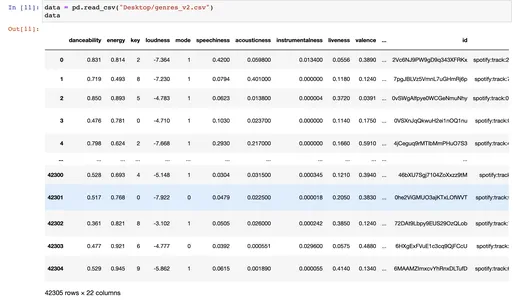
डेटा की खोज
मैं उन पंक्तियों और स्तंभों का चयन करने के लिए 'iloc' पद्धति का उपयोग करता हूं जो उनके पूर्णांक अनुक्रमणिका पदों द्वारा डेटा फ़्रेम बनाते हैं। मैं df के पहले 20 कॉलम चुन रहा हूं।
data.iloc[:,:20] # this is for the first 20 columns data.iloc[:,20:] # this is for the 21st column data.info()जब आप data.info() को कॉल करते हैं, तो यह निम्न जानकारी प्रिंट करेगा:
- डेटा फ्रेम में पंक्तियों और स्तंभों की संख्या।
- प्रत्येक कॉलम का नाम, उसका डेटा प्रकार और उस कॉलम में गैर-शून्य मानों की संख्या।
- डेटा फ्रेम में गैर-शून्य मानों की कुल संख्या।
- DataFrame का मेमोरी उपयोग।
data.nunique() # number of unique values in our data set.डेटा की सफाई
यहां, हम उन अनावश्यक स्तंभों को हटाकर अपने डेटा को साफ़ करना चाहते हैं जो भविष्यवाणी में कोई मूल्य नहीं जोड़ते हैं।
df = data.drop(["type","type","id","uri","track_href","analysis_url","song_name", "Unnamed: 0","title", "duration_ms", "time_signature"], axis =1)
df
हमने कुछ कॉलम हटा दिए हैं जो इस विशेष समस्या के लिए कोई मूल्य नहीं जोड़ते हैं और अक्ष = 1 डालते हैं, जहां यह पंक्तियों के बजाय कॉलम को छोड़ देता है। उपयोगी जानकारी के साथ नए डेटा फ़्रेम को देखने के लिए हम फिर से डेटा फ़्रेम को कॉल कर रहे हैं।
डीएफ। वर्णन () विधि एक पांडा डेटा फ़्रेम के वर्णनात्मक आँकड़े उत्पन्न करती है। यह केंद्रीय प्रवृत्ति और फैलाव और डेटासेट के वितरण के आकार का सारांश प्रदान करता है।
इस आदेश को चलाने के बाद, आप डेटा फ़्रेम के सभी वर्णनात्मक आँकड़े देख सकते हैं, जैसे कि एसटीडी, माध्य, माध्यिका, प्रतिशतक, न्यूनतम और अधिकतम।
df.describe()पंडों के डेटाफ़्रेम या श्रृंखला का सारांश प्रदर्शित करने के लिए, df.info () फ़ंक्शन का उपयोग करें। यह डेटासेट की जानकारी देता है जैसे पंक्तियों और स्तंभों की संख्या, प्रत्येक कॉलम के डेटा प्रकार, प्रत्येक कॉलम में गैर-शून्य मानों की संख्या और डेटासेट की मेमोरी का उपयोग।
df.info()
df["genre"].value_counts()
ax = sns.histplot(df["genre"]) डीएफ के "शैली" कॉलम नामक पांडा डेटाफ्रेम में मूल्यों के वितरण का हिस्टोग्राम उत्पन्न करता है। संगीत डेटासेट में कुछ Spotify शैलियों की आवृत्ति को देखने के लिए इस कोड का उपयोग किया जा सकता है।
ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=90)
_ = plt.title("Genres")निम्न कोड पांडा डेटाफ़्रेम में सभी पंक्तियों को हटा देता है या हटा देता है जहाँ "शैली" कॉलम में मान "पॉप" के बराबर होता है। DataFrame का सूचकांक तब उस सीमा पर रीसेट हो जाता है जहां यह 0 से शुरू होता है। अंत में, यह DataFrame के शेष स्तंभों के सहसंबंध मैट्रिक्स की गणना करता है।
यह कोड अनावश्यक पंक्तियों को हटाकर और शेष चर के बीच सहसंबंधों को ढूंढकर डेटासेट का अध्ययन करने में सहायता करता है।
df.drop(df.loc[df['genre']=="Pop"].index, inplace=True)
df = df.reset_index(drop = True)
df = df.corr()निम्नलिखित कोड एस.एन.एस. हीटमैप (df, cmap = 'कूलवार्म, एनोट = ट्रू) plt. शो () पंडों के डेटाफ़्रेम डीएफ के सहसंबंध मैट्रिक्स को दर्शाते हुए एक हीटमैप उत्पन्न करता है।
