Ezt a bejegyzést Mahima Agarwal, gépi tanulási mérnök és Deepak Mettel, a VMware Carbon Black vezető mérnöki menedzsere közösen írták
VMware koromfekete egy elismert biztonsági megoldás, amely védelmet kínál a modern kibertámadások teljes spektruma ellen. A termék által generált terabájtnyi adattal a biztonsági elemzőcsapat a gépi tanulási (ML) megoldások kidolgozására összpontosít a kritikus támadások felszínre hozására és a zajból fakadó újonnan felmerülő fenyegetésekre.
A VMware Carbon Black csapata számára kritikus fontosságú egy egyéni végpontok közötti MLOps-folyamat tervezése és felépítése, amely levezényli és automatizálja a munkafolyamatokat az ML életciklusában, és lehetővé teszi a modellek képzését, értékelését és telepítését.
A folyamat felépítésének két fő célja van: az adattudósok támogatása a modellfejlesztés késői szakaszában, valamint a termékben a felületi modellek előrejelzése a modellek nagy volumenű és valós idejű gyártási forgalommal való kiszolgálása révén. Ezért a VMware Carbon Black és az AWS úgy döntött, hogy egyéni MLOps folyamatot épít fel Amazon SageMaker Könnyű használhatósága, sokoldalúsága és teljesen felügyelt infrastruktúrája miatt. Az ML képzési és telepítési folyamatainkat a segítségével hangszereljük Amazon által felügyelt munkafolyamatok az Apache Airflow számára (Amazon MWAA), amely lehetővé teszi számunkra, hogy jobban összpontosítsunk a munkafolyamatok és folyamatok programozott létrehozására anélkül, hogy aggódnunk kellene az automatikus méretezés vagy az infrastruktúra karbantartása miatt.
Ezzel a folyamattal az egykor a Jupyter notebook-vezérelt ML-kutatás egy olyan automatizált folyamat, amely modelleket telepít a termelésbe, az adattudósok csekély kézi beavatkozásával. Korábban a modell betanítása, értékelése és telepítése egy napot is igénybe vehetett; Ezzel a megvalósítással minden csak egy kioldónyira van, és a teljes idő néhány percre csökkent.
Ebben a bejegyzésben a VMware Carbon Black és az AWS építészei megvitatják, hogyan építettünk és kezeltünk egyéni ML munkafolyamatokat Gitlab, Amazon MWAA és SageMaker. Megbeszéljük az eddig elért eredményeket, a folyamat további fejlesztéseit és az út során levont tanulságokat.
Megoldás áttekintése
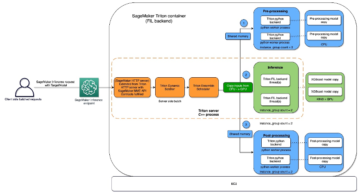
A következő ábra az ML platform architektúráját mutatja be.

Magas szintű megoldástervezés
Ezt az ML-platformot úgy tervezték és tervezték, hogy különböző modellek használhassák a különböző kódtárolókban. Csapatunk a GitLabot használja forráskód-kezelő eszközként az összes kódtár karbantartására. A modelltár forráskódjában bekövetkezett bármilyen változás folyamatosan integrálódik a Gitlab CI, amely meghívja a folyamatban lévő következő munkafolyamatokat (modell betanítás, értékelés és telepítés).
A következő architektúra diagram a végpontok közötti munkafolyamatot és az MLOps folyamatban részt vevő összetevőket szemlélteti.

Végponttól végpontig terjedő munkafolyamat
Az ML-modell képzési, kiértékelési és telepítési folyamatait az Amazon MWAA, úgynevezett Irányított aciklikus grafikon (DAG). A DAG feladatok együttes gyűjteménye, amelyek függőségekkel és kapcsolatokkal vannak megszervezve, hogy meghatározzák, hogyan kell futni.
Magas szinten a megoldás architektúrája három fő összetevőt tartalmaz:
- ML csővezeték kódtár
- ML modell képzési és értékelési folyamat
- ML modell telepítési folyamat
Beszéljük meg, hogyan kezelik ezeket a különböző összetevőket, és hogyan hatnak egymásra.
