Bevezetés
A következő szó azonosítása a következő szó előrejelzésének, más néven nyelvi modellezésnek a feladata. Az egyik NLPbenchmark feladatai a nyelvi modellezés. A legalapvetőbb formájában azt jelenti, hogy kiválasztjuk azt a szót, amely a legvalószínűbb előfordulásukra épülő szósort követi. Számos területen a nyelvi modellezésnek sokféle alkalmazása van.
Tanulási cél
- Ismerje fel a statisztikai elemzésben, a gépi tanulásban és az adattudományban használt számos modell mögött meghúzódó ötleteket és elveket.
- Ismerje meg, hogyan hozhat létre prediktív modelleket, beleértve a regressziót, az osztályozást, a klaszterezést stb., hogy adatokon alapuló precíz előrejelzéseket és típusokat állítson elő.
- Ismerje meg a túl- és alulillesztés alapelveit, és tanulja meg, hogyan értékelje a modell teljesítményét olyan mérőszámok segítségével, mint a pontosság, precizitás, visszahívás stb.
- Tanulja meg az adatok előfeldolgozását és a modellezéshez szükséges jellemzők azonosítását.
- Tanulja meg a hiperparaméterek módosítását és a modellek optimalizálását a rácskeresés és a keresztellenőrzés segítségével.
Ez a cikk részeként jelent meg Adattudományi Blogaton.
Tartalomjegyzék
A nyelvmodellezés alkalmazásai
Íme néhány figyelemre méltó nyelvi modellezési alkalmazás:
Mobil billentyűzet szöveges ajánlás
Az okostelefonok billentyűzetén található mobilbillentyűzet-szöveg-ajánlásnak, vagy prediktív szöveges vagy automatikus javaslatnak nevezett funkciója szavakat vagy kifejezéseket javasol írás közben. Arra törekszik, hogy a gépelést gyorsabbá és kevésbé hibássá tegye, valamint pontosabb és kontextusnak megfelelő ajánlásokat kínáljon.
Is Read: Tartalom alapú ajánlórendszer felépítése
Google Keresés automatikus kiegészítése
Minden alkalommal, amikor egy olyan keresőmotort használunk, mint a Google, hogy bármit keressünk, sok ötletet kapunk, és ahogy folyamatosan adunk hozzá kifejezéseket, az ajánlások egyre jobbak és relevánsabbak az aktuális kereséshez. Akkor hogyan fog történni?
A természetes nyelvi feldolgozás (NLP) technológia teszi ezt megvalósíthatóvá. Itt természetes nyelvi feldolgozást (NLP) fogunk alkalmazni, hogy egy kétirányú LSTM (hosszú rövid távú memória) modellt használó predikciós modellt hozzunk létre a mondat fennmaradó szavainak előrejelzésére.
További információk: Mi az LSTM? Bevezetés a hosszú távú rövid távú memóriába
Importálja a szükséges könyvtárakat és csomagokat
A szükséges könyvtárak és csomagok importálása a következő szó előrejelzési modelljének kétirányú LSTM segítségével történő létrehozásához lenne a legjobb. Az alábbiakban látható egy példa azokra a könyvtárakra, amelyekre általában szüksége lesz:
import pandas as pd
import os
import numpy as np import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import AdamAdatkészlet információ
Az Ön által kezelt adatkészlet jellemzőinek és attribútumainak megértéséhez ismeretekre van szükség. A következő hét, véletlenszerűen kiválasztott és 2019-ben megjelent publikáció közepes cikke szerepel ebben az adatkészletben:
- Az adattudomány felé
- UX Kollektív
- A Startup
- Az Írószövetkezet
- Adatvezérelt befektető
- Jobb Emberek
- Jobb marketing
Adatkészlet link: https://www.kaggle.com/code/ysthehurricane/next-word-prediction-bi-lstm-tutorial-easy-way/input
medium_data = pd.read_csv('../input/medium-articles-dataset/medium_data.csv')
medium_data.head()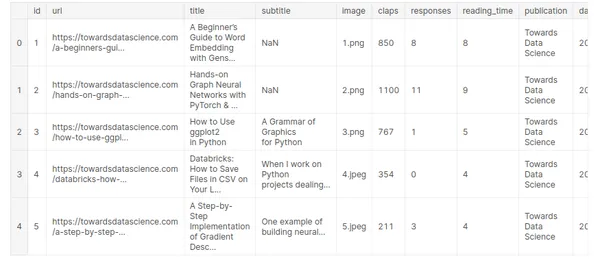
Itt tíz különböző mezőnk és 6508 rekordunk van, de csak a címmezőt használjuk a következő szó előrejelzésére.
print("Number of records: ", medium_data.shape[0])
print("Number of fields: ", medium_data.shape[1])
Az adatkészlet információinak áttekintésével és megértésével kiválaszthatja az előfeldolgozási eljárásokat, a modellt és a kiértékelési mérőszámokat a következő szó-előrejelzési kihíváshoz.
