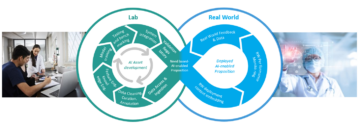
Sok vállalat túlterheli a rengeteg dokumentum feldolgozását, rendszerezését és osztályozását, hogy ügyfeleit jobban ki tudja szolgálni. Ilyen lehet például a hitelkérelem, az adóbevallás és a számlázás. Az ilyen dokumentumokat leggyakrabban képformátumban fogadják, és többnyire többoldalasak és rossz minőségű formátumúak. Ahhoz, hogy versenyképesebbek és költséghatékonyabbak legyenek, ugyanakkor biztonságban maradjanak és megfeleljenek a követelményeknek, ezeknek a vállalatoknak fejleszteniük kell dokumentumfeldolgozási képességeiket, hogy csökkentsék a feldolgozási időt és javítsák az osztályozási pontosságot automatizált és méretezhető módon. Ezeknek a cégeknek a következő kihívásokkal kell szembenézniük a dokumentumok feldolgozása során:
- Moderálás végrehajtása a dokumentumokon a nem megfelelő, nem kívánt vagy sértő tartalom észlelése érdekében
- A kézi dokumentumosztályozás, amelyet a kisebb cégek alkalmaznak, időigényes, hibás és költséges.
- A szabályokon alapuló rendszerekkel működő OCR technikák nem elég intelligensek, és nem tudnak alkalmazkodni a dokumentumformátum változásaihoz
- A gépi tanulási (ML) megközelítést alkalmazó vállalatok gyakran nem rendelkeznek erőforrásokkal ahhoz, hogy modelljüket úgy méretezzék, hogy kezeljék a bejövő dokumentummennyiség kiugrását.
Ez a bejegyzés ezekkel a kihívásokkal foglalkozik, és olyan architektúrát kínál, amely hatékonyan megoldja ezeket a problémákat. Mutatjuk, hogyan használhatod Amazon felismerés és a Amazon szöveg a dokumentumok feldolgozásával kapcsolatos emberi erőfeszítések optimalizálása és csökkentése. Az Amazon Rekognition azonosítja a moderációs címkéket a dokumentumban, és besorolja őket Amazon Rekognition egyéni címkék. Az Amazon Texttract kivonja a szöveget a dokumentumokból.
Ebben a bejegyzésben két ML-folyamat (képzés és következtetés) felépítésével foglalkozunk a dokumentumok feldolgozásához anélkül, hogy manuális erőfeszítésre vagy egyedi kódra lenne szükség. A következtetési folyamat magas szintű lépései a következők:
- Végezzen moderálást a feltöltött dokumentumokon az Amazon Rekognition segítségével.
- A Rekognition egyéni címkéivel osztályozza a dokumentumokat különböző kategóriákba, például W-2-ek, számlák, bankszámlakivonatok és fizetési csonkok.
- Szöveg kinyerése dokumentumokból, például nyomtatott szövegekből, kézírásból, űrlapokból és táblázatokból az Amazon Textract segítségével.
Megoldás áttekintése
Ez a megoldás a következő AI-szolgáltatásokat, kiszolgáló nélküli technológiákat és felügyelt szolgáltatásokat használja a méretezhető és költséghatékony architektúra megvalósításához:
- Amazon DynamoDB – Kulcsérték- és dokumentum-adatbázis, amely egyszámjegyű ezredmásodperces teljesítményt nyújt bármilyen léptékben.
- Amazon EventBridge – Szerver nélküli eseménybusz eseményvezérelt alkalmazások létrehozásához az alkalmazásaiból generált események, integrált szoftver szolgáltatásként (SaaS) alkalmazások és AWS szolgáltatások segítségével.
- AWS Lambda – Kiszolgáló nélküli számítási szolgáltatás, amely lehetővé teszi kód futtatását olyan eseményindítókra válaszul, mint például az adatok változása, a rendszerállapot eltolódása vagy a felhasználói műveletek.