यह कोड डेटासेट में वेरिएबल्स के बीच सहसंबंधों की ताकत और दिशा को खोजने और प्रदर्शित करने में मदद करता है। हीटमैप कलर कोडिंग से यह देखना आसान हो जाता है कि कौन से वेरिएबल्स के जोड़े अत्यधिक सहसंबद्ध हैं और कौन से नहीं।
sns.heatmap(df, cmap='coolwarm', annot=True ) plt.show()12pythonनिम्न कोड x नाम के पांडा डेटाफ़्रेम df में स्तंभों का एक सबसेट चुनता है, जिसमें "टेम्पो" कॉलम सहित डेटाफ़्रेम की शुरुआत से सभी कॉलम शामिल हैं। फिर यह DataFrame की "शैली" को लक्ष्य चर के रूप में चुनता है और इसे y को असाइन करता है।
X चर मूल स्तंभों के एक सबसेट के साथ एक पांडा डेटाफ़्रेम का प्रतिनिधित्व करता है, और y चर "शैली" स्तंभ मानों के साथ एक पांडा श्रृंखला का प्रतिनिधित्व करता है।
विधियाँ x.unique() और y.unique() क्रमशः x और y चरों में अद्वितीय मानों को पुनः प्राप्त करती हैं। ये रूटीन किसी डेटासेट के वेरिएबल्स में अद्वितीय मानों की संख्या निर्धारित करने में मददगार हो सकते हैं।
x = df.loc[:,:"tempo"]
y = df["genre"]
x y
x.unique()
y.unique()मैं सभी चित्र नहीं दे रहा हूँ। आप नीचे नोटबुक देख सकते हैं।
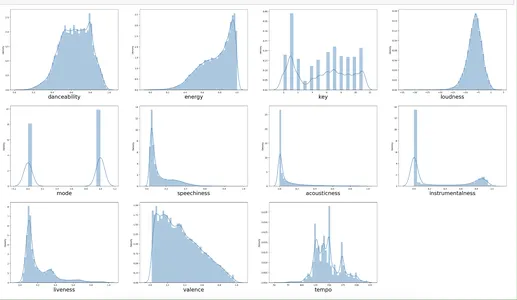
दिया गया कोड वितरण भूखंडों का एक ग्रिड उत्पन्न करता है जो उपयोगकर्ताओं को डेटासेट में कई स्तंभों पर मूल्यों के वितरण को देखने की अनुमति देता है। प्रत्येक कॉलम में मानों का वितरण दिखा कर डेटा में पैटर्न, रुझान और आउटलेयर की खोज करना। ये खोजपूर्ण डेटा विश्लेषण और डेटासेट में मूल्यवान और संभावित दोषों या अशुद्धियों को खोजने के लिए सहायक और लाभकारी हैं।
k=0
plt.figure(figsize = (40,30))
for i in x.columns: plt.subplot(4,4, k + 1) sns.distplot(x[i]) plt.xlabel(i, fontsize=24) k +=1यहां, हम फॉर लूप का उपयोग करके प्रत्येक x_columns के लिए प्लॉटिंग कर रहे हैं।
मॉडल प्रशिक्षण
निम्न कोड एक डेटासेट को प्रशिक्षण और परीक्षण सबसेट में विभाजित करता है। यह इनपुट चर और लक्ष्य चर को 80% प्रशिक्षण और 20% परीक्षण समूहों में यादृच्छिक रूप से विभाजित करता है। प्रशिक्षण डेटा के वर्णनात्मक आँकड़े तब डेटा अन्वेषण और संभावित समस्याओं की पहचान में सहायता के लिए आउटपुट किए जाते हैं।
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size= 0.2, random_state=42, shuffle = True)
xtrain.columns
xtrain.describe()यहां हम डेटा को प्रशिक्षण और परीक्षण (आकार = 20%) में विभाजित कर रहे हैं, और हम वर्णनात्मक आंकड़ों को देखने के लिए वर्णन फ़ंक्शन का उपयोग कर रहे हैं।
sklearn.preprocessing मॉड्यूल से MinMaxScaler() फ़ंक्शन का उपयोग फीचर स्केलिंग करने के लिए किया जाता है। यह प्रशिक्षण डेटा के कॉलम नामों को वेरिएबल ol में संग्रहीत करता है। स्केलर ऑब्जेक्ट का उपयोग xtest डेटा को बदलते समय xtrain डेटा को फिट और परिवर्तित करने के लिए किया जाता है।
अंत में, वैकल्पिक xtrain और xtest डेटा को मूल स्तंभ नाम (col) के साथ पांडा DataFrames में परिवर्तित कर दिया जाता है। मशीन लर्निंग मॉडल के लिए डेटा के प्रीप्रोसेसिंग और मानकीकरण में यह एक महत्वपूर्ण कदम है।
ol = xtrain.columns scalerx = MinMaxScaler() xtrain = scalerx.fit_transform(xtrain)
xtest = scalerx.transform(xtest) xtrain = pd.DataFrame(xtrain, columns = col)
xtest = pd.DataFrame(xtest, columns = col)यहां हम मुख्य रूप से डेटा को स्केल करने और सामान्य करने के लिए MinMaxScaler का उपयोग करते हैं।