Különböző cikkek címeinek megjelenítése és előfeldolgozása
Nézzünk meg néhány mintacímet a cikkcímek elkészítésének illusztrálására:
medium_data['title']
A nem kívánt karakterek és szavak eltávolítása a címekből
A szöveges adatok előrejelzési feladatokhoz való előfeldolgozása néha magában foglalja a nemkívánatos betűk és kifejezések eltávolítását a címekből. A nem kívánt betűk és szavak zajjal szennyezhetik az adatokat, és szükségtelenül bonyolulttá tehetik, ezáltal csökkentve a modell teljesítményét és pontosságát.
- Nem kívánt karakterek:
- Központozás: Távolítsa el a felkiáltójeleket, kérdőjeleket, vesszőket és egyéb írásjeleket. Általában nyugodtan eldobhatja őket, mert általában nem segítenek az előrejelzési feladatban
- Speciális karakterek: Távolítsa el a nem alfanumerikus szimbólumokat, például a dollárjeleket, a @ szimbólumokat, a hashtageket és az egyéb speciális karaktereket, amelyek nem szükségesek az előrejelzési feladathoz.
- HTML címkék: Ha a címek HTML-jelöléseket vagy címkéket tartalmaznak, távolítsa el őket a megfelelő eszközök vagy könyvtárak segítségével a szöveg kibontásához.
- Nem kívánt szavak:
- Stop szavak: Távolítsa el az olyan gyakori leállító szavakat, mint az „a”, „an”, „a”, „van”, „benne” és más gyakran előforduló szavak, amelyek nem hordoznak jelentős jelentést vagy előrejelző erőt.
- Irreleváns szavak: Azonosítson és távolítson el olyan szavakat, amelyek nem relevánsak az előrejelzési feladathoz vagy tartományhoz. Például, ha filmműfajokat jósol, előfordulhat, hogy az olyan szavak, mint a „film” vagy a „film”, nem nyújtanak hasznos információkat.
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace(u'xa0',u' '))
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace('u200a',' '))
tokenizálás
tokenizálás felosztja a szöveget tokenekre, szavakra, részszavakra vagy karakterekre, majd minden tokenhez egyedi azonosítót vagy indexet rendel, szóindexet vagy szókincset létrehozva.
A tokenizálási folyamat a következő lépésekből áll:
Szöveg előfeldolgozás: Elődolgozza a szöveget az írásjelek elhagyásával, kisbetűsre cserélésével, és ügyeljen minden konkrét feladat- vagy tartományspecifikus igényre.
Tokenizálás: Az előfeldolgozott szöveg felosztása külön tokenekre előre meghatározott szabályok vagy módszerek szerint. A reguláris kifejezések, a szóközzel történő elválasztás és a speciális tokenizátorok használata mind gyakori tokenizációs technikák.
Szókincs bővítése Szótárat, más néven szóindexet készíthet úgy, hogy minden tokenhez egyedi azonosítót vagy indexet rendel. Ebben a folyamatban minden jegy hozzá van rendelve a megfelelő indexértékhez.
tokenizer = Tokenizer(oov_token='<oov>') # For those words which are not found in word_index
tokenizer.fit_on_texts(medium_data['title'])
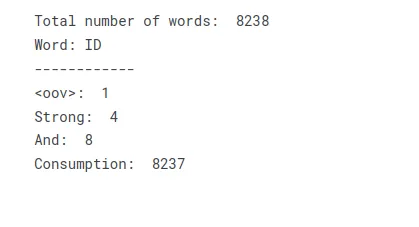
total_words = len(tokenizer.word_index) + 1 print("Total number of words: ", total_words)
print("Word: ID")
print("------------")
print("<oov>: ", tokenizer.word_index['<oov>'])
print("Strong: ", tokenizer.word_index['strong'])
print("And: ", tokenizer.word_index['and'])
print("Consumption: ", tokenizer.word_index['consumption'])Ha a szöveget szókincské vagy szóindexmé alakítja, létrehozhat egy keresési táblázatot, amely a szöveget numerikus indexek gyűjteményeként ábrázolja. A szövegben szereplő minden egyedi szó megfelelő indexértéket kap, ami lehetővé teszi a további feldolgozási vagy modellezési műveleteket, amelyek numerikus bevitelt igényelnek.
