Az Amazon eszközei minden nap tranzakciók milliárdjait dolgozzák fel és elemzik a globális szállítási, készletezési, kapacitási, ellátási, értékesítési, marketinges, gyártói és ügyfélszolgálati csapatoktól. Ezeket az adatokat az eszközök készleteinek beszerzéséhez használják fel, hogy megfeleljenek az Amazon ügyfelei igényeinek. Mivel az adatmennyiség éves szinten kétszámjegyű százalékos növekedést mutat, és a COVID-járvány 2021-ben megzavarta a globális logisztikát, kritikusabbá vált a csaknem valós idejű adatok skálázása és generálása.
Ez a bejegyzés bemutatja, hogyan költöztünk át egy AWS-re épülő szerver nélküli adattóra, amely automatikusan több forrásból és különböző formátumokból fogyaszt adatokat. Továbbá további lehetőségeket teremtett adattudósaink és mérnökeink számára, hogy mesterséges intelligencia és gépi tanulási (ML) szolgáltatásokat használjanak az adatok folyamatos betáplálására és elemzésére.
Kihívások és tervezési problémák
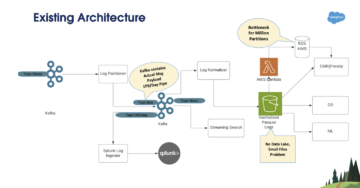
Legacy architektúránkat elsősorban használtuk Amazon rugalmas számítási felhő (Amazon EC2) az adatok kinyerésére különböző belső heterogén adatforrásokból és REST API-kból a Amazon egyszerű tárolási szolgáltatás (Amazon S3) az adatok betöltéséhez és Amazon RedShift további elemzéshez és a beszerzési rendelések generálásához.
Azt találtuk, hogy ez a megközelítés néhány hiányosságot eredményezett, és ezért a következő területeken vezetett előrelépésekhez:
- Fejlesztői sebesség – Az egységesítés és a séma feltárásának hiánya miatt, amelyek a futásidejű hibák elsődleges okai, a fejlesztők gyakran fordítottak időt az üzemeltetési és karbantartási problémákra.
- skálázhatóság – Ezen adatkészletek többsége meg van osztva az egész világon. Ezért az adatok lekérdezése során be kell tartanunk a méretezési korlátokat.
- Minimális infrastruktúra karbantartás – Az aktuális folyamat az adatforrástól függően több számítást is felölel. Ezért kritikus az infrastruktúra karbantartásának csökkentése.
- Az adatforrás változásaira való reagálás – Jelenlegi rendszerünk különböző heterogén adattárakból, szolgáltatásokból kap adatokat. Ezeknek a szolgáltatásoknak minden frissítése hónapokig tartó fejlesztői ciklusokat vesz igénybe. Ezen adatforrások válaszideje kulcsfontosságú érdekelt feleink számára. Ezért adatvezérelt megközelítést kell alkalmaznunk a nagy teljesítményű architektúra kiválasztásához.
- Tárolás és redundancia – A heterogén adattárak és modellek miatt kihívást jelentett a különböző üzleti érdekelt csoportoktól származó adatkészletek tárolása. Ezért a verziószámítás, valamint a növekményes és differenciális adatok összehasonlítása figyelemre méltó képességet biztosít optimalizáltabb tervek létrehozására.
- Menekülő és hozzáférhetőség – A logisztika ingadozó jellege miatt néhány üzleti érdekelt csapatnak igény szerint elemeznie kell az adatokat, és a beszerzési megrendelésekhez közel valós idejű optimális tervet kell készítenie. Ez szükségessé teszi mind a lekérdezést, mind pedig az adatok csaknem valós időben történő eléréséhez és elemzéséhez való ráfordítását.
Megvalósítási stratégia
Ezen követelmények alapján stratégiát váltottunk, és elkezdtük az egyes problémák elemzését, hogy megtaláljuk a megoldást. Építészetileg egy szerver nélküli modellt választottunk, és a Data Lake architektúra cselekvési vonala minden olyan architekturális hiányosságra és kihívást jelentő jellemzőre vonatkozik, amelyekről megállapítottuk, hogy a fejlesztések részét képezték. Működési szempontból új megosztott felelősségi modellt terveztünk az adatfeldolgozáshoz AWS ragasztó az Amazon EC2-n tervezett belső szolgáltatások (REST API-k) helyett az adatok kinyerésére. Mi is használtuk AWS Lambda adatfeldolgozáshoz. Aztán választottunk Amazon Athéné mint lekérdező szolgáltatásunk. Hozzáadtuk, hogy tovább optimalizáljuk és javítsuk adatfogyasztóink fejlesztői sebességét Amazon DynamoDB mint metaadattár az adattóban leszálló különböző adatforrásokhoz. Ez a két döntés vezérelte minden tervezési és megvalósítási döntésünket.
