Amazon SageMaker egy teljesen felügyelt gépi tanulási (ML) szolgáltatás. A SageMaker segítségével az adattudósok és fejlesztők gyorsan és egyszerűen építhetnek és taníthatnak ML-modelleket, majd közvetlenül telepíthetik azokat egy termelésre kész hosztolt környezetben. Integrált Jupyter szerzői jegyzetfüzet-példányt biztosít az adatforrásokhoz való könnyű hozzáféréshez feltárás és elemzés céljából, így nem kell szervereket kezelnie. Közösséget is biztosít ML algoritmusok amelyek úgy vannak optimalizálva, hogy hatékonyan fussanak rendkívül nagy adatokkal elosztott környezetben.
A SageMaker valós idejű következtetés ideális olyan munkaterhelésekhez, amelyek valós idejű, interaktív, alacsony késleltetésű követelményekkel rendelkeznek. A SageMaker valós idejű következtetéssel olyan REST-végpontokat telepíthet, amelyeket egy adott példánytípus támogat, bizonyos mennyiségű számítással és memóriával. A SageMaker valós idejű végpont telepítése sok ügyfél számára csak az első lépés a termelés felé vezető úton. Szeretnénk maximalizálni a végpont teljesítményét, hogy elérjük a másodpercenkénti tranzakciók (TPS) célértékét, miközben betartjuk a késleltetési követelményeket. A következtetések levonásához szükséges teljesítményoptimalizálás nagy része a megfelelő példánytípus kiválasztása és a végpont visszaszámlálása.
Ez a bejegyzés a SageMaker-végpont terhelési tesztelésének bevált gyakorlatait írja le, hogy megtalálja a megfelelő konfigurációt a példányok számához és méretéhez. Ez segíthet megértenünk a minimális kiépített példánykövetelményeket, hogy megfeleljünk késleltetési és TPS-követelményeinknek. Innentől kezdve belemerülünk abba, hogyan követheti nyomon és értheti meg a SageMaker végpont mérőszámait és teljesítményét a amazonfelhőóra mutatókat.
Először összehasonlítjuk modellünk teljesítményét egyetlen példányon, hogy azonosítsuk azt a TPS-t, amelyet elfogadható késleltetési követelményeink szerint kezelni tud. Ezután a megállapításokat extrapoláljuk, hogy eldöntsük, hány példányra van szükségünk a termelési forgalom kezeléséhez. Végül szimuláljuk a termelési szintű forgalmat, és terhelési teszteket állítunk be egy valós idejű SageMaker-végponthoz, hogy megbizonyosodjunk arról, hogy végpontunk képes kezelni a termelési szintű terhelést. A példa teljes kódkészlete az alábbiakban érhető el GitHub tárház.
A megoldás áttekintése
Ehhez a poszthoz egy előre kiképzett Átölelhető arc DistilBERT modell tól Átölelő Arc Hub. Ez a modell számos feladatot el tud végezni, de kifejezetten érzelemelemzésre és szövegosztályozásra küldünk egy hasznos terhet. Ezzel a minta hasznos teherrel 1000 TPS elérésére törekszünk.
Valós idejű végpont üzembe helyezése
Ez a bejegyzés feltételezi, hogy ismeri a modell üzembe helyezését. Hivatkozni Hozza létre a végpontot, és helyezze üzembe a modellt hogy megértsük a végpont hosztolása mögött rejlő belső dolgokat. Egyelőre gyorsan rámutathatunk erre a modellre a Hugging Face Hubban, és telepíthetünk egy valós idejű végpontot a következő kódrészlettel:
Teszteljük gyorsan végpontunkat a terhelési teszteléshez használni kívánt hasznos tehermintával:

Vegye figyelembe, hogy a végpontot singgel támogatjuk Amazon rugalmas számítási felhő (Amazon EC2) ml.m5.12xlarge típusú példány, amely 48 vCPU-t és 192 GiB memóriát tartalmaz. A vCPU-k száma jól jelzi a példány által kezelhető párhuzamosságot. Általában ajánlott a különböző példánytípusok tesztelése, hogy megbizonyosodjunk arról, hogy van olyan példányunk, amely megfelelően kihasznált erőforrásokkal rendelkezik. A SageMaker-példányok teljes listájának és a valós idejű következtetéshez tartozó számítási teljesítményüknek megtekintéséhez lásd: Amazon SageMaker árképzés.
