Bevezetés
Az auditálási adatok világa összetett lehet, és számos kihívást le kell küzdenie. Az egyik legnagyobb kihívás a kategorikus attribútumok kezelése adatkészletek kezelése közben. Ebben a cikkben az adatok auditálásának, az anomáliák felderítésének és a kategorikus attribútumok kódolásának modellekre gyakorolt hatásának világába fogunk beleásni.
Az adatok auditálása során az anomáliák észlelésével kapcsolatos egyik fő kihívás a kategorikus attribútumok kezelése. A kategorikus attribútumok kódolása kötelező, mert a modellek nem tudják értelmezni a szövegbevitelt. Általában ez a címkekódolás vagy a One Hot kódolás használatával történik. Egy nagy adathalmazban azonban a One-hot kódolás gyenge modellteljesítményhez vezethet a dimenzionalitás átka miatt.
Tanulási célok
-
Megérteni az adatok auditálásának fogalmát és a kihívást
- A mély, felügyelet nélküli anomáliák kimutatásának különböző módszereinek értékelése.
- Megérteni a kategorikus attribútumok kódolásának hatását az adatok anomáliák észlelésére használt modellekre.
Ez a cikk részeként jelent meg Adattudományi Blogaton.
Tartalomjegyzék
- Mi az Auata?
- Mi az anomália észlelése?
- Az adatok auditálása során felmerülő főbb kihívások
- Adatkészletek auditálása anomáliák észleléséhez
- Kategóriai attribútumok kódolása
- Kategorikus kódolások
- Felügyelet nélküli anomália-észlelő modellek
- Hogyan hat a kategorikus attribútumok kódolása a modellekre?
8.1 Az Autóbiztosítási adatkészlet t-SNE reprezentációja
8.2 A Járműbiztosítási adatkészlet t-SNE reprezentációja
8.3 A Járműkövetelések adatkészlet t-SNE reprezentációja - Következtetés
at is Auditing Data?
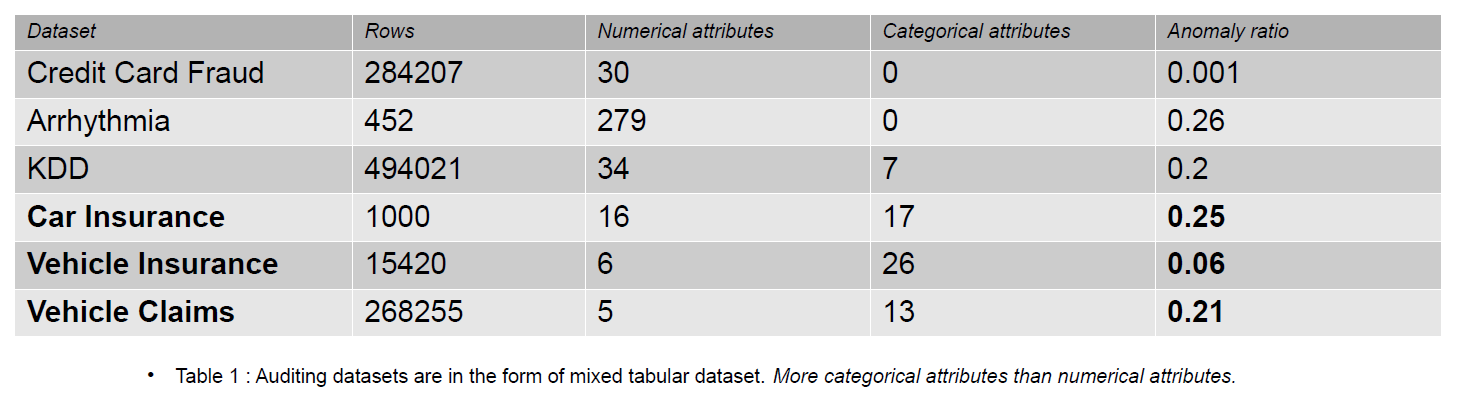
Az auditálási adatok magukban foglalhatják a naplókat, a biztosítási követeléseket és az információs rendszerek behatolási adatait; Ebben a cikkben a példák a gépjárművek biztosítási követelései. A biztosítási kárigények nagyobb számú kategorikus jellemzővel különböztethetők meg az anomália-észlelési adatkészletektől, például a KDD-től.