निम्नलिखित हमें xtrain और xtest के वर्णनात्मक आँकड़े देखने की अनुमति देता है।
xtrain.describe() xtest.describe()sklearn.preprocessing पैकेज से LabelEncoder() फ़ंक्शन का उपयोग लेबल को एनकोड करने के लिए किया जाता है। यह श्रेणी लक्ष्य चर (ytrain और ytest) को संख्यात्मक मानों में एन्कोड करने के लिए फ़िट ट्रांसफ़ॉर्म () और ट्रांसफ़ॉर्म () रूटीन का उपयोग करता है।
इनपुट (एक्स) और लक्ष्य (वाई) चर के लिए प्रशिक्षण और परीक्षण डेटा तब समेकित होते हैं। संख्यात्मक लेबल तब उनके मूल श्रेणी मानों (y ट्रेन, y परीक्षण, और y org) में व्युत्क्रमानुपाती हो जाते हैं।
अगला, हम np.unique () पद्धति का उपयोग करते हैं, जो प्रशिक्षण डेटा में अलग-अलग श्रेणियों को लौटाता है।
अंत में, सीबॉर्न लाइब्रेरी का उपयोग इनपुट विशेषताओं के बीच संबंध को दर्शाने के लिए एक हीटमैप ग्राफिक उत्पन्न करता है। यह एक महत्वपूर्ण चरण है जब हम मशीन-लर्निंग मॉडल के लिए डेटा की जांच और तैयारी करते हैं।
le = preprocessing.LabelEncoder()
ytrain = le.fit_transform(ytrain)
ytest = le.transform(ytest) x = pd.concat([xtrain, xtest], axis = 0)
y = pd.concat([pd.DataFrame(ytrain), pd.DataFrame(ytest)], axis = 0) y_train = le.inverse_transform(ytrain)
y_test = le.inverse_transform(ytest)
y_org = pd.concat([pd.DataFrame(y_train), pd.DataFrame(y_test)], axis = 0) np.unique(y_train) csvax = sns.heatmap(xtrain.corr()).set(title = "Correlation between Features")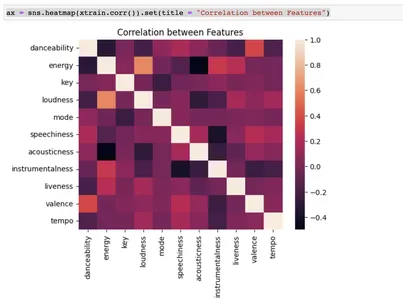
पीसीए एक लोकप्रिय डायमेंशनलिटी रिडक्शन एप्रोच है जो बड़े डेटासेट की जटिलता को कम करने और मशीन लर्निंग मॉडल के प्रदर्शन को बढ़ाने में मदद कर सकता है।
इनपुट डेटा एक्स के साथ, एल्गोरिथ्म पीसीए का उपयोग सुविधाओं की संख्या को दो भागों में कम करने के लिए करता है जो भिन्नता की व्याख्या करते हैं। घटे हुए डेटासेट को 2D स्कैटर प्लॉट पर दिखाया गया है, जिसमें y में क्लास लेबल द्वारा रंगीन डॉट्स हैं। यह कम सुविधा वाले स्थान में कुछ वर्गों के विभाजन की कल्पना करने में सहायता करता है।
pca = PCA(n_components=2)
x_pca = pca.fit_transform(x, y)
plot_pca = plt.scatter(x_pca[:,0], x_pca[:,1], c=y)
handles, labels = plot_pca.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
_ = plt.title("PCA")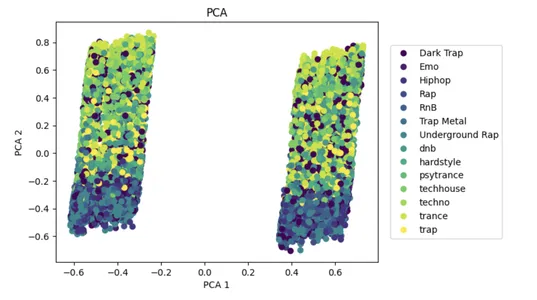
t-SNE एक लोकप्रिय नॉनलाइनियर डायमेंशनलिटी रिडक्शन एप्रोच है जो बड़े डेटासेट की जटिलता को कम करने और मशीन लर्निंग मॉडल के प्रदर्शन में सुधार करने में मदद कर सकता है।
इनपुट डेटा x पर टी-डिस्ट्रीब्यूटेड स्टोचैस्टिक नेबर एंबेडिंग (t-SNE) का उपयोग डेटा बिंदुओं के बीच समानता बनाए रखते हुए उच्च-आयामी स्थान में सुविधाओं की संख्या को 2D तक कम कर देता है।
एक 2D स्कैटर प्लॉट कम किए गए डेटासेट को दिखाता है, जिसमें डॉट्स उनके y-क्लास लेबल के अनुसार रंगीन होते हैं। यह कम सुविधा वाले स्थान में कुछ वर्गों के विभाजन की कल्पना करने में मदद करता है।
tsne = TSNE(n_components=2)
x_tsne = tsne.fit_transform(x, y)
plot_tsne = plt.scatter(x_tsne[:,0], x_tsne[:,1], c=y)
handles, labels = plot_tsne.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("T-SNE 1")
