A pénzügyi piaci szereplők túl sok információval szembesülnek, ami befolyásolja döntéseiket, és a hangulatelemzés hasznos eszköz, amely segít elkülöníteni a releváns és értelmes tényeket és számadatokat. Ugyanaz a hír azonban pozitív vagy negatív hatással lehet a részvényárfolyamokra, ami kihívás elé állítja ezt a feladatot. A hangulatelemzés és más természetes nyelvű programozási (NLP) feladatok gyakran előre betanított NLP-modellekkel indulnak, és a hiperparaméterek finomhangolását hajtják végre, hogy a modellt a környezet változásaihoz igazítsák. Transzformátor alapú nyelvi modellek, mint például a BERT (Kétirányú transzformátorok a nyelv megértéséhez). A gazdasági környezet változásainak figyelembe vételéhez a modellt még egyszer finomítani kell, amikor az adatok sodródni kezdenek, vagy ha a modell előrejelzési pontossága csökkenni kezd.
A hiperparaméter-optimalizálás nagy számításigényes a mély tanulási modelleknél. Az architektúra bonyolultsága nő, ha egyetlen modell betanításhoz több GPU szükséges. Ebben a bejegyzésben a Súlyok és torzítások (W&B) Sweep funkció és Amazon Elastic Kubernetes szolgáltatás (Amazon EKS) e kihívások kezelésére. Az Amazon EKS egy nagy rendelkezésre állású felügyelt Kubernetes szolgáltatás, amely automatikusan méretezi a példányokat a terhelés alapján, és kiválóan alkalmas elosztott képzési terhelések futtatására.
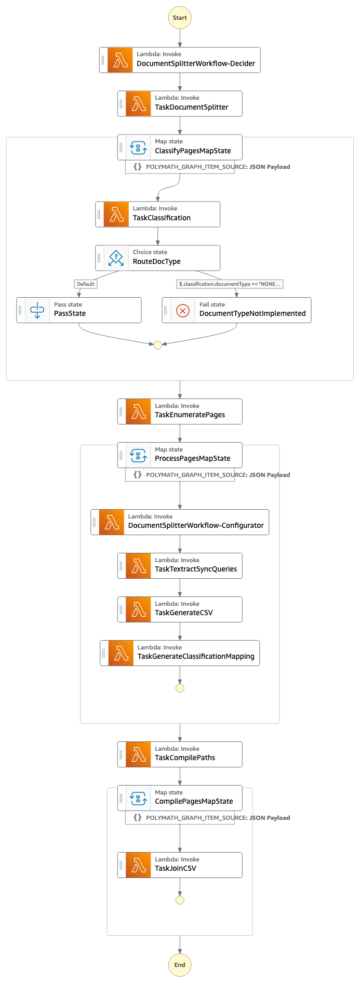
Megoldásunkban hiperparaméteres rácskeresést valósítunk meg egy EKS-klaszteren a bert-alapú modell hangolására a tőzsdei adatsorok pozitív vagy negatív hangulatának osztályozására. A kód megtalálható a GitHub repo.
Megoldás áttekintése
Ebben a bejegyzésben áttekintést adunk a megoldás architektúrájáról, és megvitatjuk annak fő összetevőit. Pontosabban a következőkről beszélünk:
- EKS-fürt beállítása méretezhető fájlrendszerrel
- PyTorch modellek betanítása a TorchElastic segítségével
- Miért a W&B platform a megfelelő választás gépi tanulási (ML) kísérletezéshez és hiperparaméteres rácskereséshez?
- A W&B-t az EKS-sel és a TorchElastic-cal integráló megoldás-architektúra
Előfeltételek
A megoldás követéséhez ismernie kell a PyTorch-t, az elosztott adatok párhuzamos (DDP) képzését és a Kuberneteset.
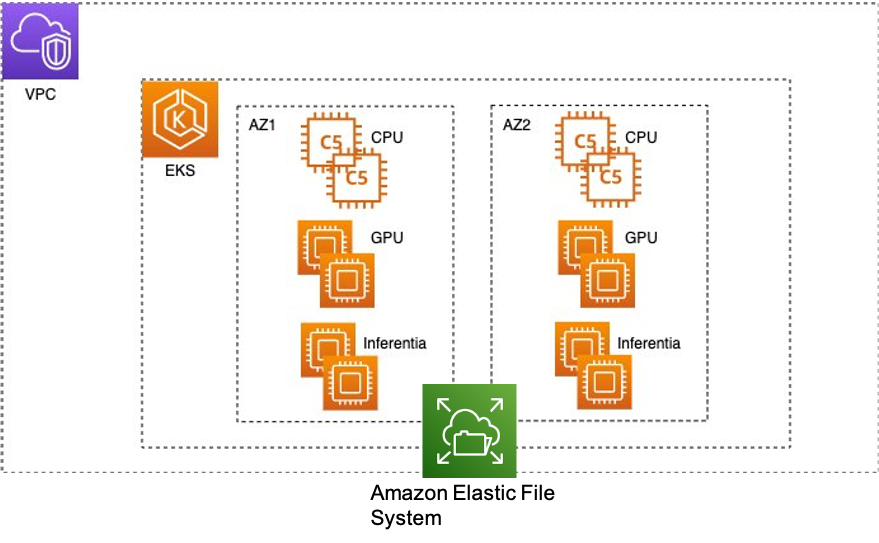
EKS-fürt létrehozása méretezhető fájlrendszerrel
Az Amazon EKS használatának megkezdésének egyik módja aws-do-eks, Ez egy nyílt forráskódú projekt, amely könnyen használható és konfigurálható szkripteket és eszközöket kínál EKS-fürtök létrehozásához és elosztott képzési feladatok futtatásához. Ez a projekt az alapelvek szerint épül fel Végezze el a keretrendszert: egyszerűség, intuitivitás és termelékenység. A kívánt fürt egyszerűen konfigurálható a eks.conf fájlt, és elindítjuk a eks-create.sh forgatókönyv. A részletes utasításokat a GitHub tárolójában találja aws-do-eks.
