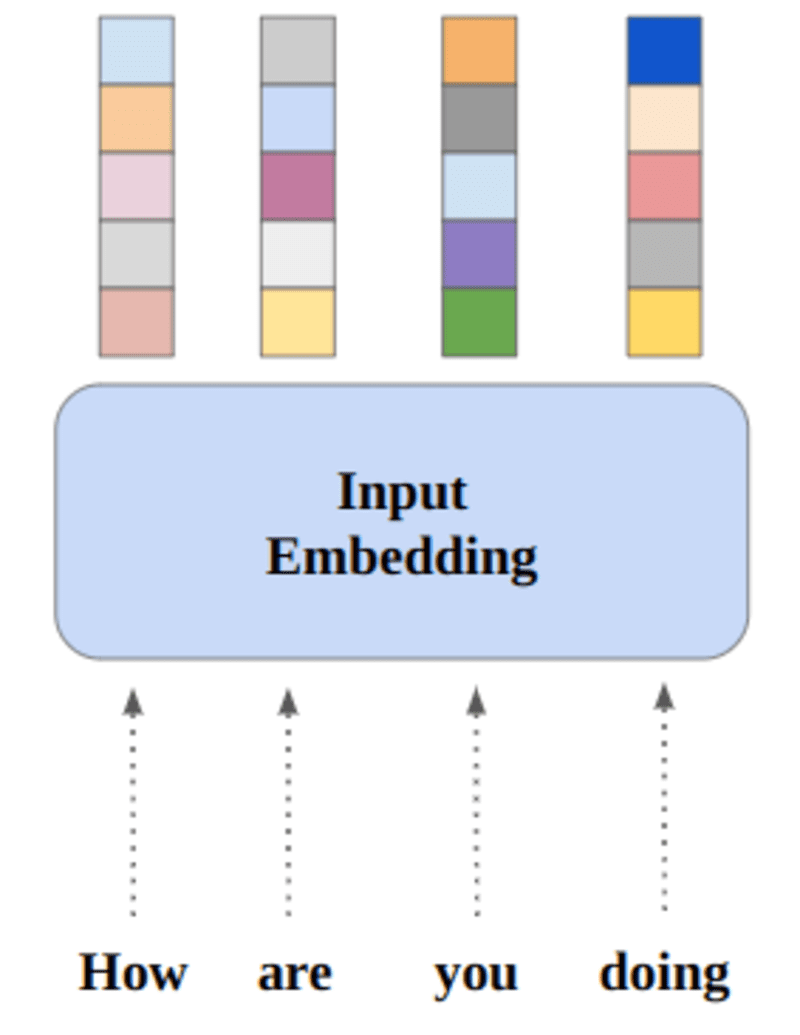
A neurális hálózatok a számokon keresztül tanulnak, így minden szó vektorokra lesz leképezve egy adott szó megjelenítésére. A beágyazási réteg egy keresőtáblázatnak tekinthető, amely tárolja a szóbeágyazásokat, és indexek segítségével visszakeresi azokat.
Az azonos jelentésű szavak közel állnak egymáshoz az euklideszi távolság/koszinusz hasonlóság szempontjából. Például az alábbi szóábrázolásban a „szombat”, „vasárnap” és a „hétfő” ugyanazon fogalomhoz kapcsolódik, így láthatjuk, hogy a szavak hasonlóak.

A szó helyzetének meghatározása, Miért kell meghatároznunk a szó pozícióját? Mivel a transzformátor kódolónak nincs ismétlődése, mint az ismétlődő neurális hálózatoknak, a bemeneti beágyazásokhoz hozzá kell adnunk néhány információt a pozíciókról. Ez pozíciókódolással történik. A cikk szerzői a következő függvényeket használták egy szó helyzetének modellezésére.
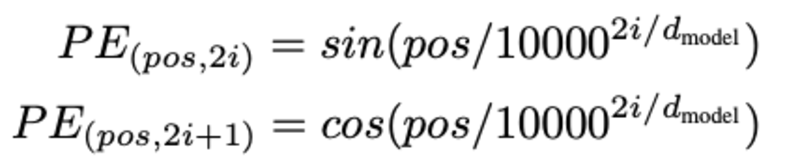
Megpróbáljuk elmagyarázni a pozicionális kódolást.
