A szervezetek úgy döntöttek, hogy ezekre építenek adattavakat Amazon egyszerű tárolási szolgáltatás (Amazon S3) évek óta. A Data Lake a legnépszerűbb választás a szervezetek számára, hogy tárolják a különböző csapatok által generált összes szervezeti adatot az üzleti tartományok között, minden különböző formátumból, sőt a történelem során is. Alapján Egy tanulmány, az átlagos vállalat azt tapasztalja, hogy adatainak mennyisége évente 50%-ot meghaladó mértékben növekszik, és általában átlagosan 33 egyedi adatforrást kezel elemzésre.
A csapatok gyakran több ezer feladatot próbálnak replikálni relációs adatbázisokból ugyanazzal a kivonat, átalakítás és betöltés (ETL) mintával. Sok erőfeszítést kell tenni a munkaállapotok fenntartásában és az egyes munkák ütemezésében. Ez a megközelítés segít a csapatoknak táblázatokat hozzáadni kevés változtatással, és minimális erőfeszítéssel megőrzi a munka állapotát. Ez hatalmas javuláshoz vezethet a fejlesztési ütemtervben és a feladatok könnyű nyomon követéséhez.
Ebben a bejegyzésben bemutatjuk, hogyan replikálhatja egyszerűen az összes relációs adattárát egy tranzakciós adattóba automatizált módon egyetlen ETL-feladattal az Apache Iceberg és AWS ragasztó.
Megoldás architektúra
Adattavak vannak általában szervezett három adatréteghez külön S3 gyűjtőket használ: az adatokat eredeti formában tartalmazó nyers réteg, a fogyasztásra optimalizált közbenső feldolgozott adatokat tartalmazó szakaszos réteg és az egyes felhasználási esetekre vonatkozó összesített adatokat tartalmazó analitikai réteg. A nyers rétegben a táblák rendszerint adatforrásaik alapján, míg a szakaszos réteg táblái a hozzájuk tartozó üzleti tartományok alapján vannak rendezve.
Ez a bejegyzés egy AWS felhőképződés sablon, amely egy AWS Glue-feladatot telepít, amely beolvas egy Amazon S3 elérési utat a Data Lake nyersréteg egyik adatforrásához, és feldolgozza az adatokat a színpadi réteg Apache Iceberg tábláiba AWS Glue támogatás Data Lake-keretrendszerekhez. A feladat elvárja, hogy a nyers rétegben lévő táblák a megfelelő módon legyenek strukturálva AWS adatbázis-migrációs szolgáltatás (AWS DMS) feldolgozza őket: séma, majd tábla, majd adatfájlok.
Ez a megoldás használ AWS Systems Manager Paramétertár táblázat konfigurálásához. Módosítania kell ezt a paramétert, megadva a feldolgozni kívánt táblákat és azok módját, beleértve az olyan információkat, mint az elsődleges kulcs, a partíciók és a társított üzleti tartomány. A feladat ezen információk alapján automatikusan létrehoz egy adatbázist (ha még nem létezik) minden üzleti tartományhoz, létrehozza az Iceberg táblákat, és végrehajtja az adatbetöltést.
Végül használhatjuk Amazon Athéné az Iceberg táblák adatainak lekérdezéséhez.
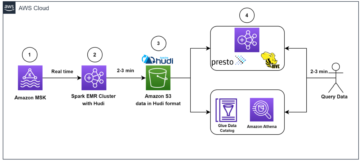
A következő diagram ezt az architektúrát szemlélteti.

Ennek a megvalósításnak a következő szempontjai vannak:
- Az adatforrásból származó összes táblának rendelkeznie kell elsődleges kulccsal, hogy ezzel a megoldással replikálható legyen. Az elsődleges kulcs lehet egyetlen oszlop, vagy több oszlopból álló összetett kulcs is.
- Ha az adattó olyan táblákat tartalmaz, amelyekhez nincs szükség feloldásokra, vagy nem rendelkeznek elsődleges kulccsal, akkor kizárhatja őket a paraméterkonfigurációból, és hagyományos ETL-folyamatokat valósíthat meg az adattóba történő bevitelükhöz. Ez kívül esik ennek a bejegyzésnek a hatókörén.
- Ha vannak további adatforrások, amelyeket be kell tölteni, több CloudFormation-vermet is telepíthet, mindegyik adatforrás kezelésére egyet.
- Az AWS Glue feladatot úgy tervezték, hogy két fázisban dolgozza fel az adatokat: a kezdeti betöltés, amely az AWS DMS teljes betöltési feladatának befejezése után fut, és a növekményes betöltés, amely az AWS DMS által rögzített változási adatrögzítési (CDC) fájlokat alkalmazó ütemezés szerint fut. A növekményes feldolgozást egy AWS ragasztó feladat könyvjelző.