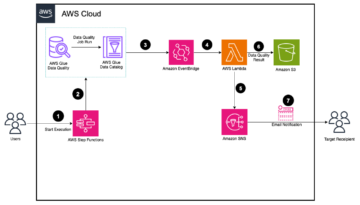
Az alábbi ábra szemlélteti az architektúrát

A következő szakaszokban részletesebben megvizsgáljuk az architektúra egyes összetevőit, miközben haladunk a folyamatfolyamon.
AWS ragasztó ETL-hez
Az ügyfelek igényeinek kielégítése és az új vállalkozások adatforrásainak nagyságrendjének támogatása érdekében kulcsfontosságú volt számunkra, hogy nagyfokú agilitással, skálázhatósággal és válaszkészséggel rendelkezzünk a különböző adatforrások lekérdezésében.
Az AWS Glue egy szerver nélküli adatintegrációs szolgáltatás, amely megkönnyíti az analitikai felhasználók számára a több forrásból származó adatok felfedezését, előkészítését, áthelyezését és integrálását. Használhatja analitikához, ML-hez és alkalmazásfejlesztéshez. Ezenkívül további termelékenységet és DataOps-eszközöket is tartalmaz a szerzői, a feladatok futtatásához és az üzleti munkafolyamatok megvalósításához.
Az AWS Glue segítségével több mint 70 különféle adatforrást fedezhet fel és csatlakozhat hozzájuk, és kezelheti adatait egy központi adatkatalógusban. Vizuálisan létrehozhat, futtathat és figyelhet kivonat, átalakítható és betölthető (ETL) folyamatfolyamatokat, hogy adatokat töltsön be az adatforrásokba. Ezenkívül azonnal kereshet és lekérdezhet katalogizált adatokban az Athena használatával, Amazon EMRés Amazon Red Shift Spectrum.
Az AWS Glue megkönnyítette számunkra a különféle adattárak adataihoz való csatlakozást, az adatok szükség szerinti szerkesztését és tisztítását, valamint az adatok betöltését egy AWS által biztosított tárolóba az egységes nézet érdekében. Az AWS ragasztófeladatok ütemezhetők vagy igény szerint meghívhatók, hogy adatokat nyerjenek ki az ügyfél erőforrásából és az adattóból.
Ezeknek a munkáknak néhány felelőssége a következő:
- Forrás entitás kibontása és átalakítása adatentitássá
- Bővítse az adatokat úgy, hogy tartalmazzon évet, hónapot és napot a jobb katalogizálás érdekében, és a jobb lekérdezés érdekében adjon meg egy pillanatfelvétel-azonosítót
- Végezze el az Amazon S3 bemeneti érvényesítését és elérési út generálását
- Társítsa az akkreditált metaadatokat a forrásrendszer alapján
A REST API-k belső szolgáltatásokból történő lekérdezése az egyik fő kihívásunk, és a minimális infrastruktúra miatt ezeket kívántuk használni ebben a projektben. Az AWS Glue csatlakozók segítettek a követelmény és cél betartásában. A REST API-kból és más adatforrásokból származó adatok lekérdezéséhez PySpark és JDBC modulokat használtunk.
Az AWS Glue a csatlakozási típusok széles skáláját támogatja. További részletekért lásd: Csatlakozási típusok és opciók az ETL-hez az AWS ragasztóban.
S3 kanál leszállózónaként
A kinyert adatok közvetlen leszállózónájául egy S3 vödröt használtunk, amelyet tovább dolgozunk és optimalizálunk.
Lambda mint AWS Glue ETL trigger
Engedélyeztük az S3 eseményértesítéseket az S3 tárolóban, hogy elindítsák a Lambdát, amely tovább particionálja adatainkat. Az adatok az InputDataSetName, év, hónap és dátum szerint particionálva vannak. Az ezen adatokon futó bármely lekérdezésfeldolgozó csak az adatok egy részét vizsgálja meg a jobb költség- és teljesítményoptimalizálás érdekében. Adataink különféle formátumokban tárolhatók, mint például CSV, JSON és Parquet.