plt.ylabel("T-SNE 2")
_ = plt.title("T-SNE")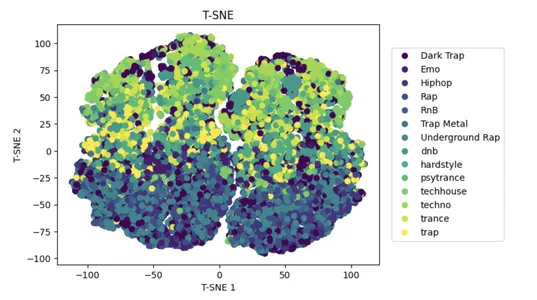
SVD एक लोकप्रिय डायमेंशनलिटी रिडक्शन दृष्टिकोण है जो बड़े डेटासेट की जटिलता को कम करने और मशीन लर्निंग मॉडल के प्रदर्शन को बढ़ाने में सहायता कर सकता है।
निम्नलिखित कोड n घटकों = 2 के साथ इनपुट डेटा x पर एकवचन मान अपघटन (SVD) लागू करता है, इनपुट सुविधाओं की संख्या को घटाकर दो कर देता है जो डेटा में सबसे अधिक भिन्नता की व्याख्या करता है। घटे हुए डेटासेट को तब 2डी स्कैटर प्लॉट पर दिखाया जाता है, जिसमें डॉट्स उनके y-क्लास लेबल के आधार पर रंगीन होते हैं।
यह कम सुविधा वाले स्थान में कई वर्गों के विभाजन की कल्पना करने की सुविधा प्रदान करता है, और स्कैटर प्लॉट को matplotlib टूल के साथ बनाया जाता है।
svd = TruncatedSVD(n_components=2)
x_svd = svd.fit_transform(x, y)
plot_svd = plt.scatter(x_svd[:,0], x_svd[:,1], c=y)
handles, labels = plot_svd.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("Truncated SVD 1")
plt.ylabel("Truncated SVD 2")
_ = plt.title("Truncated SVD")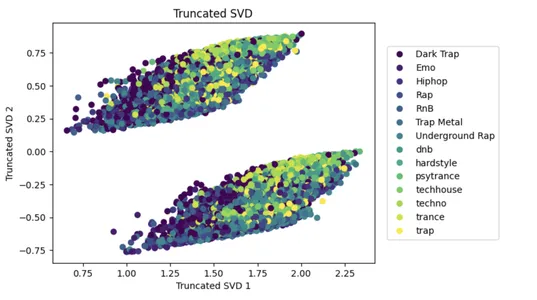
झील प्राधिकरण एक लोकप्रिय डायमेंशनलिटी रिडक्शन अप्रोच है जो अप्रासंगिक जानकारी के प्रभाव को कम करके मशीन लर्निंग मॉडल के प्रदर्शन को बढ़ा सकती है।
निम्न कोड n घटकों = 2 के साथ इनपुट डेटा x पर रैखिक विभेदक विश्लेषण (LDA) करता है, जो डेटा में विभिन्न वर्गों के बीच विभाजन को अधिकतम करने वाले दो रैखिक विभेदकों के लिए इनपुट सुविधाओं की संख्या को कम करता है।
घटे हुए डेटासेट को तब 2डी स्कैटर प्लॉट पर दिखाया जाता है, जिसमें डॉट्स उनके y-क्लास लेबल के आधार पर रंगीन होते हैं। यह कम सुविधा वाले स्थान में कुछ वर्गों के विभाजन की कल्पना करने में सहायता करता है।
lda = LinearDiscriminantAnalysis(n_components=2)
x_lda = lda.fit_transform(x, y.values.ravel())
plot_lda = plt.scatter(x_lda[:,0], x_lda[:,1], c=y)
handles, labels = plot_lda.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("LDA 1")
plt.ylabel("LDA 2")
_ = plt.title("Linear Discriminant Analysis")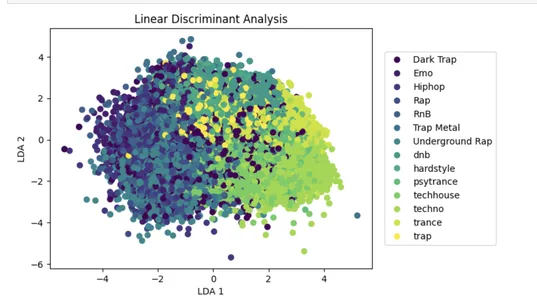
निम्नलिखित कोड 'शैली' नामक डेटा फ़्रेम कॉलम में कुछ मानों को नए सौदे 'रैप' के साथ प्रतिस्थापित करता है। विशेष रूप से, यह "ट्रैप मेटल," "अंडरग्राउंड रैप," "इमो," "आरएनबी," आदि के मूल्यों को "रैप" से बदल देता है। यह विश्लेषण या मॉडलिंग के लिए एक नाम के तहत शैलियों को समूहीकृत करने के लिए उपयोगी है।
df = df.replace("Trap Metal", "Rap")
df = df.replace("Underground Rap", "Rap")
df = df.replace("Emo", "Rap")
df = df.replace("RnB", "Rap")
df = df.replace("Hiphop", "Rap")
df = df.replace("Dark Trap", "Rap")नीचे दिया गया कोड इनपुट डेटासेट df में चर "शैली" वितरण को चित्रित करने के लिए सीबॉर्न लाइब्रेरी का उपयोग करके एक हिस्टोग्राम उत्पन्न करता है। एक्स-अक्ष लेबल की दृश्यता में सुधार के लिए आकृति को 80 डिग्री से घुमाया गया है। "शैलियाँ" एक शीर्षक है।
ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=80)
_ = plt.title("Genres")प्रदान किया गया कोड डेटा फ़्रेम से पंक्तियों को हटा देता है। विशेष रूप से, यह 0.85 की आवृत्ति वाली पंक्तियों को समाप्त करता है जहां एक यादृच्छिक संख्या जनरेटर का उपयोग करके शैली स्तंभ मान "रैप" है।
