Már bemutattam, hogyan kell hozzon létre tudásdiagramot egy Wikipédia-oldalból. Mivel azonban a bejegyzés nagy figyelmet kapott, úgy döntöttem, hogy más területeket is felfedezek, ahol van értelme az NLP-technikáknak a tudásgráf felépítéséhez. Véleményem szerint az orvosbiológiai terület a kiváló példa arra, hogy az adatok grafikonként való ábrázolásának van értelme, mivel gyakran elemezzük a gének, betegségek, gyógyszerek, fehérjék és egyebek közötti kölcsönhatásokat és kapcsolatokat.
Példa algrafikonra, amely bemutatja az aszkorbinsav kapcsolatát más orvosbiológiai koncepciókkal. Kép a szerzőtől.
A fenti vizualizációban megtalálható az aszkorbinsav, más néven C-vitamin, és annak néhány kapcsolata más fogalmakkal. Például azt mutatja, hogy a C-vitamin alkalmazható krónikus gyomorhurut kezelésére.
Most egy tartományi szakértői csapat feltérképezheti a gyógyszerek, betegségek és más orvosbiológiai fogalmak közötti összefüggéseket. Sajnos azonban nem sokan engedhetik meg maguknak, hogy orvosokból álló csapatot alkalmazzanak, hogy elvégezzék helyettünk a munkát. Ebben az esetben folyamodhatunk NLP-technikák használatához a kapcsolatok automatikus kinyerésére. A jó rész az, hogy egy NLP-folyamat segítségével elolvashatjuk az összes kutatási cikket, a rossz pedig az, hogy nem minden kapott eredmény lesz tökéletes. Tekintettel azonban arra, hogy nincs mellettem egy olyan tudóscsapat, amely készen áll a kapcsolatok manuális kinyerésére, az NLP technikák alkalmazásához fogok folyamodni egy saját orvosbiológiai tudásgráf megalkotásához.
Ebben a blogbejegyzésben egyetlen kutatási cikket fogok felhasználni, hogy végigvezessem Önt az orvosbiológiai ismeretek grafikonjának elkészítéséhez szükséges lépéseken – Bőrregenerálás és hajnövekedés szövettechnika.
A papírt írta Mohammadreza Ahmadi. A cikk PDF változata a CC0 1.0 licenc alatt érhető el. A tudásgráf felépítéséhez a következő lépéseket hajtjuk végre:
PDF dokumentum olvasása OCR segítségével
Szöveg előfeldolgozása
Orvosbiológiai koncepció felismerése és összekapcsolása
Kapcsolat kinyerése
Külső adatbázis gazdagítás
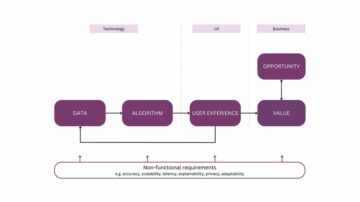
A bejegyzés végére elkészít egy grafikont a következő sémával.
Orvosbiológiai grafikon séma. Kép a szerzőtől.
A Neo4j gráf adatbázist fogjuk használni, amely a címkézett tulajdonsággráf modellt tartalmazza a gráf tárolásához. Minden cikknek egy vagy több szerzője lehet. A cikk tartalmát mondatokra bontjuk, és NLP-t használunk az orvosi entitások és kapcsolataik kinyerésére. Kicsit ellentmondó lehet, hogy az entitások közötti kapcsolatokat köztes csomópontokként tároljuk kapcsolatok helyett. A döntés mögött meghúzódó kritikus tényező az, hogy szeretnénk, hogy legyen egy ellenőrzési nyomvonal a forrásszövegről, amelyből a relációt kinyertük. A címkézett tulajdonsággráf modellnél nem lehet egy másik kapcsolatra mutató kapcsolat. Emiatt az orvosi fogalmak közötti kapcsolatot egy köztes csomóponttá alakítjuk át. Ez azt is lehetővé teszi a tartomány szakértője számára, hogy értékelje, hogy egy relációt megfelelően bontottak-e ki vagy sem.
Útközben bemutatom a felépített gráf alkalmazási lehetőségeit a tárolt információk keresésére és elemzésére.