A következő diagram az EKS-fürt architektúráját mutatja be.
Néhány hasznos tipp az EKS-fürt létrehozásához aws-do-eks:
- Győződjön meg róla,
CLUSTER_REGIONin conf ugyanaz, mint az alapértelmezett Régió, amikor végrehajtja az aws konfigurálását. - Az EKS-fürt létrehozása akár 30 percig is eltarthat. Javasoltuk egy aws-do-eks tároló létrehozását, ahogyan azt a GitHub repo javasolja a konzisztencia és az egyszerűség biztosítása érdekében, mivel a tároló rendelkezik minden szükséges eszközzel, például kubectl, aws cli, eksctl stb. Ezután berohanhat a konténerbe és futhat
./eks-create.sha fürt elindításához. - Hacsak nem adja meg a Spot példányokat a conf-ban, a példányok igény szerint jönnek létre.
- Megadhat egyéni AMI-ket vagy meghatározott zónákat a különböző példánytípusokhoz.
- A
./eks-create.shszkript létrehozza a VPC-t, az alhálózatokat, az automatikus skálázási csoportokat, az EKS-fürtöt, annak csomópontjait és minden egyéb szükséges erőforrást. Ezzel minden típusból egy példány jön létre. Akkor./eks-scale.sha csomópontcsoportokat a kívánt méretre méretezi. - A klaszter létrehozása után AWS Identity and Access Management Az (IAM) szerepkörök az Amazon EKS-hez kapcsolódó házirendekkel jönnek létre minden egyes példánytípushoz. A hozzáféréshez házirendekre lehet szükség Amazon egyszerű tárolási szolgáltatás (Amazon S3) vagy más ilyen szerepkörű szolgáltatások.
- Az alábbiakban felsoroljuk a gyakori okokat, amelyek miatt a
./eks-create.shA szkript hibát jelezhet:- A csomópontcsoportok létrehozása nem megfelelő kapacitás miatt nem sikerül. Ellenőrizze a példányok elérhetőségét a kért régióban és a kapacitáskorlátokat.
- Előfordulhat, hogy egy adott példánytípus nem érhető el vagy nem támogatott egy adott zónában.
- Az EKS klaszter létrehozása AWS felhőképződés a veremek nincsenek megfelelően törölve. Ellenőrizze az aktív CloudFormation veremeket, és ellenőrizze, hogy a veremtörlés nem sikerült-e.
Skálázható megosztott fájlrendszerre van szükség ahhoz, hogy az EKS-fürt több számítási csomópontja egyidejűleg hozzáférhessen. Ebben a bejegyzésben használjuk Amazon elasztikus fájlrendszer (Amazon EFS) megosztott fájlrendszerként, amely rugalmas és nagy átviteli sebességet biztosít. A forgatókönyvek benne aws-do-eks/Container-Root/eks/deployment/csi/ utasításokat ad az Amazon EFS EKS-fürtre való csatlakoztatásához. A fürt létrehozása és a csomópontcsoportok kívánt példányszámra skálázása után a futó podokat a kubectl get pod -A paranccsal tekintheti meg. Itt a aws-node-xxxx, kube-proxy-xxxxés nvidia-device-plugin-daemonset-xxxx A pod-ok mind a három számítási csomóponton futnak, és van egy rendszercsomópont a kube-system névtérben.
Mielőtt folytatná az EFS-kötet létrehozását és csatlakoztatását, győződjön meg arról, hogy a kube-system névtérben van. Ha nem, akkor a következő kóddal módosíthatja:
Ezután tekintse meg a futó hüvelyeket a kubectl get pod -A.

A efs-create.sh szkript létrehozza az EFS-kötetet, és beilleszti a célokat minden egyes alhálózatban és az állandó kötetben. Ezután egy új EFS-kötet lesz látható az Amazon EFS-konzolon.