ड्रॉप फ़ंक्शन का उपयोग करके डेटा फ़्रेम से हटाए जाने से पहले छोड़ी जाने वाली पंक्तियों को ड्रॉप की गई पंक्तियों की सूची में सहेजा जाता है। कोड तब सीबॉर्न प्लॉट फ़ंक्शन के साथ शेष शैली मूल्यों का एक हिस्टोग्राम प्रिंट करता है और मैटप्लोटलिब के शीर्षक और xticks विधियों के साथ एक्स-अक्ष लेबल के शीर्षक और रोटेशन को बदलता है।
rows_drop = []
for i in range(len(df)): if df.iloc[i]['genre'] == 'Rap': if random.random()<0.85: rows_drop.append(i)
df.drop(index = rows_drop, inplace=True) ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=80)
_ = plt.title("Genres")प्रदान किया गया कोड डेटा को प्रीप्रोसेस करता है। स्केलेरन लाइब्रेरी के ट्रेन टेस्ट स्प्लिट फ़ंक्शन का उपयोग करके इनपुट डेटा को प्रशिक्षण और परीक्षण सेटों में विभाजित करना पहला कदम है।
फिर यह उसी पैकेज से MinMaxScaler फ़ंक्शन का उपयोग करके आपूर्ति किए गए डेटा में संख्यात्मक विशेषताओं को समायोजित करता है। कोड प्रीप्रोसेसिंग मॉड्यूल के LabelEncoder फ़ंक्शन का उपयोग करके श्रेणी लक्ष्य चर को एन्कोड करता है।
नतीजतन, प्रशिक्षण और परीक्षण सेट पहले से पूर्व-संसाधित होते हैं जिन्हें एक एकल डेटासेट में विलय कर दिया जाता है जिसे मशीन लर्निंग एल्गोरिदम संसाधित कर सकता है।
x = df.loc[:,:"tempo"]
y = df["genre"] xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size= 0.2, random_state=42, shuffle = True) col = xtrain.columns
scalerx = MinMaxScaler() xtrain = scalerx.fit_transform(xtrain)
xtest = scalerx.transform(xtest) xtrain = pd.DataFrame(xtrain, columns = col)
xtest = pd.DataFrame(xtest, columns = col)
le = preprocessing.LabelEncoder()
ytrain = le.fit_transform(ytrain)
ytest = le.transform(ytest) x = pd.concat([xtrain, xtest], axis = 0)
y = pd.concat([pd.DataFrame(ytrain), pd.DataFrame(ytest)], axis = 0) y_train = le.inverse_transform(ytrain)
y_test = le.inverse_transform(ytest)
y_org = pd.concat([pd.DataFrame(y_train), pd.DataFrame(y_test)], axis = 0) यह कोड मॉडल प्रशिक्षण के लिए दो प्रारंभिक रोक कॉलबैक बनाता है, एक सत्यापन हानि पर आधारित है और दूसरा सत्यापन सटीकता पर आधारित है। Keras 'अनुक्रमिक API ReLU सक्रियण फ़ंक्शन, बैच सामान्यीकरण और ड्रॉपआउट नियमितीकरण का उपयोग करके विभिन्न कनेक्टेड परतों के साथ एक NN मॉडल बनाता है। मॉडल का सारांश कंसोल पर मुद्रित होता है।
अंतिम आउटपुट परत सॉफ्टमैक्स सक्रियण फ़ंक्शन का उपयोग करके वर्ग संभावनाओं को आउटपुट करती है। मॉडल का सारांश कंसोल पर मुद्रित होता है।
early_stopping1 = keras.callbacks.EarlyStopping(monitor = "val_loss", patience = 10, restore_best_weights = True)
early_stopping2 = keras.callbacks.EarlyStopping(monitor = "val_accuracy", patience = 10, restore_best_weights = True) model = keras.Sequential([ keras.layers.Input(name = "input", shape = (xtrain.shape[1])), keras.layers.Dense(256, activation = "relu"), keras.layers.BatchNormalization(), keras.layers.Dropout(0.2), keras.layers.Dense(128, activation = "relu"), keras.layers.Dense(128, activation = "relu"), keras.layers.BatchNormalization(), keras.layers.Dropout(0.2), keras.layers.Dense(64, activation = "relu"), keras.layers.Dense(max(ytrain)+1, activation = "softmax")