Kilenc lépésből áll az oktatóanyag:
- Állítson be egy forrásvégpontot az AWS DMS-hez.
- Telepítse a megoldást az AWS CloudFormation használatával.
- Tekintse át az AWS DMS replikációs feladatát.
- Opcionálisan adjon hozzá engedélyeket a titkosításhoz és a visszafejtéshez, ill AWS-tó formáció.
- Tekintse át a táblázat konfigurációját a Paramétertárban.
- Végezze el a kezdeti adatbetöltést.
- Inkrementális adatbetöltés végrehajtása.
- Figyelje az asztal lenyelését.
- Ütemezze a növekményes kötegelt adatbetöltést.
Előfeltételek
Mielőtt elkezdené ezt az oktatóanyagot, már ismernie kell az Iceberget. Ha nem, akkor kezdheti meg egyetlen táblázat replikálásával a következő utasításokat követve Valósítson meg egy CDC-alapú UPSERT-t egy adattóban Apache Iceberg és AWS Glue segítségével. Ezenkívül állítsa be a következőket:
Állítson be egy forrásvégpontot az AWS DMS számára
Mielőtt létrehoznánk az AWS DMS feladatunkat, be kell állítanunk egy forrásvégpontot a forrásadatbázishoz való csatlakozáshoz:
- Az AWS DMS konzolon válassza a lehetőséget Végpontok a navigációs ablaktáblában.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Végpont létrehozása.
- Ha az adatbázisa Amazon RDS-en fut, válassza a lehetőséget Válassza az RDS DB példányt, majd válassza ki a példányt a listából. Ellenkező esetben válassza ki a forrásmotort, és adja meg a kapcsolati információkat vagy ezen keresztül AWS Secrets Manager vagy manuálisan.
- A Végpont azonosító, adja meg a végpont nevét; például forrás-postgresql.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Végpont létrehozása.
Telepítse a megoldást az AWS CloudFormation használatával
Hozzon létre egy CloudFormation-vermet a megadott sablon segítségével. Hajtsa végre a következő lépéseket:
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Verem indítása:

- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Következő.
- Adjon meg egy veremnevet, pl
transactionaldl-postgresql. - Adja meg a szükséges paramétereket:
- DMSS3 EndpointIAMRoleARN – Az ARN IAM szerepkör az AWS DMS számára, hogy adatokat írjon az Amazon S3-ba.
- ReplicationInstanceArn – Az AWS DMS replikációs példány ARN.
- S3BucketStage – Az adattó színpadi rétegéhez használt meglévő vödör neve.
- S3BucketGlue – Az AWS Glue szkriptek tárolására szolgáló meglévő S3-tároló neve.
- S3BucketRaw – Az adattó nyers rétegéhez használt meglévő vödör neve.
- SourceEndpointArn – A korábban létrehozott AWS DMS-végpont ARN.
- SourceName – A replikálandó adatforrás tetszőleges azonosítója (pl.
postgres). Ez az adattó (nyers réteg) S3 útvonalának meghatározására szolgál, ahol az adatok tárolásra kerülnek.
- Ne módosítsa a következő paramétereket:
- SourceS3BucketBlog – A vödör neve, ahol a biztosított AWS Glue szkript tárolva van.
- SourceS3BucketPrefix – A vödör előtag neve, ahol a biztosított AWS Glue szkript tárolva van.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Következő kétszer.
- választ Tudomásul veszem, hogy az AWS CloudFormation létrehozhat IAM-erőforrásokat egyéni névvel.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Verem létrehozása.
Körülbelül 5 perc elteltével a CloudFormation verem telepítésre kerül.
Tekintse át az AWS DMS replikációs feladatát
Az AWS CloudFormation üzembe helyezése létrehozott egy AWS DMS célvégpontot az Ön számára. A két konkrét végpont-beállítás miatt az adatok az Amazon S3-on szükség szerint kerülnek felhasználásra.
- Az AWS DMS konzolon válassza a lehetőséget Végpontok a navigációs ablaktáblában.
- Keresse meg és válassza ki a következővel kezdődő végpontot
dmsIcebergs3endpoint. - Tekintse át a végpont beállításait:
DataFormatként van megadvaparquet.TimestampColumnNamehozzáadja az oszlopotlast_update_timea rekordok Amazon S3-on történő létrehozásának dátumával.

A telepítés egy AWS DMS-replikációs feladatot is létrehoz, amely a következővel kezdődik dmsicebergtask.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Replikációs feladatok a navigációs ablakban, és keresse meg a feladatot.
Látni fogja, hogy a Feladat típusa van jelölve Teljes terhelés, folyamatos replikáció. Az AWS DMS elvégzi a meglévő adatok kezdeti teljes betöltését, majd növekményes fájlokat hoz létre a forrásadatbázis módosításaival.