Követendő mutatók
Mielőtt belevágnánk a terhelési tesztelésbe, elengedhetetlen annak megértése, hogy milyen mutatókat kell követni, hogy megértsük a SageMaker végpont teljesítménybeli lebontását. A CloudWatch az elsődleges naplózó eszköz, amelyet a SageMaker használ a végpont teljesítményét leíró különböző mutatók megértéséhez. Használhatja a CloudWatch naplóit a végpont-hívások hibakereséséhez; a következtetési kódban található összes naplózási és nyomtatási utasítás itt rögzítésre kerül. További információkért lásd: Hogyan működik az Amazon CloudWatch.
A CloudWatch két különböző típusú metrikát fed le a SageMaker számára: példányszintű és hívási metrikák.
Példányszintű mérőszámok
Az első figyelembe veendő paraméterkészlet a példányszintű metrikák: CPUUtilization és a MemoryUtilization (GPU-alapú példányok esetén GPUUtilization). mert CPUUtilization, először 100% feletti százalékokat láthat a CloudWatch-ben. Fontos, hogy felismerjük CPUUtilization, az összes CPU mag összege jelenik meg. Például, ha a végpont mögötti példány 4 vCPU-t tartalmaz, ez azt jelenti, hogy a kihasználtság 400%-ig terjed. MemoryUtilization, másrészt a 0-100% tartományba esik.
Konkrétan használhatod CPUUtilization hogy mélyebben megértse, elegendő vagy akár túl sok hardverrel rendelkezik. Ha van egy alulkihasznált példánya (kevesebb mint 30%), akkor csökkentheti a példány típusát. Ezzel szemben, ha a kihasználtság körülbelül 80–90%, akkor előnyös lenne egy nagyobb számítási/memóriájú példányt választani. Tesztjeink alapján a hardver körülbelül 60-70%-os kihasználtságát javasoljuk.
Meghívási mérőszámok
Ahogy a név is sugallja, a hívási metrikák azok, amelyekben nyomon követhetjük a végponthoz érkezett bármely hívás végpontok közötti késését. A hívási metrikák segítségével rögzítheti a hibaszámot, és rögzítheti, hogy a végpontja milyen típusú hibákat (5xx, 4xx és így tovább) tapasztalhat. Ennél is fontosabb, hogy megértheti a végponthívások késleltetési bontását. Ezzel sok mindent meg lehet fogni ModelLatency és a OverheadLatency mérőszámokat, amint azt a következő diagram mutatja.

A ModelLatency A metrika azt az időt rögzíti, amely a SageMaker-végpont mögötti modelltárolón belül eltelik a következtetést. Vegye figyelembe, hogy a modelltároló minden egyéni következtetési kódot vagy szkripteket is tartalmaz, amelyeket a következtetéshez adott. Ezt az egységet a rendszer mikroszekundumokban rögzíti hívási mérőszámként, és általában a CloudWatch (p99, p90 és így tovább) százalékos értékét ábrázolja, hogy megtudja, eléri-e a megcélzott késleltetést. Vegye figyelembe, hogy számos tényező befolyásolhatja a modell és a tároló késését, például a következők:
- Egyéni következtetési szkript – Függetlenül attól, hogy saját tárolót implementált, vagy SageMaker-alapú tárolót használt egyéni következtetéskezelőkkel, a legjobb gyakorlat a szkript profilozása, hogy elkapja azokat a műveleteket, amelyek kifejezetten megnövelik a várakozási időt.
- Kommunikációs protokoll – Fontolja meg a REST vs. gRPC kapcsolatokat a modellkiszolgálóval a modelltárolón belül.
