Az a képesség, hogy előre jelezhető, hogy egy adott ügyfélnél nagy a lemorzsolódás kockázata, miközben még van idő tenni valamit ellene, hatalmas potenciális bevételi forrást jelent minden online vállalkozás számára. Az iparágtól és az üzleti céltól függően a problémameghatározás többrétegű lehet. A következő néhány üzleti cél ezen a stratégián alapul:
Ez a bejegyzés azt taglalja, hogyan alakíthat ki egy végponttól végpontig lemorzsolódás-előrejelzési modellt az egyes lépésekben: adat-előkészítés, kísérletezés egy alapmodellel és hiperparaméter-optimalizálással (HPO), betanítás és hangolás, valamint a legjobb modell regisztrálása. Kezelheti a sajátját Amazon SageMaker képzési és következtetési munkafolyamatok segítségével Amazon SageMaker Studio és a SageMaker Python SDK. A SageMaker minden eszközt kínál a kiváló minőségű adattudományi megoldások létrehozásához.
A SageMaker segít az adattudósoknak és fejlesztőknek kiváló minőségű gépi tanulási (ML) modellek gyors előkészítésében, létrehozásában, betanításában és üzembe helyezésében azáltal, hogy az ML-hez tervezett képességek széles körét egyesíti.
A Studio egyetlen, webalapú vizuális felületet biztosít, ahol elvégezheti az összes ML fejlesztési lépést, akár 10-szeresére növelve az adattudományi csapatok termelékenységét.
Amazon SageMaker csővezetékek egy olyan eszköz ML-folyamatok építésére, amely kihasználja a közvetlen SageMaker integrációt. A Pipelines segítségével egyszerűen automatizálhatja az ML-modell felépítésének lépéseit, a katalógusmodelleket a modellnyilvántartásban, és használhatja a SageMaker Projectsben található sablonok egyikét a folyamatos integráció és a folyamatos szállítás (CI/CD) beállításához a végponthoz. -vége az ML életciklusának méretarányosan.
A modell betanítása után használhatja Amazon SageMaker Clarify az elfogultság azonosítása és korlátozása, valamint az előrejelzések magyarázata az üzleti érdekelt felek számára. Ezeket az automatizált jelentéseket megoszthatja üzleti és műszaki csapatokkal a későbbi célkampányokhoz, vagy meghatározhatja azokat a funkciókat, amelyek kulcsfontosságúak az ügyfelek élettartama szempontjából.
Ennek a bejegyzésnek a végére elegendő információval kell rendelkeznie ahhoz, hogy sikeresen használja ezt a végpontok közötti sablont a Pipelines segítségével a saját prediktív elemzési használati esetének betanításához, hangolásához és üzembe helyezéséhez. A teljes útmutató elérhető a GitHub repo.
Ebben a megoldásban a belépési pont a Studio integrált fejlesztői környezete (IDE) a gyors kísérletezéshez. A Studio olyan környezetet kínál, amely a végpontok közötti Pipelines-élményt kezeli. A Studio segítségével megkerülheti a AWS felügyeleti konzol a teljes munkafolyamat-kezeléshez. A Pipeline-ok Studio-ból történő kezelésével kapcsolatos további információkért lásd: Tekintse meg, kövesse nyomon és hajtsa végre a SageMaker-folyamatokat a SageMaker Studio-ban.
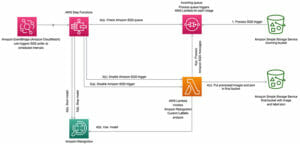
A következő diagram az adattudományi munkafolyamat magas szintű architektúráját mutatja be.
A Studio tartomány létrehozása után válassza ki a felhasználónevét, és válassza ki OpenStudio. Megnyílik egy webalapú IDE, amely lehetővé teszi az összes szükséges dolog tárolását és összegyűjtését – legyen szó kódról, jegyzetfüzetekről, adatkészletekről, beállításokról vagy projektmappákról.