]) model.summary()निम्नलिखित कोड ब्लॉक एक तंत्रिका नेटवर्क मॉडल को संकलित और प्रशिक्षित करने के लिए केरस का उपयोग करता है। मॉडल एक अनुक्रमिक मॉडल है जिसमें रिले सक्रियण फ़ंक्शन, बैच सामान्यीकरण और ड्रॉपआउट नियमितीकरण के साथ कई घने परतें हैं। "विरल श्रेणीबद्ध क्रॉस एन्ट्रॉपी" हानि फ़ंक्शन का उपयोग किया जाता है। इसी समय, "एडम" अनुकूलक है। मॉडल को 100 युगों के लिए प्रशिक्षित किया गया है, कॉलबैक के साथ जो सत्यापन हानि और सटीकता के आधार पर जल्दी समाप्त हो जाता है।
model.compile(optimizer = keras.optimizers.Adam(), loss = "sparse_categorical_crossentropy", metrics = ["accuracy"]) model_history = model.fit(xtrain, ytrain, epochs = 100, verbose = 1, batch_size = 128, validation_data = (xtest, ytest), callbacks = [early_stopping1, early_stopping2])प्रशिक्षण डेटा को xtrain और ytrain के रूप में भेजा जाता है, जबकि सत्यापन डेटा को xtest और ytest के रूप में भेजा जाता है। मॉडल का प्रशिक्षण इतिहास मॉडल इतिहास चर में सहेजा जाता है।
print(model.evaluate(xtrain, ytrain)) print(model.evaluate(xtest, ytest))निम्नलिखित कोड matplotlib का उपयोग करके एक प्लॉट उत्पन्न करता है; x_axis पर, हमारे पास epoch है, और y_axis पर, हमारे पास विरल श्रेणीबद्ध क्रॉस एंट्रॉपी है।
plt.plot(model_history.history["loss"])
plt.plot(model_history.history["val_loss"])
plt.legend(["loss", "validation loss"], loc ="upper right")
plt.title("Train and Validation Loss")
plt.xlabel("epoch")
plt.ylabel("Sparse Categorical Cross Entropy")
plt.show()ऊपर जैसा ही है, लेकिन यहां हम युग और सटीकता के बीच साजिश रच रहे हैं।
plt.plot(model_history.history["accuracy"])
plt.plot(model_history.history["val_accuracy"])
plt.legend(["accuracy", "validation accuracy"], loc ="upper right")
plt.title("Train and Validation Accuracy")
plt.xlabel("epoch")
plt.ylabel("Accuracy")
plt.show()निम्नलिखित कोड ypred, जो xtest की भविष्यवाणी करता है।
ypred = model.predict(xtest).argmax(axis=1)निम्नलिखित कोड परीक्षण और ypred पर वर्गीकरण मेट्रिक्स का मूल्यांकन करता है, जहां हम सटीकता, रिकॉल और F1score देख सकते हैं। मूल्यों के आधार पर, हम अपने मॉडल के साथ आगे बढ़ सकते हैं।
cf_matrix = metrics.confusion_matrix(ytest, ypred) _ = sns.heatmap(cf_matrix, fmt=".0f", annot=True) _ = plt.title("Confusion Matrix")अंत में, हम मॉडल मूल्यांकन करते हैं।
मॉडल मूल्यांकन
निम्नलिखित कोड परीक्षण और ypred पर वर्गीकरण मेट्रिक्स का मूल्यांकन करता है, जहां हम सटीक, रिकॉल, F1score कर सकते हैं। मूल्यों के आधार पर हम अपने मॉडल के साथ आगे बढ़ सकते हैं।
print(metrics.classification_report(ytest, ypred))निष्कर्ष
अंत में, हम इस अध्ययन में किए गए विश्लेषण और मॉडलिंग का उपयोग करके 88% की सटीकता के साथ Spotify संगीत शैलियों को वर्गीकृत कर सकते हैं। संगीत शैलियों को परिभाषित करने में जटिलता और व्यक्तिपरकता को देखते हुए, यह सटीकता का एक उचित स्तर है। फिर भी, हमेशा सुधार का अवसर होता है, और हमारे विश्लेषण की कुछ सीमाएँ हैं।
