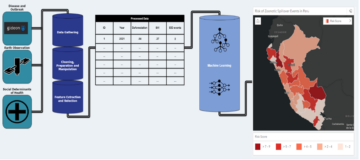
Ez a három részből álló sorozat bemutatja a gráf neurális hálózatok (GNN) és Amazon Neptun filmajánlások generálásához a IMDb és Box Office Mojo Movies/TV/OTT licencelhető adatcsomag, amely szórakoztató metaadatok széles skáláját kínálja, beleértve több mint 1 milliárd felhasználói értékelést; hitelek több mint 11 millió szereplőnek és stábtagnak; 9 millió film, TV és szórakoztató műsor; és több mint 60 ország globális kasszajelentési adatai. Sok AWS média- és szórakoztatóügyfél licenccel az IMDb-adatokon keresztül AWS adatcsere a tartalomfelfedezés javítása, valamint az ügyfelek elkötelezettségének és megtartásának növelése.
In rész 1, megvitattuk a GNN-ek alkalmazásait, valamint azt, hogyan alakítsuk át és készítsük elő IMDb-adatainkat lekérdezésre. Ebben a bejegyzésben a Neptune használatával a 3. részben a katalóguson kívüli kereséshez használt beágyazások generálására szolgáló folyamatot tárgyaljuk. Mi is átmegyünk Amazon Neptune ML, a Neptune gépi tanulási (ML) funkciója és a fejlesztési folyamatunkban használt kód. A 3. részben végigjárjuk, hogyan alkalmazhatjuk tudásgráf-beágyazásainkat egy katalóguson kívüli keresési használati esetre.
Megoldás áttekintése
A nagy összekapcsolt adatkészletek gyakran olyan értékes információkat tartalmaznak, amelyeket nehéz kinyerni pusztán emberi intuíción alapuló lekérdezések segítségével. Az ML technikák segíthetnek megtalálni a rejtett összefüggéseket több milliárd összefüggést tartalmazó gráfokban. Ezek az összefüggések hasznosak lehetnek a termékek ajánlásában, a hitelképesség előrejelzésében, a csalások azonosításában és sok más felhasználási esetben.
A Neptune ML lehetővé teszi a hasznos ML modellek felépítését és betanítását nagy grafikonokon, hetek helyett órákban. Ennek eléréséhez a Neptune ML a GNN technológiát használja, amelyet Amazon SageMaker és a Deep Graph Library (DGL) (ami nyílt forráskódú). A GNN-ek a mesterséges intelligencia feltörekvő területei (például lásd Átfogó felmérés a gráf neurális hálózatokról). A GNN-ek DGL-lel való használatáról szóló gyakorlati útmutatóért lásd: Gráf neurális hálózatok tanulása a Deep Graph Library segítségével.
Ebben a bejegyzésben bemutatjuk, hogyan használhatjuk a Neptune-t a folyamatunkban a beágyazások generálására.
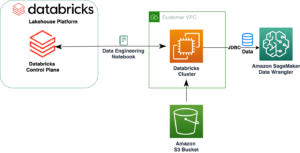
A következő diagram az IMDb adatok teljes áramlását mutatja a letöltéstől a beágyazásig.