A kategorikus jellemzők az adataink diszkutjai, amelyek lehetnek egész vagy karakteresek. A numerikus jellemzők folyamatos attribútumok az adatainkban, amelyek mindig valós értékűek. A numerikus jellemzőkkel rendelkező adatkészletek népszerűek az anomália-észlelési közösségben, például a hitelkártya-csalási adatok. A legtöbb nyilvánosan elérhető adatkészlet kevesebb kategorikus jellemzőt tartalmaz, mint a biztosítási káradatok. A kategorikus jellemzők nagyobb számban szerepelnek, mint a numerikus jellemzők a biztosítási kárigények adatkészleteiben.
A biztosítási igény olyan jellemzőket tartalmaz, mint a modell, márka, bevétel, költség, kiadás, szín stb. A kategorikus jellemzők száma magasabb az auditálási adatokban, mint a hitelkártya és a KDD adatkészletekben. Ezek az adatkészletek referenciaértékek a felügyelet nélküli anomália-észlelési módszerekben. Amint az alábbi táblázatban látható, a biztosítási kárigény-adatkészletek kategorikusabb jellemzőkkel rendelkeznek, amelyek fontosak a hamis adatok viselkedésének megértéséhez.
A kategorikus kódolások hatásának értékelésére használt auditálási adatkészletek a következők: Autóbiztosítás, Járműbiztosítás és Gépjármű-igények.
Mi az anomália észlelése?
Az anomália olyan megfigyelés, amely egy adathalmaz normál adataitól egy meghatározott távolságra (küszöbérték) távol esik. Az adatok auditálása szempontjából előnyben részesítjük a csaló adat kifejezést. Az anomália-észlelés gépi tanulás vagy mély tanulási modell segítségével megkülönbözteti a normál és a hamis adatokat. Különböző módszerek használható anomáliák kimutatására, például sűrűségbecslésre, rekonstrukciós hibára és osztályozási módszerekre.
- Sűrűségbecslés – Ezek a módszerek megbecsülik a normál adateloszlást, és osztályozzák az anomális adatokat, ha nem vettek mintát a tanult eloszlásból.
- Rekonstrukciós hiba – A rekonstrukciós hiba alapú módszerek azon az elven alapulnak, hogy a normál adatok kisebb veszteséggel rekonstruálhatók, mint az anomális adatok. Minél nagyobb a rekonstrukciós veszteség, annál nagyobb az esélye annak, hogy az adat anomáliát jelent.
- Osztályozási módszerek - Osztályozási módszerek, mint pl Véletlen Erdő, Isolation Forest, One Class – Support Vector Machines és Local Outlier Factors használhatók az anomáliák kimutatására. Az anomália-észlelésben az osztályozás magában foglalja az egyik osztály anomáliaként való azonosítását. Ennek ellenére az osztályok két csoportra (0 és 1) vannak osztva a többosztályos forgatókönyvben, és a kevesebb adatot tartalmazó osztály az anomális osztály.
A fenti módszerek kimenetele anomália pontszámok vagy rekonstrukciós hibák. Ezután döntenünk kell egy küszöbről, amely szerint osztályozzuk az anomális adatokat.
Az adatok auditálása során felmerülő főbb kihívások
- Kategorikus tulajdonságok kezelése: A kategorikus attribútumok kódolása kötelező, mert a modell nem tudja értelmezni a szövegbevitelt. Tehát az értékek Label kódolással vagy One Hot kódolással vannak kódolva. Egy nagy adatkészletben azonban a One hot encoding az attribútumok számának növelésével nagy dimenziós térré alakítja az adatokat. A modell gyengén teljesít a a dimenzionalitás átka.
