A feltáró adatelemzés (EDA) egy gyakori feladat, amelyet az üzleti elemzők végeznek a minták felfedezésére, a kapcsolatok megértésére, a feltételezések érvényesítésére és az adatok anomáliáinak azonosítására. A gépi tanulásban (ML) fontos, hogy először megértsük az adatokat és azok összefüggéseit, mielőtt belevágnánk a modellépítésbe. A hagyományos ML-fejlesztési ciklusok néha hónapokig is eltarthatnak, és fejlett adattudományi és ML-mérnöki készségeket igényelnek, míg a kód nélküli ML-megoldások segíthetnek a vállalatoknak napokig vagy akár órákig felgyorsítani az ML-megoldások kézbesítését.
Amazon SageMaker Canvas egy kód nélküli ML-eszköz, amely segít az üzleti elemzőknek pontos ML-előrejelzéseket generálni anélkül, hogy kódot kellene írnia, vagy bármilyen ML-tapasztalatot igényelne. A Canvas egy könnyen használható vizuális felületet biztosít az adatkészletek betöltéséhez, tisztításához és átalakításához, majd ML modellek felépítéséhez és pontos előrejelzések generálásához.
Ebben a bejegyzésben bemutatjuk, hogyan hajthat végre EDA-t, hogy jobban megértse adatait az ML-modell elkészítése előtt, köszönhetően a Canvas beépített fejlett vizualizációinak. Ezek a vizualizációk segítenek elemezni az adatkészletek szolgáltatásai közötti kapcsolatokat, és jobban megérteni az adatokat. Ez intuitív módon történik, lehetővé téve az adatokkal való interakciót, és olyan betekintést fedezhet fel, amely az ad hoc lekérdezés során észrevétlen marad. Az ML-modellek építése és betanítása előtt gyorsan létrehozhatók a Canvas „Adatvizualizálója” segítségével.
Megoldás áttekintése
Ezek a vizualizációk bővítik a Canvas által már kínált adat-előkészítési és -feltárási lehetőségeket, beleértve a hiányzó értékek kijavítását és a kiugró értékek pótlását; adatkészletek szűrése, összekapcsolása és módosítása; és kinyerjük az időbélyegekből meghatározott időértékeket. Ha többet szeretne megtudni arról, hogy a Canvas hogyan segíthet megtisztítani, átalakítani és előkészíteni az adatkészletet, nézze meg Adatok előkészítése speciális átalakításokkal.
Használati esetünkben megvizsgáljuk, hogy az ügyfelek miért szállnak le egy vállalkozásban, és bemutatjuk, hogyan segíthet az EDA egy elemző szemszögéből. Az ebben a bejegyzésben használt adatkészlet egy távközlési mobiltelefon-szolgáltató szintetikus adatkészlete az ügyfelek lemorzsolódásának előrejelzésére, amelyet letölthet (churn.csv), vagy saját adatkészlettel kísérletezhet. A saját adatkészlet importálására vonatkozó utasításokat lásd: Adatok importálása az Amazon SageMaker Canvasba.
Előfeltételek
Kövesse a következő utasításokat: Az Amazon SageMaker Canvas beállításának előfeltételei mielőtt továbblép.
Importálja adatkészletét a Canvasba
A mintaadatkészlet Canvasba történő importálásához hajtsa végre a következő lépéseket:
- Jelentkezzen be a Canvasba üzleti felhasználóként.Először is feltöltjük a korábban említett adatkészletet a helyi számítógépünkről a Canvasra. Ha más forrásokat szeretne használni, mint pl Amazon RedShift, hivatkozni Csatlakozás külső adatforráshoz.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a import.

- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Feltöltés, majd válassza ki Válasszon fájlokat a számítógépről.
- Válassza ki az adatkészletet (churn.csv), és válassza ki Adatok importálása.

- Válassza ki az adatkészletet, és válassza ki Modell létrehozása.