A Térképezési szabályok lapon kétféle szabály létezik:
- Kiválasztási szabály a forrásséma nevével és a forrásadatbázisból feldolgozott táblákkal. Alapértelmezés szerint az előfeltételekben megadott mintaadatbázist használja,
dms_sample, és az összes % kulcsszót tartalmazó táblázat. - Két átalakítási szabály, amelyek az Amazon S3 célfájljaiban oszlopként tartalmazzák a séma nevét és a tábla nevét. Ezt használja az AWS Glue feladatunk, hogy megtudja, mely tábláknak felelnek meg az adattóban lévő fájlok.
Ha többet szeretne megtudni arról, hogyan szabhatja ezt a saját adatforrásaihoz, tekintse meg a következőt: Kiválasztási szabályok és műveletek.

Változtassunk meg néhány konfigurációt, hogy befejezzük a feladat előkészítését.
- A Hozzászólások menüben válasszon módosít.
- A Feladatbeállítások fejezet alatt A teljes betöltés befejezése után állítsa le a feladatot, választ A gyorsítótárazott módosítások alkalmazása után állítsa le.
Így két különböző lépésben tudjuk szabályozni a kezdeti betöltést és a növekményes fájlgenerálást. Ezt a kétlépéses megközelítést használjuk az AWS ragasztófeladat futtatására lépésenként egyszer.
- Alatt Feladatnaplók, választ Kapcsolja be a CloudWatch naplóit.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Megtakarítás.
- Várjon körülbelül 1 percet, amíg az adatbázis-áttelepítési feladat állapota a következőként jelenik meg: Kész.
Adjon hozzá engedélyeket a titkosításhoz és a visszafejtéshez vagy a Lake Formationhez
Opcionálisan megadhat engedélyeket a titkosításhoz és a visszafejtéshez vagy a Lake Formationhez.
Adjon hozzá titkosítási és visszafejtési engedélyeket
Ha a nyers és a színpadi rétegekhez használt S3 gyűjtők a következővel vannak titkosítva AWS kulcskezelési szolgáltatás (AWS KMS) ügyfél által kezelt kulcsok, engedélyeket kell hozzáadnia ahhoz, hogy az AWS Glue feladat hozzáférjen az adatokhoz:
Add hozzá a Lake Formation engedélyeket
Ha a Lake Formation használatával kezeli az engedélyeket, engedélyeznie kell az AWS Glue-feladatnak, hogy létrehozza a domain adatbázisait és tábláit az IAM szerepkörön keresztül. GlueJobRole.
- Engedélyek megadása adatbázisok létrehozásához (az utasításokat lásd: Adatbázis létrehozása).
- Adjon SUPER engedélyeket a
defaultadatbázisban. - Adjon meg engedélyeket az adatok helyére.
- Ha manuálisan hoz létre adatbázisokat, adjon engedélyt az összes adatbázisnak a táblák létrehozásához. Hivatkozni Táblaengedélyek megadása a Lake Formation konzol és a megnevezett erőforrás metódus használatával or Adatkatalógus-engedélyek megadása LF-TBAC módszerrel használati esetének megfelelően.
Miután befejezte a kezdeti adatbetöltés későbbi lépését, ügyeljen arra, hogy a fogyasztók számára is adjon engedélyeket a táblák lekérdezéséhez. A munkakör lesz az összes létrehozott tábla tulajdonosa, és a Data Lake adminisztrátora további felhasználóknak adhat támogatást.
Tekintse át a táblázat konfigurációját a Paramétertárban
Az Iceberg táblákba való adatfeldolgozást végrehajtó AWS Glue feladat a Paramétertárban megadott táblázatspecifikációt használja. Hajtsa végre az alábbi lépéseket az automatikusan beállított paramétertár megtekintéséhez. Ha szükséges, módosítsa saját igényei szerint.
- A Paramétertár konzolon válassza a lehetőséget Az én paramétereim a navigációs ablaktáblában.
A CloudFormation verem két paramétert hozott létre:
iceberg-configmunkakonfigurációkhoziceberg-tablestáblázat konfigurációhoz
- Válassza ki a paramétert jéghegy-asztalok.
A JSON-struktúra olyan információkat tartalmaz, amelyeket az AWS Glue használ az adatok olvasásához és az Iceberg-táblázatok írásához a céltartományon:
- Táblánként egy objektum – Az objektum neve a sémanév, egy pont és a táblanév használatával jön létre; például,
schema.table. - elsődleges kulcs – Ezt minden forrástáblánál meg kell adni. Megadhat egyetlen oszlopot vagy vesszővel elválasztott oszloplistát (szóközök nélkül).
- partícióCols – Ez opcionálisan felosztja az oszlopokat a céltáblákhoz. Ha nem szeretne particionált táblákat létrehozni, adjon meg egy üres karakterláncot. Ellenkező esetben adjon meg egyetlen oszlopot vagy a használandó oszlopok vesszővel elválasztott listáját (szóközök nélkül).