Mint említettük, a kutatás PDF-változata a nyilvánosság számára elérhető a CC0 1.0 licenc alatt, ami azt jelenti, hogy Python segítségével könnyedén letölthetjük. Használni fogjuk a pytesseract könyvtárat, hogy kivonja a szöveget a PDF-ből. Amennyire én tudom, a pytesseract könyvtár az egyik legnépszerűbb OCR könyvtár. Ha szeretné követni a kódpéldákat, elkészítettem a Google Colab jegyzetfüzet, így nem kell magának másolnia-beillesztenie a kódot.
import requests
import pdf2image
import pytesseract pdf = requests.get('https://arxiv.org/pdf/2110.03526.pdf')
doc = pdf2image.convert_from_bytes(pdf.content) # Get the article text
article = []
for page_number, page_data in enumerate(doc): txt = pytesseract.image_to_string(page_data).encode("utf-8") # Sixth page are only references if page_number < 6: article.append(txt.decode("utf-8"))
article_txt = " ".join(article)
Szöveg előfeldolgozása
Most, hogy a cikk tartalma elérhető, eltávolítjuk a szövegből a szakaszcímeket és az ábraleírásokat. Ezután a szöveget mondatokra bontjuk.
import nltk
nltk.download('punkt') def clean_text(text): """Remove section titles and figure descriptions from text""" clean = "n".join([row for row in text.split("n") if (len(row.split(" "))) > 3 and not (row.startswith("(a)")) and not row.startswith("Figure")]) return clean text = article_txt.split("INTRODUCTION")[1]
ctext = clean_text(text)
sentences = nltk.tokenize.sent_tokenize(ctext)
Orvosbiológiai nevű entitás összekapcsolása
Most jön az izgalmas rész. Azok számára, akik még nem ismerik az NLP-t és az elnevezett entitások felismerését és összekapcsolását, kezdjük néhány alapelvvel. Az elnevezett entitás felismerési technikák a releváns entitások vagy fogalmak felismerésére szolgálnak a szövegben. Például az orvosbiológiai területen különféle géneket, gyógyszereket, betegségeket és egyéb fogalmakat szeretnénk azonosítani a szövegben.
Orvosbiológiai fogalmak kitermelése. Kép a szerzőtől.
Ebben a példában az NLP-modell géneket, betegségeket, gyógyszereket, fajokat, mutációkat és útvonalakat azonosított a szövegben. Mint említettük, ezt a folyamatot elnevezett entitás felismerésnek nevezik. A megnevezett entitásfelismerés frissítése az úgynevezett elnevezett entitás összekapcsolás. A megnevezett entitás-összekapcsolási technika felismeri a releváns fogalmakat a szövegben, és megpróbálja leképezni azokat a céltudásbázisra. Az orvosbiológiai területen néhány céltudásbázis a következő:
Miért akarjuk az orvosi entitásokat egy céltudásbázishoz kapcsolni? Az elsődleges ok az, hogy segít kezelni az entitás egyértelművé tételét. Például nem szeretnénk, hogy a grafikonon külön entitások jelenjenek meg, amelyek az aszkorbinsavat és a C-vitamint képviselik, mivel a tartományszakértők elmondhatják, hogy ezek ugyanazok. A másodlagos ok az, hogy a fogalmak céltudásbázisba való leképezésével a gráfmodellünket gazdagíthatjuk úgy, hogy a leképezett fogalmakra vonatkozó információkat lekérjük a céltudásbázisból. Ha ismét az aszkorbinsav példát használjuk, könnyen lekérhetnénk további információkat a CHEBI adatbázisból, ha már ismerjük a CHEBI id.
Az aszkorbinsavról elérhető dúsítási adatok a CHEBI honlapján. A weboldalon található összes tartalom elérhető a alatt CC BY 4.0 licenc. Kép a szerzőtől.
Már egy ideje keresek egy tisztességes, nyílt forráskódú, előre kiképzett orvosbiológiai nevű entitást, amely linkelhető. Sok NLP-modell az orvosi fogalmak, például a gének vagy a betegségek egy meghatározott részhalmazának kinyerésére összpontosít. Még ritkább olyan modellt találni, amely észleli a legtöbb orvosi koncepciót, és összekapcsolja azokat egy céltudásbázissal. Szerencsére belebotlottam BERN[1], egy neurális orvosbiológiai entitás felismerő és többtípusú normalizációs eszköz. Ha jól értem, ez egy finomhangolt BioBert-modell, amely különféle elnevezésű entitásmodelleket integrál a koncepciók és az orvosbiológiai céltudásbázisok leképezésére. Nem csak ez, hanem ingyenes REST végpontot is biztosítanak, így nem kell megküzdenünk a függőségek és a modell működésbe hozásával járó fejfájással. Az általam fentebb használt biomedicinális nevű entitásfelismerési vizualizációt a BERN modell segítségével hozták létre, így tudjuk, hogy géneket, betegségeket, gyógyszereket, fajokat, mutációkat és útvonalakat észlel a szövegben.