A nyers adatok a legtöbb felhasználási esetünkben nem ideálisak az optimális terv létrehozásához, mivel gyakran ismétlődnek vagy helytelen adattípusok. A legfontosabb, hogy az adatok többféle formátumban vannak, de gyorsan módosítottuk az adatokat, és jelentős lekérdezési teljesítménynövekedést tapasztaltunk a Parquet formátum használatával. Itt az egyik teljesítmény tippet használtuk A 10 legjobb teljesítményhangolási tipp az Amazon Athena számára.
AWS ragasztómunkák ETL-hez
Jobb adatelkülönítést és hozzáférhetőséget szerettünk volna, ezért a teljesítmény további javítása érdekében egy másik S3-csoportot választottunk. Ugyanazokat az AWS Glue-feladatokat használtuk az adatok további átalakítására és betöltésére a szükséges S3 tárolóba, valamint a kivont metaadatok egy részét a DynamoDB-be.
DynamoDB metaadat-tárként
Most, hogy rendelkezésünkre állnak az adatok, a különböző üzleti érdekelt felek tovább fogyasztják azokat. Így két kérdésünk van: melyik forrásadatok találhatók az adattóban és milyen verzióban. Metaadattárunknak a DynamoDB-t választottuk, amely a legfrissebb részletekkel látja el a fogyasztókat az adatok hatékony lekérdezéséhez. Rendszerünkben minden adatkészletet egyedileg azonosítunk egy pillanatkép azonosítóval, amelyet metaadattárunkból kereshetünk. Az ügyfelek API-val érik el ezt az adattárat.
Amazon S3 mint adattó
A jobb adatminőség érdekében a dúsított adatokat egy másik S3 tárolóba bontottuk ki ugyanazzal az AWS ragasztófeladattal.
AWS ragasztó lánctalpas
A bejárók a „titkos szósz”, amely lehetővé teszi számunkra, hogy reagáljunk a sémaváltozásokra. A folyamat során úgy döntöttünk, hogy minden lépést a lehető legséma-aggnosztikusabbá tesszük, ami lehetővé teszi a sémamódosítások áthaladását, amíg el nem érik az AWS Glue-t. Egy bejáróval fenn tudjuk tartani a sémában bekövetkező agnosztikus változásokat. Ez segített nekünk az Amazon S3 adatainak automatikus feltérképezésében, valamint a séma és a táblázatok létrehozásában.
AWS ragasztóadat-katalógus
Az adatkatalógus segített nekünk fenntartani a katalógust az adatok helyének, sémájának és futásidejű mutatóinak indexeként az Amazon S3-ban. Az adatkatalógusban lévő információk metaadattáblázatokként vannak tárolva, ahol minden tábla egyetlen adattárat határoz meg.
Athena SQL lekérdezésekhez
Az Athena egy interaktív lekérdezési szolgáltatás, amely megkönnyíti az Amazon S3-ban lévő adatok szabványos SQL használatával történő elemzését. Az Athena szerver nélküli, így nincs kezelhető infrastruktúra, és csak a futtatott lekérdezésekért kell fizetni. Legfontosabb fejlesztési tényezőinknek a működési stabilitást és a növekvő fejlesztői sebességet tekintettük.
Tovább optimalizáltuk az Athena lekérdezésének folyamatát, hogy a felhasználók a következők létrehozásával beillesszék az értékeket és a lekérdezéseket, hogy adatokat nyerjenek ki az Athénából:
- An AWS Cloud Development Kit (AWS CDK) sablon az Athena infrastruktúra létrehozásához és AWS Identity and Access Management (IAM) szerepkörökkel hozzáférhet a Data Lake S3 tárolóihoz és az adatkatalógushoz bármely fiókból
- Egy olyan könyvtár, amelynek segítségével az ügyfél megadhat egy IAM-szerepet, lekérdezést, adatformátumot és kimeneti helyet az Athena-lekérdezés elindításához, és a lekérdezés állapotának és eredményének lekéréséhez az általa választott tárolóban.
