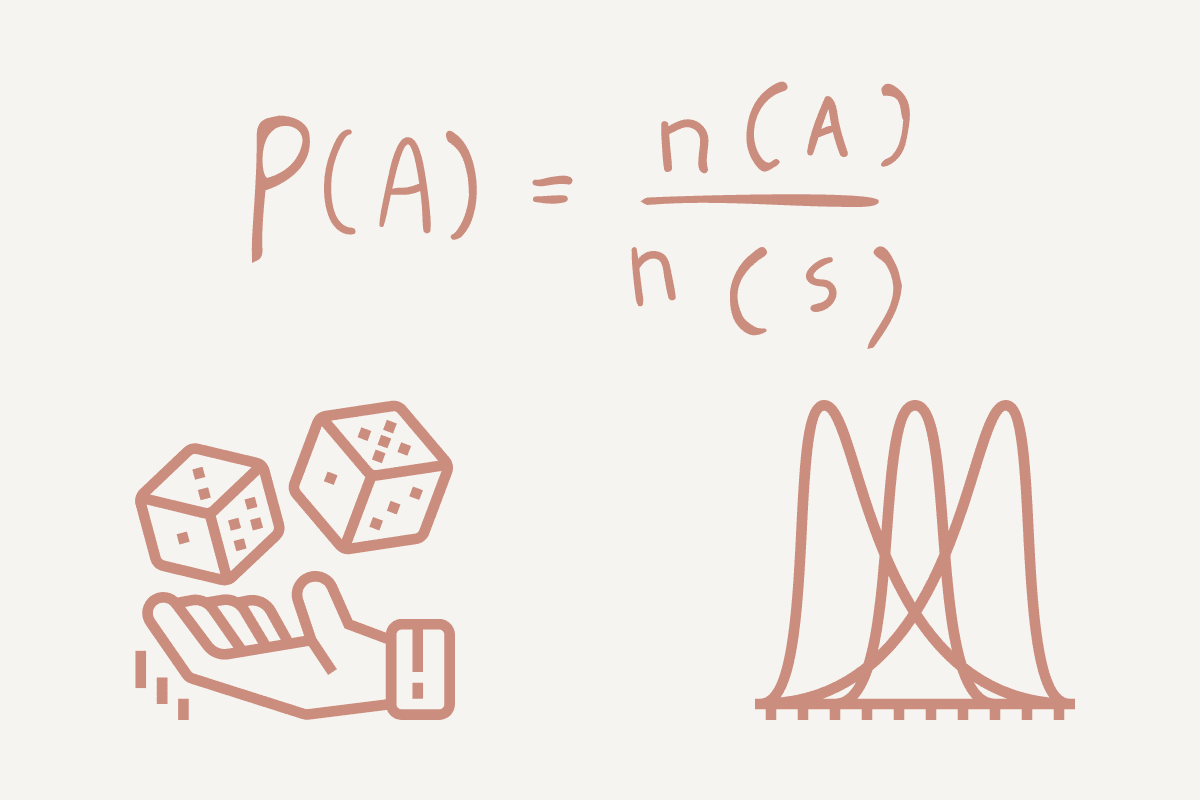
लेखक द्वारा छवि
एक डेटा वैज्ञानिक के रूप में, आप वैधता सुनिश्चित करने के लिए अपने परिणामों की सटीकता जानना चाहेंगे। डेटा विज्ञान वर्कफ़्लो नियंत्रित स्थितियों के साथ एक नियोजित परियोजना है। आपको प्रत्येक चरण का आकलन करने की अनुमति देता है और यह आपके आउटपुट पर कैसे असर डालता है।
संभाव्यता किसी घटना/कुछ घटित होने की संभावना का माप है। यह पूर्वानुमानित विश्लेषण में एक महत्वपूर्ण तत्व है जो आपको अपने परिणाम के पीछे कम्प्यूटेशनल गणित का पता लगाने की अनुमति देता है।
एक सरल उदाहरण का उपयोग करते हुए, आइए एक सिक्का उछालते हुए देखें: या तो चित (H) या पट (T)। आपकी संभावना किसी घटना के घटित होने के तरीकों की संख्या को संभावित परिणामों की कुल संख्या से विभाजित करने पर प्राप्त होगी।
- यदि हम चित की प्रायिकता ज्ञात करना चाहें, तो यह 1 (चित)/2 (चित और पट) = 0.5 होगी।
- यदि हम पट की प्रायिकता ज्ञात करना चाहें, तो यह 1 (पूंछ)/2 (चित और पट) = 0.5 होगी।
लेकिन हम संभाव्यता और संभाव्यता को भ्रमित नहीं करना चाहते - एक अंतर है। संभाव्यता किसी विशिष्ट घटना या परिणाम के घटित होने का माप है। संभावना तब लागू की जाती है जब आप किसी विशिष्ट घटना या परिणाम के घटित होने की संभावना बढ़ाना चाहते हैं।
इसे तोड़ने के लिए - संभाव्यता संभावित परिणामों के बारे में है, जबकि संभावना परिकल्पनाओं के बारे में है।
जानने के लिए एक और शब्द है ''परस्पर अनन्य घटनाएँ''। ये ऐसी घटनाएँ हैं जो एक ही समय में घटित नहीं होती हैं। उदाहरण के लिए, आप एक ही समय में दाएं और बाएं नहीं जा सकते। या यदि हम सिक्का उछाल रहे हैं, तो हम या तो चित या पट प्राप्त कर सकते हैं, दोनों नहीं।
प्रायिकता के प्रकार
- सैद्धांतिक संभाव्यता: यह इस बात पर केंद्रित है कि किसी घटना के घटित होने की कितनी संभावना है और यह तर्क की नींव पर आधारित है। सिद्धांत का उपयोग करते हुए, परिणाम अपेक्षित मूल्य है। हेड और टेल उदाहरण का उपयोग करते हुए, हेड पर उतरने की सैद्धांतिक संभावना 0.5 या 50% है।
- प्रायोगिक संभाव्यता: यह इस बात पर केंद्रित है कि प्रयोग अवधि के दौरान कोई घटना कितनी बार घटित होती है। हेड और टेल उदाहरण का उपयोग करते हुए - यदि हम एक सिक्के को 10 बार उछालते हैं और यह 6 बार हेड पर गिरता है, तो सिक्के के हेड पर उतरने की प्रायोगिक संभावना 6/10 या 60% होगी।