- Az osztályozási küszöb kiválasztása: Ha az adatok nincsenek címkézve, akkor nehéz a modell teljesítményét értékelni, mert nem ismerjük az adathalmazban előforduló anomáliák számát. Az adatkészlettel kapcsolatos előzetes ismeretek megkönnyítik a küszöb meghatározását. Tegyük fel, hogy adataink között 5-ből 10 rendellenes minta szerepel. Tehát kiválaszthatjuk a küszöböt az 50 százalékos pontszámnál.
- Nyilvános adatkészletek: A legtöbb auditálási adatkészlet bizalmas, mivel vállalati vállalatokhoz tartoznak, és érzékeny és személyes információkat tartalmaznak. A titoktartási problémák mérséklésének egyik lehetséges módja a szintetikus adatkészletek (Vehicle Claims) használatának oktatása.
Adatkészletek auditálása anomáliák észleléséhez
A gépjárművekre vonatkozó biztosítási kárigények a jármű tulajdonságaira vonatkozó információkat tartalmaznak, mint például a modell, a márka, az ár, az évjárat és az üzemanyag típusa. Információkat tartalmaz a sofőrről, a születési dátumról, a nemről és a szakmáról. Ezenkívül a követelés tartalmazhat információkat a javítás teljes költségéről. A cikkben használt adatkészletek mindegyike egyetlen tartományból származik, de az attribútumok és a példányok száma eltérő.
-
A Vehicle Claims adatkészlet nagy, több mint 250,000 1171 sort tartalmaz, és kategoriális attribútumainak száma XNUMX. Nagy mérete miatt ez az adatkészlet szenved a dimenzionalitás átkától.
- A Járműbiztosítás adatkészlet közepes méretű, 15,420 151 sorral és XNUMX egyedi kategorikus értékkel rendelkezik. Ezáltal kevésbé hajlamos a dimenzionalitás átka elszenvedésére.
- Az Autóbiztosítási adatkészlet kicsi, címkékkel és 25%-ban anomáliás mintákkal, és hasonló számú numerikus és kategorikus jellemzőt tartalmaz. 169 egyedi kategóriájával nem szenved a dimenzionalitás átkától.
Kategorikus attribútumok kódolása
Kategorikus értékek különböző kódolásai
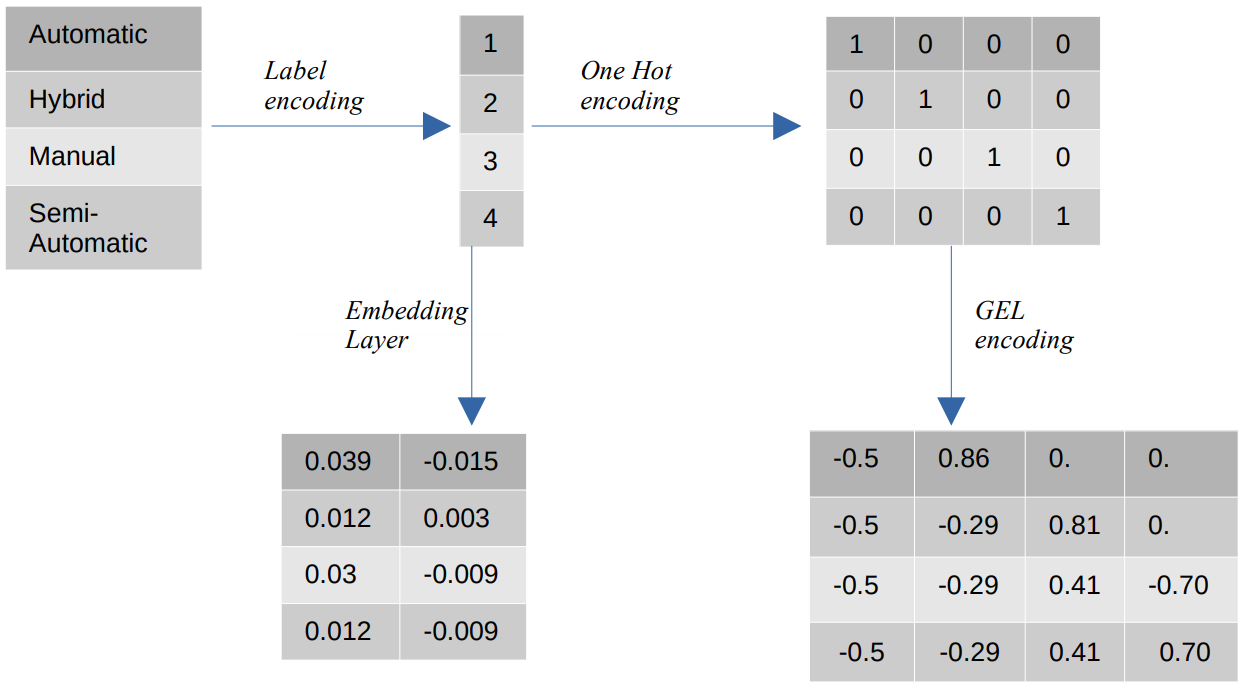