Ezután futtassa a ./deploy.sh parancsfájlt az EFS fájlok rendszerazonosítójának lekéréséhez, egy EFS-CSI illesztőprogram telepítéséhez minden csomópontcsoporthoz, és csatolja az EFS állandó kötetet a efs-sc.yaml és a efs-pv.yaml manifeszt fájlok. Ellenőrizéssel ellenőrizheti, hogy egy állandó kötet csatlakoztatva van-e kubectl get pv. Futni is lehet kubectl apply -f efs-share-test.yaml, amely egy efs-share-teszt-podát fog felpörgetni az alapértelmezett névtérben. Ez egy tesztdoboz, amely azt írja, hogy „hello from EFS” /shared-efs/test.txt fájlt. Használatával belefuthat egy hüvelybe kubectl exec -it <pod-name> -- bash. Az Amazon S3-ból az Amazon EFS-be történő adatátvitelhez efs-data-prep-pod.yaml példa jegyzékfájlt ad, feltételezve, hogy a data-prep.sh A szkript létezik egy Docker-képben, amely az Amazon S3-ból az Amazon EFS-be másolja az adatokat.
Ha a modellképzésnek nagyobb áteresztőképességre van szüksége, Amazon FSx Lusterhez lehet jobb megoldás.
Tanítsa a PyTorch modelleket a TorchElastic segítségével
Az olyan mélytanulási modelleknél, amelyek túl nagy mennyiségű adatra edznek ahhoz, hogy egyetlen GPU memóriájában elférjenek, DistributedDataParallel (PyTorch DDP) lehetővé teszi a nagy betanítási adatok mini kötegekre való felosztását több GPU-n és példányon keresztül, csökkentve a betanítási időt.
A TorchElastic egy PyTorch könyvtár, amelyet natív Kubernetes stratégiával fejlesztettek ki, amely támogatja a hibatűrést és a rugalmasságot. Az azonnali példányokon végzett képzés során a betanításnak hibatűrőnek kell lennie, és képesnek kell lennie attól a korszaktól folytatni, ahol a számítási csomópontok elhagyták, amikor a spot példányok utoljára elérhetőek voltak. A rugalmasság lehetővé teszi új számítási erőforrások zökkenőmentes hozzáadását, ha rendelkezésre állnak, vagy erőforrások eltávolítását, ha máshol van rájuk szükség.
A következő ábra az architektúrát mutatja be DistributedDataParallel TorchElastic-al. A TorchElastic for Kubernetes két összetevőből áll: a TorchElastic Kubernetes Controllerből és a paraméterkiszolgálóból (stb.). A vezérlő felelős a betanítási feladatok figyeléséért és kezeléséért, a paraméterkiszolgáló pedig nyomon követi a betanítási feladatok dolgozóit az elosztott szinkronizálás és a társkeresés érdekében.

W&B platform ML kísérletezéshez és hiperparaméteres rácskereséshez
A W&B segít az ML csapatoknak gyorsabban jobb modelleket készíteni. Csak néhány sornyi kóddal azonnal hibakeresést, összehasonlítást és reprodukálást végezhet a modelljein – az architektúra, a hiperparaméterek, a git-commitok, a modellsúlyok, a GPU-használat, az adatkészletek és az előrejelzések –, miközben együttműködik csapattársaival.

A W&B Sweeps egy hatékony eszköz a hiperparaméter-optimalizálás automatizálására. Lehetővé teszi a fejlesztők számára, hogy beállítsák a hiperparaméteres keresési stratégiát, beleértve a rácskeresést, a véletlenszerű keresést vagy a Bayes-keresést, és automatikusan végrehajtja az egyes edzéseket.
A W&B ingyenes kipróbálásához regisztráljon a következő címen: Súlyok és torzításokVagy keresse fel a A W&B AWS Marketplace-lista.
Integrálja a W&B-t az Amazon EKS-sel és a TorchElastic-cal
A következő ábra a végpontok közötti folyamatfolyamatot szemlélteti több DistributedDataParallel képzési futtatáshoz az Amazon EKS rendszeren a TorchElastic segítségével W&B sweep konfiguráció alapján. Konkrétan az érintett lépések a következők:
- Adatok áthelyezése az Amazon S3-ból az Amazon EFS-be.
- Adatok betöltése és előfeldolgozása a W&B segítségével.
- Hozzon létre egy Docker-képet a képzési kóddal és az összes szükséges függőséggel, majd tolja el a képet az Amazon ECR-be.
- Telepítse a TorchElastic vezérlőt.
- Hozzon létre egy W&B sweep konfigurációs fájlt, amely tartalmazza az összes söpörni kívánt hiperparamétert és tartományukat.
- Hozzon létre egy yaml jegyzéksablonfájlt, amely bemeneteket vesz a sweep konfigurációs fájlból.
- Hozzon létre egy Python-feladatvezérlő-parancsfájlt, amely N tanítási jegyzékfájlt hoz létre, minden betanítási futtatáshoz egyet, és elküldi a feladatokat az EKS-fürtnek.
- Vizualizálja az eredményeket a W&B platformon.

A következő részekben minden lépést részletesebben végigjárunk.