सशर्त संभाव्यता किसी मौजूदा घटना/परिणाम के आधार पर किसी घटना/परिणाम के घटित होने की संभावना है। उदाहरण के लिए, यदि आप किसी बीमा कंपनी के लिए काम कर रहे हैं, तो आप इस शर्त के आधार पर किसी व्यक्ति द्वारा अपने बीमा का भुगतान करने में सक्षम होने की संभावना का पता लगाना चाहेंगे कि उन्होंने गृह ऋण लिया है।
सशर्त संभाव्यता डेटा वैज्ञानिकों को डेटासेट में अन्य चर का उपयोग करके अधिक सटीक मॉडल और आउटपुट तैयार करने में मदद करती है।
संभाव्यता वितरण एक सांख्यिकीय कार्य है जो किसी दिए गए सीमा के भीतर यादृच्छिक चर के लिए संभावित मूल्यों और संभावनाओं का वर्णन करने में मदद करता है। सीमा में संभावित न्यूनतम और अधिकतम मान होंगे, और उन्हें वितरण ग्राफ़ पर कहां प्लॉट किया गया है यह सांख्यिकीय परीक्षणों पर निर्भर करता है।
प्रोजेक्ट में उपयोग किए गए डेटा के प्रकार के आधार पर, आप यह पता लगा सकते हैं कि आप किस प्रकार के वितरण का उपयोग कर रहे हैं। मैं उन्हें दो श्रेणियों में विभाजित करूंगा: पृथक वितरण और निरंतर वितरण।
पृथक वितरण
असतत वितरण तब होता है जब डेटा केवल कुछ निश्चित मान ले सकता है या उसके सीमित संख्या में परिणाम हो सकते हैं। उदाहरण के लिए, यदि आपको पासा फेंकना है, तो आपके सीमित मान 1, 2, 3, 4, 5, और 6 हैं।
असतत वितरण विभिन्न प्रकार के होते हैं। उदाहरण के लिए:
- पृथक समान वितरण वह तब होता है जब सभी परिणाम समान रूप से संभावित हों। यदि हम छह-तरफा पासे को घुमाने के उदाहरण का उपयोग करते हैं, तो इसकी समान संभावना है कि यह 1, 2, 3, 4, 5, या 6 - ⅙ पर गिर सकता है। हालाँकि, असतत समान वितरण के साथ समस्या यह है कि यह हमें प्रासंगिक जानकारी प्रदान नहीं करता है, जिसे डेटा वैज्ञानिक उपयोग और लागू कर सकते हैं।
- बर्नौली वितरण एक अन्य प्रकार का असतत वितरण है, जहां प्रयोग के केवल दो संभावित परिणाम होते हैं, या तो हां या नहीं, 1 या 2, सही या गलत। इसका उपयोग सिक्का उछालते समय किया जा सकता है, यह या तो हेड या टेल होता है। बर्नौली वितरण का उपयोग करते समय, हमारे पास परिणामों में से एक (पी) की संभावना होती है और हम इसे कुल संभावना (1) से घटा सकते हैं, जिसे (1-पी) के रूप में दर्शाया जाता है।