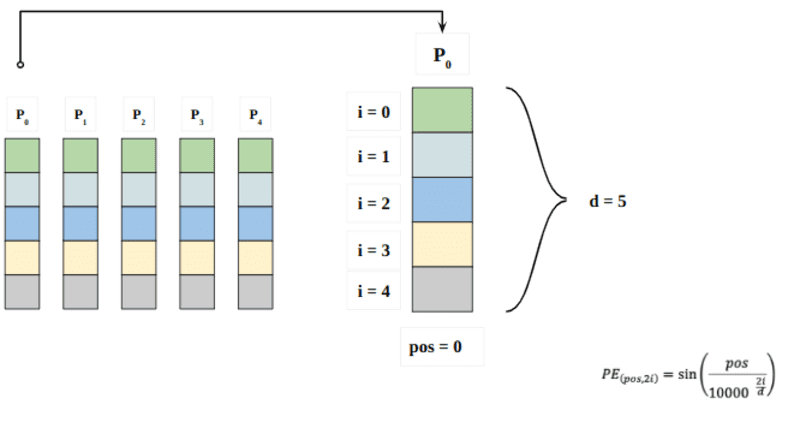
Itt a „poz” a „szó” pozíciójára utal a sorozatban. P0 az első szó pozícióbeágyazására utal; A „d” a szó/token beágyazás méretét jelenti. Ebben a példában d=5. Végül az „i” a beágyazás mind az 5 egyedi dimenziójára vonatkozik (azaz 0, 1,2,3,4)
ha az „i” változó a fenti egyenletben, akkor egy csomó változó frekvenciájú görbét kapunk. A pozícióbeágyazási értékek leolvasása különböző frekvenciákhoz képest, különböző értékek megadása különböző beágyazási méreteknél P0 és P4 esetén.
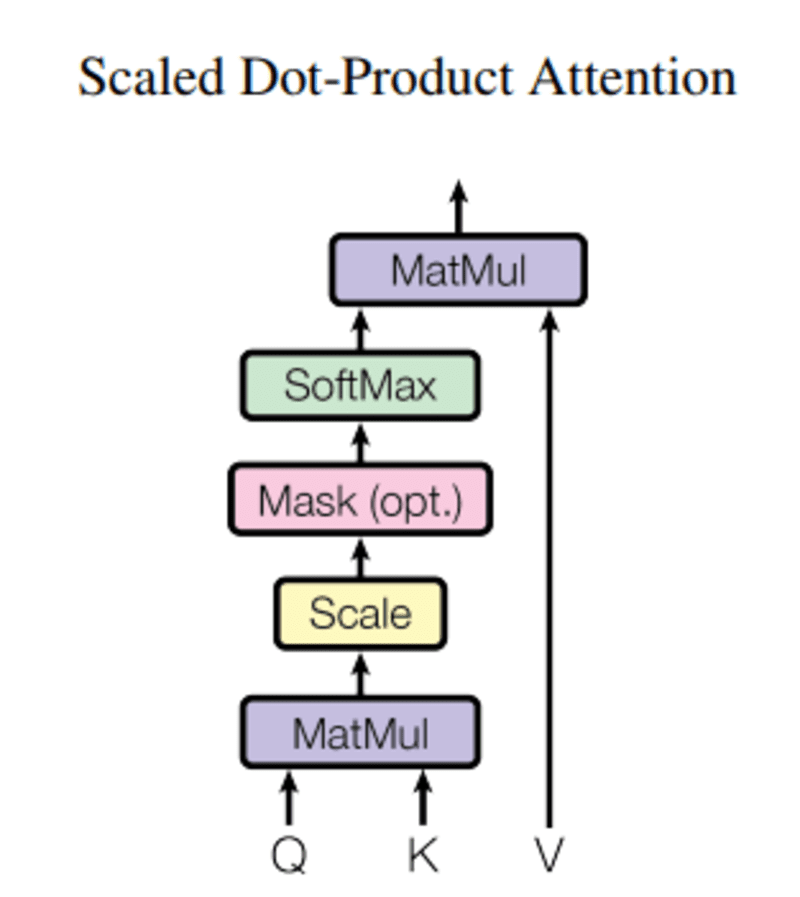
Ebben lekérdezés, Q vektorszót jelöl, a kulcsok K az összes többi szó a mondatban, és V érték a szó vektorát jelenti.
A figyelem célja a kulcskifejezés fontosságának kiszámítása az azonos személyhez/dologhoz vagy fogalomhoz kapcsolódó lekérdezési kifejezéshez képest.
Esetünkben V egyenlő Q-val.