- Amazon felismerés – ML segítségével azonosítja az objektumokat, személyeket, szövegeket, jeleneteket és tevékenységeket a képeken és videókon, valamint észlel minden nem megfelelő tartalmat.
- Amazon Rekognition egyéni címkék – Az AutoML-t használja a számítógépes látáshoz és az átviteli tanuláshoz, hogy segítsen az egyéni modellek betanításában, hogy azonosítsa a képeken szereplő objektumokat és jeleneteket, amelyek kifejezetten az Ön üzleti igényeihez igazodnak.
- Amazon Simple Storage Service (Amazon S3) – Objektumtárolóként szolgál a dokumentumok számára, és lehetővé teszi a központi kezelést finomhangolt hozzáférés-vezérléssel.
- Amazon Step Functions – Szerver nélküli funkciókezelő, amely megkönnyíti a Lambda-funkciók és több szolgáltatás sorba rendezését az üzleti szempontból kritikus alkalmazásokban.
- Amazon szöveg – ML segítségével kinyeri a szöveget és adatokat a beolvasott dokumentumokból PDF, JPEG vagy PNG formátumban.
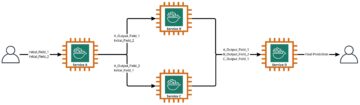
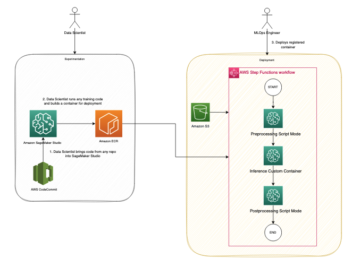
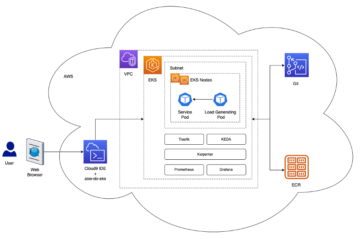
A következő diagram a következtetési folyamat felépítését mutatja be.
 Munkafolyamatunk a következő lépéseket tartalmazza:
Munkafolyamatunk a következő lépéseket tartalmazza:
- A felhasználó feltölti a dokumentumokat a bemeneti S3 vödörbe.
- A feltöltés egy Amazon S3 eseményértesítés valós idejű eseményeket közvetlenül az EventBridge-re szállítani. Az Amazon S3 események, amelyek megfelelnek a „
object created” szűrő definiált an EventBridge szabály elindítja a Step Functions munkafolyamatot. - A Step Functions munkafolyamat Lambda-függvények sorozatát indítja el, amelyek a következő feladatokat hajtják végre:
- Az első funkció előfeldolgozási feladatokat hajt végre, és API-hívásokat indít az Amazon Rekognition számára:
- Ha a bejövő dokumentumok képformátumúak (például JPG vagy PNG), a függvény meghívja az Amazon Rekognition API-t, és a dokumentumokat S3 objektumként adja meg. Ha azonban a dokumentum PDF formátumú, a függvény az Amazon Rekognition API meghívásakor a kép bájtjait továbbítja.
- Ha egy dokumentum több oldalt tartalmaz, a funkció a dokumentumot különálló oldalakra bontja, és egy közbenső mappába menti a kimeneti S3 tárolóba, mielőtt egyenként feldolgozná őket.
- Amikor az előfeldolgozási feladatok befejeződtek, a funkció API-hívást indít az Amazon Rekognition felé, hogy észlelje a nem megfelelő, nem kívánt vagy sértő tartalmakat, és újabb API-hívást indít a betanított Rekognition Custom Labels modellnek a dokumentumok osztályozása érdekében.
- A második funkció API-hívást kezdeményez az Amazon Textract számára, hogy elindítson egy feladatot a szöveg kivonásához a bemeneti dokumentumból, és azt a kimeneti S3 tárolóban tárolja.
- A harmadik függvény a dokumentumok metaadatait, például a moderálási címkét, a dokumentum osztályozását, az osztályozási megbízhatóságot, az Amazon Textract feladatazonosítót és a fájl elérési útját tárolja egy DynamoDB táblában.