Adatok áthelyezése az Amazon S3-ból az Amazon EFS-be
Az első lépés a képzési, érvényesítési és tesztadatok áthelyezése az Amazon S3-ból az Amazon EFS-be, hogy az összes EKS számítási csomópont hozzáférhessen. A s3_efs mappa rendelkezik a szkriptekkel az adatok Amazon S3-ból az Amazon EFS-be való áthelyezéséhez. Kövesd a Végezze el a keretrendszert, szükségünk van egy alap Dockerfile-ra, amely egy tárolót hoz létre a data-prep.sh forgatókönyv, build.sh szkript és nyomja.sh szkriptet a kép elkészítéséhez, és elküldi az Amazon ECR-be. Miután a Docker-képet az Amazon ECR-be küldték, használhatja a efs-data-prep-pod.yaml manifest fájlt (lásd a következő kódot), amelyet hasonlóan futtathat kubectl apply -f efs-data-prep-pod.yaml a data-prep.sh parancsfájl podban történő futtatásához:
apiVersion: v1
kind: ConfigMap
metadata
name: efs-data-prep-map
data:
S3_BUCKET:<S3 Bucket URI with data>
MOUNT_PATH: /shared-efs
---
apiVersion: v1
kind: Pod
metadata:
name: efs-data-prep-pod
spec:
containers:
- name: efs-data-prep-pod
image: <Path to Docker image in ECR>
envFrom:
- configMapRef:
name: efs-data-prep-map
command: ["/bin/bash"]
args: ["-c", "/data-prep.sh $(S3_BUCKET) $(MOUNT_PATH)"]
volumeMounts:
- name: efs-pvc
mountPath: /shared-efs
volumes:
- name: efs-pvc
persistentVolumeClaim:
claimName: efs-claim
restartPolicy: Never
Adatok betöltése és előfeldolgozása a W&B segítségével
Az előfeldolgozási feladat elküldésének folyamata néhány kivételtől eltekintve nagyon hasonló az előző lépéshez. A data-prep.sh szkript helyett valószínűleg Python-feladatot kell futtatnia az adatok előfeldolgozásához. Az előfeldolgozási mappa tartalmazza az előfeldolgozási feladat futtatásához szükséges parancsfájlokat. A pre-process_data.py A script két feladatot hajt végre: beveszi a nyers adatokat az Amazon EFS-ben, és felosztja azokat képzési és tesztfájlokra, majd hozzáadja az adatokat a W&B projekthez.
Hozzon létre egy Docker-képet képzési kóddal
main.py bemutatja, hogyan valósítható meg a DistributedDataParallel képzés a TorchElastic segítségével. A W&B-vel való kompatibilitás érdekében szokásos gyakorlat hozzáfűzni WANDB_API_KEY környezeti változóként és add hozzá wandb.login() a kód legelején. A szabványos argumentumok (korszakok száma, kötegméret, az adatbetöltő dolgozóinak száma) mellett át kell adnunk wandb_project név és sweep_id is.
A main.py kódban a run() függvény tárolja a végpontok közötti folyamatot a következő műveletekhez:
- A wandb inicializálása a 0. csomóponton az eredmények naplózásához
- Az előre betanított modell betöltése és az optimalizáló beállítása
- Egyéni képzési és érvényesítési adatbetöltők inicializálása
- Ellenőrzőpontok betöltése és mentése minden korszakban
- A korszakokon való körözés, a képzési és érvényesítési függvények meghívása
- Az edzés befejezése után előrejelzések futtatása a megadott tesztkészleten
A betanítási, érvényesítési, egyéni adatbetöltő és összeválogatási funkciókat nem kell módosítani az eredmények W&B-be naplózásához. Elosztott betanítási beállításhoz a következő kódblokkot kell hozzáadnunk a 0 csomóponti folyamatba való bejelentkezéshez. Itt az args a betanítási funkció paraméterei a sweep ID és a W&B projekt neve mellett:
if local_rank == 0: wandb.init(config=args, project=args.wandb_project) args = wandb.config do_log = True
else: do_log = False
A W&B-vel és az elosztott képzéssel kapcsolatos további információkért lásd: Elosztott képzési kísérletek naplózása.
A main() függvényt, a run() függvényt a következő kód szerint hívhatja meg. Itt a wandb.agent a sweep irányítója, de mivel párhuzamosan több képzési feladatot is futtatunk az Amazon EKS-en, meg kell adnunk count = 1:
wandb.require("service") wandb.setup() if args.sweep_id is not None: wandb.agent(args.sweep_id, lambda: run(args), project=args.wandb_project, count = 1) else: run(args=args)
A dockerfile telepíti a PyTorch, HuggingFace és W&B szükséges függőségeit, és belépési pontként megadja a torch.distributed.run Python-hívást.
Telepítsen egy TorchElastic vezérlőt
A képzés előtt telepítenünk kell egy TorchElastic-vezérlőt a Kuberneteshez, amely egy Kubernetes egyéni ErasticJob-erőforrást kezel a TorchElastic-munkaterhelések futtatásához Kubernetesen. Az etcd-kiszolgálót futtató pod-ot is telepítünk a szkript futtatásával telepíteni.sh. Javasoljuk, hogy törölje és indítsa újra az etcd szervert, amikor újraindítja az új betanítási feladatot.