ML csővezeték kódtár
Miután a modellrepó integrálja az MLOps repót a lefelé irányuló folyamatként, és egy adattudós kódot hagy be a modellrepóban, a GitLab futtatója elvégzi az abban a repóban meghatározott szabványos kódellenőrzést és tesztelést, és elindítja az MLOps folyamatot a kódváltozások alapján. A Gitlab többprojektes folyamatát használjuk, hogy engedélyezzük ezt a triggert a különböző repókban.
Az MLOps GitLab folyamat bizonyos szakaszokat futtat. Alapvető kódellenőrzést végez a pylint segítségével, a modell betanítási és következtetési kódját a Docker-képbe csomagolja, és a tárolóképet közzéteszi Amazon Elastic Container Registry (Amazon ECR). Az Amazon ECR egy teljesen felügyelt konténer-nyilvántartás, amely nagy teljesítményű tárhelyszolgáltatást kínál, így bárhol megbízhatóan telepítheti az alkalmazásképeket és a műtermékeket.
ML modell képzési és értékelési folyamat
A kép közzététele után elindítja a képzést és az értékelést apache légáramlás csővezetéken keresztül AWS Lambda funkció. A Lambda egy kiszolgáló nélküli, eseményvezérelt számítási szolgáltatás, amely gyakorlatilag bármilyen típusú alkalmazás vagy háttérszolgáltatás kódjának futtatását teszi lehetővé kiszolgálók kiépítése vagy kezelése nélkül.
A folyamat sikeres elindítása után lefuttatja a Training and Evaluation DAG-t, amely viszont elindítja a modellképzést a SageMakerben. A képzési folyamat végén az azonosított felhasználói csoport e-mailben értesítést kap a képzési és modellértékelési eredményekről Amazon Simple Notification Service (Amazon SNS) és a Slack. Az Amazon SNS egy teljesen felügyelt pub/sub szolgáltatás A2A és A2P üzenetküldéshez.
Az értékelési eredmények alapos elemzése után az adattudós vagy az ML mérnök telepítheti az új modellt, ha az újonnan betanított modell teljesítménye jobb az előző verzióhoz képest. A modellek teljesítményét a modell-specifikus mérőszámok (például F1 pontszám, MSE vagy zavaros mátrix) alapján értékelik.
ML modell telepítési folyamat
A telepítés megkezdéséhez a felhasználó elindítja a GitLab-feladatot, amely ugyanazon a Lambda-függvényen keresztül indítja el a telepítési DAG-t. A folyamat sikeres lefutása után létrehozza vagy frissíti a SageMaker végpontot az új modellel. Ez egy értesítést is küld a végpont részleteivel e-mailben az Amazon SNS és a Slack használatával.
Bármelyik csővezeték meghibásodása esetén a felhasználók ugyanazon a kommunikációs csatornán kapnak értesítést.
A SageMaker valós idejű következtetést kínál, amely ideális az alacsony késleltetésű és nagy áteresztőképességi követelményekkel járó munkaterhelésekhez. Ezek a végpontok teljes mértékben felügyeltek, terheléskiegyenlítettek és automatikusan skálázottak, és több rendelkezésre állási zónára is telepíthetők a magas rendelkezésre állás érdekében. A folyamat sikeres lefutása után létrehoz egy ilyen végpontot egy modellhez.
A következő szakaszokban kibővítjük a különböző összetevőket, és belemerülünk a részletekbe.
GitLab: Csomagmodellek és trigger-folyamatok
A GitLabot használjuk kódtárunkként és a folyamathoz a modellkód csomagolásához és a downstream Airflow DAG-ok indításához.
Több projektből álló csővezeték
A többprojektes GitLab-folyamatszolgáltatás akkor használatos, ha a szülő folyamat (felfelé) egy modelltár, az utódfolyamat (lejjebb) pedig az MLOps repo. Minden tárház egy .gitlab-ci.yml fájlt tart fenn, és a következő kódblokk, amely az upstream folyamatban engedélyezett, aktiválja a downstream MLOps folyamatot.