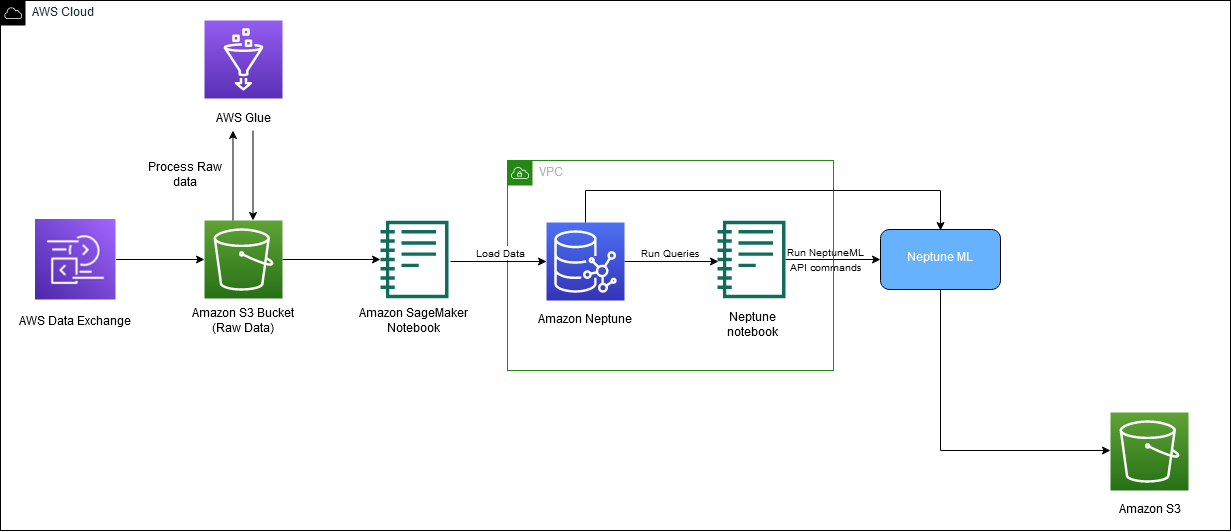
A megoldás megvalósításához az alábbi AWS szolgáltatásokat használjuk:
Ebben a bejegyzésben a következő magas szintű lépéseken mutatjuk be:
- Állítsa be a környezeti változókat
- Hozzon létre egy exportálási feladatot.
- Hozzon létre egy adatfeldolgozási feladatot.
- Adjon be képzési munkát.
- Beágyazások letöltése.
A Neptune ML parancsok kódja
A megoldás megvalósításának részeként a következő parancsokat használjuk:
Az általunk használt neptune_ml export az állapot ellenőrzéséhez vagy a Neptune ML exportálási folyamat elindításához, és neptune_ml training egy Neptune ML modell képzési feladat elindításához és állapotának ellenőrzéséhez.
Ezekkel és más parancsokkal kapcsolatos további információkért lásd: Neptune munkapad varázslatok használata a notebookokban.
Előfeltételek
A bejegyzés követéséhez a következőkre van szüksége:
- An AWS-fiók
- A SageMaker, az Amazon S3 és az AWS CloudFormation ismerete
- A Neptune-fürtbe betöltött grafikon adatok (lásd rész 1 további információért)
Állítsa be a környezeti változókat
Mielőtt elkezdené, be kell állítania a környezetét a következő változók beállításával: s3_bucket_uri és a processed_folder. s3_bucket_uri az 1. részben használt vödör neve és processed_folder az Amazon S3 helye az exportálási feladat kimenetének.
Hozzon létre egy exportálási feladatot
Az 1. részben létrehoztunk egy SageMaker notebook és export szolgáltatást, amellyel a Neptune DB fürtből az Amazon S3-ba exportálhatjuk adatainkat a szükséges formátumban.
Most, hogy adataink betöltődnek, és az exportszolgáltatás létrejött, létre kell hoznunk egy exportálási feladatot, és elindítani kell. Ehhez használjuk NeptuneExportApiUri és hozzon létre paramétereket az exportálási feladathoz. A következő kódban a változókat használjuk expo és a export_params. Készlet expo a NeptuneExportApiUri érték, amelyet megtalálhat a Kimenetek a CloudFormation verem lapját. Mert export_params, a Neptune-fürt végpontját használjuk, és megadjuk az értéket outputS3path, amely az Amazon S3 helye az exportálási feladat kimenetének.
Az exportálási feladat elküldéséhez használja a következő parancsot:
Az exportálási feladat állapotának ellenőrzéséhez használja a következő parancsot:
A munka befejezése után állítsa be a processed_folder változó, amely megadja a feldolgozott eredmények Amazon S3 helyét:
Hozzon létre egy adatfeldolgozási feladatot
Most, hogy az exportálás megtörtént, létrehozunk egy adatfeldolgozási feladatot, amely előkészíti az adatokat a Neptune ML képzési folyamathoz. Ezt többféleképpen is megteheti. Ehhez a lépéshez módosíthatja a job_name és a modelType változókat, de az összes többi paraméternek változatlannak kell maradnia. Ennek a kódnak a fő része a modelType paraméter, amely lehet heterogén gráfmodell (heterogeneous) vagy tudásgráfok (kge).