W&B sweep konfig
A fürt és a tároló beállítása után több párhuzamos futtatást állítottunk be kissé eltérő paraméterekkel, hogy javítsuk modellünk teljesítményét. W&B söprés automatizálni fogja ezt a fajta feltárást. Létrehozunk egy konfigurációs fájlt, ahol meghatározzuk a keresési stratégiát, a figyelni kívánt mérőszámot és a feltárandó paramétereket. A következő kód egy példakénti sweep konfigurációs fájlt mutat:
method: bayes
metric: name: val_loss goal: minimize
parameters: learning_rate: min: 0.001 max: 0.1
optimizer: values: ["adam", "sgd"]
A sweepek konfigurálásával kapcsolatos további részletekért kövesse a W&B Sweeps - Gyorsindítás.
Hozzon létre egy train.yaml sablont
A következő kód egy példa a train.yaml sablonra, amelyet létre kell hoznunk. A Python feladatvezérlő ezt a sablont használja, és a hiperparaméteres rácskeresés minden egyes futtatásához egy betanító .yaml fájlt generál. Néhány fontos megjegyzés:
- A
kubernetes.io/instance-typeAz érték az EKS számítási csomópontok példánytípusának nevét veszi fel. - Az args szakasz tartalmazza az összes olyan paramétert, amelyet a py kód argumentumként vesz fel, beleértve az epochok számát, a köteg méretét, az adatbetöltő dolgozók számát,
sweep_id, wandb projekt neve, ellenőrzőpont fájl helye, adatkönyvtár helye stb. - A
--nproc_per_nodeés anvidia.com/gpuaz értékek a képzéshez használni kívánt GPU-k számát jelentik. Például a következő konfigurációban a p3.8xlarge az EKS számítási csomópontja, amely 4 Nvidia Tesla V100 GPU-val rendelkezik, és minden edzési futásban 2 GPU-t használunk. Hat edzést indíthatunk párhuzamosan, amelyek kimerítik az összes rendelkezésre álló 12 GPU-t, ezzel biztosítva a magas GPU kihasználtságot.
apiVersion: elastic.pytorch.org/v1alpha1
kind: ElasticJob
metadata: name: wandb-finbert-baseline #namespace: elastic-job
spec: # Use "etcd-service:2379" if you already apply etcd.yaml rdzvEndpoint: etcd-service:2379 minReplicas: 1 maxReplicas: 128 replicaSpecs: Worker: replicas: 1 restartPolicy: ExitCode template: apiVersion: v1 kind: Pod spec: nodeSelector: node.kubernetes.io/instance-type: p3.8xlarge containers: - name: elasticjob-worker image: <path to docker image in ECR> imagePullPolicy: Always env: - name: NCCL_DEBUG value: INFO # - name: NCCL_SOCKET_IFNAME # value: lo # - name: FI_PROVIDER # value: sockets args: - "--nproc_per_node=2" - "/workspace/examples/huggingface/main.py" - "--data=/shared-efs/wandb-finbert/" - "--epochs=1" - "--batch-size=16" - "--workers=6" - "--wandb_project=aws_eks_demo" - "--sweep_id=jba9d36p" - "--checkpoint-file=/shared-efs/wandb-finbert/job-z74e8ix8/run-baseline/checkpoint.tar" resources: limits: nvidia.com/gpu: 2 volumeMounts: - name: efs-pvc mountPath: /shared-efs - name: dshm mountPath: /dev/shm volumes: - name: efs-pvc persistentVolumeClaim: claimName: efs-claim - name: dshm emptyDir: medium: Memory
Hozzon létre egy rácskeresési feladatvezérlőt
A script run-grid.py a kulcsfontosságú irányító, amely bevesz egy TorchElastic képzési .yaml sablont és W&B sweep konfigurációs fájlt, több képzési jegyzékfájlt generál, és elküldi azokat.
Vizualizálja az eredményeket
Létrehoztunk egy EKS klasztert hárommal p3.8xlarge példányok egyenként 4 Tesla V100 GPU-val. Hat párhuzamos futtatást állítottunk be 2-25 GPU-val, miközben változtattuk az Adam-optimalizáló tanulási sebességét és súlycsökkenési paramétereit. Minden egyes edzési futás nagyjából 25 percet vesz igénybe, így a teljes hiperparaméterrácsot 150 perc alatt le lehetne söpörni párhuzamosan, szemben a XNUMX perccel, ha egymást követően. Kívánság szerint minden edzési körben egyetlen GPU használható a --nproc_per_node és a nvidia.com/gpu értékeket a képzési .yaml sablonban.
A TorchElastic rugalmasságot és hibatűrést biztosít. Ebben a munkában On-Demand példányokat használunk, de az EKS konfigurációjában néhány változtatással azonnali példányok fürtje is létrehozható. Ha egy példány később elérhetővé válik, és hozzá kell adni a képzési készlethez, miközben a képzés zajlik, csak frissítenünk kell a képzési .yaml sablont, és újra el kell küldenünk. A TorchElastic randevúzási funkciója dinamikusan asszimilálja az új példányt a képzési munkában.
Miután a rácskeresési feladatvezérlő fut, láthatja mind a hat Kubernetes-feladatot kubectl get pod -A. Tanulási futtatásonként egy feladat lesz, és minden feladathoz csomópontonként egy dolgozó tartozik. Az egyes tömbök naplóinak megtekintéséhez használja a faroknaplókat kubectl logs -f <pod-name>. kubetail egyszerre jeleníti meg az összes naplót minden egyes képzési feladathoz. A rácsvezérlő elején kap egy hivatkozást a W&B platformra, ahol megtekintheti az összes feladat előrehaladását.