- Címkekódolás – A címkekódolásban a kategorikus értékeket 1 és a kategóriák száma közötti numerikus egész értékekre cseréljük. A címkekódolás a kategóriákat a sorrendi értékeknek szánt módon reprezentálja. Mégis, ha a jellemzők névlegesek, az ábrázolás helytelen, mivel a kategorikus értékek nem felelnek meg egy meghatározott sorrendnek.
Például, ha egy szolgáltatásban olyan kategóriák vannak, mint az Automatikus, Hibrid, Kézi és Félautomata, a címkekódolás ezeket az értékeket {1: Automatic, 2: Hibrid, 3: Manual, 4:Semi-Automatic} értékké alakítja. Ez az ábrázolás nem ad információt a kategorikus értékekről, de az olyan ábrázolások, mint például a {0: Alacsony, 1: Közepes, 2: Magas} egyértelmű megjelenítést adnak, mivel az Alacsony jellemzőváltozóhoz alacsonyabb számérték van hozzárendelve. Ezért a címkekódolás jobb az ordinális értékeknél, de hátrányos a névleges értékeknél. - One Hot Encoding – A névleges kódolási értékek problémájának megoldására a One Hot kódolást használják, amely minden kategorikus értéket a bináris értékekből álló adatkészletben különálló jellemzővé alakít át. Például négy különböző, {1, 2, 3, 4} kódolású kategória esetén a One Hot kódolás új funkciókat hoz létre, mint például {Automatic: [1,0,0,0], Hibrid: [0,1,0,0 ,0,0,1,0], Kézi: [0,0,0,1], Félautomata: [XNUMX]}.
Az adatkészlet dimenziója ezután közvetlenül függ az adatkészletben található kategóriák számától. Ennek eredményeként a One Hot kódolás a dimenzionalitás átkához vezethet, ami ennek a kódolási módszernek a hátránya. - GEL kódolás – A GEL kódolás egy beágyazási technika, amely felügyelt és felügyelet nélküli tanulási módszerekben is használható. A One Hot kódolás elvén alapul, és a One Hot kódolással kódolt kategorikus jellemzők dimenziójának csökkentésére használható.
- Réteg beágyazása - A szóbeágyazások lehetőséget biztosítanak egy kompakt és sűrű ábrázolás használatára, amelyben a hasonló szavak hasonló kódolásúak. A beágyazás olyan lebegőpontos értékek sűrű vektora, amelyek betanítható paraméterek. A Word-beágyazások 8-dimenzióstól (kis adatkészletekhez) 1024-dimenziósig (nagy adatkészletekhez) terjedhetnek.