A Pipelines közvetlenül integrálva van a SageMakerrel, így nem kell kölcsönhatásba lépnie semmilyen más AWS-szolgáltatással. Ezenkívül nem kell semmilyen erőforrást kezelnie, mert a Pipelines egy teljesen felügyelt szolgáltatás, ami azt jelenti, hogy erőforrásokat hoz létre és kezel az Ön számára. További információért a különböző SageMaker összetevőkről, amelyek mind önálló Python API-k, mind a Studio integrált összetevői, tekintse meg a SageMaker szolgáltatási oldal.
Ebben az esetben a következő összetevőket használja a teljesen automatizált modellfejlesztési folyamathoz:
A SageMaker-folyamat egymással összekapcsolt lépések sorozata, amelyeket egy JSON-folyamat definíció határoz meg. Ez a folyamatdefiníció irányított aciklikus gráf (DAG) segítségével kódol egy folyamatot. Ez a DAG tájékoztatást ad a folyamat egyes lépéseire vonatkozó követelményekről és azok közötti kapcsolatokról. A folyamat DAG szerkezetét a lépések közötti adatfüggőségek határozzák meg. Ezek az adatfüggőségek akkor jönnek létre, amikor egy lépés kimenetének tulajdonságait egy másik lépés bemeneteként adják át.
Ebben a bejegyzésben a használati esetünk egy klasszikus ML probléma, amelynek célja annak megértése, hogy a fogyasztói magatartáson alapuló különféle marketingstratégiákat alkalmazhatunk egy adott kiskereskedelmi üzlet vásárlói megtartásának növelésére. A következő diagram a teljes ML munkafolyamatot szemlélteti a lemorzsolódás előrejelzésének használati esetéhez.
Nézzük meg részletesen a gyorsított ML munkafolyamat-fejlesztési folyamatot.
A bejegyzés követéséhez le kell töltenie és el kell mentenie a minta adatkészlet alapértelmezetten Amazon egyszerű tárolási szolgáltatás (Amazon S3) tároló, amely a SageMaker munkamenethez van társítva, és az Ön által választott S3 tárolóban. A gyors kísérletezéshez vagy az alapmodell-építéshez elmentheti az adatkészlet másolatát a saját könyvtárába Amazon elasztikus fájlrendszer (Amazon EFS), és kövesse a Jupyter notebookot Customer_Churn_Modeling.ipynb.
A következő képernyőképen látható a mintakészlet, amelynek célváltozója megtartott 1, ha feltételezzük, hogy az ügyfél aktív, vagy 0 egyébként.
Futtassa a következő kódot egy Studio notebookban az adatkészlet előfeldolgozásához, és töltse fel a saját S3 tárolójába:
import boto3
import pandas as pd
import numpy as np ## Preprocess the dataset
def preprocess_data(file_path): df = pd.read_csv(file_path) ## Convert to datetime columns df["firstorder"]=pd.to_datetime(df["firstorder"],errors='coerce') df["lastorder"] = pd.to_datetime(df["lastorder"],errors='coerce') ## Drop Rows with null values df = df.dropna() ## Create Column which gives the days between the last order and the first order df["first_last_days_diff"] = (df['lastorder']-df['firstorder']).dt.days ## Create Column which gives the days between when the customer record was created and the first order df['created'] = pd.to_datetime(df['created']) df['created_first_days_diff']=(df['created']-df['firstorder']).dt.days ## Drop Columns df.drop(['custid','created','firstorder','lastorder'],axis=1,inplace=True) ## Apply one hot encoding on favday and city columns df = pd.get_dummies(df,prefix=['favday','city'],columns=['favday','city']) return df ## Set the required configurations
model_name = "churn_model"
env = "dev"
## S3 Bucket
default_bucket = "customer-churn-sm-pipeline"
## Preprocess the dataset
storedata = preprocess_data(f"s3://{default_bucket}/data/storedata_total.csv")A rugalmas számítási funkcióval rendelkező Studio noteszgépekkel most könnyedén futtathat több képzési és hangolási feladatot. Ebben az esetben használja a SageMaker beépített XGBoost algoritmust és a SageMaker HPO-t célfüggvénnyel, mint "binary:logistic" és a "eval_metric":"auc".
