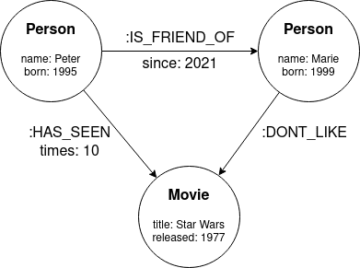
ब्रूस वारिंगटन Unsplash के माध्यम से
सामान्य तौर पर मशीन लर्निंग मॉडल अधिक स्मार्ट होते जा रहे हैं, इसका कारण दो समान वस्तुओं के बीच उन्हें पहचानने में मदद करने के लिए लेबल किए गए डेटा का उपयोग करने पर उनकी निर्भरता है।
हालांकि, इन लेबल वाले डेटासेट के बिना, सबसे प्रभावी और भरोसेमंद मशीन-लर्निंग मॉडल बनाते समय आपको बड़ी बाधाओं का सामना करना पड़ेगा। किसी मॉडल के प्रशिक्षण चरण के दौरान लेबल किए गए डेटासेट महत्वपूर्ण होते हैं।
सुपरवाइज्ड लर्निंग का उपयोग करके कंप्यूटर विजन जैसे कार्यों को हल करने के लिए डीप लर्निंग का व्यापक रूप से उपयोग किया गया है। हालांकि, जैसा कि जीवन में कई चीजों के साथ होता है, यह प्रतिबंधों के साथ आता है। पर्यवेक्षित वर्गीकरण के लिए एक मजबूत मॉडल तैयार करने के लिए लेबल किए गए प्रशिक्षण डेटा की उच्च मात्रा और गुणवत्ता की आवश्यकता होती है। इसका मतलब यह है कि वर्गीकृत मॉडल अनदेखी कक्षाओं को संभाल नहीं सकता है।
और हम सभी जानते हैं कि गहन शिक्षण मॉडल को प्रशिक्षित करने में कितनी कम्प्यूटेशनल शक्ति, पुन: प्रशिक्षण, समय और पैसा लगता है।
लेकिन क्या कोई मॉडल अभी भी प्रशिक्षण डेटा का उपयोग किए बिना दो वस्तुओं के बीच भेद करने में सक्षम हो सकता है? हाँ, इसे जीरो-शॉट लर्निंग कहते हैं। जीरो-शॉट लर्निंग एक मॉडल की क्षमता है जो किसी भी प्रशिक्षण उदाहरण को प्राप्त या उपयोग किए बिना किसी कार्य को पूरा करने में सक्षम है।
मनुष्य बहुत अधिक प्रयास किए बिना स्वाभाविक रूप से जीरो-शॉट सीखने में सक्षम हैं। हमारा दिमाग पहले से ही शब्दकोशों को संग्रहीत करता है और हमें अपने वर्तमान ज्ञान आधार के कारण वस्तुओं को उनके भौतिक गुणों को देखकर अलग करने की अनुमति देता है। हम इस ज्ञानकोष का उपयोग वस्तुओं के बीच समानताएं और अंतर देखने और उनके बीच की कड़ी खोजने के लिए कर सकते हैं।
उदाहरण के लिए, मान लीजिए कि हम जानवरों की प्रजातियों पर एक वर्गीकरण मॉडल बनाने की कोशिश कर रहे हैं। के अनुसार आवरवर्ल्डइनडाटा, 2.13 में 2021 मिलियन प्रजातियों की गणना की गई थी। इसलिए, यदि हम पशु प्रजातियों के लिए सबसे प्रभावी वर्गीकरण मॉडल बनाना चाहते हैं, तो हमें 2.13 मिलियन विभिन्न वर्गों की आवश्यकता होगी। साथ ही बहुत सारे डेटा की जरूरत होगी। उच्च मात्रा और गुणवत्ता डेटा मिलना मुश्किल है।
तो जीरो-शॉट लर्निंग इस समस्या को कैसे हल करती है?