- Az első funkció előfeldolgozási feladatokat hajt végre, és API-hívásokat indít az Amazon Rekognition számára:
A munkafolyamatot igénye szerint módosíthatja, például természetes nyelvi feldolgozási (NLP) képességet adhat hozzá ehhez a munkafolyamathoz a Amazon Comprehend hogy betekintést nyerjen a kivonatolt szövegbe.
Képzési csővezeték
Az architektúra üzembe helyezése előtt egy egyéni modellt tanítunk a dokumentumok különböző kategóriákba sorolására a Rekognition egyéni címkék segítségével. A képzési folyamatban a dokumentumokat a segítségével címkézzük Amazon SageMaker Ground Truth. Ezután a címkézett dokumentumokat felhasználva betanítjuk a modellt Rekognition egyéni címkékkel. Ebben a példában egy an Amazon SageMaker jegyzetfüzetben, hogy végrehajtsa ezeket a lépéseket, de megjegyzéseket is fűzhet a képekhez a Rekognition Custom Labels konzoljával. Az utasításokat lásd Képek címkézése.
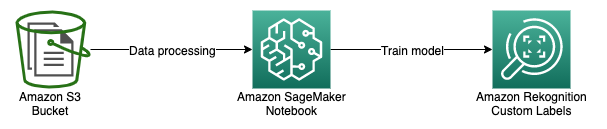
adatbázisba
A modell betanításához a következő nyilvános adatkészleteket használjuk, amelyek W2-ket és számlákat tartalmaznak:
Használhat egy másik, az Ön iparága szempontjából releváns adatkészletet.
Az alábbi táblázat összefoglalja az adatkészlet felosztását a képzés és a tesztelés között.
| Osztály | Edzőkészlet | Tesztkészlet |
| Számlák | 352 | 75 |
| W-2s | 86 | 16 |
| Végösszeg | 438 | 91 |
Telepítse a képzési folyamatot az AWS CloudFormation segítségével
Telepít egy AWS felhőképződés sablon a szükséges biztosításához AWS Identity and Access Management (IAM) szerepkörei és a képzési folyamat összetevői, beleértve a SageMaker notebook példányt.
- Indítsa el a következő CloudFormation sablont az Egyesült Államok keleti (N. Virginia) régiójában:

- A Verem neve, írjon be egy nevet, például
document-processing-training-pipeline. - A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Következő.
- A Képességek és átalakítások szakaszban jelölje be a jelölőnégyzetet, hogy elismerje, hogy az AWS CloudFormation létrehozhat IAM erőforrások.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Verem létrehozása.
A verem részleteinek oldalán a verem állapotának kell megjelennie: CREATE_IN_PROGRESS. Akár 5 percig is eltarthat, amíg az állapot megváltozik CREATE_COMPLETE. Ha kész, megtekintheti a kimeneteket a Kimenetek Tab.
- A verem sikeres elindítása után nyissa meg a SageMaker konzolt, és válassza a lehetőséget Notebook példányok a navigáció nevében.
- Keressen példát a
DocProcessingNotebookInstance-előtagot, és várja meg, amíg állapota InService lesz. - Alatt Hozzászólások, választ Nyissa meg a Jupytert.

Futtassa a példafüzetet
A jegyzetfüzet futtatásához hajtsa végre a következő lépéseket:
- Válassza a
Rekognition_Custom_Labelspéldafüzet.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a futás hogy a példajegyzetfüzet celláit sorrendben futtassuk.

A notebook bemutatja a képzési és tesztképek elkészítésének, címkézésének, manifest fájlok létrehozásának, modell betanításának és a betanított modell futtatásának teljes életciklusát a Rekognition egyedi címkékkel. Alternatív megoldásként betaníthatja és futtathatja a modellt a Rekognition Custom Labels konzol segítségével. Az utasításokat lásd Modell betanítása (konzol).
A jegyzetfüzet magától értetődő; követheti a lépéseket a modell betanításának befejezéséhez.