Az Athena lekérdezése két lépésből áll:
- StartQueryExecution – Ez elindítja a lekérdezés futtatását, és megkapja a futtatási azonosítót. A felhasználók megadhatják azt a kimeneti helyet, ahol a lekérdezés kimenete tárolódik.
- GetQueryExecution – Ez megkapja a lekérdezés állapotát, mert a futás aszinkron. Sikeres esetben lekérdezheti a kimenetet egy S3 fájlban vagy via API.
A lekérdezés elindításának és az eredmény lekérésének segítő módszere a könyvtárban lenne.
Data Lake metaadat szolgáltatás
Ez a szolgáltatás egyedi fejlesztésű, és együttműködik a DynamoDB-vel, hogy a metaadatokat (adatkészlet neve, pillanatkép azonosítója, partíciós karakterlánc, időbélyeg és az adatok S3-hivatkozása) REST API formájában kapja meg. A séma felfedezésekor az ügyfelek az Athena-t használják lekérdezésfeldolgozóként az adatok lekérdezéséhez.
Mivel minden adatkészletnek van pillanatkép-azonosítója, particionálva van, az összekapcsolási lekérdezés nem eredményez teljes táblavizsgálatot, hanem csak partícióvizsgálatot az Amazon S3-on. Az Athena-t használtuk lekérdezésfeldolgozóként, mert egyszerűen nem kezelhető a lekérdezési infrastruktúra. Később, ha úgy érezzük, hogy szükségünk van még valamire, használhatjuk a Redshift Spectrumot vagy az Amazon EMR-t.
Következtetés
Az Amazon Devices csapatai jelentős értéket fedeztek fel azáltal, hogy az AWS Glue-t használó Data Lake architektúrára tértek át, amely lehetővé tette a globális üzleti szereplők számára, hogy hatékonyabban dolgozzanak fel adatokat. Ez lehetővé tette a csapatoknak, hogy a különböző adatkészletek közel valós időben történő elemzésével, megfelelő üzleti logikával az ellátási lánc, a kereslet és az előrejelzés problémáinak megoldása érdekében optimális tervet készítsenek az eszközök beszerzésére.
Működési szempontból a beruházás már kezdett megtérülni:
- Szabványosította a beviteli, tárolási és visszakeresési mechanizmusainkat, megtakarítva ezzel a belépési időt. A rendszer bevezetése előtt egy adatkészlet bevezetése 1 hónapig tartott. Új architektúránknak köszönhetően kevesebb mint 15 hónap alatt 2 új adatkészletet tudtunk beépíteni, ami 70%-kal javította agilitásunkat.
- Eltávolította a méretezési szűk keresztmetszeteket, így egy homogén rendszert hozott létre, amely gyorsan több ezer futtatásra skálázható.
- A megoldás séma- és adatminőség-ellenőrzést adott a bemenetek elfogadása és az adatminőség-sértések észlelése esetén történő elutasítása előtt.
- Könnyűvé tette az adatkészletek lekérését, miközben támogatta a jövőbeni szimulációkat és a verziószámú bemeneteket igénylő visszatesztelő használati eseteket. Ez egyszerűbbé teszi a modellek elindítását és tesztelését.
- A megoldás egy közös infrastruktúrát hozott létre, amely könnyen kiterjeszthető más, a DIAL-on keresztüli csapatokra, amelyek hasonló problémákkal küzdenek az adatbevitellel, tárolással és visszakereséssel.
- Működési költségeink közel 90%-kal csökkentek.
- Ehhez az adattóhoz hatékonyan hozzáférhetnek adattudósaink és mérnökeink, hogy más elemzéseket végezzenek, és előrejelző megközelítést alkalmazzanak, mint a jövőbeni lehetőséget, hogy pontos terveket készítsenek a beszerzési rendelésekhez.
A bejegyzés lépései segíthetnek egy hasonló modern adatstratégia megtervezésében az AWS által felügyelt szolgáltatások használatával, amelyek segítségével különböző forrásokból származó adatokat gyűjthet be, automatikusan metaadat-katalógusokat hozhat létre, zökkenőmentesen oszthatja meg az adatokat az adattó és az adattárház között, valamint riasztásokat hozhat létre az eseményben. egy összehangolt adatmunkafolyamat-hiba miatt.