Az export munkakörbe tartozik még training-data-configuration.json. Ezzel a fájllal adhat hozzá vagy távolíthat el minden olyan csomópontot vagy élt, amelyet nem szeretne biztosítani a betanításhoz (ha például meg szeretné jósolni két csomópont közötti kapcsolatot, eltávolíthatja a hivatkozást ebben a konfigurációs fájlban). Ehhez a blogbejegyzéshez az eredeti konfigurációs fájlt használjuk. További információkért lásd Edzés konfigurációs fájl szerkesztése.
Hozza létre adatfeldolgozási feladatát a következő kóddal:
Az exportálási feladat állapotának ellenőrzéséhez használja a következő parancsot:
Adjon be képzési munkát
A feldolgozási munka befejezése után megkezdhetjük a betanítási munkánkat, ahol létrehozzuk a beágyazásainkat. Javasoljuk az ml.m5.24xlarge példánytípust, de ezt megváltoztathatja számítási igényeinek megfelelően. Lásd a következő kódot:
Kinyomtatjuk a training_results változót, hogy megkapjuk a képzési feladat azonosítóját. A feladat állapotának ellenőrzéséhez használja a következő parancsot:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Beágyazások letöltése
A betanítási feladat befejezése után az utolsó lépés a nyers beágyazások letöltése. A következő lépések bemutatják, hogyan töltheti le a KGE használatával létrehozott beágyazásokat (ugyanezt a folyamatot használhatja az RGCN-hez is).
A következő kódban használjuk neptune_ml.get_mapping() és a get_embeddings() a leképezési fájl letöltéséhez (mapping.info) és a nyers beágyazási fájl (entity.npy). Ezután hozzá kell rendelnünk a megfelelő beágyazásokat a megfelelő azonosítókhoz.
Az RGCN-ek letöltéséhez kövesse ugyanazt a folyamatot egy új betanítási feladatnévvel úgy, hogy feldolgozza az adatokat a modelType paraméter beállításával heterogeneous, majd betanítja a modellt a modelName paraméter beállításával rgcn lát itt további részletekért. Ha ez kész, hívja a get_mapping és a get_embeddings funkciókat az új letöltéséhez mapping.info és a entity.npy fájlokat. Miután megvan az entitás és a leképezési fájlok, a CSV-fájl létrehozásának folyamata megegyezik.
Végül töltse fel beágyazásait a kívánt Amazon S3 helyre:
Ügyeljen arra, hogy emlékezzen erre az S3-as helyre, ezt a 3. részben kell használnia.
Tisztítsuk meg
Ha végzett a megoldással, ne felejtse el megtisztítani az erőforrásokat, hogy elkerülje a folyamatos költségeket.
Következtetés
Ebben a bejegyzésben megvitattuk, hogyan használhatjuk a Neptune ML-t a GNN-beágyazások IMDb-adatokból történő betanításához.
A tudásgráf-beágyazások egyes kapcsolódó alkalmazásai olyan fogalmak, mint a katalóguson kívüli keresés, tartalmi ajánlások, célzott hirdetések, hiányzó hivatkozások előrejelzése, általános keresés és kohorszelemzés. A katalóguson kívüli keresés olyan tartalom keresésének folyamata, amely nem az Ön tulajdonában van, és olyan tartalmat keres vagy ajánl a katalógusában, amely a lehető legközelebb áll ahhoz, amit a felhasználó keresett. A 3. részben mélyebben belemerülünk a katalóguson kívüli keresésbe.
A szerzőkről
 Matthew Rhodes adatkutató, az Amazon ML Solutions Lab-ban dolgozom. Olyan gépi tanulási folyamatok építésére specializálódott, amelyek olyan fogalmakat foglalnak magukban, mint a Natural Language Processing és a Computer Vision.
Matthew Rhodes adatkutató, az Amazon ML Solutions Lab-ban dolgozom. Olyan gépi tanulási folyamatok építésére specializálódott, amelyek olyan fogalmakat foglalnak magukban, mint a Natural Language Processing és a Computer Vision.