Címek szöveget szekvenciákba és Make N_gram modell.
Ezek a szakaszok felhasználhatók egy n-gramm modell felépítésére a címsorozatok alapján történő pontos előrejelzéshez:
- Címek konvertálása sorozatokká: Használjon tokenizert, hogy minden címet tokenek láncává alakítson, vagy manuálisan válassza szét az egyes cédulákat alkotó szavakká. Rendeljen a lexikon minden szavához külön számindexet.
- n-gramm generálása: A sorozatokból készítsünk n-grammokat. Az n-című tokenek folyamatos futtatását n-gramnak nevezzük.
- Számolja meg a gyakoriságot: Határozza meg, hogy az egyes n-gramok milyen gyakorisággal jelenjenek meg az adatkészletben.
- Építsd meg az n-gram modellt: Készítse el az n-grammodellt az n-gramos frekvenciák felhasználásával. A modell nyomon követi az egyes token valószínűségeket az előző n-1 tokenek alapján. Ez megjeleníthető keresőtáblaként vagy szótárként.
- A következő szó megjóslása: Az n-1 token sorozatban várható következő tokent az n-gram modell segítségével azonosíthatjuk. Ehhez meg kell találni a valószínűséget az algoritmusban, és ki kell választani a legnagyobb valószínűségű tokent.
További információk: Mik azok az N-gramok, és hogyan lehet őket megvalósítani a Pythonban?
Ezekkel a lépésekkel olyan n-grammodellt hozhat létre, amely a címek sorozatait használja a következő szó vagy token megjóslására. A betanítási adatok alapján ez a módszer pontos előrejelzéseket tud készíteni, mivel rögzíti a címek nyelvhasználatának statisztikai összefüggéseit és trendjeit.

input_sequences = []
for line in medium_data['title']: token_list = tokenizer.texts_to_sequences([line])[0] #print(token_list) for i in range(1, len(token_list)): n_gram_sequence = token_list[:i+1] input_sequences.append(n_gram_sequence) # print(input_sequences)
print("Total input sequences: ", len(input_sequences))
Tegye az összes címet egyforma hosszúságúvá a kitöltés használatával
Az alábbi lépések végrehajtásával kitöméssel biztosíthatja, hogy minden cím azonos méretű legyen:
- Keresse meg az adatkészlet leghosszabb címét az összes többi cím összehasonlításával.
- Ismételje meg ezt a folyamatot minden címnél, és hasonlítsa össze mindegyik hosszát a teljes korláttal.
- Ha egy cím túl rövid, ki kell bővíteni egy speciális kitöltő token vagy karakter segítségével.
- Az adatkészlet minden egyes címénél hajtsa végre újra a kitöltési eljárást.
A kitöltés biztosítja, hogy minden cím azonos hosszúságú legyen, és következetességet biztosít az utófeldolgozáshoz vagy a modellképzéshez.
# pad sequences max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
input_sequences[1]
Készítsen funkciókat és címkéket
Az adott forgatókönyvben, ha az egyes bemeneti sorozatok utolsó elemét tekintjük címkének, akkor egy-hot kódolást hajthatunk végre a címeken, hogy azokat az egyedi szavak teljes számának megfelelő vektorokként ábrázoljuk.
# create features and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words) print(xs[5])
print(labels[5])
print(ys[5][14])
A kétirányú LSTM neurális hálózat architektúrája
Ismétlődő neurális hálózatok (RNN-ek) a Long Short-Term Memory (LSTM) segítségével kiterjedt szekvenciákon keresztül gyűjthet és tárolhat információkat. Az LSTM-hálózatok speciális memóriacellákat és kapuzási technikákat használnak a normál RNN-k korlátainak leküzdésére, amelyek gyakran küzdenek az eltűnő gradiens problémával, és gondot okoz a hosszú távú függőség fenntartása.