def split_datasets(df): y=df.pop("retained") X_pre = df y_pre = y.to_numpy().reshape(len(y),1) feature_names = list(X_pre.columns) X= np.concatenate((y_pre,X_pre),axis=1) np.random.shuffle(X) train,validation,test=np.split(X,[int(.7*len(X)),int(.85*len(X))]) return feature_names,train,validation,test # Split dataset
feature_names,train,validation,test = split_datasets(storedata) # Save datasets in Amazon S3
pd.DataFrame(train).to_csv(f"s3://{default_bucket}/data/train/train.csv",header=False,index=False)
pd.DataFrame(validation).to_csv(f"s3://{default_bucket}/data/validation/validation.csv",header=False,index=False)
pd.DataFrame(test).to_csv(f"s3://{default_bucket}/data/test/test.csv",header=False,index=False)
Tanuljon, hangoljon és találja meg a legjobb jelölt modellt a következő kóddal:

Miután megállapította az alapvonalat, használhatja Amazon SageMaker Debugger offline modellelemzéshez. A Debugger a SageMaker egy olyan képessége, amely automatikusan betekintést nyújt a modell betanítási folyamatába valós idejű és offline elemzéshez. A Debugger rendszeres időközönként elmenti a belső modell állapotát, amelyet valós időben elemezhet edzés közben, illetve offline módban a képzés befejezése után. Ebben a használati esetben használja a SHAP (SHapley Additive ExPlanation) magyarázhatósági eszközt és az SHAP és a Debugger natív integrációját. Lásd a következőket jegyzetfüzet részletes elemzéshez.
Az alábbi összefoglaló diagram megmagyarázza a prediktorok pozitív és negatív kapcsolatait a célváltozóval. Például a legfelső változó itt, esent, az elküldött e-mailek száma. Ez a diagram a képzési halmaz összes adatpontját tartalmazza. A kék azt jelzi, hogy a végső kimenetet a 0. osztályba kell húzni, a rózsaszín pedig az 1. osztályt. A legfontosabb befolyásoló jellemzők csökkenő sorrendben vannak rangsorolva.

Most folytathatja az ML munkafolyamat telepítési és kezelési lépését.
A munkafolyamat fejlesztése és automatizálása
Kezdjük a projekt felépítésével:
- /customer-churn-modell - Projekt neve
- /adat – Adatkészlet
- /csővezetékek – A SageMaker csővezeték-összetevők kódja
- SageMaker_Pipelines_project.ipynb – Lehetővé teszi az ML munkafolyamat létrehozását és futtatását
- Customer_Churn_Modeling.ipynb – Alapmodell-fejlesztési jegyzetfüzet

Alatt <project-name>/pipelines/customerchurn, a következő Python-szkripteket láthatja:
- Preprocess.py – Integrálható a SageMaker Processing-el a funkciótervezés érdekében
- Evaluate.py – Lehetővé teszi a modellmetrikák számítását, ebben az esetben az auc_score
- Generate_config.py – Lehetővé teszi a későbbi Clarify feladathoz szükséges dinamikus konfigurációt a modell magyarázhatósága érdekében
- Pipeline.py – Sablonozott kód a Pipelines ML munkafolyamathoz

Nézzük végig a DAG minden lépését és azt, hogyan futnak. A lépések hasonlóak az adatok első elkészítéséhez.
Végezze el az adatok készenlétét a következő kóddal:
Tanuljon, hangoljon és találja meg a legjobb jelölt modellt:
Hozzáadhat egy modellhangolási lépés (TuningStep) folyamatban, amely automatikusan meghív egy hiperparaméter-hangolási feladatot (lásd a következő kódot). A hiperparaméter-hangolás úgy találja meg a modell legjobb verzióját, hogy számos betanítási feladatot futtat az adatkészleten a megadott algoritmus és hiperparaméter-tartományok használatával. Ezután a RegisterModel lépéssel regisztrálhatja a modell legjobb verzióját a modellnyilvántartásba.