- A Modell név, írjon be egy nevet (ehhez a bejegyzéshez a Churn előrejelzés nevet adtuk).
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Teremt.

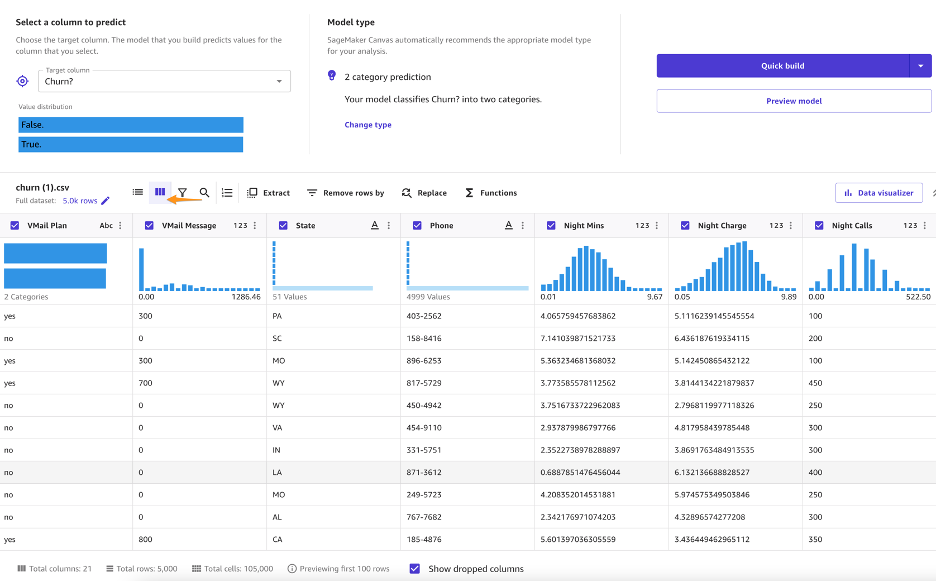
Amint kiválasztja az adatkészletet, megjelenik egy áttekintés, amely felvázolja az adattípusokat, a hiányzó értékeket, a nem egyező értékeket, az egyedi értékeket, valamint a megfelelő oszlopok átlag- vagy módértékeit.
Az EDA szemszögéből megfigyelhető, hogy nincsenek hiányzó vagy nem egyező értékek az adatkészletben. Üzleti elemzőként érdemes lehet kezdeti betekintést nyerni a modell felépítésébe még az adatfeltárás megkezdése előtt, hogy meghatározza, hogyan fog teljesíteni a modell, és milyen tényezők járulnak hozzá a modell teljesítményéhez. A Canvas lehetővé teszi, hogy betekintést nyerjen az adatokból, mielőtt modellt készítene a modell előnézetének megtekintésével. - Mielőtt bármilyen adatfeltárást végezne, válassza ki Modell előnézete.

- Válassza ki a megjósolni kívánt oszlopot (lemorzsolódás). A Canvas automatikusan észleli, hogy ez kétkategóriás előrejelzés.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Modell előnézete. A SageMaker Canvas az adatok egy részhalmazát használja fel egy modell gyors felépítéséhez, hogy ellenőrizze, hogy az adatok készen állnak-e a pontos előrejelzés létrehozására. Ennek a mintamodellnek a segítségével megértheti a modell jelenlegi pontosságát és az egyes oszlopok relatív hatását az előrejelzésekre.
Az alábbi képernyőképen látható az előnézetünk.