एक नुकसान हमारे डेटासेट में अधिक विविधता की आवश्यकता है, मुख्य रूप से Spotify पर रैप और हिप-हॉप संगीत। इसने विशिष्ट शैलियों के पक्ष में हमारे शोध और मॉडलिंग को प्रभावित किया। हमें अपने मॉडल को बेहतर बनाने के लिए डेटासेट में व्यापक विविधता वाली संगीत शैलियों को शामिल करना चाहिए।
एक अन्य प्रतिबंध डेटा को वर्गीकृत करने में मानवीय गलतियों की संभावना है, जिसके परिणामस्वरूप शैली वर्गीकरण विसंगतियां हो सकती हैं। हम इसे संबोधित करने के लिए श्रवण विशेषताओं के आधार पर संगीत को स्वचालित रूप से लेबल करने के लिए गहन शिक्षण मॉडल जैसे अधिक परिष्कृत दृष्टिकोणों का उपयोग कर सकते हैं।
हमारा विश्लेषण और मॉडलिंग Spotify संगीत शैलियों को वर्गीकृत करने के लिए एक ठोस आधार प्रदान करता है, लेकिन मॉडल की सटीकता और लचीलापन बढ़ाने के लिए अधिक अध्ययन और सुधार की आवश्यकता है।
चाबी छीन लेना
- गति, नृत्य क्षमता, ऊर्जा और वैलेंस जैसी श्रवण विशेषताओं को Spotify संगीत शैलियों में अलग किया जा सकता है।
- मॉडलिंग के लिए डेटा तैयार करने में डेटा की सफाई और प्रीप्रोसेसिंग महत्वपूर्ण प्रक्रियाएं हैं और मॉडल के प्रदर्शन को महत्वपूर्ण रूप से प्रभावित कर सकती हैं।
- प्रारंभिक रोक दृष्टिकोण, जैसे सत्यापन हानि और सटीकता की निगरानी, मॉडल ओवरफिटिंग को रोकने में मदद कर सकती है।
- वर्गीकरण मॉडल के प्रदर्शन को बढ़ाने के लिए डेटासेट का आकार बढ़ाएं, सुविधाएँ जोड़ें और वैकल्पिक तरीकों और हाइपरपैरामीटर के साथ प्रयोग करें।
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/03/solving-spotify-multiclass-genre-classification-problem/
- 1
- 10
- 100
- 2D
- a
- ऊपर
- अनुसार
- शुद्धता
- सही रूप में
- के पार
- सक्रियण
- पता
- सहायता
- एड्स
- करना
- कलन विधि
- एल्गोरिदम
- सब
- की अनुमति देता है
- वैकल्पिक
- हमेशा
- विश्लेषण
- विश्लेषिकी
- एनालिटिक्स विधा
- और
- एपीआई
- आवेदन
- दृष्टिकोण
- दृष्टिकोण
- लेख
- सहायता
- विशेषताओं
- ऑडियो
- स्वचालित
- स्वतः
- अक्ष
- आधारित
- बन
- से पहले
- शुरू
- जा रहा है
- नीचे
- लाभदायक
- के बीच
- खंड
- इमारत
- बिल्डिंग मॉडल
- कॉल
- बुलाया
- बुला
- सूची
- श्रेणियाँ
- वर्गीकरण
- वर्ग
- केंद्र
- केंद्रीय
- परिवर्तन
- बदलना
- विशेषताएँ
- चेक
- चुनने
- कक्षा
- कक्षाएं
- वर्गीकरण
- सफाई
- कोड
- कोडन
- रंग
- स्तंभ
- स्तंभ
- जटिलता
- संगणना
- कंप्यूटिंग
- निष्कर्ष
- भ्रम
- जुड़ा हुआ
- कंसोल
- शामिल हैं
- बदलना
- परिवर्तित
- सह - संबंध
- सहसंबंध
- सका
- बनाना
- बनाता है
- महत्वपूर्ण
- क्रॉस
- ग्राहक
- अंधेरा
- तिथि
- डेटा विश्लेषण
- डेटा अंक
- डेटा सेट
- डेटा विज़ुअलाइज़ेशन
- डेटासेट
- सौदा
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- परिभाषित करने
- मांग
- चित्रण
- तैनात
- वर्णन
- निर्धारित करने
- विकसित करना
- विकास
- विभिन्न
- दिशा
- हानि
- खोज
- विवेक
- डिस्प्ले
- विशिष्ट
- वितरण
- विविधता
- विभाजन
- कर
- नीचे
- डाउनलोड
- बूंद
- गिरा
- ड्रॉप
- से प्रत्येक
- शीघ्र
- आसान
- को हटा देता है
- ऊर्जा
- युग
- अवधियों को
- आदि
- मूल्यांकन करें
- मूल्यांकन
- अनुभव
- प्रयोग
- समझाना
- अन्वेषण
- अन्वेषणात्मक डेटा विश्लेषण
- उद्धरण
- की सुविधा
- एहसान
- Feature
- विशेषताएं
- कुछ
- आकृति
- फ़ाइलें
- अंतिम