Sajnos a BERN modell nem rendel minden fogalomhoz céltudásbázis-azonosítót. Ezért elkészítettem egy szkriptet, amely először megvizsgálja, hogy adott-e külön azonosító egy fogalomhoz, és ha nem, akkor az entitásnevet fogja használni azonosítóként. A mondatok szövegének sha256 értékét is kiszámítjuk, hogy később könnyebben azonosíthassuk a konkrét mondatokat, amikor relációkivonást fogunk végezni.
import hashlib def query_raw(text, url="https://bern.korea.ac.kr/plain"): """Biomedical entity linking API""" return requests.post(url, data={'sample_text': text}).json() entity_list = []
# The last sentence is invalid
for s in sentences[:-1]: entity_list.append(query_raw(s)) parsed_entities = []
for entities in entity_list: e = [] # If there are not entities in the text if not entities.get('denotations'): parsed_entities.append({'text':entities['text'], 'text_sha256': hashlib.sha256(entities['text'].encode('utf-8')).hexdigest()}) continue for entity in entities['denotations']: other_ids = [id for id in entity['id'] if not id.startswith("BERN")] entity_type = entity['obj'] entity_name = entities['text'][entity['span']['begin']:entity['span']['end']] try: entity_id = [id for id in entity['id'] if id.startswith("BERN")][0] except IndexError: entity_id = entity_name e.append({'entity_id': entity_id, 'other_ids': other_ids, 'entity_type': entity_type, 'entity': entity_name}) parsed_entities.append({'entities':e, 'text':entities['text'], 'text_sha256': hashlib.sha256(entities['text'].encode('utf-8')).hexdigest()})
Megvizsgáltam a nevezett entitás összekapcsolásának eredményét, és ahogy az várható volt, nem tökéletes. Például nem azonosítja az őssejteket orvosi fogalomként. Másrészt egyetlen entitást észlelt, „szív, agy, idegek és vese” néven. Mindazonáltal a BERN továbbra is a legjobb nyílt forráskódú orvosbiológiai modell, amelyet a vizsgálatom során találtam.
Készítsen tudásgráfot
Mielőtt megvizsgálnánk a relációkivonási technikákat, egy orvosbiológiai tudásgráfot készítünk kizárólag entitások felhasználásával, és megvizsgáljuk a lehetséges alkalmazásokat. Mint említettem, elkészítettem a Google Colab jegyzetfüzet amelyek segítségével követheti a kódpéldákat ebben a bejegyzésben. A grafikonunk tárolásához a Neo4j-t fogjuk használni. Nem kell foglalkoznia a helyi Neo4j környezet előkészítésével. Ehelyett használhat egy ingyenes Neo4j Sandbox példányt.
Neo4j Sandbox csatlakozási részletek. Kép a szerzőtől.
Most már folytathatja a Neo4j kapcsolat előkészítését a notebookban.
from neo4j import GraphDatabase
import pandas as pd host = 'bolt://3.236.182.55:7687'
user = 'neo4j'
password = 'hydrometer-ditches-windings'
driver = GraphDatabase.driver(host,auth=(user, password)) def neo4j_query(query, params=None): with driver.session() as session: result = session.run(query, params) return pd.DataFrame([r.values() for r in result], columns=result.keys())
Kezdjük a szerző és a cikk importálásával a grafikonba. A cikk csomópontja csak a címet tartalmazza.
Ha megnyitja a Neo4j böngészőt, a következő grafikont kell látnia.
Kép a szerzőtől.