- द्विपद वितरण बर्नौली घटनाओं का एक क्रम है और असतत संभाव्यता वितरण है जो एक प्रयोग में केवल दो संभावित परिणाम उत्पन्न कर सकता है, या तो सफलता या विफलता। सिक्का उछालते समय, किए गए प्रत्येक प्रयोग में सिक्का उछालने की संभावना हमेशा 1.5 या ½ होगी।
- पॉसों वितरण किसी निर्दिष्ट अवधि या दूरी में किसी घटना के कितनी बार घटित होने की संभावना है इसका वितरण है। किसी घटित घटना पर ध्यान केंद्रित करने के बजाय, यह एक विशिष्ट अंतराल में घटित होने वाली घटना की आवृत्ति पर ध्यान केंद्रित करता है। उदाहरण के लिए, यदि 12 कारें हर दिन सुबह 11 बजे किसी विशेष सड़क पर जाती हैं, तो हम पॉइसन वितरण का उपयोग करके यह पता लगा सकते हैं कि एक महीने में सुबह 11 बजे उस सड़क पर कितनी कारें चलती हैं।
सतत वितरण
असतत वितरणों के विपरीत जिनके परिणाम सीमित होते हैं, सतत वितरणों के परिणाम सातत्य होते हैं। ये वितरण आम तौर पर ग्राफ़ पर एक वक्र या रेखा के रूप में दिखाई देते हैं क्योंकि डेटा निरंतर होता है।
- सामान्य वितरण यह वह है जिसके बारे में आपने सुना होगा क्योंकि यह सबसे अधिक बार उपयोग किया जाता है। यह माध्य के चारों ओर मूल्यों का एक सममित वितरण है, जिसमें कोई तिरछापन नहीं है। प्लॉट किए जाने पर डेटा एक घंटी के आकार का अनुसरण करता है, जहां मध्य सीमा माध्य है। उदाहरण के लिए, ऊँचाई और IQ स्कोर जैसी विशेषताएँ सामान्य वितरण का अनुसरण करती हैं।
- टी वितरण एक प्रकार का निरंतर वितरण है जिसका उपयोग तब किया जाता है जब जनसंख्या मानक विचलन (σ) अज्ञात होता है और नमूना आकार छोटा होता है (n<30)। यह सामान्य वितरण, घंटी वक्र के समान आकार का अनुसरण करता है। उदाहरण के लिए, यदि हम देख रहे हैं कि एक दिन में कितने चॉकलेट बार बेचे गए, तो हम सामान्य वितरण का उपयोग करेंगे। हालाँकि, यदि हम यह देखना चाहते हैं कि किसी विशिष्ट घंटे में कितने बेचे गए, तो हम टी-वितरण का उपयोग करेंगे।
- घातांकी रूप से वितरण एक प्रकार का सतत संभाव्यता वितरण है जो किसी घटना के घटित होने तक के समय पर ध्यान केंद्रित करता है। उदाहरण के लिए, हम भूकंपों पर गौर करना चाह सकते हैं और घातीय वितरण का उपयोग कर सकते हैं। इस बिंदु से शुरू होकर भूकंप आने तक का समय। घातीय वितरण को एक घुमावदार रेखा के रूप में प्लॉट किया जाता है और संभावनाओं को तेजी से दर्शाया जाता है।