- Ha saját adatforrását szeretné használni, használja a következő JSON-kódot, és cserélje ki a szöveget CAPS betűkkel a megadott sablonból. Ha a megadott mintaadatforrást használja, tartsa meg az alapértelmezett beállításokat:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a A változtatások mentéséhez.
Végezze el a kezdeti adatbetöltést
Most, hogy a szükséges konfiguráció kész, feldolgozzuk a kezdeti adatokat. Ez a lépés három részből áll: az adatok bevitele a forrás relációs adatbázisból az adattó nyers rétegébe, az Iceberg táblák létrehozása az adattó színpadi rétegén, és az eredmények ellenőrzése az Athena használatával.
Adatok feldolgozása az adattó nyers rétegébe
Ha a relációs adatforrásból (ha a mellékelt mintát használja, a PostgreSQL-ből) szeretné feldolgozni az adatokat a tranzakciós adatforrásunkba az Iceberg segítségével, hajtsa végre a következő lépéseket:
- Az AWS DMS konzolon válassza a lehetőséget Adatbázis migrációs feladatok a navigációs ablaktáblában.
- Válassza ki a létrehozott replikációs feladatot, majd a Hozzászólások menüben válasszon Újraindítás/Folytatás.
- Várjon körülbelül 5 percet, amíg a replikációs feladat befejeződik. Nyomon követheti a bevitt táblázatokat a Statisztika a replikációs feladat lapján.

Néhány perc múlva a feladat az üzenettel befejeződik Teljes betöltés kész.
- Az Amazon S3 konzolon válassza ki a nyers rétegként megadott gyűjtőt.
Az AWS DMS-ben meghatározott S3 előtag alatt (például postgres), látnia kell a mappák hierarchiáját a következő szerkezettel:
- Séma
- Tábla neve
LOAD00000001.parquetLOAD0000000N.parquet
- Tábla neve

Ha az S3 vödör üres, ellenőrizze Áttelepítési feladatok hibaelhárítása az AWS Database Migration Service szolgáltatásban az AWS ragasztó feladat futtatása előtt.
Hozzon létre és dolgozzon fel adatokat Iceberg-táblázatokba
A feladat futtatása előtt navigáljunk a CloudFormation verem részeként biztosított AWS Glue-feladat szkriptjében, hogy megértsük a viselkedését.
- Az AWS Glue Studio konzolon válassza a lehetőséget Állások a navigációs ablaktáblában.
- Keresse meg azt a munkát, amely ezzel kezdődik
IcebergJob-és a CloudFormation verem nevének utótagja (példáulIcebergJob-transactionaldl-postgresql). - Válassza ki a munkát.

A feladatszkript megkapja a szükséges konfigurációt a Paramétertárból. A funkció getConfigFromSSM() feladattal kapcsolatos konfigurációkat ad vissza, például forrás- és célcsoportokat, ahonnan az adatokat olvasni és írni kell. A változó ssmparam_table_values táblázattal kapcsolatos információkat tartalmaznak, például az adattartományt, a tábla nevét, a partíció oszlopait és a feldolgozandó táblák elsődleges kulcsát. Lásd a következő Python kódot:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']A szkript egy tetszőleges katalógusnevet használ az Iceberghez, amely a saját_katalógus definíciója. Ez az AWS ragasztóadat-katalógusban Spark-konfigurációk használatával valósul meg, így a my_catalog-ra mutató SQL-művelet kerül alkalmazásra az adatkatalógusban. Lásd a következő kódot:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
A szkript a Parameter Store-ban definiált táblákon iterál, és végrehajtja a logikát annak észlelésére, hogy a tábla létezik-e, és hogy a bejövő adat kezdeti betöltés vagy feloldás:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')A initialLoadRecordsSparkSQL() függvény betölti a kezdeti adatokat, ha az S3 fájlokban nincs műveleti oszlop. Az AWS DMS ezt az oszlopot csak a folyamatos replikáció (CDC) által előállított Parquet adatfájlokhoz adja hozzá. Az adatok betöltése az INSERT INTO paranccsal történik a SparkSQL-lel. Lásd a következő kódot:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Most az AWS ragasztófeladatot futtatjuk, hogy a kezdeti adatokat az Iceberg táblákba töltsük be. A CloudFormation verem hozzáadja a --datalake-formats paramétert, hozzáadva a szükséges Iceberg könyvtárakat a feladathoz.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Futtassa a munkát.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Job Runs az állapot figyelésére. Várja meg az állapotot Futás Sikerült.
Ellenőrizze a betöltött adatokat
Ha meg szeretné győződni arról, hogy a munka a várt módon dolgozta fel az adatokat, hajtsa végre a következő lépéseket:
- Az Athena konzolon válassza a lehetőséget Lekérdező szerkesztő a navigációs ablaktáblában.
