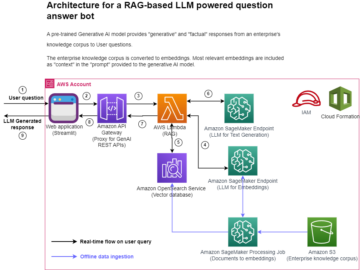
A számítógépes látásban a szemantikai szegmentálás az a feladat, hogy a kép minden pixelét osztályozzák egy ismert címkekészletből származó osztályba úgy, hogy az azonos címkével ellátott pixelek bizonyos jellemzőkkel rendelkezzenek. A bemeneti képek szegmentációs maszkját generálja. Például a következő képek a szegmentációs maszkot mutatják be cat címke.
 |
 |
Novemberben 2018, Amazon SageMaker bejelentette a SageMaker szemantikus szegmentáló algoritmus elindítását. Ezzel az algoritmussal betaníthatja modelljeit nyilvános adatkészlettel vagy saját adatkészlettel. A népszerű képszegmentációs adatkészletek közé tartozik a Common Objects in Context (COCO) adatkészlet és a PASCAL Visual Object Classes (PASCAL VOC), de ezek címkéinek osztályai korlátozottak, és érdemes lehet modellt betanítani olyan célobjektumokra, amelyek nem szerepelnek a nyilvános adatkészletek. Ebben az esetben használhatja Amazon SageMaker Ground Truth saját adatkészletének címkézéséhez.
Ebben a bejegyzésben a következő megoldásokat mutatom be:
- A Ground Truth használata szemantikai szegmentációs adatkészlet címkézésére
- Az eredmények átalakítása a Ground Truth-ból a szükséges bemeneti formátumba a SageMaker beépített szemantikus szegmentáló algoritmusához
- A szemantikus szegmentációs algoritmus használata modell betanításához és következtetés végrehajtásához
Szemantikus szegmentációs adatcímkézés
A szemantikai szegmentáláshoz gépi tanulási modell felépítéséhez pixelszinten kell felcímkéznünk egy adatkészletet. A Ground Truth lehetőséget ad emberi annotátorok használatára Amazon Mechanical Turk, külső szállítók vagy saját magánszemélyek. Ha többet szeretne megtudni a munkaerőről, tekintse meg a Munkaerő létrehozása és kezelése. Ha nem szeretné egyedül kezelni a címkézési munkaerőt, Amazon SageMaker Ground Truth Plus egy másik nagyszerű lehetőség új kulcsrakész adatcímkézési szolgáltatásként, amely lehetővé teszi kiváló minőségű edzési adatkészletek gyors létrehozását, és akár 40%-kal csökkenti a költségeket. Ebben a bejegyzésben megmutatom, hogyan lehet manuálisan címkézni az adatkészletet a Ground Truth automatikus szegmentálási funkciójával és a crowdsource címkézését a Mechanical Turk munkaerővel.
Kézi címkézés a Ground Truth segítségével
2019 decemberében a Ground Truth egy automatikus szegmentálási funkciót adott a szemantikus szegmentációs címkézés felhasználói felületéhez, hogy növelje a címkézési sebességet és javítsa a pontosságot. További információkért lásd: Objektumok automatikus szegmentálása az Amazon SageMaker Ground Truth segítségével végzett szemantikus szegmentációs címkézés során. Ezzel az új funkcióval felgyorsíthatja a címkézési folyamatot a szegmentálási feladatoknál. Ahelyett, hogy szorosan illeszkedő sokszöget rajzolna, vagy az ecset eszközzel rögzítene egy objektumot a képen, csak négy pontot rajzol: az objektum legfelső, legalsó, bal és jobb szélső pontjára. A Ground Truth ezt a négy pontot veszi bemenetként, és a Deep Extreme Cut (DEXTR) algoritmus segítségével szorosan illeszkedő maszkot állít elő az objektum köré. A Ground Truth segítségével a kép szemantikai szegmentálásának címkézéséhez oktatóanyagot a következő helyen talál Kép szemantikai szegmentálása. A következő példa arra mutat, hogy az automatikus szegmentáló eszköz hogyan generál automatikusan szegmentációs maszkot, miután kiválasztotta egy objektum négy szélső pontját.