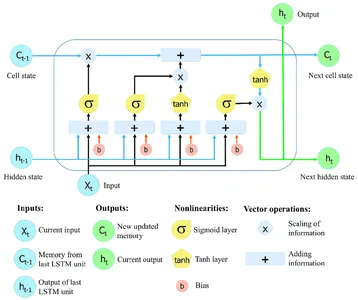
Az LSTM-hálózatok kritikus jellemzője a cella állapota, amely memóriaegységként szolgál, amely idővel információkat tárolhat. A cella állapotát három fő kapu védi és vezérli: a felejtőkapu, a bemeneti kapu és a kimeneti kapu. Ezek a kapuk szabályozzák az információáramlást az LSTM cellába, ki és az LSTM cellán belül, lehetővé téve a hálózat számára, hogy különböző időlépésekben szelektíven emlékezzen vagy felejtsen el információkat.
További információk: Hosszú rövid távú memória | Az LSTM építészete
Kétirányú LSTM
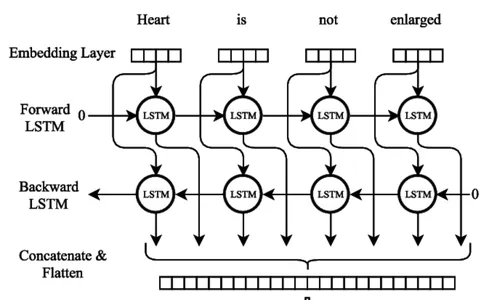
Bi-LSTM Neurális Hálózati Modell tréning
A kétirányú LSTM (Bi-LSTM) neurális hálózati modell betanítása során számos kulcsfontosságú eljárást kell követni. Az első lépés egy betanítási adatkészlet összeállítása a hozzájuk tartozó bemeneti és kimeneti szekvenciákkal, jelezve a következő szót. A szöveges adatokat külön sorokra bontva, az írásjelek eltávolításával és a kis- és nagybetűk kisbetűsre cserélésével kell előfeldolgozni.
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
history = model.fit(xs, ys, epochs=50, verbose=1)
#print model.summary()
print(model)
A fit() metódus meghívásával a modell betanításra kerül. A betanítási adatok a bemeneti szekvenciákból (xs) és a megfelelő kimeneti sorozatokból (ys) állnak. A modell 50 iteráción keresztül halad, végighaladva a teljes képzési készleten. Az edzési folyamat során megjelenik az edzés előrehaladása (beszéd=1).
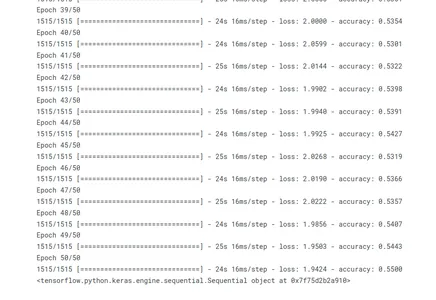
A modell pontosságának és veszteségének ábrázolása
A modell pontosságának és veszteségének ábrázolása a képzés során hasznos információkat nyújt arról, hogy a modell milyen jól teljesít és hogyan zajlik a képzés. A várt és a tényleges értékek közötti hibát vagy eltérést veszteségnek nevezzük. Míg a modell által generált pontos előrejelzések százalékos arányát pontosságnak nevezzük.
import matplotlib.pyplot as plt def plot_graphs(history, string): plt.plot(history.history[string]) plt.xlabel("Epochs") plt.ylabel(string) plt.show() plot_graphs(history, 'accuracy')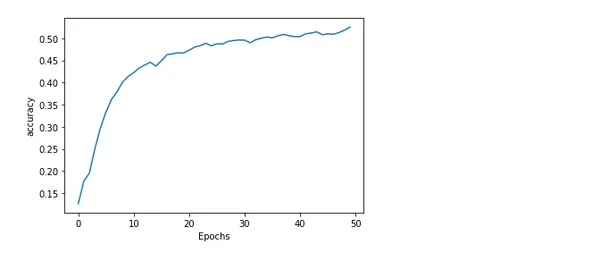
plot_graphs(history, 'loss')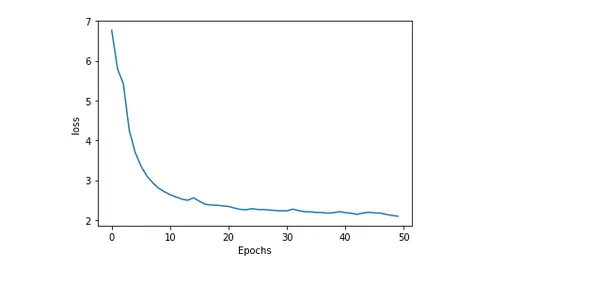
A cím következő szavának megjóslása
A természetes nyelvi feldolgozás lenyűgöző kihívása a következő szó kitalálása a címben. A modellek javaslatot tehetnek a legvalószínűbb beszédre, ha mintákat és összefüggéseket keresnek a szöveges adatokban. Ez a prediktív képesség lehetővé teszi az olyan alkalmazások használatát, mint a szövegjavaslat-rendszerek és az automatikus kiegészítés. Az olyan kifinomult megközelítések, mint az RNN-k és a transzformátor-alapú architektúrák, növelik a pontosságot és rögzítik a kontextuális kapcsolatokat.