A figyelemmechanizmus megadja számunkra a szó fontosságát a mondatban.
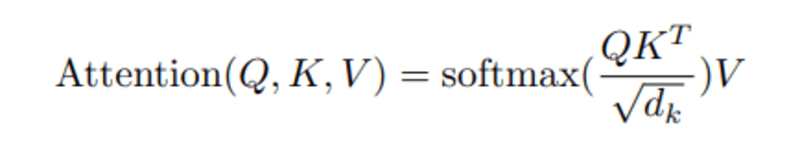
Amikor kiszámítjuk a normalizált pontszorzatot a lekérdezés és a kulcsok között, akkor egy tenzort kapunk, amely az egymás szavának relatív fontosságát jelzi a lekérdezés szempontjából.
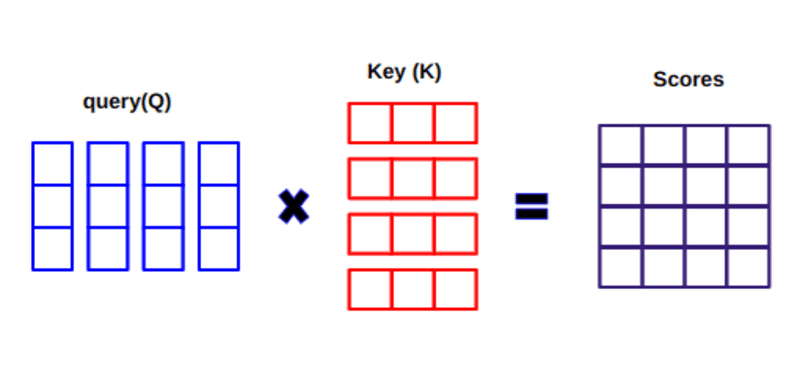
A Q és KT közötti pontszorzat kiszámításakor megpróbáljuk megbecsülni a vektorok (azaz a lekérdezés és a kulcsok közötti szavak) igazítását, és súlyt adunk vissza a mondat minden szavára.
Ezután normalizáljuk az eredményt d_k négyzetével, és a softmax függvény szabályosítja a tagokat, és átskálázza őket 0 és 1 közé.
Végül megszorozzuk az eredményt (azaz a súlyokat) az értékkel (azaz az összes szóval), hogy csökkentsük a nem releváns szavak jelentőségét, és csak a legfontosabb szavakra koncentráljunk.
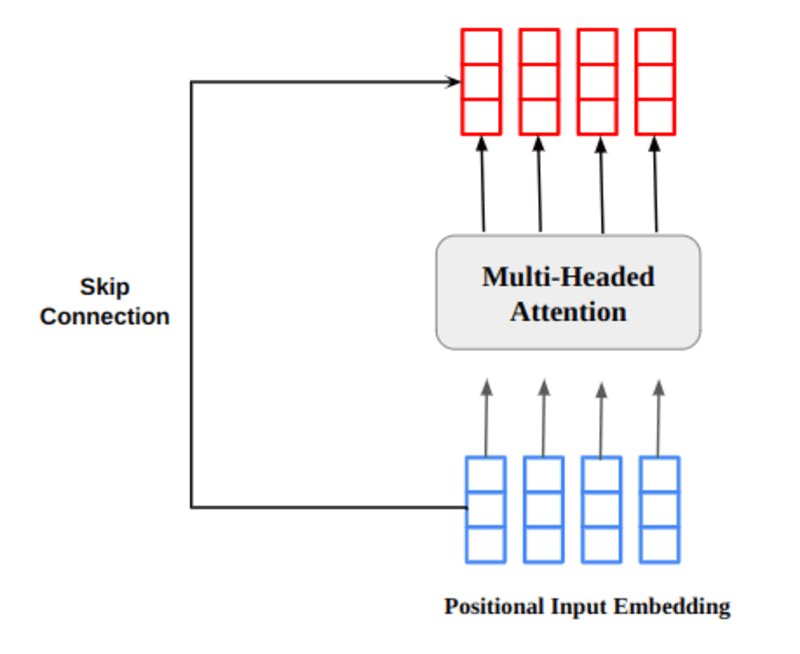
A többfejű figyelemkimeneti vektor hozzáadódik az eredeti pozíciós bemeneti beágyazáshoz. Ezt hívják maradék kapcsolatnak/kihagyó kapcsolatnak. A maradék kapcsolat kimenete rétegnormalizáláson megy keresztül. A normalizált maradék kimenetet egy pontszerű előrecsatoló hálózaton vezetik át további feldolgozás céljából.