Crowdsourcing címkézés Mechanical Turk munkaerővel
Ha nagy adatkészlettel rendelkezik, és nem szeretne saját kezűleg több száz vagy több ezer képet felcímkézni, használhatja a Mechanical Turk alkalmazást, amely igény szerinti, méretezhető emberi munkaerőt biztosít olyan munkák elvégzéséhez, amelyeket az emberek jobban el tudnak végezni, mint a számítógépek. A Mechanical Turk szoftver hivatalossá teszi az állásajánlatokat azon dolgozók ezrei számára, akik hajlandóak részmunkát végezni a számukra legmegfelelőbb módon. A szoftver az elvégzett munkát is lekéri és lefordítja Önnek, a kérelmezőnek, aki (csak) a kielégítő munkáért fizeti a dolgozókat. A Mechanical Turk használatának megkezdéséhez lásd: Az Amazon Mechanical Turk bemutatása.
Hozzon létre egy címkézési feladatot
A következő példa egy Mechanical Turk címkézési feladatra egy tengeri teknős adatkészlethez. A tengeri teknősök adatkészlete a Kaggle versenyből származik Tengeri teknős arcfelismerés, és az adatkészletből 300 képet választottam ki demonstrációs célból. A tengeri teknős nem gyakori osztály a nyilvános adatkészletekben, így olyan helyzetet képviselhet, amely egy hatalmas adatkészlet címkézését igényli.
- A SageMaker konzolon válassza a lehetőséget Címkézési munkák a navigációs ablaktáblában.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Címkézési feladat létrehozása.
- Adja meg a munkája nevét.
- A Bemeneti adatok beállításaválassza Automatikus adatbeállítás.
Ez létrehozza a bemeneti adatok manifesztjét. - A S3 hely a bemeneti adatkészletekhez, adja meg az adatkészlet elérési útját.

- A Feladat kategória, választ Kép.
- A Feladat kiválasztásaválassza Szemantikus szegmentálás.

- A Munkás típusokválassza Amazon Mechanical Turk.
- Konfigurálja a beállításokat a feladat időtúllépéséhez, a feladat lejárati idejéhez és a feladatonkénti árhoz.

- Címke hozzáadása (ehhez a bejegyzéshez,
sea turtle), és adjon meg címkézési utasításokat. - A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Teremt.

A címkézési feladat beállítása után a SageMaker konzolon ellenőrizheti a címkézés folyamatát. Ha készként van megjelölve, kiválaszthatja a munkát az eredmények ellenőrzéséhez, és felhasználhatja azokat a következő lépésekhez.

Adatkészlet átalakítás
Miután megkapta a Ground Truth kimenetét, a SageMaker beépített algoritmusaival betaníthat egy modellt ezen az adatkészleten. Először is elő kell készítenie a címkézett adatkészletet a SageMaker szemantikus szegmentáló algoritmus kért beviteli felületeként.
Kért bemeneti adatcsatornák
A SageMaker szemantikai szegmentálása elvárja, hogy a képzési adatkészletet a rendszer tárolja Amazon egyszerű tárolási szolgáltatás (Amazon S3). Az Amazon S3 adatkészletét várhatóan két csatornán fogják bemutatni, az egyik a számára train és az egyik a validation, négy könyvtárat használva, kettőt a képekhez és kettőt a megjegyzésekhez. A megjegyzések várhatóan tömörítetlen PNG-képek. Az adatkészlet tartalmazhat egy címkeleképezést is, amely leírja a megjegyzésleképezések létrehozását. Ha nem, akkor az algoritmus alapértelmezést használ. Következtetés céljából egy végpont olyan képeket fogad el image/jpeg tartalom típus. Az adatcsatornák szükséges struktúrája a következő:
A vonatban és az érvényesítési könyvtárban lévő minden JPG-képhez tartozik egy megfelelő PNG-címkekép azonos névvel train_annotation és a validation_annotation könyvtárakat. Ez az elnevezési konvenció segít az algoritmusnak egy címkét a megfelelő képhez társítani a képzés során. A vonat, train_annotation, érvényesítés és validation_annotation csatornák kötelezőek. A megjegyzések egycsatornás PNG-képek. A formátum mindaddig működik, amíg a kép metaadatai (módjai) segítik az algoritmust, hogy a megjegyzésképeket egycsatornás, 8 bites előjel nélküli egész számmá olvassa be.