seed_text = "implementation of"
next_words = 2 for _ in range(next_words): token_list = tokenizer.texts_to_sequences([seed_text])[0] token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre') predicted = model.predict_classes(token_list, verbose=0) output_word = "" for word, index in tokenizer.word_index.items(): if index == predicted: output_word = word break seed_text += " " + output_word
print(seed_text)
Következtetés
Összefoglalva, egy olyan modell betanítása, amely a szavak sorában következő szó előrejelzésére szolgál, az izgalmas természetes nyelvi feldolgozási kihívás, amelyet a következő szó előrejelzéseként ismerünk a kétirányú LSTM segítségével. Íme a következtetés pontokban összefoglalva:
- A szekvenciális adatfeldolgozás hatékony mély tanulási architektúrája, a BI-LSTM hosszú távú kapcsolatokat és kifejezéskontextust rögzíthet.
- A nyers szöveges adatok BI-LSTM képzéshez való előkészítéséhez elengedhetetlen az adatok előkészítése. Ez magában foglalja a tokenizálást, a szókincs létrehozását és a szöveg vektorizálását.
- A BI-LSTM modell betanításának lépései egy veszteségfüggvény létrehozása, a modell felépítése optimalizálóval, illesztése az előfeldolgozott adatokhoz, és a teljesítmény értékelése az érvényesítési halmazokon.
- A BI-LSTM következő szó előrejelzése az elméleti tudás és a gyakorlati kísérletezés kombinációját igényli.
- Az automatikus kiegészítési, nyelvi létrehozási és szövegjavaslati algoritmusok példák a következő szó előrejelzési modellalkalmazásaira.
A következő szó előrejelzésére szolgáló alkalmazások közé tartoznak a chatbotok, a gépi fordítás és a szövegkiegészítés. További kutatásokkal és fejlesztésekkel precízebb és kontextustudatosabb következő szó előrejelzési modelleket hozhat létre.
Gyakran ismételt kérdések
V. A következő szó előrejelzése egy NLP-feladat, ahol a modell előrejelzi, hogy melyik szó a legvalószínűbb, hogy egy adott szósorozatot vagy kontextust kövessen. Célja, hogy koherens és kontextuálisan releváns javaslatokat generáljon a következő szóhoz a képzési adatokból tanult minták és kapcsolatok alapján.
V. A következő szó előrejelzése általában az ismétlődő neurális hálózatokat (RNN) és azok változatait használja, mint például a hosszú rövid távú memóriát (LSTM) és a kapuzott ismétlődő egységet (GRU). Ezenkívül az olyan modellek, mint a Transformer-alapú architektúrák, mint például a GPT (Generative Pre-train Transformer) modellek, szintén jelentős előrelépést mutattak ebben a feladatban.
V. Általában a következő szó előrejelzéséhez való betanítási adatok előkészítésekor a szöveget szavak sorozataira osztja, és bemenet-kimenet párokat hoz létre. A megfelelő kimenet a következő szót jelöli az egyes bemeneti sorozatok szövegében. A szöveg előfeldolgozása magában foglalja az írásjelek eltávolítását, a szavak kisbetűssé alakítását, valamint a szöveg egyedi szavakká alakítását.