A nagyobb dimenziójú beágyazás részletesebb kapcsolatokat rögzíthet a szavak között, de több adatot igényel a tanuláshoz. A beágyazási réteg egy keresőtábla, amely a mátrixban lévő minden szót meghatározott méretű vektorokká alakít.
Felügyelet nélküli anomália-észlelő modellek
A való világban az adatok a legtöbb esetben nincsenek címkézve, és az adatok címkézése drága és időigényes. Ezért értékeléseinkhez felügyelet nélküli modelleket fogunk használni.
- SOM - A Self-Organizing Map (SOM) egy versengő tanulási módszer, ahol a neuronok súlyát kompetitív módon frissítik, nem pedig a backpropagation tanulást. A SOM neuronok térképéből áll, amelyek mindegyikének súlyvektora megegyezik a bemeneti vektorral. A súlyvektor véletlenszerű súlyokkal inicializálódik az edzés megkezdése előtt. A betanítás során minden bemenetet összehasonlítanak a térkép neuronjaival egy távolságmérő (pl. euklideszi távolság) alapján, és leképezik a legjobb egyezési egységre (BMU, Best Matching Unit), amely a bemeneti vektortól minimális távolsággal rendelkező neuron.
A BMU súlyai a bemeneti vektor súlyaival frissülnek, a szomszédos neuronok pedig a szomszédsági sugár (szigma) alapján. Mivel a neuronok egymással versengenek a legjobban illeszkedő egységért, ezt a folyamatot kompetitív tanulásnak nevezik. Végül a normál minták neuronjai közelebb vannak, mint az anomálisak. Az anomália pontszámait a kvantálási hiba határozza meg, amely a bemeneti minta és a legjobban illeszkedő egység súlyai közötti különbség. A nagyobb kvantálási hiba azt jelzi, hogy nagyobb a valószínűsége annak, hogy a minta anomália. - DAGMM – A Deep Autoencoding Gaussian Mixture Model (DAGMM) egy sűrűségbecslési módszer, amely feltételezi, hogy az anomáliák egy kis valószínűségű régióban találhatók. A hálózat két részre oszlik: egy tömörítő hálózatra, amely egy autoencoder segítségével az adatok alacsonyabb dimenziókba történő kivetítését szolgálja, valamint egy becslési hálózatra, amely a Gauss-féle keverékmodell paramétereinek becslésére szolgál. A DAGMM megbecsüli k számú Gauss-elegyet, ahol k tetszőleges szám lehet 1-től N-ig (az adatpontok száma), és feltételezzük, hogy a normál pontok egy nagy sűrűségű tartományban helyezkednek el, ami azt jelenti, hogy a mintavétel valószínűsége A Gauss-elegy magasabb a normál pontoknál, mint az anomális mintáknál. Az anomália pontszámokat a minta becsült energiája határozza meg.
- RSRAE – A Felügyelet nélküli anomália-észlelés robusztus felület-helyreállítási rétege egy olyan rekonstrukciós hibamódszer, amely először egy automatikus kódoló segítségével alacsonyabb dimenzióba vetíti az adatokat. A látens reprezentációt ezután ortogonális vetületnek vetik alá egy lineáris altérre, amely robusztus a kiugró értékekre. A dekóder ezután rekonstruálja a lineáris altér kimenetét. Ennél a módszernél a nagyobb rekonstrukciós hiba azt jelzi, hogy nagyobb a valószínűsége annak, hogy a minta anomália.
- SOM-DAGMM- Az önszervező térkép (SOM) – Mélyen Autoencoding Gaussian Mixture Model (DAGMM) egyben sűrűségbecslési modell is. A DAGMM-hez hasonlóan a normál adatpontok valószínűségi eloszlását is megbecsüli, és egy adatpontot anomáliának minősít, ha kicsi a valószínűsége annak, hogy a tanult eloszlásból mintavételre kerül. A fő különbség a SOM-DAGMM és a DAGMM között az, hogy a SOM-DAGMM tartalmazza a SOM normalizált koordinátáit a bemeneti mintához, amely DAGMM esetén a hiányzó topológiai információkat szolgáltatja a becslési hálózatnak. A cél abban is hasonló a DAGMM-hez, hogy az anomália pontszámokat a minta becsült energiája határozza meg, az alacsony energia pedig a minta anomáliájának nagyobb valószínűségét jelzi.