चूंकि शून्य-शॉट सीखने के लिए मॉडल को प्रशिक्षण डेटा सीखने और कक्षाओं को वर्गीकृत करने के तरीके की आवश्यकता नहीं होती है, यह हमें लेबल किए गए डेटा के लिए मॉडल की आवश्यकता पर कम भरोसा करने की अनुमति देता है।
जीरो-शॉट लर्निंग के साथ आगे बढ़ने के लिए आपके डेटा में निम्न चीज़ें शामिल होनी चाहिए।
देखी गई कक्षाएं
इसमें वे डेटा वर्ग शामिल हैं जिनका उपयोग पहले एक मॉडल को प्रशिक्षित करने के लिए किया गया है।
अनदेखी कक्षाएं
इसमें वे डेटा क्लासेस शामिल हैं जिनका उपयोग किसी मॉडल को प्रशिक्षित करने के लिए नहीं किया गया है और नया जीरो-शॉट लर्निंग मॉडल सामान्यीकृत होगा।
सहायक सूचना
जैसा कि अनदेखी कक्षाओं में डेटा को लेबल नहीं किया जाता है, शून्य-शॉट सीखने के लिए सह-संबंध, लिंक और गुणों को सीखने और खोजने के लिए सहायक जानकारी की आवश्यकता होगी। यह शब्द एम्बेडिंग, विवरण और सिमेंटिक जानकारी के रूप में हो सकता है।
शून्य-शॉट सीखने के तरीके
जीरो-शॉट लर्निंग का आमतौर पर उपयोग किया जाता है:
- क्लासिफायर आधारित तरीके
- उदाहरण-आधारित तरीके
इंटर्नशिप
जीरो-शॉट लर्निंग का उपयोग उन कक्षाओं के लिए मॉडल बनाने के लिए किया जाता है जो लेबल किए गए डेटा का उपयोग करके प्रशिक्षित नहीं होते हैं, इसलिए इसके लिए इन दो चरणों की आवश्यकता होती है:
1। ट्रेनिंग
प्रशिक्षण चरण डेटा के गुणों के बारे में जितना संभव हो उतना ज्ञान हासिल करने की कोशिश करने वाली सीखने की प्रक्रिया की प्रक्रिया है। हम इसे सीखने के चरण के रूप में देख सकते हैं।
2. अनुमान
निष्कर्ष चरण के दौरान, प्रशिक्षण चरण से सभी सीखा ज्ञान लागू किया जाता है और उदाहरणों को कक्षाओं के एक नए सेट में वर्गीकृत करने के लिए उपयोग किया जाता है। हम इसे भविष्यवाणियां करने के चरण के रूप में देख सकते हैं।
यह कैसे काम करता है?
देखी गई कक्षाओं के ज्ञान को एक उच्च-आयामी सदिश स्थान में अनदेखी कक्षाओं में स्थानांतरित किया जाएगा; इसे सिमेंटिक स्पेस कहा जाता है। उदाहरण के लिए, छवि वर्गीकरण में छवि के साथ शब्दार्थ स्थान दो चरणों से गुजरेगा:
1. संयुक्त एम्बेडिंग स्थान
यह वह जगह है जहाँ सिमेंटिक वैक्टर और विज़ुअल फ़ीचर के वैक्टर का अनुमान लगाया जाता है।
2. उच्चतम समानता
यह वह जगह है जहां एक अनदेखी वर्ग के खिलाफ सुविधाओं का मिलान किया जाता है।
प्रक्रिया को दो चरणों (प्रशिक्षण और अनुमान) के साथ समझने में मदद करने के लिए, आइए उन्हें छवि वर्गीकरण के उपयोग में लागू करें।
प्रशिक्षण

जरी ह्योटन Unsplash के माध्यम से
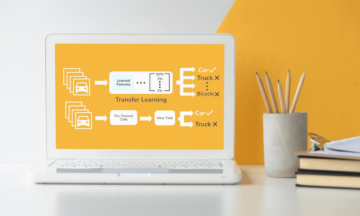