A modell hangolása után, a hangolási feladat célkitűzéseitől függően, elágazási logikát használhat a munkafolyamat összehangolásakor. Ennél a bejegyzésnél a modellminőség-ellenőrzés feltételes lépése a következő:
A legjobb jelölt modell regisztrálása kötegpontozáshoz a RegisterModel lépéssel történik:
Most, hogy a modellt betanították, nézzük meg, hogyan segít a Clarify megérteni, hogy a modellek milyen jellemzőkre alapozzák előrejelzéseiket. Létrehozhat egy analysis_config.json fájlt dinamikusan, munkafolyamatonként futtatva a generate_config.py hasznosság. A konfigurációs fájlt folyamatonként verziózhatja és nyomon követheti runId és tárolja az Amazon S3-ban további hivatkozásokért. Inicializálja a dataconfig és a modelconfig fájlokat az alábbiak szerint:
Miután hozzáadta a Tisztázás lépést utófeldolgozási feladatként a használatával sagemaker.clarify.SageMakerClarifyProcessor a folyamatban részletes jellemző- és torzításelemzési jelentést láthat folyamatonkénti futtatásonként.



A csővezeték munkafolyamat utolsó lépéseként használhatja a TransformStep lépés az offline pontozáshoz. Haladjon be a transformer instance és a TransformInput a ... val batch_data korábban meghatározott pipeline paraméter:
Végül a választással elindíthat egy új folyamatot Indítsa el a végrehajtást a Studio IDE felületén.

Az alábbiak szerint is leírhat egy folyamatot, vagy elindíthatja a folyamatot jegyzetfüzet. A következő képernyőkép a kimenetünket mutatja.

A SageMaker modellépítési folyamat futtatását a segítségével ütemezheti Amazon EventBridge. A SageMaker modellépítő csővezetékek támogatottak célpontként az Amazon EventBridge-ben. Ez lehetővé teszi a folyamat elindítását az eseménybusz bármely eseménye alapján. Az EventBridge lehetővé teszi a folyamat automatizálását, és automatikusan reagál az olyan eseményekre, mint például a képzési feladatok vagy a végpont állapotváltozásai. Az események közé tartozik egy új fájl feltöltése az S3 tárolóba, a SageMaker végpont állapotának változása a sodródás miatt, és Amazon Simple Notification Service (Amazon SNS) témákban.
Következtetés
Ez a bejegyzés elmagyarázza, hogyan használható a SageMaker Pipelines más beépített SageMaker-funkciókkal és az XGBoost algoritmussal a lemorzsolódás előrejelzésére szolgáló legjobb jelölt modell kifejlesztéséhez, iterálásához és telepítéséhez. A megoldás megvalósításához lásd a GitHub repo. Ezt a megoldást klónozhatja és bővítheti további adatforrásokkal a modell átképzéséhez. Javasoljuk, hogy lépjen kapcsolatba AWS-fiókkezelőjével, és beszélje meg ML-használati eseteit.
További hivatkozások
További információkért tekintse meg a következő forrásokat:
A szerzőkről
 Gayatri Ghanakota gépi tanulási mérnök az AWS professzionális szolgáltatásokkal. Szenvedélye az AI/ML megoldások fejlesztése, bevezetése és magyarázata a különböző területeken. Ezt megelőzően több kezdeményezést vezetett adattudósként és ML mérnökként a pénzügyi és kiskereskedelmi szektor vezető globális cégeinél. A Colorado Egyetemen (Boulder) szerzett mesterfokozatot számítástechnikából, adattudományra specializálódott.
Gayatri Ghanakota gépi tanulási mérnök az AWS professzionális szolgáltatásokkal. Szenvedélye az AI/ML megoldások fejlesztése, bevezetése és magyarázata a különböző területeken. Ezt megelőzően több kezdeményezést vezetett adattudósként és ML mérnökként a pénzügyi és kiskereskedelmi szektor vezető globális cégeinél. A Colorado Egyetemen (Boulder) szerzett mesterfokozatot számítástechnikából, adattudományra specializálódott.