- खोज
- खोज
- प्रथम
- फिट
- फोकस
- निम्नलिखित
- प्रपत्र
- बुनियाद
- फ्रेम
- आवृत्ति
- से
- समारोह
- उत्पन्न करता है
- जनक
- मिल
- देना
- दी
- देता है
- देते
- ग्रिड
- समूह की
- गाइड
- हैंडल
- मदद
- सहायक
- मदद करता है
- यहाँ उत्पन्न करें
- अत्यधिक
- इतिहास
- कैसे
- HTTPS
- मानव
- पहचान
- छवियों
- कार्यान्वयन
- आयात
- में सुधार
- सुधार
- सुधार
- in
- सहित
- सम्मिलित
- बढ़ना
- वृद्धि हुई
- बढ़ती
- अनुक्रमणिका
- व्यक्ति
- उद्योग
- प्रभाव
- प्रभावित
- करें-
- निवेश
- स्थापित
- परिचय
- जांच
- IT
- keras
- लेबल
- लेबल
- भाषा
- बड़ा
- परत
- परतों
- प्रमुख
- सीख रहा हूँ
- स्तर
- LG
- पुस्तकालयों
- पुस्तकालय
- सीमाओं
- LINK
- सूची
- सूचीबद्ध
- भार
- बंद
- मशीन
- यंत्र अधिगम
- बनाया गया
- बनाता है
- जोड़ - तोड़
- विशाल
- matplotlib
- मैट्रिक्स
- मैक्स
- अधिकतम करने के लिए
- सार्थक
- मीडिया
- याद
- धातु
- तरीका
- तरीकों
- मेट्रिक्स
- हो सकता है
- लाखों
- कम से कम
- गलतियां
- आदर्श
- मोडलिंग
- मॉडल
- मॉड्यूल
- मॉनिटर
- निगरानी
- अधिक
- अधिकांश
- विभिन्न
- संगीत
- संगीत उद्योग
- संगीत स्ट्रीमिंग
- नाम
- नामांकित
- नामों
- निवल परिसंपत्ति मूल्य
- आवश्यक
- आवश्यकता
- नेटवर्क
- तंत्रिका
- तंत्रिका नेटवर्क
- नया
- नोटबुक
- संख्या
- numpy
- वस्तु
- ONE
- ऑनलाइन
- खुला स्रोत
- अवसर
- आदेश
- मूल
- अन्य
- स्वामित्व
- शांति
- पैकेज
- जोड़े
- पांडा
- भाग
- विशेष
- भागों
- धैर्य
- पैटर्न उपयोग करें
- स्टाफ़
- निष्पादन
- प्रदर्शन
- निजीकृत
- की पसंद
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- अंक
- पॉप
- लोकप्रिय
- पदों
- संभव
- संभावित
- शुद्धता
- भविष्यवाणी करना
- भविष्यवाणी
- भविष्यवाणी
- वरीयताओं
- तैयार करना
- तैयारी
- आवश्यक शर्तें
- को रोकने के
- पहले से
- मुख्यत
- छाप
- प्रिंट
- मुसीबत
- समस्याओं
- प्रक्रिया
- प्रक्रियाओं
- प्रोग्रामिंग
- परियोजना
- बशर्ते
- प्रदान करता है
- प्रकाशित
- रखना
- अजगर
- बिना सोचे समझे
- रेंज
- खटखटाना
- बल्कि
- उचित
- की सिफारिश
- सिफारिश
- घटी
- कम कर देता है
- को कम करने
- संबंध
- शेष
- हटाया
- हटाने
- का प्रतिनिधित्व करता है
- अपेक्षित
- अनुसंधान
- पलटाव
- बंधन
- परिणाम
- रिटर्न
- दिनचर्या
- रन
- दौड़ना
- वही
- स्केलिंग
- विज्ञान
- समुद्र में रहनेवाला
- चयनित
- कई
- सेवाएँ
- सेट
- सेट
- कई
- आकार
- दिखाया
- दिखाता है
- घसीटना
- काफी
- एक
- विलक्षण
- साइटें
- आकार
- ठोस
- सुलझाने
- कुछ
- परिष्कृत
- अंतरिक्ष
- विशिष्ट
- विशेष रूप से
- विभाजित
- Spotify
- ट्रेनिंग
- मानकीकरण
- शुरू
- शुरू होता है
- आँकड़े
- कदम
- रोक
- भंडार
- स्ट्रीमिंग
- स्ट्रीमिंग सेवाएं
- शक्ति
- अध्ययन
- ग्राहकों
- ऐसा
- सारांश
- आपूर्ति
- सिस्टम
- लक्ष्य
- कार्य
- गति
- tensorflow
- परीक्षण
- परीक्षण
- RSI
- लेकिन हाल ही
- पहर
- शीर्षक
- सेवा मेरे
- साधन
- कुल
- ट्रैक
- रेलगाड़ी
- प्रशिक्षित
- प्रशिक्षण
- तब्दील
- रुझान
- <strong>उद्देश्य</strong>
- प्रकार
- के अंतर्गत
- अद्वितीय
- अज्ञात
- यूआरआइ
- us
- प्रयोग
- उपयोग
- उपयोगकर्ताओं
- उपयोग
- उपयोग किया
- सत्यापन
- मूल्यवान
- मूल्य
- मान
- चर
- विविधता
- विभिन्न
- देखें
- दृश्यता
- दृश्य
- कल्पना
- कौन कौन से
- जब
- व्यापक
- मर्जी
- दुनिया की
- X
- जेफिरनेट