A Ground Truth címkézési feladat kimenete
A Ground Truth címkézési feladatból generált kimenetek a következő mappaszerkezettel rendelkeznek:
A szegmentációs maszkok mentésre kerülnek s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Minden megjegyzéskép egy .png fájl, amelyet a forráskép indexe és a képcímkézés befejezésének időpontja után neveztek el. Például a következők a forráskép (Image_1.jpg) és a Mechanical Turk munkaerő által generált szegmentációs maszk (0_2022-02-10T17:41:04.724225.png). Figyelje meg, hogy a maszk indexe eltér a forráskép nevében szereplő számtól.
 |
 |
A címkézési feladat kimeneti jegyzéke a /manifests/output/output.manifest fájlt. Ez egy JSON-fájl, és minden sor rögzíti a forráskép és a címkéje, valamint az egyéb metaadatok közötti leképezést. A következő JSON-sor leképezést rögzít a megjelenített forráskép és a megjegyzés között:
A forráskép neve Image_1.jpg, a kommentár neve pedig 0_2022-02-10T17:41: 04.724225.png. Ahhoz, hogy az adatokat a SageMaker szemantikus szegmentáló algoritmus szükséges adatcsatorna-formátumaiként előkészítsük, meg kell változtatnunk az annotáció nevét, hogy az megegyezzen a forrás JPG-képekkel. És az adatkészletet is fel kell osztanunk train és a validation könyvtárak a forrásképekhez és a megjegyzésekhez.
Alakítsa át a Ground Truth címkézési feladat kimenetét a kívánt bemeneti formátumra
A kimenet átalakításához hajtsa végre a következő lépéseket:
- Töltse le az összes fájlt a címkézési feladatból az Amazon S3-ból egy helyi könyvtárba:
- Olvassa el a jegyzékfájlt, és módosítsa az annotáció nevét a forrásképek neveire:
- A vonat és az érvényesítési adatkészlet felosztása:
- Készítsen egy könyvtárat a szükséges formátumban a szemantikus szegmentációs algoritmus adatcsatornáihoz:
- Helyezze át a vonat- és érvényesítési képeket és a megjegyzéseiket a létrehozott könyvtárakba.
- A képekhez használja a következő kódot:
- A megjegyzésekhez használja a következő kódot:
- Töltse fel a vonat- és érvényesítési adatkészleteket, valamint a hozzájuk tartozó annotációs adatkészleteket az Amazon S3-ba:
SageMaker szemantikus szegmentációs modell képzés
Ebben a részben a szemantikai szegmentációs modell betanításának lépéseit mutatjuk be.