- Ellenőrzése
AwsDataCatalogadatforrásként van kiválasztva. - Alatt adatbázis, válassza ki a felfedezni kívánt adattartományt a paramétertárolóban megadott konfiguráció alapján. Ha a mintaadatbázist használja, használja
sports.
Alatt Táblázatok és nézetek, láthatjuk az AWS ragasztófeladat által létrehozott táblák listáját.
- Válassza ki a beállítások menüt (három pont) az első táblázat neve mellett, majd válassza a lehetőséget Adatok előnézete.
Megtekintheti az Iceberg táblákba betöltött adatokat. 
Inkrementális adatbetöltés végrehajtása
Most elkezdjük rögzíteni a változásokat a relációs adatbázisunkból, és alkalmazzuk őket a tranzakciós adattóra. Ez a lépés is három részre oszlik: a változások rögzítése, alkalmazása az Iceberg táblákra és az eredmények ellenőrzése.
Változások rögzítése a relációs adatbázisból
Az általunk megadott konfiguráció miatt a replikációs feladat leállt a teljes betöltési fázis futtatása után. Most újraindítjuk a feladatot, hogy a változtatásokat tartalmazó növekményes fájlokat adjunk hozzá az adattó nyers rétegéhez.
- Az AWS DMS konzolon válassza ki az általunk korábban létrehozott és futtatott feladatot.
- A Hozzászólások menüben válasszon Folytatás.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Indítsa el a feladatot a változások rögzítésének megkezdéséhez.
- Ha új fájlokat szeretne létrehozni az adattóban, hajtson végre beszúrásokat, frissítéseket vagy törléseket a forrásadatbázis tábláiban a preferált adatbázis-adminisztrációs eszközzel. Ha a mintaadatbázist használja, akkor a következő SQL-parancsokat futtathatja:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- Az AWS DMS feladat részleteinek oldalán válassza ki a Statisztikai táblázat lapon a rögzített változások megtekintéséhez.

- Nyissa meg az adattó nyers rétegét, és keressen egy új fájlt, amely tartalmazza a növekményes változtatásokat minden tábla előtagján belül, például a
sporting_eventelőtagot.
A rekord változtatásokkal a sporting_event táblázat úgy néz ki, mint a következő képernyőkép.

Figyeljük meg a Op oszlop elején egy frissítéssel (U). Ezenkívül a második dátum/idő érték az AWS DMS által hozzáadott vezérlőoszlop a változás rögzítésének időpontjával.

Alkalmazza a változtatásokat az Iceberg asztalokon az AWS ragasztóval
Most újra futtatjuk az AWS ragasztófeladatot, és automatikusan csak az új növekményes fájlokat dolgozza fel, mivel a feladat könyvjelzője engedélyezve van. Tekintsük át, hogyan működik.
A dedupCDCRecords() A funkció végrehajtja az adatok duplikációjának megszüntetését, mivel egyetlen rekordazonosító többszöri módosítása is rögzíthető ugyanabban az adatfájlban az Amazon S3 rendszeren. A deduplikáció a alapján történik last_update_time Az AWS DMS által hozzáadott oszlop, amely jelzi a változás rögzítésének időbélyegét. Lásd a következő Python kódot:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFA 99-es vonalon a upsertRecordsSparkSQL() függvény a kezdeti betöltéshez hasonló módon hajtja végre az upsert, de ezúttal egy SQL MERGE paranccsal.
Tekintse át az alkalmazott módosításokat
Nyissa meg az Athena konzolt, és futtasson egy lekérdezést, amely kijelöli a módosított rekordokat a forrásadatbázisban. Ha a megadott mintaadatbázist használja, használja a következő SQL-lekérdezések egyikét:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Figyelje az asztal lenyelését
Az AWS Glue feladatszkriptje egyszerű kódolású Python kivételkezelés hogy egy adott tábla feldolgozása során hibákat észleljen. A munkakönyvjelző mentésre kerül, miután minden tábla feldolgozása sikeresen befejeződött, hogy elkerülje a táblák újrafeldolgozását, ha a feladatot újra megpróbálja a hibás táblákra vonatkozóan.
A AWS parancssori interfész (AWS CLI) biztosítja a get-job-bookmark parancs az AWS Glue számára, amely betekintést nyújt a könyvjelzők állapotába minden feldolgozott táblázathoz.
- Az AWS Glue Studio konzolon válassza ki az ETL-feladatot.
- Válassza a Job Runs fület, és másolja ki a feladat futtatási azonosítóját.