A modell előnézete azt mutatja, hogy a modell az esetek 95.6%-ában megjósolja a helyes célt (lemorzsolódást?). Megtekintheti a kezdeti oszlophatást is (az egyes oszlopok hatását a céloszlopra). Végezzünk néhány adatfeltárást, vizualizációt és átalakítást, majd folytassuk a modell felépítését.
Adatfeltárás
A Canvas már biztosít néhány általános alapvizualizációt, például az adatelosztást a rácsnézetben Épít lapon. Ezek kiválóan alkalmasak az adatok magas szintű áttekintésére, az adatok elosztásának megértésére és az adatkészlet összefoglaló áttekintésére.
Üzleti elemzőként magas szintű betekintést kell szereznie az adatok elosztásáról, valamint arról, hogy az eloszlás hogyan tükröződik a céloszlopban (lemorzsolódás), hogy könnyen megértse az adatkapcsolatot a modell felépítése előtt. Most már választhat Rács nézet hogy áttekintést kapjunk az adateloszlásról.
A következő képernyőkép az adatkészlet elosztásának áttekintését mutatja.

A következő megfigyeléseket tehetjük:
- A telefon túl sok egyedi értéket vesz fel ahhoz, hogy gyakorlati haszna legyen. Tudjuk, hogy a telefon egy ügyfél-azonosító, és nem akarunk olyan modellt építeni, amely bizonyos ügyfeleket is figyelembe vehet, hanem általánosabb értelemben megtudjuk, mi vezethet lemorzsolódáshoz. Eltávolíthatja ezt a változót.
- A numerikus jellemzők nagy része szépen eloszlik, követve a Gauss haranggörbe. Az ML-ben azt szeretné, hogy az adatok normálisan legyenek elosztva, mivel bármely normál eloszlást mutató változó nagyobb pontossággal előre jelezhető.
Menjünk mélyebbre, és nézzük meg a Canvasban elérhető fejlett vizualizációkat.
Adatmegjelenítés
Üzleti elemzőként szeretné látni, hogy vannak-e kapcsolatok az adatelemek között, és hogyan kapcsolódnak ezek a lemorzsolódáshoz. A Canvas segítségével felfedezheti és megjelenítheti adatait, ami segít az ML-modellek elkészítése előtt részletes betekintést nyerni az adatokba. Vizualizálhat szórványdiagramok, oszlopdiagramok és dobozdiagramok segítségével, amelyek segíthetnek megérteni az adatokat, és felfedezni azokat a kapcsolatokat a jellemzők között, amelyek befolyásolhatják a modell pontosságát.
A vizualizációk létrehozásának megkezdéséhez hajtsa végre a következő lépéseket:
- A Épít a Canvas alkalmazás lapján válassza a lehetőséget Adatvizualizáló.

A Canvas vizualizációjának kulcsgyorsítója a Adatvizualizáló. Változtassuk meg a minta méretét a jobb áttekintés érdekében.
- Válassza ki a sorok számát a mellett Vizualizációs minta.
- A csúszkával válassza ki a kívánt mintaméretet.

- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Frissítések a mintaméret módosításának megerősítéséhez.
Érdemes lehet módosítani a minta méretét az adatkészlet alapján. Bizonyos esetekben előfordulhat, hogy néhány száz-néhány ezer sorból választhatja ki a teljes adatkészletet. Egyes esetekben több ezer sor is lehet, ilyenkor a használati esettől függően néhány száz vagy néhány ezer sort is kiválaszthat.

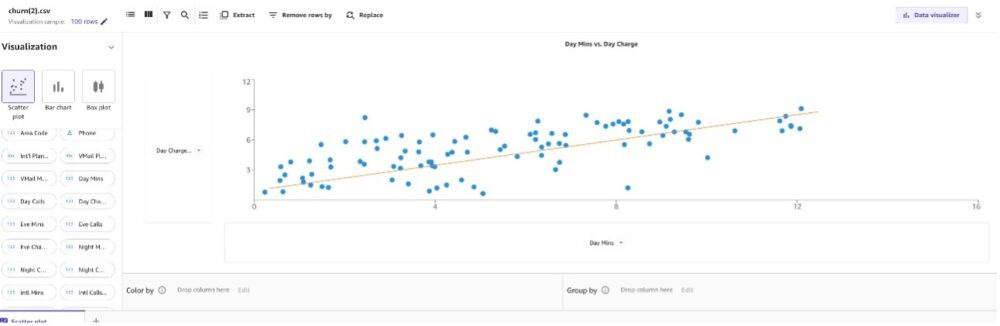
A szóródiagram két, ugyanazon egyedre mért mennyiségi változó közötti kapcsolatot mutatja. Esetünkben fontos megérteni az értékek közötti kapcsolatot, hogy ellenőrizzük a korrelációt.
Mivel rendelkezünk hívásainkkal, perceinkkel és töltésünkkel, a köztük lévő összefüggést a nappal, az esti és az éjszakai viszonyok között ábrázoljuk.
Először hozzunk létre egy szórványrajz Napi díj és napi min.