Kövesse a mintafüzetet, és állítsa be az adatcsatornákat
Az utasításokat követheti A szemantikus szegmentációs algoritmus már elérhető az Amazon SageMakerben a szemantikai szegmentációs algoritmus megvalósításához a címkézett adatkészletben. Ezt a mintát jegyzetfüzet egy végponttól végpontig terjedő példát mutat be, amely bemutatja az algoritmust. A jegyzetfüzetben megtudhatja, hogyan taníthat és tárolhat szemantikai szegmentációs modellt a teljesen konvolúciós hálózat segítségével (FCN) algoritmus segítségével Pascal VOC adatkészlet edzéshez. Mivel nem tervezek modellt betanítani a Pascal VOC adatkészletből, kihagytam a 3. lépést (adat-előkészítés) ebben a notebookban. Ehelyett közvetlenül én hoztam létre train_channel, train_annotation_channe, validation_channelés validation_annotation_channel az S3 helyek használatával, ahol a képeimet és megjegyzéseimet tároltam:
Állítsa be a hiperparamétereket saját adatkészletéhez a SageMaker becslőben
Követtem a jegyzetfüzetet, és létrehoztam egy SageMaker becslő objektumot (ss_estimator) a szegmentációs algoritmusom betanításához. Egy dolgot kell testreszabnunk az új adatkészlethez ss_estimator.set_hyperparameters: változtatnunk kell num_classes=21 nak nek num_classes=2 (turtle és a background), és én is változtam epochs=10 nak nek epochs=30 mert a 10 csak demó célokat szolgál. Ezután a p3.2xlarge példányt modellképzésre használtam beállítással instance_type="ml.p3.2xlarge". Az edzés 8 perc alatt lezajlott. A legjobb MIoU (Mean Intersection over Union) 0.846 értéket a 11. korszakban érjük el pix_acc (a képen a helyesen besorolt képpontok százalékos aránya) 0.925, ami elég jó eredmény ennél a kis adatkészletnél.
Modellkövetkeztetési eredmények
A modellt egy olcsó ml.c5.xlarge példányon tároltam:
Végül elkészítettem egy 10 teknős képből álló tesztkészletet, hogy lássam a betanított szegmentációs modell következtetési eredményét:
A következő képek az eredményeket mutatják.

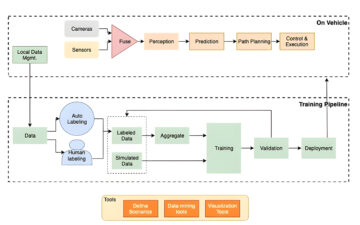
A tengeri teknősök szegmentáló maszkjai pontosnak tűnnek, és elégedett vagyok ezzel az eredménnyel, amelyet a Mechanical Turk dolgozói által felcímkézett 300 képből álló adatkészlet alapján képeztek ki. Felfedezhet más elérhető hálózatokat is, mint pl piramis-jelenet-elemző hálózat (PSP) or DeepLab-V3 a mintafüzetben az adatkészletével.
Tisztítsuk meg
Ha végzett vele, törölje a végpontot, hogy elkerülje a folyamatos költségeket:
Következtetés
Ebben a bejegyzésben bemutattam, hogyan lehet testreszabni a szemantikus szegmentációs adatcímkézést és a modellképzést a SageMaker segítségével. Először is beállíthat egy címkézési feladatot az automatikus szegmentáló eszközzel, vagy használhat egy Mechanical Turk munkaerőt (valamint más lehetőségeket is). Ha több mint 5,000 objektummal rendelkezik, akkor automatizált adatcímkézést is használhat. Ezután átalakíthatja a Ground Truth címkézési feladat kimeneteit a szükséges bemeneti formátumokra a SageMaker beépített szemantikai szegmentálási képzéséhez. Ezt követően egy gyorsított számítási példány (például p2 vagy p3) segítségével betaníthat egy szemantikai szegmentációs modellt a következőkkel jegyzetfüzet és telepítse a modellt egy költséghatékonyabb példányra (például ml.c5.xlarge). Végül néhány sornyi kód segítségével áttekintheti a következtetési eredményeket a tesztadatkészletben.
Kezdje el a SageMaker szemantikus szegmentálást adatcímkézés és a modell képzés kedvenc adatkészletével!
A szerzőről
 Kara Yang az AWS Professional Services adattudósa. Szenvedélyesen támogatja ügyfeleit üzleti céljaik elérésében az AWS felhőszolgáltatásaival. Segített a szervezeteknek ML megoldások kidolgozásában több iparágban, például a gyártásban, az autóiparban, a környezeti fenntarthatóságban és a repülőgépiparban.
Kara Yang az AWS Professional Services adattudósa. Szenvedélyesen támogatja ügyfeleit üzleti céljaik elérésében az AWS felhőszolgáltatásaival. Segített a szervezeteknek ML megoldások kidolgozásában több iparágban, például a gyártásban, az autóiparban, a környezeti fenntarthatóságban és a repülőgépiparban.