 Divya Bhargavi Data Scientist és Media and Entertainment vertikális vezető az Amazon ML Solutions Labnál, ahol nagy értékű üzleti problémákat old meg az AWS-ügyfelek számára a Machine Learning segítségével. Kép/videó megértéssel, tudásgrafikon ajánlórendszerekkel, prediktív hirdetéshasználati esetekkel foglalkozik.
Divya Bhargavi Data Scientist és Media and Entertainment vertikális vezető az Amazon ML Solutions Labnál, ahol nagy értékű üzleti problémákat old meg az AWS-ügyfelek számára a Machine Learning segítségével. Kép/videó megértéssel, tudásgrafikon ajánlórendszerekkel, prediktív hirdetéshasználati esetekkel foglalkozik.
 Gaurav Rele adattudós az Amazon ML Solution Labnál, ahol az AWS-ügyfelekkel dolgozik különböző ágazatokban, hogy felgyorsítsa a gépi tanulás és az AWS felhőszolgáltatások használatát üzleti kihívásaik megoldása érdekében.
Gaurav Rele adattudós az Amazon ML Solution Labnál, ahol az AWS-ügyfelekkel dolgozik különböző ágazatokban, hogy felgyorsítsa a gépi tanulás és az AWS felhőszolgáltatások használatát üzleti kihívásaik megoldása érdekében.
 Karan Sindwani az Amazon ML Solutions Lab adatkutatója, ahol mély tanulási modelleket épít és telepít. Szakterülete a számítógépes látás. Szabadidejében szívesen túrázik.
Karan Sindwani az Amazon ML Solutions Lab adatkutatója, ahol mély tanulási modelleket épít és telepít. Szakterülete a számítógépes látás. Szabadidejében szívesen túrázik.
 Soji Adeshina Alkalmazott tudós az AWS-nél, ahol gráf-neurális hálózat alapú modelleket fejleszt gépi tanuláshoz gráffeladatokon, csalással és visszaélésekkel, tudásgráfokkal, ajánlórendszerekkel és élettudományokkal kapcsolatos alkalmazásokkal. Szabadidejében szívesen olvas és főz.
Soji Adeshina Alkalmazott tudós az AWS-nél, ahol gráf-neurális hálózat alapú modelleket fejleszt gépi tanuláshoz gráffeladatokon, csalással és visszaélésekkel, tudásgráfokkal, ajánlórendszerekkel és élettudományokkal kapcsolatos alkalmazásokkal. Szabadidejében szívesen olvas és főz.
 Vidya Sagar Ravipati az Amazon ML Solutions Lab menedzsere, ahol a nagyszabású elosztott rendszerek terén szerzett hatalmas tapasztalatát és a gépi tanulás iránti szenvedélyét hasznosítja, hogy segítse az AWS ügyfeleit a különböző iparágakban az AI és a felhő alkalmazásának felgyorsításában.