A szerzőkről
 Avinash Kolluri az AWS vezető megoldási építésze. Az Amazon Alexa és a Devices területén dolgozik a modern elosztott megoldások tervezésén és tervezésén. Szenvedélye az, hogy költséghatékony és nagymértékben méretezhető megoldásokat építsen az AWS-re. Szabadidejében szeret fúziós recepteket főzni és utazni.
Avinash Kolluri az AWS vezető megoldási építésze. Az Amazon Alexa és a Devices területén dolgozik a modern elosztott megoldások tervezésén és tervezésén. Szenvedélye az, hogy költséghatékony és nagymértékben méretezhető megoldásokat építsen az AWS-re. Szabadidejében szeret fúziós recepteket főzni és utazni.
 Vipul Verma Sr.Software Engineer az Amazon.com-nál. 2015 óta dolgozik az Amazonnál, és valós kihívásokat old meg olyan technológia segítségével, amely közvetlenül befolyásolja és javítja az Amazon ügyfeleinek életét. Szabadidejében szívesen túrázik.
Vipul Verma Sr.Software Engineer az Amazon.com-nál. 2015 óta dolgozik az Amazonnál, és valós kihívásokat old meg olyan technológia segítségével, amely közvetlenül befolyásolja és javítja az Amazon ügyfeleinek életét. Szabadidejében szívesen túrázik.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/how-amazon-devices-scaled-and-optimized-real-time-demand-and-supply-forecasts-using-serverless-analytics/
- 1
- 10
- 100
- 2021
- 70
- a
- képesség
- Képes
- hozzáférés
- igénybe vett
- megközelíthetőség
- meghatalmazott
- pontos
- át
- Akció
- hozzáadott
- További
- AI
- Alexa
- Minden termék
- lehetővé teszi, hogy
- már
- amazon
- amazon alexa
- Amazon EC2
- Amazon EMR
- Amazon.com
- elemzés
- analitika
- elemez
- elemzése
- és a
- Másik
- api
- API-k
- Alkalmazás
- Application Development
- megközelítés
- megfelelő
- építészeti
- építészet
- területek
- szerző
- automatikusan
- AWS
- AWS ragasztó
- vissza
- alapján
- mert
- előtt
- Jobb
- között
- milliárd
- épít
- épült
- üzleti
- hívott
- Kapacitás
- esetek
- katalógus
- katalógusok
- központosított
- lánc
- kihívások
- kihívást
- Változások
- választás
- választotta
- vásárló
- ügyfél részére
- felhő
- COM
- kombináció
- Közös
- összehasonlítani
- összetevő
- Kiszámít
- Csatlakozás
- kapcsolat
- figyelembe vett
- figyelembe véve
- fogyaszt
- Fogyasztók
- folyamatosan
- főzés
- Mag
- Költség
- költséghatékony
- kiadások
- tudott
- Covidien
- lánctalpas
- teremt
- készítette
- létrehozása
- kritikai
- Jelenlegi
- szokás
- vevő
- Vevőszolgálat
- Ügyfelek
- ciklusok
- dátum
- adatintegráció
- adattó
- adatfeldolgozás
- adatminőség
- adatstratégia
- adattárház
- adatalapú
- adatkészletek
- találka
- nap
- foglalkozó
- döntés
- határozatok
- Fok
- Kereslet
- igények
- attól
- Design
- tervezett
- részlet
- részletek
- eltökélt
- fejlett
- Fejlesztő
- fejlesztők
- Fejlesztés
- Eszközök
- különböző
- közvetlenül
- felfedez
- felfedezett
- felfedezés
- megosztott
- számos
- Nem
- ismétlődések
- minden
- könnyen
- hatékonyan
- eredményesen
- bármelyik
- engedélyezve
- lehetővé teszi
- mérnök
- Mérnökök
- dúsított
- egység
- Eter (ETH)
- esemény
- Minden
- kivonat
- kivonni az adatokat
- tényezők
- Kudarc
- Elesett
- Jellemzők
- kevés
- filé
- áramlási
- következő
- következik
- Előrejelzés
- forma
- formátum
- talált
- ból ből
- Tele
- további
- Továbbá
- magfúzió
- jövő
- Nyereség
- generál
- generáló
- generáció
- kap
- szerzés