- Coinsmart. Európa legjobb Bitcoin- és kriptográfiai tőzsdéje.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. SZABAD HOZZÁFÉRÉS.
- CryptoHawk. Altcoin radar. Ingyenes próbaverzió.
- Forrás: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Rólunk
- gyorsul
- felgyorsult
- pontos
- Elérése
- elért
- át
- hozzáadott
- légtér
- algoritmus
- algoritmusok
- Minden termék
- amazon
- bejelentés
- Másik
- körül
- Társult
- Automatizált
- automatikusan
- autóipari
- elérhető
- AWS
- háttér
- mert
- BEST
- Jobb
- között
- épít
- beépített
- üzleti
- elfog
- eset
- bizonyos
- változik
- csatornák
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- osztály
- osztályok
- osztályozott
- felhő
- felhő szolgáltatások
- kód
- Közös
- verseny
- teljes
- számítógép
- számítógépek
- számítástechnika
- bizalom
- Konzol
- tartalom
- kényelem
- Megfelelő
- költséghatékony
- kiadások
- teremt
- készítette
- Ügyfelek
- testre
- dátum
- adattudós
- mély
- bizonyítani
- telepíteni
- különböző
- közvetlenül
- rajz
- alatt
- minden
- lehetővé teszi
- végtől végig
- Endpoint
- belép
- környezeti
- megalapozott
- példa
- Kivéve
- várható
- elvárja
- feltárása
- szélső
- Arc
- Funkció
- vezetéknév
- következik
- következő
- formátum
- ból ből
- generált
- Célok
- jó
- szürke
- nagy
- boldog
- segített
- segít
- segít
- jó minőségű
- házigazdája
- Hogyan
- How To
- HTTPS
- emberi
- Az emberek
- Több száz
- kép
- képek
- végre
- javul
- tartalmaz
- beleértve
- Növelje
- index
- iparágak
- információ
- bemenet
- példa
- Felület
- útkereszteződés
- bevezetéséről
- IT
- Munka
- Állások
- ismert
- Címke
- címkézés
- Címkék
- nagy
- indít
- TANUL
- tanulás
- szint
- Korlátozott
- vonal
- vonalak
- Lista
- helyi
- elhelyezkedés
- helyszínek
- Hosszú
- néz
- gép
- gépi tanulás
- kezelése
- kötelező
- kézzel
- gyártási
- térkép
- térképészet
- maszk
- maszkok
- tömeges
- mechanikai
- esetleg
- ML
- modell
- modellek
- több
- többszörös
- nevek
- elnevezési
- Navigáció
- hálózat
- hálózatok
- következő
- jegyzetfüzet
- szám
- Ajánlatok
- opció
- Opciók
- szervezetek
- Más
- saját
- szenvedélyes
- százalék
- előadó
- pont
- Poligon
- Népszerű
- Készít
- szép
- ár
- magán
- folyamat
- gyárt
- szakmai
- ad
- biztosít
- nyilvános
- célokra
- gyorsan
- RE
- nyilvántartások
- képvisel
- kötelező
- megköveteli,
- Eredmények
- Kritika
- azonos
- skálázható
- Tudós
- SEA
- szegmentáció
- kiválasztott
- szolgáltatás
- Szolgáltatások
- készlet
- beállítás
- Megosztás
- előadás
- mutatott
- Egyszerű
- helyzet
- kicsi
- So
- szoftver
- Megoldások
- osztott
- kezdődött
- tárolás
- Fenntarthatóság
- cél
- feladatok
- csapat
- teszt
- A
- The Source
- dolog
- harmadik fél
- ezer
- Keresztül
- áteresztőképesség
- idő
- szerszám
- Vonat
- Képzések
- Átalakítás
- unió
- használ
- érvényesítés
- gyártók
- látomás
- WHO
- Munka
- dolgozók
- munkaerő
- művek
- A te