A mondatokat és az említett entitásokat a következő Cypher lekérdezés végrehajtásával importálhatja:
neo4j_query("""
MATCH (a:Article)
UNWIND $data as row
MERGE (s:Sentence{id:row.text_sha256})
SET s.text = row.text
MERGE (a)-[:HAS_SENTENCE]->(s)
WITH s, row.entities as entities
UNWIND entities as entity
MERGE (e:Entity{id:entity.entity_id})
ON CREATE SET e.other_ids = entity.other_ids, e.name = entity.entity, e.type = entity.entity_type
MERGE (s)-[m:MENTIONS]->(e)
ON CREATE SET m.count = 1
ON MATCH SET m.count = m.count + 1
""", {'data': parsed_entities})
A következő Cypher lekérdezést hajthatja végre az összeállított gráf ellenőrzéséhez:
MATCH p=(a:Article)-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN p LIMIT 25
Ha megfelelően importálta az adatokat, hasonló megjelenítést kell látnia.
Entitáskivonás grafikonként tárolva. Kép a szerzőtől.
Tudásgráf alkalmazások
Még a relációkivonási folyamat nélkül is van néhány használati eset a gráfunknak.
Keresőmotor
Használhatnánk a grafikonunkat keresőként. Például használhatja a következő Cypher-lekérdezést olyan mondatok vagy cikkek keresésére, amelyek egy adott egészségügyi entitást említenek.
MATCH (e:Entity)<-[:MENTIONS]-(s:Sentence)
WHERE e.name = "autoimmune diseases"
RETURN s.text as result
Eredmények
Kép a szerzőtől.
Együtt-előfordulás elemzése
A második lehetőség az együttes előfordulás elemzése. Meghatározhatja az orvosi entitások közötti együttes előfordulást, ha ugyanabban a mondatban vagy cikkben szerepelnek. Találtam egy cikket[2], amely az orvosi együttállási hálózatot használja az egészségügyi entitások közötti új lehetséges kapcsolatok előrejelzésére.
A következő Cypher-lekérdezést használhatja olyan entitások keresésére, amelyek gyakran előfordulnak ugyanabban a mondatban.
MATCH (e1:Entity)<-[:MENTIONS]-()-[:MENTIONS]->(e2:Entity)
MATCH (e1:Entity)<-[:MENTIONS]-()-[:MENTIONS]->(e2:Entity)
WHERE id(e1) < id(e2)
RETURN e1.name as entity1, e2.name as entity2, count(*) as cooccurrence
ORDER BY cooccurrence
DESC LIMIT 3
Eredmények
entitás1
entitás2
együttes előfordulása
bőrbetegségek
diabéteszes fekélyek
2
krónikus sebek
diabéteszes fekélyek
2
bőrbetegségek
krónikus sebek
2
Nyilvánvalóan jobbak lennének az eredmények, ha több ezer vagy több cikket elemeznénk.
Ellenőrizze a szerző szakértelmét
Ezt a grafikont arra is használhatja, hogy megtalálja a szerző szakértelmét, megvizsgálva azokat az orvosi entitásokat, amelyekről leggyakrabban írnak. Ezen információk birtokában jövőbeli együttműködéseket is javasolhat.
Hajtsa végre a következő Cypher-lekérdezést, hogy megvizsgálja, hogy egyetlen szerzőnk mely egészségügyi entitásokat említette a kutatási cikkben.
MATCH (a:Author)-[:WROTE]->()-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN a.name as author, e.name as entity,
MATCH (a:Author)-[:WROTE]->()-[:HAS_SENTENCE]->()-[:MENTIONS]->(e:Entity)
RETURN a.name as author, e.name as entity, count(*) as count
ORDER BY count DESC
LIMIT 5
Eredmények
szerző
egység
számít
Mohammadreza Ahmadi
kollagén
9
Mohammadreza Ahmadi
égések
4
Mohammadreza Ahmadi
bőrbetegségek
4
Mohammadreza Ahmadi
kollagenáz enzimek
2
Mohammadreza Ahmadi
Epidermolysis bullosa
2
Kapcsolat kinyerése
Most megpróbáljuk kibontani az orvosi fogalmak közötti kapcsolatokat. Tapasztalataim szerint a reláció kinyerése legalább egy nagyságrenddel nehezebb, mint a nevesített entitás kinyerése. Ha nem várhat tökéletes eredményt a megnevezett entitások összekapcsolásával, akkor a relációkivonási technikával biztosan számíthat hibákra.