ऊपर से, आप देख सकते हैं कि कैसे डेटा वैज्ञानिक डेटा के बारे में अधिक समझने और सवालों के जवाब देने के लिए संभाव्यता का उपयोग कर सकते हैं। किसी घटना के घटित होने की संभावनाओं को जानना और समझना डेटा वैज्ञानिकों के लिए बहुत उपयोगी है और निर्णय लेने की प्रक्रिया में बहुत प्रभावी हो सकता है।
आप लगातार डेटा के साथ काम करते रहेंगे और किसी भी प्रकार का विश्लेषण करने से पहले आपको इसके बारे में और अधिक जानने की आवश्यकता होगी। डेटा वितरण को देखने से आपको बहुत सारी जानकारी मिल सकती है और आप इसका उपयोग डेटा वितरण को पूरा करने के लिए अपने कार्य, प्रक्रिया और मॉडल को समायोजित करने के लिए कर सकते हैं।
यह डेटा को समझने में लगने वाले आपके समय को कम करता है, अधिक प्रभावी वर्कफ़्लो प्रदान करता है, और अधिक सटीक आउटपुट देता है।
डेटा विज्ञान की बहुत सारी अवधारणाएँ संभाव्यता के मूल सिद्धांतों पर आधारित हैं।
निशा आर्य डेटा साइंटिस्ट और फ्रीलांस टेक्निकल राइटर हैं। वह विशेष रूप से डेटा साइंस करियर सलाह या ट्यूटोरियल और डेटा साइंस के आसपास सिद्धांत आधारित ज्ञान प्रदान करने में रुचि रखती है। वह उन विभिन्न तरीकों का भी पता लगाना चाहती है जो आर्टिफिशियल इंटेलिजेंस मानव जीवन की लंबी उम्र का लाभ उठा सकते हैं। एक उत्सुक शिक्षार्थी, दूसरों को मार्गदर्शन करने में मदद करते हुए, अपने तकनीकी ज्ञान और लेखन कौशल को व्यापक बनाने की कोशिश कर रही है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/02/importance-probability-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-importance-of-probability-in-data-science
- 1
- 10
- 11
- a
- योग्य
- About
- इसके बारे में
- ऊपर
- शुद्धता
- सही
- सलाह
- सब
- की अनुमति दे
- हमेशा
- राशि
- विश्लेषण
- और
- अन्य
- जवाब
- दिखाई देते हैं
- लागू
- लागू करें
- चारों ओर
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- सलाखों
- आधारित
- से पहले
- पीछे
- जा रहा है
- घंटी
- लाभ
- टूटना
- व्यापक
- नही सकता
- कैरियर
- कारों
- श्रेणियाँ
- कुछ
- संभावना
- विशेषताएँ
- चॉकलेट
- सिक्का
- कंपनी
- अवधारणाओं
- शर्त
- स्थितियां
- उलझन में
- निरंतर
- निरंतर
- सातत्य
- नियंत्रित
- वक्र