Ezután a kategorikus attribútumok kezelésének kihívásával foglalkozunk.
Hogyan hat a kategorikus attribútumok kódolása a modellekre?
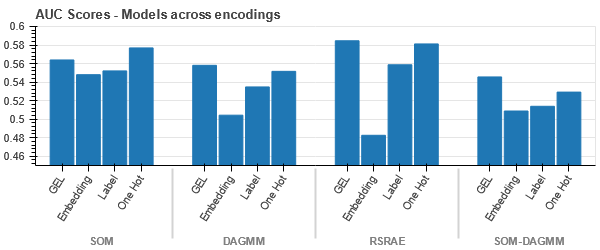
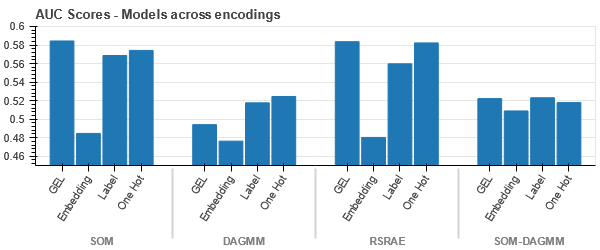
A különböző kódolások adatkészletekre gyakorolt hatásának megértéséhez a t-SNE-t fogjuk használni az adatok alacsony dimenziós reprezentációinak megjelenítésére a különböző kódolásokhoz. A t-SNE a nagy dimenziós adatokat egy alacsonyabb dimenziójú térbe vetíti, így könnyebben láthatóvá válik. Ha összehasonlítjuk a t-SNE vizualizációkat és ugyanannak az adatkészletnek a különböző kódolásainak numerikus eredményeit, a különbség megfigyelhető a kapott reprezentációkban és a kódolásnak az adatkészletre gyakorolt hatásának megértésében.
Az autóbiztosítási adatkészlet t-SNE reprezentációja
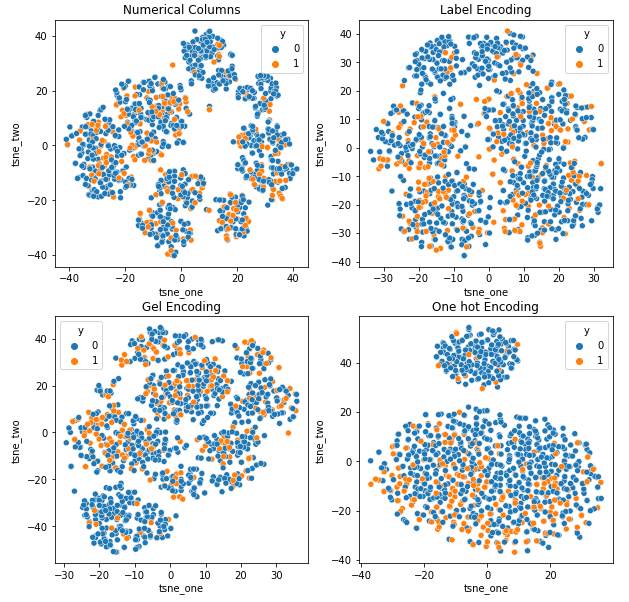
A járműbiztosítási adatkészlet t-SNE reprezentációja
-
Az adatok közelebb állnak egymáshoz, mert a sorok száma magasabb, mint az Autóbiztosítás adatkészletében. A One Hot kódolás megnövekedett dimenziójával nehéz elválasztani.
-
A GEL kódolás minden esetben jobb, mint a One Hot kódolás, kivéve a DAGMM-et.