 Sarita Joshi az AWS Professional Services vezető adattudósa, aki az ügyfelek támogatására összpontosít olyan iparágakban, mint a kiskereskedelem, a biztosítás, a gyártás, az utazás, az élettudomány, a média és a szórakoztatás, valamint a pénzügyi szolgáltatások. Több éves tapasztalattal rendelkezik, mint tanácsadó, aki számos iparágban és műszaki területen ad tanácsot ügyfeleknek, beleértve az AI-t, az ML-t, az analitikát és az SAP-t. Napjainkban szenvedélyesen dolgozik az ügyfelekkel a gépi tanulási és mesterséges intelligencia megoldások széles körű fejlesztésén és megvalósításán.
Sarita Joshi az AWS Professional Services vezető adattudósa, aki az ügyfelek támogatására összpontosít olyan iparágakban, mint a kiskereskedelem, a biztosítás, a gyártás, az utazás, az élettudomány, a média és a szórakoztatás, valamint a pénzügyi szolgáltatások. Több éves tapasztalattal rendelkezik, mint tanácsadó, aki számos iparágban és műszaki területen ad tanácsot ügyfeleknek, beleértve az AI-t, az ML-t, az analitikát és az SAP-t. Napjainkban szenvedélyesen dolgozik az ügyfelekkel a gépi tanulási és mesterséges intelligencia megoldások széles körű fejlesztésén és megvalósításán.
- "
- 100
- 107
- 39
- Fiók
- aktív
- További
- Előny
- AI
- algoritmus
- Minden termék
- Alpha
- amazon
- Amazon SageMaker
- elemzés
- analitika
- API-k
- építészet
- Automatizált
- AWS
- kiindulási
- BEST
- épít
- Épület
- busz
- üzleti
- Kampányok
- esetek
- változik
- Város
- ügyfél részére
- kód
- Colorado
- Oszlop
- Kiszámít
- Computer Science
- szaktanácsadó
- fogyasztó
- fogyasztói magatartás
- Konténer
- Ügyfélmegtartás
- Ügyfelek
- DAG
- dátum
- adat-tudomány
- adattudós
- kézbesítés
- részlet
- Dev
- Fejleszt
- fejlesztők
- Fejlesztés
- domainek
- Csepp
- Endpoint
- mérnök
- Mérnöki
- Szórakozás
- Környezet
- esemény
- események
- végrehajtás
- tapasztalat
- Magyarázatosság
- Funkció
- Jellemzők
- pénzügyi
- pénzügyi szolgáltatások
- leletek
- vezetéknév
- következik
- Tele
- funkció
- Globális
- itt
- Magas
- Kezdőlap
- Hogyan
- How To
- HTTPS
- hatalmas
- azonosítani
- Beleértve
- Növelje
- iparágak
- ipar
- információ
- biztosítás
- integráció
- IT
- Munka
- Állások
- Jupyter Jegyzetfüzet
- Kulcs
- nagy
- tanulás
- Led
- Life Sciences
- gépi tanulás
- vezetés
- gyártási
- Marketing
- Média
- közepes
- Metrics
- ML
- modell
- laptopok
- bejelentés
- Ajánlatok
- online
- Online Business
- nyit
- érdekében
- Más
- előrejelzés
- Tippek
- Prediktív elemzés
- termelékenység
- program
- projektek
- Piton
- világítás
- Készenlét
- real-time
- Kapcsolatok
- jelentést
- Jelentések
- követelmények
- Tudástár
- Eredmények
- kiskereskedelem
- átképzés
- jövedelem
- Kockázat
- futás
- futás
- sagemaker
- nedv
- Skála
- Tudomány
- TUDOMÁNYOK
- tudósok
- sdk
- Series of
- Szolgáltatások
- készlet
- Megosztás
- Egyszerű
- So
- Megoldások
- Hely
- osztott
- kezdet
- Állami
- nyilatkozat
- Állapot
- tárolás
- tárolni
- Stratégia
- Támogatott
- cél
- Műszaki
- teszt
- idő
- felső
- Témakörök
- vágány
- Képzések
- Átalakítás
- utazás
- egyetemi
- us
- hasznosság
- érték
- láthatóság
- belül
- munkafolyamat
- X
- év