Megfigyelhetjük, hogy a Napi percek növekedésével a Napi töltés is növekszik.
Ugyanez vonatkozik az esti hívásokra is.

Az éjszakai hívásoknak is ugyanez a mintája.

Mivel úgy tűnik, hogy a perc és a töltés lineárisan növekszik, megfigyelhető, hogy ezek egymással szorosan összefüggenek. Ezeknek a jellemzőpároknak egyes ML algoritmusokba való belefoglalása további tárhelyet igényelhet, és csökkentheti a képzés sebességét, és ha több oszlopban is hasonló információk találhatók, a modell túlhangsúlyozhatja a hatásokat, és nemkívánatos torzításhoz vezethet a modellben. Távolítsunk el egy-egy jellemzőt az erősen korrelált párok mindegyikéből: a nappali töltést a nappali percekkel, az éjszakai töltést az éjszakai percekkel és a nemzetközi töltést a nemzetközi percekkel rendelkező párból.
Adategyensúly és variáció
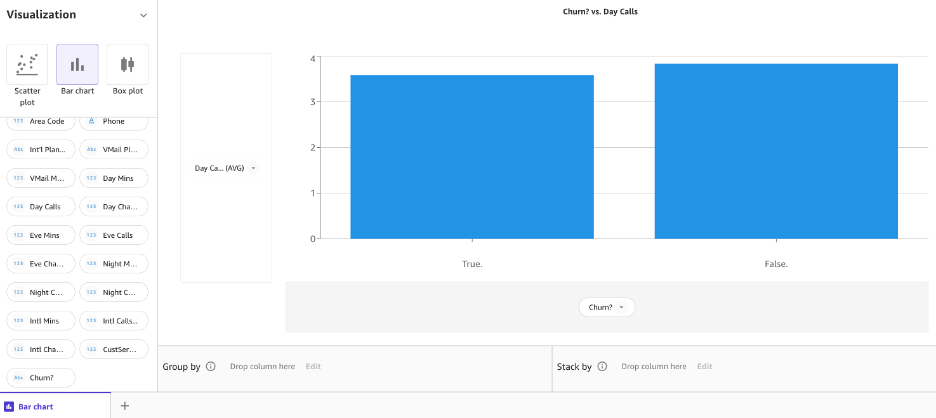
Az oszlopdiagram az x tengelyen lévő kategorikus változó és az y tengelyen lévő numerikus változó közötti diagram a két változó közötti kapcsolat feltárására. Hozzon létre egy oszlopdiagramot, amely megmutatja, hogy a hívások hogyan oszlanak meg a Churn for True and False céloszlopban. Választ Oszlopdiagram és húzza át a napi hívásokat, és leállítja az y tengelyre, illetve az x tengelyre.
Most hozzuk létre ugyanazt az oszlopdiagramot az esti hívásokhoz és a lemorzsolódáshoz.
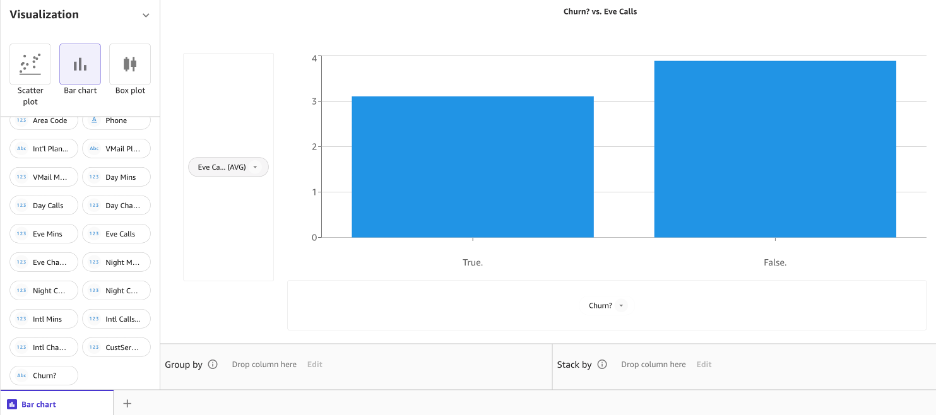
Ezután hozzunk létre egy oszlopdiagramot az éjszakai hívásokhoz és a lemorzsolódáshoz.