Az upstream folyamat a modellkódot továbbítja a downstream folyamatnak, ahol a csomagolási és közzétételi CI-feladatok aktiválódnak. A modellkód konténerbe helyezéséhez és az Amazon ECR-ben való közzétételéhez szükséges kódot az MLOps folyamat karbantartja és kezeli. Olyan változókat küld, mint az ACCESS_TOKEN (a következő alatt hozható létre beállítások, Hozzáférés), JOB_ID (az upstream melléktermékek eléréséhez) és $CI_PROJECT_ID (a modell repo projektazonosítója) változók, így az MLOps folyamat hozzáférhet a modellkódfájlokhoz. A ... val munkaleletek A Gitlab szolgáltatásának köszönhetően a downstream repo a következő paranccsal éri el a távoli melléktermékeket:
A modellrepó több modellhez is felhasználhat lefelé irányuló folyamatokat ugyanabból a repóból azáltal, hogy kiterjeszti azt a szakaszt, amely kiváltja nyúlik kulcsszó a GitLab-tól, amely lehetővé teszi ugyanazt a konfigurációt a különböző szakaszokban.
A modellkép Amazon ECR-ben való közzététele után az MLOps folyamat elindítja az Amazon MWAA képzési folyamatot a Lambda segítségével. A felhasználó jóváhagyása után elindítja a modelltelepítési Amazon MWAA folyamatot is ugyanazzal a Lambda funkcióval.
Szemantikus verziókészítés és átadási verziók downstream
Egyedi kódot fejlesztettünk ki az ECR képek és a SageMaker modellek verziójához. Az MLOps folyamat kezeli a képek és modellek szemantikai verziókezelési logikáját annak a szakasznak a részeként, ahol a modellkód konténerbe kerül, és műtermékként továbbítja a verziókat a későbbi szakaszoknak.
Átképzés
Mivel az átképzés az ML életciklusának kulcsfontosságú aspektusa, folyamatunk részeként átképzési képességeket vezettünk be. A SageMaker list-models API-t használjuk annak azonosítására, hogy átképzésről van-e szó a modell újraképzési verziószáma és az időbélyeg alapján.
Az átképzési csővezeték napi beosztását segítségével kezeljük A GitLab ütemezési folyamatai.
Terraform: Infrastruktúra beállítása
Ez a megoldás az Amazon MWAA-fürtön, az ECR-tárolókon, a Lambda-függvényeken és az SNS-témán kívül AWS Identity and Access Management (IAM) szerepkörök, felhasználók és szabályzatok; Amazon egyszerű tárolási szolgáltatás (Amazon S3) vödrök, és egy amazonfelhőóra rönkszállító.
Az infrastruktúra beállításának és karbantartásának egyszerűsítésére a folyamatunk során érintett szolgáltatásokhoz használjuk Terraform az infrastruktúra kódként való megvalósításához. Amikor infrafrissítésekre van szükség, a kódváltozások egy általunk beállított GitLab CI-folyamatot indítanak el, amely ellenőrzi és különböző környezetekben telepíti a változtatásokat (például engedélyt ad egy IAM-házirendhez a fejlesztői, szakaszos és termékfiókokban).
Amazon ECR, Amazon S3 és Lambda: Pipeline facilitation
Az alábbi kulcsfontosságú szolgáltatásokat vesszük igénybe csővezetékünk megkönnyítése érdekében:
- Amazon ECR – A modelltároló képeinek karbantartása és kényelmes lekérésének lehetővé tétele érdekében szemantikus verziókkal látjuk el őket, és feltöltjük őket az ECR-repozitóriumokba.
${project_name}/${model_name}a Terraformon keresztül. Ez jó elkülönítési réteget tesz lehetővé a különböző modellek között, és lehetővé teszi számunkra, hogy egyéni algoritmusokat használjunk, és formázzuk a következtetési kéréseket és válaszokat a kívánt modell jegyzékinformációihoz (modellnév, verzió, betanítási adatútvonal stb.). - Amazon S3 – S3 gyűjtőcsoportokat használunk a modell betanítási adatok, a modellenként betanított modelltermékek, az Airflow DAG-ok és a csővezetékek által megkívánt egyéb további információk megőrzésére.
- Lambda – Mivel az Airflow-fürtünket biztonsági megfontolások miatt külön VPC-ben telepítjük, a DAG-okhoz nem lehet közvetlenül hozzáférni. Ezért a Terraformmal is karbantartott Lambda függvényt használunk a DAG név által meghatározott DAG-ok kiváltására. Megfelelő IAM-beállítás esetén a GitLab CI-feladat elindítja a Lambda funkciót, amely áthalad a konfigurációkon a kért képzési vagy telepítési DAG-ig.