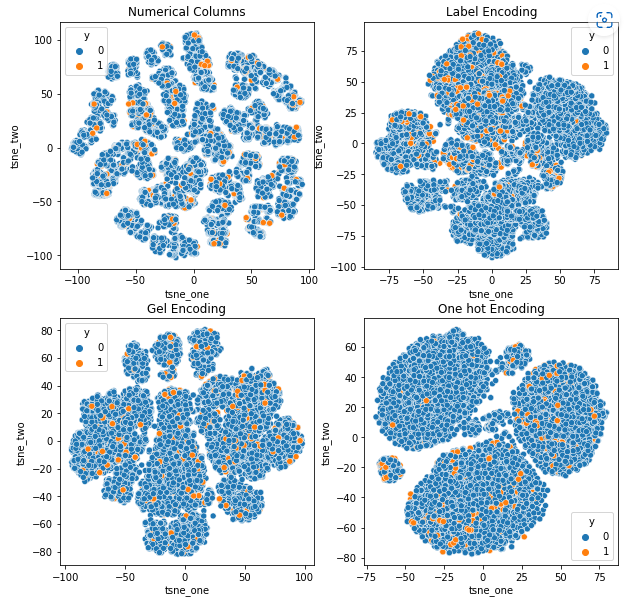
A Vehicle Claims adatkészlet t-SNE reprezentációja
-
Az adatok minden esetben szorosan kötöttek, ami megnehezíti az elkülönítést a megnövekedett dimenzióval. Ez az egyik oka a modellek gyenge teljesítményének a megnövekedett méretek miatt.
- A SOM felülmúlja az összes többi modellt ennél az adatkészletnél. Ennek ellenére a legtöbb esetben a beágyazási réteg alkalmasabb, ami alternatívát kínál a kódolás helyett kategorikus tulajdonságok az anomália észlelésére.
Következtetés
Ez a cikk rövid áttekintést nyújt az auditálási adatokról, az anomáliák észleléséről és a kategorikus kódolásokról. Fontos megérteni, hogy a kategorikus attribútumok kezelése az adatok auditálása során kihívást jelent. Ha megértjük az attribútumok kódolásának a modellekre gyakorolt hatását, javíthatjuk az anomáliák észlelésének pontosságát az adatkészletekben. Ennek a cikknek a legfontosabb elemei a következők:
- Az adatok méretének növekedésével fontos, hogy a kategorikus attribútumokhoz alternatív kódolási módszereket alkalmazzunk, mint például a GEL-kódolás és a rétegek beágyazása, mivel a One Hot kódolás nem megfelelő.
- Egy modell nem működik minden adatkészlethez. A táblázatos adatkészletek esetében a domain ismerete rendkívül fontos.
- A kódolási módszer kiválasztása a modell választásától függ.
A modellek értékelésének kódja a következő címen érhető el: GitHub.
A cikkben bemutatott média nem az Analytics Vidhya tulajdona, és a szerző saját belátása szerint használja.
Összefüggő
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- Rólunk
- felett
- Szerint
- pontosság
- Ezen kívül
- cím
- Minden termék
- lehetővé teszi, hogy
- alternatív
- mindig
- analitika
- Analytics Vidhya
- és a
- anomália észlelése
- megközelít
- cikkben
- kijelölt
- társult
- feltételezte
- attribútumok
- könyvvizsgálat
- Automatikus
- elérhető
- alapján
- mert
- válik
- előtt
- hogy
- lent
- referenciaértékek
- BEST
- Jobb
- között
- Legnagyobb
- köteles
- márka
- nem tud
- elfog
- autó
- autó biztosítás
- kártya
- eset
- esetek
- kategóriák
- kihívás
- kihívások
- kihívást
- esély
- karakter
- választás
- követelés
- követelések
- osztály
- osztályok
- besorolás
- osztályoz
- világos
- közelebb
- kód
- szín
- általában
- közösség
- Companies
- képest
- összehasonlítva
- versenyez
- versenyképes
- bonyolult
- koncepció
- titoktartási
- Összeáll
- tartalmaz
- folyamatos
- Társasági
- Költség
- teremt
- hitel
- hitelkártya
- dátum
- adat pontok
- adatkészletek
- találka
- foglalkozó
- csökkenés
- mély
- mély tanulás
- függ
- részletes
- Érzékelés
- Határozzuk meg
- különbség
- különböző
- nehéz
- Dimenzió
- méretek
- közvetlenül
- belátása
- távolság
- különböző
- terjesztés
- megosztott
- domain
- gépkocsivezető
- alatt
- minden
- könnyebb
- bármelyik
- energia
- hiba
- hibák
- becslés
- becsült
- becslések
- stb.