Úgy tűnik, különbség van a viselkedésben azoknak az ügyfeleknek, akik lemorzsolódtak, és azok között, akik nem.
A dobozdiagramok azért hasznosak, mert osztályonként (lemorzsolódás vagy sem) eltéréseket mutatnak az adatok viselkedésében. Mivel a lemorzsolódást (céloszlopot) fogjuk megjósolni, hozzunk létre egy négyzetdiagramot néhány jellemzőről a céloszlopunkhoz viszonyítva, hogy leíró statisztikákat következtessünk az adatkészletről, például átlag, max, min, medián és kiugró értékek.
A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Doboz telek és húzza át a Nap percek és Lemorzsolódás elemet az y tengelyre, illetve az x tengelyre.

Ugyanezt a megközelítést más oszlopoknál is kipróbálhatja a céloszlopunkkal (churn) szemben.
Most hozzunk létre egy dobozdiagramot a nappercekről az ügyfélszolgálati hívások függvényében, hogy megértsük, hogyan terjednek át az ügyfélszolgálati hívások a napperc értéken. Látható, hogy az ügyfélszolgálati hívásoknak nincs függősége vagy korrelációja a nap perc értékétől.

Megfigyeléseink alapján megállapíthatjuk, hogy az adathalmaz meglehetősen kiegyensúlyozott. Azt akarjuk, hogy az adatok egyenletesen oszlanak el az igaz és hamis értékek között, hogy a modell ne legyen egy érték felé torzítva.
transzformációk
Megfigyeléseink alapján eldobjuk a Telefon oszlopot, mert ez csak egy számlaszám, és a Napi díj, Este díj, Éjszakai díj oszlopokat, mert átfedő információkat tartalmaznak, mint például a perc oszlopok, de a megerősítéshez ismét futtathatunk egy előnézetet.

Az adatok elemzése és átalakítása után nézzük meg újra a modellt.

Megfigyelhető, hogy a modell becsült pontossága 95.6%-ról 93.6%-ra változott (ez változhat), azonban az oszlopok hatása (a funkció fontossága) az egyes oszlopok esetében jelentősen megváltozott, ami javítja a képzés sebességét, valamint az oszlopok hatását az előrejelzés, amikor a modellépítés következő lépéseihez lépünk. Adatkészletünk nem igényel további átalakítást, de ha szüksége van rá, kihasználhatja ML adattranszformációk adatok tisztításához, átalakításához és modellépítéshez való előkészítéséhez.
Építsd meg a modellt
Most folytathatja a modell felépítését és az eredmények elemzését. További információkért lásd: Az Amazon SageMaker Canvas használatával kód nélküli gépi tanulással jósolhatja meg az ügyfelek lemorzsolódását.
Tisztítsuk meg
Hogy elkerüljük a jövőbeli eseményeket munkamenet díjak, jelentkezzen ki vászonból.