- Modell keretrendszer optimalizálása – Ez keretspecifikus, pl TensorFlow, számos olyan környezeti változót hangolhat, amelyek TF-szolgáltatásspecifikusak. Ügyeljen arra, hogy ellenőrizze, milyen tárolót használ, és van-e olyan keretspecifikus optimalizálás, amelyet hozzáadhat a szkripten belül vagy környezeti változóként a tárolóba.
OverheadLatency a mérés attól az időponttól kezdődik, amikor a SageMaker megkapja a kérést, amíg az választ nem ad vissza az ügyfélnek, levonva a modell késleltetését. Ez a rész nagyrészt az Ön ellenőrzésén kívül esik, és a SageMaker rezsiköltségeinek ideje alá esik.
A végpontok közötti késleltetés egésze számos tényezőtől függ, és nem feltétlenül ezek összege ModelLatency plusz OverheadLatency. Például, ha az Ön ügyfele a InvokeEndpoint API-hívás az interneten keresztül, az ügyfél szemszögéből a végpontok közötti késleltetés internet + lenne ModelLatency + OverheadLatency. Ezért a végpont terheléses tesztelésekor magának a végpontnak a pontos összehasonlítása érdekében ajánlatos a végponti mérőszámokra összpontosítani (ModelLatency, OverheadLatencyés InvocationsPerInstance) a SageMaker végpont pontos összehasonlításához. A végpontok közötti késleltetéssel kapcsolatos problémák ezután külön elkülöníthetők.
Néhány megfontolandó kérdés a végpontok közötti késleltetéshez:
- Hol van a végpontját hívó ügyfél?
- Vannak közvetítő rétegek az ügyfél és a SageMaker futási környezet között?
Automatikus méretezés
Ebben a bejegyzésben nem foglalkozunk kifejezetten az automatikus méretezéssel, de ez fontos szempont a munkaterhelés alapján megfelelő számú példány biztosítása érdekében. A forgalmi mintáktól függően csatolhat egy automatikus méretezési szabályzat a SageMaker végpontjához. Különféle méretezési lehetőségek vannak, mint pl TargetTrackingScaling, SimpleScalingés StepScaling. Ez lehetővé teszi, hogy a végpont automatikusan be- és kicsinyítse a forgalmi mintázat alapján.
Gyakori lehetőség a célkövetés, ahol megadhat egy CloudWatch-mutatót vagy egyéni mérőszámot, amelyet definiált, és ez alapján méretezhet. Az automatikus méretezés gyakori használata követi a InvocationsPerInstance metrikus. Miután azonosított egy szűk keresztmetszetet egy bizonyos TPS-nél, gyakran használhatja ezt mérőszámként, hogy nagyobb számú példányra skálázzon, hogy képes legyen kezelni a forgalom csúcsterhelését. Az automatikus skálázás SageMaker végpontjainak részletesebb lebontásához tekintse meg a következőt: Automatikus skálázási következtetési végpontok konfigurálása az Amazon SageMakerben.
Terhelési tesztelés
Noha a Locust használjuk annak megjelenítésére, hogyan tölthetjük be a tesztet nagyarányúan, ha a végpont mögötti példányt próbálja megfelelő méretre állítani, SageMaker Inference Recommender hatékonyabb lehetőség. Harmadik féltől származó terhelési tesztelő eszközökkel manuálisan kell telepítenie a végpontokat a különböző példányokon. Az Inference Recommender segítségével egyszerűen átadhatja azoknak a példánytípusoknak a tömbjét, amelyekkel szemben tesztet szeretne betölteni, és a SageMaker felpörög. munkahelyek ezen esetek mindegyikére.
Sáska
Ebben a példában használjuk Sáska, egy nyílt forráskódú terheléstesztelő eszköz, amelyet a Python használatával valósíthat meg. A Locust hasonló sok más nyílt forráskódú terheléstesztelő eszközhöz, de van néhány konkrét előnye:
- Egyszerű beállítás – Amint azt ebben a bejegyzésben bemutatjuk, egy egyszerű Python-szkriptet adunk át, amely könnyen átstrukturálható az adott végponthoz és hasznos terheléshez.