A maszk egy mátrix, amely akkora, mint a 0-k és negatív végtelen értékekkel megtöltött figyelempontszámok.
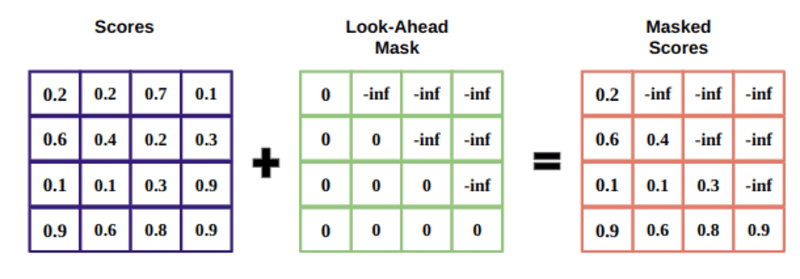
A maszk oka az, hogy ha egyszer felveszi a maszkolt pontszámok softmax-ját, a negatív végtelen nulla lesz, így nulla figyelempont marad a jövőbeli tokeneknél.
Ez arra utasítja a modellt, hogy ne összpontosítson ezekre a szavakra.
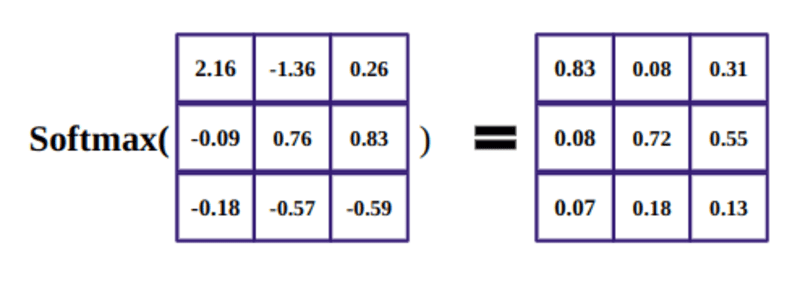
A softmax függvény célja valós számok (pozitív és negatív) megragadása és pozitív számokká alakítása, amelyek összege 1.
Ravikumar Naduvin elfoglalt az NLP-feladatok felépítésével és megértésével a PyTorch használatával.
eredeti. Engedéllyel újra közzétéve.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- Rólunk
- felett
- hozzáadott
- ellen
- igazított
- Minden termék
- és a
- társult
- figyelem
- szerzők
- mert
- előtt
- lent
- között
- Épület
- Csokor
- hívott
- eset
- közel
- képest
- Kiszámít
- számítástechnika
- koncepció
- fogalmak
- kapcsolat
- Határozzuk meg
- meghatározó
- különböző
- méretek
- DOT
- minden
- becslés
- példa
- Magyarázza
- megtöltött
- Végül
- vezetéknév
- Összpontosít
- következő
- funkció
- funkciók
- további
- jövő
- kap
- szerzés
- GitHub
- ad
- Giving
- Goes
- megragad
- Hogyan
- HTTPS
- fontosság
- fontos
- in
- indexek
- egyéni
- információ
- bemenet
- KDnuggets
- Kulcs
- kulcsok
- Ismer
- réteg
- TANUL
- kilépő
- lookup
- maszk
- Mátrix
- jelenti
- eszközök
- mechanizmus
- modell
- a legtöbb
- Szükség
- negatív
- hálózat
- hálózatok
- ideg-
- neurális hálózatok
- NLP
- számok
- eredeti
- Más
- Papír
- különös
- Elmúlt
- engedély
- Plató
- Platón adatintelligencia
- PlatoData
- pozíció
- pozíciók
- pozitív
- feldolgozás
- Termékek
- cél
- tesz
- pytorch
- Olvasás
- igazi
- ok
- ismétlődés
- csökkenteni
- kifejezés
- összefüggő
- képvisel
- képviselet
- jelentése
- eredményez
- kapott
- visszatérés
- azonos
- mondat
- Sorozat
- kellene
- hasonló
- Méret
- So
- néhány
- Négyzet
- árnyékolók
- táblázat
- Vesz
- feladatok
- megmondja
- feltételek
- A
- gondoltam
- Keresztül
- nak nek
- tokenek
- transzformerek
- FORDULAT
- megértés
- us
- érték
- Értékek
- súly
- ami
- lesz
- szó
- szavak
- zephyrnet
- nulla