- Futtassa a következő parancsot az AWS parancssori felületre hitelesített terminálon, cserélje le
<GLUE_JOB_RUN_ID>az 1. sorban a másolt értékkel. Ha a CloudFormation verem nincs elnevezvetransactionaldl-postgresql, adja meg a munkája nevét a szkript 2. sorában:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunEbben a megoldásban, ha egy táblafeldolgozás kivételt okoz, az AWS ragasztófeladat nem fog meghibásodni ennek a logikának megfelelően. Ehelyett a táblázat hozzáadódik egy tömbhöz, amely a feladat befejezése után kerül kinyomtatásra. Ebben a forgatókönyvben a feladat sikertelenként lesz megjelölve, miután megpróbálja feldolgozni a nyers adatforráson észlelt többi táblát. Így a hibamentes tábláknak nem kell megvárniuk, amíg a felhasználó azonosítja és megoldja a problémát az ütköző táblákon. A felhasználó gyorsan észlelheti azokat a feladatfuttatásokat, amelyeknél problémák merültek fel az AWS Glue-feladat futtatási állapota használatával, és azonosíthatja, hogy mely konkrét táblák okozzák a problémát a CloudWatch naplóinak segítségével.
- A feladatszkript ezt a funkciót a következő Python-kóddal valósítja meg:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')A következő képernyőkép azt mutatja, hogy a CloudWatch naplói hogyan keresik a feldolgozás során hibákat okozó táblázatokat.

Igazítva a AWS jól megtervezett Framework Data Analytics lencse Kifinomultabb ellenőrzési mechanizmusokat alkalmazhat az érintettek azonosítására és értesítésére, ha hibák jelennek meg az adatfolyamokon. Például használhat egy Amazon DynamoDB vezérlőtábla az összes hibát tartalmazó tábla és jobfuttatás tárolásához vagy használatával Amazon Simple Notification Service (Amazon SNS) a riasztásokat küldeni az üzemeltetőknek ha bizonyos kritériumok teljesülnek.
Ütemezze a növekményes kötegelt adatbetöltést
A CloudFormation verem telepít egy Amazon EventBridge szabály (alapértelmezés szerint letiltva), amely elindíthatja az AWS ragasztófeladat ütemezett futtatását. A saját ütemterv megadásához és a szabály engedélyezéséhez hajtsa végre a következő lépéseket:
- Az EventBridge konzolon válassza a lehetőséget Szabályok a navigációs ablaktáblában.
- Keresse meg azt a szabályt, amelynek előtagja a CloudFormation verem neve, majd ezt követi
JobTrigger(például,transactionaldl-postgresql-JobTrigger-randomvalue). - Válassza ki a szabályt.
- Alatt Események ütemezése, választ szerkesztése.
Az alapértelmezett ütemezés úgy van beállítva, hogy óránként aktiválódjon.
- Adja meg a feladat futtatásához szükséges ütemezést.
- Ezenkívül használhat egy EventBridge cron kifejezés kiválasztásával Finom beosztású menetrend.

- Ha befejezte a cron kifejezés beállítását, válassza a lehetőséget Következő háromszor, és végül válassza ki Frissítse a szabályt a módosítások mentéséhez.
A szabály alapértelmezés szerint le van tiltva, hogy lehetővé tegye a kezdeti adatbetöltés első futtatását.
- Aktiválja a szabályt a kiválasztással engedélyezése.
Használhatja a megfigyelés lapon megtekintheti a szabályhívásokat, vagy közvetlenül az AWS ragasztón Job Run részletek.
Következtetés
A megoldás üzembe helyezése után automatizálta a táblák feldolgozását egyetlen relációs adatforráson. A Data Lake-et központi adatplatformként használó szervezeteknek általában több, néha akár több tíz adatforrást is kezelniük kell. Emellett egyre több használati eset teszi szükségessé a szervezetek számára, hogy tranzakciós képességeket építsenek be az adattóba. Ezzel a megoldással felgyorsíthatja az ilyen képességek alkalmazását az összes relációs adatforrásban, hogy új üzleti felhasználási eseteket tegyen lehetővé, automatizálva a megvalósítási folyamatot, hogy több értéket nyerjen ki az adatokból.
A szerzőkről
 Luis Gerardo Baeza Big Data Architect az Amazon Web Services (AWS) Data Labnál. 12 éves tapasztalattal rendelkezik az egészségügyi, pénzügyi és oktatási szektorban működő szervezetek segítésében a vállalati architektúra programok, a számítási felhő és az adatelemzési képességek átvételében. Luis jelenleg Latin-Amerika szerte segíti a szervezeteket a stratégiai adatkezelési kezdeményezések felgyorsításában.
Luis Gerardo Baeza Big Data Architect az Amazon Web Services (AWS) Data Labnál. 12 éves tapasztalattal rendelkezik az egészségügyi, pénzügyi és oktatási szektorban működő szervezetek segítésében a vállalati architektúra programok, a számítási felhő és az adatelemzési képességek átvételében. Luis jelenleg Latin-Amerika szerte segíti a szervezeteket a stratégiai adatkezelési kezdeményezések felgyorsításában.