- Elosztott és méretezhető – A Locust eseményalapú és hasznosítható gevent a motorháztető alatt. Ez nagyon hasznos nagyon egyidejű munkaterhelések teszteléséhez és több ezer párhuzamos felhasználó szimulálásához. Magas TPS-t érhet el egyetlen Locust futtató folyamattal, de rendelkezik a elosztott terhelés generálása Ez a funkció lehetővé teszi, hogy több folyamatra és ügyfélgépre skálázható, amint azt ebben a bejegyzésben megvizsgáljuk.
- Sáska-metrikák és felhasználói felület – A Locust a végpontok közötti késést is rögzíti mérőszámként. Ez segíthet a CloudWatch-mutatók kiegészítésében, hogy teljes képet festhessen a tesztekről. Mindezt a Locust UI rögzíti, ahol nyomon követheti az egyidejű felhasználókat, dolgozókat és egyebeket.
A Locust további megértéséhez nézze meg őket dokumentáció.
Amazon EC2 beállítás
A Locust bármilyen kompatibilis környezetben beállíthatja. Ehhez a bejegyzéshez beállítunk egy EC2-példányt, és telepítjük oda a Locust a tesztek elvégzéséhez. C5.18xlarge EC2 példányt használunk. Az ügyféloldali számítási teljesítményt is figyelembe kell venni. Időnként, amikor elfogy a számítási teljesítmény az ügyféloldalon, ez gyakran nem kerül rögzítésre, és összetéveszthető SageMaker végponti hibának. Fontos, hogy az ügyfél megfelelő számítási teljesítményű helyre kerüljön, amely képes kezelni a tesztelt terhelést. EC2-példányunkhoz Ubuntu Deep Learning AMI-t használunk, de bármilyen AMI-t használhatunk, amennyiben megfelelően be tudja állítani a Locustot a gépen. Az EC2-példány elindításának és csatlakozásának megértéséhez tekintse meg az oktatóanyagot Kezdje el az Amazon EC2 Linux példányait.
A Locust UI a 8089-es porton keresztül érhető el. Ezt úgy nyithatjuk meg, hogy módosítjuk a bejövő biztonsági csoport szabályait az EC2 példányhoz. Megnyitjuk a 22-es portot is, hogy SSH-t tudjunk bevinni az EC2 példányba. Fontolja meg a forrás hatókörét arra az IP-címre, amelyről az EC2-példányt eléri.

Miután csatlakozott az EC2 példányához, beállítunk egy Python virtuális környezetet, és telepítjük a nyílt forráskódú Locust API-t a CLI-n keresztül:
Most már készen állunk arra, hogy együttműködjünk a Locusttal a végpontunk terhelési tesztelésében.
Sáska vizsgálat
Az összes Locust terhelési tesztet az a Sáska fájl hogy biztosítod. Ez a Locust fájl meghatároz egy feladatot a terhelési teszthez; itt határozzuk meg a Boto3-unkat invoke_endpoint API hívás. Lásd a következő kódot:
Az előző kódban állítsa be a meghívási végpont hívás paramétereit az adott modellhívásnak megfelelően. Használjuk a InvokeEndpoint API a következő kódrészletet használja a Locust fájlban; ez a terhelési tesztfutási pontunk. Az általunk használt Locust fájl locust_script.py.
Most, hogy készen áll a Locust-szkriptünk, elosztott Locust-teszteket akarunk futtatni, hogy stressz-teszttel tesztelhessük egyetlen példányunkat, hogy megtudjuk, mekkora forgalmat képes kezelni példányunk.
A Locust elosztott mód egy kicsit árnyaltabb, mint az egyfolyamatos Locust teszt. Elosztott módban egy elsődleges és több dolgozónk van. Az elsődleges dolgozó utasítja a dolgozókat a kérést küldő egyidejű felhasználók létrehozására és vezérlésére. Miénkben terjesztett.sh script, alapértelmezés szerint azt látjuk, hogy 240 felhasználó lesz elosztva a 60 dolgozó között. Vegye figyelembe, hogy a --headless jelző a Locust CLI-ben eltávolítja a Locust felhasználói felület funkcióját.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Először futtatjuk az elosztott tesztet a végpontot támogató egyetlen példányon. Az ötlet az, hogy teljes mértékben maximalizálni akarunk egyetlen példányt, hogy megértsük a cél TPS eléréséhez szükséges példányszámot, miközben a késleltetési követelményeinken belül maradunk. Vegye figyelembe, hogy ha hozzá szeretne férni a felhasználói felülethez, módosítsa a Locust_UI környezeti változó True értékre, és vegye át az EC2-példány nyilvános IP-címét, és rendelje hozzá a 8089-es portot az URL-hez.