Amazon MWAA: Képzési és telepítési csővezetékek
Ahogy korábban említettük, az Amazon MWAA-t használjuk a képzési és telepítési folyamatok összehangolására. A következő helyen elérhető SageMaker operátorokat használjuk Amazon szolgáltatói csomag az Airflow számára integrálni a SageMakerrel (a jinja sablonok elkerülése érdekében).
Ebben a képzési folyamatban a következő operátorokat használjuk (a következő munkafolyamat diagramon látható):

MWAA Training Pipeline
A következő operátorokat használjuk a telepítési folyamatban (a következő munkafolyamat diagramon látható):

Modell bevezetési folyamat
A Slacket és az Amazon SNS-t használjuk a hiba-/sikerüzenetek és az értékelési eredmények közzétételére mindkét folyamatban. A Slack számos lehetőséget kínál az üzenetek testreszabására, beleértve a következőket:
- SnsPublishOperator - Mi használjuk SnsPublishOperator sikerről/kudarcról szóló értesítések küldése felhasználói e-mailekre
- Slack API – Mi alkottuk meg a bejövő webhook URL hogy a folyamatban lévő értesítések a kívánt csatornához kerüljenek
CloudWatch és VMware Wavefront: Monitoring és naplózás
CloudWatch irányítópultot használunk a végpontfigyelés és naplózás konfigurálására. Segít megjeleníteni és nyomon követni az egyes projektekre jellemző különféle működési és modellteljesítmény-mutatókat. A némelyikük nyomon követésére beállított automatikus skálázási házirendek mellett folyamatosan figyeljük a CPU- és memóriahasználat változásait, a másodpercenkénti kéréseket, a válaszadási késéseket és a modell mérőszámait.
A CloudWatch még a VMware Tanzu Wavefront irányítópultjával is integrálva van, így képes megjeleníteni a modell végpontjainak mérőszámait, valamint más projektszintű szolgáltatásokat.
Az üzleti előnyök és a következő lépések
Az ML-folyamatok nagyon fontosak az ML szolgáltatások és szolgáltatások szempontjából. Ebben a bejegyzésben egy végponttól végpontig terjedő ML használati esetet tárgyaltunk az AWS képességeit használva. Egyedi folyamatot építettünk a SageMaker és az Amazon MWAA segítségével, amelyet újra felhasználhatunk projektekben és modellekben, és automatizáltuk az ML életciklust, ami a modell betanításától az éles üzembe helyezésig tartó időt mindössze 10 percre csökkentette.
Az ML életciklus terheinek a SageMakerre való áthárításával optimalizált és méretezhető infrastruktúrát biztosított a modell betanításához és telepítéséhez. A SageMakerrel végzett modellszolgáltatás segített nekünk valós idejű előrejelzéseket készíteni ezredmásodperces késleltetésekkel és figyelési képességekkel. Terraformot használtunk a beállítás megkönnyítése és az infrastruktúra kezelése érdekében.
Ennek a folyamatnak a következő lépése a modell betanítási folyamat továbbképzési képességekkel való bővítése, függetlenül attól, hogy az ütemezett vagy modelleltolódás-észlelésen alapul, az árnyéktelepítés támogatása vagy az A/B tesztelés a gyorsabb és minősített modelltelepítés érdekében, valamint az ML vonalkövetés. Tervezzük az értékelést is Amazon SageMaker csővezetékek mert a GitLab integráció már támogatott.
Tanulságok
A megoldás kidolgozása során megtanultuk, hogy korán általánosítani kell, de ne általánosítson túl. Amikor először befejeztük az architektúra tervezését, legjobb gyakorlatként próbáltunk kódsablont létrehozni és kényszeríteni a modellkódhoz. Azonban a fejlesztési folyamat olyan korai szakaszában volt, hogy a sablonok vagy túl általánosak voltak, vagy túl részletesek ahhoz, hogy a jövőbeni modellekhez újra felhasználhatók legyenek.
Az első modell csővezetéken keresztül történő leszállítása után a sablonok természetesen előkerültek a korábbi munkáink meglátásai alapján. Egy csővezeték nem tud mindent az első naptól kezdve.