- तिथि
- डेटा विज्ञान
- आँकड़े वाला वैज्ञानिक
- दिन
- निर्णय
- वर्णन
- विचलन
- Умереть
- अंतर
- विभिन्न
- दूरी
- वितरण
- वितरण
- विभाजित
- dont
- नीचे
- दौरान
- से प्रत्येक
- भूकंप
- प्रभावी
- भी
- सुनिश्चित
- समान रूप से
- कार्यक्रम
- घटनाओं
- प्रत्येक
- प्रतिदिन
- उदाहरण
- अनन्य
- मौजूदा
- अपेक्षित
- प्रयोग
- का पता लगाने
- घातीय
- तेजी
- विफलता
- आकृति
- खोज
- केंद्रित
- ध्यान केंद्रित
- का पालन करें
- इस प्रकार है
- प्रपत्र
- बुनियाद
- फ्रीलांस
- आवृत्ति
- अक्सर
- से
- समारोह
- आधार
- मिल
- देना
- दी
- Go
- ग्राफ
- गाइड
- हो रहा है
- सिर
- सिर
- सुना
- ऊंचाई
- मदद
- मदद करता है
- मकान
- कैसे
- तथापि
- HTTPS
- मानव
- महत्व
- महत्वपूर्ण
- in
- बढ़ना
- करें-
- बीमा
- बुद्धि
- रुचि
- IT
- केडनगेट्स
- इच्छुक
- जानना
- ज्ञान
- भूमि
- अवतरण
- जानें
- सिखाने वाला
- जीवन
- संभावित
- सीमित
- लाइन
- लिंक्डइन
- ऋण
- दीर्घायु
- देखिए
- देख
- लॉट
- बहुत
- गणित
- अधिकतम
- माप
- मध्यम
- न्यूनतम
- आदर्श
- मॉडल
- महीना
- अधिक
- अधिकांश
- आवश्यकता
- साधारण
- संख्या
- ONE
- अन्य
- अन्य
- परिणाम
- विशेष
- विशेष रूप से
- वेतन
- प्रदर्शन
- अवधि
- व्यक्ति
- की योजना बनाई
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- बिन्दु
- आबादी
- संभावना
- संभव
- भविष्य कहनेवाला विश्लेषण
- संभावना
- मुसीबत
- प्रक्रिया
- उत्पादन
- परियोजना
- प्रदान करना
- प्रदान करता है
- प्रदान कर
- प्रशन
- बिना सोचे समझे
- रेंज
- कम कर देता है
- प्रासंगिक
- प्रतिनिधित्व
- का प्रतिनिधित्व करता है
- परिणाम
- सड़क
- रोल
- रोलिंग
- वही
- विज्ञान
- वैज्ञानिक
- वैज्ञानिकों
- मांग
- अनुक्रम
- आकार
- सरल
- आकार
- तिरछा
- कौशल
- छोटा
- बेचा
- विशिष्ट
- विनिर्दिष्ट
- खर्च
- ट्रेनिंग
- मानक
- शुरुआत में
- सांख्यिकीय
- सफलता
- ऐसा
- लेना
- कार्य
- तकनीक
- तकनीकी
- परीक्षण
- RSI
- सैद्धांतिक
- पहर
- बार
- सेवा मेरे
- टॉस
- कुल
- की ओर
- <strong>उद्देश्य</strong>
- ट्यूटोरियल
- प्रकार
- आम तौर पर
- समझना
- समझ
- us
- उपयोग
- वैधता
- मूल्य
- मान
- चर
- तरीके
- क्या
- कौन कौन से
- Whilst
- मर्जी
- इच्छाओं
- अंदर
- वर्कफ़्लो
- काम कर रहे
- होगा
- लेखक
- लिख रहे हैं
- आपका
- जेफिरनेट