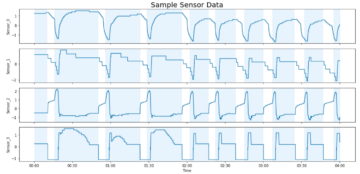
A következő képernyőkép a CloudWatch mérőszámainkat mutatja.

Végül észrevesszük, hogy bár kezdetben 200-as TPS-t értünk el, 5xx hibákat kezdünk észrevenni az EC2 kliensoldali naplóinkban, amint az a következő képernyőképen látható.
Ezt úgy is ellenőrizhetjük, ha megnézzük a példányszintű mérőszámainkat CPUUtilization.
 Itt vesszük észre
Itt vesszük észre CPUUtilization közel 4,800%-on. Az ml.m5.12x.large példányunk 48 vCPU-val rendelkezik (48 * 100 = 4800 ~). Ez telíti az egész példányt, ami szintén segít megmagyarázni az 5xx hibáinkat. Növekedést is látunk ModelLatency.
Úgy tűnik, hogy egyetlen példányunk felborul, és nincs meg a számítási módja, hogy elviselje a megfigyelt 200 TPS feletti terhelést. A cél TPS-ünk 1000, ezért próbáljuk meg 5-re növelni a példányszámunkat. Éles környezetben ennek még többnek kell lennie, mert egy bizonyos pont után 200 TPS-nél észleltünk hibákat.

Mind a Locust UI, mind a CloudWatch naplóiban azt látjuk, hogy közel 1000-es TPS-ünk van, és öt példány támogatja a végpontot.

 Ha még ezzel a hardverbeállítással is hibákat tapasztal, ügyeljen a figyelésre
Ha még ezzel a hardverbeállítással is hibákat tapasztal, ügyeljen a figyelésre CPUUtilization hogy megértse a végpont-tárhely mögötti teljes képet. Alapvető fontosságú, hogy megértse a hardverhasználatot, hogy megtudja, fel kell-e léptetnie vagy akár le is kell lépnie. Néha a tárolószintű problémák 5xx hibákhoz vezetnek, de ha CPUUtilization alacsony, ez azt jelzi, hogy nem a hardver, hanem valami a tároló vagy a modell szintjén okozhatja ezeket a problémákat (például nincs beállítva megfelelő környezeti változó a dolgozók számára). Másrészt, ha azt észleli, hogy a példánya teljesen telítődik, ez annak a jele, hogy vagy növelnie kell az aktuális példányflottát, vagy ki kell próbálnia egy nagyobb példányt egy kisebb flottával.
Bár a példányszámot 5-re növeltük a 100 TPS kezeléséhez, láthatjuk, hogy a ModelLatency a mérőszám még mindig magas. Ennek oka az esetek telítettsége. Általában azt javasoljuk, hogy a példány erőforrásait 60-70% között használja ki.
Tisztítsuk meg
A terhelési tesztelés után győződjön meg arról, hogy a SageMaker konzolon vagy a delete_endpoint Boto3 API hívás. Ezenkívül ügyeljen arra, hogy leállítsa az EC2-példányt vagy bármilyen más kliens beállítását, hogy ne számítson fel további költségeket.
Összegzésként
Ebben a bejegyzésben leírtuk, hogyan töltheti be a SageMaker valós idejű végpontját. Azt is megbeszéltük, hogy milyen mutatókat kell értékelnie a végpont terhelési tesztelésekor, hogy megértse a teljesítmény lebontását. Mindenképpen nézd meg SageMaker Inference Recommender hogy jobban megértsük a példányok megfelelő méretezését és több teljesítményoptimalizálási technikát.