A modellkísérleteknek és a gyártásnak gyakran nagyon eltérő (vagy néha egymásnak ellentmondó) követelményei vannak. Kulcsfontosságú, hogy csapatként a kezdetektől egyensúlyba hozzuk ezeket a követelményeket, és ennek megfelelően rangsoroljuk.
Ezenkívül előfordulhat, hogy nincs szüksége a szolgáltatás minden funkciójára. A szolgáltatás alapvető jellemzőinek használata és a moduláris felépítés kulcsa a hatékonyabb fejlesztés és a rugalmas folyamat.
Következtetés
Ebben a bejegyzésben bemutattuk, hogyan építettünk fel egy MLOps-megoldást a SageMaker és az Amazon MWAA segítségével, amely automatizálta a modellek üzembe helyezésének folyamatát az adattudósok csekély kézi beavatkozásával. Javasoljuk, hogy értékelje a különféle AWS-szolgáltatásokat, mint például a SageMaker, Amazon MWAA, Amazon S3 és Amazon ECR egy teljes MLOps megoldás létrehozásához.
*Az Apache, az Apache Airflow és az Airflow a cég bejegyzett védjegyei vagy védjegyei Apache Software Foundation az Egyesült Államokban és/vagy más országokban.
A szerzőkről
 Deepak Mettem Senior Engineering Manager a VMware, Carbon Black Unit. Ő és csapata azon dolgoznak, hogy olyan streaming alapú alkalmazásokat és szolgáltatásokat építsenek ki, amelyek magasan elérhetőek, méretezhetők és rugalmasak, hogy az ügyfelek valós időben gépi tanuláson alapuló megoldásokat kínáljanak. Ő és csapata felelős az adattudósok számára szükséges eszközök létrehozásáért is, hogy megépítsék, képezzék, telepítsék és érvényesítsék ML-modelleik termelésben.
Deepak Mettem Senior Engineering Manager a VMware, Carbon Black Unit. Ő és csapata azon dolgoznak, hogy olyan streaming alapú alkalmazásokat és szolgáltatásokat építsenek ki, amelyek magasan elérhetőek, méretezhetők és rugalmasak, hogy az ügyfelek valós időben gépi tanuláson alapuló megoldásokat kínáljanak. Ő és csapata felelős az adattudósok számára szükséges eszközök létrehozásáért is, hogy megépítsék, képezzék, telepítsék és érvényesítsék ML-modelleik termelésben.
 Mahima Agarwal gépi tanulási mérnök a VMware-nél, a szénfekete egységnél.
Mahima Agarwal gépi tanulási mérnök a VMware-nél, a szénfekete egységnél.
A VMware CB SBU gépi tanulási platformjának alapvető összetevőinek és architektúrájának tervezésén, megépítésén és fejlesztésén dolgozik.
 Vamshi Krishna Enabothala Sr. Applied AI Specialist Architect az AWS-nél. Különböző ágazatokból származó ügyfelekkel dolgozik a nagy hatású adatok, elemzések és gépi tanulási kezdeményezések felgyorsítása érdekében. Szenvedélyesen rajong az ajánlórendszerekért, az NLP-ért és a számítógépes látási területekért az AI és az ML területén. A munkán kívül Vamshi RC-rajongó, RC-berendezéseket (repülőket, autókat és drónokat) épít, és a kertészkedést is szereti.
Vamshi Krishna Enabothala Sr. Applied AI Specialist Architect az AWS-nél. Különböző ágazatokból származó ügyfelekkel dolgozik a nagy hatású adatok, elemzések és gépi tanulási kezdeményezések felgyorsítása érdekében. Szenvedélyesen rajong az ajánlórendszerekért, az NLP-ért és a számítógépes látási területekért az AI és az ML területén. A munkán kívül Vamshi RC-rajongó, RC-berendezéseket (repülőket, autókat és drónokat) épít, és a kertészkedést is szereti.
 Sahil Thapar az Enterprise Solutions Architect. Együttműködik az ügyfelekkel, hogy segítsen nekik kiválóan elérhető, méretezhető és rugalmas alkalmazásokat készíteni az AWS Cloudon. Jelenleg a konténerekre és a gépi tanulási megoldásokra koncentrál.