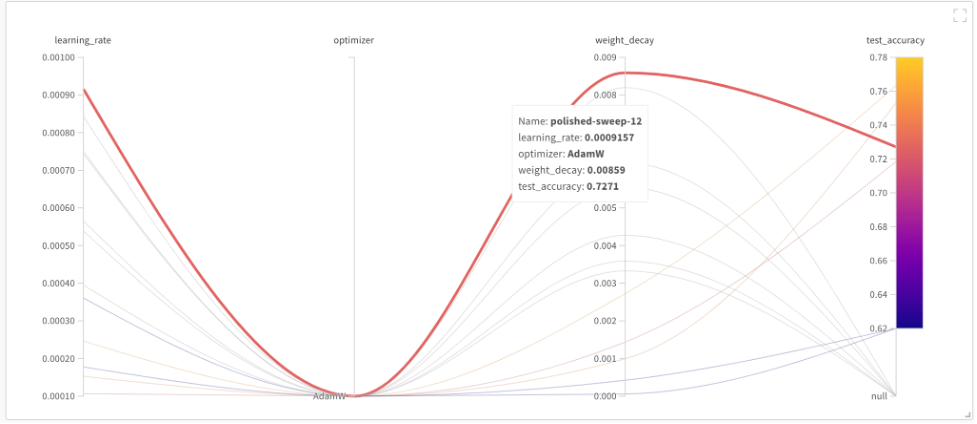
A következő párhuzamos koordináta-grafikon az összes rácskeresési futtatást vizualizálja a tesztpontosság szempontjából egy diagramon, beleértve azokat is, amelyek nem fejeződtek be. A legmagasabb tesztpontosságot 9.1e-4 tanulási sebességgel és 8.5e-3 súlycsökkenéssel kaptuk.
A következő irányítópult az összes rácskeresést együtt jeleníti meg az összes metrika esetében.

Tisztítsuk meg
A modell betanítása után fontos az erőforrások lebontása, hogy elkerülje a tétlen példányok futtatásával járó költségeket. Minden erőforrást létrehozó szkriptnél a GitHub repo megfelelő szkriptet biztosít ezek törléséhez. A beállítás megtisztításához törölnünk kell az EFS fájlrendszert a fürt törlése előtt, mert az a fürt VPC-jében lévő alhálózathoz van társítva. Az EFS fájlrendszer törléséhez futtassa a következő parancsot (belülről EFS mappa):
Ne feledje, hogy ezzel nem csak az állandó kötetet törli, hanem az EFS fájlrendszert is, és a fájlrendszeren lévő összes adat elveszik. Ha ez a lépés befejeződött, törölje a fürtöt a következő parancsfájl használatával a volt mappa:
Ezzel törli az összes meglévő podot, eltávolítja a klasztert, és törli az elején létrehozott VPC-t.
Következtetés
Ebben a bejegyzésben bemutattuk, hogyan használhatunk EKS-fürtöt súlyokkal és torzításokkal a mélytanulási modellek hiperparaméteres rácskeresésének felgyorsítására. A Weights & Biases és az Amazon EKS lehetővé teszi több edzés párhuzamos megszervezését, hogy csökkentse a mély tanulási modell finomhangolásához szükséges időt és költséget. Megjelentettük a GitHub repo, amely lépésről lépésre útmutatást ad az EKS-fürt létrehozásához, a Weights & Biases és a TorchElastic beállításához az elosztott adatok párhuzamos képzéséhez, és egy kattintással elindítja a rácskeresést az Amazon EKS-en.
A szerzőkről
Ankur Srivastava Sr. Solutions Architect az ML Frameworks csapatában. Arra összpontosít, hogy segítse az ügyfeleket a saját maga által irányított, elosztott képzéssel és az AWS-re vonatkozó széles körű következtetésekkel. Tapasztalatai közé tartozik az ipari prediktív karbantartás, a digitális ikrek, a valószínűségi tervezés optimalizálása, doktori tanulmányait a Rice Egyetem gépészmérnöki szakán, valamint a Massachusetts Institute of Technology posztdoktori kutatását végezte.
Thomas Chapelle gépi tanulási mérnök a súlyok és elfogultságok területen. Ő felelős azért, hogy a www.github.com/wandb/examples adattárat folyamatosan naprakészen tartsa. Tartalmakat is épít az MLOPS-ra, a W&B ipari alkalmazásokra és általában a szórakoztató mély tanulásra. Korábban mély tanulással oldotta meg a napenergia rövid távú előrejelzését. Várostervezési, kombinatorikus optimalizálási, közlekedésgazdasági és alkalmazott matematikai háttérrel rendelkezik.
Scott Juang a súlyok és elfogultságok szövetségeinek igazgatója. A W&B előtt számos stratégiai szövetséget vezetett az AWS-nél és a Clouderánál. Scott Anyagmérnököt tanult, és szenvedélye a megújuló energia.