 SaiKiran Reddy Aenugu adatépítész az Amazon Web Services (AWS) Data Labnál. 10 éves tapasztalattal rendelkezik adatbetöltési, átalakítási és vizualizációs folyamatok megvalósításában. A SaiKiran jelenleg segít az észak-amerikai szervezeteknek modern adatarchitektúrák, például adattó- és adathálók átvételében. Tapasztalata van a kiskereskedelmi, légitársasági és pénzügyi szektorban.
SaiKiran Reddy Aenugu adatépítész az Amazon Web Services (AWS) Data Labnál. 10 éves tapasztalattal rendelkezik adatbetöltési, átalakítási és vizualizációs folyamatok megvalósításában. A SaiKiran jelenleg segít az észak-amerikai szervezeteknek modern adatarchitektúrák, például adattó- és adathálók átvételében. Tapasztalata van a kiskereskedelmi, légitársasági és pénzügyi szektorban.
 Narendra Merla adatépítész az Amazon Web Services (AWS) Data Labnál. 12 éves tapasztalattal rendelkezik mind a valós idejű, mind a kötegelt adatfolyamok tervezésében és gyártásában, valamint felhőalapú és helyszíni környezetekben az adatlakok építésében. A Narendra jelenleg segít az észak-amerikai szervezeteknek robusztus adatarchitektúrák felépítésében és tervezésében, és tapasztalata van a távközlési és pénzügyi szektorban.
Narendra Merla adatépítész az Amazon Web Services (AWS) Data Labnál. 12 éves tapasztalattal rendelkezik mind a valós idejű, mind a kötegelt adatfolyamok tervezésében és gyártásában, valamint felhőalapú és helyszíni környezetekben az adatlakok építésében. A Narendra jelenleg segít az észak-amerikai szervezeteknek robusztus adatarchitektúrák felépítésében és tervezésében, és tapasztalata van a távközlési és pénzügyi szektorban.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Rólunk
- gyorsul
- hozzáférés
- Szerint
- elismerni
- át
- alkalmazkodni
- hozzáadott
- További
- Ezen kívül
- Hozzáteszi
- admin
- igazgatás
- elfogadja
- Örökbefogadás
- Után
- légitársaság
- Minden termék
- már
- amazon
- Amazon Athéné
- Amazon RDS
- Az Amazon Web Services
- Amazon Web Services (AWS)
- Amerika
- elemzés
- analitika
- és a
- Angeles
- Apache
- megjelenik
- Alkalmazás
- alkalmazott
- Alkalmazása
- megközelítés
- körülbelül
- építészet
- Sor
- társult
- hitelesített
- automatizált
- Automatizált
- automatikusan
- automatizálás
- átlagos
- elkerülése érdekében
- AWS
- AWS felhőképződés
- AWS ragasztó
- alapján
- denevérek
- mert
- válik
- előtt
- Kezdet
- Nagy
- Big adatok
- épít
- építész
- Épület
- üzleti
- Kaphat
- képességek
- sapkák
- elfog
- Rögzítése
- eset
- esetek
- katalógus
- Fogás
- Okoz
- okai
- okozó
- CDC
- központi
- bizonyos
- változik
- Változások
- választás
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- választja
- választott
- felhő
- cloud computing
- kód
- Oszlop
- Oszlopok
- vállalat
- teljes
- számítástechnika
- Configuration
- konfigurációk
- megerősít
- Ellentmondó
- Csatlakozás
- kapcsolat
- megfontolások
- Konzol
- Fogyasztók
- fogyasztás
- tartalmaz
- folytatódik
- folyamatos
- ellenőrzés
- tudott
- teremt
- készítette
- teremt
- létrehozása
- teremtés
- kritériumok
- Jelenleg
- szokás
- vevő
- testre
- dátum
- Adatelemzés
- adattó
- Adatplatform
- adatbázis
- adatbázisok
- találka
- alapértelmezett
- meghatározott
- telepíteni
- telepített
- bevezetéséhez
- bevetés
- bevet
- Design
- tervezett
- tervezés
- részletek
- észlelt
- Fejlesztés
- különböző
- közvetlenül
- Tiltva
- megosztott
- Nem
- domain
- domainek
- ne
- alatt
- minden
- Korábban
- könnyen
- Oktatás
- erőfeszítés
- bármelyik
- lehetővé
- engedélyezve
- titkosított
- titkosítás
- Endpoint
- Motor
- belép
- Vállalkozás
- környezetek
- hibák
- Eter (ETH)
- Még
- Minden
- példa
- meghaladja
- Kivéve
- kivétel
- létező
- létezik
- várható
- elvárja
- tapasztalat
- feltárása