Sahil Thapar az Enterprise Solutions Architect. Együttműködik az ügyfelekkel, hogy segítsen nekik kiválóan elérhető, méretezhető és rugalmas alkalmazásokat készíteni az AWS Cloudon. Jelenleg a konténerekre és a gépi tanulási megoldásokra koncentrál.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :is
- $ UP
- 1
- 10
- 100
- 7
- 8
- a
- Rólunk
- gyorsul
- hozzáférés
- igénybe vett
- Eszerint
- Fiókok
- elért
- át
- aciklikus
- mellett
- További
- további információ
- Után
- ellen
- AI
- algoritmusok
- Minden termék
- lehetővé teszi, hogy
- amazon
- Amazon SageMaker
- elemzés
- analitika
- és a
- bárhol
- Apache
- api
- Alkalmazás
- alkalmazások
- alkalmazott
- Alkalmazott AI
- jóváhagyás
- építészet
- VANNAK
- területek
- AS
- megjelenés
- At
- Támadások
- szerző
- auto
- Automatizált
- automaták
- elérhetőség
- elérhető
- elkerülése érdekében
- AWS
- háttér
- Egyenleg
- alapján
- alapvető
- BE
- mert
- Kezdet
- Előnyök
- BEST
- Jobb
- között
- Fekete
- Blokk
- Ág
- hoz
- épít
- Épület
- épült
- teher
- by
- TUD
- nem tud
- képességek
- szén
- autók
- eset
- CB
- bizonyos
- Változások
- csatornák
- gyermek
- választotta
- felhő
- Fürt
- kód
- gyűjtemény
- közlés
- képest
- teljes
- alkatrészek
- Kiszámít
- számítógép
- Számítógépes látás
- magatartások
- Configuration
- konfigurációk
- Ellentmondó
- zavar
- megfontolások
- fogyaszt
- fogyasztott
- Konténer
- Konténerek
- folyamatosan
- Kényelmes
- Mag
- tudott
- országok
- CPU
- teremt
- készítette
- teremt
- létrehozása
- kritikai
- kritikus
- Jelenleg
- szokás
- Ügyfelek
- testre
- cyberattacks
- DAG
- napi
- műszerfal
- dátum
- adattudós
- nap
- meghatározott
- átadó
- telepíteni
- telepített
- bevezetéséhez
- bevetés
- bevetések
- bevet
- Design
- tervezett
- tervezés
- részletes
- részletek
- Érzékelés
- Dev
- fejlett
- fejlesztése
- Fejlesztés
- különböző
- közvetlenül
- megvitatni
- tárgyalt
- Dokkmunkás
- ne
- le-
- Drónok
- minden
- Korábban
- Korai
- egyszerű használat
- hatékony
- bármelyik
- csiszolókő
- lehetővé
- engedélyezve
- lehetővé teszi
- ösztönzése
- végtől végig
- Endpoint
- mérnök
- Mérnöki
- Vállalkozás
- Vállalati megoldások
- rajongó
- környezetek
- felszerelés
- alapvető
- Eter (ETH)
- értékelni
- értékelték
- értékelő
- értékelés
- értékelések
- Még
- esemény
- Minden
- minden
- példa
- Bontsa
- kiterjedő
- f1
- megkönnyítése
- Kudarc
- messze
- gyorsabb
- Funkció
- Jellemzők
- kevés
- Fájlok
- vezetéknév
- rugalmas
- Összpontosít
- összpontosított
- koncentrál
- következő
- A
- formátum
- ból ből
- Tele
- teljes spektrum
- teljesen
- funkció
- funkciók
- további
- jövő
- generált
- kap
- jó
- Csoport
- Legyen
- tekintettel
- segít
- segített
- segít
- Magas
- nagy teljesítményű
- nagyon
- tárhely
- Hogyan
- azonban
- HTML
- http
- HTTPS
- IAM
- ID
- ideális
- azonosított
- azonosítani
- Identitás
- kép
- képek
- végre
- végrehajtás
- végre
- in
- tartalmaz
- magában foglalja a
- Beleértve
- információ
- Infrastruktúra
- kezdeményezések
- meglátások
- integrálni
- integrált
- integrál
- integráció