- értékelni
- értékelés
- értékelések
- példa
- példák
- Kivéve
- drága
- rendkívüli módon
- szembe
- tényezők
- Funkció
- Jellemzők
- vezetéknév
- erdő
- csalás
- csaló
- ból ből
- Üzemanyag
- nem
- Csoportok
- Kezelés
- Magas
- <p></p>
- FORRÓ
- azonban
- HTTPS
- hibrid
- azonosító
- Hatás
- fontos
- javul
- in
- tartalmaz
- magában foglalja a
- Jövedelem
- <p></p>
- Növeli
- növekvő
- jelzi
- információ
- Információs Rendszerek
- bemenet
- biztosítás
- szigetelés
- kérdés
- kérdések
- IT
- Kulcs
- Ismer
- tudás
- ismert
- Címke
- címkézés
- Címkék
- nagy
- nagyobb
- réteg
- tojók
- vezet
- TANUL
- tanult
- tanulás
- helyi
- található
- lookup
- le
- veszteség
- Elő/Utó
- gép
- gépi tanulás
- gép
- Fő
- KÉSZÍT
- Gyártás
- kötelező
- kézikönyv
- sok
- térkép
- egyező
- Mátrix
- jelenti
- Média
- közepes
- módszer
- mód
- metrikus
- minimum
- hiányzó
- Enyhít
- keverék
- modell
- modellek
- több
- a legtöbb
- hálózat
- neuronok
- Új
- Új funkciók
- normális
- szám
- célkitűzés
- ONE
- érdekében
- Más
- felülmúlja
- Overcome
- áttekintés
- tulajdonú
- paraméterek
- rész
- alkatrészek
- teljesítmény
- Előadja
- személyes
- Plató
- Platón adatintelligencia
- PlatoData
- pont
- pont
- szegény
- Népszerű
- lehetséges
- jobban szeret
- be
- ajándékot
- ár
- alapelv
- Előzetes
- valószínűség
- Probléma
- folyamat
- szakma
- program
- projekt adatai
- Vetítés
- projektek
- ingatlanait
- ad
- feltéve,
- biztosít
- közzétett
- véletlen
- hatótávolság
- igazi
- való Világ
- miatt
- felépülés
- vidék
- Kapcsolatok
- javítás
- helyébe
- képviselet
- jelentése
- megköveteli,
- eredményez
- kapott
- Eredmények
- erős
- azonos
- Tudomány
- érzékeny
- különálló
- mutatott
- Sigma
- hasonló
- óta
- egyetlen
- Méret
- kicsi
- kisebb
- So
- Hely
- különleges
- kezdődik
- Még mindig
- ilyen
- szenved
- megfelelő
- támogatás
- felületi
- szintetikus
- Systems
- táblázat
- Elvitelre
- feltételek
- A
- a világ
- ebből adódóan
- küszöb
- szorosan
- időigényes
- nak nek
- Végösszeg
- Vonat
- Képzések
- megért
- megértés
- egyedi
- egység
- felügyelet nélküli tanulás
- frissítve
- us
- használ
- érték
- Értékek
- jármű
- Járművek
- súly
- Mit
- Mi
- ami
- míg
- lesz
- szó
- szavak
- Munka
- világ
- lenne
- év
- zephyrnet