Ilan Gleiser az AWS globális hatásszámítási szakértője, aki a körkörös gazdaság, a felelős mesterségesintelligencia és az ESG üzletágakat vezeti. Az ENSZ körforgásos gazdasággal foglalkozó digitális technológiáinak szakértői tanácsadója. Az AWS előtt az AI Enterprise Solutions-t vezette a Wells Fargonál. 10 évet töltött a Morgan Stanley algoritmikus kereskedési részlegének vezetőjeként San Franciscóban.
Ana Simoes az AWS vezető ML-szakértője, aki a feltörekvő technológiai területen működő startupok GTM-stratégiájára összpontosít. Ana számos vezető szerepet töltött be olyan startupoknál és nagyvállalatoknál, mint az Intel és az eBay, az ML következtetésekhez és a nyelvészethez kapcsolódó termékekben. Ana számítógépes nyelvészetből mesterképzést és MBA diplomát szerzett a Haas/UC Berkeley-n, és vendégkutató volt nyelvészetből a Stanfordban. Műszaki háttérrel rendelkezik mesterséges intelligencia és természetes nyelvi feldolgozás területén.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/accelerate-hyperparameter-grid-search-for-sentiment-analysis-with-bert-models-using-weights-biases-amazon-eks-and-torchelastic/
- 1
- 10
- 7
- 9
- a
- képesség
- Képes
- gyorsul
- hozzáférés
- Fiók
- pontosság
- át
- cselekvések
- aktív
- Ádám
- hozzáadott
- mellett
- cím
- Hozzáteszi
- tanácsadó
- Után
- AI
- algoritmikus
- algoritmikus kereskedés
- Minden termék
- lehetővé teszi, hogy
- már
- mindig
- amazon
- Összegek
- Ana
- elemzés
- és a
- alkalmazások
- alkalmazott
- alkalmaz
- építészeti
- építészet
- érvek
- társult
- auto
- automatizált
- automatikusan
- elérhetőség
- elérhető
- elkerülése érdekében
- AWS
- AWS piactér
- háttér
- alapján
- alapvető
- bayesi
- mert
- válik
- előtt
- Kezdet
- Berkeley
- Jobb
- nagyobb
- Blokk
- épít
- épít
- épült
- vállalkozások
- hívás
- hívás
- Kapacitás
- elfog
- kihívás
- kihívások
- változik
- Változások
- változó
- ellenőrizze
- ellenőrzése
- választás
- körkörös gazdaság
- besorolás
- Cloudera
- Fürt
- kód
- együttműködő
- Közös
- összehasonlítani
- kompatibilitás
- teljes
- Befejezett
- bonyolultság
- alkatrészek
- Kiszámít
- számítástechnika
- Configuration
- Konzol
- Konténer
- Konténerek
- tartalom
- kontextus
- ellenőr
- Corporations
- Költség
- kiadások
- tudott
- teremt
- készítette
- teremt
- létrehozása
- teremtés
- Jelenlegi
- Jelenlegi állapot
- szokás
- Ügyfelek
- műszerfal
- dátum
- adatkészletek
- találka
- DDP
- határozatok
- mély
- mély tanulás
- alapértelmezett
- Kereslet
- igényes
- mutatja
- telepíteni
- Design
- részlet
- részletes
- részletek
- fejlett
- fejlesztők
- különböző
- digitális
- Digitális ikrek
- Igazgató
- felfedezés
- megvitatni
- kijelző
- megosztott
- elosztott képzés
- osztály
- Dokkmunkás
- ne
- le-
- gépkocsivezető
- dinamikusan
- minden
- könnyen használható
- eBay
- Gazdasági
- Közgazdaságtan
- gazdaság
- máshol
- csiszolókő
- Feltörekvő technológia
- lehetővé
- lehetővé teszi
- végtől végig
- energia
- mérnök
- Mérnöki
- biztosítására
- biztosítása
- Vállalkozás
- Vállalati megoldások
- Egész
- belépés
- Környezet
- korszak
- korszakok
- hiba
- ESG
- Eter (ETH)
- Minden
- példa
- létező
- létezik
- tapasztalat
- szakértő
- kutatás
- feltárása
- szembe
- FAIL
- Sikertelen
- gyorsabb
- kevés
- Ábra
- ábrák
- filé
- Fájlok
- befejezni
- vezetéknév
- megfelelő
- áramlási
- koncentrál
- összpontosítás
- következik
- következő
- Startupoknak
- forma
- talált
- keretek
- Francisco
- Ingyenes
- friss
- ból ből
- móka
- funkció
- funkcionalitás
- funkciók
- általános
- generál
- generált
- generál
- kap
- megy
- GitHub
- Ad
- adott
- ad
- Globális
- cél
- megy
- GPU
- GPU
- grafikon
- Rács
- Csoport
- Csoportok
- fej
- Headlines
- segít
- hasznos
- segít
- segít
- itt
- Magas
- <p></p>
- legnagyobb
- nagyon
- Hogyan
- How To
- azonban
- HTML
- HTTPS
- HuggingFace
- Hiperparaméter optimalizálás
- IAM