V. Kiértékelheti a következő szó előrejelzési modelljének teljesítményét olyan értékelési mérőszámok segítségével, mint a zavartság, a pontosság vagy a csúcspontosság. A zavartság azt méri, hogy a modell mennyire jósolja meg a következő szót a kontextusban. A pontossági mérőszámok összehasonlítják a megjósolt szót az alapigazsággal, míg a felső k pontosság a modell előrejelzését veszi figyelembe a top k legvalószínűbb megjegyzésen belül.
A cikkben bemutatott média nem az Analytics Vidhya tulajdona, és a szerző saját belátása szerint használja.
Összefüggő
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Autóipar / elektromos járművek, Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- BlockOffsets. A környezetvédelmi ellentételezési tulajdon korszerűsítése. Hozzáférés itt.
- Forrás: https://www.analyticsvidhya.com/blog/2023/07/next-word-prediction-with-bidirectional-lstm/
- :van
- :is
- :nem
- :ahol
- 1
- 100
- 13
- 14
- 20
- 2019
- 50
- 9
- a
- Rólunk
- pontosság
- pontos
- át
- tényleges
- Ádám
- hozzá
- hozzáadásával
- Ezen kívül
- fejlesztések
- újra
- célok
- algoritmus
- algoritmusok
- Minden termék
- lehetővé téve
- Is
- an
- elemzés
- analitika
- Analytics Vidhya
- és a
- várható
- bármilyen
- bármi
- alkalmazások
- megközelít
- megfelelő
- építészet
- VANNAK
- cikkben
- cikkek
- AS
- kérdezte
- értékelése
- At
- attribútumok
- autocomplete
- alapján
- alapvető
- BE
- mert
- mögött
- hogy
- lent
- benchmark
- BEST
- Jobb
- között
- blogaton
- szünet
- épít
- Épület
- de
- by
- hívott
- hívás
- TUD
- elfog
- fogások
- ami
- visz
- eset
- sejt
- Cellák
- kihívás
- változó
- karakter
- jellemzők
- karakter
- chatbots
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- besorolás
- csoportosítás
- ÖSSZEFÜGGŐ
- gyűjt
- gyűjtemény
- kombináció
- Hozzászólások
- Közös
- általában
- összehasonlítani
- összehasonlítva
- befejezés
- bonyolultság
- átfogó
- következtetés
- Fontolja
- úgy véli,
- áll
- alkotó
- korlátok
- konstrukció
- fogyasztás
- kontextus
- szövegre vonatkozó
- folyamatos
- vezérelt
- konvertáló
- összefüggések
- Megfelelő
- teremt
- létrehozása
- teremtés
- kritikai
- kritikus
- Jelenlegi
- dátum
- Adatok előkészítése
- adatfeldolgozás
- adat-tudomány
- foglalkozó
- mély
- mély tanulás
- sűrű
- függőség
- Határozzuk meg
- különböző
- belátása
- kijelző
- Megjelenik
- különböző
- megosztott
- oszt
- do
- Dollár
- domain
- ne
- hajtott
- alatt
- minden
- elem
- megszüntetése
- beágyazás
- Motor
- biztosítására
- korszakok
- alapvető
- stb.
- Eter (ETH)
- értékelni
- értékelték
- értékelés
- példa
- példák
- izgalmas
- várható
- kifejezések
- kiterjedt
- kivonat
- elbűvölő
- gyorsabb
- megvalósítható
- Funkció
- Jellemzők
- kevés
- mező
- Fields
- Találjon
- vezetéknév
- szerelvény
- áramlási
- következik
- követ
- következő
- következik
- A
- forma
- talált
- Frekvencia
- gyakran
- ból ből
- funkció
- további
- kapuzott
- Gates
- általában
- generál
- generált
- generáció
- nemző
- adott
- megy
- Google keresés
- legnagyobb
- Rács
- Földi
- Nő
- útmutató
- hands-on
- történik
- Legyen
- segít
- hasznos
- itt
- történelem
- tart
- Hogyan
- How To
- HTML
- HTTPS
- i
- ID
- ötletek
- azonosított
- azonosítani
- if
- végre
- végrehajtás
- importál
- javulás
- in
- tartalmaz
- beleértve
- magában foglalja a
- Beleértve
- Növelje
- index
- indexek
- jelezve
- egyéni
- információ
- bemenet
- éleslátó
- bele
- Bevezetés
- jár
- IT
- iterációk
- ITS
- Munka
- Tart
- keras
- tudás
- ismert
- Címke
- Címkék
- nyelv
- keresztnév
- tojók
- TANUL
- tanult
- tanulás
- Hossz
- kevesebb
- könyvtárak
- mint
- valószínűség
- Valószínű
- LIMIT
- vonal
- vonalak
- LINK
- Hosszú
- hosszú lejáratú
- néz
- keres
- lookup
- le
- leeresztés
- gép
- gépi tanulás
- gépi fordítás
- Fő
- fenntartása
- csinál
- KÉSZÍT
- kézzel
- sok
- mester
- mastering
- egyező
- matplotlib
- Lehet..