Kerestem elérhető orvosbiológiai kapcsolat-kivonási modelleket, de nem találtam semmit, ami a dobozból működik, vagy nem igényel finomhangolást. Úgy tűnik, hogy a relációk kitermelésének területe az élvonalban van, és remélhetőleg a jövőben több figyelmet fogunk kapni rá. Sajnos nem vagyok NLP szakértő, ezért kerültem a saját modellem finomhangolását. Ehelyett a papíron alapuló zero-shot reláció-kivonatot fogjuk használni A FewRel zéró felvételi határának feltárása[3]. Bár nem ajánlom ennek a modellnek a gyártásba helyezését, egy egyszerű bemutatóhoz elég jó. A modell elérhető a HuggingFace, így nem kell betanítással vagy a modell felállításával foglalkoznunk.
from transformers import AutoTokenizer
from zero_shot_re import RelTaggerModel, RelationExtractor model = RelTaggerModel.from_pretrained("fractalego/fewrel-zero-shot")
tokenizer = AutoTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-finetuned-squad")
relations = ['associated', 'interacts']
extractor = RelationExtractor(model, tokenizer, relations)
A zero-shot reláció kivonóval meghatározhatja, hogy mely relációkat szeretné észlelni. Ebben a példában a társult és a kölcsönhatásba lép kapcsolatok. Kipróbáltam specifikusabb kapcsolattípusokat is, például kezeléseket, okokat és másokat, de az eredmények nem voltak nagyszerűek.
Ezzel a modellel meg kell határoznia, hogy mely entitáspárok között szeretne kapcsolatokat észlelni. A megnevezett entitás összekapcsolásának eredményeit a relációkivonási folyamat bemeneteként fogjuk használni. Először megkeressük azokat a mondatokat, amelyekben két vagy több entitás szerepel, majd futtatjuk őket a relációkivonási modellen az esetleges kapcsolatok kinyeréséhez. Meghatároztam egy 0.85-ös küszöbértéket is, ami azt jelenti, hogy ha egy modell 0.85-nél kisebb valószínűséggel jósol egy kapcsolatot az entitások között, figyelmen kívül hagyjuk az előrejelzést.
import itertools
# Candidate sentence where there is more than a single entity present
candidates = [s for s in parsed_entities if (s.get('entities')) and (len(s['entities']) > 1)]
predicted_rels = []
for c in candidates: combinations = itertools.combinations([{'name':x['entity'], 'id':x['entity_id']} for x in c['entities']], 2) for combination in list(combinations): try: ranked_rels = extractor.rank(text=c['text'].replace(",", " "), head=combination[0]['name'], tail=combination[1]['name']) # Define threshold for the most probable relation if ranked_rels[0][1] > 0.85: predicted_rels.append({'head': combination[0]['id'], 'tail': combination[1]['id'], 'type':ranked_rels[0][0], 'source': c['text_sha256']}) except: pass # Store relations to Neo4j
neo4j_query("""
UNWIND $data as row
MATCH (source:Entity {id: row.head})
MATCH (target:Entity {id: row.tail})
MATCH (text:Sentence {id: row.source})
MERGE (source)-[:REL]->(r:Relation {type: row.type})-[:REL]->(target)
MERGE (text)-[:MENTIONS]->(r)
""", {'data': predicted_rels})
A grafikonon tároljuk a kapcsolatokat, valamint a kapcsolat kinyeréséhez használt forrásszöveget.
Grafikonban tárolt relációk kinyerése. Kép a szerzőtől.
Az entitások és a forrásszöveg közötti kinyert kapcsolatokat a következő Cypher-lekérdezéssel vizsgálhatja meg:
MATCH (s:Entity)-[:REL]->(r:Relation)-[:REL]->(t:Entity), (r)<-[:MENTIONS]-(st:Sentence)
RETURN s.name as source_entity, t.name as target_entity, r.type as type, st.text as source_text
Eredmények
Kép a szerzőtől.
Mint említettem, az NLP-modell, amit a kapcsolatok kivonására használtam, nem tökéletes, és mivel nem vagyok orvos, nem tudom, hány kapcsolat hiányzott belőle. Az észleltek azonban ésszerűnek tűnnek.
Külső adatbázis gazdagítás
Mint korábban említettem, továbbra is használhatjuk a külső adatbázisokat, mint például a CHEBI vagy a MESH, hogy gazdagítsuk a gráfunkat. Például a grafikonunk egy orvosi entitást tartalmaz Epidermolysis bullosa és ismerjük a MeSH azonosítóját is.