- Identitás
- Idle
- kép
- Hatás
- végre
- munkagépek
- fontos
- javul
- in
- magában foglalja a
- Beleértve
- Növeli
- egyéni
- ipari
- iparágak
- info
- információ
- példa
- helyette
- Intézet
- utasítás
- integrálása
- Intel
- részt
- IT
- Munka
- Állások
- tartás
- Kulcs
- rúg
- Kedves
- Kubernetes
- nyelv
- nagy
- keresztnév
- indít
- indított
- Vezetés
- vezető
- tanulás
- Led
- könyvtár
- Valószínű
- határértékek
- vonalak
- nyelvészet
- LINK
- él
- kiszámításának
- rakodó
- elhelyezkedés
- gép
- gépi tanulás
- Fő
- karbantartás
- csinál
- sikerült
- kezeli
- kezelése
- piacára
- Piaci adatok
- piactér
- Massachusetts
- Massachusetts Institute of Technology
- egyező
- anyagok
- matematikai
- max
- MBA
- jelentőségteljes
- mechanikai
- gépészet
- közepes
- Memory design
- Metaadatok
- metrikus
- Metrics
- esetleg
- minimalizálása
- jegyzőkönyv
- ML
- MLOps
- modell
- modellek
- monitor
- ellenőrzés
- több
- Morgan
- SZERELJÜK
- mozog
- többszörös
- név
- Nemzetek
- bennszülött
- Természetes
- Természetes nyelv
- Természetes nyelvi feldolgozás
- elengedhetetlen
- Szükség
- szükséges
- igények
- negatív
- Új
- hír
- NLP
- csomópont
- csomópontok
- szám
- Nvidia
- felajánlás
- ONE
- nyílt forráskódú
- üzemeltetési
- ellentétes
- optimalizálás
- opció
- érdekében
- Más
- áttekintés
- Párhuzamos
- paraméter
- paraméterek
- résztvevők
- szenvedély
- ösvény
- egyenrangú
- teljesítmény
- darab
- csővezeték
- tervezés
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- hüvely
- pont
- pont
- Politikák
- medence
- pozitív
- állás
- erős
- gyakorlat
- előrejelzés
- Tippek
- be
- ajándékot
- korábban
- Áraink
- Fő
- elvek
- Előzetes
- folyamat
- feldolgozás
- termelékenység
- Termékek
- Programozás
- Haladás
- program
- megfelelően
- ad
- feltéve,
- biztosít
- ellátás
- közzétett
- Nyomja
- meglökött
- Piton
- pytorch
- véletlen
- Arány
- Nyers
- nyers adatok
- miatt
- ajánlott
- csökkenteni
- csökkentő
- vidék
- összefüggő
- eltávolítás
- eltávolítása
- Megújuló
- megújuló energia
- raktár
- kért
- megköveteli,
- kutatás
- forrás
- Tudástár
- felelős
- Eredmények
- folytatás
- Rizs
- szerepek
- nagyjából
- körül
- futás
- futás
- azonos
- San
- San Francisco
- megtakarítás
- skálázható
- Skála
- Mérleg
- skálázás
- szkriptek
- zökkenőmentes
- Keresés
- Rész
- szakaszok
- érzés
- különálló
- szolgáltatás
- Szolgáltatások
- készlet
- beállítás
- felépítés
- számos
- SGD
- szilánkos
- megosztott
- rövid időszak
- kellene
- mutatott
- Műsorok
- <p></p>
- hasonló
- Egyszerű
- egyszerűség
- egyszerűen
- egyszerre
- egyetlen
- SIX
- Méret
- méretek
- kicsit más
- So
- nap
- napenergia
- megoldások
- Megoldások
- SOLVE
- néhány
- Hely
- szakember
- különleges
- kifejezetten
- meghatározott
- költött
- Centrifugálás
- szakadások
- Spot
- verem
- Stacks
- standard
- állványok
- Stanford
- kezdet
- kezdődött
- kezdődik
- Startups
- Állami
- Lépés
- Lépései
- készlet
- részvénypiac
- tárolás
- árnyékolók
- Stratégiai
- Stratégia
- tanult
- tanulmányok
- beküldése
- alhálózati
- alhálózatok
- ilyen
- javasolja,
- Támogatott
- Támogató
- Söprés
- összehangolás
- rendszer
- Vesz
- tart
- célok
- Feladat
- feladatok
- csapat
- csapat
- Műszaki
- Technologies
- Technológia
- sablon
- Tesla
- teszt
- A
- a világ
- azok
- ezáltal
- három
- Keresztül
- áteresztőképesség
- idő
- tippek
- nak nek
- együtt
- tolerancia
- is
- szerszám
- szerszámok
- fáklya
- vágány
- Kereskedés
- Vonat
- Képzések
- transzformerek
- szállítás
- igaz
- Ikrek
- típusok
- megértés
- Egyesült
- Egyesült Nemzetek
- egyetemi
- Frissítések
- városi
- URI
- Használat
- használ
- ÉRVÉNYESÍT
- érvényesítés
- érték
- Értékek
- Megnézem
- látható
- kötet
- kötetek
- súly
- Wells
- Wells Fargo
- vajon
- ami
- míg
- lesz
- belül
- szavak
- Munka
- munkás
- dolgozók
- világ
- lenne
- yaml
- év
- A te
- zephyrnet
- zónák