- Jegyezze fel a
ProjectVersionArnhogy egy későbbi lépésben biztosítsuk a következtetési folyamatot.
A SageMaker jegyzetfüzet-példányok esetében a választott példánytípusért kell fizetnie, a használat időtartama alapján. Ha befejezte a modell betanítását, leállíthatja a notebook példányt, hogy elkerülje a tétlen erőforrások költségeit.
Telepítse a következtetési folyamatot az AWS CloudFormation segítségével
A következtetési folyamat telepítéséhez hajtsa végre a következő lépéseket:
- Indítsa el a következő CloudFormation sablont az Egyesült Államok keleti (N. Virginia) régiójában:
- A Verem neve, írjon be egy nevet, például
document-processing-inference-pipeline. - A DynamoDBTableName, adjon meg egy egyedi DynamoDB táblanevet; például,
document-processing-table. - A InputBucketName, adjon meg egy egyedi nevet a verem által létrehozott S3 vödörnek; például,
document-processing-input-bucket.
A bemeneti dokumentumok feldolgozásuk előtt feltöltődnek ebbe a tárolóba. A beviteli csoport nevének létrehozásakor csak kisbetűket használjon, szóközt ne. Ezenkívül ez a művelet egy új S3 tárolót hoz létre, ezért ne használja egy meglévő tároló nevét. További információkért lásd A vödör elnevezésének szabályai.
- A OutputBucketName, adjon meg egyedi nevet a kimeneti tárolónak; például d
ocument-processing-output-bucket.
Ez a vödör tárolja a kimeneti dokumentumokat feldolgozásuk után. A többoldalas PDF beviteli dokumentumok oldalait is tárolja, miután azokat a Lambda funkcióval felosztotta. Kövesse ugyanazokat az elnevezési szabályokat, mint a beviteli tárhelynél.
- A FelismerésCustomLabelModelARN, írd be a
ProjectVersionArnértéket, amelyet a Jupyter notebookból jegyzett fel. - A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Következő.
- A Állítsa be a verembeállításokat oldalon állítsa be a verem további paramétereit, beleértve a címkéket is.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Következő.
- A Képességek és átalakítások szakaszban jelölje be a jelölőnégyzetet, hogy elismerje, hogy az AWS CloudFormation létrehozhat IAM-erőforrásokat.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Verem létrehozása.
A verem részleteinek oldalán a verem állapotának kell megjelennie: CREATE_IN_PROGRESS. Akár 5 percig is eltarthat, amíg az állapot megváltozik CREATE_COMPLETE. Ha kész, megtekintheti a kimeneteket a Kimenetek Tab.
Dokumentum feldolgozása a folyamaton keresztül
Mind a képzési, mind a következtetési folyamatokat telepítettük, és készen állunk a megoldás használatára és egy dokumentum feldolgozására.
- Az Amazon S3 konzolon nyissa meg a beviteli tárolót.
- Töltsön fel egy mintadokumentumot az S3 mappába.
Ezzel elindul a munkafolyamat. A folyamat feltölti a DynamoDB táblát dokumentumosztályozási és moderációs címkékkel. Az Amazon Textract kimenete a kimeneti S3 vödörbe kerül TextractOutput mappát.
Beküldtünk néhány különböző mintadokumentumot a munkafolyamatba, és a következő információkat kaptuk a DynamoDB táblában.