एक इंसान के रूप में, यदि आप ऊपर की छवि में दाईं ओर पाठ पढ़ते हैं, तो आप तुरंत मान लेंगे कि भूरे रंग की टोकरी में 4 बिल्ली के बच्चे हैं। लेकिन मान लीजिए कि आपको पता नहीं है कि 'बिल्ली का बच्चा' क्या होता है। आप मानेंगे कि एक भूरे रंग की टोकरी में 4 चीजें हैं, जिन्हें 'बिल्ली के बच्चे' कहा जाता है। एक बार जब आप अधिक छवियों में आते हैं जिसमें 'बिल्ली का बच्चा' जैसा कुछ होता है, तो आप अन्य जानवरों से 'बिल्ली का बच्चा' को अलग करने में सक्षम होंगे।
जब आप उपयोग करते हैं तो ऐसा होता है विरोधाभासी भाषा-छवि पूर्व प्रशिक्षण (CLIP) OpenAI द्वारा छवि वर्गीकरण में शून्य-शॉट सीखने के लिए। इसे सहायक सूचना के रूप में जाना जाता है।
आप सोच रहे होंगे, 'ठीक है कि यह केवल लेबल किया गया डेटा है'। मैं समझता हूं कि आप ऐसा क्यों सोचेंगे, लेकिन वे ऐसा नहीं हैं। सहायक जानकारी डेटा का लेबल नहीं है, वे प्रशिक्षण चरण के दौरान मॉडल को सीखने में मदद करने के लिए पर्यवेक्षण का एक रूप हैं।
जब एक जीरो-शॉट लर्निंग मॉडल पर्याप्त मात्रा में इमेज-टेक्स्ट पेयरिंग देखता है, तो यह वाक्यांशों को अलग करने और समझने में सक्षम होगा और वे छवियों में कुछ पैटर्न के साथ कैसे सहसंबंधित होते हैं। CLIP तकनीक 'कंट्रास्टिव लर्निंग' का उपयोग करते हुए, जीरो-शॉट लर्निंग मॉडल वर्गीकरण कार्यों पर भविष्यवाणियां करने में सक्षम होने के लिए एक अच्छा ज्ञान आधार जमा करने में सक्षम रहा है।
यह CLIP दृष्टिकोण का सारांश है जहां वे (छवि, पाठ) प्रशिक्षण उदाहरणों के एक बैच की सही जोड़ी की भविष्यवाणी करने के लिए एक इमेज एनकोडर और एक टेक्स्ट एनकोडर को एक साथ प्रशिक्षित करते हैं। कृपया नीचे दी गई छवि देखें:

प्राकृतिक भाषा पर्यवेक्षण से हस्तांतरणीय दृश्य मॉडल सीखना
अनुमान
एक बार जब मॉडल प्रशिक्षण चरण से गुजर चुका होता है, तो उसके पास इमेज-टेक्स्ट पेयरिंग का अच्छा ज्ञान होता है और अब इसका उपयोग भविष्यवाणियां करने के लिए किया जा सकता है। लेकिन इससे पहले कि हम भविष्यवाणी करने में सक्षम हों, हमें उन सभी संभावित लेबलों की सूची बनाकर वर्गीकरण कार्य स्थापित करने की आवश्यकता है जो मॉडल आउटपुट कर सकते हैं।
उदाहरण के लिए, जानवरों की प्रजातियों पर छवि वर्गीकरण कार्य को जारी रखते हुए, हमें जानवरों की सभी प्रजातियों की एक सूची की आवश्यकता होगी। इन लेबलों में से प्रत्येक को एन्कोड किया जाएगा, टी? टी के लिए? प्रशिक्षण चरण में होने वाले पूर्व-प्रशिक्षित पाठ एनकोडर का उपयोग करना।
एक बार लेबल एन्कोड हो जाने के बाद, हम पूर्व-प्रशिक्षित इमेज एनकोडर के माध्यम से इमेज इनपुट कर सकते हैं। हम छवि एन्कोडिंग और प्रत्येक पाठ लेबल एन्कोडिंग के बीच समानता की गणना करने के लिए दूरी मीट्रिक कोसाइन समानता का उपयोग करेंगे।
छवि का वर्गीकरण उस लेबल के आधार पर किया जाता है जो छवि से सबसे अधिक समानता रखता है। और इसी तरह जीरो-शॉट लर्निंग हासिल की जाती है, विशेष रूप से छवि वर्गीकरण में।