Következtetés
Ebben a bejegyzésben bemutattuk, hogyan használhatja a Canvas vizualizációs képességeit az EDA-hoz, hogy jobban megértse adatait a modellépítés előtt, pontos ML-modelleket hozzon létre, és előrejelzéseket generáljon kód nélküli, vizuális, point-and-click felület segítségével.
A szerzőkről
 Rajakumar Sampathkumar az AWS fő műszaki ügyfélmenedzsere, aki útmutatást nyújt az ügyfeleknek az üzleti technológia összehangolásához, és támogatja felhőalapú működési modelljeik és folyamataik újrafeltalálását. Szenvedélye a felhő és a gépi tanulás. Raj egyben gépi tanulási specialista is, és az AWS-ügyfelekkel együttműködve tervezi, telepíti és kezeli az AWS-munkaterheléseket és architektúrákat.
Rajakumar Sampathkumar az AWS fő műszaki ügyfélmenedzsere, aki útmutatást nyújt az ügyfeleknek az üzleti technológia összehangolásához, és támogatja felhőalapú működési modelljeik és folyamataik újrafeltalálását. Szenvedélye a felhő és a gépi tanulás. Raj egyben gépi tanulási specialista is, és az AWS-ügyfelekkel együttműködve tervezi, telepíti és kezeli az AWS-munkaterheléseket és architektúrákat.
 Rahul Nabera az AWS Professional Services adatelemzési tanácsadója. Jelenlegi munkája arra összpontosít, hogy lehetővé tegye az ügyfelek számára, hogy adat- és gépi tanulási terheléseiket az AWS-re építsék. Szabadidejében szívesen játszik krikettet és röplabdát.
Rahul Nabera az AWS Professional Services adatelemzési tanácsadója. Jelenlegi munkája arra összpontosít, hogy lehetővé tegye az ügyfelek számára, hogy adat- és gépi tanulási terheléseiket az AWS-re építsék. Szabadidejében szívesen játszik krikettet és röplabdát.
 Raviteja Yelamanchili a New York-i székhelyű Amazon Web Services vállalati megoldások építésze. Nagy pénzügyi szolgáltató vállalati ügyfelekkel dolgozik együtt, hogy rendkívül biztonságos, méretezhető, megbízható és költséghatékony alkalmazásokat tervezzen és telepítsen a felhőben. Több mint 11 éves kockázatkezelési, technológiai tanácsadási, adatelemzési és gépi tanulási tapasztalattal rendelkezik. Amikor nem segít az ügyfeleknek, szeret utazni és PS5-öt játszani.
Raviteja Yelamanchili a New York-i székhelyű Amazon Web Services vállalati megoldások építésze. Nagy pénzügyi szolgáltató vállalati ügyfelekkel dolgozik együtt, hogy rendkívül biztonságos, méretezhető, megbízható és költséghatékony alkalmazásokat tervezzen és telepítsen a felhőben. Több mint 11 éves kockázatkezelési, technológiai tanácsadási, adatelemzési és gépi tanulási tapasztalattal rendelkezik. Amikor nem segít az ügyfeleknek, szeret utazni és PS5-öt játszani.
- Haladó (300)
- AI
- ai művészet
- ai art generátor
- van egy robotod
- Amazon SageMaker
- Amazon SageMaker Canvas
- mesterséges intelligencia
- mesterséges intelligencia tanúsítás
- mesterséges intelligencia a bankszektorban
- mesterséges intelligencia robot
- mesterséges intelligencia robotok
- mesterséges intelligencia szoftver
- AWS gépi tanulás
- blockchain
- blokklánc konferencia ai
- coingenius
- társalgási mesterséges intelligencia
- kriptokonferencia ai
- dall's
- mély tanulás
- google azt
- gépi tanulás
- Plató
- plato ai
- Platón adatintelligencia
- Platón játék
- PlatoData
- platogaming
- skála ai
- szintaxis
- Technikai útmutató
- zephyrnet