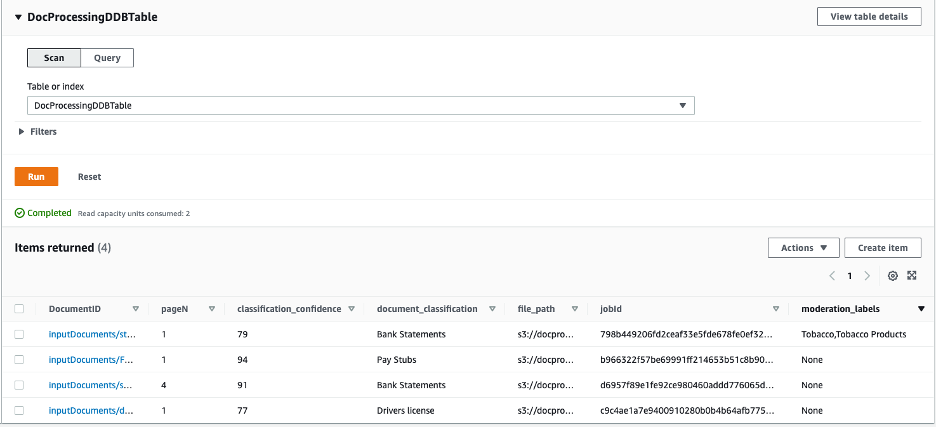
Ha nem lát elemeket a DynamoDB táblában vagy a kimeneti S3 tárolóba feltöltött dokumentumokat, ellenőrizze a Amazon CloudWatch naplók a megfelelő lambda funkcióhoz, és keresse meg a hibát okozó lehetséges hibákat.
Tisztítsuk meg
Hajtsa végre a következő lépéseket a megoldáshoz telepített erőforrások megtisztításához:
- A CloudFormation konzolon válassza a lehetőséget Stacks.
- Válassza ki a megoldáshoz telepített veremeket.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a töröl.
Ezek a lépések nem törlik az S3-tárolókat, a DynamoDB-táblát és a betanított Rekognition egyéni címkék modelljét. Ha nem törlik, továbbra is tárhelydíjat kell fizetnie. Ezeket az erőforrásokat közvetlenül a megfelelő szervizkonzoljukon keresztül kell törölnie, ha már nincs szüksége rájuk.
Következtetés
Ebben a bejegyzésben egy méretezhető, biztonságos és automatizált megközelítést mutattunk be a dokumentumok moderálására, osztályozására és feldolgozására. Több iparág vállalatai használhatják ezt a megoldást üzletük fejlesztésére és ügyfeleik jobb kiszolgálására. Gyorsabb dokumentumfeldolgozást és nagyobb pontosságot tesz lehetővé, valamint csökkenti az adatkinyerés bonyolultságát. Emellett nagyobb biztonságot és a személyes adatokra vonatkozó jogszabályok betartását is biztosítja azáltal, hogy csökkenti a beérkező dokumentumok feldolgozásában részt vevő munkaerőt.
További információkért lásd a Amazon Rekognition egyéni címkék útmutatója, Amazon Rekognition fejlesztői útmutató és a Amazon Textract fejlesztői útmutató. Ha még nem ismeri az Amazon Rekognition egyéni címkéket, próbálja ki ingyenes szintünkkel, amely 3 hónapig tart, és havi 10 ingyenes edzésórát és havi 4 ingyenes következtetési órát tartalmaz. Az Amazon Rekognition ingyenes szintje havi 5,000 kép feldolgozását tartalmazza 12 hónapon keresztül. Az Amazon Textract ingyenes szintje szintén három hónapig tart, és havi 1,000 oldalt tartalmaz a Detect Document Text API-hoz.
A szerzőkről
 Jay Rao az AWS vezető megoldási építésze. Szeret technikai és stratégiai útmutatást nyújtani ügyfeleinek, és segíteni nekik az AWS-re vonatkozó megoldások tervezésében és megvalósításában.
Jay Rao az AWS vezető megoldási építésze. Szeret technikai és stratégiai útmutatást nyújtani ügyfeleinek, és segíteni nekik az AWS-re vonatkozó megoldások tervezésében és megvalósításában.
 Uchenna Egbe az AWS Solutions Architect munkatársa. Szabadidejét azzal tölti, hogy gyógynövényekről, teákról, szuperételekről kutakod, és hogyan tudja ezeket beépíteni a napi étrendjébe.
Uchenna Egbe az AWS Solutions Architect munkatársa. Szabadidejét azzal tölti, hogy gyógynövényekről, teákról, szuperételekről kutakod, és hogyan tudja ezeket beépíteni a napi étrendjébe.