A szerzőkről
 Marc Karp ML építész a SageMaker Service csapatánál. Arra összpontosít, hogy segítse az ügyfeleket az ML-munkaterhelések nagyszabású tervezésében, telepítésében és kezelésében. Szabadidejében szívesen utazik és új helyeket fedez fel.
Marc Karp ML építész a SageMaker Service csapatánál. Arra összpontosít, hogy segítse az ügyfeleket az ML-munkaterhelések nagyszabású tervezésében, telepítésében és kezelésében. Szabadidejében szívesen utazik és új helyeket fedez fel.
 Ram Vegiraju ML építész a SageMaker Service csapatánál. Arra összpontosít, hogy segítse ügyfeleit AI/ML megoldásaik kiépítésében és optimalizálásában az Amazon SageMakeren. Szabadidejében szeret utazni és írni.
Ram Vegiraju ML építész a SageMaker Service csapatánál. Arra összpontosít, hogy segítse ügyfeleit AI/ML megoldásaik kiépítésében és optimalizálásában az Amazon SageMakeren. Szabadidejében szeret utazni és írni.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- Képes
- felett
- elfogadható
- hozzáférés
- hozzáférhető
- Hozzáférés
- pontosan
- Elérése
- át
- mellett
- cím
- Után
- ellen
- AI / ML
- Célzás
- Minden termék
- lehetővé teszi, hogy
- Bár
- amazon
- Amazon EC2
- Amazon SageMaker
- összeg
- elemzés
- és a
- api
- körül
- Sor
- csatolja
- szerző
- auto
- automatikusan
- elérhető
- AWS
- vissza
- háttal ellátott
- támogatás
- alapján
- mert
- mögött
- hogy
- benchmark
- haszon
- Előnyök
- BEST
- legjobb gyakorlatok
- között
- test
- Bontás
- épít
- C + +
- hívás
- kéri
- Kaphat
- elfog
- fogások
- Fogás
- bizonyos
- változik
- díjak
- ellenőrizze
- osztály
- besorolás
- vásárló
- kód
- Közös
- összeegyeztethető
- Kiszámít
- egyidejű
- Magatartás
- Configuration
- megerősít
- Csatlakozás
- összefüggő
- kapcsolatok
- Fontolja
- megfontolás
- Konzol
- Konténer
- tartalmaz
- kontextus
- ellenőrzés
- Megfelelő
- tudott
- terjed
- burkolatok
- CPU
- teremt
- kritikus
- Jelenlegi
- szokás
- Ügyfelek
- dátum
- mély
- mély tanulás
- mélyebb
- alapértelmezett
- Annak meghatározása,
- bizonyítani
- attól
- függ
- telepíteni
- bevezetéséhez
- leírni
- leírt
- Design
- fejlesztők
- különböző
- közvetlenül
- tárgyalt
- kijelző
- megosztott
- Nem
- ne
- le-
- minden
- könnyen
- hatékony
- eredményesen
- bármelyik
- lehetővé teszi
- végtől végig
- Endpoint
- Egész
- Környezet
- hiba
- hibák
- alapvető
- Eter (ETH)
- Még
- példa
- kivétel
- kivégez
- tapasztal
- Magyarázza
- kutatás
- feltárása
- Feltárása
- export
- rendkívüli módon
- Arc
- tényezők
- Vízesés
- ismerős
- Funkció
- kevés
- filé
- Végül
- Találjon
- vezetéknév
- FLOTTA
- Összpontosít
- koncentrál
- következő
- formátum
- Keretrendszer
- gyakori
- ból ből
- Tele
- teljesen
- további
- általános
- általában
- kap
- szerzés
- jó
- grafikon
- nagyobb
- Csoport
- Csoportok
- fogantyú
- boldog
- hardver
- segít
- segít
- segít
- itt
- Magas
- nagyon
- motorháztető
- vendéglátó
- házigazdája
- tárhely