डेटा की कमी
जैसा कि पहले उल्लेख किया गया है, उच्च मात्रा और गुणवत्ता डेटा प्राप्त करना कठिन है। मनुष्यों के विपरीत जिनके पास पहले से ही शून्य-शॉट सीखने की क्षमता है, मशीनों को सीखने के लिए इनपुट लेबल वाले डेटा की आवश्यकता होती है और फिर स्वाभाविक रूप से होने वाले भिन्नताओं को अनुकूलित करने में सक्षम होती है।
अगर हम जानवरों की प्रजातियों का उदाहरण देखें, तो बहुत सारे थे। और जैसे-जैसे विभिन्न डोमेन में श्रेणियों की संख्या बढ़ती जा रही है, वैसे-वैसे एनोटेटेड डेटा एकत्र करने में बहुत काम करना होगा।
इसके कारण जीरो-शॉट लर्निंग हमारे लिए अधिक मूल्यवान हो गई है। उपलब्ध डेटा की कमी की भरपाई के लिए अधिक से अधिक शोधकर्ता स्वचालित विशेषता पहचान में रुचि रखते हैं।
डेटा लेबलिंग
जीरो-शॉट लर्निंग का एक अन्य लाभ इसके डेटा लेबलिंग गुण हैं। डेटा लेबलिंग श्रम-गहन और बहुत थकाऊ हो सकती है, और इसके कारण प्रक्रिया के दौरान त्रुटियां हो सकती हैं। डेटा लेबलिंग के लिए विशेषज्ञों की आवश्यकता होती है, जैसे चिकित्सा पेशेवर जो बायोमेडिकल डेटासेट पर काम कर रहे हैं, जो अत्यधिक महंगा और समय लेने वाला है।
डेटा की उपरोक्त सीमाओं के कारण जीरो-शॉट लर्निंग अधिक लोकप्रिय हो रही है। यदि आप इसकी क्षमताओं में रूचि रखते हैं तो कुछ कागजात हैं जो मैं आपको पढ़ने की सलाह दूंगा:
निशा आर्य डेटा साइंटिस्ट और फ्रीलांस टेक्निकल राइटर हैं। वह विशेष रूप से डेटा साइंस करियर सलाह या ट्यूटोरियल और डेटा साइंस के आसपास सिद्धांत आधारित ज्ञान प्रदान करने में रुचि रखती है। वह उन विभिन्न तरीकों का भी पता लगाना चाहती है जो आर्टिफिशियल इंटेलिजेंस मानव जीवन की लंबी उम्र का लाभ उठा सकते हैं। एक उत्सुक शिक्षार्थी, दूसरों को मार्गदर्शन करने में मदद करते हुए, अपने तकनीकी ज्ञान और लेखन कौशल को व्यापक बनाने की कोशिश कर रही है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2022/12/zeroshot-learning-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=zero-shot-learning-explained
- 2021
- a
- क्षमताओं
- क्षमता
- योग्य
- About
- ऊपर
- अनुसार
- संचय करें
- हासिल
- के पार
- अनुकूलन
- सलाह
- के खिलाफ
- सब
- की अनुमति देता है
- पहले ही
- राशि
- और
- जानवर
- जानवरों
- लागू
- लागू करें
- दृष्टिकोण
- चारों ओर
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- स्वचालित
- उपलब्ध
- आधार
- आधारित
- टोकरी
- बन
- बनने
- से पहले
- जा रहा है
- नीचे
- लाभ
- के बीच
- बायोमेडिकल
- व्यापक
- निर्माण
- परिकलित
- बुलाया
- पा सकते हैं
- नही सकता
- सक्षम
- कब्जा
- कैरियर
- श्रेणियाँ
- कुछ
- कक्षा
- कक्षाएं
- वर्गीकरण
- वर्गीकृत
- एकत्रित
- कैसे
- पूरा
- कम्प्यूटेशनल शक्ति