- Globális
- globális üzlet
- földgolyó
- cél
- Növekedés
- tekintettel
- segít
- segített
- itt
- Magas
- nagy teljesítményű
- nagyon
- turisztika
- Hogyan
- HTML
- HTTPS
- IAM
- ideális
- azonosított
- azonosítani
- Identitás
- azonnali
- azonnal
- Hatás
- végrehajtás
- végrehajtási
- javul
- javított
- javulás
- fejlesztések
- in
- tartalmaz
- magában foglalja a
- növekvő
- index
- információ
- Infrastruktúra
- bemenet
- helyette
- integrálni
- integráció
- interaktív
- kölcsönhatásba lép
- belső
- Bemutatja
- leltár
- beruházás
- kérdés
- kérdések
- IT
- Munka
- Állások
- csatlakozik
- json
- Kulcs
- hiány
- tó
- leszállási
- legutolsó
- indítás
- tanulás
- Örökség
- könyvtár
- élet
- határértékek
- vonal
- LINK
- kiszámításának
- elhelyezkedés
- logisztika
- néz
- gép
- gépi tanulás
- készült
- fenntartása
- karbantartás
- csinál
- KÉSZÍT
- kezelése
- kezelése
- Marketing
- Találkozik
- Metaadatok
- módszer
- Metrics
- minimális
- ML
- modell
- modellek
- modern
- módosított
- Modulok
- monitor
- Hónap
- hónap
- több
- a legtöbb
- mozog
- mozgó
- többszörös
- név
- Természet
- Szükség
- szükséges
- Új
- értesítések
- Fedélzeti
- Beszállás
- ONE
- üzemeltetési
- operatív
- Lehetőségek
- Alkalom
- optimálisan
- optimalizálás
- Optimalizálja
- optimalizált
- Opciók
- rendelés
- Más
- járvány
- rész
- szenvedély
- ösvény
- Fizet
- százalék
- teljesít
- teljesítmény
- perspektíva
- Hely
- terv
- tervek
- Plató
- Platón adatintelligencia
- PlatoData
- lehetséges
- állás
- Készít
- elsősorban
- elsődleges
- problémák
- folyamat
- feldolgozás
- Processzor
- Termelők
- termelő
- termelékenység
- program
- ad
- biztosít
- Vásárlás
- Toló
- világítás
- Kérdések
- gyorsan
- Arány
- Nyers
- nyers adatok
- el
- való Világ
- real-time
- miatt
- receptek
- csökkentő
- kifejezés
- figyelemre méltó
- eltávolított
- kötelező
- követelmény
- követelmények
- forrás
- válasz
- felelősség
- felelősség
- fogékony
- REST
- eredményez
- Szerep
- szerepek
- futás
- futás
- értékesítés
- azonos
- megtakarítás
- skálázhatóság
- skálázható
- Skála
- skálázás
- beolvasás
- tervezett
- tudósok
- zökkenőmentesen
- Keresés
- szakaszok
- idősebb
- vagy szerver
- szolgáltatás
- Szolgáltatások
- Megosztás
- megosztott
- Szállítás
- Műsorok
- jelentős
- hasonló
- Egyszerű
- óta
- egyetlen
- Pillanatkép
- So
- szoftver
- Software Engineer
- megoldások
- Megoldások
- SOLVE
- Megoldása
- valami
- forrás
- Források
- ível
- Spektrum
- költött
- SQL
- Stabilitás
- érdekeltek
- érdekeltek
- standard
- kezdet
- kezdődött
- Kezdve
- kezdődik
- Állapot
- Lépés
- Lépései
- tárolás
- tárolni
- memorizált
- árnyékolók
- stratégiák
- Stratégia
- sikeres
- ilyen
- kínálat
- ellátási lánc
- Támogató
- Támogatja
- rendszer
- táblázat
- Vesz
- tart
- csapat
- Technológia
- sablon
- Tesztelés
- A
- The Source
- azok
- ebből adódóan
- ezer
- Keresztül
- egész
- idő
- alkalommal
- időbélyeg
- tippek
- nak nek
- felső
- Tranzakciók
- Átalakítás
- Utazó
- kiváltó
- típusok
- egységes
- Frissítés
- us
- használ
- Felhasználók
- érvényesítés
- érték
- Értékek
- fajta
- különféle
- Sebesség
- változat
- keresztül
- Megnézem
- jogsértések
- illó
- kötetek
- kívánatos
- Raktár
- módon
- Mit
- ami
- míg
- széles
- lesz
- munkafolyamat
- munkafolyamatok
- művek
- lenne
- év
- A te
- zephyrnet