- Hogyan
- How To
- HTML
- HTTPS
- Kerékagy
- ötlet
- ideális
- azonosított
- azonosítani
- Hatás
- végre
- végre
- importál
- fontos
- in
- magában foglalja a
- Növelje
- <p></p>
- jelzi
- jelzés
- információ
- alapvetően
- telepíteni
- példa
- integrált
- interaktív
- Internet
- behívja
- IP
- IP-cím
- izolált
- kérdések
- IT
- maga
- json
- nagy
- nagymértékben
- nagyobb
- Késleltetés
- indít
- tojók
- vezet
- vezető
- tanulás
- szint
- linux
- Lista
- kis
- kiszámításának
- terhelések
- elhelyezkedés
- Hosszú
- keres
- Sok
- Elő/Utó
- gép
- gépi tanulás
- gép
- csinál
- Gyártás
- kezelése
- sikerült
- kézzel
- sok
- térkép
- Maximize
- eszközök
- Találkozik
- találkozó
- Memory design
- metrikus
- Metrics
- esetleg
- minimum
- ML
- Mód
- modell
- modellek
- monitor
- több
- hatékonyabb
- többszörös
- név
- közel
- szükségszerűen
- Szükség
- Új
- jegyzetfüzet
- szám
- ONE
- nyitva
- nyílt forráskódú
- Művelet
- optimalizálás
- Optimalizálja
- optimalizált
- opció
- Opciók
- érdekében
- Más
- kívül
- saját
- festék
- paraméterek
- rész
- Elmúlt
- múlt
- ösvény
- Mintás
- minták
- Csúcs
- teljesít
- teljesítmény
- perspektíva
- vedd
- kép
- darab
- Hely
- Helyek
- Plató
- Platón adatintelligencia
- PlatoData
- plusz
- pont
- állás
- potenciálisan
- hatalom
- gyakorlat
- gyakorlat
- Predictor
- elsődleges
- problémák
- folyamat
- Folyamatok
- Termelés
- profil
- megfelelő
- megfelelően
- ad
- biztosít
- ellátás
- nyilvános
- Piton
- Kérdések
- gyorsan
- hatótávolság
- kész
- real-time
- észre
- kap
- ajánlott
- vidék
- összefüggő
- kérni
- követelmények
- Tudástár
- válasz
- REST
- eredményez
- Eredmények
- Visszatér
- szabályok
- futás
- futás
- sagemaker
- SageMaker következtetés
- Skála
- skálázás
- tudósok
- Hatókör
- szkriptek
- Második
- biztonság
- Úgy tűnik,
- MAGA
- elküldés
- érzés
- szolgáltatás
- szolgáló
- készlet
- beállítás
- beállítások
- felépítés
- számos
- kellene
- mutatott
- Műsorok
- <p></p>
- hasonló
- Egyszerű
- egyszerűen
- egyetlen
- Méret
- kisebb
- So
- Megoldások
- valami
- forrás
- Források
- Ívik
- különleges
- kifejezetten
- Centrifugálás
- standard
- kezdet
- kezdődött
- nyilatkozatok
- Lépés
- Még mindig
- megáll
- feszültség
- törekszünk
- ilyen
- elegendő
- Öltöny
- szuper
- kiegészítés
- Vesz
- tart
- cél
- Feladat
- feladatok
- csapat
- technikák
- teszt
- Tesztfutás
- Tesztelés
- tesztek
- Szöveg osztályozása
- A
- The Source
- azok
- harmadik fél
- ezer
- Keresztül
- idő
- alkalommal
- nak nek
- szerszám
- szerszámok
- idő
- vágány
- Csomagkövetés
- forgalom
- Vonat
- Tranzakciók
- Utazó
- igaz
- oktatói
- típusok
- Ubuntu
- ui
- alatt
- megért
- megértés
- egység
- URL
- us
- használ
- Felhasználók
- hasznosít
- hasznosított
- hasznosítja
- kihasználva
- fajta
- ellenőrzése
- keresztül
- Tényleges
- Mit
- vajon
- ami
- míg
- lesz
- belül
- Munka
- munkás
- dolgozók
- lenne
- írás
- A te
- zephyrnet