- kiterjesztések
- kivonat
- Sikertelen
- ismerős
- Divat
- Funkció
- kevés
- filé
- Fájlok
- Végül
- finanszíroz
- pénzügyi
- Találjon
- befejezni
- vezetéknév
- követ
- következő
- A fogyasztók számára
- forma
- képződés
- Keretrendszer
- ból ből
- Tele
- funkció
- generált
- generáció
- kap
- biztosít
- támogatások
- Növekvő
- fogantyú
- egészségügyi
- segít
- segít
- hierarchia
- történelem
- holding
- Hogyan
- How To
- HTML
- HTTPS
- hatalmas
- IAM
- azonosított
- azonosító
- azonosítja
- azonosítani
- végre
- végrehajtás
- végre
- végrehajtási
- munkagépek
- javulás
- in
- tartalmaz
- magában foglalja a
- Beleértve
- Bejövő
- jelzi
- egyéni
- információ
- kezdetben
- kezdeményezések
- Betétek
- Insight
- példa
- helyette
- utasítás
- Közbülső
- kérdés
- kérdések
- IT
- ismétlés
- Munka
- Állások
- json
- Tart
- Kulcs
- kulcsok
- Ismer
- labor
- tó
- latin
- latin Amerika
- réteg
- tojók
- vezet
- TANUL
- könyvtárak
- LIMIT
- vonal
- Lista
- kiszámításának
- betöltés
- terhelések
- elhelyezkedés
- néz
- MEGJELENÉS
- az
- Los Angeles
- Sok
- Fő
- fenntartja
- csinál
- sikerült
- vezetés
- menedzser
- kezelése
- kézzel
- sok
- térképészet
- megjelölt
- Menü
- megy
- üzenet
- esetleg
- elvándorlás
- minimum
- perc
- jegyzőkönyv
- modern
- módosítása
- monitor
- ellenőrzés
- több
- a legtöbb
- Legnepszerubb
- többszörös
- név
- Nevezett
- nevek
- Keresse
- Navigáció
- Szükség
- szükséges
- igények
- Új
- következő
- Északi
- Észak Amerika
- bejelentés
- szám
- tárgy
- objektumok
- ONE
- folyamatban lévő
- OP
- működés
- optimalizált
- Opciók
- szervezeti
- szervezetek
- Szervezett
- eredeti
- másképp
- kívül
- saját
- tulajdonos
- üvegtábla
- paraméter
- paraméterek
- rész
- alkatrészek
- ösvény
- Mintás
- teljesít
- előadó
- Előadja
- időszak
- engedélyek
- fázis
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- Népszerű
- állás
- postgresql
- gyakorlat
- előnyben részesített
- előfeltételek
- be
- elsődleges
- Probléma
- folyamat
- Folyamatok
- feldolgozás
- Készült
- Programok
- ad
- feltéve,
- biztosít
- Piton
- gyorsan
- emel
- Arány
- Nyers
- nyers adatok
- Olvass
- real-time
- rekord
- nyilvántartások
- cserélni
- többszörözött
- replikáció
- szükség
- kötelező
- forrás
- Tudástár
- REST
- Eredmények
- kiskereskedelem
- visszatérés
- Visszatér
- Kritika
- erős
- Szerep
- Szabály
- szabályok
- futás
- futás
- azonos
- Megtakarítás
- forgatókönyv
- menetrend
- hatálya
- szkriptek
- Keresés
- Második
- ágazatok
- látás
- kiválasztott
- kiválasztása
- kiválasztás
- különálló
- Szolgáltatások
- készlet
- beállítás
- beállítások
- kellene
- előadás
- Műsorok
- hasonló
- Egyszerű
- óta
- egyetlen
- So
- megoldások
- Megoldja
- néhány
- kifinomult
- forrás
- Források
- terek
- Szikra
- különleges
- leírás
- meghatározott
- Sport
- SQL
- verem
- Stacks
- Színpad
- érdekeltek
- kezdet
- kezdődött
- Kezdve
- kezdődik
- Államok
- statisztika
- Állapot
- Lépés
- Lépései
- megállt
- tárolás
- tárolni
- memorizált
- árnyékolók
- Stratégiai
- struktúra
- szerkesztett
- stúdió
- sikeresen
- ilyen
- szuper
- támogatás
- Systems
- táblázat
- cél
- Feladat
- feladatok
- csapat
- csapat
- távközlési
- sablon
- terminál
- A
- The Source
- azok
- ezer
- három
- Keresztül
- idő
- időrendben
- alkalommal
- időbélyeg
- nak nek
- szerszám
- felső
- Végösszeg
- Csomagkövetés
- hagyományos
- ügyleti
- Átalakítás
- Átalakítás
- kiváltó
- oktatói
- típusok
- alatt
- megért
- egyedi
- Frissítések
- Frissítés
- használ
- használati eset
- használó
- Felhasználók
- rendszerint
- érték
- ellenőrzése
- Megnézem
- megjelenítés
- kötet
- várjon
- Raktár
- háló
- webes szolgáltatások
- ami
- lesz
- belül
- nélkül
- művek
- ír
- írott
- yaml
- év
- év
- A te
- zephyrnet