- jelenti
- intézkedések
- Média
- közepes
- Memory design
- módszer
- mód
- Metrics
- esetleg
- hiba
- Mobil
- modell
- modellezés
- modellek
- több
- a legtöbb
- film
- kell
- Természetes
- Természetes nyelv
- Természetes nyelvi feldolgozás
- elengedhetetlen
- Szükségtelen
- igények
- hálózat
- hálózatok
- ideg-
- neurális hálózat
- neurális hálózatok
- következő
- NLP
- Zaj
- figyelemre méltó
- szám
- számos
- számtalan
- előfordul
- előforduló
- of
- ajánlat
- Ajánlatok
- on
- ONE
- csak
- Művelet
- Optimalizálja
- or
- OS
- Más
- mi
- ki
- teljesítmény
- felett
- átfogó
- Overcome
- tulajdonú
- csomagok
- párna
- párok
- pandák
- rész
- különös
- minták
- százalék
- teljesít
- teljesítmény
- Előadja
- kifejezés
- Plató
- Platón adatintelligencia
- PlatoData
- pont
- lehetséges
- hatalom
- pre
- pontos
- Pontosság
- előre
- jósolt
- előrejelzésére
- előrejelzés
- Tippek
- jósolja
- előkészítés
- Készít
- előkészített
- előkészítése
- előző
- elvek
- valószínűség
- Probléma
- eljárás
- eljárások
- bevétel
- folyamat
- feldolgozás
- gyárt
- Haladás
- megfelelő
- javasol
- védett
- ad
- kiadványok
- közzétett
- Piton
- kérdés
- véletlen
- Nyers
- Olvass
- kap
- kap
- Ajánlást
- ajánlások
- nyilvántartások
- regresszió
- szabályos
- Szabályoz
- Kapcsolatok
- megmaradó
- eszébe jut
- eltávolítása
- eltávolítása
- képvisel
- képviselő
- jelentése
- szükség
- megköveteli,
- kutatás
- szabályok
- futás
- biztosan
- azonos
- forgatókönyv
- Tudomány
- Keresés
- kereső
- Keresi
- kiválasztott
- különálló
- elválasztó
- Sorozat
- szolgálja
- készlet
- Szettek
- hét
- rövid
- rövid időszak
- kellene
- mutatott
- jelentős
- Jelek
- óta
- Méret
- okostelefon
- néhány
- kifinomult
- speciális
- specializált
- különleges
- osztott
- állapota
- Állami
- statisztikai
- Lépés
- Lépései
- megáll
- tárolni
- Húr
- erős
- Küzdelem
- későbbi
- ilyen
- javasolja,
- Systems
- táblázat
- tart
- bevétel
- Beszél
- Feladat
- feladatok
- technikák
- Technológia
- tíz
- tensorflow
- kifejezés
- hogy
- A
- azok
- Őket
- akkor
- elméleti
- ezáltal
- Ezek
- ők
- ezt
- azok
- három
- Keresztül
- egész
- jegy
- idő
- Cím
- címei
- nak nek
- jelképes
- tokenizálás
- bontja le
- tokenek
- is
- szerszámok
- Végösszeg
- vágány
- kiképzett
- Képzések
- transzformátor
- transzformáló
- Fordítás
- Trends
- baj
- igazság
- FORDULAT
- típusok
- jellemzően
- mögöttes
- egyedi
- egység
- felesleges
- felesleges
- Használat
- használ
- használt
- használ
- segítségével
- rendszerint
- hasznosítja
- kihasználva
- érvényesítés
- érték
- Értékek
- fajta
- különféle
- volt
- we
- webp
- JÓL
- Mit
- Mi
- amikor
- mivel
- ami
- míg
- egész
- széles
- lesz
- val vel
- belül
- szó
- szavak
- lenne
- ír
- írás
- X
- te
- A te
- zephyrnet