- गणना करना
- कंप्यूटर
- Computer Vision
- जारी
- सका
- बनाना
- बनाना
- वर्तमान
- तिथि
- डेटा विज्ञान
- आँकड़े वाला वैज्ञानिक
- डेटासेट
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- निर्भरता
- मतभेद
- विभिन्न
- में अंतर
- दूरी
- डोमेन
- दौरान
- से प्रत्येक
- प्रभावी
- प्रयास
- त्रुटियाँ
- उदाहरण
- उदाहरण
- महंगा
- विशेषज्ञों
- समझाया
- का पता लगाने
- Feature
- विशेषताएं
- कुछ
- खोज
- निम्नलिखित
- प्रपत्र
- फ्रीलांस
- से
- सामान्य जानकारी
- मिल
- अच्छा
- अधिकतम
- आगे बढ़ें
- गाइड
- संभालना
- हाथ
- हो जाता
- कठिन
- होने
- मदद
- मदद
- हाई
- उच्चतम
- अत्यधिक
- कैसे
- How To
- तथापि
- HTTPS
- मानव
- मनुष्य
- विचार
- की छवि
- छवि वर्गीकरण
- छवियों
- महत्वपूर्ण
- in
- करें-
- निवेश
- बुद्धि
- रुचि
- IT
- इच्छुक
- रखना
- जानना
- ज्ञान
- जानने वाला
- लेबल
- लेबलिंग
- लेबल
- रंग
- भाषा
- नेतृत्व
- जानें
- सीखा
- सीख रहा हूँ
- जीवन
- सीमाओं
- LINK
- लिंक्डइन
- लिंक
- सूची
- दीर्घायु
- देखिए
- देख
- लग रहा है
- लॉट
- मशीन
- यंत्र अधिगम
- मशीनें
- प्रमुख
- बनाना
- निर्माण
- बहुत
- साधन
- मेडिकल
- उल्लेख किया
- तरीका
- तरीकों
- मीट्रिक
- हो सकता है
- दस लाख
- आदर्श
- मॉडल
- धन
- अधिक
- अधिकांश
- प्राकृतिक
- आवश्यकता
- नया
- संख्या
- वस्तुओं
- बाधाएं
- हुआ
- ONE
- OpenAI
- आदेश
- अन्य
- अन्य
- बाँधना
- जोड़ियां
- कागजात
- विशेष रूप से
- पैटर्न उपयोग करें
- पीडीएफ
- चरण
- मुहावरों
- भौतिक
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- कृप्या अ
- लोकप्रिय
- संभव
- बिजली
- भविष्यवाणी करना
- भविष्यवाणियों
- पहले से
- मुसीबत
- प्रक्रिया
- उत्पादन
- पेशेवरों
- प्रक्षेपित
- गुण
- प्रदान कर
- रखना
- गुण
- गुणवत्ता
- मात्रा
- पढ़ना
- कारण
- प्राप्त
- मान्यता
- की सिफारिश
- की आवश्यकता होती है
- की आवश्यकता होती है
- शोधकर्ताओं
- प्रतिबंध
- मजबूत
- विज्ञान
- वैज्ञानिक
- मांग
- देखता है
- सेट
- समान
- समानता
- कौशल
- होशियार
- So
- हल
- कुछ
- अंतरिक्ष
- विशेष रूप से
- ट्रेनिंग
- चरणों
- कदम
- चिपचिपा
- फिर भी
- की दुकान
- ऐसा
- पर्याप्त
- सारांश
- पर्यवेक्षण
- लेना
- लेता है
- कार्य
- कार्य
- तकनीक
- तकनीकी
- RSI
- लेकिन हाल ही
- इसलिये
- चीज़ें
- विचारधारा
- यहाँ
- पहर
- बहुत समय लगेगा
- सेवा मेरे
- एक साथ
- रेलगाड़ी
- प्रशिक्षण
- का तबादला
- भरोसेमंद
- ट्यूटोरियल
- आम तौर पर
- समझना
- us
- उपयोग
- उपयोग किया
- मूल्यवान
- के माध्यम से
- देखें
- दृष्टि
- तरीके
- क्या
- कौन कौन से
- Whilst
- कौन
- व्यापक रूप से
- मर्जी
- बिना
- शब्द
- काम
- काम कर रहे
- होगा
- लेखक
- लिख रहे हैं
- आपका
- जेफिरनेट
- जीरो-शॉट लर्निंग