Vidya Sagar Ravipati az Amazon ML Solutions Lab menedzsere, ahol a nagyszabású elosztott rendszerek terén szerzett hatalmas tapasztalatát és a gépi tanulás iránti szenvedélyét hasznosítja, hogy segítse az AWS ügyfeleit a különböző iparágakban az AI és a felhő alkalmazásának felgyorsításában.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- Rólunk
- visszaélés
- gyorsul
- át
- További
- további információ
- Örökbefogadás
- Hirdetés
- Után
- AI
- Minden termék
- kizárólag
- amazon
- Amazon ML Solutions Lab
- elemzés
- és a
- alkalmazások
- alkalmazott
- alkalmaz
- megfelelő
- TERÜLET
- mesterséges
- mesterséges intelligencia
- AWS
- alapján
- között
- Billió
- milliárd
- Blog
- Doboz
- jegyiroda
- épít
- Épület
- épít
- üzleti
- hívás
- eset
- esetek
- katalógus
- kihívások
- változik
- díjak
- ellenőrizze
- közel
- felhő
- felhő elfogadása
- felhő szolgáltatások
- Fürt
- kód
- kohort
- teljes
- átfogó
- számítógép
- Számítógépes látás
- számítástechnika
- fogalmak
- Magatartás
- Configuration
- összefüggő
- tartalom
- Megfelelő
- országok
- teremt
- készítette
- hitel
- Credits
- vevő
- Ügyfél-elkötelezettség
- Ügyfelek
- dátum
- adatfeldolgozás
- adattudós
- adatkészletek
- mély
- mély tanulás
- mélyebb
- bevet
- részletek
- Fejlesztés
- fejleszt
- dgl
- különböző
- felfedezés
- megvitatni
- tárgyalt
- megosztott
- elosztott rendszerek
- ne
- letöltés
- bármelyik
- csiszolókő
- Endpoint
- eljegyzés
- Szórakozás
- egység
- Környezet
- Eter (ETH)
- példa
- tapasztalat
- export
- kivonat
- Funkció
- kevés
- mező
- filé
- Fájlok
- Találjon
- megtalálása
- áramlási
- következik
- következő
- formátum
- csalás
- ból ből
- Tele
- funkciók
- általános
- generál
- generáció
- kap
- Globális
- Go
- grafikon
- grafikonok
- hands-on
- Kemény
- segít
- hasznos
- Rejtett
- magas szinten
- NYITVATARTÁS
- Hogyan
- How To
- HTML
- HTTPS
- emberi
- identiques
- azonosító
- végre
- végrehajtási
- javul
- in
- magában foglalja a
- Beleértve
- Növelje
- index
- ipar
- info
- információ
- példa
- helyette
- Intelligencia
- vonja
- IT
- Munka
- json
- Kulcs
- tudás
- labor
- nyelv
- nagy
- nagyarányú
- keresztnév
- vezet
- tanulás
- kihasználja
- könyvtár
- Engedély
- élet
- Life Sciences
- LINK
- linkek
- elhelyezkedés
- gép
- gépi tanulás
- Fő
- KÉSZÍT
- menedzser
- sok
- térkép
- térképészet
- Média
- közepes
- Partnerek
- Metaadatok
- millió
- hiányzó
- ML
- modell
- modellek
- több
- film
- név
- Természetes
- Természetes nyelvi feldolgozás
- Szükség
- igények
- Neptun
- hálózati alapú
- hálózatok
- neurális hálózatok
- Új
- csomópontok
- jegyzetfüzet
- Office
- folyamatban lévő
- eredeti
- Más
- átfogó
- saját
- csomag
- paraméter
- paraméterek
- rész
- szenvedély
- csővezeték
- Plató
- Platón adatintelligencia
- PlatoData
- lehetséges
- állás
- hatalom
- powered
- előre
- előrejelzésére
- Készít
- problémák
- folyamat
- feldolgozás
- Termékek
- profil
- ad
- biztosít
- hatótávolság
- értékelés
- Nyers
- Olvasás
- ajánl
- Ajánlást
- ajánlások
- ajánló
- összefüggő
- Kapcsolatok
- marad
- eszébe jut
- eltávolítása
- Jelentő
- kötelező
- Tudástár
- Eredmények
- visszatartás
- sagemaker
- azonos
- TUDOMÁNYOK
- Tudós
- Keresés
- keres
- Series of
- szolgáltatás
- Szolgáltatások
- készlet
- beállítás
- kellene
- előadás
- megoldások
- Megoldások
- SOLVE
- Megoldja
- specializálódott
- verem
- kezdet
- Állapot
- Lépés
- Lépései
- tárolni
- beküldése
- ilyen
- Öltöny
- Felmérés
- Systems
- célzott
- feladatok
- technikák
- Technológia
- A
- A terület
- azok
- Keresztül
- idő
- címei
- nak nek
- Vonat
- Képzések
- Átalakítás
- igaz
- oktatói
- tv
- megértés
- használ
- használati eset
- használó
- Értékes
- érték
- Hatalmas
- változat
- függőlegesek
- látomás
- módon
- Hetek
- Mit
- ami
- széles
- Széleskörű
- lesz
- dolgozó
- művek
- A te
- zephyrnet