Az Epidermolysis bullosa MeSH azonosítóját a következő lekérdezéssel kérheti le:
MATCH (e:Entity)
WHERE e.name = "Epidermolysis bullosa"
RETURN e.name as entity, e.other_ids as other_ids
Megvizsgálhatja a MeSH-t, hogy megtalálja a rendelkezésre álló információkat:
Képernyőkép a szerzőtől. Az adatok az Egyesült Államok Nemzeti Orvosi Könyvtárának jóvoltából származnak.
Íme egy képernyőkép a MeSH webhelyén elérhető információkról az Epidermolysis bullosa esetében. Mint említettem, nem vagyok orvos, így nem tudom pontosan, mi lenne a legjobb módja ennek az információnak a grafikonon való modellezésére. Megmutatom azonban, hogyan kérheti le ezeket az információkat a Neo4j-ben az apoc.load.json eljárással, hogy lekérje az információkat a MeSH REST végpontról. Ezután megkérhet egy domain szakértőt, hogy segítsen modellezni ezeket az információkat.
A Cypher-lekérdezés az információknak a MeSH REST végpontból való lekéréséhez:
MATCH (e:Entity)
WHERE e.name = "Epidermolysis bullosa"
WITH e, [id in e.other_ids WHERE id contains "MESH" | split(id,":")[1]][0] as meshId
CALL apoc.load.json("https://id.nlm.nih.gov/mesh/lookup/details?descriptor=" + meshId) YIELD value
RETURN value
Tudásgráf gépi tanulási adatbevitelként
Utolsó gondolatként gyorsan végigvezetem, hogyan használhatja az orvosbiológiai ismeretek grafikonját a gépi tanulási munkafolyamat bemeneteként. Az elmúlt években sok kutatás és előrelépés történt a csomópont-beágyazás területén. A csomópont-beágyazási modellek a hálózati topológiát beágyazási térré fordítják.
Tegyük fel, hogy összeállított egy orvosbiológiai tudásgráfot, amely orvosi entitásokat és fogalmakat, azok kapcsolatait és gazdagítását tartalmazza különböző orvosi adatbázisokból. Csomópont-beágyazási technikák segítségével megtanulhatja a csomópont-reprezentációkat, amelyek rögzített hosszúságú vektorok, és beviheti őket a gépi tanulási munkafolyamatba. Különböző alkalmazások alkalmazzák ezt a megközelítést, kezdve a gyógyszer újrahasznosításától a gyógyszermellék- vagy káros hatások előrejelzéséig. Találtam egy kutatási cikket, amely felhasználja link-előrejelzés az új betegségek lehetséges kezeléséhez[4].
Következtetés
Az orvosbiológiai terület kiváló példa arra, ahol a tudásgráfok alkalmazhatók. Számos alkalmazás létezik, az egyszerű keresőmotoroktól a bonyolultabb gépi tanulási munkafolyamatokig. Remélhetőleg ennek a blogbejegyzésnek az elolvasása után ötletet fogalmazott meg arra vonatkozóan, hogyan használhatja fel az orvosbiológiai tudásgrafikonokat alkalmazásai támogatására. Elkezdheti a ingyenes Neo4j Sandbox és kezdje el felfedezni még ma.
[1] D. Kim et al., „A neurális nevű entitás felismerő és többtípusú normalizáló eszköz orvosbiológiai szövegbányászathoz”, in IEEE hozzáférés, vol. 7, 73729–73740, 2019, doi: 10.1109/ACCESS.2019.2920708.
[2] Kastrin A, Rindflesch TC, Hristovski D. Link-előrejelzés MeSH együttes előfordulási hálózatban: előzetes eredmények. Stud Health Technol Inform. 2014; 205:579–83. PMID: 25160252.
[3] Cetoli, A. (2020). A FewRel zéró felvételi határának feltárása. Ban ben A 28. Nemzetközi Számítógépes Nyelvészeti Konferencia anyaga (1447–1451. o.). Nemzetközi Számítógépes Nyelvészeti Bizottság.
[4] Zhang, R., Hristovski, D., Schutte, D., Kastrin, A., Fiszman, M., & Kilicoglu, H. (2021). Kábítószer-újrafelhasználás a COVID-19-hez tudásdiagram kitöltésével. Journal of Biomedical Informatics, 115, 103696.
Ezt a cikket eredetileg közzétették Az adattudomány felé és a szerző engedélyével újra közzétesszük a TOPBOTS-nál.
Tetszett ez a cikk? Iratkozzon fel további AI-frissítésekért.
Értesíteni fogunk, ha további műszaki oktatást adunk ki.