- kölcsönhatásba
- beavatkozás
- behívja
- részt
- szigetelés
- IT
- ITS
- Munka
- Állások
- jpg
- Tart
- Kulcs
- kulcsok
- Késleltetés
- réteg
- tanult
- tanulás
- Tanulságok
- Tanulságok
- Lets
- szint
- életciklus
- mint
- kis
- kiszámításának
- Elő/Utó
- gép
- gépi tanulás
- Fő
- fenntartása
- fenntartja
- karbantartás
- csinál
- kezelése
- sikerült
- vezetés
- menedzser
- kezeli
- kezelése
- kézikönyv
- Mátrix
- Memory design
- említett
- üzenetek
- üzenetküldés
- Metrics
- esetleg
- miliszekundum
- jegyzőkönyv
- ML
- MLOps
- modell
- modellek
- modern
- monitor
- ellenőrzés
- több
- hatékonyabb
- többszörös
- név
- természetesen
- elengedhetetlen
- Szükség
- Új
- következő
- NLP
- Zaj
- bejelentés
- értesítések
- szám
- of
- felajánlás
- Ajánlatok
- on
- ONE
- operatív
- üzemeltetők
- optimalizált
- Opciók
- hangszerelt
- Szervezett
- Más
- kívül
- átfogó
- csomag
- csomagok
- csomagolás
- rész
- bérletek
- Múló
- szenvedélyes
- ösvény
- teljesítmény
- engedély
- csővezeték
- terv
- Planes
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- Politikák
- politika
- állás
- gyakorlat
- Tippek
- előző
- Fontossági sorrendet
- folyamat
- Termékek
- Termelés
- program
- projektek
- megfelelő
- védelem
- feltéve,
- ellátó
- biztosít
- közzétesz
- közzétett
- közzéteszi
- Kiadás
- célokra
- képzett
- hatótávolság
- real-time
- Ajánlást
- Csökkent
- említett
- nyilvántartott
- iktató hivatal
- Kapcsolatok
- távoli
- Híres
- raktár
- kért
- kéri
- kötelező
- követelmények
- kutatás
- rugalmas
- válasz
- felelős
- Eredmények
- átképzés
- újrahasználható
- szerepek
- futás
- futó
- sagemaker
- azonos
- skálázható
- skálázás
- menetrend
- tervezett
- Tudós
- tudósok
- Második
- szakaszok
- ágazatok
- biztonság
- idősebb
- különálló
- vagy szerver
- Szerverek
- szolgáltatás
- Szolgáltatások
- szolgáló
- készlet
- felépítés
- árnyék
- VÁLTOZÁS
- kellene
- mutatott
- Egyszerű
- laza
- So
- eddig
- szoftver
- megoldások
- Megoldások
- néhány
- forrás
- forráskód
- szakember
- különleges
- meghatározott
- Spektrum
- reflektorfény
- Színpad
- állapota
- standard
- kezdet
- kezdődik
- Államok
- Lépései
- tárolás
- Stratégia
- folyó
- áramvonal
- későbbi
- sikeresen
- ilyen
- támogatás
- Támogatott
- felületi
- Systems
- TAG
- Vesz
- feladatok
- csapat
- sablonok
- Terraform
- Tesztelés
- hogy
- A
- azok
- Őket
- ebből adódóan
- Ezek
- fenyegetések
- három
- Keresztül
- egész
- áteresztőképesség
- idő
- időbélyeg
- nak nek
- együtt
- is
- szerszám
- szerszámok
- felső
- téma
- vágány
- Csomagkövetés
- védjegye
- forgalom
- Vonat
- kiképzett
- Képzések
- kiváltó
- váltott
- FORDULAT
- alatt
- egység
- Egyesült
- Egyesült Államok
- Frissítés
- us
- Használat
- használ
- használati eset
- használó
- Felhasználók
- ÉRVÉNYESÍT
- érvényesítés
- változók
- különféle
- változat
- gyakorlatilag
- látomás
- Képzeld
- vmware
- kötet
- Út..
- JÓL
- Mit
- vajon
- ami
- széles
- Széleskörű
- val vel
- belül
- nélkül
- Munka
- munkafolyamat
- munkafolyamatok
- művek
- lenne
- zephyrnet
- Postai irányítószám
- zónák