- Coinsmart. Európa legjobb Bitcoin- és kriptográfiai tőzsdéje.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. SZABAD HOZZÁFÉRÉS.
- CryptoHawk. Altcoin radar. Ingyenes próbaverzió.
- Forrás: https://aws.amazon.com/blogs/machine-learning/moderate-classify-and-process-documents-using-amazon-rekognition-and-amazon-text/
- "
- 000
- 10
- 100
- 116
- 12 hónap
- Rólunk
- hozzáférés
- át
- cselekvések
- tevékenységek
- További
- AI
- AI szolgáltatások
- amazon
- Másik
- api
- alkalmazások
- megközelítés
- építészet
- Társult
- Automatizált
- AWS
- Bank
- előtt
- számlázás
- határ
- Doboz
- épít
- Épület
- busz
- üzleti
- hívás
- képességek
- okozott
- központi
- kihívások
- változik
- töltött
- díjak
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- besorolás
- kód
- Companies
- versenyképes
- teljesítés
- engedékeny
- Kiszámít
- számítógép
- bizalom
- Konzol
- tartalmaz
- tartalom
- folytatódik
- Megfelelő
- költséghatékony
- terjed
- teremt
- teremt
- létrehozása
- szokás
- Ügyfelek
- dátum
- adatbázis
- szállított
- szállít
- telepíteni
- telepített
- Design
- részletek
- Fejlesztő
- Diéta
- különböző
- közvetlenül
- dokumentumok
- eredményesen
- erőfeszítés
- erőfeszítések
- belép
- esemény
- események
- fejlődik
- példa
- példák
- létező
- kivonatok
- Arc
- Kudarc
- gyorsabb
- vezetéknév
- következik
- következő
- forma
- formátum
- formák
- Ingyenes
- funkció
- funkciók
- Továbbá
- fogantyú
- segít
- segít
- <p></p>
- Hogyan
- azonban
- HTTPS
- emberi
- azonosítani
- Identitás
- kép
- végre
- javul
- tartalmaz
- magában foglalja a
- Beleértve
- egyéni
- iparágak
- ipar
- információ
- bemenet
- meglátások
- integrált
- Intelligens
- részt
- IT
- Munka
- címkézés
- Címkék
- nyelv
- indított
- tanulás
- Jogalkotás
- gép
- gépi tanulás
- KÉSZÍT
- sikerült
- vezetés
- kézikönyv
- Mérkőzés
- esetleg
- ML
- modell
- modellek
- Hónap
- hónap
- több
- többszörös
- Természetes
- Navigáció
- elengedhetetlen
- igények
- jegyzetfüzet
- nyitva
- működés
- Optimalizálja
- érdekében
- Fizet
- Emberek (People)
- teljesítmény
- személyes
- személyes adat
- potenciális
- Fő
- problémák
- folyamat
- feldolgozás
- ad
- biztosít
- amely
- nyilvános
- real-time
- kapott
- csökkenteni
- csökkentő
- Tudástár
- válasz
- szabályok
- futás
- futás
- skálázható
- Skála
- jelenetek
- biztonság
- biztonság
- Series of
- vagy szerver
- szolgáltatás
- Szolgáltatások
- készlet
- Egyszerű
- So
- szoftver
- szoftver mint szolgáltatás
- szilárd
- megoldások
- Megoldások
- Megoldja
- terek
- osztott
- szakadások
- verem
- kezdődik
- Állami
- nyilatkozatok
- Állapot
- tartózkodás
- tárolás
- tárolni
- árnyékolók
- Stratégiai
- benyújtott
- sikeresen
- rendszer
- Systems
- feladatok
- adó
- Műszaki
- technikák
- Technologies
- teszt
- Tesztelés
- Keresztül
- idő
- időigényes
- alkalommal
- Képzések
- átruházás
- egyedi
- us
- használ
- érték
- Igazolás
- Videók
- Megnézem
- Virginia
- látomás
- kötet
- várjon
- nélkül
- munkaerő